
Abstract
The development of efficient methods for searching and browsing large assets of video content has been considered by the academia and content owners for long. Different approaches that range from manual structured annotations, to unstructured metadata collected from several sources, as well as multimedia processing for automatic description of the content, can be identified. The growth on the number of hours of video content put online in video sharing platforms has however shown that video retrieval is still quite inefficient as rich contextual data that describes the content is most of the times still not available. Additionally, metadata is usually not linked to timed moments of content, making direct access to the most relevant moments not possible. In this paper, an approach for making web videos available in the YouTube platform more accessible is presented. The solution is based on a collaborative process presented as a game that enables collecting metadata from the crowd while implementing mechanisms that remove erroneous information usually encountered in this type of information. Metadata, exported to YouTube in the form of captions and descriptions, contributes to enhance video retrieval, guaranteeing a better user experience and exposure of the content.
Keywords
Introduction
Online video platforms have provided the ground for multimedia content to become widely used and a source of information and entertainment for millions of users. Among the different video sharing websites such as Vimeo 1 , YouTube 2 and Dailymotion 3 , YouTube is certainly the most popular, with videos shared amongst 1.5 billion of users across the whole world. With more than 300 hours of video uploaded every minute, YouTube offers a valuable knowledge base for multimedia data [1]. Apart from allowing users to upload and share their videos, it also encourages them to enrich the visual content with context information that includes tags, categories, title, etc. This process results in coupling massive amounts of content with user-generated metadata that greatly facilitates video retrieval and browsing by using text-based search engines.
YouTube success is not only a consequence of its huge collection of videos. It is also influenced by its diversified video discovery mechanisms that include video recommendations and highlights, a keyword based search engine, channel subscription, and the multiple embedding capabilities on websites and social networks. By helping exposing videos to the users, these discovery mechanisms allow users to become aware of videos of their interest in the huge video repository and to direct them to view this content. However, the current approach is based on the association of descriptions to the full content and no timecoded annotations are available. Therefore, search performance and accuracy are unlike to be satisfactory, since users must watch the entire video to find parts of their interest – a tedious and time-consuming task. This lack of timecoded annotations will make some of the users to miss the chance to watch the intended scenes at a specific time [2]. Generating descriptions associated to specific points in the video is then an important feature to improve the quality of experience when browsing large assets of video content.
However, manually annotating video streams is an expensive and time-consuming process, demanding new methods that enable the creation of richly described video assets. Several video annotation approaches have been proposed, but no solution has been yet provided for creating metadata to improve third party platforms like YouTube.
In this paper, we propose using a collaborative video annotation game platform to extend YouTube metadata with timecoded descriptions. Crowdsourced metadata created in the game produces tags of YouTube videos which are then exported to YouTube as description and captions files in order to be indexed by YouTube’s search engine. Our work will contribute to create better video content descriptions, which will enhance video searching results, as well as help users to quickly find scenes of their interest without having to watch the full stream.
This paper extends previously published work [3] by providing 1) a deeper overview of related work; 2) details on relevant aspects of the YouTube Platform; 3) supplementary information on the architecture and implementation of the proposed solution; 4) additional results; 5) further information on future work.
Related work
Methods for efficiently searching and browsing in large assets of video content are essential for the user not to be overwhelmed with irrelevant information. Different approaches have been proposed for managing professional video archives in large broadcasters or other content owners. The same goal can be identified in video sharing websites that have been proliferating on the web. By allowing both ordinary people as well as professionals to share videos, vast content repositories have been created. However, most of them only provide brief descriptions of the content, with no temporal linking to specific timecodes. However, most of the times, users of those platforms not only want to simply watch videos but do also want to be able to navigate into the content in an efficient way. The use of slider bars in video players may enable browsing and repeating chosen scenes but keyword searching should enable directly access to a specific happening in the video. Unfortunately, it is rather difficult to directly support this enhanced user interaction in existing video platforms because of the lack of metadata that can facilitate such interactions.
Different approaches have been described in the literature with the aim of improving the usability of social sharing platforms like YouTube or Flickr 4 Solutions include extracting from comments information on the content, that might include not only the identification of relevant objects and other contextual data but also sentiment analysis [4, 5]. Extracting visual features from the video to enable the identification of high-level information has also been exploited. This approach requires, however, more computational resources.
Using YouTube comments to facilitate access and retrieval of online videos has been a natural approach due to the fact that social platforms promote the interaction with users as an engagement factor: having the chance of contributing with opinions and discussing the video content, contributes to a feeling of participation and belonging. On their proposal [6], authors describe a set of temporal transformations for multimedia content that allows end-users to create and share personalized timed-text comments that are combined chronologically. A survey confirms a better user experience when watching videos together with these timed related comments. However, this solution uses the deprecated Flash Player.
Based on social interaction in the form of comments and weblog authoring, [7] describes a mechanism for helping users associating video scenes with user comments, to generate tags that quote video scenes and to extract deep-content-related information about video contents for automatic annotation. This solution is, however, made available as a standalone Windows application, not web-based. Moreover, it is too complex for a standard user and requires the user to fill a lot of specific metadata fields to annotate a simple video.
The use of comments to increase the efficiency in the transmission of the concepts associated with a course has also been considered in software coding tutorials that enable programmers to visually write, debug and execute code. By using an efficient linear probabilistic classifier in combination with machine learning algorithms and text processing techniques, [1] detects useful viewer’s comments that can help content creators to understand the needs and concerns of their viewers and, therefore, increasing the quality content.
Annotations originated from sentiment analysis and modelling of emotions based on YouTube channel comments has been proposed by [8]. The solution developed uses gamification approaches to help on the collection of the information that is then used to enable content recommendation.
Sentiment analysis on the comments of anorexia-topic videos has also been used in [9] to study emotional reactions while watching the videos. Sentiments on comments in both pro and anti-anorexia videos using ordinary least squares regression models was analyzed. The results shown that anti-anorexia videos had both more positive comments and more likes than pro-anorexia videos. By studying the correlation between comment’s sentiments and comment rating, the work presented in [10] concluded that it is possible to create a classifier that accurately predicts which comments are useful and which are not. This enables filtering the more adequate information to be used for video indexing.
A tool that supports the automatic fragmentation and concept-based annotation of videos, and the exploration of the annotated video fragments through an interactive user interface is presented in [11]. The developed application decomposes the video into shots and scenes, and annotates each fragment by evaluating the existence of high-level visual concepts in the key-frames extracted from those fragments. The tool enables labeling and linking semantically coherent video fragments, allowing retrieving these fragments using human-interpretable concepts.
The work described in [12] considers both information extraction from the visual content as well as user contributed tags. It suggests a method to automatically annotate shots of YouTube videos using Flickr images. Authors have developed a system for video tag suggestion and temporal localization based on collective knowledge embedded in tags and Wikipedia and visual similarity of frames and images uploaded to social sites like YouTube and Flickr. The tags provided by the users that share videos on internet are located within the shots and new tags are added.
