
Abstract
Obtaining interval estimates of nonlinear model parameters is as important as point estimates of model parameters. Because the estimated value of the parameters cannot always be expressed as a single numerical quantity exactly. In this study, it is aimed to propose an interval estimation procedure for nonlinear model parameters with combining soft computing methods instead of using probabilistic assumptions. For this purpose, response and model parameters were presented as triangular fuzzy numbers (TFNs) in nonlinear regression model. The errors were defined as intervals through alpha-cut operations and minimized according to the least absolute deviation (LAD) metric. The novelty of the study is achieving the minimization in a multi-objective framework in which the objective functions are lower and upper bound of interval type error functions. The NSGA-II (Non-dominated Sorting Genetic Algorithm-II) and the TOPSIS (Technique for Order Preference by Similarity to Ideal Solution) methods were used for multi-objective optimization (MOO) and multi-criteria decision making (MCDM) stages, respectively. Innovatively, in order to obtain reasonable interval estimates, predefined sized compromise solution set was composed and the fuzzy C-means (FCM) clustering algorithm was applied to the compromise set of interval estimates according to the predicted alpha-cut values. The proposed interval estimation approach is applied on a synthetic and a real data sets for application purpose.
Keywords
Introduction
Fuzzy regression analysis has been commonly used as a modeling tool since uncertainty always exists in real life problems. In the presence of vague nonlinear relationship between input and response variables, fuzzy nonlinear regression (FNR) becomes a powerful tool for modeling of the uncertain data sets. There have been several types of FNR application studies in the literature, e.g. FNR with fuzzy numbers [5, 26], FNR using a random weight network [31, 32], FNR with fuzzy functional networks [21], Artificial Neural Network for FNR [7, 27], Evolutionary Algorithms for FNR [13, 16– 18], Support Vector Machines for FNR [3, 11], Takagi-Sugeno fuzzy model for FNR [20, 28].
The FNR models usually consider fuzzy inputs-fuzzy response or crisp inputs-fuzzy response to define the fuzzy nonlinear functional relationship between inputs and response variables. Besides, the model parameters are assumed as crisp or fuzzy numbers. Using fuzzy model parameters helps to present the uncertainty of the parameter estimates in the FNR models. However, it is sometimes difficult to make analytical calculations with fuzzy numbers. In this case, it is proper to use interval valued fuzzy numbers obtained by α-cuts. The α-cut of a fuzzy number, a kind of threshold cut that restrict the domain of the fuzzy numbers, is always closed and bounded interval. In this manner, the α-cut of fuzzy model parameters can be considered as interval estimates for a confidence of 1-α for nonlinear model parameters.
Even though many authors have studied about FNR model, there have been only a few studies for the FNR model, based on interval valued data, obtained from the α-cuts of fuzzy numbers. Akrami et al. [1] presented a new method for solving fuzzy nonlinear optimization problems where all coefficients of the problem are triangular fuzzy numbers (TFNs) which are converted to intervals by using α-cuts. In [29], Choi et al. proposed fuzzy regression model with the monotonic response function by using the α-cuts of fuzzy number. The current studies make calculations for specifically defined an α-level. However, it is important to see the uncertainty of model parameters according to all α-levels where the α is not predefined.
In this study, the interval estimates of nonlinear regression model parameters were obtained by using α-cuts of model parameters which were considered as TFNs. It was supposed that the nonlinear functional form of the model was known explicitly. The response variable was dealed as TFN where the input variable was crisp. It was aimed to minimize the distance between observed and predicted interval valued fuzzy responses according to the least absolute deviation (LAD) metric. The main contribution of this study is achieving the minimization of errors in multi-objective framework. For this purpose, NSGA-II (Non-dominated Sorting Genetic Algorithm-II), a well-known population based stochastic multi-objective optimization (MOO) method, was used as a MOO tool to obtain Pareto set for interval estimates of model parameters with corresponding α-levels. Then, a compromise solution was chosen among the Pareto set by using TOPSIS (Technique for Order Preference by Similarity to Ideal Solution) which is a popular multi-criteria decision making (MCDM) method. As a matter of fact that the MOO procedure gives different compromise interval estimates since the NSGA-II uses stochastic search mechanism. Innovatively, in this paper, compromise set of interval estimates for parameters was composed with the application of TOPSIS to many independent runs of the NSGA-II. Then, fuzzy C-means (FCM) clustering algorithm was applied to obtain compromise set of interval estimates. The interval estimates were categorized according to the α-levels to make decision easier.
The rest of the paper is organized as follows: In Section 2, some preliminary concept of fuzzy sets were reviewed and the FNR with fuzzy α-cuts was explained in detail. In Section 3, proposed fuzzy MOO and fuzzy decision making were presented. The NSGA-II, the TOPSIS, the FCM methods were explained briefly. In Section 4, a synthetic and a real data sets were used to illustrate the applicability of proposed interval estimates approach. Finally, conclusion was given in Section 5.
Fuzzy nonlinear regression with fuzzy α-cuts
Preliminaries
Fuzzy set theory, introduced by Zadeh [19], is generally used to deal with vague data and uncertain structure. A fuzzy number
Even there have been several types of fuzzy numbers in the literature, the TFN is the most popular one with wide application. The TFN is presented by two endpoints, a1 and a3, and one peak-point, a2, denoted as
The definitions of arithmetic operations can be seen in the study of Shyamal and Pal [2]. An α-cut operation of the TFN, generates a finite closed interval, called as α-cut interval. This α-cut interval is denoted as
Let
Addition:
Subtraction:
Multiplication:
Division:
Multiplication by a crisp number: Let k be a crisp number.
