
Abstract
Defect prediction is a method of identifying possible locations of software defects without testing. Software tests can be laborious and costly thus one may expect defect prediction to be a first class citizen in software engineering. Nonetheless, the industry apparently does not see it that way as the level of practical usages is limited. The study describes the possible reasons of the low adoption and suggests a number of improvements for defect prediction, including a confusion matrix-based model for assessing the costs and gains. The improvements are designed to increase the level of practitioners acceptance of defect prediction by removing the recognized by authors implementation obstacles. The obtained predictors showed acceptable performance. The results were processed through the suggested model for assessing the costs and gains and showed the potential of significant benefits, i.e. up to 90% of the overall cost of the considered test activities.
Keywords
Introduction
Defect prediction is a technique used to predict faultiness of a given software artefact expressed in terms of defects. It could be the number of defects or binary information indicating whether the artefact is defect free or not. Such a technique seems to be very useful in the software development process. If one knew which artefacts are defect free, one could save efforts related to testing them. The software tests are often estimated for up to 50% of the costs of the whole software development (Kettunen et al. [1]). Therefore, such savings should be substantial, but surprisingly there is few evidence of defect prediction implementations in real life software development processes and all of the few exceptions most likely were conducted in close collaboration with defect prediction researchers ([2–4]), i.e. the companies were not able to implement the prediction by their own. Moreover, there are reports from research departments of software vendors with complaints regarding challenges related to convincing project managers to start using the defect prediction models (Weyuker and Ostrand [5]). One may wonder why as one of the earliest defect prediction models was suggested in the 70’ (Halstead [6]) and since then it is intensively investigated by many researchers (Hall et al. [7] or Jureczko and Madeyski [8]) and the prediction results are encouraging. According to Hall et al. [7] the model precision is usually close to 0.65 and after calibration it can be much better (e.g. up to 0.97 after performing feature selection and choosing optimal classifier as reported by Shivaji et al. [9]). We considered a survey aiming at characterizing the reasons of low adoption of the technique. Unfortunately, preliminary interviews with people deciding about the shape of development process show very limited understanding of the concept of defect prediction (there was no case where the defect prediction was even considered). Thus a survey might be of low value. It makes us thinking about the possibility of launching defect prediction program in our own environments and we faced challenges related to discrepancies between defect prediction assumptions and the real life software development processes. We identified challenges that in our opinion should be solved before recommending defect prediction. Let us present the issues and our concerns.
An additional parameter is passed to the isElectricKey method. Does it mean that the method was defective before the change? The answer is not clear, specifically because the ‘buffer’ class (i.e. JEditBuffer) was changed in the same commit. We ended up with a real defect mapped into changes in the source code that really solve it which is not exactly the same as a set of defective classes. Nonetheless, the prediction model is trained to predict them as defective, whereas in fact we are not sure about their real status. Furthermore, it is hardly possible that a unit test or code review of the JEditTextArea.java file will result in a corrective action regarding the isElectricKey method, as without the broader context that comes from the defect report, it is not clear that there is something wrong with the method call. Defect prediction output pointing at the JEditTextArea.java would be useless for a practitioner despite being correct. Furthermore, automatic identification of technical issues is the goal of static code analysis which already have good tool support e.g. FindBugs™2, SonarQube™3. Not all defects are similar to the one described above, but neither it is an exceptional corner case.
The usefulness of the redefined defect prediction is tested on two open–source projects using the suggested model for assessing costs and gains. The rest of this paper is organized as follows. The suggested approach to defect prediction as well as the method of assessing prediction gains and cost are described in the next section. The Section 3 contains the detailed description of our empirical investigation aimed at predicting defects re–opens. Threats to validity are discussed in Section 4. Related studies concerning re–opens prediction and the evaluation of costs and gains of defect prediction are presented in Section 5. The conclusions, contributions and plans for future research are discussed in Section 6.
Proposed approach for implementing and assessing defect prediction
The goal of this work is to redesign the defect prediction by suggesting approaches that avoid or resolve the issues mentioned in introduction. We conducted an empirical experiment that employs the defect prediction in such a way that makes the practical application of prediction outcomes straightforward and minimizes the possibility of misleading evaluation of prediction effects. Additionally, we suggest a model for assessment of the defect prediction application costs and benefits.
The place of defect prediction in software development
The defect prediction models that use larger artefacts as the unit of analysis seem to be more handy as it is easier to map them to system level requirements and due to the size, they come with a broader context. Hall and Fenton [7] reported modules which unfortunately are vaguely defined. We believe that the usefulness of such models depends on what in fact the module is and what the software development process looks like. Nonetheless, in our opinion the larger artefacts are a promising direction and therefore constitute our primary concern.
