
Abstract
Traditional approaches to content-based recommendation and collaborative filtering do not suffer from cold-start problem, which is a challenge to recommend items for an unknown user. In this paper we present a Personalized Document Retrieval System which takes into account a social network information about the users. The overall idea of the system is to cluster users into groups of similar interests based on theirs usage data and to determine a representative profile for each of the groups. When a new user joins the system, he or she is classified into one of existing group based on his or her user data and the representative profile of the group becomes a starting profile for the new user. This paper focuses on a method for updating ontology-based user profile using Bayesian network approach. We analyze some properties of proposed updating method and describe an idea of experimental evaluations.
Keywords
Introduction
Due to the wide accessibility and overload of information, it is very helpful to use systems that implement recommendation or personalization methods. The aim of recommendation systems is to propose to the user some items that can be useful for him based on some user and usage data. They predict if the user is interested in the propositions. Personalization systems allow to obtain better results in the sense of user information needs. Different users can submit the same query to retrieval system and their results can differ because of different context, user experience, etc.
The most important aspects of personalization systems are as follows: a user prefers to formulate simple queries that should reference his or her information needs but the queries are often ambiguous [25]. The user can not be able to ask a proper query due to his or her lack of knowledge. The crucial issue to alleviate the problem is to collect up-to-date knowledge about the user interests (with context of his or her queries), store it in appropriate profile and process it using effective methods.
The effectiveness of personalization systems depends on data about users and methods for processing and analyzing data. When system provides documents which user is not interested in (documents are not relevant to user information needs), he or she is discouraged from using the system.
In our previous works [9, 16–20] we have developed a generic framework for social recommendation system which allows to use collaborative filtering and social information about similar users to determine non-empty starting user profile. This profile is a representative profile of the group of similar users. When a new user joins the system, he or she should be classified into one of existing groups of users based on his or her demographic data. A method for determining profile of a group of users and feature selection problem in this case was presented in [17].
Our current approach is based on social characteristics of a user which allows us to improve classification procedure. It is possible to focus on relations between users (in real social networks, it can be relation of friendship, followers, co-authors, etc). Graph theory research area delivers many ideas to use social collective to clustering methods, e.g. cliques analysis [14] or other density measures [1]. For each group we have used knowledge integration techniques to develop a representative profile which best characterize a set of similar users as a whole [20].
The objective of the paper is to present a method for building and updating user profile in personalized document retrieval system to alleviate cold-start problem. When a new user joins the system, there is not available usage data about him or her. The proposed method combines collaborative filtering approach and social network, usage data and user data to prepare the starting profile for a user that joins the system for the first time. According to his or her current activities in retrieving documents or concepts, it is necessary to modify his or her profile to ensure the effectiveness of retrieval and personalization processes. In our work we consider ontology-based user profile which allows us to take advantage of relations between index terms (concepts) to introduce semantics of user queries to some extend. It allows us to analyze a context of user queries to disambiguate their meaning.
Our previous works focused on determining representative profile of the group of similar users [9] and profile clustering methods [18]. Also some ideas about creating and adapting user profile were considered [16]. The current research refers to updating ontology-based user profile based on Bayesian network and social network approaches.
A novel aspect of our current research is to check the hypothesis that convergence of user profile is better when using proposed methods to update profile than the convergence of profiles built without social aspects or empty starting profile. The essential question we want to answer is whether and how we can avoid cold-start problem by leveraging the power of social network.
As the user satisfaction of obtained result is subjective, it requires to perform some experiments with real users. Due to the time- and cost-consuming aspects, it is not possible to gather real results. It is necessary to define quality factors to judge the effectiveness of proposed method. We have developed a set of postulates that should be satisfied and we have analyzed properties of the methods.
The rest of the paper has the following structure: Section 2 provides related works to locate our solution in proper area of research. In Section 3 we present an overall idea of our approach to personalization system, define necessary structures (domain ontology, user profile, problem definition). Proposed algorithms are described in detail in Section 4 and analysis of postulates and quality factors are presented in Section 5. Section 6 contains methodology for experimental evaluation of the whole personalization system. Conclusions and system limitations are discussed in the Section 7.
Related works
In this Section, we present existing approaches to recommendation systems, personalization systems and social networks. These elements are used to develop a Personalized Document Retrieval System.
