
Abstract
Solving difficult, usually NP-hard problems, requires metaheuristic-based approach. Such algorithms are very often demanding from the point of view of computational power. Therefore various approaches to parallelize or distribute such systems were made. Many of such algorithms are structurally very easy to parallelize, e.g. evolutionary ones. However, swarm computing algorithms, in particular ACO (Ant Colony Optimization), in order to be implemented properly must use a significant amount of global knowledge (pheromones matrix). Therefore strict parallelization/distribution strategies for ACO are difficult to work-out. In the presented paper we propose a novel approach for parallelization and distribution of the most important element of ACO, namely the pheromone table. Our prototype implementation is tested on a real-world HPC (High Performance Computing) infrastructure, with good observed scalability. At the end of this paper we present actual experimental results focusing on two class of problems, namely TSP (Travelling Salesman Problem) and VRPTW (Vehicle Routing Problem with Time Windows), using popular benchmarks.
Keywords
Introduction
Transport-related optimization problems are often characterized by a high complexity which makes them practically impossible or inviable to solve accurately. Metaheuristic algorithms are designed to handle such problems in an efficient way – providing a reasonable solution while only requiring a specific representation of the problem data, e.g. graph for Ant Colony Optimization. In case of well-known problems there are plenty of problem specific optimizations improving the performance of the metaheuristics. Nonetheless the efficiency of the algorithm itself is also important, especially when there are no problem specific optimizations.
Modern computation hardware, especially big homogeneous or heterogeneous clusters, encourage the researchers to consider parallelization of algorithms. The time-limited solving of an optimization problem requires efficient utilization of these resources (e.g., in the case of traffic optimization [12]). The parallelization of evolutionary algorithms has been quite well-explored. These can be implemented in multiple models, like master-slave, cellular, and island based [2], which scale well on the existing hardware.
The Ant Colony Optimization [3] involves creation of multiple solutions in each iteration. That makes it a great candidate to be parallelized, by distributing the process of solutions creation across multiple processors [8] or even computation nodes [7]. The high-scalability enables creation of higher number of solutions in the same time, which may increase exploration of the solutions space and finally lead to better solutions.
The scalability of the algorithm is limited by sharing the global knowledge represented as the pheromone matrix. In case of big problems the matrix can be distributed over the computation nodes in order to parallelize the operations of the matrix update at the end of each iteration. To the best of our knowledge, however, there are no computing systems that are capable of running ACO-computing efficiently in large-scale distributed systems (i.e., HPC-grade).
In this paper we would like to apply the ACO with the distributed pheromone matrix, involving more ants than the standard approaches, to hard optimization problem. We also present basic scalability tests. The bottom line is that presented algorithm outperforms classic MMAS (Max-Min Ant System) algorithm.
In the next section we present state of the art related to the investigated research area. Section 3 describes the distributed ACO algorithm, involving the distribution of ants and the pheromone matrix. Section 4 lists conducted experiments and thoroughly discusses obtained results. Section 5 summarizes the article.
From classic to parallel ACO
The first version of Ant Colony Optimization was introduced in [3] to solve TSP. The algorithm was inspired by the behavior of the natural ants colonies. ACO as a meta-heuristic algorithm was described in [4].
The ACO meta-heuristic algorithm expects the optimization problem to be considered as a graph consisting of finite set of components connected by edges with assigned cost. A valid solution is a path that respects posed restrictions and fulfills requirements defined by the problem. A solution cost is defined as a function of all the costs of all the connections belonging to the solution. The optimal solution is the path with minimum cost. E.g. in case of TSP solution’s cost is a total distance or in case of VRP (Vehicle Routing Problem) it is a number of vehicles and a sum of the routes distance, where the number of vehicles is more important.