Let us consider two scenarios that commonly emerge in software development, i.e. implementation of a new feature and correction of a defect. Both of them can be very complex, but for our considerations we can limit them to several crucial steps. In the case of the new feature, there is the writing of the source code; afterwards the tests should be conducted and then, according to the tests results, the feature is released or goes back to the development team for further improvements and tests, which creates a loop in the process. Eventually, the feature is released and in consequence the end users start to use it. Unfortunately, the tests do not guarantee correctness and it is possible that after the release some hidden defect will emerge. Such situations create losses for the software vendor regarding efforts contributed to defect fixing as well as ruining the brand image.
The second scenario, i.e. defect correction (commonly called bug fixing) is in fact very similar. When a new defect report appears, some source code must be written or changed, subsequently the defect correction should be tested and according to the test result, released or re–implemented. Due to the similarities, a single activity diagram can be used to render both of them, that is Fig. 1.
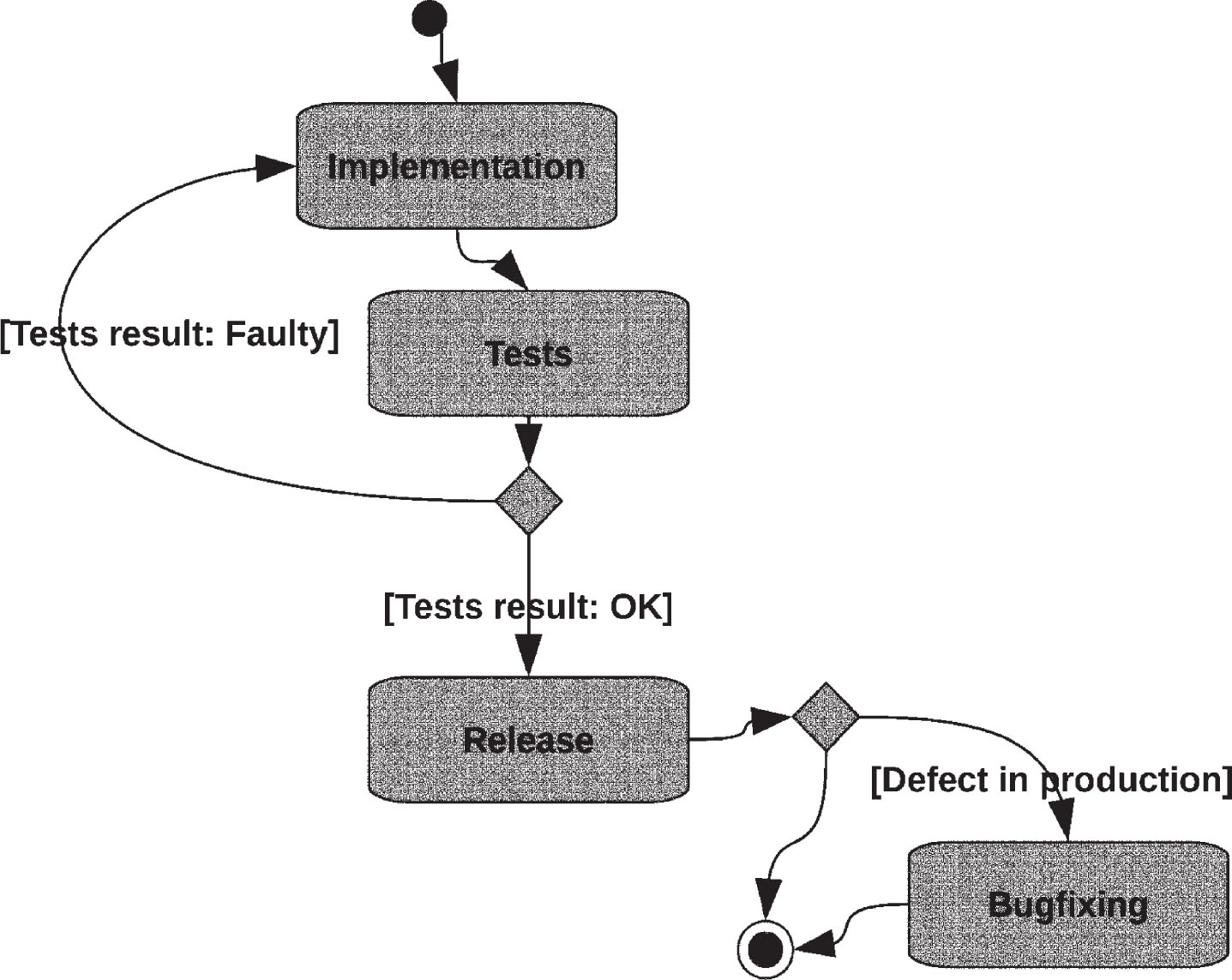
Software implementation: new features & bugfixing.