Let consider a nonlinear regression model as
Data set with replicated response measures
In Table 1, n denotes the number of experimental units and r is the number of replications for the response. It should be noted that each replication is measured for each setting of a group of p input variables. In order to get interval estimates of model parameters, it is aimed to apply the FNR to the data set given in Table 1. For this purpose, the replicated response measures are transformed to the TFNs by using order and descriptive statistics, e.g. minimum, median, maximum. The fuzzy valued response is denoted as
Data set with triangular fuzzy response variable
The membership function of the triangular observed fuzzy response vector,
The general form of the fuzzy nonlinear regression model can be defined as
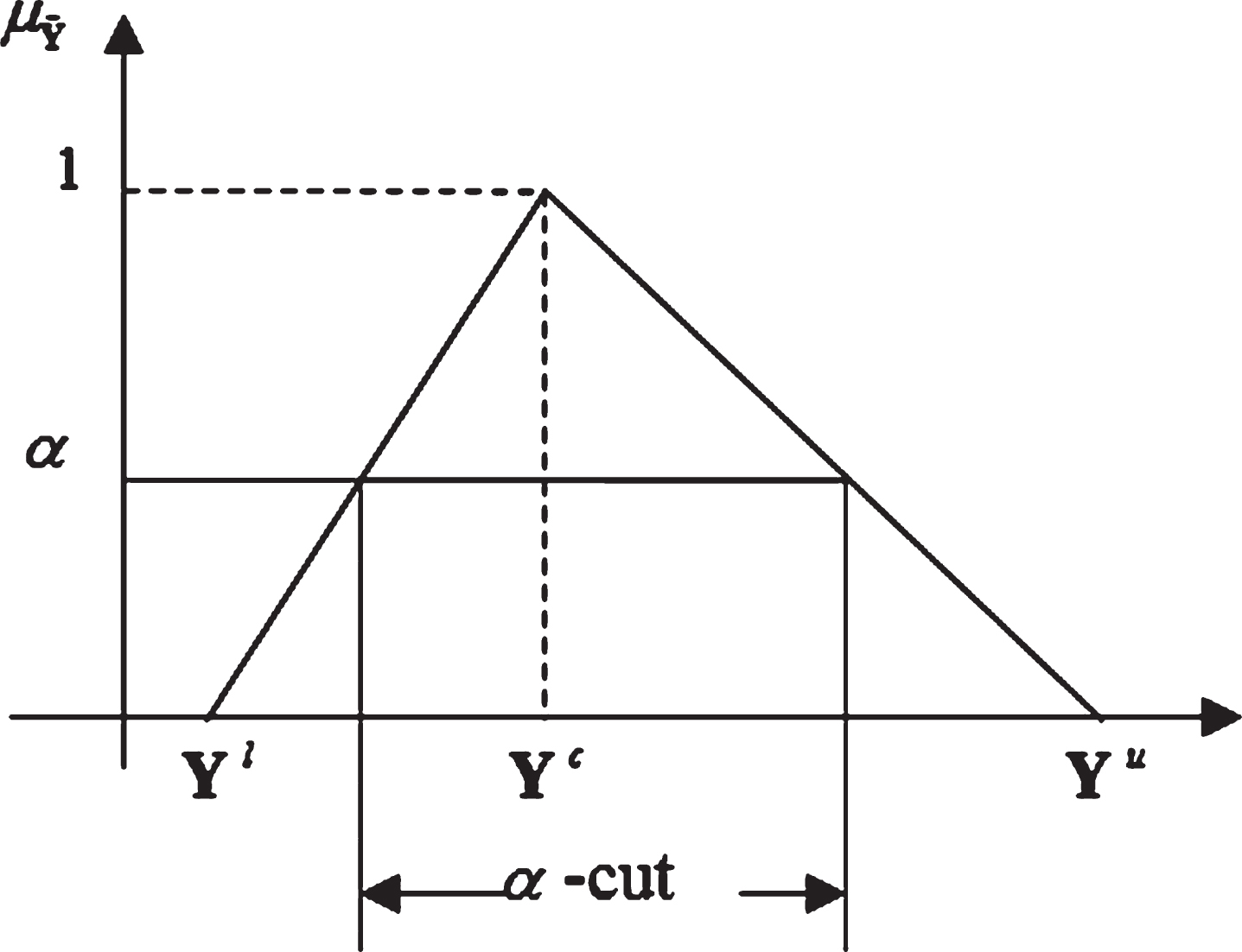
A triangular fuzzy response variable,
It is clear that the solution of the problem, given in Equation (7), is the LAD estimates of
In this section, MOO methodology is presented to optimize the problem, given in Equation (7). The NSGA-II, introduced by Deb [15], is preferred to use as a MOO tool since it has a capability of getting Pareto solution set which is composed of alternative solutions. The NSGA-II uses a fast non-dominated sorting mechanism and predefined tunable parameters which are population size (n pop ), crossover probability (Pr cr ), mutation probability (Pr mut ) and maximum number of generations (maxgen). The basic algorithmic steps of the NSGA-II can be seen in the study of Türkşen [23]. After obtaining the Pareto solution set, it is necessary to apply a MCDM approach to choose a compromise solution among many alternative solutions. For this purpose, TOPSIS method, presented by Chen and Hwang [30], is preferred to use as a MCDM method. It should be noted here that different compromise solution may be chosen at each run of the NSGA-II since the NSGA-II finds the Pareto solution set by using probabilistic rules in a random search process. From this perspective, in this study, it is suggested to use fuzzy knowledge at decision making stage. It is achieved by applying FCM clustering algorithm, presented by Bezdek [12], with the predefined number of NSGA-II runs. Here, running number of NSGA-II corresponds to the size of compromise solutions set, denoted as ncs. The composed compromise solution set is clustered according to the α-cut values by using the FCM clustering algorithm. The brief algorithmic steps of the FCM can be seen in the study of Türkşen [23], Türkşen and Güler [24]. Here, the number of clusters is chosen equal to three because of possible basic decision scenarios for objective functions f1 and f2, e.g. f1 ≺ f2, f2 ≺ f1 and f1 ≅ f2. It is assumed that the objective functions have equal importance. So, the median of the non-dominated solutions, which belong to the equal importance cluster, are considered as interval estimates of the model parameters. The proposed interval estimation procedure for fuzzy response valued data set is summarized as below:
Step 1. Define a proper nonlinear regression function for the replicated response measured data set.
Step 2. Create a FNR function by using α-cuts of triangular fuzzy response and triangular fuzzy model parameters.
Step 3. Compose MOO problem as given in Equation (7).
Step 4. Define the size of compromise solution set, ncs, and initialize the tunable parameters of the NSGA-II.
Step 5. Apply the NSGA-II to the problem composed in Step 3.
Step 6. Choose a compromise solution, considering that the two objectives have equal importance, by using TOPSIS method. Set ncs = ncs+1.
Step 7. If the ncs is not reached, go to Step 5, else go to Step 8.
