
Abstract
An enormous volume of well-structured data with explicit semantics, in accordance with W3C’s standards, becomes a reality in the Web of Linked Data. However, the Semantic Web promise to turn it into a machine-processable global graph of knowledge still encounters numerous impediments. Efficient access and discovery along with the semantic heterogeneity have been identified as major stumbling blocks. Following the design principles for Semantic Web and Linked Data, we present ActiveDiscovery, a decentralized infrastructure for distributed SPARQL query evaluation based on its terminological entities, namely the ontologies used in a query. ActiveDiscovery’s main goal is to facilitate distributed and transparent semantic search based on structural rather than keyword-based querying in the Semantic Web. Key architectural extensions regarding metadata, indexing and ontology alignment are proposed to achieve transparency for federated query execution in a decentralized manner. The rewriting procedure for extensional SPARQL query is considered regarding the proposed components and SERVICE clause as a standard recommendation for query federation. We investigate the feasibility of our approach and present preliminary results of initial evaluation. We conclude by indicating questions which need to be addressed in future work.
Introduction
The Semantic Web and Linked Data initiative together lay the foundation for the new paradigm of information processing and knowledge discovery on a global scale. The vision of the Web as being more data- and resource-oriented space rather than document-centric medium has been a well established and widely known idea for over a decade. An important role is played by common vocabularies and ontologies as a semantic layer for datasets, as they add explicit semantics and reasoning capabilities, thus enabling intelligent data processing on the Web. Means for both, data exposure in a machine-processable form and semantic awareness along with structured querying, are provided by W3C standards, namely Resource Description Framework [39], Ontology Web Language [38] and SPARQL [40]. They constitute a set of formalisms for Semantic Web. The Linked Data initiative follows the Design Issues [3] which stipulate dereferenceable HTTP URIs to identify resources, providing useful information expressed with W3C standards and linking across datasets. The ultimate goal is to turn Web into shared space of machine-understandable knowledge. However, Web’s heterogeneity as its inherent quality makes it a challenging task. It is agreed upon that decentralization of data sources and semantic diversity expressed in many ontologies may be tackled with integration efforts. The prevailing approach regarding the semantic integration on the Web is to provide mappings, thus having miscellaneous ontologies loosely coupled rather than seeking full semantic alignment. There is a variety of styles and approaches to access and integration of assertional data, in particular federation architectures regarding SPARQL queries executed in distributed manner.
In this article we consider a decentralized infrastructure for knowledge discovery in the Semantic Web, which we refer to as ActiveDiscovery, in terms of distributed SPARQL query evaluation, automatic discovery of data sources based on terminological elements of a query and semantic expansion for result set broadening. The purpose for such an infrastructure is to enable Semantic Web applications to execute structural queries across the Web without prior knowledge of relevant data sources. In order to achieve this goal we propose architectural extensions for OWL ontologies metadata, decentralized indexing services and an algorithm for federated SPARQL query execution based on a standard SERVICE clause.
In section 2 the research landscape in the area of data discovery in the Semantic Web is briefly illustrated. Section 3 depicts conceptual foundation and main architectural assumptions of the infrastructure. Section 4 presents preliminary results of evaluation of a proof-of-concept implementation. Finally, section 5 concludes and shows the directions for future research.
Related work
Data discovery on the Semantic Web has been a widely explored topic in two primary research areas, namely access to distributed RDF datasets on the Web and semantic integration of Web ontologies. Both issues are vital for efficient data discovery.