According to the Fig. 1 there is a saving possibility. By knowing upfront that something is implemented correctly we can skip the tests without harm to the system quality (in some cases such simplification may be impossible due to regulations, e.g. development of medical devices. Unfortunately, this is knowledge the practitioners do not posses. It is only possible to predict the correctness of implementation and this is what the defect prediction models are about. When considering the usage of defect prediction the software implementation diagram should be extended as it is presented on Fig. 2. The defect prediction is used to decide whether tests should be conducted. Software vendors are not eager to plan the tests according to prediction results, i.e. to chose upfront to not test some of the artefacts. However, when there are not enough resources to meet the deadline some hard decisions must be made. When postponing the deadline is not an option the only alternative is to skip some of the tests. The number of skipped test will presumably depend on the available resources whereas defect prediction will only be used to prioritize them. Nonetheless, the available resources are not a feature of defect prediction and thus should not be considered as a factor in defect prediction costs and gains assessment. This is a simplification that deviates from the real resources allocation, but without significantly worsening the estimation quality of the expected costs and gains which is introduced in the next subsection. The estimation is acceptable since after testing all artifacts marked as defective we can do more tests i.e. trading some of the saved resources for lower risk of releasing a defect.

Software implementation with defect prediction. In brackets there are probabilities and efforts used in the discussed in next subsection model.
There are two different defect prediction units of analysis that are compatible with the flow presented on Fig. 2: features and defect fixes and in order to have an easy commercial implementation we suggest to not use other ones. When the unit of analysis is smaller (e.g. the commonly investigated files or classes) it is challenging to define a set of actions that should be executed in response to the prediction results. The file or class level artefact are covered by unit tests which are usually automated and created not only to detect defects but also to prevent regression, enable safe refactorings and sometimes as a low level documentation, hence optimizing the number of unit tests according to prediction outcome may have unexpected consequences and makes the impact of defect prediction application hardly possible to evaluate. Furthermore, even the two suggested units of analysis may create complications. A defect fix which is the object of re–opens prediction is usually small and thus we do not expect significant deviations from the presented flows. However, features differ in size and not always are autonomous. When a project is developed in phases and each of the phases spans a number of possibly tightly coupled which each other features it might be not reasonable to analyze each feature in separation as there is considerable risk of introducing defect in feature B when developing feature A. We can consider a feature autonomous for the sake of defect prediction only when regression in other features can be guarded without manual tests and thus there (in the other features) is no significant test effort during development of the autonomous feature. Otherwise the scope of tests executed during verification of a feature exceeds the boundaries of the feature which makes reasonable releasing features in bulks to reduce the number of repetitions of the same test scenarios and dramatically changes the flow. As a consequence, the suggested in this work solution is applicable to iterative processes that are driven by features (e.g. Scrum) and take care of modularity (e.g. micro services architecture). Application in other processes (e.g. waterfall) or designs (e.g. monolith) may not work as expected.
The defect predictions are not perfect. Sometimes, the prediction is wrong and the low quality source code that would be reported during tests may be released and hence there is a loss for the software vendor. Therefore, it is not obvious that the process depicted on Fig. 2 is more cost–effective. Let us consider four different scenarios in order to evaluate the overall effect of employing a defect prediction model. The intention of the evaluation is to show the gain (or loss) in comparison to a baseline which is testing all software artefacts. Scenario faulty&faulty (implementation: faulty, prediction: faulty). The artefacts are tested and thus there is no deviation from the baseline. Scenario faulty&ok (implementation: faulty, prediction: OK). According to the prediction results the software artefacts are not tested, but in fact they are incorrect and thus should be tested and corrected. Not all defects are discovered during tests, thus the testing effectiveness should be considered in this scenario. In consequence, there is a loss related to releasing system with defects. Scenario ok&faulty (implementation: OK, prediction: faulty). The artefacts are tested and thus there is no deviation from the baseline. Scenario ok&ok (implementation: OK, prediction: OK). The artefacts are correct and are not tested. Thus, there are savings that come from skipping the tests.