Recommendation systems
The main objective of traditional recommendation systems is to predict the relevance of an item: a product or a document i (i ∈ I, I is a set of items) for some user u (u ∈ U, U is a set of users).
In content-based approach, the historical relevance judgments are taken into account ru,i, u ∈ U = {u l : l = 1, 2, …, n u } and i ∈ I = {i k : k = 1, 2, …, n i }, where n u is the number of users and n i is the numbers of items in the system, respectively. The cold-start problem arises when a new user comes to the system and no usage data is available or a new item can be recommended but first, this item should be compared with existing items to find similar items.
Collaborative filtering approach allows us to manage out the cold-start problem to some extend. When a new user judges relevance of first few items, it is possible to find out other users that judged the same items in similar way and to propose to the new user items that were relevant for similar users. One can meet such approach in many transactional systems (e.g. on-line shops). When looking for an item, the system shows the following recommendations: “Customers who viewed this item also viewed …” and present a list of items that were bought or judged as relevant by other users, or “Frequently bought together” – presents a list of items that were bought in the same transactions. In this approach some data mining techniques are used.
Another approach is social recommendations which requires a social network between the set of users. Recommendation techniques can be divided into 4 groups [22]: Link Prediction – it allows to recommend friends to a new user in a social network. The connection can be directed when both users agreed to have a friendship relation or undirected network when a user follows an arbitrary number of other users to receive news or activity updates. Follow Recommendation – social network can be treated as a source of information that allows to improve collaboration and recommendation. Partner Recommendation – it allows to find collaborators, researches or other partners. In scientific network it is possible to analyze relations between co-authors or citations network. Broker Recommendation – with rapid growth of social network, it is a possibility to assist in the formation process and to support flexible and evolving interaction patterns in cross-organizational environments. Broker acts as intermediaries between separated communities and helps to start the collaboration between these communities.
Nowadays, it is also popular to analyze big data streaming for the follow recommendation. Their effectiveness can be improved by using graph and probabilistic models, e.g. Markov chains [8].
In this paper we focus on follow and partner recommendations. The main idea is to use information about groups of users with similar interests and similar sets of items to alleviate cold-start problem in recommendation system.
Personalization systems
Information about user’s needs are basis for the personalized search procedure [5]. The information can be collected in a direct or indirect ways: user can be asked to provide his or her interests explicitly or a system can observe user activities to find out some patterns in user actions [10, 21]. It is also popular approach to combine long-term and short-term user interests [6]. Short-term profile stores information about current user session and long-term profile contains interests that occured in many previous sessions.
User profile is built to facilitate effective processing the information. Depending on the source of the information, the following data can be used to create the profile [5]: browsing history – Web pages that were visited by the user when he or she browses; bookmarks added in a browser; queries asked by the user and the results found for them; methods that combined above mentioned.
If we track all user’s activities, it is possible to gather broader context of user data [2]: emails read or created; bookmarks from a social bookmarking site; web communities or blocks of interests; social networking service.
It allows us to disambiguate user information needs, especially when user submit only a few terms in a query.
Different type of profile structure can be considered as a model of user interests: bag of keywords, list of interests concepts, list of Web pages, hierarchy of concepts or ontologies. First three examples assume that keywords or concepts are independent to each other, while the rest takes into account relations between concepts. Hierarchical or ontology-based approaches also allow us to gather information about the context of user queries. Profiles normally include topics of interests but may also include topics of disinterest by taking into account relevant and non-relevant documents [2].
Different methods for learning user profile can be also found in different systems. The most popular are the following: vector-space model, genetic algorithms, probabilistic model, fuzzy model, etc.
Our current research on Personalized Document Retrieval System focuses on developing a user profile. In this sense we are similar to work of [25] – the aim of this paper is to create accurate profile without the user interaction. In our methods we also build ontology-based model of the user to enhance important concepts and remove unimportant concepts. A novel aspect of our work is to exploit the power of Bayesian networks – value of probability shows us the level of user interest in particular concepts.
Bayesian network
“A Bayesian network is a directed acyclic graph D = (V, E), where V is a finite set of nodes and E is a finite set of directed edges between the nodes. Each node v ∈ V reflects a random variable X v and is connected with its parent node pa (v). It is also attached a local probability distribution, p (x v |xpa(v)). Let us use P for the set of local probability distributions for all variables in the network. A Bayesian network for a set of random variables X is then the pair (D, P)” [4].
