
Abstract
HAUIM (High Average-Utility Itemset Mining) is a variation of HUIM (High-Utility Itemset Mining) that provides a reliable measure to reveal utility patterns in light of the length of the mined pattern. Several works have been studied to improve mining efficiency by designing multiple pruning strategies and efficient frameworks, but fewer studies have centered on the sophisticated database maintenance algorithm. Existing works still have to rescan the databases multiple times when it is necessary. We first use the pre-large principle in this paper to efficiently update the newly discovered HAUIs. For further updates and maintenance on the basis of the two thresholds, the Pre-large Average Utility Itemset (PAUI) can be maintained to increase the mining performance. Experiments will then be performed to compare the batch model, the Fast-Updated (FUP)-based model, and the Apriori-like HAUIM (APHAUIM) model designed in respect of the number of maintenance patterns, scalability, runtime, and memory usage.
Keywords
Introduction
Knoweldge Discovery in Database (KDD) [1, 44] is an efficient way to reveal the relationships of the itemsets in database. KDD methodology can, of course, also be applied in many different applications but the security [6, 45], and optimization [40, 41] are the major considerations during the KDD progress, which has also been an emerging topic in recent decades. Association rule mining (ARM) [1] is the first algorithm for identifying frequent itemsets (FIs) on the basis of minimum support and then generating association rules (ARs) with another threshold of minimum confidence. The first Apriori method utilizes the generate-and-test approach for mining ARs by a level-wise process. Based on the Apriori algorithm [1], the downward closure (DC) property can thus be maintained; the numerous unpromising candidates can be ignored. FP-tree and FP-growth mining approach [11] were presented to efficiently discover the set of FIs to accelerate the mining performance. Many extensions provided the information needed in different domain knowledge, like HUIM or HAUIM, based on the Apriori-like (or DC) property. Furthermore, existing algorithms are mainly focused on handling the static database; when the volume of a database is modified, for instance, transaction insertion, the revealed knowledge becomes useless and the batch model is then processed to handle the entire database to retrieve the requiredinformation.
In ARM, it only considers the binary database, but the other meaningful information and factors, for example, the quantity, interestingness, importantness, or weight are not considered in ARM. However, those information can reveal better knowledge for decision-making. High-utility itemset mining (HUIM) [10, 36] has been considered as an effective way for decision-making to show profitable products and itemsets. The quantity and utility of the itemsets are concerned for determining HUIs. An item is called a HUI when its utility exceeds the predefined minimum utility threshold. Since traditional HUIM cannot hold the DC property, the search space for the desired patterns is enormous. To overcome this problem, Liu et al. implemented a TWU (transaction-weighted utilization) model [17] to retain the TWDC (transaction-weighted Downward Closure) property. Therefore, it can further reduce the search space for revealing HUIs. It first finds HTWUIs in which each itemset retains the upper bound utility value on the pattern, thereby ensuring the TWDC property for the correctness and completeness. Nonetheless, the TWU model relies on the generate-and-test approach; thus vast numbers of candidates can, therefore, be produced and evaluated. In order to solve this limitation, by maintaining the promising 1-itemsets in the tree structure, a high-utility pattern (HUP)-tree [3] was thus proposed by Lin et al. to decrease computational costs considerably. The UP-growth+ approach [33] was proposed with the UP-tree structure to reveal the HUIs efficiently. Liu et al. [23] then presented a new utility-list (UL) to extract the k-HUIs easily based on the join operation. Several previous methods [24, 38] have been extensively studied and discussed, and most of them focused on the TWU model toreveal HUIs.
