
Abstract
The monitoring of the computational processes in highly distributed environments remains challenging in today’s High Performance Computing. In this paper, we define the agent-based cloud monitoring system for supporting the computational tasks scheduling and resource allocation. The system consists of two types of agents, which may decide about the initialization of the schedule execution and monitor the work of the cloud computational nodes. The decision about running the new scheduling process is based on the expected number of available computational units in the specified time window. The efficiency of the proposed MAS-based model was justified through 40 empirical tests, where clouds without and within the MAS support were compared. The multiagent system (MAS) effectiveness has been expressed in the average number of floating point operations completed at the cloud resources in one second. The obtained results show the importance of setting the optimal initial time for execution of the new schedule. Our experiments show that for running the new schedule, at least 25% of the computing units in the clouds should be in the idle mode. Also the batches of tasks should not be too large, cause the waiting time for new schedule for execution should be short and not greater than 10% of expected batch execution time.
Introduction
Scheduling of the complex numerical workloads in computational clouds and efficient management of the cloud resources remain the challenging research and engineering tasks over the past decade. The maximization of the resource utilization and benefits of the cloud service providers and the resource owners are the key objectives of the scheduling. However, such aspects may be opposite to the expectations and specific end users’ requirements, such as privacy and data protection, security, system reliability, responsiveness of the service software applications, possible minimal cost of using the cloud services. The generation and successful execution of the optimal schedules should guarantee the trade–off among the needs and requirements of the cloud end users and benefits and expectations of the cloud managers and resource owners. The intelligent scheduling monitoring tools may efficiently support the executions of tasks, but also play the role of the recommendation systems for the improvement of the scheduling methods and algorithms.
Multiagent Systems (MAS) allow to provide the autonomous and distributed decisions of intelligent agents and their adaptation to the changes in the environment. The agents are located in the shared environment, perform the autonomous actions, may interact with each other and change the environment [7, 33]. The first MAS models were developed about 30 years ago as the the tools for solving the complex problems in massive open distributed systems. Collective intelligence is helpful in the specification of agent–to–agent and agent–to–environment relations. The MAS are also successfully applied for parallel implementations of the complex meta–tasks in computational grids and clouds [6, 28].
The autonomous decisions and actions of the agents are the basic properties of agents in classical and today’s modern MAS models [7, 31]. The intelligent agent, through his autonomous decisions, has a full control on his behaviour. It allows to specify the full characteristics of the agent, which is called the ”internal state” of the intelligent agent [22].
In the formal model of MAS developed by Wooldridge [31], the agent interacts with the environment and may change its status. The dynamic changes of the environment may have the impacts on the agent’s behaviour and his future decisions. Such influence of the environment may be positive or negative. Also the agent may take the wrong decisions. Therefore, the parameters of the MAS should be relevant to the considered problems in order to fulfill the agent’s individual goals and realize the tasks defined for the agents.
The main characteristics of the intelligent agents can be defined in the following way:
In this paper, we develop the agent-based monitoring system of the execution of schedules of computational tasks in the cloud environment. The tasks are grouped into batches and can be run independently of each other. There are two types of agents defined in our model denoted by Ag1 and Ag2. Each Ag1 agent monitors the progress in the execution of the tasks allocated at the cloud computational units and detect the idle units. Ag2 agent sends the queries to the agents Ag1 about the status of the run schedule. Based on the information collected from Ag1-s, Ag2 decides about the initialization of the execution of the new schedule and reports the idle units.
The main contributions of this paper are the following: definition of the MAS model integrated with the cloud environment for monitoring the execution times of schedules of batches of tasks; definition of the agents’ decision mechanism for setting the proper sizes of the batches of tasks and schedules and identification of the proper time points for starting the schedule execution; definition of the method of tuning the parameters of the MAS model to the considered scheduling problem; and finally, performing excessive numerical analysis for the validation the MAS-based cloud scheduling model.
The developed model is the second step in our research on the monitoring and recommendation systems supporting the cloud task and resource management. In our previous work, we implemented the Artificial Neural Network as the recommendation system for the resource management in computational grids [16, 17]. The developed MAS model is a simple tool for the improvement of the effectiveness of the cloud small clusters in the calculation of the batch schedules. We would like to extend this model for the online schedulers.
The rest of the paper is organized as follows. In Section 2 we present a short state–of–the–art critical analysis of the existing monitoring models based on the MAS paradigm, which are used for monitoring of the processes in the distributed computational environments. We justify the originality of our model. The basic concept of the MAS and definition of the considered scheduling problem are presented in Section 3. The new MAS–based model for monitoring of the execution of schedules in computational clouds is defined in Section 4. Developed model was experimentally evaluated in Section 5. We summarize our work and draw simple conclusions in Section 6.