RDF data access
RDF data is distributed across the Web, thus making it difficult to seek, query and consume. Triples are freely available via standard HTTP GET mechanism or stored in datasets equipped with SPARQL endpoint. These sources are frequently disconnected, leading to the so-called data islands. There are four general approaches to this problem. Navigational [1, 37] mimics the way we browse the Web exploiting graph nature of RDF and cross-linking RDF graphs. Navigating does not require any additional structures supporting data collection; however, the collected data is heavily dependent on a starting point selection. This technique is implemented in semantic browsers, Tabulator [4], Disco [5], DBpedia Mobile [2]. Warehousing [9, 39] is another approach originating from database theory, where heterogenous data needs standarization and schema unification prior to being queried. It assumes collecting and loading entire datasets into central repository, thus enabling efficient query evaluation. This approach, however, suffers from data redundancy which raises problems with scalability and data becoming obsolete. Semantic Web search engines SWOOGLE [13], Sindice [29], SWSE [18], Falcons [8] crawl the Web and index RDF documents much like traditional search engines. They collect RDF documents, create centralized indexing structure and enable keyword-based search exploiting classic information retrieval methods. Since they are not resource-oriented, the support for structural or semantic querying is limited only to metadata and search results refer to RDF documents rather than RDF resources. Federation [16, 17] is oriented towards structural query evaluation across multiple data sources on the Web. It derives from database researches on distributed query processing [21] and assumes a role of a mediator which splits the query into subqueries which are then delegated to different endpoints. Mediator collects and merge intermediate results to obtain final result set for the query. SPARQL 1.1 [31] has built-in support for federation implemented as a SERVICE clause. Two examples of federated SPARQL system are DARQ [32] and SemiWIQ [22].
Semantic integration
Web ontologies determine terminological layer for RDF triples, so they constitute the semantics both for datasets and for query. Ontologies, even if shared and reused, introduce heterogeneity on a semantic level. Fruitful knowledge discovery in the Semantic Web requires alignment of miscellaneous ontologies used to describe RDF data. Ontology matching is a wide topic including a variety of methods that can be split into categories regarding matching objective and human involvement. Ontology merging and integration produce new ontology which may be significantly altered in a deep reengineering process requiring extensive human involvement. Mapping and alignment of ontologies are considered more lightweight and better fitting Web’s reality. A potentially incomplete mapping between Web ontologies, (semi-)automatically computed and represented without affecting their autonomy is believed to be particularly suitable to aid semantic alignment. [10, 35] provide a comprehensive survey on ontology matching. Another important aspect is the representation formalism that determines mappings’ expresiveness and ways they can be exploited. Formal and logic-oriented approaches [14, 28] consider the interpretation of logic concepts across different ontologies, first-order formulas for cross-ontological translations and upper ontologies for schema mediation. Query language level approaches [11, 34] propose various extensions for SPARQL to evaluate queries in one ontology over data expressed in another. A great deal of attention is dedicated to query rewriting strategies and algorithms. Lightweight mapping representation tools are represented by Alignment API [12], R2R [6], BLOOMS [19].
ActiveDiscovery infrastructure
Current approaches to information seeking and knowledge discovery in the Semantic Web require active involvement of a querying party, hereafter referred to as a querying agent (QA), thus assuming the Web infrastructure to behave passively. In particular, data sources discovery and selection remains an unresolved issue. Our goal is to introduce a set of means, consisting of architectural extensions and decentralized infrastructure, to change the perspective on how the query could be evaluated with Web playing an active part and taking over the responsibilities of the QA. The motivating scenario is QA issuing an extensional SPARQL query using terminological entities of OWL ontologies according to Semantic Web standards. We expect certain Web components to take care of query processing from now on and bring the best possible results back to QA. It can be seen as a generalization of a query federation problem. A set of expectations towards an infrastructure is claimed.
It is the Web’s underlying infrastructure which is to behave proactively in query evaluation process, QA merely states the query. Data sources localizations are unknown to the QA; it is the Web’s responsibility to discover proper data sources and execute the query against them. The number of contributing data sources is to be maximized. QA’s query is based on any dereferenceable Web ontologies of its choice; terminological components of the query are to determine the evaluation process. Semantically related data should contribute even if described with different ontology than the query ontology. Such an infrastructure should constitute robust and scalable system ensuring independence from any controlling entity.