Even if HUIM can find more information to make decisions, it still fails to restrict the eruption of the utility, mainly when the size of the pattern is very long. For example, any combinations with caviar can also be regarded as a HUI in a supermarket that is not realistic in the real situation. HAUIM (High average-utility itemset mining) [15] was investigated to use a average measure for evaluating high utility patterns to detect the itemsets with high average-utility regarding the length of an itemset. An itemset is stated to be a HAUI, while the value of utility divides the length of the itemsets (or referred to as the average utility of the element set) is larger than minimum utility threshold (count). This approach offers another way to fair estimate the pattern utility. Hong et al. developed the TPAU algorithm [15] in a level-wise way to reveal the required HAUIs. This approach applies the auub (average-utility upper bound) to hold downward closure property in order to discover the HAUUBIs (high average-utility-upper-bound itemsets). Lin et al. proposed the high average utility pattern (HAUP)-tree structure [21] to maintain the 1-HAUUBIs in the compressed tree structure in order to improve mining performance. An AU-list (average-utility-list) structure was also proposed through simple the join operation to generate the k-itemsets. Numerous extensions of HAUIM [28, 29] have also been explored and discussed in order to enhance the efficiency ofknowledge discovery.
The bulk of the current HUIM or HAUIM algorithms were built on the maintenance of the static database, but the storage sizes have changed dynamically in realistic situations. The traditional way of dealing with the dynamic situation is to update the discovered knowledge in a batch manner, which wastes past computational costs and information that was discovered. Before, the Fast Updated (FUP) concept [4] was developed to manage the complex situation of incremental mining, used in various fields and applications such as association rule mining [19], sequential mining pattern [18], HUIM (high-utility itemset mining) [2, 20], and HAUIM (high average-utility itemset mining) [30]. However, the FUP-based HAUIM still has to rescan the database for acquiring the up-to-date information. In this article, we first utilize the pre-large concept [19] for efficiently handling the incremental mining while some transactions are inserted. Some contributions of the developed algorithm are described below. The pre-large Apriori-based APHAUI is first designed for transaction insertion, which is used to update the found information effectively in the progress of maintenance. A new principle called PAUUBI (pre-large average-utility upper-bound itemset) is described here to preserve the potential HAUBI that acts as a buffer to minimize rescanning processes by checking a small itemest being a large itemset and vice-versa. An equation is specified here to ensure that an additional database scan is unnecessarily performed. However, the up-to-date HAUIs can still maintained in terms of completeness and correctness. Several experiments have been validated to show that the proposed APHAUI is effective and presents much superior performance compared to the FUP-based algorithm, in terms of runtime and number of candidates for pattern evaluation.
Literature review
In this section, we have examined the works relevant to HAUIM and dynamic data mining.
High average-utility itemset mining
The traditional ARM (association rule mining) algorithm [1] finds the relationships of the itemsets based upon two minimum thresholds to identify the ARs (association rules), and the original algorithm is called Apriori [1]. However, the Apriori can only handle the binary database; thus, the other impacts such as weight, interestingness, importantness, and quantity are ignored in ARM. In order to find more meaningful information from the discovered of knowledge, HUIM (high-utility itemset mining) [3] was presented to involve two factors, including the unit profit and the quantity of an item to find the beneficial information from the database. An itemset is known as a HUI (high utility itemset) if the utility on the itemset is not smaller than the pre-defined minimum utility threshold (count). Traditional HUIM fails a problem of the combinational explosion; thus, the search space is enormous to find the required HUIs. Moreover, the TWU model [17] was proposed to hold the downward closure property by preserving HTWUIs (high transaction-weighted utilization itemsets). HTWUIs contain the upper-bound utility on the itemset, and therefore the Transaction-weighted Downward Closure (TWDC) property is maintained for the correctness and completeness of the HUIs discovered. Lin et al. then proposed a HUP-tree (high-utility pattern tree) [22] to establish a compact tree structure by maintaining the 1-HTWUIs, which reduces the computational cost compared to the level-wise approach. Moreover, the utility pattern (UP)-growth+ [33] was proposed to apply the UP-tree structure and several pruning strategies were presented to accelerate the mining efficiency. Besides, a utility-list (UL)-structure and the HUI-Miner algorithm [21] were designed to generate the k-candidate HUIs easily through a straightforward join operation. Several HUIM algorithms [23, 38] have been discussed extensively, and most of them focused on the TWU model in order to reduce the number of candidates and discover the set of HUIs.
