
Abstract
The task of discovering sets of good rules from imbalanced class datasets may not come easy for existing class association rule mining algorithms. The reason is that they often generate rules belonging to the dominant classes. For example, in medical applications, some symptoms of illness are not popular, and the doctors are very interested in the rules associated with these symptoms. This paper proposes a novel approach for mining class association rules (CARs) in imbalanced class datasets. Firstly, assuming there are n given classes, the training dataset is split into n corresponding groups. For each group, the data is clustered by the k-means algorithm into k groups where the value of k is equal to the number of records of the smallest group. Secondly, we combine all records from the groups after clustering and use the CAR-Miner-Diff algorithm to mine all CARs. We also propose an iterative method to get a highly accurate classifier. From experiments, we show that the proposed approach outperforms existing algorithms while maintaining a large number of useful rules in the classifier.
Keywords
Introduction
Classification is one of the most important topics in data mining and knowledge discovery techniques. Rule-based classification is one kind of classifications which has a high accuracy and an easy interpretation. Association rule mining (ARM) is the process of generating all rules in the dataset that their supports satisfy a minimum support threshold (minSup) and their confidences satisfy a minimum confidence threshold (minConf). Classification rule mining (CRM) aims to mine a small set of association rules in the dataset, in which the consequent of each rule contains a value of the class attribute and form an accurate classifier.
Many methods for rule-based classification have been proposed in recent years such as CART [4], decision trees [25, 26], ILA [31, 32], associative classification (AC) [2, 36], weighted CARs [1, 23], imbalanced classification [37], mining CARs with imbalanced attribute [40]. In which, associative classification, which integrates both association rule mining and classification [9, 29], is an efficient classification approach and attracts a lot of research interests. Its purpose is to mine a subset of association rules (denoted by CARs) where their right-hand sides are restricted to values of the class attribute (or the target attribute). Currently, there are many methods in associative classification including predictive association rules [38], multiple association rules [11], associations [7, 14], multi-class, multi-label association classification [31], multi-class classification based on association rules [13], greedy method to build classifier [29], class association rule mining based on equivalence class [17, 33], mining class association rules in updated datasets [18, 20], mining fuzzy class association rules in big data [27].
Although there have many methods to improve the accuracy of classifiers based on class association rules. However, most of them use the mined CARs to build classifiers. One of the challenges of classification based on association rules is how to determine the value of minSup to achieve a good performance. If the value of minSup is too high, the class with the small number of samples only contains infrequent itemsets, and it cannot generate any rules. This influences the prediction for new cases. Otherwise, the number of rules is very few and it also affects the class prediction stage. The problem becomes more challenging on imbalanced class datasets.
To address this challenge, we propose a method for mining CARs on imbalanced class datasets. First, we divide the dataset containing m classes into m sub-datasets, the ith sub-dataset contains the samples that belong to the ith class. Then, for each sub-dataset that has the number of records being larger than k (k is determined based on the number of rows in the smallest dataset), we use the k-means algorithm to cluster this sub-dataset into k groups and select each group a representative sample. Thus, the number of records in each sub-dataset is k. Finally, we focus on m sub-datasets and use the CAR-Miner-Diff algorithm to mine CARs.
Preliminaries for class association rule mining
In this section, we briefly introduce the definition of the associative classification problem in data mining.
Let D be a training dataset with n attributes A1, A2, . . . , An, the attribute C be a set that consists of different values, denoted by C = {c1, c2, . . . , c k }, where k ≤ |D|. With 0 ≤ i ≤ k, each value ci ∈ C represents a different class in D.
For example, Table 1 shows a training dataset D, in which there exist 8 records, the attributes are {A, B, C}, class denotes the class attribute, and class = {0, 1} (i.e., there are 2 classes).
An example of training dataset
An example of training dataset
For example, we have many itemsets, such as {(A, a3)}, {(B, b3), (C, c1)}, etc from Table 1.