The optimization process is based on a population of ants. They iteratively traverse the graph creating the candidate solutions. A probabilistic decision rule (see Eq. 1) is a basis of the ant’s decision regarding selection of the next selected vertex. In each iteration each ant starts from an initial vertex, which can be selected randomly as in the TSP or can be specified by the problem liek a depot node in the VRP. The probabilistic decision rule takes into account the values of pheromone trails left on the edges by the previous generations of ants.
In the basic ACO algorithm - Ant System (AS, [6]) the probability of moving from component i to component j for ant k in iteration t is defined as follows:
Since the first publication describing Ant System [3] researchers have put a lot of effort into improving the optimization performance. One of the most efficient modifications is Max-Min Ant System (MMAS, [10]). The algorithm introduced three major adjustments into the AS algorithm: only one ant leaves the pheromone trails after each iteration - either the best from the iteration or the best found so far by the algorithm, the pheromone trials values are limited by τ
min
and τ
max
, the pheromone matrix is initialized with the τ
max
value.
The effectiveness of the MMAS algorithm was further improved by the pheromone trail smoothing mechanism. When the algorithm is very close to convergence, the pheromone matrix gets smoothed by increasing the values proportionally to their difference to τ max . This mechanism can also be effectively applied to other elitist ant systems [1, 6].
Besides the standard modifications of the Ant System, e.g., Elitist Ant System (EAS), Rank-based Ant System (ASRank, [1]), Max-Min Ant System (MMAS, [10]) or Ant Colony System (ACS, [5]), which focused on introducing modifications to the original sequential algorithm, the researchers tried to additionally boost the performance by leveraging parallelization of the algorithm. A taxonomy proposed in [9] classifies the numerous parallel algorithms into four main categories based on two primary criteria: the number of colonies (one or many) and the cooperation or lack thereof among the parallel parts: Master-slave model – a single colony, where the master process manages the global information, Cellular model – a single colony with cooperation, where the colony is divided into small overlapping neighborhoods with their own pheromone matrices, Parallel independent runs model – several sequential ACOs are independently executed on a set of processors using identical or different meta-parameters, Multi-colony model – several colonies explore the solution space with their own pheromone matrices but periodically exchange information.
There are algorithms, which do not fit any of the proposed group. The architecture proposed in this paper is close to the Master-slave model, but the global knowledge is also distributed.
There are only a few articles regarding implementation of a single ants colony in a big cluster environment, which could allow not only for improving the computations speed but also leveraging extended exploration by a higher number of ants in a single colony. The most common use-case for clusters is to run multiple colonies. Ilie and Bădică et al. [7] presented an agent-based approach to ACO modeling. This article reports a very good scalability up to 7 nodes on the gr666 problem from TSPLIB1. The algorithm’s efficiacy is comparable to the standard Ant System. Unfortunately, the authors did not report any experiments with large-scale TSP problems or larger clusters.
The majority of research is focused on ACO modifications in order to solve complex problems faster, usually with a cost of obtaining suboptimal solution. In this paper we propose a scalable, distributed implementation of ACO. The highly scalable architecture is the basis of the efficient and distributed algorithm involving numerous ants. Nonetheless, the problem representation and setting the meta-parameters of this algorithm is also important. This section describes the architecture of the system and the proposed way to setup the parameters, with focus on leveraging the knowledge collected by the numerous ants to improve the results obtained from the algorithm.
High scalability of ACO
Achieving highly scalable ACO architecture requires distribution of many processes and components and assuring low inter-process (also inter-node) communication overhead. The first step is a distribution of the ants (representing the processes of a single solution creation), which is a standard master-slave approach to this problem (see Fig. 1). The architecture enables parallel creation of the new solutions, however, it is limited by the performance of the master node, which has to provide the pheromones data to all other nodes. Moreover, the process of the pheromones update at the end of each iteration is performed only on the single node, while other resources are waiting for the results.