In order to render the evaluation in a more formal way, let us define: I
f
– implementation not correct (faulty), I
ok
– implementation correct, C
pr
– post–release cost connected with releasing a defective software artefact, C
t
– costs of testing a software artefact, Pr
ok
– prediction result: implementation is ok, e – testing effectiveness, where 0 ≤ e ≤ 1 and e = 1 represents detecting all defects in the inspected software artefacts, G – expected gain (or loss when G is below 0) of prediction model application for certain artefact, i.e. the gain that comes from employing the model in software development with respect to a certain artefact, TG – total gain of prediction model application, i.e. the sum of values of G calculated for all artefacts, P (x) – probability of x, we are using also conditional probabilities,
The equation can be reformulated in a more compact form when assuming that P (gain) = P (I
ok
) * P (Pr
ok
|I
ok
) and P (loss) = P (I
f
) * P (Pr
ok
|I
f
):
We see two different defect prediction units of analysis that corresponds well with the presented in previous section considerations, those are features and defect “re-opens”. In this section we are applying defect prediction to the later ones. The purpose of the experiment was to predict whether and in what conditions a bug which was resolved can be “re–opened” in the future. The experiment is based on data collected from two open–source projects: Flume and Oozie.
Experiments design
In order to perform classification we created an application using WEKA that is a powerful tool for data mining. It gives a possibility to classify data using various classification methods, feature selection, visualize obtained classification results (e.g. decision trees), etc.
To validate the performance of a prediction we used 10–fold cross–validation method (CV). After splitting data into training and test sets, in the next step a feature selection on training set was performed for each fold. Thanks to that we could select a subset of features which are the most appropriate for predicting whether a bug can reappear in the future. In the feature selection process we used Best-First Search algorithm. This algorithm connects advantages of breadth–first searching (prevents the situation of finding a ‘dead end’) and depth of the first search (finding solution without examining every ‘competitive’ resolution). Generally, the algorithm is used for searching the graph, but in our situation it is suitable too. The Best–First Search algorithm is based on choosing every step in this option, for which estimation of evaluation function is the best. In our case Best–First searches the space of feature subsets by greedy hill-climbing augmented with a backtracking facility. As evaluating function we chose the ‘ClassifierSubsetEval’ function. It evaluates attribute subsets on training data and uses a classifier to estimate the ‘merit’ of a set of attributes. We used J48 classifier as an evaluator.
The next step was data classification. Number of instances belonging to specific classes: “Bad” or “Good” in predicting if bug can be re–opened (“Bad” means, that bug can be re–opened and “Good” that it will probably not happen) was imbalanced. In initial dataset, a number of instances with “Good” value for “Re–opened” attribute was much more numerous than those with “Bad” value in both Flume and Oozie projects. To solve this problem we used SMOTE (Synthetic Minority Over–sampling Technique) [19].
After including SMOTE, a classification method was chosen. According to [7] among the most frequently used in defect prediction are Decision Trees, Regression-based and Bayesian approaches. Hence, we decided to employ two from each of those categories: J48graft, BFTree, Logistic, ClassificationViaRegression, BayesNet and NaiveBayesSimple. with default classifiers parameters values, only the threshold value has been raised to 0.85 to reflect the loss function which in our case is asymmetric. We recommend using a value that is related to the ratio of the cost of releasing defect (e * C pr - C t ) to the cost of testing (C t ).
To evaluate the obtained results we used Recall (probability of correct classification of a faulty artefact) and Precision (proportion of correctly predicted faulty modules amongst all modules classified as faulty).
Data collection
We investigated two open-source projects:
The two projects were chosen due to their rich history about defects including re–opens, i.e. they have 1,087 bugs and 77 bugs which have (or had) status “Re–opened” (Flume) and 1,484 bugs and 429 have a “Re–opened” status (Oozie). To collect data about defects we used an application developed at Wroclaw University of Science and Technology – QualitySpy [20]. It is a tool for collecting data about the history of issues in software projects stored in issue tracking systems (e.g. Atlassian JIRA) and other software development systems. More information about QualitySpy can be found on https://opendce.atlassian.net/wiki/spaces/QS. Using this tool we collected 18 attributes – 17 independent variables and the object of prediction, i.e. whether a defect has been re–opened:
Most of selected attributes was suggested by [21]. We investigated attributes which can be divided into 4 categories:
Experiment result
In this section we want to put results of our research about predicting whether bug can be re–opened in future. Results obtained for the Flume project are presented in Table 1 and for Oozie in Table 2.