Video entity linking, which connects online videos to the related entities in a semantic knowledge base, can enable a wide variety of video-based applications, including video retrieval and video recommendation. The solution presented by [13] proposes exploiting video visual content to improve video entity linking. Videos obtained from YouTube are first linked to entity candidates using a text-based method and the entity candidates are verified and re-ranked according to visual content. The experiments on a large annotated YouTube video set have demonstrated the effectiveness of the proposed model.
A collaborative algorithm for semantic video annotation using a consensus-based social network analysis is proposed in [14]. A method to semantically embed media content with available information from the Internet is presented. A multimedia ontology that semantically describes the media content and each media object is considered for offering advanced semantic search functionalities and to facilitate the sharing of media content among heterogeneous agents. According to the experimental results, the density of the network can contribute to address conflicts over the annotations and provide additional confidence created by trustable users.
ShotTagger [15] uses a combination of context and content-based methods to annotate the shots corresponding to the same tag within YouTube videos. Based on co-occurring tags and temporal smoothing, annotations are refined enabling consistency across shots. The results have shown the feasibility and effectiveness of tag annotation and tag-based shots, as well as, how locating tags into video can be achieved in a tag-based video browsing.
To accomplish tag suggestion for web videos, the solution proposed in [16] searches relevant images in user-shared photo collections based on existing tags. It then models relationships between tags associated with the retrieved images and the key-frames of the original video using a bipartite graph.
With the goal of building a semantic representation and annotation of video shots, [17] applied 34 concept detectors to video frames. The same detectors were applied to Flickr images and semantic similarity with video frames is used to suggest tags selected from those of the images.
A tag cloud based scene annotation method has been proposed in [18]. YouTube comments associated to a video are collected and processed for creating a tag cloud based on those comments. Based on the user clicks on a tag in the cloud while watching the video, the tag gets associated with the scene in the video. The main drawback of this proposal is not using HTML5 technologies to present and control the videos and the restriction of the set of allowed tags to the ones extracted from the comments.
A social media annotation system relying on a collaborative process and including the temporal duration of the scenes has been proposed in [19]. The application allows users to annotate content using free-text or following ontologically rules, with the objective of enhancing faster retrieval when browsing and searching for videos (specific scene, events, object, etc.).
The use of speech recognition to improve descriptions of online content has also been proposed.
A framework for extracting relevant information from the audio track is exploited in [20]. Results show that the superimposition of relevant text and image-based information could be used for augmenting the viewing experience, as well as to give a full context-aware perception.
A browser extension that enables crowdsourcing of event detection in YouTube videos through a combination of textual, visual and behavior analysis techniques has been proposed in [21]. Based on the analysis of the visual content, it offers the user the choice to quickly jump to a specific shot in the video by clicking on a representative frame. The available metadata combines the one uploaded by the video owner such as title, description, tags, etc., and closed captions, which can be user-generated or auto-generated via speech-recognition. Interest-based event detection is achieved by counting clicks on shots. Although this seems promising, it requires installing a browser extension, what could be an obstacle for a significant number of people. Furthermore, as in the examples above, the produced metadata is not stored on YouTube and does not then contribute to enrich the platform’s video content.
An automatic Video Tagging System (ViTS) that joins video analysis and user comments is proposed in [22]. It analyses videos using computer vision techniques to extract relevant scenes and quickly understand their semantics’ contents. By combining a web scraping and social media information, each video is enriched in real time with new tags and relations between concepts. Evaluation of results using YouTube-8M dataset was performed by volunteers that manually validate the created annotations and the experiment shows a precision of 80.9% tag agreement. However, this kind of implementation can lead to a reduced number of different labels. An improvement to this approach is described in [23] that proposes identifying the relevance of the tags and enables detecting irrelevant misleading metadata for YouTube videos. By gathering the semantics of all the tags in a video, and based on the hierarchical semantic relationships and extending the Google distance concept, authors determine the co-occurrence in text search results and compute similarity between words using Google page counts. Additionally, they use user-generated comments and try to predict each comment sentiment by using natural language processing, text analysis and computational linguistics to identify and extract subjective information in text.
Although the different approaches identified are promising on the purpose of enriching video content with additional information, all of them present several limitations. Besides the ones already identified, the most important drawback of these proposals is the lack of a functionality that enables making the provided metadata available for everyone. This means that metadata is stored locally, and only local users who provided the annotations have access to this information. The full YouTube’s community does not have a solution for accessing videos enhanced with richer content information. When considering comments as a mean to provide additional information, it is also important to consider the fact that, although user comments are quite popular in YouTube, they are also extremely controversial and usually acknowledged as very noise. Given of the amount of comments posted daily, makes the task of filtering good video related comments not easy.
The impact on having metadata available in the YouTube platform has been confirmed in several studies. YouTube captions mechanism has proven to be a good method to increase views. An experiment has found an overall increase of 7.32% in views for captioned videos [24]. Professional services are even available for adding captions to YouTube videos [25]. However, the service is paid and only transcribes the audio.
The question on how YouTube videos are discovered and its impact on the three major view sources (video recommendation, search and highlights) has been analyzed by [2]. Authors have concluded that the YouTube recommendation system increases the view diversity, while search and video highlights create an effect of rich-get-richer. They also conclude that those mechanisms would benefit from the appropriate keywords being placed on the related video lists of more popular videos.
In our proposal, we try to overcome the identified limitations by implementing mechanisms for the validation of descriptions provided by users, eliminating noisy and irrelevant flawed inputs, and by making this validated metadata available to the full YouTube’s community using the captions and description fields. By using crowdsourced information and by implementing automatic validation mechanisms, it does not require high computational costs as the solutions based on visual feature analysis, and erroneous information is not considered.
YouTube video platform
The online video sharing website YouTube was originally created in February 2005 to help people sharing videos of personal or well-known events. It provides a forum for people to engage with video content across the world and acts as a distribution platform for content creators.
YouTube content ranges from professional to amateur and the diversity of videos goes from TV clips to short videos with a variety of content types, such as tutorials, educational videos, music clips, video blogging, etc. The popularity of the platform is driven by the easiness of sharing and reproducing video content [26].
Several other key factors that helped YouTube to reach success can be listed: 1) the video recommendation feature helps users to easily find videos from the same author; 2) a list of related videos where similar video content is displayed enables spreading content users might not be aware of; 3) a sharing functionality enables videos to be easily embed in others websites or social networks; 4) the comments that a registered user can insert, providing his opinion/doubts about the content enable creating communities of active users; 5) captions enable improving accessibility for the hearing impaired and non-native speakers; etc.
Despite its success, YouTube and all the other social platforms that enable sharing a lot of videos, do not provide mechanisms for direct access to specific points of the stream. They usually only provide brief and generic information for an overall contextualization of the content.