In the process of HUIM, the value of utility arises under the length of an itemset. Therefore, any composite elements with the caviar or diamond are called a HUI in a database, which is not reasonable in the real applications, especially if a transaction is with many items. HAUIM (high average-utility itemset mining) [15, 21] was extended from HUIM regarding the length of the itemset for pattern evaluation. The first algorithm in HAUIM was TPAU [15] that uses the Apriori approach in the auub (average-utility upper-bound) model for keeping the downward closure property. Lin et al. presented a HAUP-tree [21] to keep the 1-itemsets in a compressed tree structure, thereby significantly reducing the computational cost. Several extensions of HAUIM [25, 28–30] were respectively studied and most of them rely on the auub model to find the set of HAUIs.
Dynamic data mining
For the traditional pattern mining, including association rule mining (ARM) [1], high-utility itemset mining (HUIM) [16, 36] and sequential pattern mining [9], they only focused on mining the meaningful patterns from the static databases. In case of changing the size of the database, such as insertion, deletion, or modification, the batch model algorithms, even if a small change (i.e., tiny transactions 1-5 are inserted into the database) have to process the entirely updated database. This is very cost progress since the discovered knowledge at the previous stage cannot be re-used, and the database is needed for multiple database scans to obtain the updated information.
Cheung et al. therefore developed the Fast UPdate (FUP) concept [4] in order to handle the dynamic data mining for transaction insertion to maintain the frequent itemsets that were discovered. With regard to the original database and the inserted transactions, the found information can be grouped into four parts, and each part is then maintained and processed using the designed approaches. This concept has been utilized into different domains for knowledge discovery, such as ARM [12], sequential pattern mining [18], HUIM [20], and HAUIM [14]. Although the FUP-based approach can handle dynamic data mining, it still needs to rescan the database in some cases, which is still inefficient for knowledge maintenance.