Architectural extensions
We follow common distinction between terminological data (TBox), namely ontologies, and assertional data (ABox) stored in RDF datasets, usually of much higher volume. Dereferenceability of ontology IRI and availability of ontology document including its metadata, is not only stipulated by Linked Data design recommendations but also required by OWL2 specification [27]. It renders a basis for additional annotation of owl : Ontology concept (owl, rdfs and rdf are abbreviations for standard namespaces of those vocabularies) regarding new services necessary to facilitate query federation. Two annotations are defined and illustrated in Figure 1.
IndexingService : owl:Class
hasIndexingService : owl:AnnotationProperty
⊤ ⊑ ∀ hasIndexingService.IndexingService
∃ hasIndexingService.Thing ⊑ owl:Ontology
MappingService : owl:Class
hasMappingService : owl:AnnotationProperty
⊤ ⊑ ∀ hasMappingService.MappingService
∃ hasMappingService.Thing ⊑ owl:Ontology
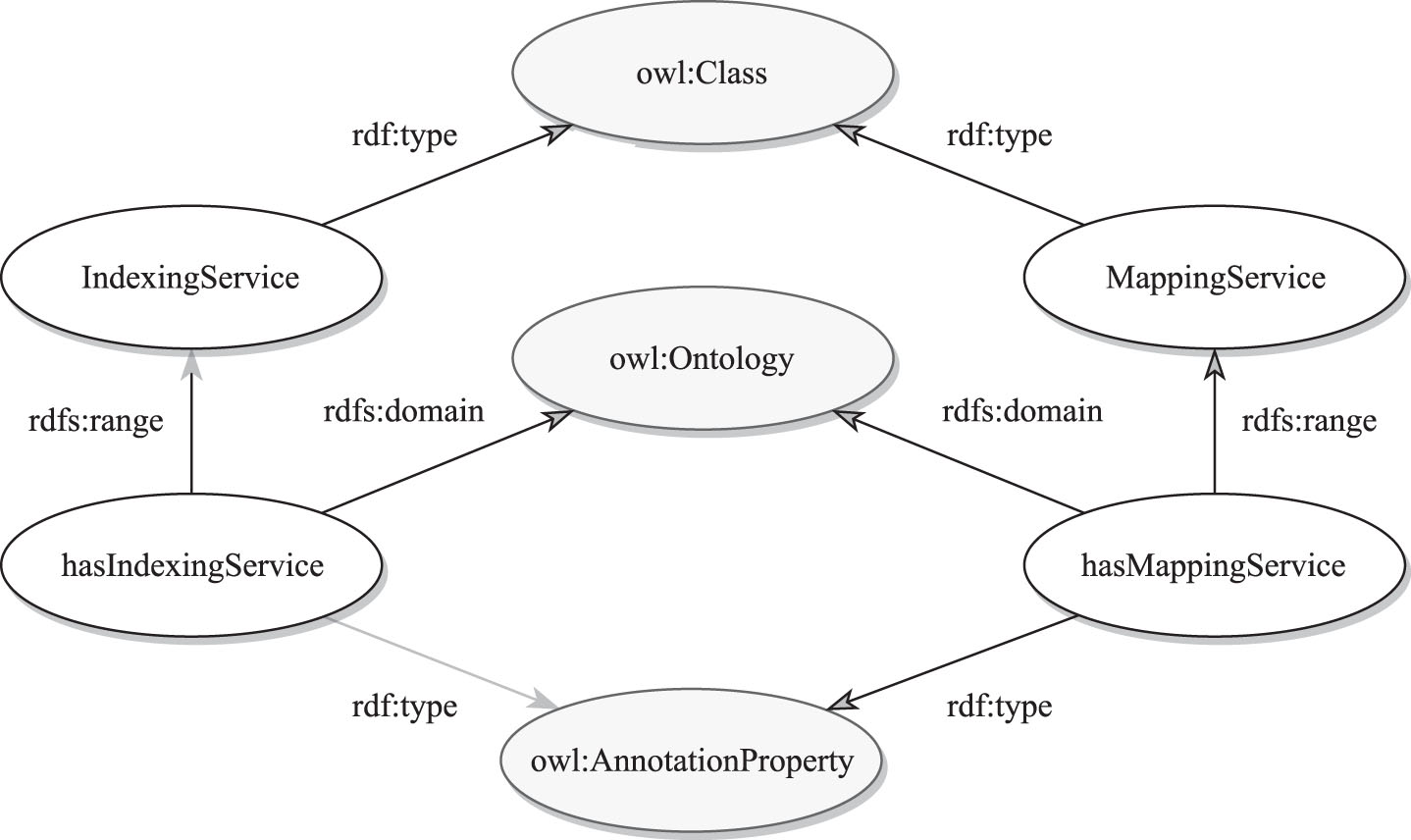
Indexing and Mapping annotations.