Search mechanisms
YouTube doesn’t yet include the tools for automatic scene description. This means that the system depends on provided metadata and relevant information to help users to find content when searching for something. Therefore, uploaders should create useful and optimized metadata to have better chances for their video to be found. Some important good practices that could help on this goal are: Title: in a few words, users should create an optimized title that perfectly matches the video content and that includes the major keywords of the video. Tags: the use of relevant tags increases the chance of reaching people to whom the video is relevant. Description: a full description, with more than just a few words, will contribute to rank the video higher in the search engine. Closed captions: closed captions help viewers understanding the video narration and provide an additional indexing data. Moreover, by enabling the translation to different languages, content becomes more universally available. Users’ reactions: comments, likes and shares are a great social indication of impact, and comments are especially good for getting feedback and insight from audience. Thumbs up and sharing the video are all positive signals to YouTube for sending searchers to the right video.
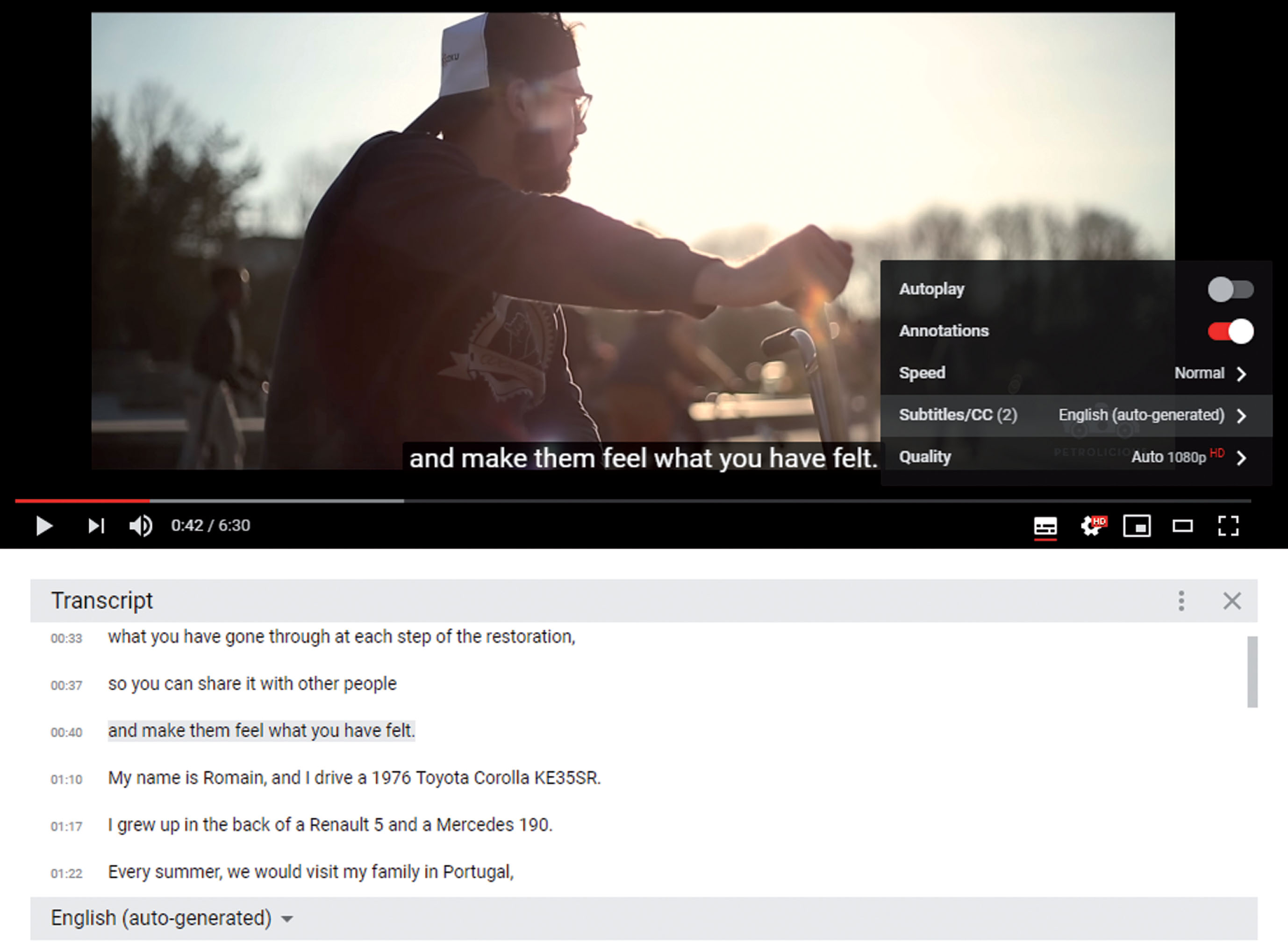
YouTube automatic captions.
By using all this information, YouTube search engine will have a lot more data associated to the video, and not just a title or description of that video, enabling more precise results on a search query.
For the purpose of this paper, we will focus on a new approach of using the captions and description features to improve search for videos and, more important, search within videos on YouTube.
YouTube allows owners to upload their own closed captions file as subtitles to YouTube videos. A subtitle or closed caption file contains the text transcription of the audio stream and the time codes for when each line of text should be displayed. Some files also include position and style information enabling the customization of the presentation.
A vast list of captions’ file formats is supported. The most usual formats are SubRip (.srt), SubViewer (.sub) and YouTube’s preferred format – Scenarist Closed Caption (.scc). A new feature that allows uploading a simple text transcript of the spoken content and leave synchronization decision to the speech recognition mechanisms of YouTube is available. This feature avoids the need of having to manually transcribe the spoken video content and define start/end times.
Figure 1 shows a YouTube video with automatic generated captions. These captions are overlaid on the video content, by clicking on the “CC button". As shown in the bottom part of the figure, close captions allow the video to be browsed by clicking on a given segment in the scrollable part of the entire caption track.
Design and implementation
Figure 2 presents the main blocks and workflow of the implemented platform. By combining a game-based annotation system and YouTube, it provides an innovative solution for audiovisual content management and access. In a first step, YouTube videos are made available for the annotation application, and after having metadata contributed and validated by the crowd, this information is uploaded to YouTube in the form of captions and descriptions.