Classification results for “Re–opens” prediction in Flume project
Classification results for “Re–opens” prediction in Flume project
Classification results for “Re–opens” prediction in Oozie project
Ten–fold cross validation with the SMOTE technique for data balancing was used and resulted in satisfactory outcomes, i.e. Recall up to 0.982 and Precision up to 0.997 in the Flume project and Recall up to 0.946 and Precision up to 0.999 in the Oozie project. Nonetheless, the confusion matrix is the most interesting outcome with respect to the defect prediction costs and gains assessment. It shows in the case of the Flume project that there were 1009 correctly resolved defects (n
ok
= 1009) and 77 re–opened ones (n
f
= 77). The further calculations are done using the equation 3. To get the final gain (or cost) of defect prediction, two additional variables must be evaluated, i.e. the average cost of testing a bugfix (
According to Table 1 the best prediction model (i.e. BayesNet) can save 1845 working hours in the testing process. The tests’ effectiveness was assumed to be equal 1 for the calculations which represents the perfect effectiveness. It is a defensive approach as it minimizes the expected gain produced by defect prediction. Please note that the gain shall be considered as a difference in costs in comparison with an approach where each of the software artefacts is tested, which is 85% of the overall bugfixing testing cost (the cost was estimated using the aforementioned value of
The same evaluation procedure and the same values of
The experiments cover very limited scope while there are similar studies conducted by other researchers. This section applies suggested model for defect prediction costs and gains assessment to publicly available defect reopens prediction results. We went through all the studies mentioned in Section 5 and selected those that provide all the data required by the aforementioned model which in fact is the confusion matrix. The confusion matrix is not published frequently, but there are methods to restore it suggested by Bowes et al. [23].
Experiments regarding defects reopens prediction were conducted by An et al. [24], Jureczko [25], Shihab et al. [21], Xia et al. [26] and Xia et al. [27]. An et al. [24] was focused on supplementary bug fixes which unfortunately changes the context and makes our model inapplicable. Thus, we excluded this study. Jureczko [25] and Xia et al. [27] did not publish enough data to restore the confusion matrix. Xia et al. [26] investigated one of the projects analyzed by Shihab et al. [21], hence we choose only the later one (the confusion matrix was restored using equations suggested by Bowes et al. [23]). As a consequence, there were only two study that can contribute to external validity of the suggested model for defect prediction costs and gains assessment, i.e. [21, 25]. [21] is an experiment conducted on three open-source projects: Eclipse, Apache HTTP and OpenOffice. The authors investigated prediction performance with respect to the selected subset of dependent variables. For the sake of simplicity we consider only the results obtained for all dependent variables. Three different classification algorithms are considered. The fourth one analyzed by Shihab et al. [21], i.e. Zero–R, is excluded. The Zero-R algorithm predicted the majority class, which was not re-opened and hence it did not detect them. Restoring the confusion matrix for the Zero-R algorithm would be challenging and the results could be not representative.
Classification results for projects investigated by Shihab et al. [21]
Classification results for projects investigated by Shihab et al. [21]
The results are presented in Table 3. We used the restored confusion matrix to calculate costs and gains. The results are very encouraging as the possibility of savings varies between 4% to 81.9% of estimated cost of defects testing which is in our simulation the approximation of cost of testing all bugfixes. It is also noteworthy that this is in line with the results obtained for the Flume and Oozie projects.
This section evaluates the trustworthiness of the obtained results and conclusions, and reports all aspects of this study that are possibly affected by the authors subjective point of view.
Construct validity
The threats to construct validity refers to the extent to which the employed measures accurately represent the theoretical concepts they are intended to measure. The data about defects were collected directly from an issue tracking system. The employed data mostly comes from issue tracking systems which is a data source connected with a well known threat. According to Antoniol et al. [28] a fraction of the reports are not connected with corrective actions. We had no reliable means to identify and correct the aforementioned threat, thus we decided to take the data as is and do not introduce changes.
A method of defect prediction evaluation was suggested and assessed on five projects. The assessment is in fact a simulation conducted on real projects. Each of the investigated software artefacts come from the real world, but the application of defect prediction and its results are the authors expectation of a most plausible scenario. Therefore, an empirical evaluation conducted on a real project is a natural direction of further development that will allow to mitigate the aforementioned threat to validity.
External validity
Limited number of projects were investigated. To some extent we improved the external validity by using prediction results published by other researchers. Nonetheless, it is hard to justify whether the experiment’s results can be extrapolated and make sense for other projects. There is no basis for claiming that a general rule has been discovered. It is rather a prove of concept – it has been shown that there exist projects for which the suggested approach to defect prediction is beneficial. We believe that the results are applicable to a wide scope of projects, however, providing evidence requires further empirical investigation. It must be also stated that it was not our intention to discover a silver bullet, an approach that is useful in every single project. In consequence, we believe that following project characteristics may make the suggested approach inapplicable: not following the work–flow presented on Fig. 1; using automated tests instead of manual (for automated tests the gains and costs should be calculated differently); unacceptable possibility of regression that exceeds the boundaries of the object of prediction but is caused by its development; regulations forbidding test optimization, e.g. skipping some of the tests.
Internal validity
The threats to internal validity refer to the misinterpretation of the true cause of the obtained results.
The conducted experiments are based on a limited number of data sources, i.e. the issue tracking system. There is considerable possibility that employing additional data sources results in better prediction efficiency. Nonetheless, we decided not to pursue efficiency related goals but rather keep the track on the primary objective which is removing obstacles related to defect prediction practical application. The selection of data source for predicting re–opens corresponds with findings of other researchers, e.g. [21].