Bayesian network is used in our research as a flexible tool to model documents and user’s profile. Ontology-based structure allows us to define relations between concepts and Bayesian network provides a possibility to extend this structure to take into account also a level if user interests in each concepts.
Nodes in Bayesian network reflect concepts and edges – relation between them. If there is no connection between two concept in Bayesian network, we treat them as independent. The following formula can be used to calculate the joint probability distribution (Equation 1):
Druzdzel and Diez [7] have proved the following theorem about conditional probability distribution for independent nodes.
Let us consider a node of selection variable X r in a Bayesian network and a node X i (other than X r ). We additionally assume that X i is not an ancestor of X r .
The conditional probability distribution of X
i
given pa (X
i
) is the same in the general population and in the subpopulation induced by value x
r
(Equation 2):
In our work, the above-mentioned theory allows us to simplify calculations to create user profile while we use fixed structure of the domain ontology. A naive Bayes classifiers are quick learning and low computational overhead what is important in user modeling system [3, 24]. Another machine learning techniques can improve Bayesian networks approach [23] and they can be used for processing incrementally incorporate new data [26] which is important aspect when tracking user activities in the system.
It is not sufficient to find concepts of user interests (as in binary model: user is interested in the concept or not) but also the level of user interests is crucial factor in personalization system. Probabilistic Bayesian approach allows us to create a conditional probability tables for each concept which reflects the strength of user interests or disinterests of the concept. It is also possible to analyze dependencies between concepts and compare them with previously defined relations (e.g. generalization – specification relation).
In this section we present an overall idea of the Personalized Document Retrieval System which consist of three modules: clustering users, determining representative profile of each group and modifying a profile of the new user. The main objective of the proposed system is to tackle a cold-start problem of new users.
To realize the above-mentioned tasks, we develop a model of documents and the users based on existing domain ontology of the Main Library and Scientific Information Centre in Wroclaw University of Science and Technology (ML&SCI) [27].
Personalized document retrieval system
A general architecture of information retrieval system is presented in Fig. 1.
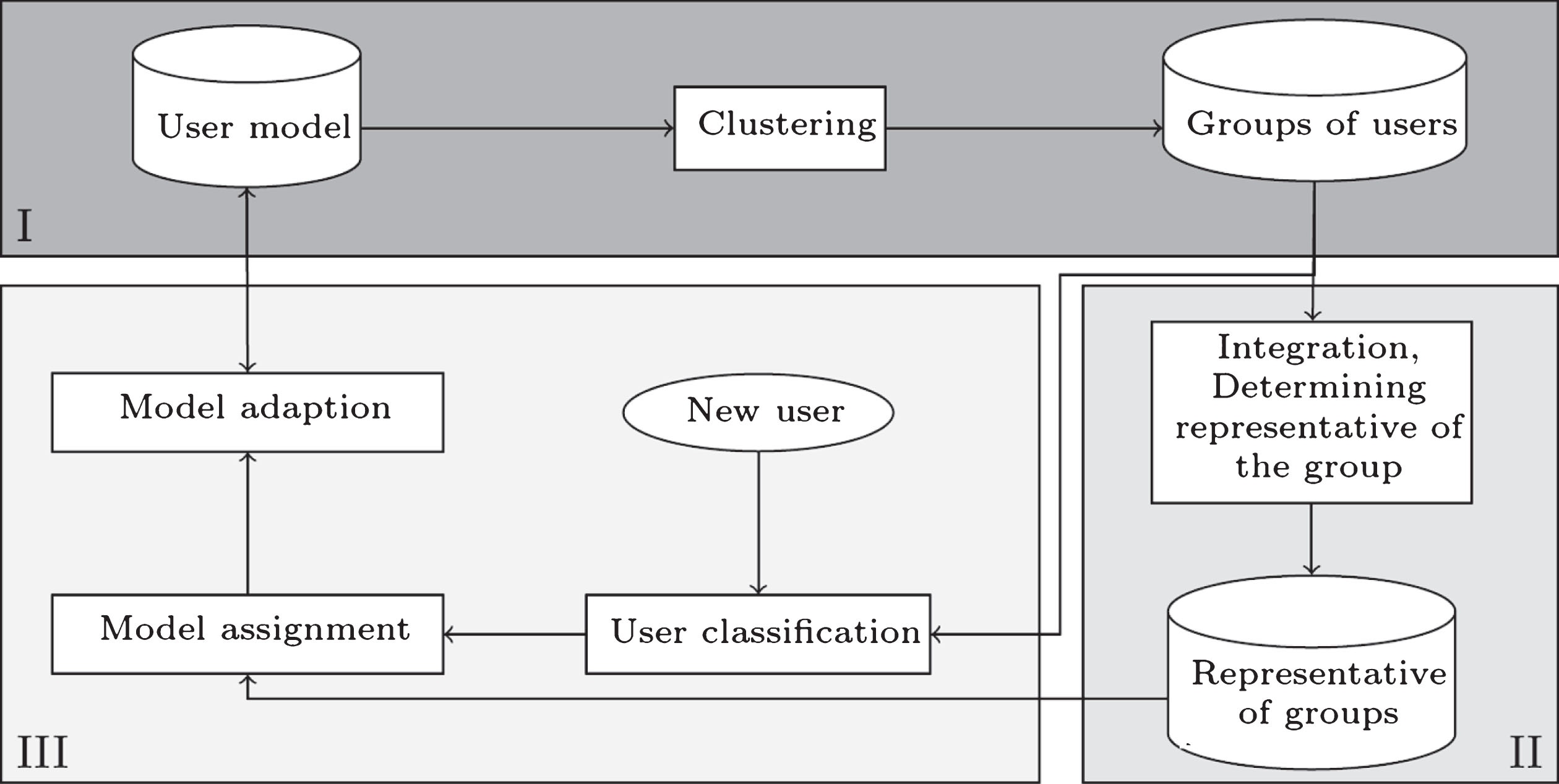
A general IR system architecture.
In our previous works [9] we have developed a methodology for determining representation model of profile for each group of similar users. The main idea of the procedure can be described as follows.