Step 8. Define the cluster numbers, taken to be three, and compute the clusters according to the predicted α-cut values by using FCM clustering algorithm.
Step 9. Choose the equal importance cluster and calculate the median of the estimates of the bounds.
Application
In this section, a hypothetical and a real data sets were used to illustrate the suggested fuzzy α-cut based interval estimation procedure for nonlinear regression model parameters. The hypothetical data set was studied by Duncan [8] and the real data, called nitrite utilization data set, can be seen in the study of Bates and Watts [6]. Throughout the work, the calculations for interval estimation procedure were conducted in MatLab R2013a.
Example 1. (Hypothetical data set) The hypothetical data set includes a response variable (Y) and an input variable (X) with six-point design. The response variable was replicated four times at each design points. The hypothetical data set is given in Table 3.
The hypothetical data set [8]
The hypothetical data set [8]
The plotted data set is presented in Fig. 2. It can be easily seen from Fig. 2 that the functional relationship between input and response variables is not linear.
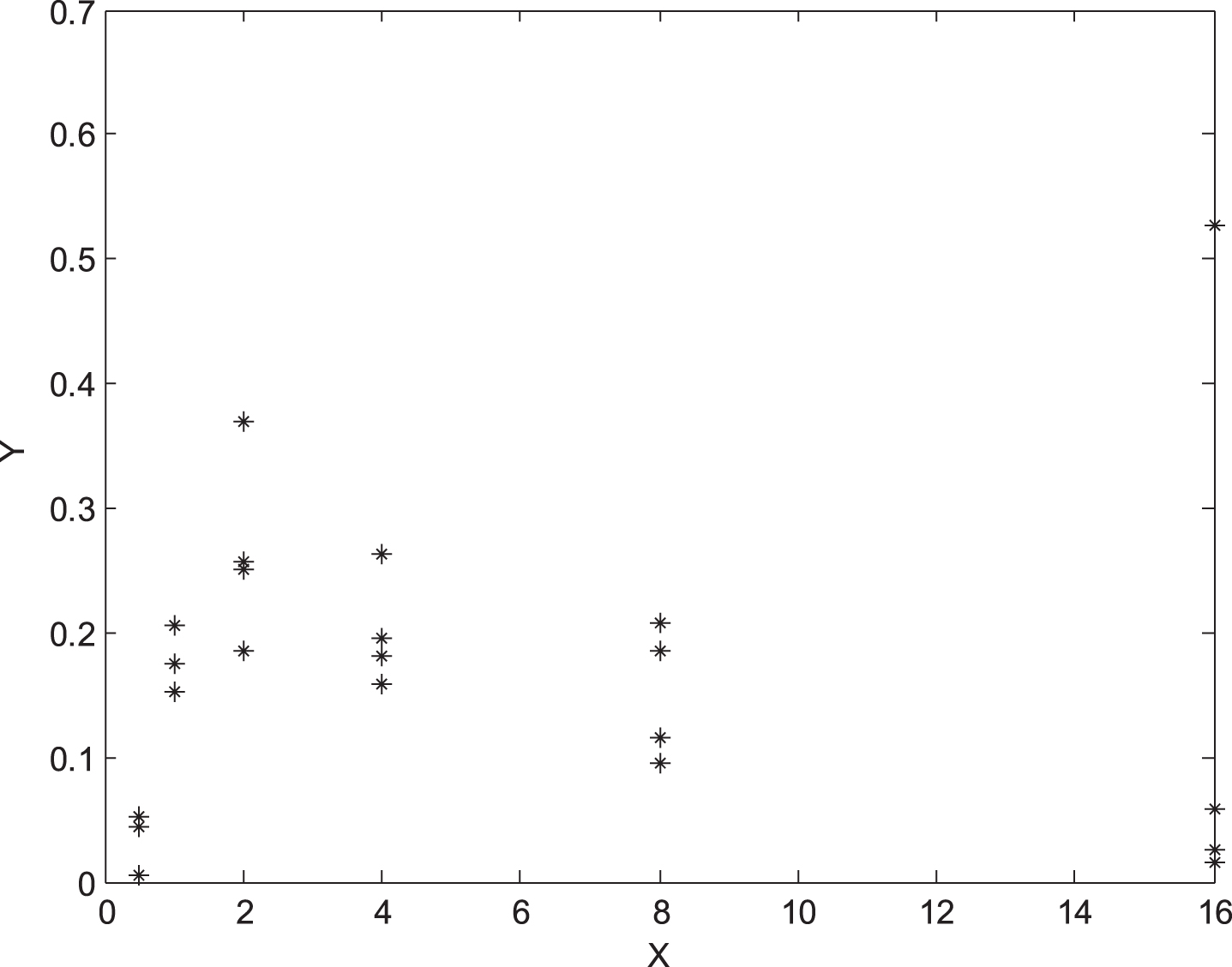
Plot of hypothetical data set input vs. response.
The appropriate nonlinear model is assumed as a first order chemical reaction function similar to study of Duncan [8]. Under certain conditions, the nonlinear regression model can be written as
Interval estimates of parameters [8]
It can be easily seen from Table 4 that the interval estimates of conventional and jackknife procedures are quite close for the 5% nominal significance level and also both intervals cover the point estimates,
In order to create the FNR function, the data set, given in Table 3, is transformed to fuzzy response valued data set by using the minimum, median and maximum statistics of the replicated response measures. The fuzzified data set is given in Table 5.