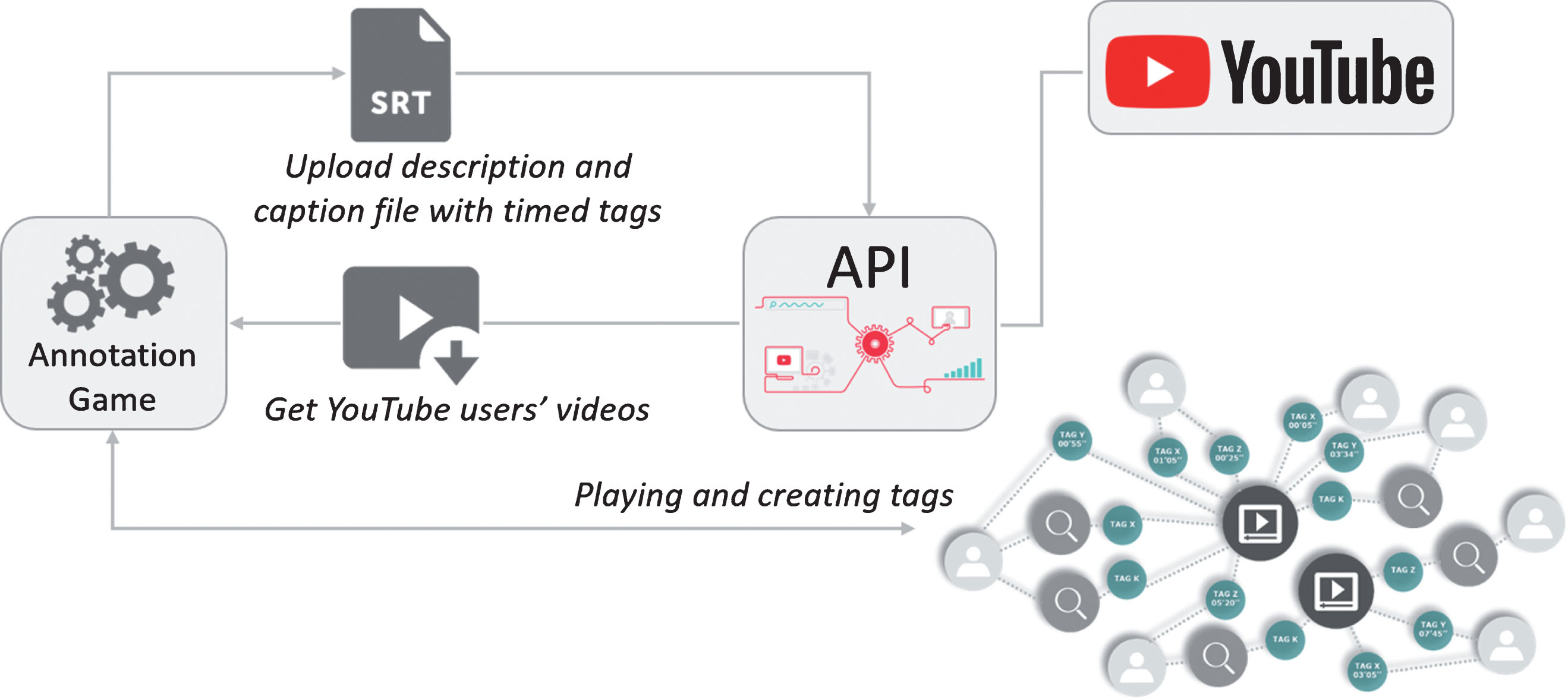
Proposed system architecture.
The annotation system relies on a collaborative process and on gamification mechanisms to engage users on the tagging process. The game includes two main parts: 1) a competition mode phase, where players are invited to provide tags while watching a video and 2) a crowd judgment mode, where players may provide their opinion on the quality of the available metadata and identify the most relevant moments in the video.
In the competition phase, tags may be freely introduced and, following the concepts used in GWAP (Games with a Purpose), players are rewarded if their contributions provide valid inputs. The created labels, or tags, are associated to specific video timecodes, enabling improving the access to exact instants of a video clip.
Former introduced information is used in the scoring mechanism as an incentive for users to provide correct tags. Tag validation is achieved through a collaborative process, by analyzing the matchup between players’ contributions. Additionally, semantically correlated tags are also considered, enabling enhancing and improving the quality of the dataset.
The tag validation mechanism considers three aspects: the tag itself and the list of semantically correlated tags obtained from a dictionary; groups of tags organized in clusters; the number of times a tag, or correlated tag, appears in the respective cluster.
A set of matching tags located nearby each other generates a cluster. Each one has a pre-defined length and is described by its centroid. The distance of a tag to its centroid has an impact on the score obtained: 100, 50 and 10 points are possible. The higher the score, the closer the user is to the centroid. In this experiment, clusters were assigned windows of 12 sec width, while scoring was linked to 8, 6 and 4 sec time slots.
On the contribution of a player, the tag is checked against the existing clusters. If no match is found, a new one is created. Assignment to a cluster considers a pre-defined distance from its centroid and its correlated tags. Contributing a tag may result, or not, on the award of a score and on the validation of a tag if the number of agreements reaches a defined threshold.
These mechanisms allow filtering erroneous information usually found on free tags and comments, to link metadata to timecodes and to have a collaborative effort on enhancing video information.
The first player to introduce a tag that is later validated by other players will have his effort compensated through an offline mechanism that rewards this first effective contribution. An additional bonus is considered for having antedated useful metadata when the requirements for a score attribution are reached.
The quality of the metadata is further enhanced by using a semantically aware dictionary that provides additional concepts. This dictionary, based on the NUS-WIDE database [27], was integrated in the system allowing not only to match words but also meanings and concepts. A total of 269,648 Flickr images with 424,853 tags was considered to create the dictionary. This allows the system to extend the default tag matching and, consequently, to enhance and improve the quality of the available metadata. Besides proposing synonymous, it provides matching concepts that frequently occur together enabling going beyond simple relations and guessing additional context-aware concepts. Figure 3 illustrates this idea of semantically related tags that co-occur together. Each node represents a concept which is linked to other relevant concepts through weighted edges that can be used to define confidence levels for the selection of additional concepts. Table 1 presents some of the results accomplished using this approach.