Conceptually, five separate logical nodes in the network infrastructure can be denoted. Each of them exposes a service which, along with ontology annotation, facilitates discovery protocol.
These elements form the infrastructural basis for looking up the data sources necessary for query rewrite and execution.
Following the distinction between TBox and ABox data, the evaluated query is considered to be an ABox query according to definition 3. Let V be the set of variables, L be the set of literals, I TBox be the set of terminological IRIs of any ontology excluding common vocabularies for OWL, RDFS and RDF, I ABox be the set of any assertional IRIs.
Definition 3 entails five types of a triple pattern. TP i is a shorthand for triple pattern of type i.
An immediate consequence is that there is at most one element of I TBox in each triple pattern in Q ABox and at least one element of I ABox . Any variable is bounded by elements of I ABox . According to the primary proposition, the initial ABox query carries no addressing elements, in terms of FROM or SERVICE clauses, and no background dataset or default graph is assumed either.
Having introduced architecture components and the input query defined, the scenario of ontology-based ABox query evaluation can be described. An overall protocol is presented in Fig. 2. The sequence diagram illustrates message passing between nodes depicting pieces of intermediary data collected in the evaluation process. An entry point for the querying agent is Query Service Node, which receives the input SPARQL query and starts the procedure in Algorithm 1 listing. Data sources discovery and query rewriting interleave in course of algorithm execution. First, the query’s BGP is extracted and a new one is initialized (lines 1-2). Next, all triple patterns are subsequently analyzed (lines 3-27). We are interested in TPs having a TBox element on predicate or object position, so only TP1, TP2 and TP3 are further processed (line 4). TP4 and TP5 are appended to the new BGP untouched (line 24). From each triple pattern TBox IRI is extracted (line 6) and respective ontology is dereferenced by issuing HTTP GET request to this location. Then ontology hasMappingService annotation is consulted (line 7) and, after the respective Mapping Service Node is contacted, the set of mappings for TP TBox element is acquired (line 8). The new TBoxes extracted from mappings, along with source TBox form the basis for data sources search (lines 9-13). For each TBox set element, by dereferencing its IRI, the indicated ontology is loaded from respective Ontology Repository Node and hasIndexingService annotation is referred to (line 15). The IndexingService pointer enables a remote invocation to Indexing Service Node which returns data sources for a given TBox (line 16). At this point all addressing information required for query rewrite is in place. For each data source new SERVICE clause for a given endpoint and rewritten triple pattern is appended, thus creating a part of compound UNION clause which in turn forms a new expanded triple pattern (lines 17-20), appended to the new BGP in the target query. When all triple patterns are transformed the rewriting procedure stops. There is some important pre-and-postprocessing for the query with optimization in mind, elaborated in the next section.
The rewritten (and optimized) query is then executed by SPARQL engine being part of QSN implementation. Subqueries from SERVICE clauses are delegated to respective sources, intermediate results are joined on QSN and sent back to the querying agent.