Let us consider a set of N users profiles UP in social community and a new user u. Based on the set of users profiles UP determine groups of similar users based on social and usage data stored in profiles. For each group of users determine a representative profile based on usage data about the users in the group or by combining the knowledge on the profile level. Appropriate algorithms were proposed in our previous works ([9, 17]).
When a new user u comes to the system, classify him or her to the proper group based on his or her social data. The basis of this step can be e.g. sets of users that the user knows (friends) or follows. Assign him or her the representative profile of the proper group (it can be e.g. a median profile of his or her friends and other users that have similar interests). With growing user activity of the system, it is necessary to keep his profile up-to-date. However the median profile can not fit best to the user, his or her own interests should become more and more important. This is a crucial issue in personalization systems as out-of-date profile can determine non-adequate recommendations and user can be discouraged from using the system.
Let us consider a definition of an ontology O:
The definition of the ontology can be used to model a set of index terms from the Main Library and Scientific Information Centre in Wroclaw University of Science and Technology (ML&SCI) [27]. In the paper we consider the document retrieval system in ML&SCI. It contains over 220000 items (books or scientific articles) which are indexed by the concepts from domain thesaurus. Each document is an instance of the domain ontology. The thesaurus consists of almost 90000 index terms. There exists a few kinds of relations between terms (they were defined by librarian specialists): the main term (with different wording but with the same meaning), set of broader terms, set of narrower terms, correlated terms (relation defined by librarian specialist as “see also”).
Sets of broader and narrower terms can be interpreted as a hierarchy relation. Correlated terms are rather loosely related to the main term. Each document in the system has a defined main term. We do not have any information about relations between documents – it is the reason to omit a part of relations between instances R I in general definition of the ontology.
Based on the librarian system, it is possible to define the formal domain ontology. Let us define domain ontology O′ as a quadruple:
In our model, C is a set of index terms – concepts in domain ontology. We propose to distinguish a hierarchical relation H between two concepts c1 and c2 when concept c1 is broader then c2 (and simultaneously, c2 is narrower then c1). In the set of relations between concepts we can use only “see also” relation – it could not be symmetric relation. An exemplary concept of “computer science” term is presented in Table 1. Document model were explained in details in our previous work [16].