Next, assuming the dataset in Table 1 is used as an example, we briefly introduce the generation of candidate rules from the dataset. Let r: (A, a1) ⟶ 0, with X = (A, a1) and c
i
= 0. We have Supp(X) = 3, Supp(r) = 2 because there are three records with A = a1, and two of them have class 0, and
Besides, we utilize the list of transaction identifications, denoted as Obidset, to calculate the support of candidate ruleitems.
Mining class association rules
CAR mining was first introduced by Liu et al. in [12]. They proposed CBA-RG (a rule generator of CBA) for mining CARs. They also proposed CBA-CB algorithm to build a classifier based on mined CARs. CBA-CB is based on a heuristic to select the strongest rules to form a classifier. It includes two phases: (1) The first phase was to generate rules; all CARs were mined using CBA, an extended of the Apriori algorithm; and (2) The second was to build a classifier by following steps: First, the set of generated rules is sorted according to descending precedence. Then, the rules are selected to form the classifier from CARs following the stored sequence. Finally, the rules in CARs that do not improve the accuracy of the classifier are discarded. The authors in [11] proposed CMAR (Classification based on Multiple Association Rules) algorithm, an FP-tree-based approach, for mining CARs. To predict a new case r, CMAR finds a set of rules (R) in the mined rule set that their right-hand sides satisfy r condition and divides the rules in R into m groups corresponding to m classes in R. A weighted χ2 is calculated for each group and the class with the highest weighted χ2 is selected and assigned to this record. This approach prunes redundant rules after mining CARs. In 2004, MMAC method was proposed [30]. The authors use multi-class, multi-label to mine CARs. Vo and Le proposed ECR-CARM (Equivalence class rule – class association rule mining) algorithm [33] for fast mining CARs with one dataset scan. The authors built the ECR-tree to store all frequent itemsets and based on the tree, they proposed an algorithm to mine CARs. Nguyen et al. proposed CAR-Miner algorithm to mine CARs [22]. Each value was stored into one node on the tree to save the time of checking the superset of itemsets. The authors also modified ECR-tree [33] into MECR-tree and based on this tree, they developed some theorems to prune itemsets that are infrequent as soon as possible and prevent joining two itemsets that have the same attributes. Nguyen et al. also proposed CAR-Miner-Diff [18] to save the time by replacing the intersection between two Obidsets by the difference between two Obidsets. Besides, mining CARs with constraints [19, 21] and mining CARs from updated datasets [18, 20] were proposed in recent years.
Clustering
k-means algorithm [15], proposed by MacQueen in 1967, is the simplest and most well-known unsupervised learning algorithms [34]. At the beginning of the algorithm process, k initial centroids are chosen where k was given by users. Then, each point of the dataset is assigned to its nearest centroid using a selected articular proximity measure (e.g., Euclidean distance). Next, the centroids for each cluster are recomputed by taking the mean of all data points in this cluster. Those two above steps are then repeated until no modification is observed in the centroid points. k-means can be seen as a greedy algorithm. This algorithm was listed in the top ten famous algorithms for data mining (Nominated by prestigious scientists for data mining at the IEEE-ICDM in 2006) [35]. The detailed mathematical convergence, as well as its proof of k-means, were presented in [15].