Related work
The efficient monitoring of the schedule execution in the cloud system requires salable intelligent tools. Although there are many examples of such tools in the literature [4, 30], the very few of them are based on the MAS model. In this section, we provide a simple survey of the selected MAS-based monitoring techniques and address pros and cons of their applications in concrete scenarios.
MonALISA monitoring agent system [11] is defined as a Large Integrated Services Architecture. The main idea of this model is based on the generation of a set of dispersed communicating agents that collect and analyze data necessary for optimizing task processing in the distributed computational environments. The agents’ actions are mainly gathering information from the other agents and environment, but the agents are not capable of making any complex decisions.
Zubok et al. present in [10] the agent-based system for monitoring dynamic cloud environments. There are three types of agents defined in their model. The agents are able to monitor the cloud system performance, record the incoming tasks, and monitor the status of the computing resources, which includes the times of tasks execution, memory usage and available disk space at the cloud servers. The presented agent system does not implement any intelligent methods for decision making processes.
In [8], M. Dhingry developed the monitoring models with a set of virtual machine agents in order to collect the information about the resource usage for single virtual machine (VM) implemented in a given physical server. The model has also a bare metal supervisor agent, which monitors non virtual cloud infrastructure. The third agent plays the role of the central authority in the whole monitoring systems. This agent collects information and data from the rest of the agents and make the decisions about mapping the tasks to the cloud servers.
Meera and Swamynathan in [27] define the model with a set of agents monitoring each VM in the cloud. The data collected from that monitoring is sent to the central agent. Agents do not make intelligent decisions in this model, just collect and deliver the monitoring data to the system administrators.
Another model is New Relic Digital Intelligence Platform defined in [2], where the implemented agents monitor the efficiency of the execution of the software applications run in the cloud. The system can be easily integrated with Amazon AWS, Azure, OpenStack or HP Cloud Services.
IDERA Uptime Cloud Monitor [18] can be used for cloud monitoring and the prediction of the potential system misbehaviour and disturbances.
All above models are agent–based models and may be used for monitoring of the execution of computational tasks processed in distributed computing systems. Together, with other popular monitoring systems such as Ganglia [26], Nagios [5], Opsview [32], CloudHarmony [1] or SPAE Server Monitoring [3], they may support the environmental operator decisions. However, in the surveyed models, the agents do not have to make any complex (intelligent decisions). Their behaviours do not necessary have an impact on the states of the environment, in which they are situated. Such agents focus rather on the monitoring of the utilization of the physical nodes in the the cloud’s IaaS (Infrastructure as a service) layer. This is just one aspect of the complex monitoring of the schedule execution. The results of the simple analysis of the existing models inspired us for the research on the new MAS monitoring system, where collective intelligence methods can be used for the characteristics of agent-environment and agent-agent interactions.
Backgrounds of the monitoring model
Multiagent systems
The model of intelligent software agent developed by Wooldridge in [33] and updated by Weiss [31, 33] is one of the most popular formal models of the multiagent systems. The model in its recent form defines the agents in the dynamic environment, which is the integral part of the whole system. The agents and the environments can interact and change each other.
Based on the model of Wooldridge, let us denote by
the finite set of n states of the environment. The parameter e
t
i
defines the state of the environment in the time interval t
i
, i = 0, …, n - 1. The set of all possible finite subsets of the environment E, which may be achieved in at most n time intervals is defined in the following way:
The agent’s environment is defined as 3–tuple:
An intelligent agent Ag is located in the environment Env, and can perform actions from the set Ac, where:
The set of all possible finite subsets of Ac is the set of all possible finite sets of agent’s actions performed in the at most n time intervals and it is defined as follows:
The agent’s actions may change the states of the environment. Formally, the agent Ag may be represented by its action function in the following way:
Let us denote by
The agent–environment interactions can be defined by the following procedure:
The steps
The whole process of agent–environment interactions can be defined as the chain r of environmental states and agent’s actions in the sequence t0, t1, . . . , tn-1:
The following pair 〈Ag, Env〉 defines a multiagent system.
The agents have their own internal structure, which is used for recording the information about the changes in the environment. Let us denote by I
Ag
the set of all internal states of the agent Ag. The function of the monitoring of the environment Env by the agent Ag is defined as follows:
Based on the agent’s perception of the environment the agent’s action now is defined as follows:
The function next, which updates the internal state of the agent is defined in the following way:
Problem of task scheduling can be formally defined using the following notation: [29]:
A – represents the available resources and system architecture, B – the mode of tasks processing and its constraints, C – the scheduling criteria.