Reliability
The study design is driven by reasons for low level applicability of defect prediction in industry identified by authors. Each of the authors have industrial experience, from 5 to 20 years. Thereby, one may expect that the reasoning is not detached from software development reality and corresponds with what the industry copes with. Nevertheless, it is a subjective point of view and it is possible that some of the assumptions are false or some important factors were overseen.
Related work
This work touches several different concepts. The main driver and contribution regards the suggested method of implementation and costs–benefits assessment of defect prediction. Therefore, this section is mostly focused on such research. Additionally we conducted an empirical experiment and thereby we also mention studies investigating defect prediction in context of similar experiments.
Costs and benefits of defect prediction
According to Arora et al. [29] most of the work regarding defect prediction has been done considering its ease of use and very few of them have focused on its economical position but determining the answer to when and how much benefit it has is very important. Among the few exceptions are the study conducted by Khoshgoftaar et al. [30, 31] where costs of misclassification was investigated or by Jiang et al. [32] that suggested cost curves as a complementary prediction technique.
Weyuker et al. [10] examined six large industrial systems. The evidences they collected were used to build a defect prediction model which later become the core of an automated defect prediction system. In other words, the authors created and reported a tool (they declared that it is a prototype of a tool) that requires no advanced knowledge regarding data mining nor software engineering but allows to generate defect prediction for the files in a release that is about to enter the system testing phase. The tool is considered helpful in scheduling test execution and assigning test resources. The tool output can also point places (i.e. files) for additional code inspections. In consequence, this should lead, according to the authors, to faster defects identification and therefore testing costs reduction (the authors recommend against skipping quality related activities in files predicted to be defect free). The prototype had been presented to practitioners and was recognized as interesting and useful. Nonetheless, the authors admitted that it is difficult to get customers and thus they were not able to report field data regarding costs and benefits of installing the model in a real software development process.
Bell et al. [17] discussed empirical assessment of the impact of incorporating defect predictions into the software development process. They considered several experiment designs including randomized controlled trial, randomized controlled trial with crossover design and considering individual files as subject. The conclusion was that the most suitable is a hybrid approach where a large system with a number of independent subsystems is examined. In that case, subsystems are assigned at random to groups of testers and developers with and without feedback from the prediction model. The impact assessment is considered to be challenging since according to the authors there are no reports of industrial application and the assessment method has not been investigated and presented in the literature. It also must be noted that we have narrowed in this paper the issue regarding assessment and the scenarios we are considering were identified by Bell et al. [17] as using prediction model ‘to speed up the testing process, and advance the release date of a release’ that should result in cost savings which is consistent with our interpretation.
In contrast to the aforementioned works, Briand et al. [16] suggested a formal method of evaluating the results of using a defect prediction model. The one presented by Briand et al. [16] is in many aspects similar to ours, thus let us focus on the differences. Other objects of prediction were considered which is crucial with respect to this study goals. We used defect re–opens and feature defectiveness whereas Briand et al. [16] assumed that it is software class and thus the main driver of their model design was class size (expressed using number of lines), which is inadequate in our case. Another relevant difference regards the baseline. We compared the defect predictions against a scenario where all artefacts are tested. Briand et al. [16] referred to a prediction model with outcomes being proportional to the size of the considered software class. This difference had a significant impact on the final costs and gains model equation, as using another baseline allowed other equation transformations.
The gap between defect prediction research and commercial applications was also recognized by Hryszko and Madeyski [22]. The authors addressed it mostly by providing tool support, but also by analyzing the benefit cost ratio which was based on the Boehm’s Law about defect fix cost. Namely, it was assumed that in a waterfall project the cost is higher when a defect is identified in a later project phase and that some savings can be done by moving well targeted quality assurance activities to earlier phases. The suggested solution differs from ours as it operates on class level predictions and is not focus on iterative projects.
The evaluation methods of defect prediction models with class as object of prediction were analyzed by Arisholm et al. [33]. The authors noticed that test efforts for a single class are likely to be proportional to its size and hence suggested a surrogate measure of cost–effectiveness that is defined in terms of number of lines of source code that should be visited according to the model output. Classes are ordered from high to low defect probability. Accordingly a curve is defined. The curve represents the actual defects percentage given the percentage of lines of code of the selected by prediction model classes. The overall cost–effectiveness is the surface area between the aforementioned curve and a baseline that one would obtain on average, if classes were selected randomly. The authors clearly stated that the suggested cost–effectiveness measure is a surrogate one and the evaluation of a real return of investment requires field data. Nonetheless, a pilot study was conducted and the obtained results were very promising. The authors have not considered evaluation of defect prediction models with other objects of prediction thus their consideration does not overlap our work. Measuring test effort using the number of lines of code were considered also by other researchers (e.g. Mende and Koschke [34], Kamei et al. [35] or Zhang et al. [12]) in the form of so called effort aware defect prediction models. Using number of lines corresponds well with small prediction unit of analysis (e.g. classes or methods) which is not in line with our solution. Thus we do not discuss this approach further.