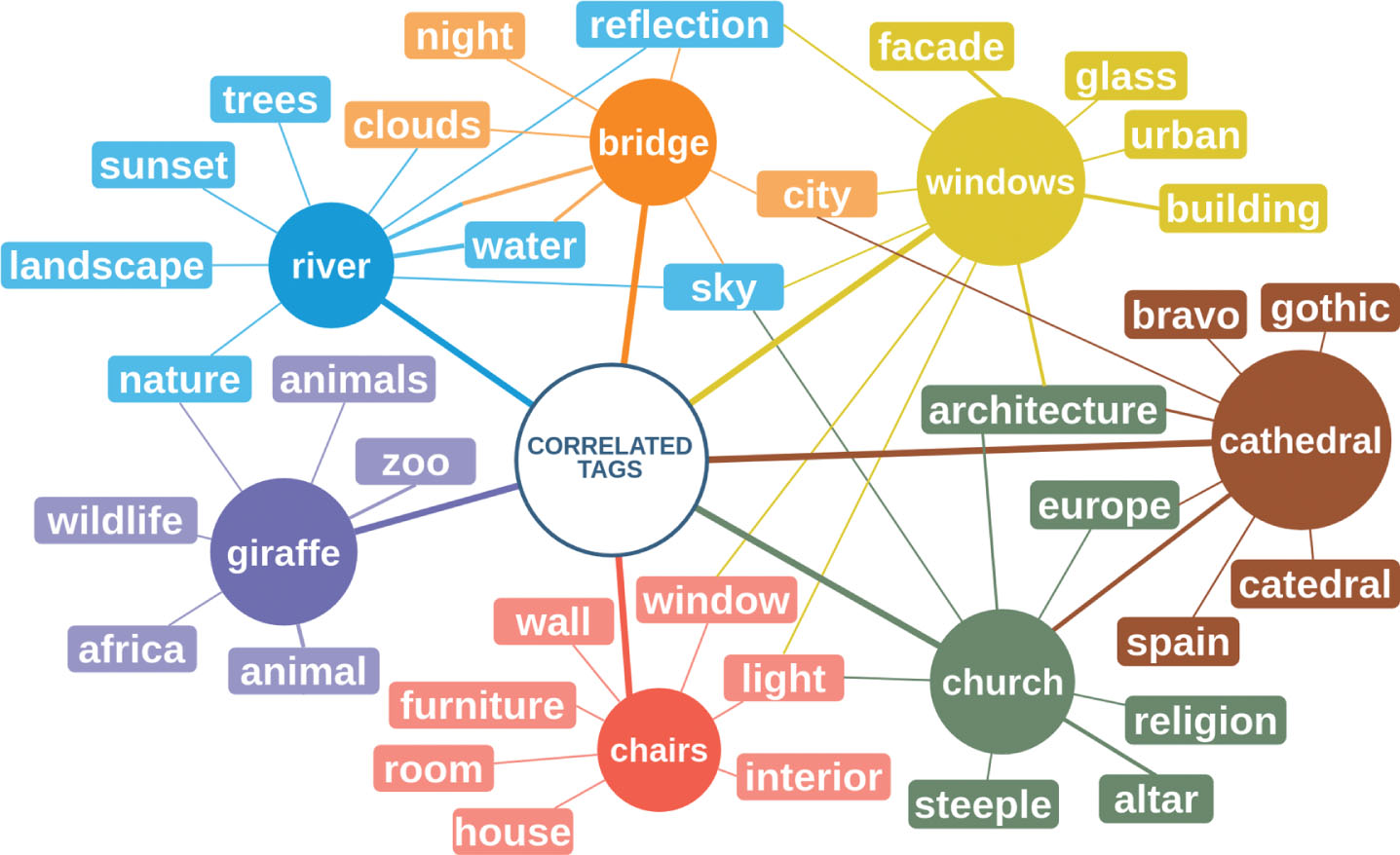
Network of correlated tags.
Correlated tags
Besides scoring, other rewarding mechanisms that help on motivating good contributions and on maximizing the performance, are implemented. Prizes for finishing an action, such as special badges, the definition of different game levels that the player may access and a leaderboard that shows his performance are some of the flagships that player will find. Game levels are used on benefit of the annotation process as more difficult tasks (videos with less metadata are less likely to produce scoring) are provided to more qualified players.
Besides contributing with metadata, in the crowd judgment mode of the game, players may also provide information that helps on the quality control of the tags. Actions such as liking or disliking a contributed tag are used as an additional parameter for tag quality monitoring Fig. 4.
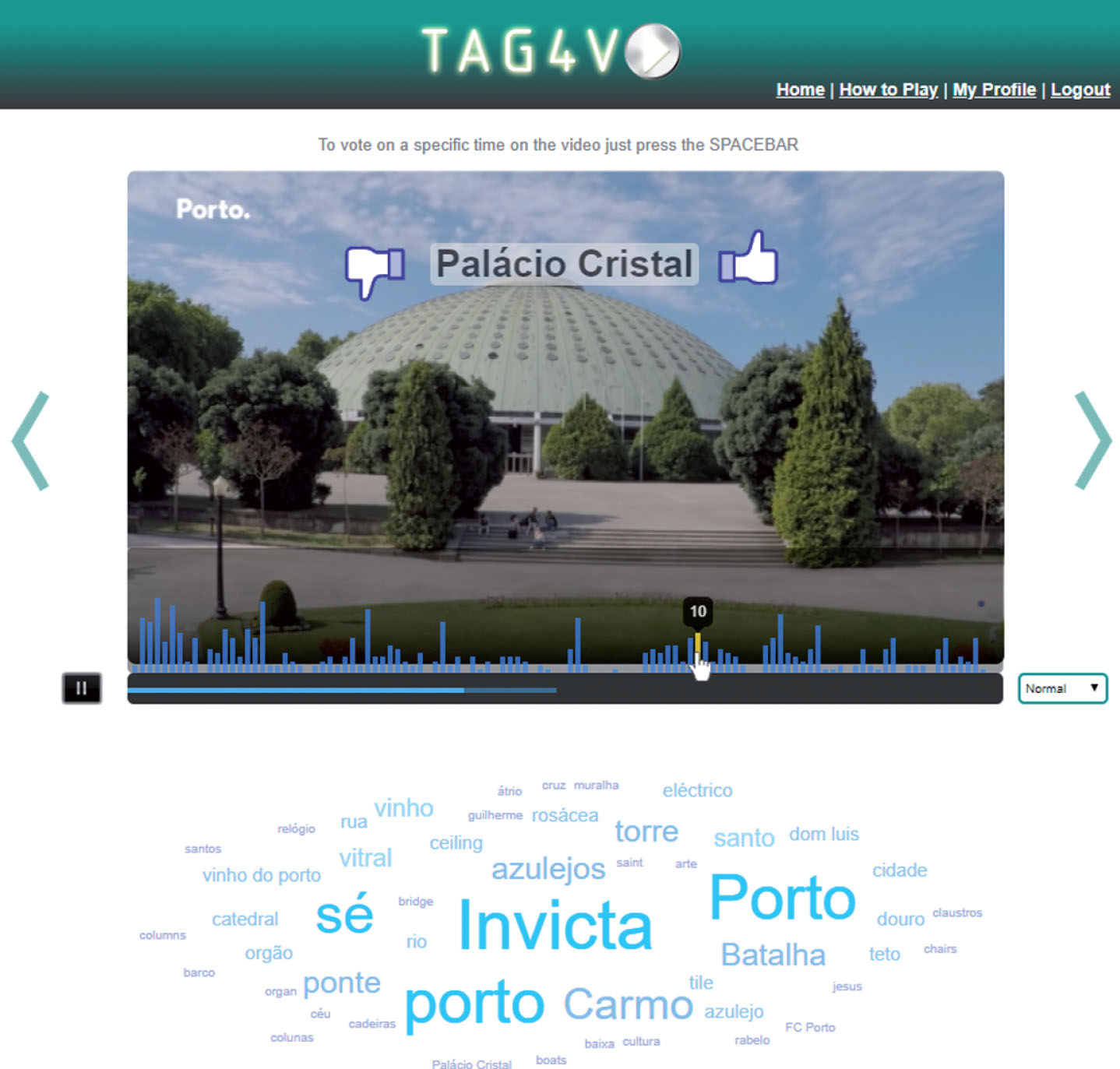
Game’s crowd judgment mode.