1: BGP← extractBGP (Q ABox ) ;
2: newBGP← initEmptySet () ;
3:
4:
5: nTP← initNewTP () ;
6: tbox← tp . getTBoxIRI () ;
7: mServ← getMappingService (tbox) ;
8: mappings← mServ . getMappings (tbox) ;
9: tboxSet← initEmptySet () ;
10: tboxSet . add (tbox) ;
11:
12: tboxSet . add (map . getTBox ()) ;
13:
14:
15: iServ← getIndexingService (tbox) ;
16: DSs← iServ . getDataSources (tbox) ;
17:
18: nTP . appendSERVICE (tp, ds, tbox) ;
19: nTP . append (′UNION′) ;
20:
21:
22: newBGP . append (nTP) ;
23:
24: newBGP . append (tp) ;
25:
26: newBGP . append (′ . ′) ;
27:
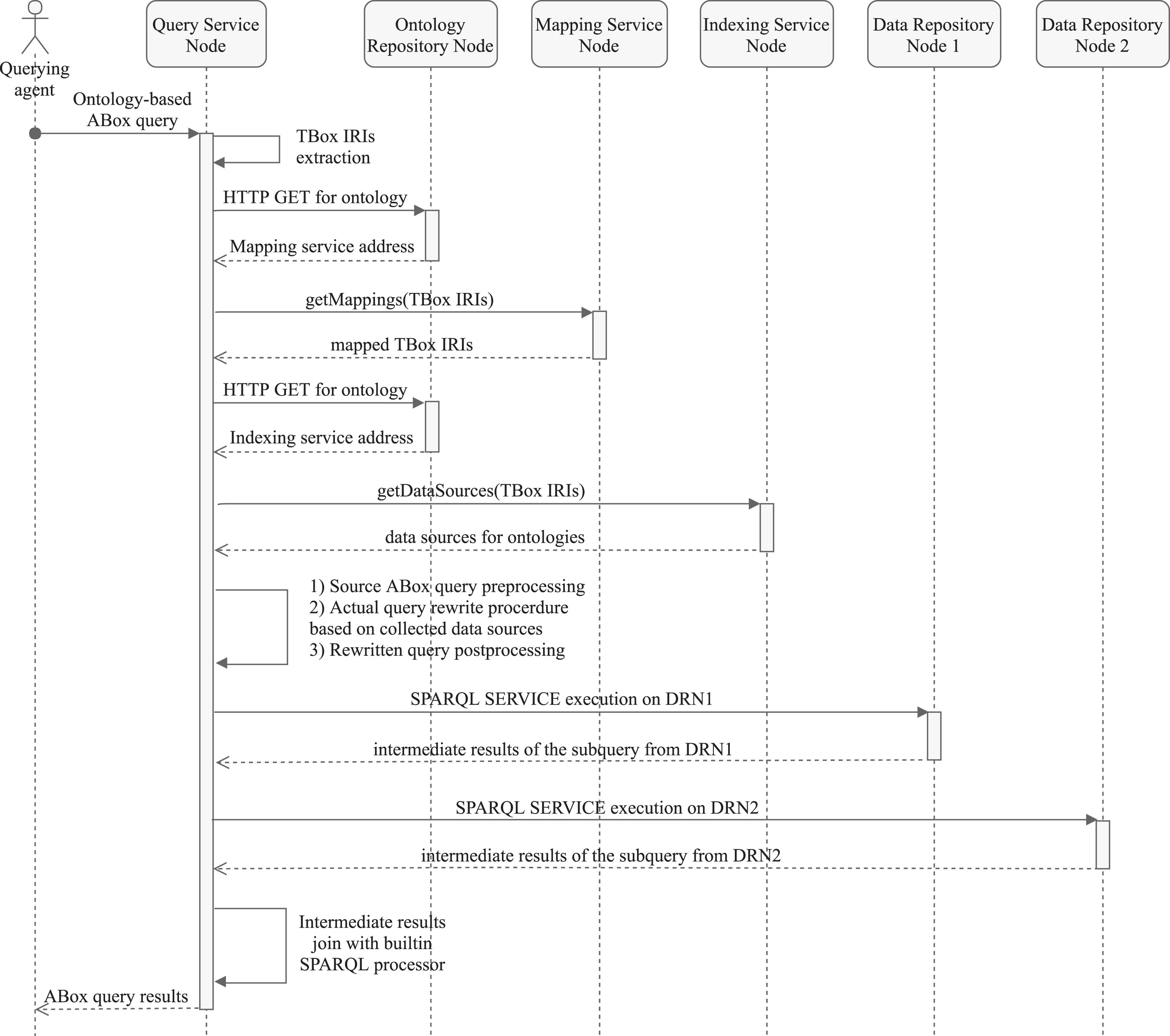
Query evaluation protocol
The already mentioned query preprocessing and postprocessing parts in Fig. 2 regard various optimization efforts undertaken to prepare the target query for efficient evaluation in distributed environment. In federation architecture the most expensive operation is connected with subquery execution on remote nodes, transmission the intermediate results over the network and join them on mediator. Therefore, it is crucial for performance reasons to ensure the intermediate results are as limited as possible and query planner on mediator supports smallest-first join order. The key factor is the selectivity of a triple pattern, Definition 4.