Taipale et al. [3] analyzed how to communicate defect prediction outcomes to practitioners effectively. Three presentation methods were considered and two of them directly refers to the prediction results, those are: Commit hotness ranking – ranking of file changes sorted by their probability of causing an error. Error probability mapping to source – copy of source of project with an estimate of the error probability for each line of code.
The first one is in line with our approach, as a defect fix can be delivered in a single commit (it is also possible in the case of a feature, but less likely), thus the findings regarding its visualisation are relevant for us as well. Taipale et al. [3] reported feedback suggesting that the presentation should be more proactive and specifically that there should be an instant response when committing source code, which leads towards the available solutions for static code analysis. The concept is also similar to the just–in–time defect prediction ([36, 37]) where not only single commit is used as the unit of analysis but also quick feedback loop is recommended. The just-in-time approach is focused on making the unit of analysis small in order to provide the practitioners with well targeted predictions whereas in our approach we recommend relatively big unit of analysis to simplify the defect prediction installation in a software development process. Nonetheless, the difference is smaller than one may think. Both, defect fix and feature implementation can be delivered in a single commit, the trunk based development approach encourages that to some extent. However, there are also other approaches, like feature branches, where a fraction of commits represents work in progress and cannot be considered as a object of code review nor testing. That makes expected costs and gains assessment challenging (one of our objectives), especially when we take into consideration the popularity of distributed version control systems where two different operations can be recognized, i.e. committing changes to local repository and pushing a set of commits to remote repository (and of top of that there is the rebasing operation that enables altering the history of commits).
Predicting re–opens
The concept of predicting re–opens has been recognized a couple years ago ([25, 38]). Since then a number of studies on this topic were conducted: [21, 40]. Among them we especially would like to note Shihab et al. [21] as it employs a very similar metrics set to the one used in our study. Please note that the goal of our work does not regard improving quality of predicting re–opens and thus the similarities with listed above works are very limited.
Discussion and conclusions
The study was motivated by the limited usage of defect prediction in industry. The authors identified four issues that may create an obstacle in using defect prediction, i.e. the mapping of defects to the prediction unit of analysis, lack of clear definition of defect prediction data collection program, no method of estimating return of investment and poor tool support. The issues were addressed with propositions of changes in the method and application of defect prediction. It was shown how to implement the defect prediction in a software development process and other objects of prediction than the commonly used were suggested, i.e. defect re–open and feature defectiveness.
The new units of analysis are free of challenges related to defects mapping (
We recommend against using small unit of prediction (classes or methods) for two reasons. Classes and methods are the subject of unit tests which are usually automated and responsible not only for detecting defects but also for allowing safe refactorings or preventing regression in a continuous manner. Driving the unit tests with defect prediction results would ignore those factors and hence might have unpredictable consequences. And there are difficulties in applying the results to other types of tests. The functional, acceptance, integration or contract (the list may go on) tests aim at artifacts that consist of a number of classes and methods. In the case of some test scenarios, e.g. when testing a feature, a class may be even only partly involved. As a consequence it is not obvious how such tests should be prioritized to correspond well with outcomes of class level defect prediction. When the defect prediction is trained using such data, its outcomes are not very usable for practitioners. Obstacles regarding non unit tests can be overcome as many companies collect data about traceability and are at least able to identify relations between classes, features and test scenarios. There is room for interpretation in mapping class or method level prediction results on large artifacts thus we consider that as interesting direction of further research. We did not investigate it in this work as we do not see other than manual inspection solution to the low quality of class level data issue which would make the industrial application challenging.
The second reason regards the quality of training data. We discussed a defect report in the Section 1 that represents a real system malfunction but did not make much sense on the class level. It could be questioned whether the defect report is representational. It is very challenging to assess the quality of file or class level training data. We believe that it can be reliably done only by manual analysis of each file marked to be defective by experts with project domain knowledge, that is involving the developers that developed it. Since it is not feasible and the question of quality of input data is critical we decided to investigated a sample of files by ourselves. We do not posses the domain knowledge, but we have access to the actual changes intended to fix the defect. We investigated 10 subsequent defect reports of the JEdit project that followed the issue detailed in Section 1 and were in status fixed and could be mapped to changed during fixing source code files. Than we carefully analyzed each of the changed files and classified it as one of the following: detectable_defect – the change removed a defect from the changed file, non_detectable_defect – the change removed a defect from the changed file but it was an issue that without broader, exceeding the content of changed file context was undetectable, not_a_defect – the change was a side effect of fixing defect in another file, i.e. before the change the file was as good as after it, unclassifiable – we were not able to classify the file to one of the aforementioned categories.