Instead of using the mean point as the center of a cluster, Kaufman and Rousseeuw proposed PAM (Partitioning Around Medoids) [10], a k-medoids-based clustering algorithm, to be more insusceptible to noise and outliers compared to k-means, which uses an actual point in the cluster to represent it. PAM focuses to minimize the AEC (Absolute Error Criterion) rather than the SSE (Sum of Square Errors). Like k-means, PAM proceeds iteratively between data assignments and medoid update steps until each representative object is almost the medoid of the cluster. This algorithm works well with small or medium datasets. It has performance problems when processing with large datasets. The most powerful approach based on the k-medoids algorithm, which was also proposed by Kaufman and Rousseeuw, was called CLARA. The strength of CLARA is that it can deal with larger datasets than PAM can. However, it still has some weaknesses because its efficiency depends on the sample size. Recently, CLARANS algorithm (A Clustering Algorithm based on Randomized Search) [16] was proposed for clustering objects for spatial data mining which draws samples of neighbors dynamically. This technique is considered as searching a graph where each node is a potential solution which is a set of k-medoids. The performance of this algorithm is efficient and scalable compared to those of both PAM and CLARA. BIRCH [39] is a hierarchical clustering algorithm, with a CF-Tree data structure to store the summary as clusters. It builds the tree as it encounters the data points and inserts the data points based on one or more of distance function metrics. BIRCH has the ability to incrementally and dynamically cluster upcoming objects with a single data scan. In addition, CURE algorithm [28] is also a robust approach for outliers and identifies clusters with non-spherical shapes and wide variances in terms of size. The distance between clusters is calculated based on a strategy that uses a group of points. After which, the algorithm chooses a c of well-scattered points from a cluster and it shrinks the selected points toward the centroid of the cluster using some predetermined fraction. An improved k-medoids clustering algorithm [5] using CF-Tree based on clustering features of BIRCH algorithm. This approach preserves all training sample in the tree structure then uses k-medoids methods to cluster the leaf nodes of the tree. It then scans from the root of CF-Tree to get k clusters.
Mining class association rules based on clustering
AC-Cluster algorithm
Our proposed approach has three steps as follows. The first step is to split the training dataset into m sub-datasets corresponding to m classes. For each sub-dataset that has the number of records greater than k, k-means algorithm is used to cluster all the records into k groups. In each group, our algorithm selects a representative record that is so-called the kernel record of each group. Therefore, each sub-dataset has k records.
In step 2, we can use k-means, k-medoids, etc., for clustering. In our experiments, k-means clustering algorithm was used on the experimental datasets because of its effectiveness. Euclidian measure is used to compute the distance between two objects. We select the record that is the closest one to the center of each cluster as a representative record.
In step 3, we can use any class association rule mining algorithms to mine CARs such as CBA [12], CMAR [11], MMAC [30], CPAR [38].
An illustration of AC-Cluster
Following is an illustration for the steps of the algorithm in Fig. 1.

The steps for mining class association rules based on clustering.
An example of imbalanced dataset (5 records belong to class 0 and 2 records belong to class 1)
Dataset D’ after clustering and reordering OIDs
Class association rules from dataset D’
One of the weaknesses of k-means is that the clusters may be different in different runs. It, therefore, effects on the accuracy of classifiers. To improve the accuracy, we propose an improved method to choose a good classifier by running AC-Cluster n times on the training dataset D to create n classifiers and choose the classifier with the highest accuracy in D.
Conf (r1)> Conf (r2) Conf (r1) = Conf (r2) and Supp(r1)> Supp(r2) Conf (r1) = Conf (r2), Supp(r1)> Supp(r2) and r1 is generated earlier than r2.
1. u ≤ v.
2. ∀k∈ [1, u] : (A
i
1
, a
i
1
) ∈ {< (B
j
1
, b
j
1
) , … (B
v
1
, b
v
1
) >
The details of the improved method is shown in Fig. 2.

An improved version of AC-Cluster.
Remarks for the improved version of AC-Cluster:
Algorithms were coded by C# 2012 in PC with Intel Core i3-350 2.26 GHz, 4GB RAM, 320GB. Experimental datasets were downloaded from http://mlearn.ics.uci.edu and characteristics of them are shown in Table 5.
Experimental datasets
Experimental datasets
Breast, Iono have two classes and the percentage of class 0 is nearly 2 times larger than class 1. Iris has three classes, and this is a balanced dataset (we use it to show that AC-Cluster does not effect on balanced class datasets). Zoo has 7 classes and the percentage of the smallest class is 3.96% while the percentage of the biggest class is 40.6%. Breast, Iono, and Zoo are imbalanced class datasets.
We choose these datasets for our experiments because of the following reasons: We want to have both imbalanced datasets (Breast, Iono and Zoo) and balanced dataset (Iris) in our experiments. For imbalanced datasets, we want to have both two classes (Breast, Iono) and multiple classes (Zoo with 7 classes).