To better maintain the discovered knowledge and avoid the multiple database scans, Hong et al. developed the pre-large concept [13, 19], which is used to set up two thresholds for knowledge maintenance. These two thresholds (upper and lower) are then used to maintain the large itemsets (the pattern count is no less than the default upper threshold / count), and the pre-large itemsets (the pattern count is between the upper and lower thresholds / counts). Thus, the pre-large itemsets will be retained in the buffer to avoid the multiple unnecessary rescanning of the patterns from large itemsets to small itemsets and vice-versa. An equation is also defined to determine while the number of the newly inserted transactions is less than the safety bound, some cases for database rescans can be avoided, but the completeness and correctness of the discovered knowledge can still be maintained. The summary of the pre-large concept can be seen in Fig. 1.
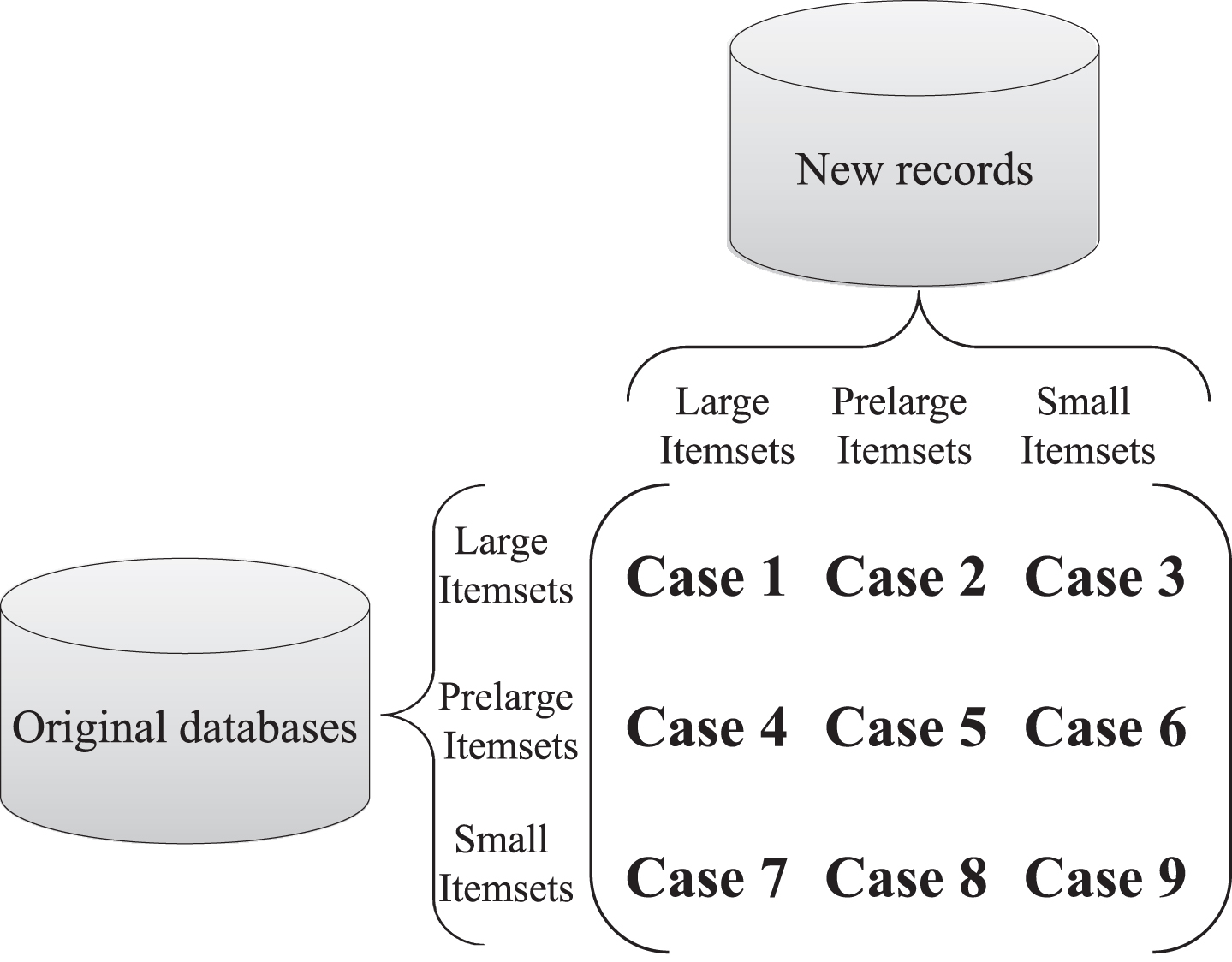
Nine cases of the pre-large concept.
The final results cannot be affected under cases 1, 5, 6, 8, and 9. However, the number of discovered knowledge can be reduced for cases 2 and 3, and some new knowledge may be discovered for cases 4 and 7. As the pre-large itemsets are maintained, it is easy to handle the itemsets for cases 2, 3, and 4. The safety bound (f) used in the pre-large principle is defined below.
Assume D consists of n transactions such that D = {T1, T2, …, T n }, and d represents as a set of new transactions. Every transaction T q in D or d consists of several distinct items such that T q = {i1, i2, …, i k }, and I is set as the collection of all items appearing in D and d such that I = {i1, i2, …, i m }. Thus, we can have that i j ∈ I, and T q ⊆ D or T q ⊆ d. A profit table is defined as utable = {p (i1), p (i2), …, p (i m )}, which shows the profit values of the items in the database. An upper bound utility threshold is defined as S u , and the lower bound utility threshold is set as S l . Both of two values would be set by user’s preference. The definitions can be given below.
The auub model [15] was designed to overestimate the utility value of itemsets in order to obtain the downward closure property for the early pruning of possible itemsets. This process ensures that the itemsets discovered are correct and comprehensive, as well as the following definitions.
Hence, if TU D × S u ≥ auub (X) D then TU D × S u ≥ auub (X) D ≥ auub (Y) D is satified for any superset of X.