A full description of the game functionalities is provided in [28, 29]. Performance, usability, user engagement and tag accuracy, have been assessed in a user testbed [30].
The YouTube Data API enables developers to incorporate a variety of YouTube functionalities into their applications by providing access to the videos and user information.
To enable including YouTube videos in the annotation process, on user’s consent, the system retrieves the videos on a YouTube account, integrating them in our platform. To make the procedure simple, future requests on user’s behalf are enabled by extracting an access token that is used for all the needed communication between our platform and YouTube, providing then a transparent, non-intrusive process. No additional action is then request to a user willing to use the annotation game for enhancing his YouTube video description content. Token renewing is also automatic, enabling access to the user account even when he is offline.
Table 2 shows the main steps used for the upload/update process under YouTube API.
YouTube upload/update API process
YouTube upload/update API process
To enable sharing his videos with the game engine and to make them available for the annotation community, the owner is requested to select his content (Fig. 5). Video IDs are then uploaded into the annotation system.

Video selection framework.
Inserted tags are initially stored locally to enable using the validation mechanisms, comparing and matching time-related information. Caption and description files that include the tag and the associated timecode, are automatically created and upload to the YouTube account when conditions for a tag to become validated are achieved 0. This makes the metadata fully available for everyone.
Figure 6 exemplifies the use of the YouTube’s description field, for the storage of timed tags imported from the annotation game. Not to lose any relevant data, the initial description provided by the owner is kept but the field is updated with the navigable tags that, besides helping enhancing search precision, enable jumping to exact moments on the video. Figure 7 illustrates the use of captions for presenting metadata. Besides listing and enabling hyperlinking to video instants, tags may also be overlaid in the video for a more appealing presentation.
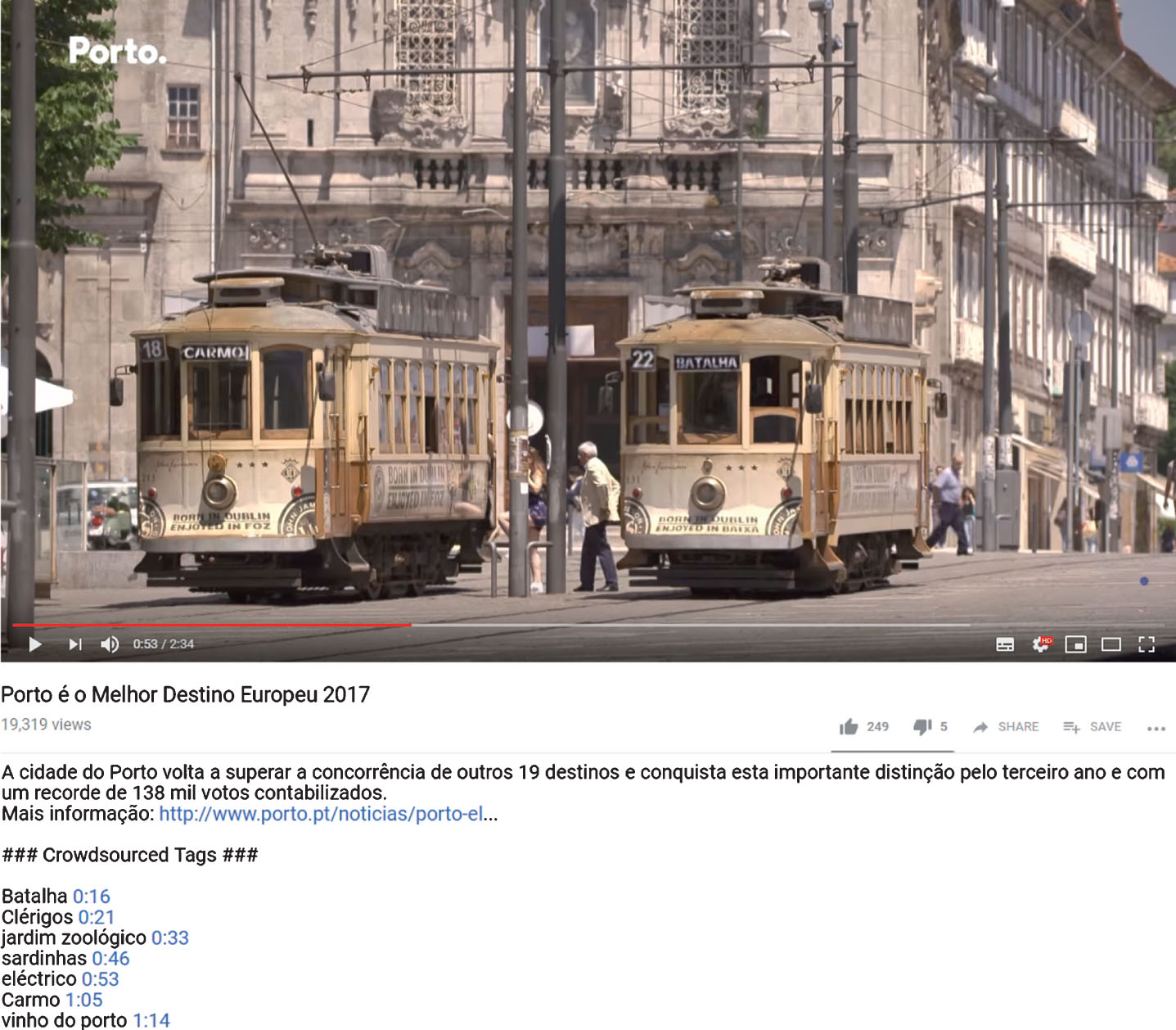
Crowdsourced timed tags description.

Timed caption track.
The data flow process is depicted in Fig. 8 showing the interactions between the different blocks: the annotation system, the browser and the YouTube API. The process can be summarized as:
User logs into our platform and chooses the built-in functionality for sharing his YouTube videos with our system.
To enable retrieving his videos from the YouTube, and later on to publish captions and descriptions under his account, an authorization is required. This will allow our system to use the YouTube API methods. The user’s Google Account is used to authorize the application to access the videos and to upload metadata.
The OAuth2 authorization process is initiated on the first attempt to use the functionality in the game. On user consent, Google returns an access or/and a refresh token that is/are stored in the database for future use. This token allows uploading information from the annotation process into the user YouTube account.
User’ videos are listed and can be selected and shared with the annotation platform.
Video IDs are extracted and added to our database to make them available for the crowd and playable along with other existing videos.
According to the user gaming level, videos from our database will be retrieved in order to be presented to the user and played during the game.
During the game and following the validation rules, tags can become valid due to exact or concept matching.