Besides, we also want to show the experiments in datasets that the ratios among classes are small (such as Breast and Iono) and large (such as Zoo).
Experimental results were evaluated based on the four datasets from Table 5. Classifiers are built based on mined CARs using CAR-Miner-Diff and Improved-AC-Cluster with c = 1 and 1.2. We choose CAR-Miner-Diff to mine CARs because it is a state-of-the-art algorithm for mining CARs.
We compare the accuracy of the two algorithms with a fixed minConf = 60% for all datasets and n is set to 4. Algorithms are tested using 10-fold cross-validation.
Figures 3 to 6 compare the accuracy of CAR-Miner-Diff and Improved-AC-Cluster (n = 4).
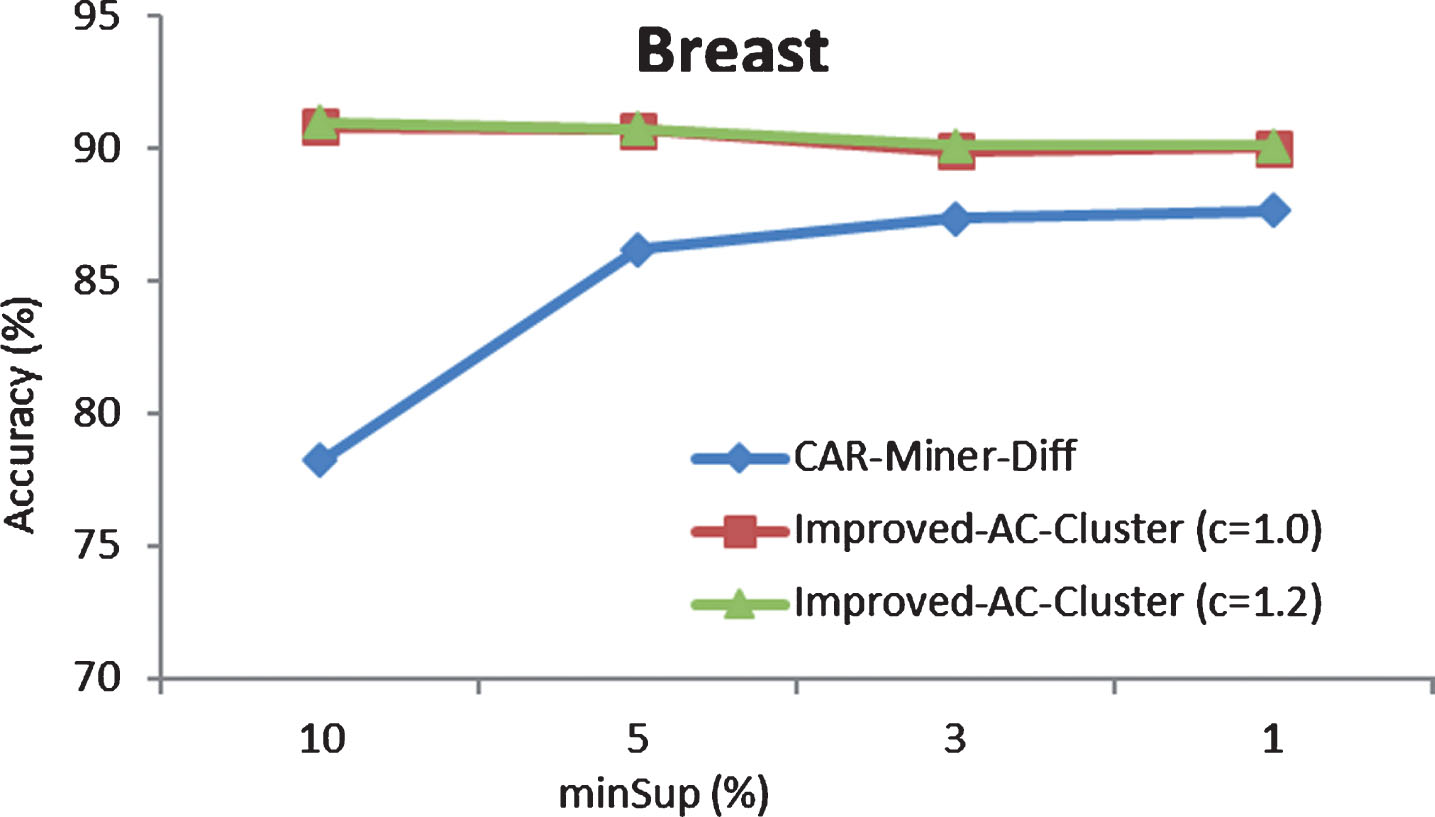
Comparison of the accuracy between Improved-AC-Cluster and CAR-Miner- Diff in Breast dataset.