For the transaction insertion in the dynamic database, we can assume that d is the inserted transactions, and |d| is the quantity of transactions in d. The issue of incremental HAUIM for transaction insertion is as follows:
In the past, a transaction insertion was carried out using the FUP-based method [4] to maintain the discovered HAUIs in HAUIM. In order to update the discovered HAUIs, the original database also requires multiple database scans. In this article, we use the pre-large concept [13, 19] to maintain the discovered HAUIs, and to prevent multiple database scans when a small number of transactions is added into the database. This model splits the original database and the inserted transactions into nine parts based on two utility thresholds (upper and lower) and each part will be handled by the developed approach. In Algorithm 1, the details of the designed algorithm are given.

The safety bound (f) of the designed algorithm is set below to decide if a database must be scanned.
Therefore, if the TU for new transactions is less than the safety bound (f), any itemset in the case 7 has no possibility to be a HAUBI after the new database has been inserted (TU d ). Numerous database scans could, therefore, be avoided, but the completeness and correctness of HAUIs for transaction insertion can be maintained and updated.
After the set of HAUBI D has been updated, it will then search the database again to find the actual average-utilities of the candidates, and it will, therefore, keep the final set of HAUIs.
The experiments are going to compare with the designed APHAUP to the FUP-based HAUIM algorithm [14] in two different actual datasets [8]. In Figs 2 to 3, the results are shown respectively. All algorithms are built in Java language and running in MacOS Mojave operating system with 2.7 GHz CPU and 8 GB DDR3 main memory. There are two sections of the experimental results, first the runtime of the developed algorithm compare to the FUP-based algorithm, and then the number of candidates for the proposed method compared to the FUP-based algorithm, respectively.