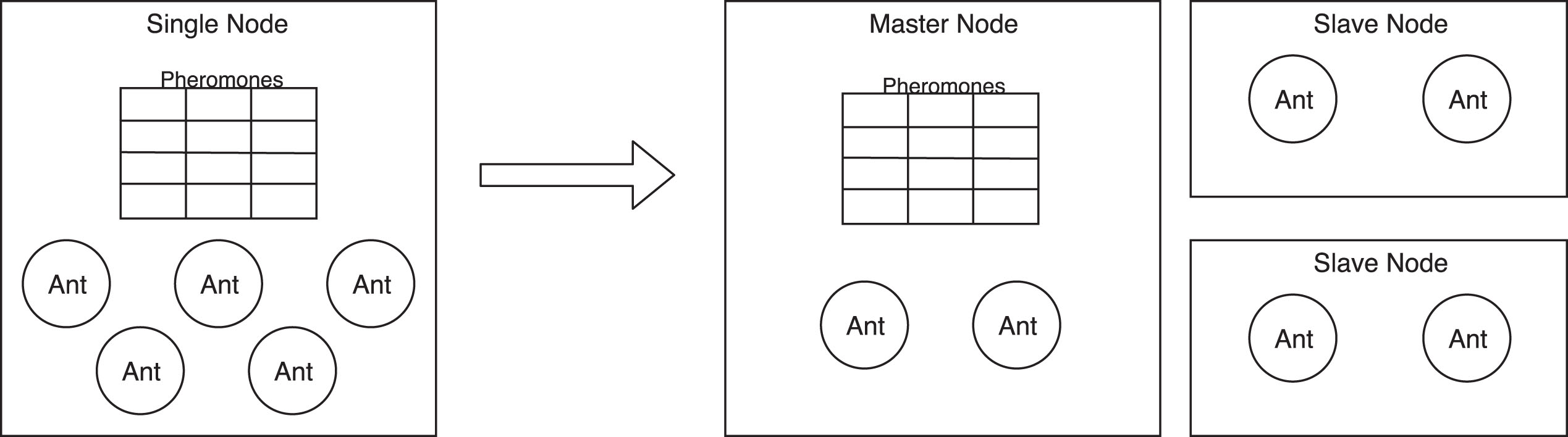
Master-slave model of the distributed ACO.
The distributed pheromone matrix (see Fig. 2) reduces influence of these limits. Each computation node owns a part of the matrix and has the following responsibilities:
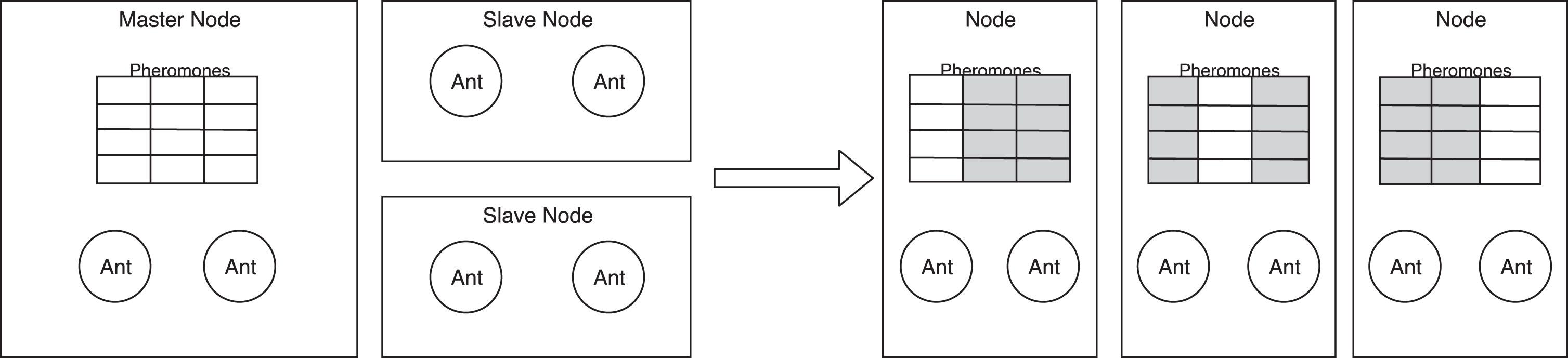
ACO with distributed pheromone matrix.
providing the pheromone values to all other nodes (see Fig. 3),
caching values from the remote parts of the matrix and providing them to the local ants (see Fig. 3),
collecting the solutions from the local ants and broadcasting them to all other nodes,
applying the pheromone updates on its part of the matrix.