Figure 3 presents the comparison between Improved-AC-Cluster and CAR-Miner-Diff in Breast dataset. We can see that Improved-AC-Cluster has a higher accuracy than CAR-Miner-Diff. For example, with minSup = 10%, CAR-Miner-Diff has the accuracy of 78.25% while Improved-AC-Cluster with c = 1.0 has the accuracy of 90.84%. For a lower minSup, the accuracy of CAR-Miner-Diff is increasing but the accuracy of Improved-AC-Cluster is always better. The highest accuracy of CAR-Miner-Diff is 87.68% at minSup = 1% while the lowest accuracy of Improved-AC-Cluster with c = 1.0 is 90.06% at minSup = 1%. When we change c from 1.0 to 1.2, the accuracy of Improved-AC-Cluster is just slightly changed. One of the strong points of Improved-AC-Cluster is that it can achieve a high accuracy at a high minSup. Improved-AC-Cluster improves the performance of both two steps of classification including (1) Building classifier; and (2) Prediction.
Figure 4 presents the comparison between Improved-AC-Cluster and CAR-Miner-Diff in Iono dataset. Improved-AC-Cluster also has a higher accuracy than CAR-Miner-Diff. The results are the same Breast dataset.
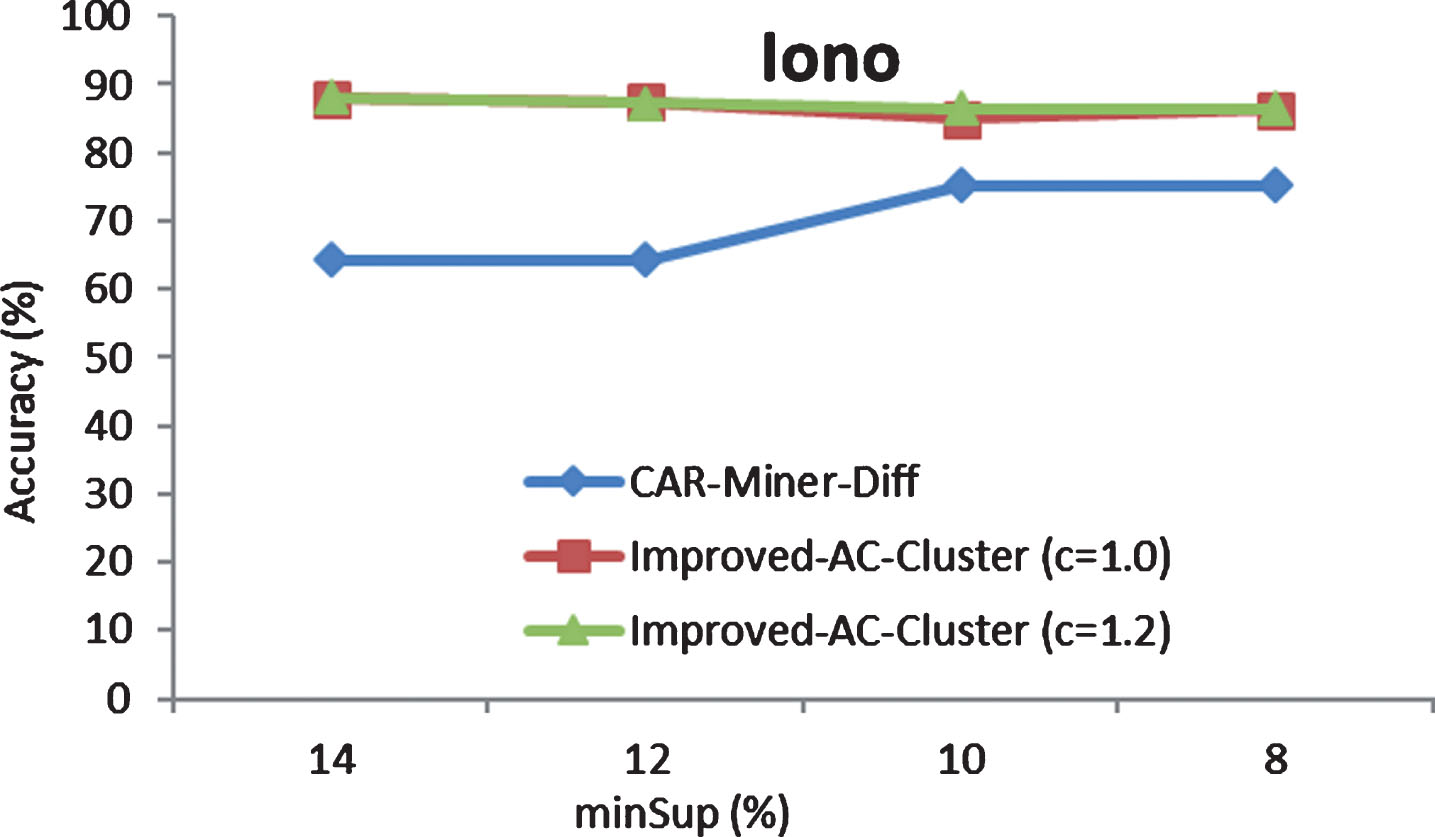
Comparison of the accuracy between Improved-AC-Cluster and CAR-Miner-Diff in Iono dataset.
Figure 5 compares the accuracy of between Improved-AC-Cluster and CAR-Miner-Diff in Iris, a balanced class dataset. The accuracy is not different between Improved-AC-Cluster and CAR-Miner-Diff.

Comparison of the accuracy between Improved-AC-Cluster and CAR-Miner-Diff in Iris dataset.