Using the generic scheme, we may define the batch scheduling of idependent task in the following way [24]):
where Rm – the heterogeneous environment of hardware resources allowing parallel task processing; CM – central management; batch/on - line – tasks processing modes; independent/dependent/workflow – tasks having or not having dependencies between them or the additional data flow necessary during tasks processing; static/dynamic static environment with constant processing unit characteristics or dynamic environment that may change during scheduling process; objectives – the main criterion for particular task – resource mapping.
In the paper we are considering independent batch scheduling mode [17, 24]. Considered tasks are collected in batches. The numbers of tasks in the batches may change in the different time intervals. The tasks from a given batch are processed independently on available Virtual Machines (VMs). The number of VMs may vary in the system but remain constant during the execution of task:
Therefore, each single scheduling problem may have different number of possible schedules to chose from.
To estimate the time that computing unit will be calculating particular task, the computing capacity vector for VMs in Giga Floating point Operations Per Second (GFLOPS) was introduced:
The tasks are characterized by workload vector expressed in Giga Floating point Operations (GFLO):
To calculate the schedules, the Expected Time to Compute (ETC)[sec.] matrix was defined in the following way:
Task execution process may be summarized as [25]: monitoring the number m of computing units, and their computing capacity vector; collecting tasks and formulating the batch; monitoring the number n of tasks in the batch and workload vector for formulated batch; calculating schedule; allocating tasks at computing units; monitoring the execution of the schedule.
To find the schedule, the time difference between the start and finish of a batch of tasks (makespan) was considered:
The particular schedule is selected for the execution that minimizes the makespan of tasks from the formulated batch assuming given processing units characteristics, see [20, 24]. The makespan is one of the most common optimizing criterion for batch scheduling problem.
In this section, we define our developed MAS–based model for monitoring the execution of the schedules of batches of tasks in the cloud environment. The main idea is based on the MAS model developed by Dobrowolski in [9]. The analysis of the MAS system performance and structure is provided through the decomposition of the whole system into the set of the local coordinated units (in many cases – single agents). Such decomposition allows to focus on the definition of the strategies and actions of the agents and integrate those components into the global model, instead of the global analysis of the whole complex system.
Generic model of the MAS monitoring system
The model of MAS used for monitoring of the batch scheduling problem is defined as the following structure:
AG – set of agents in MAS; ID – set of individual agents’ ID parameters; TP – set of agents’ types parameters; LOC – set of agents’ location parameters; ES – set of all possible states of the environment; ACT – set of the agents’ actions taken in the environment; ST – set of the agents’ strategies.
Each agent Ag is characterized by the following parameters:
id ∈ ID – individual agent’s ID parameter; tp ∈ TP – type of the agent; k ∈ K – actual agent’s knowledge; γ – agent’s perception of the environment function – based on it, each agent may improve of his knowledge;
β – strategy selection function:
δ – agent’s decision function, which defines his action based on the agent’s strategy:
Two types of agents are specified in the developed model, namely TP = {Ag1, Ag2}, where: Ag1 – monitors the execution of tasks according to the defined schedule and number of idle computational units, in which the new tasks may be allocated; Ag2 – receives the reports from the agents Ag1 and defines the start time of the execution of the next batch of tasks (another new schedule).
We assume in the model presented in this paper, that just one agent Ag2 is generated.
The main characteristics of the above MAS model are the restrictions of the continuous monitoring of the agents’ locations
1
. There are two such locations defined in the system:
The set of the agents’ strategies ST contains the strategies defined for the agent Ag2 and several Ag1 agents, i.e.:
Each strategy generates the set of possible actions of the agent of a given type. Formally, the set of the agents’ actions in the proposed MAS model can be defined in the following way:
The interpretation of the elements of both sets ACT
st
1
and ACT
st
2
is as follows: getstage – the update of the Ag1 agent’s knowledge about the execution of the schedules based on the values of the environment monitoring function; informstage – Ag1 reports to the agent Ag2 the progress in the realization of the tasks in the schedule; gentimepoint – Ag2 initialize the start time of the execution of the schedule based on the data received from all agents Ag1; startsched – Ag2 starts the execution of the generated schedule.
The monitoring of the work of the cloud computational units (VMs) during the scheduling process is based on the agents’ strategies of the generation of the time points in the process of execution of the schedules t k (k ≥ 1). Each time point parameter defines the start time of the execution of tasks from the schedule at the cloud servers. Agents Ag1 are defined for each cloud unit (VM) and monitors the execution of tasks assigned to that unit. Ag2 quests all agents Ag1 and asks for the information about the execution times of particular tasks from the batch at the units associated with the concrete Ag1 agents. Then, agent Ag2, based on the collected data from the agents Ag1, defines the start time of the execution of the schedule.