Roughly speaking, selectivity represents a capability of a triple pattern to restrict results. It can be estimated based on the triple pattern itself or it may take into account additional metadata carried by index entries. Both possibilities are considered in ActiveDiscovery query evaluation.
In preprocessing phase the FILTER expression is analyzed in the first place. The filter pushing strategy is applied by converting the filtering formula into conjunctive form. Any conjunct having its variables set contained in the TP’s variables set, is glued to the respective TPs as separate FILTER, so that they later can be pushed into one SERVICE call. Afterwards, initial reordering of the triple pattern is performed. TPs containing URI ABox , namely TP2 and TP4, as well as TPs with glued FILTER clause are moved to the beginning of the BGP according to obvious heuristics. They become a seed of BGP. Next in line are TPs with variables shared with seeders, which narrows possible bindings for those TPs.
In postprocessing phase the reordering is augmented with the information about the cardinality of TBoxes. Basic index entry couple is extended to the triple (IRI
TBox
, URL
SEndpoint
, n), where n is a number of occurrences of IRI
TBox
in data source exposed by URL
SEndpoint
. The total number of occurences of IRI
TBox
in all data sources URL
SEndpoint
i
discovered for this element is denoted as
To summarize optimization strategies applied, filter pushing and aggregating as many TPs as possible within one SPARQL SERVICE invocation improve selectivity and reduce network transmission by cutting off useless intermediary results. Reordering triple patterns based on heuristics and source statistics tend to significantly reduce resource consumption spent on mediator joins.
Although an evaluation of ActiveDiscovery has been carried out primarily on artificial datasets, the real world example is presented. The example validates the value added and as such, plays a role of proof-of-concept for the architecture’s feasibility. In the second part of the evaluation the matter of scalability, as an important factor of feasibility, is briefly discussed and the preliminary results of quantitative analysis are presented. An evaluation environment consists of computational nodes, one per each logical node. Fuseki SPARQL execution engine based on JENA ARQ open library is used for all SPARQL endpoints. Services on ISN, MSN and QSN nodes are implemented in Java. Apache Web Server serves as an implementation of ORN.
Validation example
Two ontologies are used to express the source query, presented in Listing 1, Schema.org1 and Geonames2 ontology. The query declares all cities in Poland with their names (labels) and population. It may be trivial, but still worth mentioning, that source query cannot be successfully executed unless it is explicitly submitted to the specific endpoint. First of all, a querying agent must know the address. If there are multiple endpoints it needs to make a decision which one to query, which leads to different results. Moreover, the data necessary to form the results may be split into various sources, which makes the task even harder.
Listing 1: Source query
For the purpose of the experiment, the ontologies’ namespaces need to be altered and ontologies themselves hosted accordingly. The reason for this is that they had to be augmented with relevant annotations regarding Mapping and Indexing Service. However, it does not affect the principles so original namespaces are used.