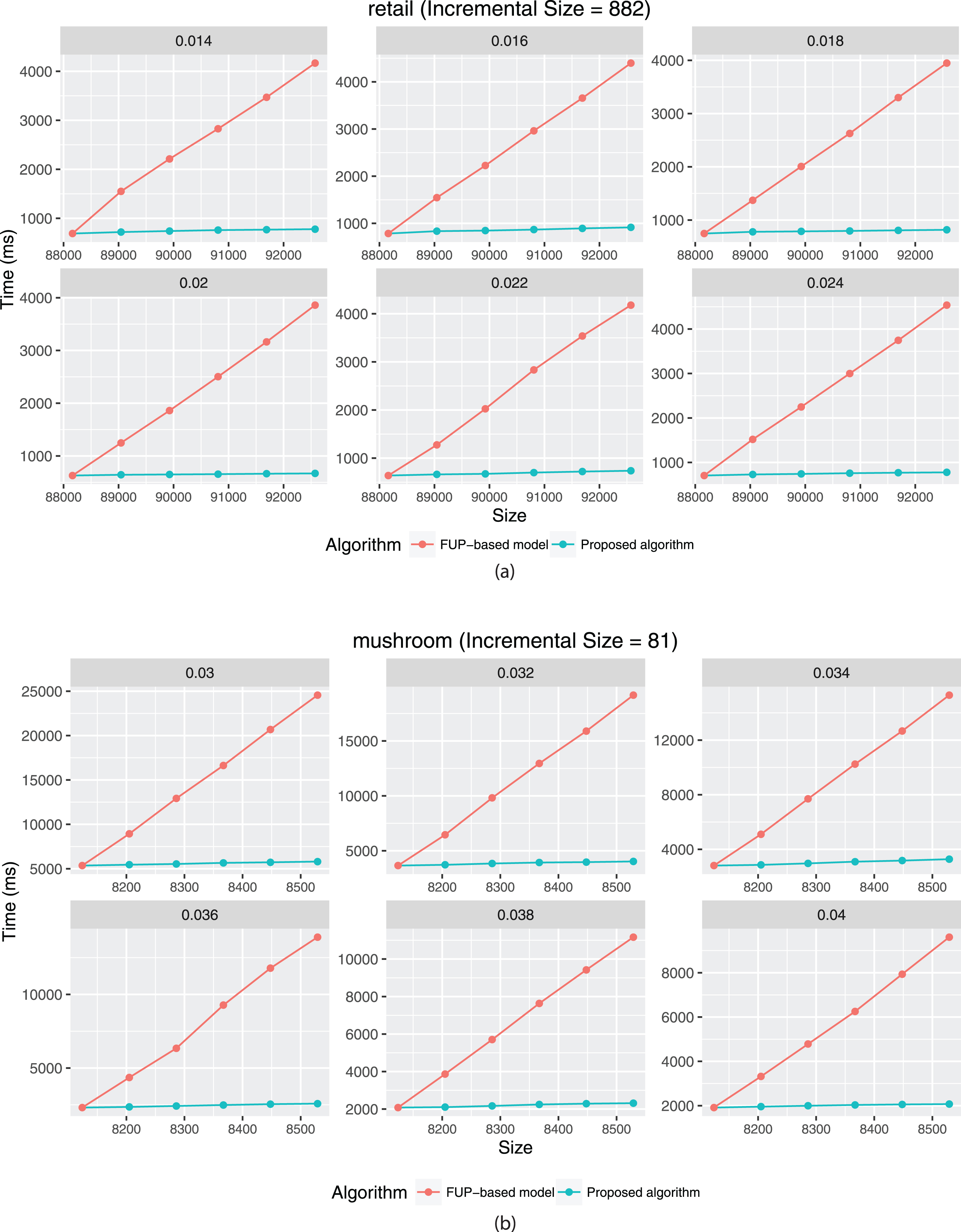
The compared runtimes under varied thresholds.
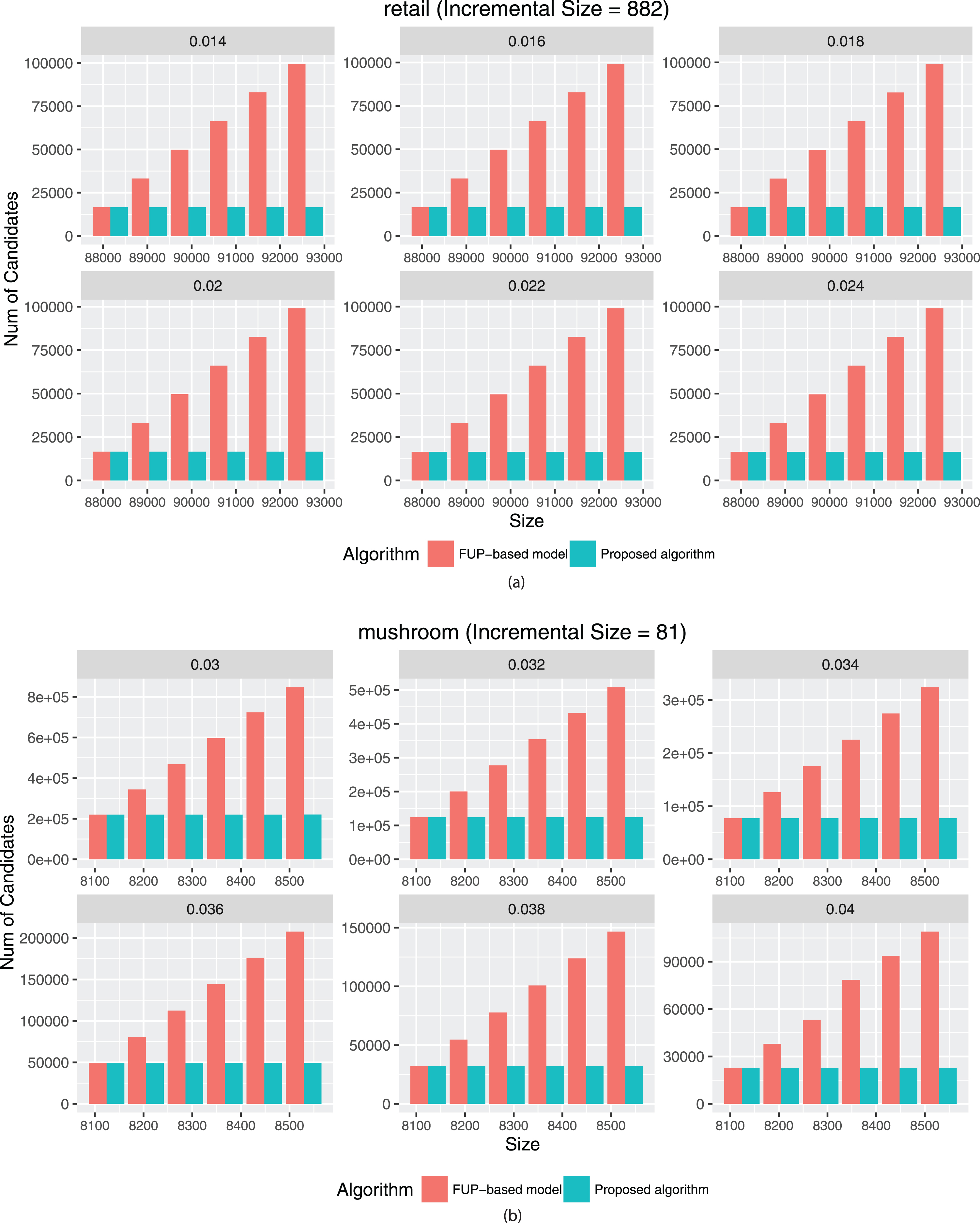
The number of the compared candidates under varied thresholds.
From the experiments conducted in Fig. 2 under various minimum utility thresholds, we notice that the designed algorithm has the greatest performance than the FUP-based method. It is understandable because sometimes the FUP model needs to constantly re-scan the database, while some transactions are inserted into the database. It, therefore, requires high computational costs for database scanning, particularly when certain itemsets on case 3 are based on the FUP concept. Furthermore, the runtime of the designed approach is more stable compared to the FUP-based algorithm. This is also acceptable, because the designed algorithm can prevent multiple database scans to ensure that the discovered patterns are correct and complete. To sum up, we can obtain that the designed algorithm achieves better performance in maintaining the up-to-date HAUIs in dynamic databases for transaction insertion. It has to be noticed that the rescanning time of the developed approach is always larger than the traditional FUP-based algorithm. That is because the proposed algorithm needs to reveal more itemsets into the buffer in order to perform the updating process for the insertion progress. Therefore, setting asuitable threshold to obtain the pre-large itemsets is very important. If the safety bound is too small, it causes that the proposed algorithm needs to perform rescanning actions while some newly transactions are inserted into the original dataset. The performance will be worse than the traditional FUP-based model on the contrary.
Candidate comparisons