The hypothetical data set with fuzzy response
The Equation (8) can be written according to the α-cuts of parameters and response as below:
By using the basic α-cut arithmetic operations, the Equation (9) is rewritten explicitly as following calculations, given in two-part,
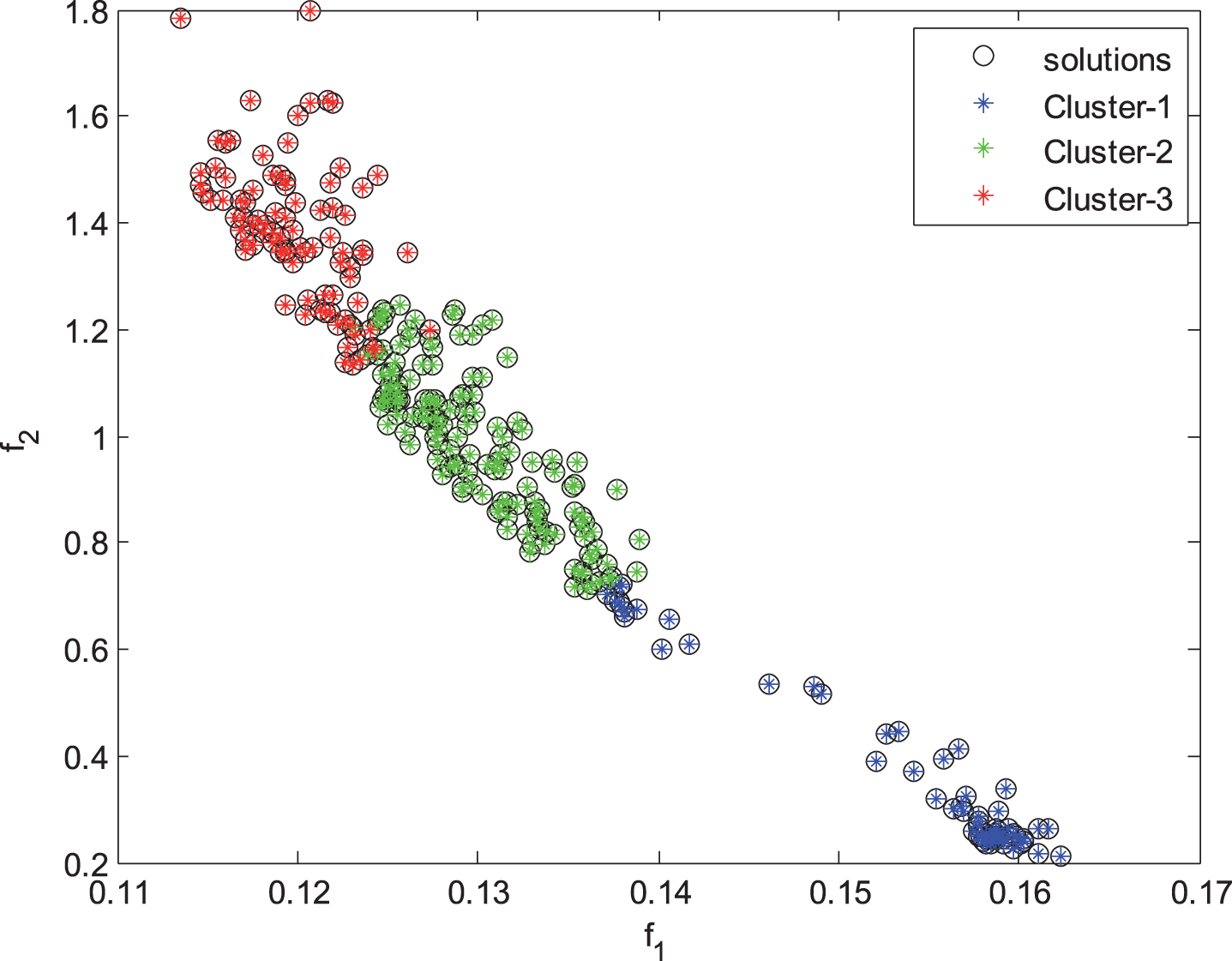
The clustered non-dominated parameter estimates.
According to the proposed multi-objective model, given in Equation (7), the objective functions are formed as
It is clear from the Equations (12)-(13) that the objective functions are composed based on LAD metric. Thus, the MOO problem is described as
To obtain the interval estimates of model parameters, the multi-objective constrained model, given in Equation (14), is solved by using the NSGA-II
with the initialized tunable parameters as n pop = 70, Pr cr = 0.90, Pr mut = 0.01, and maxgen = 50. The NSGA-II is runned maxgen times and at the end of 50 generations, Pareto solution set, sized 70, is obtained. The compromise solution set is composed by applying TOPSIS method to the Pareto set. The size of compromise solution set (ncs) is chosen equal to 300. Then, the FCM clustering algorithm is used to compute the interval estimate clusters according to the predicted α-cut values. The obtained clusters for non-dominated parameter estimates are presented in Fig. 3. It can be said from Fig. 3 that the Cluster-2 is the most preferable one according to the assumption of equal importance for f1 and f2.
The predicted α-cut values are given according to the interval parameter estimates of clusters in Fig. 4. From Fig. 4, it is possible to categorize the predicted α-cut values as [0.05– 0.4], [0.4– 0.75], and [0.75– 0.99] for Cluster-3, Cluster-2, and Cluster-1, respectively. The predicted α-cut values which are between 0.4 and 0.75 are more reasonable since the Cluster-2 is preferred. The box-plots of calculated interval estimates are presented for each cluster in Fig. 5.