Let us denote by the ordered set of times of completing the tasks in the schedule at the time points t
k
. The procedure of the generation of the time points by MAS has the following two main parameters: θ1, θ1 ∈ {1, 2, …, m} – this parameter defines the number of the computational units, which must be in the idle mode in order to generate of the new time point; θ2, θ2 ≥ 0 – this parameter defines the maximal waiting time for finishing all tasks in the schedule.
MAS generate new time point t k based on the following relation:
In the case of finishing work by the the computational units approximately in the same time, θ
k
coordinates of the vector
Only the units from the set
The values of the parameter θ1 are the fractions of the active computational units working in the agent environment, i.e.:
The parameter θ2 was calculated based on the percentage of the average mean loading of 1 GFLOPS computing capacity. This calculation was made assuming the requested workload from currently processed batch and available computing capacity of the idle resources:
The aim of the presented numerical experiment is to examine the environment behaviour considering the different number of computing units, diversified load and several sets of parameters. The basic design of the system monitoring depends on the parameters described by Equations (34)–(35). Presented numerical tests show the influence of the parameter setting on the environmental performance that is measured by the for the number of floating-point operations performed in one second.
The evaluation was conducted under the dedicated simulator of a computational cloud. The implementation is based on C++11 programming language, FastFlow framework and POSIX library. The simulator was build in Microsoft Visual Studio 2017 environment, The source code was optimized and compiled using Microsoft C/C++ compiler for 64-bit platforms.
Specification of the simulated environment is presented in Table 1. For presented experiments, we have used 2 characteristics of tasks presented in Table 2. The schedule was generated by the evolutionary algorithm specifically described in [15, 21].
Characteristics of computational units
Characteristics of computational units
Characteristics of tasks
First scheduling starts with all available computational units and with the whole batch of tasks ready to process. Characteristics of the tasks are presented in the Table 2. The next time points are generated based on agents’ decisions. The number of tasks in one batch is strictly proportional to the number of available computational units. It can be defined by:
The experiments were conducted under 40 different tests with the parameters Ω1 and Ω2, different characteristics of tasks batches and sets of computational units. Each test consists of 4 schedule execution processes in a sequence. Each experiment was repeated 100 times under the same configuration of parameters. The considered test scenarios are presented in Table 3 and Table 4. The value of θ2 was determined by using eq. (35).
Characteristics of scenarios for Ag2
Values of θ1 parameter
The results of conducted experiments are presented in Figures 2–4. Each graph is described by a scenario, and values of Ω1 and Ω2. The results obtained for Ω1 = 100 are achieved in the case, that cloud system was not monitored by the agents Ag1 and Ag2.
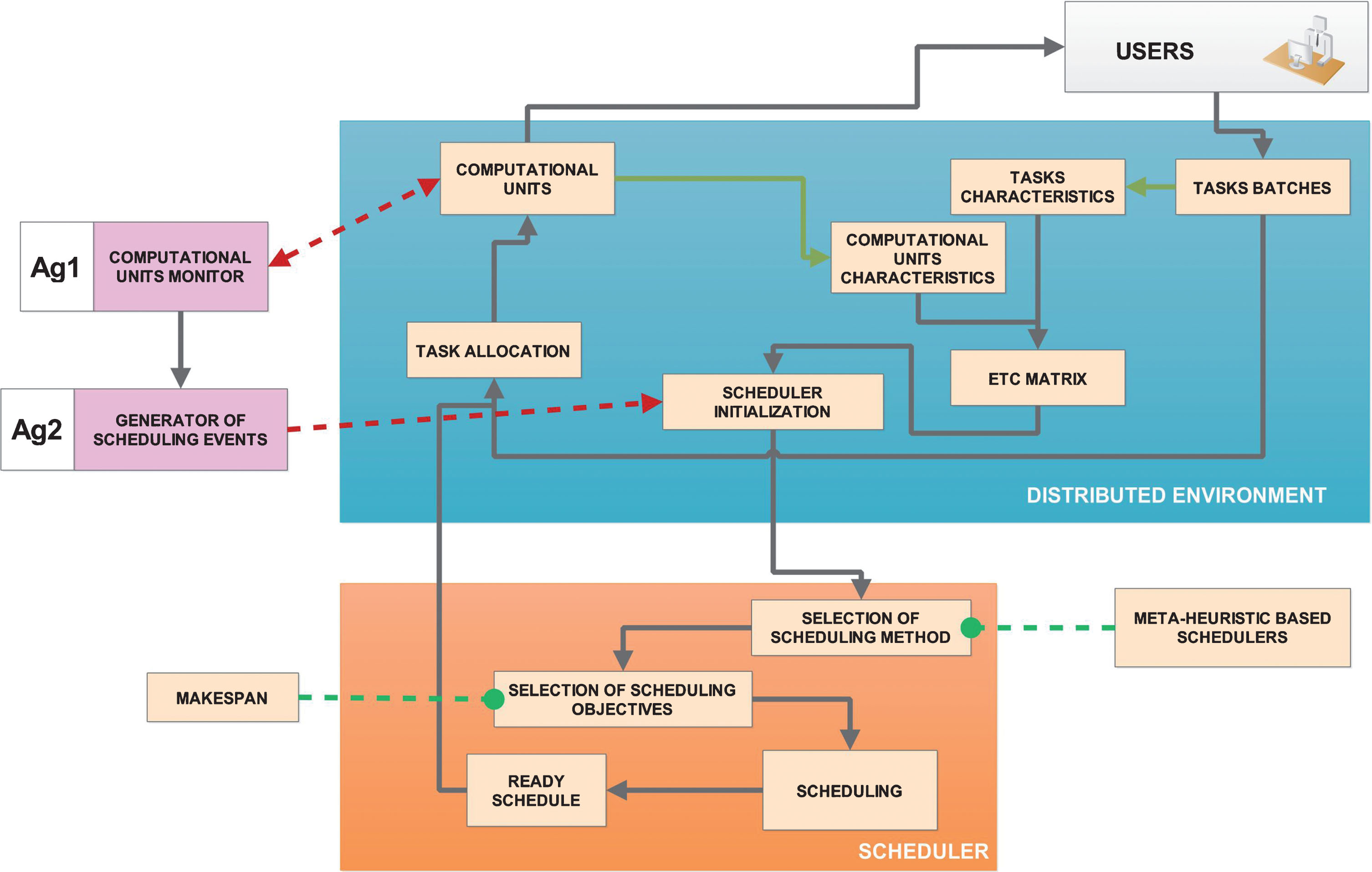
Work flow in distributed computational environment supported by MAS–based monitoring system.
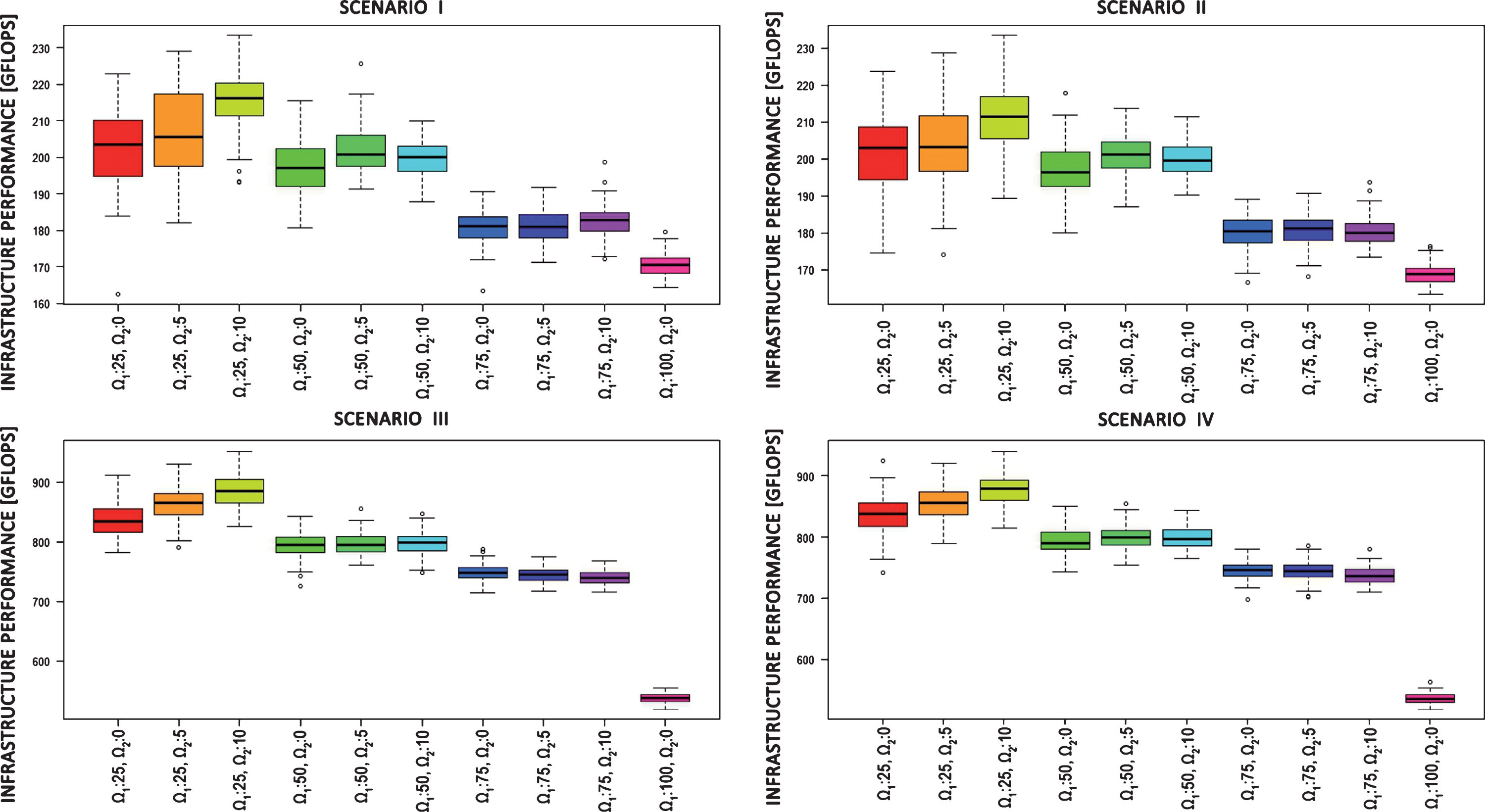
Cloud units performance for each agent strategy and scenario.
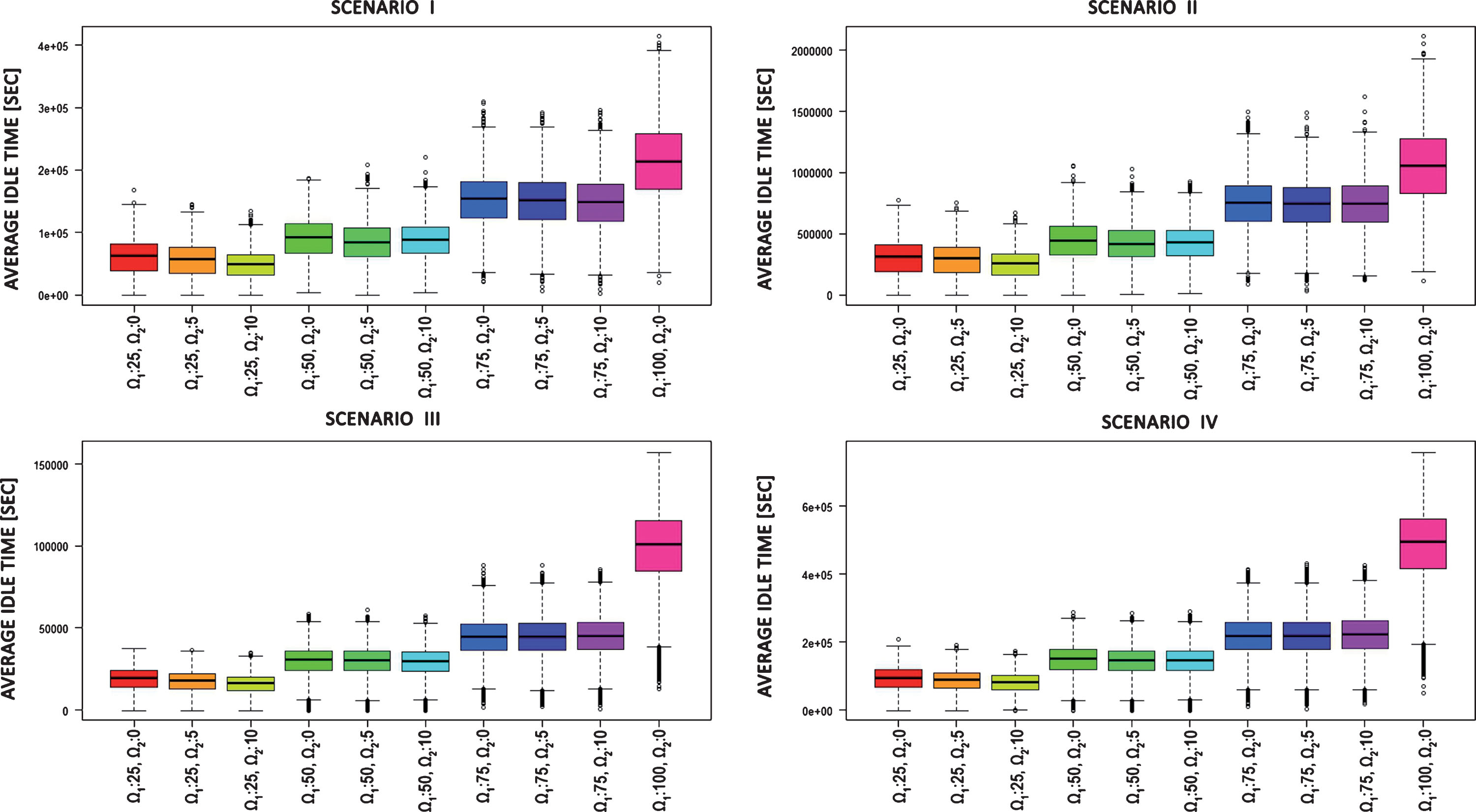
Box plots presenting average idle times of computational units for each agent strategy and scenario.