Providing pheromone values to the ants on different nodes. Computation node 1 contains pheromone data regarding node i.
The pheromone matrix data is uniformly distributed across all the system nodes, which enables distribution of the matrix related operations and improves utilization of the computing resources. Each node runs numerous ants, so the values loaded from the remote parts are cached, which greatly reduces the network communication (a single value from the matrix can be loaded only once per iteration). The remote values are loaded on-demand, which enables parallel data synchronization and solutions constructing. Also, in case of problems which do not require visiting all of the graph nodes (such as the discrete knapsack problem), the on-demand loading does not synchronize unnecessary parts of the data.
In order to further reduce the network communication, the loading of the remote data does not ask for a single cell from the pheromone matrix, instead it loads pheromones of all outgoing edges from the given node in the problem graph, since these values are required by the ant’s probabilistic decision rule (see Eq. 1).
The architecture do not change any constraints of the sequential Ant System implementation. Each ant creates exactly one solution in each iteration, then it starts creation of the new solution, but blocks on waiting for the pheromone values for the next iteration, until the other ants finish their job in the current iteration and all nodes update their parts of the matrix.
This subsection describes parameters of the proposed algorithm and relations between their values. The parameters are similar to the ideas from the standard ACO variations, the proposed configuration modifies their relations and default values in order to efficiently use the knowledge collected by the numerous ants.
The configuration of the algorithm includes: N - a number of ants in the system. ρ - a pheromone persistence coefficient. Q - a pheromone update unit. α - importance of the pheromones. β - importance of desirability. IBU - iteration best updates; a number of the best ants from the iteration updating pheromones after each iteration, their update is not weighted by the ranking position. GBU - a multiplier for the pheromones left on the global best solution after each iteration. τ (0) - global best updates; an initial amount of the pheromones on every edge, usually it is equal to the τ
Max
value. τ
Max
- a maximum value of the pheromone on an edge. τ
Min
- a minimum value of the pheromone on an edge.
In a standard implementation of ACO selection of values for the parameters α and β depends on the desirability values from a problem representation and the τMax/Min parameters (if they are used). If desirability values and τ values are normalized and fit [0, 1) bounds, the choice of α and β values is less dependent on the problem instance.
A similar situation occurs with the Q parameter. The range of usable values of this parameter depends on the fitness values of the problem solutions and the ρ and N parameters. The order of magnitude of values
The algorithm uses the standard representation of TSP for use in ACO algorithms: the problem nodes are the cities to visit, all nodes are connected and the cost of each edge is defined as a distance between cities. The solution needs to include all nodes exactly once and the cost is a sum of costs of all included edges. The desirability of an edge is an inverse of its cost [3].
The representation of VRPTW includes one special node which is the depot node. The rest of the nodes represent clients to be served. Each client node has an assigned order size (related to the cars capacity) and a time window when the client is to be visited. All nodes are connected. A solution starts from the depot node and can come back to this node multiple times – every return is considered as a new vehicle selection. The route of each vehicle in the solution starts at time 0, the time of travel between nodes is equal to the distance between them. The sum of clients’ orders assigned to a single vehicle cannot exceed the globally defined vehicle capacity. The cost of the solution is a number of vehicles used by the solution, in case of equal number of vehicles the traveled distance is used to select the better solution. The desirability of node is an average of inverse of distance to travel and inverse of the end of target’s time window. These values are normalized respectively by the maximum distance between nodes and the maximum time window end time [11].