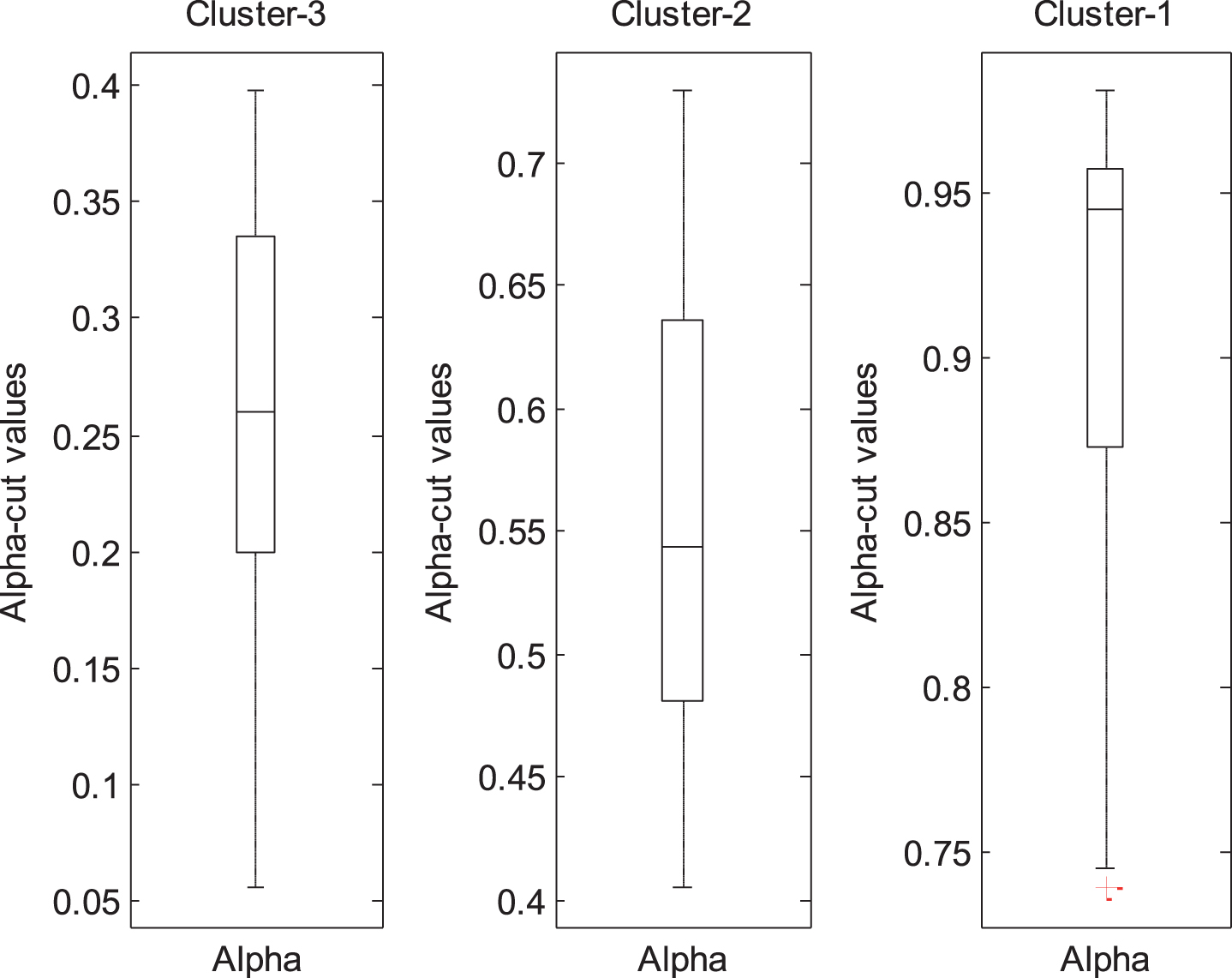
The predicted α-cut values according to the clusters.
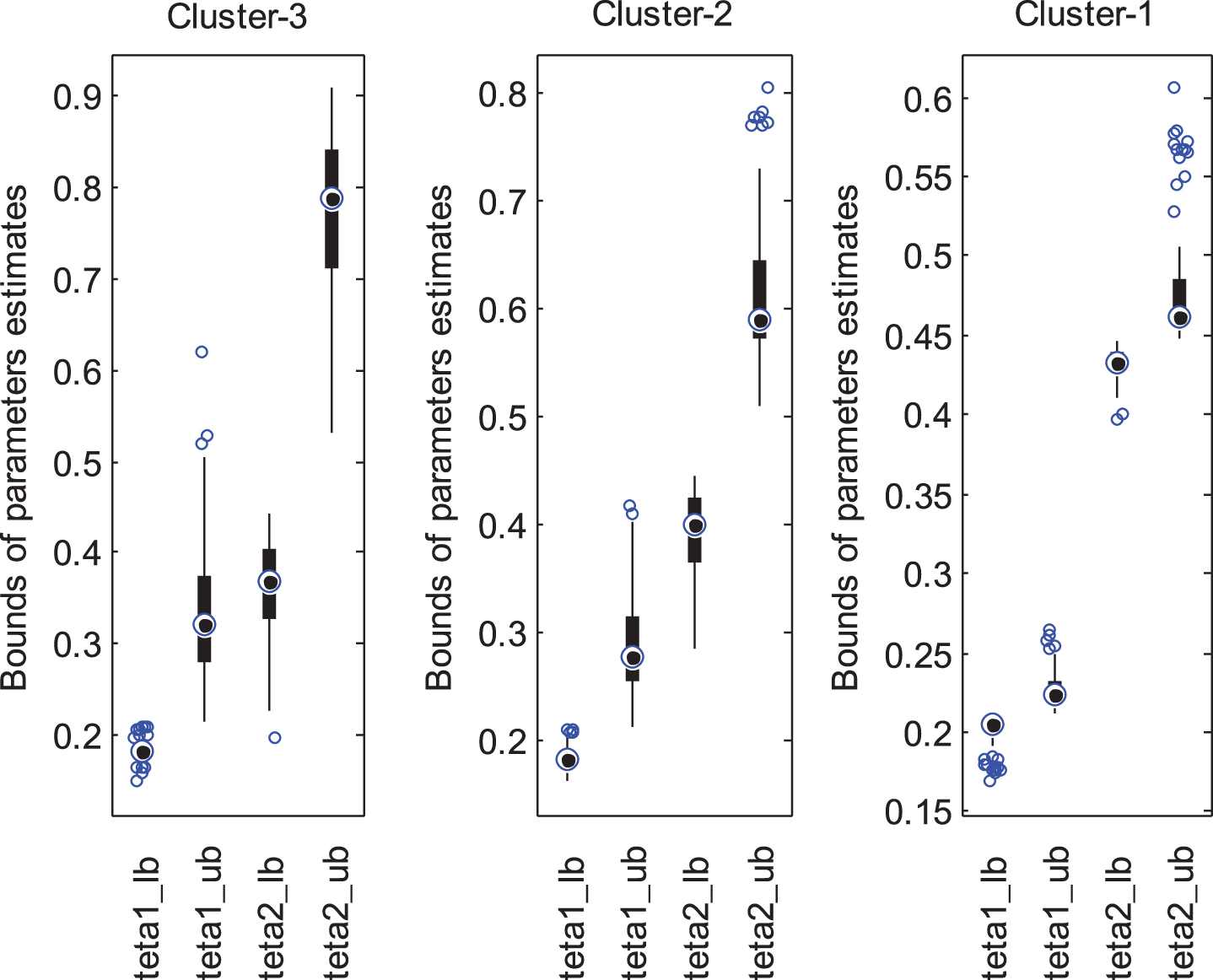
Box-plots for the interval estimates of parameters according to the clusters.