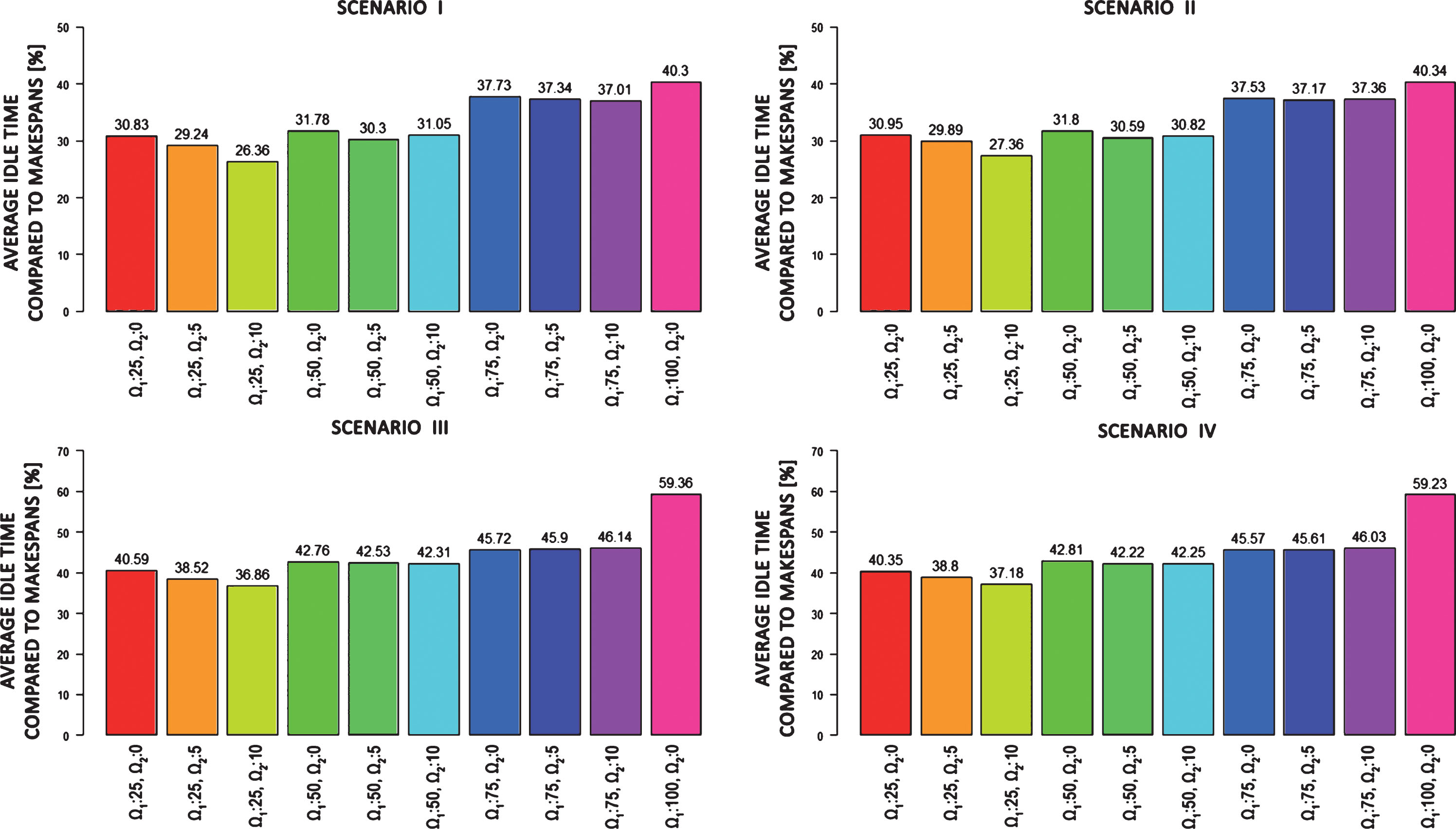
Average idle times of computational units divided by a time spent for processing all batches of tasks for each agent strategy and scenario.