In the second part of the experimental results, the number of candidates in retail and mushroom is compared in Fig. 3. The definition of a candidate is an itemset that needs to be calculated for the utility value in the newly updated dataset. Obviously, due to the benefit of pre-large concept, few itemsets are needed to be checked for their utility values in the updated dataset. If the incremental dataset is smaller than the safety bound, the proposed approach does not have to check the utility values for all possible items in the updated dataset. Thus, all of the itemsets that need to be rescanned is a small part of all possible itemsets. Therefore, comparing with FUP-based model, the rescanning cost is not huge in the proposed algorithm. The designed model is suitable for the stream environment in a dynamic situation.
Conclusion
In this paper, we then design an incremental transaction insertion algorithm based on the pre-large concept of high average-utility itemset mining. The results of experiments showed that the developed model can significantly reduce the execution times for updating knowledge compared to the FUP-based approach. Furthermore, the number of determined candidates is much less than the FUP-based algorithm. The pre-large concept has already been showed that it has the potential ability to improve the performance for the traditional HAUIM approaches. We will try to apply the pre-large concept to more art-of stat HAUIM algorithms and compare them with the developed algorithm in this paper. On the other hand, we will also develop new upper-bound based on the pre-large concept in order to further enhance the mining performance in future works. In real-world situations, transaction deletion and modification are also significant. They should be considered to be efficiently maintained for knowledge updating, which will be explored and studied as our next research topics.
Footnotes
Acknowledgment
This paper is partially supported by the National Natural Science Foundation of China General Program under grant No. 61976126.