It is possible to say from Fig. 5 that if predicted α-cut values to close 0 in the range of interval estimates gets larger, if predicted α-cut values to close 1 in the range of interval estimates gets narrower. The obtained interval estimates of Cluster-2 are more reasonably acceptable since the objective functions have equal importance. The median of the interval estimates are [0.1829, 0.2781] and [0.4009, 0.5894] for θ1 and θ2, respectively. It can be said that these interval estimates also cover the point estimates and can be considered as an alternative interval estimates of parameters. Furthermore, the interval estimates of first parameter is narrower than the obtained interval estimates which are given in Table 4.
Example 2. (Nitrit utilization data set) The utilization of nitrite in bush beans as a function of light intensity is considered as a real data set to illustrate the proposed interval estimation approach. In the data set, the portions of primary leaves from three 16-day-old bean plants were subjected to eight levels of light intensity (μE/m2s), and the nitrite utilization (nmol/g hr) was measured on two days. The detailed information about the experiment is given in the study of Bates and Watts [6]. Here, the nitrite utilization and the light intensity are considered as the response variable and the input variable, respectively. The experimental results with three replicated response measures for each day are given in Table 6.
The replicated measured data set for nitrite utilization versus light intensity [6]
In order to understand the functional relationship between the utilization of nitrite in bush beans and the light intensity, plot of replicated nitrite utilization measures versus light intensity is presented in Fig. 6. It can be seen from the Fig. 6 that the nitrite utilization amounts have nonlinear trend considering all the light intensities.
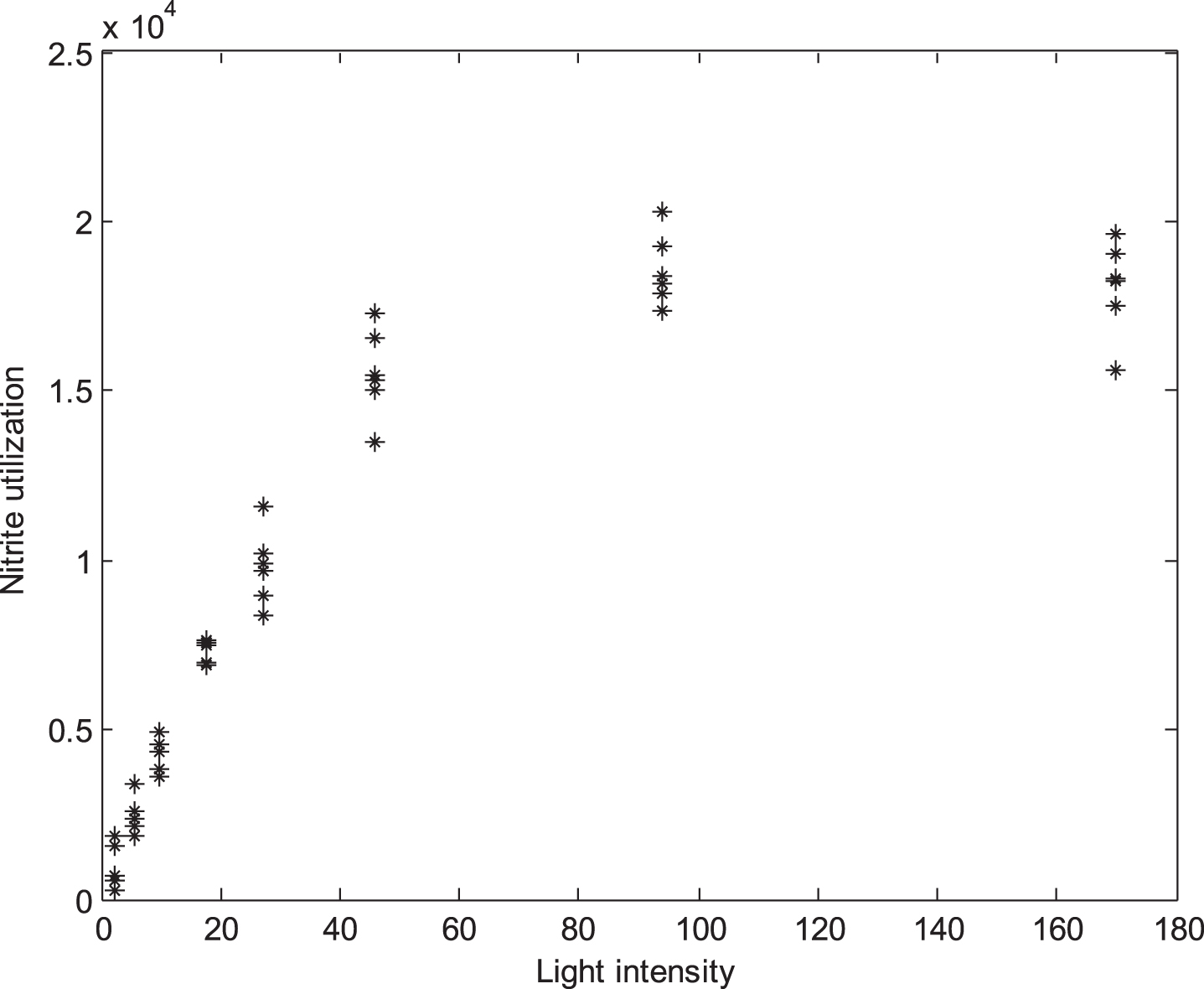
Plot of nitrite utilization data set input vs. response.