First, the generated schedules were compared in terms of the number of floating-point operations performed in one second within the entire available infrastructure (i.e. the average efficiency of the entire infrastructure). The main goal of the agents’ strategies was to determine such moments in the execution of the tasks that would allow better use of the available (i.e. idle) infrastructure.
Best results for the number of floating-point operations performed in one second were achieved for the third strategy (see: Fig. 2), when at least 25% of the computing units were idle and waiting time was equal 10% of average time for execution whole batch (see: eq. 35). In comparison to the not monitored environment, the third strategy allowed the improvement of the order of 26.14% for the scenario I, 25.14% for scenario II, 64.3% for scenario III, 63.61% for scenario IV.
A larger dispersion of values for cases supported by agents should also be noticed. On the one hand, this indicates less predictability of the generated schedules, and on the other, it can provide an opportunity to develop solutions (scheduling algorithms) that allow for better results.
The presented results also indicate a better use of computing power for smaller infrastructures – environments consisting of 40 computing units were characterized by approximately 20% better efficiency.
Two next Figures (3, 4) shows average idle times of computational units. Fig. 3 presents the distribution of idle values of individual computational units. The highest values are characterized by the unsupervised strategy, while for all supported scenarios the third strategy obtains the best results. The third strategy allows for the maximal reduction of idle time.
Fig. 4 shows the most important results of idle times savings. The figure presents average idle times divided by a time spent for processing all batches of tasks. It shows the profit of using agents strategies. In the case of scenarios number I and II, each unsupported computational unit was idle for about 40% of the running time. The best strategy minimized this time by about 13–14%, the rest from about 2.6% to 11%.
For large–scale environment (scenario III and IV), the profit resulting from the use of agent supervision was even greater. For unsupported strategy, the average idle time reached nearly 60% of the running time. As in the previous scenarios, the best results were achieved for the third strategy (Ω1: 25, Ω2: 10) – idle time equal to 36.86% and 37.18% for strategy III and IV respectively. An improvement of 22–22.5% was achieved in this way. The remaining strategies have reduced the average idle time from 13.2% to 20.84%.
Presented MAS model does not depends on the methods of generation of the schedules. The application of strategies of Ag1 and Ag2 agents gives good results in the case of high idle time of computational units.
Comparing to the systems mentioned in Section 2, the actions of the agents are more complex. They are taking intelligent decisions and they are able to change the environment. Moreover, the presented MAS is not monitoring all the processes passively. The collective intelligence of them supports the decisions to be taken during task scheduling and processing.
In this paper, we defined the multiagent system consisting of two types of agents. The proposed model supports the efficient execution of the schedules generated in distributed computing environments such as computational clouds. Those agents are making decisions about the starting time of batch execution. Additionally, they are monitoring the progress of the task calculations.
The agents Ag1 and Ag2 supports resource management by generating the optimal time points when the execution of the new schedules should be started. The decision is based on the number of actually available computational units and the earliest time when the new units may be available.
The proposed model was evaluated in 40 different numerical tests. The results were compared with the cloud environment without the MAS monitoring system. The best results were obtained for the strategy in which the next scheduling process was started when at least 25% of the computing units were idle, and the waiting time for new units was less or equal 10% of expected batch execution time. Similarly, the best results in terms of using the environmental infrastructure were obtained for the same strategy. The obtained results showed the significant impact of choosing the moment of the scheduling process on the infrastructure performance.
We plan to extend the model to the more complex scheduling scenarios and wider cloud infrastructure with many Ag2 agents. For that, we need to define the novel ontologies for better modelling the agents’ social behaviours and interactions.
A very interesting development of the presented research may be changing the uniqueness of agent number two. Introducing several agents of that type may decrease the probability of system failure. Such decentralization of responsibility may increase the resiliency of the system.
Footnotes
Acknowledgment
The contribution of Dr Daniel Grzonka was supported by the Foundation for Polish Science (FNP).
In general MAS model, the locations of agents do not have to be controlled by the other agents or the MAS monitoring unit.