A concept of “Computer science” in domain ontology
The basic for every personalization system is a model of user interests. Algorithms for changing user profile or for personalized retrieval process (out of the scope of this paper) are strictly determined by the structure and model of the user. Only up-to-date profile can be useful to obtain relevant documents and guarantee higher level of user satisfaction.
An overall idea of developing user profile is to combine domain ontology with a Bayesian network. The conditional probability tables should be calculated for each node (concept) in domain ontology based on the set of relevant and irrelevant documents. The main advantage of such approach is that it takes into account both positive and negative samples of user interests.
Let us consider the following definition of the user profile:
Information about relevant and irrelevant documents are gathered when a user uses the system. The profile should be up-to-date to give better results.
The problem arises at the beginning of the retrieval process, when a new user joins the system. Until we gather a set of relevant and irrelevant documents, it is hard to build appropriate profile and the recommendations can be unsuitable to user information needs.
It is easier to identify positive samples (relevant documents) – they were opened or saved by the user. When user does not choose a document, it can not be obvious if it is irrelevant to him or her or e.g. he or she has found important information in previous document. Relevance of the document should also be considered in the context of a user query – user can be interested in a particular concept in general but int he context of current query, the document could be irrelevant.
To alleviate the cold-start problem, we developed a method to determine starting user profile based on social network [9]. The focus of current work is to propose a method for updating user profile starting with non-empty profile and using running user queries, relevant and irrelevant documents. The method is presented in the next section.
In this section we present an algorithm for updating user profile based on his or her current profile and a set of relevant and irrelevant documents. The sets of documents were returned by the system and the user judges them as relevant or irrelevant according to his or her information needs. As the users can have different experience in formulating his or her needs in terms of concepts, the relevance is his or her subjective measure. It is a reason why we should focus both on usage data and on the context of user queries.
If a document is irrelevant to the user, it can mean that he or she is not interested in it or they are looking for something else and the problem is to formulate a proper query.
According to developed Personalized Document Retrieval System, the starting user profile is non-empty because the user has been classified into one of existing group – in the group of the most similar users in terms of his or her social network information or other user data (e.g. demographic data). The algorithm for modules of clustering and representative determination were described at the beginning of Section 3.
Below we present an algorithm for updating user profile. It assumes that current user profile is not empty (it contains at least elements from a representative of the group of similar users).
Additional structure: empty short-term profile to performed some calculations.
For each concept k ∈ Q (s) Add concept k to short-term profile. Compute the predictive distribution P (k|class) based on sets of relevant and irrelevant documents. Value of attribute class reflects the relevance of document: relevant: class = 1 irrelevant: class = 0 Compute joint distribution P (class, k) and marginal probabilities P (k) and P (class). Assign calculated value to conditional probability table of short-term profile:
Calculate a weighted average values of each probability in conditional probability table of each concept in user profile UP (s):
In the algorithm we introduce some parameters connected with weighted average probabilities. Let us consider the following formula:
Presented algorithm tackles with the problem of changing user profile according to his or her current activities. The assumption is that the system as a whole is up-to-date: clusters contains users with similar interests and representative profile is proper one (in terms of some quality conditions).
In this section we propose some properties of user profile updating method. First three properties are intuitive and they could be obvious for some simple methods based on vector-space model of user profile – a proof is presented in [19]. When developing Bayesian network with conditional probabilities, they should be still satisfied.
The two last properties are connected with profile convergence and was proposed by Trajkova and Gauch in paper [25]. They consider such a situation: when a user joins the system, a set of his or her usage data become bigger and bigger (the number of relevant and irrelevant documents increases). As a result, some new concepts are added to user profile (concepts with non-zero values of probabilities) and it is obvious that the number of concepts in user profile monotonically increases. According to the property 2, the major user interests should become relatively stable.
The following two properties of the user profile was proposed based on the idea described in [25].
Authors of [25] have shown that judging about 70 documents is enough to obtain stable profile. The appropriate number of documents in our system will be established in experimental evaluation stage. Also level of satisfaction for all these properties will be check experimentally.
Proposal of an experimental evaluation
To evaluate the quality of Personalized Document Retrieval System, it is necessary to collect data about documents, users and users’ activities.