Experiments
This section describes experiments aiming to prove that the presented algorithm can outperform the standard ACO implementations. The conducted experiments show the scalability of the system and compare different configurations performance in terms of the quality of the solution.
In order to verify the proposed algorithm of distribution of pheromone table, a dedicated computing system was implemented based on Scala and Akka technologies.
The experiments were conducted on the Prometheus supercomputer—a peta-scale (2.4 PFlops) cluster located in the Academic Computer Center Cyfronet AGH in Krakow, Poland. As of November 2018, Prometheus is ranked on the 131st position on the TOP500 fastest supercomputer list. Prometheus is a cluster of the HP Apollo 8000 nodes, each with 24 Xeon E5-2680v3 CPUs working at 2.5GHz frequency, connected via InfiniBand FDR network.
System scalability
The scalability of the system is not our main point in this paper, however, it is the basis of reasonableness of running numerous ants in a single iteration. In this section, we present basic tests of the scalability, which we will extend in the future.
Table 1 and Table 2 show a single iteration duration on various number of computing nodes with 25 ants simulated on each of them. The former presents results for a problem from TSPLIB: pr2392, the latter uses RC1_10_1 from Gehring & Homberger benchmark. Every test case was repeated 10 times.
Scalability on pr2392 from TSPLIB
Scalability on pr2392 from TSPLIB
Scalability on RC1_10_1 from Gehring & Homberger benchmark
When the problem exceeds particular size, additional computing nodes reduce duration of a single iteration, which is a result of the distribution of updating the pheromones matrix. In case of a big matrix for the pr2392 problem, the system scale very well up to 50 nodes. The VRPTW instance requires a much smaller matrix, so the system achieved good scalability up to 30 nodes. When the number of nodes is too high, the performance breaks down due to high impact of the inter-node communication.
In this section we will compare the effectiveness of the sequential Max-Min Ant System, Distributed Ant System (distributed Ant System without improvements regarding problem representation and parameters setup) and Enhanced Distributed Ant System (including all improvements described in the previous section).
The MMAS algorithm [10] is one of the most efficient sequential extensions of the Ant System. The Table 3 presents comparison of the results obtained by the reference MMAS implementation2 with 25/250 ants, Distributed Ant System with 1k/10k ants and Enhanced Distributed Ant System with 250/500 ants. None of the algorithms used any local optimization mechanisms nor TSP specific assumptions and each tests case was repeated 10 times.
Distributed Ant System was running 400 iterations for both problems, Enhanced Distributed Ant System had 1000 iterations and MMAS had 2500 iterations.
The algorithms configuration: MMAS: α = 3, β = 5, ρ = 0.95. DAS: α = 2, β = 3, τ (0) =0.01, ρ = 0.99, Q = 1. EDAS with 250 ants: α = 3, β = 5, τ
Max
= 0.9999, τ
Min
= 0.0001, τ (0) =0.9999, ρ = 0.95, Q = 0.0005, IBU = 100, GBU = 100. EDAS with 500 ants: α = 3, β = 5, τ
Max
= 0.9999, τ
Min
= 0.0001, τ (0) =0.9999, ρ = 0.95, Q = 0.0002, IBU = 250, GBU = 250.
Comparison of results achieved by MMAS, Distributed Ant System and Enhanced Distributed Ant System on TSP instances from TSPLIB
Comparison of results achieved by MMAS, Distributed Ant System and Enhanced Distributed Ant System on TSP instances from TSPLIB
Comparison of results of Enhanced Distributed Ant System on VRPTW instances from Gehring & Homberger benchmarks. Best/average/worst result
The results show that increasing the number of ants in case of the standard MMAS does not improve the solutions - in case of u1432 the result of 25 ants was better. MMAS allows only one ant to put the pheromones after each iteration, so the knowledge from the extended exploration is wasted.