Figure 6 shows the accuracy results in Zoo dataset. We can analyze the results as follows: Comparison of the accuracy between Improved-AC-Cluster and CAR-Miner-Diff in Zoo dataset. Improved-AC-Cluster is significantly better than CAR-Miner-Diff. For example, with minSup = 10%, CAR-Miner-Diff has the accuracy of 72% while Improved-AC-Cluster with c = 1.0 has the accuracy of 78% and with c = 1.2 it has the accuracy of 78.4%. For a lower minSup, the accuracy of CAR-Miner-Diff increases but the accuracy of Improved-AC-Cluster is always better. The highest accuracy of CAR-Miner-Diff is 76% at minSup = 4% while the lowest accuracy of Improved-AC-Cluster with c = 1.0 is 78% at minSup = 10%.
When we change c from 1.0 to 1.2, the accuracy of Improved-AC-Cluster is better on Breast and Iono. This result shows that when the ratio between the majority class and the minority class is large, increasing c will increase the accuracy.
In this paper, we proposed a new method for classification based on association rules in imbalanced class datasets. The proposed method used clustering to balance the dataset and CAR-Miner-Diff to mine CARs in the balanced dataset. We also proposed an improved method to improve the accuracy of the classifier. Experimental results showed that our method has a higher accuracy than the method does not use clustering.
One of the weaknesses of our method is that it will remove many records when the number of records in the smallest dataset is small (and c is small). In future, we will expand our method to choose a suitable value of c. We will try to use others clustering methods in imbalanced datasets. Besides, this method will be used with other classification methods such as decision trees, ILA, SVM, etc. We also study how to fill data [24] for incomplete datasets for a better classification.