A complex experimental evaluation should consists of the following steps: gathering user and usage data of a set of users; determining groups of similar users based on usage data; determining a set of significant features of user data (e.g. demographic or social features); determining a representative profile for each group; gathering social and demographic data about a new user and classifying him or her to the most similar group; assigning him or her a representative profile; updating his or her profile according to retrieval activities using developed method; calculating some quality factors (RMSE, MAE, F-measure, etc.)
As the proposed methods are only a part of the whole system, it is impossible to perform experimental evaluations without the other features of the system. It is also impossible to use benchmark data because available data sets do not contain all elements that we consider in our model.
In our previous work [19], experimental evaluation were performed using simulations of such a system. All elements of the system were generated randomly, taking into account some statistical distributions of the features in a real population.
In this paper we present a proposition of the updating method – it is only a part of the whole system. When methods for each element of the proposed system are ready, the complex experiments will be conducted. Nevertheless, a description of future empirical analysis and experimentation is presented in this section.
A general architecture of information retrieval system, which is presented in Fig. 1, can be evaluated using classical measures such as: root mean squared error (RMSE), mean absolute error (MAE), precision, recall, or F-measure [9]. It is possible to perform the complex evaluations when existing data set covers all necessary elements: documents, user and usage data, and user ratings. Unfortunately, we have not found benchmark data that can be used.
To obtain values of the above-mentioned measures in reality, the system should be available for a set of real users. The users could be invited to join the system, submit queries and judge the relevance of the obtained results. It will be also necessary to have a source of social connections between the users to perform clustering procedure.
We plan to realize the evaluations by gathering data about researchers: theirs’ affiliations, areas of research (they can be obtained from keywords of the papers) and other user data. The social aspect in this case can be taken from information about co-authorship relation between the researchers or other popular social networks. The process of determining group of similar users and developing representative model of each group will be based on the papers of the researchers.
A new user in this context is a new person who starts his adventure with a fixed research area. Based on his or her relations with other researchers (in e.g., existing social network), he or she can be classified into a group of users with similar research interests. When he or she starts to publish his or her own paper, the profile can be updated using the described methods.
At the level of the system as a whole, it should be checked how recommended papers are judged by the user – in particular, which documents are relevant and irrelevant for his or her information needs. It will then be possible to calculate the values of classical measures and compare different models between each other.
To check the quality of adaption method that were presented in the paper, it will be also possible to explore described properties of updating algorithms and convergence factor of the profile.
Summary and future works
The significance of recommendation and personalization systems is still a current topic. More and more algorithms are developed and new aspects of everyday life of the users are taken into account to improve the quality of recommendations.
In our opinion, there are still many unsolved problems. Existing solutions are not sufficient from the point of view of the user. In our current research, we are developing an overall idea of Personalized Document Retrieval System which consists of three modules: clustering, the representative determination, and adaption to handle new users. The scope of this paper is to determine a method in adaptation module to update user profile while a new user joins the system and wants to obtain personalized results. With growing set of usage data, we have proposed a method to modify user profile according to his or her current interests. Presented approach allows us to alleviate well-known cold-start problem in recommendation systems.
As described part of the proposed system is a theoretical one, the main future project is to evaluate its efficiency using real-world datasets or to perform experimental evaluations using real users and documents. The first task is to collect data and prepare adequate dataset – it allows us to learn the perform “learning” stage of the system.
It is necessary to also develop methods for clustering and representative determination modules at the level of Personalized Document Retrieval System. Additionally, the framework should be implemented in a big-data infrastructure, considering the storage of the different models in an appropriate graph database. A big-data infrastructure is also needed to handle the huge amount of users, items and ratings, and the complexity of the algorithms.
There are still many unsolved features of the system as a whole (in each module). They can be e.g.: checking dynamic of the groups: if the user fits to the classified group after fixed number of sessions or time interval; when the clustering process should be executed (what are the conditions that start this process); or when recalculate the representative profile of the group (assuming that new users join the system). Above-mentioned problems are out of the scope of this paper and will be considered in future works.
We also plan to investigate how the Personalized Document Retrieval System can answer to other traditional recommendation problems such as grey-sheep users (i.e., users who present rating patterns mismatching any other users, and hence, receive poor recommendations) [11] or shilling attacks (i.e., when fake user profiles are created by malicious users to manipulate item ratings and disrupt recommendations) [13].
Footnotes
Acknowledgments
This research was partially supported by Polish Ministry of Science and Higher Education.