In both cases the DAS and EDAS algorithms significantly outperform the MMAS implementation. The DAS achieved better results than EDAS in case of u1432 and similar in case of pr2392, but EDAS requires much smaller number of ants, so the computation time was around 10 times smaller in case of EDAS with the same number of computing nodes.
The experimental results show that the additional exploration conducted by the numerous ants makes significant difference when the collected knowledge is properly utilized.
EDAS outperforms MMAS, because it extends exploration by numerous ants and efficiently uses the knowledge collected by these ants. This sections covers the topic of selecting number of ants and the values of IBU and GBU parameters. Table 4 contains results of various VRPTW calculations with different parameters configurations. The result contains only the number of vehicles, for every test case we present best/average/worst result of 5 repeats. The configuration parameters were: α = 3, β = 5, τ
Max
= 0.9999, τ
Min
= 0.0001, τ (0) =0.9999, ρ = 0.95,
The first part of a problem name describes the problem type: C / R / RC - clustered / random / mixed problem. 1 - short planning time horizon - shorter routes, more vehicles. 2 - long planning time horizon - longer routes, fewer vehicles.
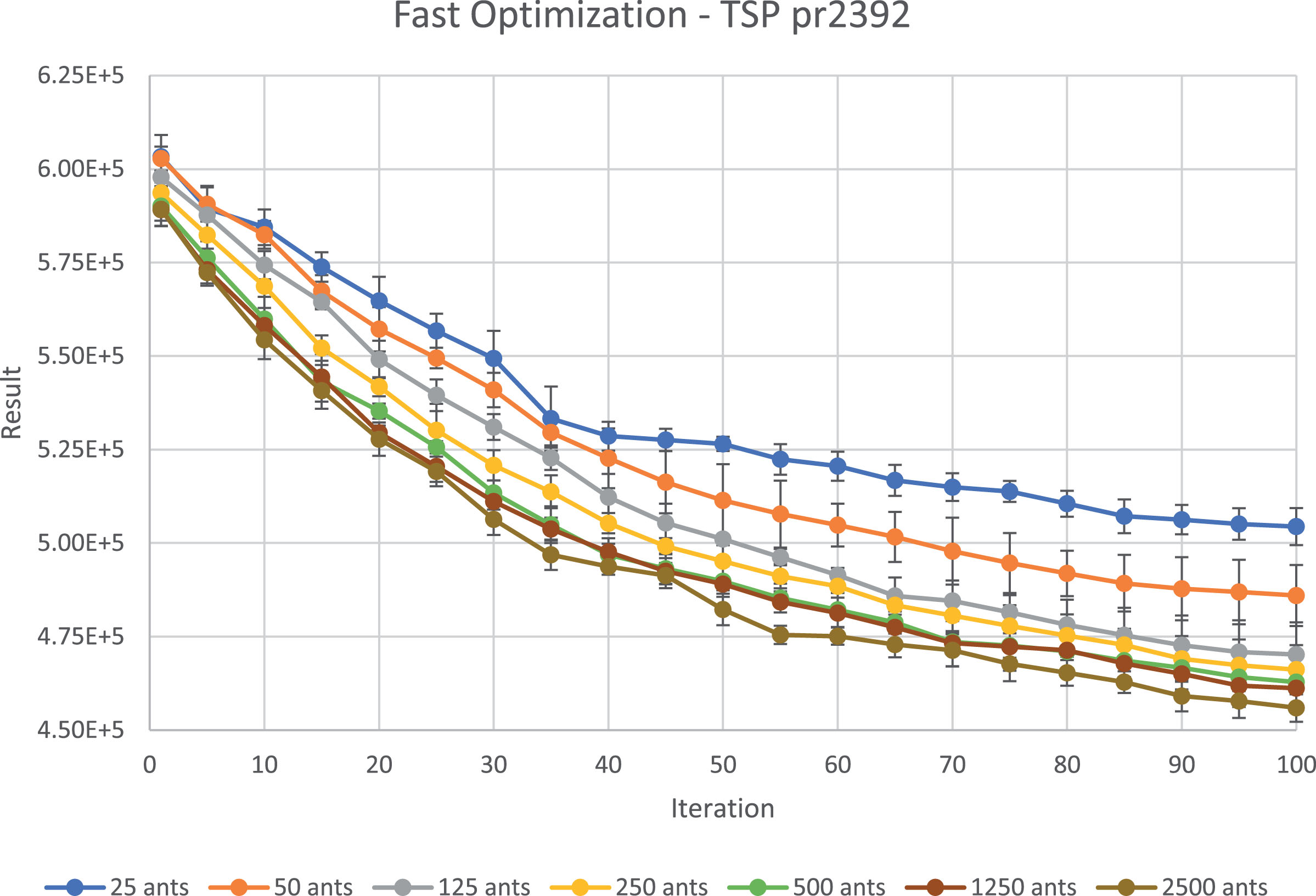
Best solution over iterations with different ants number; Problem TSPLIB: pr2392.