A YouTube compatible.srt (SubRip) caption file and a description, both including timed tags, are automatically generated. The original description is merged with the new description so that no information is lost.
Data is uploaded to the YouTube account by using the user ID and the token.
Caption track and description become publicly available and ready to use/view.
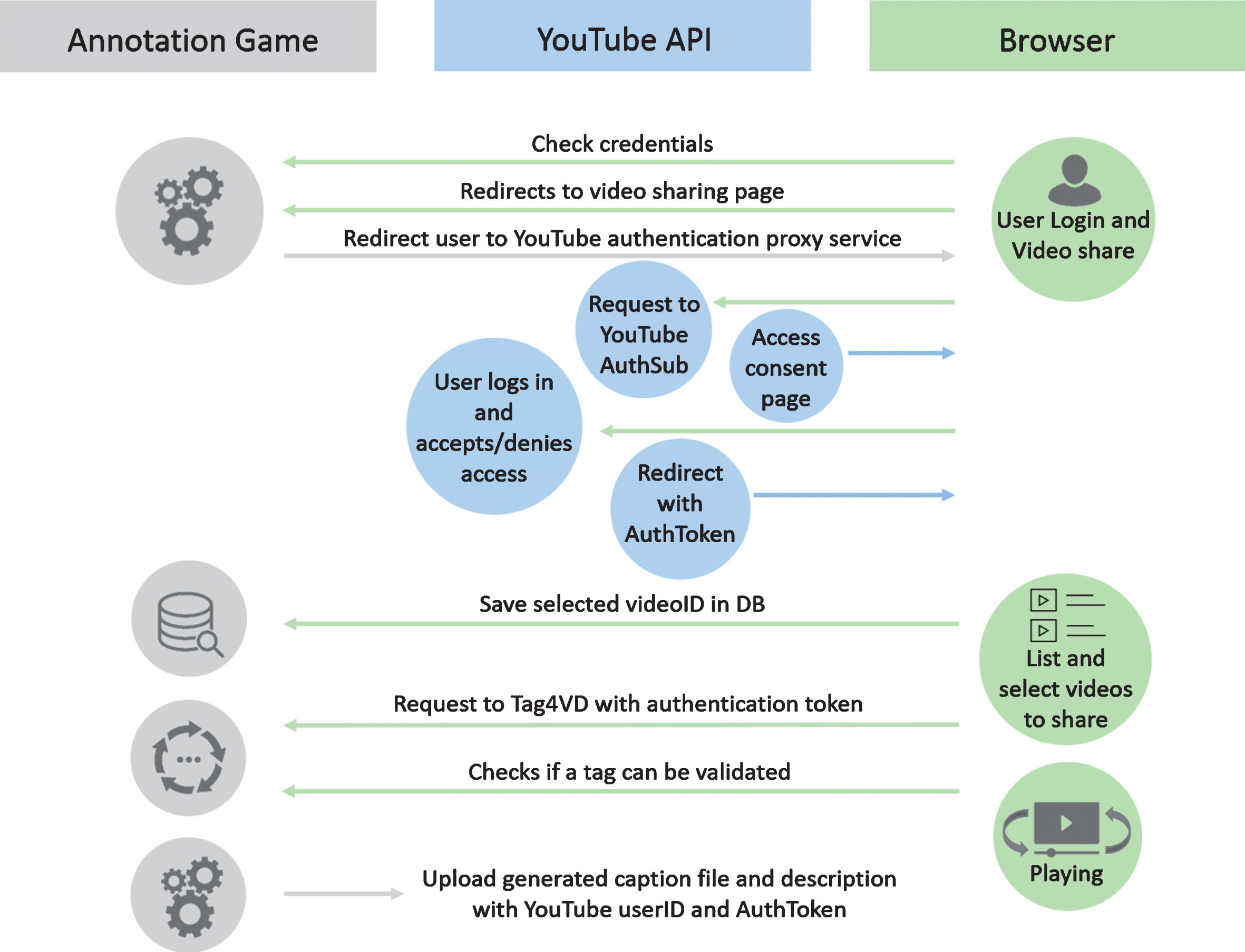
Data workflow.
The developed platform was tested to evaluate its performance, usability and acceptance. A set of volunteers that simulated a crowdsourcing environment was asked to interact with the system. A selection of video streams with different characteristics was considered to make the annotation process not focusing in just one kind of material.
Besides analyzing the quality of the annotations, this testbed enabled also checking the usability of the system and collecting feedback from the users by means of a survey. A five-level Likert scale was used for assessing the degree of satisfaction on several aspects that included: enjoyability, motivation to tag videos and unlock new achievements, the easiness of use and willing to have a continuous contribution and to invite new users. Additionally, some open questions were also included to enable understanding the users’ main difficulties as well as the preferred implemented features in the game.
Findings show that players tend to be very accurate in time when typing some tag: 92.4% of the users were very consistent and introduced the same tag, or correlated tags, near other players’ tags. This can be explained by the fact that the gamification approach encourages users to provide accurate information in order to score and progress in the game. 60% of the contributed tags were validated by the system showing tag matchup. These contributions allowed indexing 71 moments of the videos.
We have received a total of 28 responses to the questionnaire. Users tended to score high most of the scaled questions, strongly supporting the positive aspects – for most of the features, the more frequent answers were 4 or 5. A more detail analysis of the results can be found in 0.
The open questions tried to identify which aspects users’ didn’t like or what suggestions/improvements they had in order to enhance the system. Their answers allowed us to improve some of the drawbacks by implementing new features that can help to increase the usability.
As a post-experience action, several improvements were introduced. A shortcut key has been implemented to enable a quicker and easier way for the users to interact with the agreement functionality. Additionally, it was noticed that users tend to play without reading the instructions. For that, an in-game tutorial was introduced to enable a more user-friendly approach. Another conclusion was that users don’t like having to tag large video clips and want to have feedback on what they have already accomplished for a given expected tasks. To help improve this aspect, a progress bar that helps users understanding their progress in the game was introduced.
From this experiment it was also possible to notice that, due to the delay that may happen on the introduction of the tags, they may be assigned to later frames, where the concept does not exist anymore. Figure 9 illustrates this problem: the tag “bridge” is correctly linked to frame “t” and “t+1” but it was also introduced in frame “t+2” by one of the players. If this delay is very frequent, the centroid for the cluster (that is used for indexing purpose) might be linked to a future frame and make the viewer losing the concept he is searching for. Having found this, the centroid value is now decremented by a few frames to guarantee that the user will still see the concept when the video starts playing from the hyperlinked timecode.

Revise a possible delayed centroid point.
Figure 10 illustrates another aspect that is relevant for the user to get access to important video content. Although the tag “Lello” was correctly linked to all the frames, there are some initial frames that, although already shooting the facade of this famous bookshop, were not tagged. By using also the approach described above, the user will be directed to the beginning of the shooting, getting the full context scene.