Index entries for Schema, DBpedia and Geonames
Index entries for Schema, DBpedia and Geonames
The annotation property has Mapping Service of Schema ontology points at node returning the following mappings dbpedia : City ≡ schema : City
dbpedia : country ⊑ schema : location
which extend the query in a way that DBpedia ontology3 is used in a query as well. Index entries for all TBoxes in question are collected in Table 1 as they were returned by Indexing Service Nodes for three ontologies. Two endpoints are available (ff.net is a shorthand for factforge.net). Cardinality measures reflect real world numbers for TBoxes occurrences in both sources.
Listing 2: Target query
The source query submission to either DBpedia endpoint or Factforge.net endpoint returns no bindings. Translation of the query and optimization-oriented transformation produce target query presented in Listing 2. The target query executed on Query Service Node returns 39 bindings of which 31 bindings are distinct due to the fact that Factforge aggregates data from multiple sources, DBpedia included.
The scalability of the ActiveDiscovery architecture is measured in terms of execution time of a rewritten query Q as a function of database size, for different Q, varying in size (triple patterns number) and selectivity.
The goal of the experiment is to figure out a shape of f
Q
for increasing size of RDF datasets. Four different queries have been examined: Q1 consisting of 7 triple patterns of low selectivity, Q2 the same 7 triple patterns query but of higher selectivity, Q3 smaller in size 3 triple patterns query of moderate selectivity and Q4 small 2 triple patterns query of low selectivity.

Execution time of test queries.
RDF triples generator was used to produce twelve datasets of different size for measurement, starting from 38 triples in the smallest dataset it doubled each time reaching 77824 triples in the largest. Each dataset was uniformly distributed on four separate DRN nodes. Evaluation methodology was to take 100 samples for each setting of dataset size and query type, cut off 10 highest and 10 lowest results and take an average of others. The results for each query are presented in Fig. 3. Logarithmic scale for both axes has been used to clearly show all average measures.
The first and most significant observation is the linear growth of f Q for all queries. The difference in execution time between queries is constant and depends on the query type. The much smaller Q4 outperforms the biggest Q1 by factor cca 24 while Q2, equal in size to Q1 but more selective, performs 4 times faster. It is important to note that these results cannot be meaningfully compared to the performance of a single query engine which provides measure of central query execution rather than distributed execution against multiple endpoints.
In this paper a decentralized infrastructure for extensional SPARQL query evaluation based on terminological components of the query has been presented. Following the essential principles for Web of Data we have proposed extensions to OWL ontology annotations, a service-oriented architecture and protocol for RDF data sources discovery, which determines query rewriting procedure and distributed execution. Certain optimization issues and a selection of improvements have been discussed. The proof-of-concept implementation has enabled an initial evaluation of the infrastructure’s feasibility. The preliminary results have been presented including a validation example of added value gained for real world query and data sources as well as performance metrics showing linear growth of execution time w.r.t. datasets size.
Our future work will focus on such areas as results ranking and limitation. An efficient way to control the volume of intermediate results from triple patterns delegated to remote endpoints is crucial, particularly when low selectivity is observed. Means for more adequate selectivity measurement might be provided by indexing services. Moreover, additional metadata to express more complex characteristics of data available via an endpoint seems helpful, both for cut-off threshold assignment and results ranking strategy. Development of ranking criteria goes hand in hand with data chunking necessity. Another area of research is index creation and update, which is necessary whenever data source appears or ceases to be available. Likewise, when dataset content changes in terms of data volume or new vocabulary is used, index update is needful. The protocol extension for datasets registration, deregistration or update could follow the pattern known from DNS architecture. Linked data connections between RDF datasets enable updates based on Web crawling. Lastly, more expressive representation language for inter-ontology mappings remains a direction for future research. The ability to make use of equivalence between individual resources (OWL:sameAs) would further improve accuracy of the discovery process.