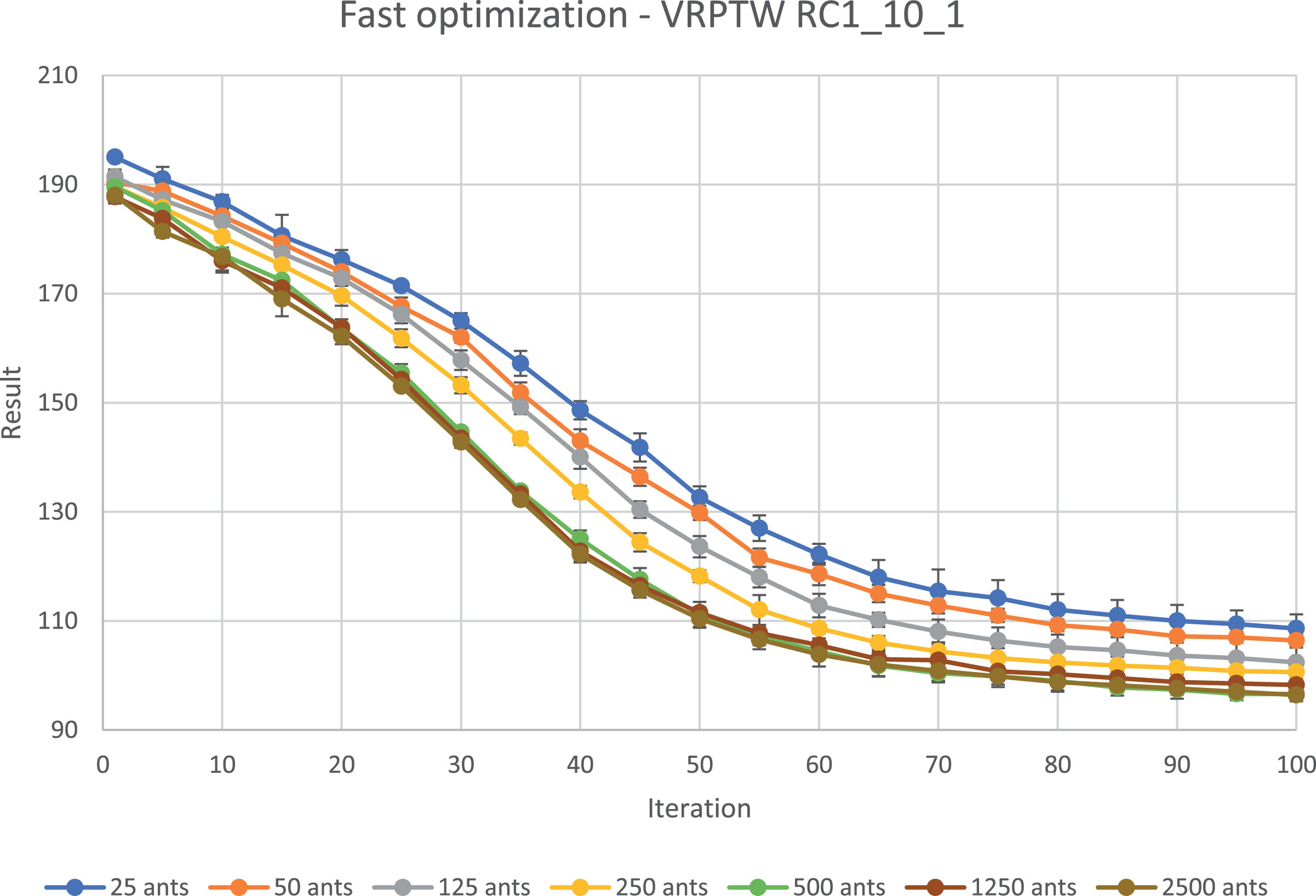
Best solution over iterations with different ants number; Problem VRPTW: RC1_10_1.