Redirect to the beginning of the shooting.
Motivation and engagement features included in the annotation process proved to be effective. Not only accuracy was achieved, as well as it was evident that players interacted actively with the game, competition within the top positions was acknowledged and answers to the questionnaire enable identifying motivation and enthusiasm (82% of the players declared having enjoyed the game and it’s features) [30]. These findings are quite important, as productivity will depend on the motivation and enthusiasm that the gamification concepts can provide.
The metadata obtained collaboratively is expected to make searching and navigation in video archives more efficient and to reduce the need for professional and expensive processes of describing content. Figure 11 presents the navigation efficiency increase achieved by uploading into YouTube the crowd contributed tags resulting from the experiment. This figure presents two distinct frames of the same video stream with a total length of 2:34 seconds. Crowdsourced tags are linked to instants 0:16 (“Batalha”), 0:21 (“Clérigos”), 0:37 (“jardim zoológico”), 0:46 (“sardinhas”), 0:53 (“eléctrico”), 1:05 (“Carmo”) and 1:14 (“vinho do porto”). Direct access to relevant specific parts of the same video (“Clérigos” and “sardinhas”) was enabled by navigating on the hyperlinked tags introduced in the description field shown below the video.
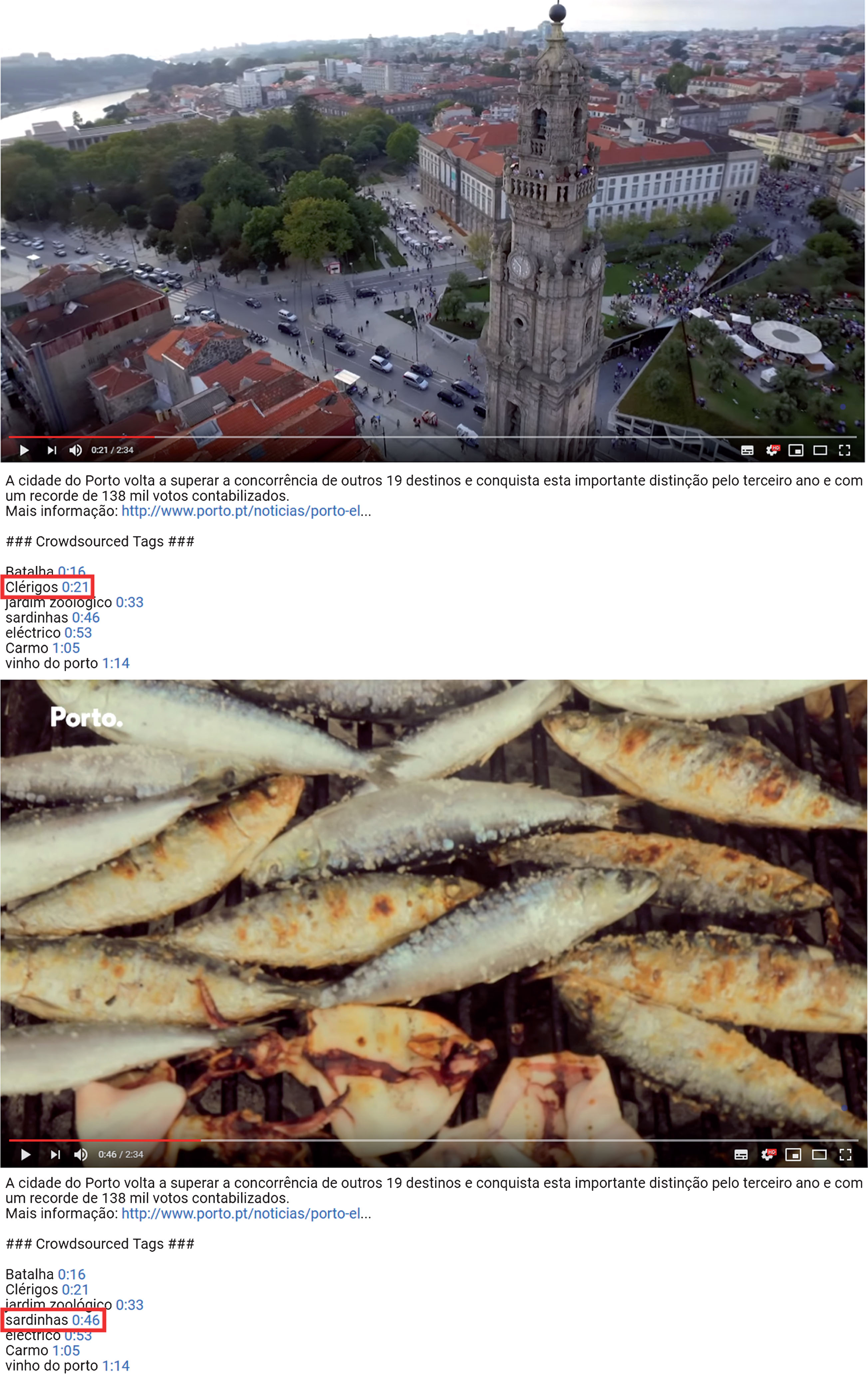
Example of a YouTube video with timed tags obtained collaboratively.
This paper describes a platform that enables enhancing video content available in the YouTube platform by increasing its existing metadata. This new metadata, collected using a collaborative annotation game is made available by using the caption feature and the description field of YouTube.
Erroneous contributions are cleaned by using a validation mechanism before uploading it to YouTube. This approach has then important improvements over the popular use of comments. To the best of our knowledge this is the first implementation of a system that uses YouTube caption and description features to improve YouTube search results using a collaborative approach. Apart from adding keywords to the video, it also associates timecodes to video descriptions, enhancing the navigation on YouTube content. Our method tries to solve two problems: the lack of useful metadata for accurate video retrieval and the difficulty on video navigation due to the lack of timed descriptions.
Future work includes adding others video sharing platforms besides YouTube and creating a browser extension that allows the player to directly play the game on YouTube without the need to access another application.
The integration of the crowdsourced process and video analysis algorithms is also being considered. Object detection, based on machine learning techniques, enable extracting key elements from the videos that are then made available for the players in the crowd judgment mode. These initial automatic annotations can help in the improvement of the cold start problem shortening the period when users are not rewarded because no metadata exists to match their suggestions.
Footnotes
Acknowledgment
The work presented was partially supported by: FourEyes, a Research Line within project “TEC4Growth: Pervasive Intelligence, Enhancers and Proofs of Concept with Industrial Impact/NORTE-01- 0145-FEDER-000020” financed by the North Portugal Regional Operational Programme (NORTE 2020), under the Portugal 2020 Partnership Agreement, and through the European Regional Development Fund (ERDF); and by “CHIC: Cooperative Holistic view on Internet and Content CHIC POCI-01-0247-FEDER-024498”, financed by COMPETE 2020, under Portugal 2020, and through the European Regional Development Fund (ERDF).