According to the behavior of the replicated response measured data, the appropriate nonlinear model is preferred as Michaelis-Menten model, which met the researcher’s beliefs about nitrite utilization and light intensity, given below
It is possible to rewrite Equation (15) according to the α-cuts of parameters and response
The data set with fuzzy valued nitrite utilization versus light intensity
The Equation (16) can be written explicitly by using α-cut arithmetic operations as below:
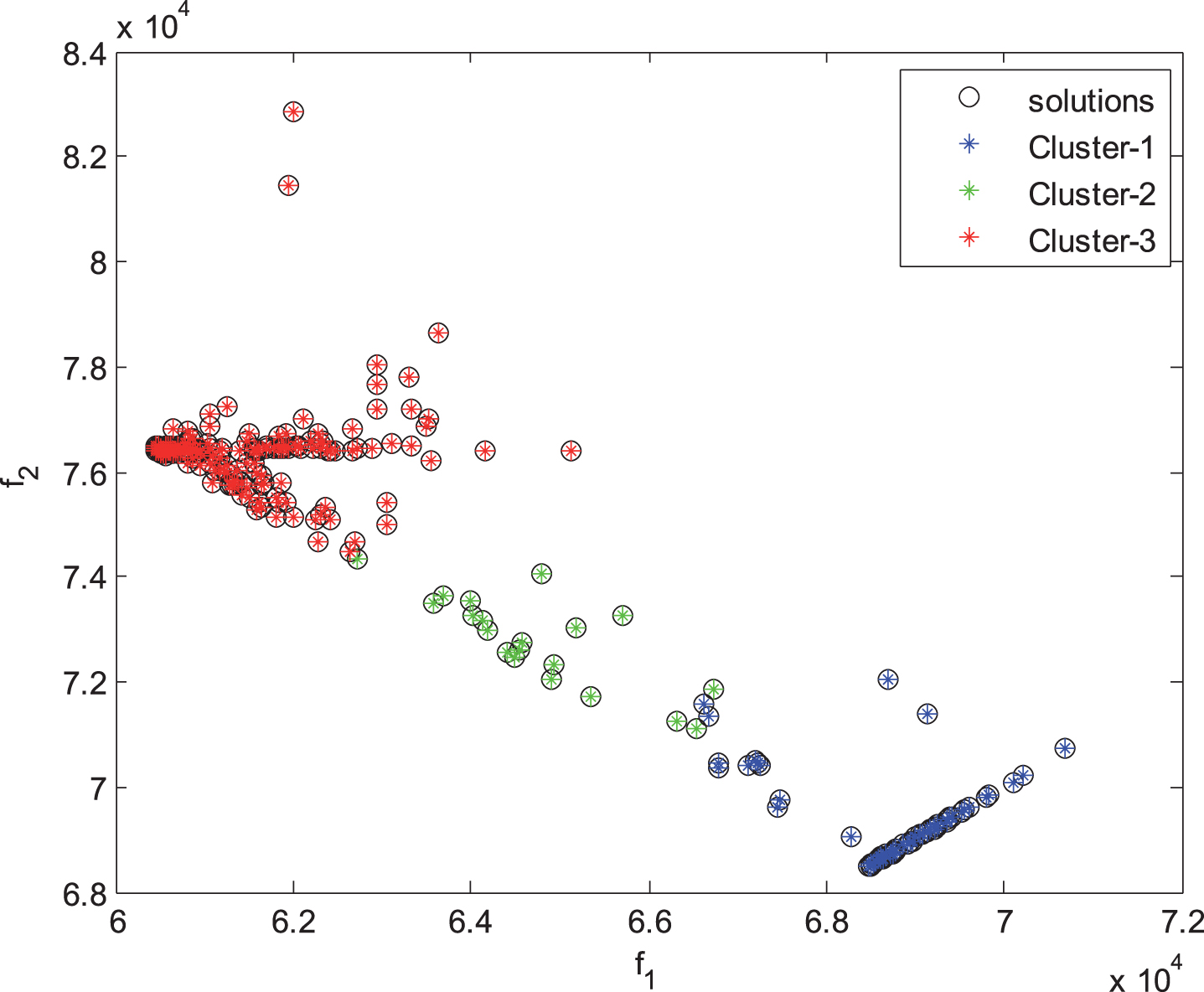
The clustered non-dominated parameter estimates.
The predicted α-cut values are given according to the interval parameter estimates of clusters in Fig. 8. From Fig. 8, it is possible to categorize the predicted α-cut values as [0.75–1], [0.25– 0.75], and [0– 0.25] for Cluster-1, Cluster-2, and Cluster-3, respectively.
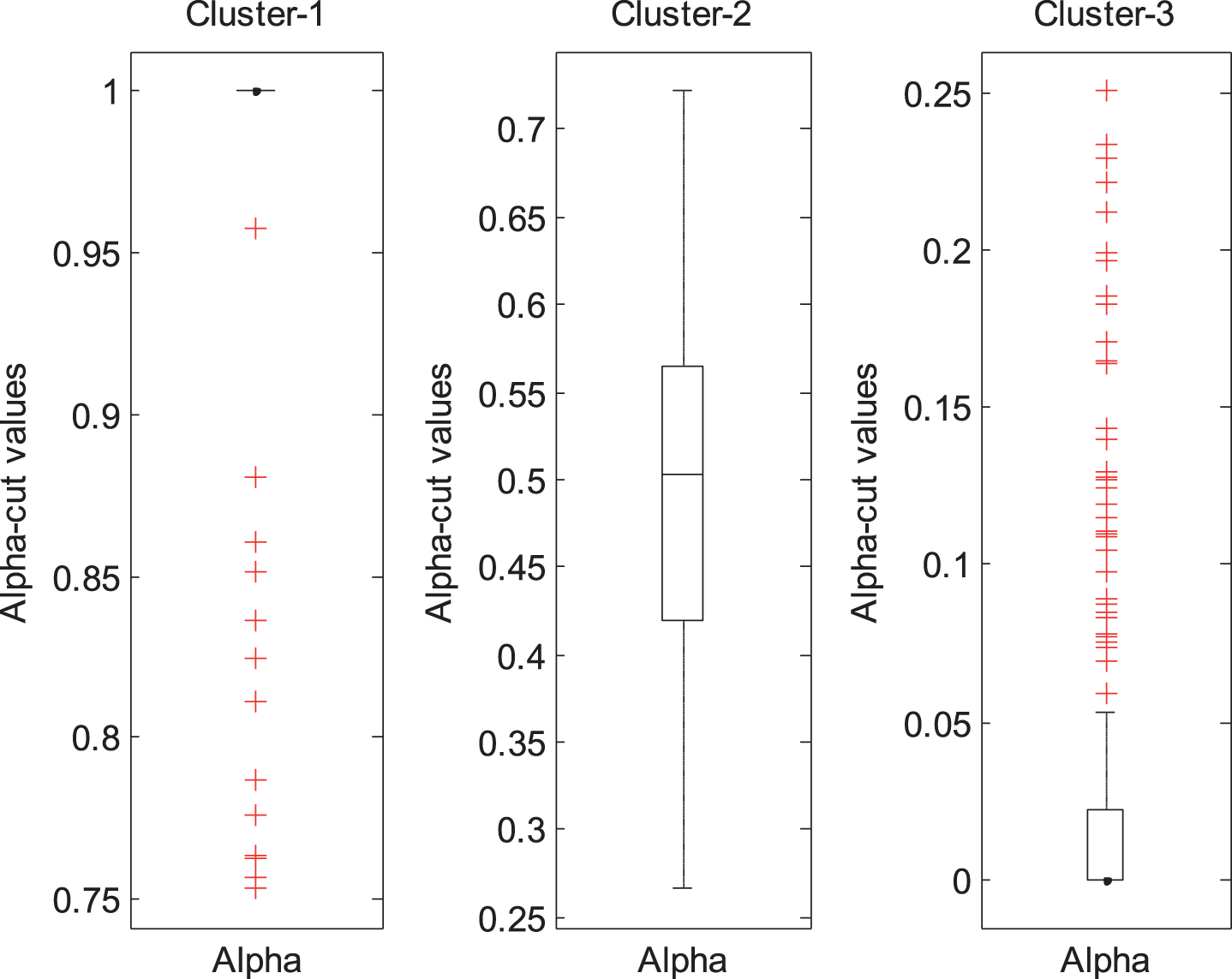
The predicted α-cut values according to the clusters.