The results show that the number of ants itself without any changes of GBU and IBU has an influence on the solutions - the more ants the better solution is. The GBU and IBU parameters changes seem to be also important - the best results were yielded when less than a half of the best solutions were strengthen in the pheromone matrix.
The extended exploration arisen from the high number of ants leads to better solutions at the beginning of computations. It can be useful in dynamic optimization tasks, where rapid optimization is required.
Figure 4 and Figure 5 show that there is an upper limit of profitability of higher number of ants for each problem. The bigger the problem is, the higher is the limit. In case of VRPTW with 1000 nodes there is no gain from increasing ants number further than 500 ants, but for TSP with 2392 nodes even 2500 ants configuration provides better results than the less numerous configurations.
Summary
The experiments show that the higher number of ants leads to better optimization results when the additional knowledge is used properly. The scalability of the algorithm enables usage of big clusters in order to obtain better results without noticeable computation time elongation. The distributed system architecture is able to handle big optimization problems.
Conclusions
In this paper a design of ACO with distributed pheromone matrix has been presented. The idea is based on the well-known master-slave model. The distribution of the matrix enables high scalability and effective running of numerous ants. Besides scalability, we have focused on leveraging the knowledge collected in the system. The proposals were inspired by the well known sequential Ant System extensions and adapted to the numerous ants in the simulated Ant System. The problem representation normalization has been proposed, which enabled defining sensible values of the algorithm parameters, independently from the problem instance specific values like route length in TSP.
The algorithm compares well with Max-Min Ant System when basing on the two TSP problems from TSPLIB. The bigger a problem instance is the more prominent is the difference. The experiments based on VRPTW showed that the higher number of ants in the system improves the results. This property combined with the high scalability enables high potential of improving the efficiency of the raw metaheuristic (without local and problem specific optimizations) without rising the computation time. The experiments proved that the high number of ants also improves rapid optimization, due to extensive exploration at the beginning of the computations.
To sum up, the presented metaheuristic algorithm gives a significant improvement when compared to the standard Ant System variations like the Min-Max Ant System. It is a result of efficient usage of the knowledge collected by the numerous ants without extending the computation time thanks to the high scalability.
In order to conduct the experiments in this paper, a prototype computing system was implemented using Scala/Akka technology. The obtained efficiency and scalability results are very promising (and we will devote a dedicated publication to these phenomena) and confirm that this technology should be further leveraged when developing our research.
In the future we plan to improve scalability of the algorithm by desynchronizing the operations related to the pheromones matrix. It should enable efficient deployment of the ants on the higher number of computing nodes and enhance the algorithm’s performance on huge problem instances. The application of this system design to other swarm intelligence algorithms (or more generally to the algorithms with global knowledge) is another path of future research in this topic.
Footnotes
Acknowledgments
The research presented in this paper was partially supported by the Polish Ministry of Science and Higher Education funds assigned to AGH University of Science and Technology. The authors acknowledge using of PLGrid infrastructure.