The results of the classification are as follows: detectable_defect = 5, non_detectable_defect = 4, not_a_defect = 7, unclassifiable = 4, and are available online with comments explaining our reasoning8. The reliability of those results is questionable as the sample is small and did not involved people with knowledge required to grasp project insights. Nonetheless, we cannot ignore the fact that only less than the half of the files contains a defect, and only quarter of them was considered to be detectable. If those results are close to the reality, the defect prediction significantly suffers from the ‘garbage in, garbage out’ anti–pattern which makes significant point against using fine-grained unit of analysis in defect prediction studies. Please note, that besides the discrepancy between files changed within defect fix and defective files there are well known challenges with issue reports misclassification (Antoniol et al. [28] or Herzig et al. [41]), i.e. enhancements are labelled as defects and vice versa which according to Bird et al. [42] can be related to a bias. There are also minor issues regarding quality of defect data like the reported by Ostrand et al. [43] inaccuracies in severity ratings.
The suggested in this work improvements were tested in a simulation conducted on real world, open–source projects. The conducted experiments showed that the usage of defect prediction can produce substantial savings. When applying the prediction according to recommendations presented in this work, the tests efforts can be significantly reduced, i.e. more than thousand of man–hours in the case of predicting re–opens (i.e. up to 90% of the overall bugfixing testing effort – please note that such impressive results may be obtained only for projects where the majority of bugfixes is correct). Savings were obtained for almost all projects and classifiers, but the results have noticeable variance. There are differences between projects and between classifiers within specific project. Thus we believe that it is not challenging to get re–opens predictions leading to savings, but there are no guarantees. There is some risk of having low quality prediction that results in releasing defects. The risk should be taken into consideration when deciding if the defect prediction is the right choice as the study results suggest that we will have savings on average but not for each case.
The study was conducted on a limited number of projects. Specifically, we did not simulate the effect of predicting feature defectiveness. Predicting defects re–opens is relevant only for bugfixing activities, whereas implementing new features can happen in every project iteration. Unfortunately, collecting feature level data from open–source projects is challenging. The development of a feature may be extended over long period of time and tracing feature dependant artifacts without comprehensive project specific knowledge is hardly possible. We increased the number of projects investigated with respect to predicting defect re–opens by reusing Shihab et al. [21] experiments data in our model for defect prediction costs and gains assessment. We obtained encouraging results that are in line with our own experiments regarding Flume and Oozie projects. Nonetheless, further research regarding additional projects and different type of artifacts (i.e. features) should be considered. Particularly interesting are proprietary projects that employ manual test as this is the primary target of the suggested approach.
Prototypes that can be installed in an issue tracking system were developed. Nonetheless, we consider the study only as a promising proof of concept and foundation for further research. We are planning a tool for software engineers, but before designing it, we are going to at least improve external validity and identify a reasonable set of useful independent variables.
Footnotes
https://www.researchgate.net/profile/Marian_Jureczko/publication/271735532_Oozie_Flume_-_collected_ data/data/596108f8aca2728c11cf1067/flume-input-data.arffation/271735532_Oozie_Flume_-_collected_ data/data/596108f8aca2728c11cf1067/flume-input-data.arff and ![]() gate.net/profile/Marian_Jureczko/publication/271735532_Oozie_Flume_-_collected_ data/data/596109250f7e9b81943f66f7/oozie-input-data.arff.
gate.net/profile/Marian_Jureczko/publication/271735532_Oozie_Flume_-_collected_ data/data/596109250f7e9b81943f66f7/oozie-input-data.arff.
The rule recently became very popular among practitioners, e.g. ![]() (last access on 29/11/2018). We are using the rule to cover not only the costs of bugfix implementation which are usually smaller but also the costs of reverting defect side effects, e.g. data migrations cleaning broken data or adjustments to changes in published API.
(last access on 29/11/2018). We are using the rule to cover not only the costs of bugfix implementation which are usually smaller but also the costs of reverting defect side effects, e.g. data migrations cleaning broken data or adjustments to changes in published API.
https://www.researchgate.net/publication/271735579_Reopens_prediction_Jira_AddOn_-_prototypeReopens_prediction_Jira_AddOn_-_prototype whereas the one for predicting feature defectiveness can be downloaded from ![]() defectiveness_Jira_AddOn_-_prototype.
defectiveness_Jira_AddOn_-_prototype.