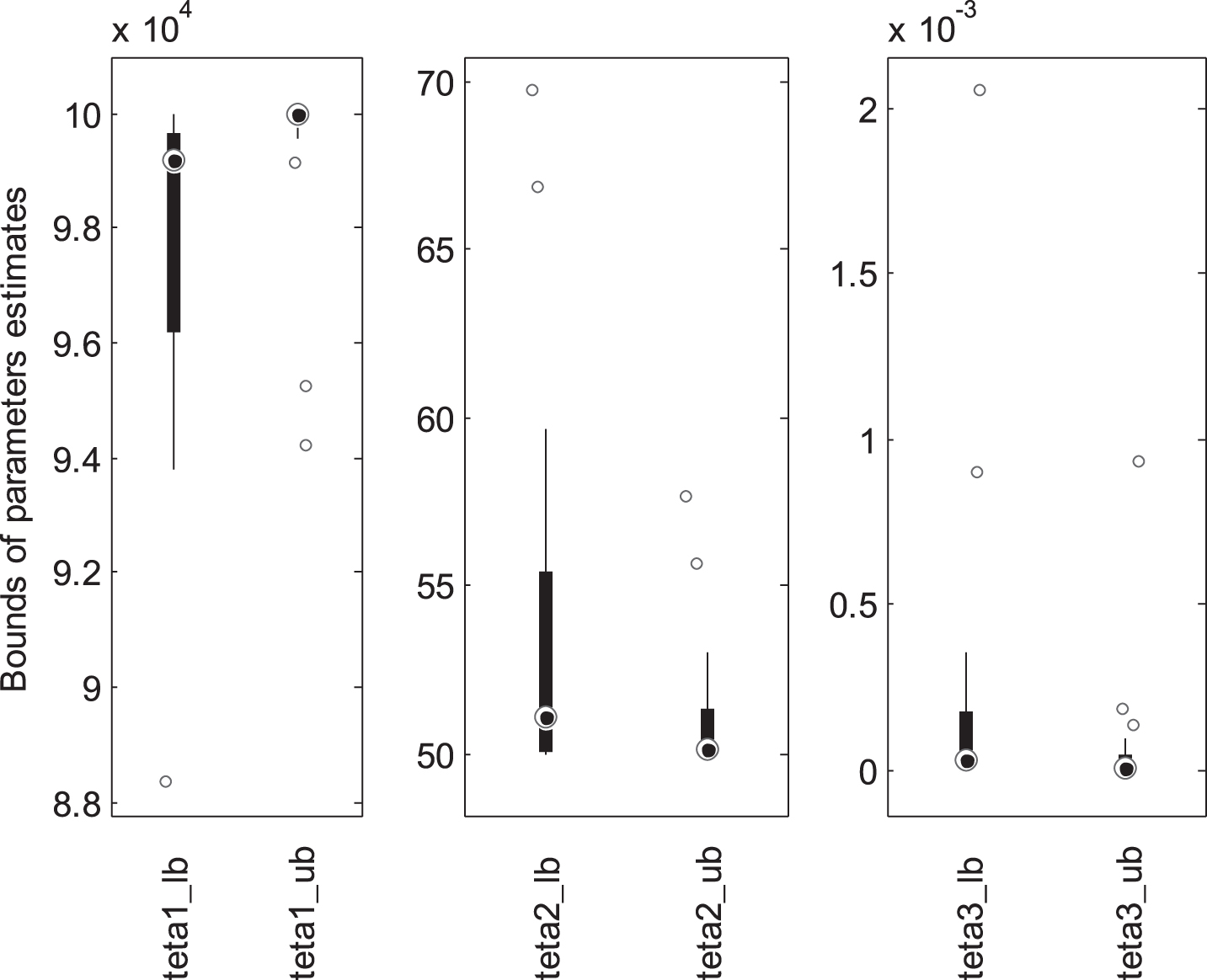
Box-plots for the interval estimates of parameters according to the clusters.
The predicted α-cut values which are between 0.25 and 0.75 are more reasonable since the Cluster-2 is preferred (Fig. 8). In Fig. 9, the box-plots of calculated interval estimates are presented. The median of the interval estimates are obtained as [97093, 99896], [50.01, 50.02] and [0.001, 0.002] for θ1, θ2 and θ3, respectively. The interval estimates can be considered as a soft computing based interval estimates.
This paper presents a flexible interval estimation approach for nonlinear regression model parameters by using α-cut operation of fuzzy numbers without using any probabilistic assumptions. The obtained interval estimates show that the proposed interval estimation approach, which is based on combination of soft computing tools, e.g. fuzzy α-cut, NSGA-II, TOPSIS and FCM, can be used as an alternative interval estimation procedure. It is seen from the results of hypothetical data set that the proposed approach gives similar interval estimates which are previously obtained by using conventional and Jackknife procedures. In order to obtain more reasonable interval estimates of model parameters, MOO, MCDM and clustering tools can be improved for future work.
Footnotes
Acknowledgments
The author thanks to Dr. Nilüfer Vural (Ankara University, Chemical Engineering Department) for her valuable contributions, helpful suggestions and enjoyable discussion.