
Abstract
Time series is a classification of data series of variables, orderly arranged with respect to time. In time series analysis, forecasting is the vital area of study besides other meaningful characteristics of the data. It has vast application in decision-making and prediction in the domain of economics, agriculture, medicine, industries, energy sector and other sciences. Fuzzy time series emerged as a robust tool to cater for historical data in linguistic values. This paper proposes the new method of fuzzy time series forecasting based on the approach of fuzzy clustering and information granules integrated with the weighted average approach to deal with the uncertainty in data series. To distinguish the power of modeling and prediction, the strategies of Root Mean Squared Error (RMSE) and Mean Absolute Error (MAE) are utilized as a criterion. Findings illustrate that proposed fuzzy based time series approach is vigorous to compute the accurate estimates.
Introduction
In practice consistent performance analysis, few would be contended about the need and significance of prediction as policy makers are concerned in assessing the future events of system disaster for the capital planning, stock management, creating reasonable opportunities for age substitution and logistic support. Intact, realistically most frameworks are repairable, and its significance measures change with time. Considering this rectification as a time series process, the “development” or “decline” of the system can be assessed.
The theory of fuzzy time series was first introduced by Song and Chissom [1] based on fuzzy sets premised independently by Zadeh [2] as an extension of the classical set theory. Fuzzy time series models perform without any assumptions that the conventional statistical models require. In addition, ecological information such as temperature, financial data sets of the stock exchange, energy consumption in different sectors and data series collections in numerous domains ought to be considered as fuzzy time series due to the ambiguous and uncertainty that they contain. Due to the above-mentioned reasons, intense for researchers in fuzzy time series is boosting.
In recent years, besides the formation of new soft computing mechanisms practiced in different fields such as privacy and security [3–6], optimal solutions using genetic algorithms [7, 8] and medical domain [9], fuzzy time series prediction analysis has been broadly utilized in various domains. It includes the study of enrollments [10–12], prediction analysis of temperature [13, 14] and stock index [15–18]. Due to the significance of FTS to tackle the genuine issues, many models of different types have been developed and, mostly, are related to the algorithm of Chen’s model [10]. These investigations address various issues to improve the forecasting accuracy, including partitioning of data set into different space intervals [19–22], number of variables [23, 24] and order [25, 26].
The process of defuzzification in FTS forecasting, affectively influenced by interval partitioning. In the earlier proposed algorithms, fuzzification was examined as optimization of an interval partitioning based on equal space intervals [1], average based partitioning [19] and ratio based partitioning [20]. After that, to improve the accuracy in forecasting, many novel approaches are introduced in the literature, such as genetic algorithm [27], particle swarm optimization (PSO) [28], single variable based optimization model [29], clustering approach [22], entropy-based partitioning [30] and fuzzy k-Medoid clustering method [31]. Since the FTS algorithms based on a clustering approach do not utilize intervals, rather use cluster centers in fuzzification of information. Fuzzy c-means clustering (FCM) [32] is widely used in the generation of forecasting algorithms, which is soft form of K-Means algorithm. Due to uncertainty and vagueness in data series, the prescribed algorithm generates less accurate outcomes and to cope with the perceptive issues, some modifications have been made to increase the accuracy in forecasting [33, 34]. To handle the issue of optimize partitioning; a vigorous methodology is required, which contains the property of adequacy to improve the accuracy in forecasting.
In this paper, the historical data series is clustered by using the approach of FCM [32] and information granules [35] which relies on the concept introduced in [36]. Unequal length of intervals are established and then fuzzified the input data using triangular membership function. In the end, the output is generated after defuzzification as the weighted average approach is employed to get crisp forecasts.
The rest of the paper is described as: section 2 reviews about the basic approaches of fuzzy sets, fuzzy time series, triangular membership function, fuzzy c-means and information granules. In section 3, the proposed fuzzy c-means clustering method integrated with the concept of weighted average approach is briefly introduced. Section 4 consists of an implementation of the proposed method on a historical data set and evaluation in terms of statistical accuracy measures such as RMSE and MAE. Finally, section 5 serves as a conclusion and recommendations of our present study.
Preliminaries
This section contains the review of basic definitions of fuzzy sets [2], fuzzy time series [1] and other theories.
Fuzzy time series
The FCM clustering technique was first presented by Bezdek [32]. This is the most broadly applied clustering method that deals with the uncertainty in variables. This approach minimizes the least-squares with the execution of fuzzy clusters. Let h
ji
denotes the membership value, n is the number of variables and c describes the number of clusters. Then the objective function with minimizing in the fuzzy clustering environment is as follows:
Where β is called the fuzzy index, which satisfy the condition such that β > 1, d (y
j
, ν
i
) is the similarity measure between the observation and center of the cluster. The function J
β
(Y, V) has the following constraints
The theory of information granules was firstly addressed by Zadeh [37]. It considers disintegration a whole into small elements, and each element is considered as a granule. Bargiela [35] exhibited the idea of recursive data granulation with tending to the issues of conglomeration and assessment. This advancement can be shown in a specific proper structure of the granular computation. In this paper, the concern is going to build up a solitary data granule depend upon some time-series information. Being developed procedure of data granule, reasonable granularity and semantic adequacy are the two instinctively convincing prerequisites. The state of reasonable granularity is achieved by including the more information inside the limits of Ω. Furthermore, the prerequisite of semantic is practiced by the length of the granule. Consider a data series of a variable y1, y2, . . . , y n , spread over a time period t1, t2, . . . , t n ; then data granule Ω1, Ω2, . . . , Ω n can be achieved by considering the idea of legitimate granularity to the informational index y1, y2, . . . , y n .
Proposed fuzzy time series method
In this section, the complete process of the proposed algorithm is presented for forecasting of time series data. On the basis of FCM and information granules clusters and effective intervals [36] are developed, triangular membership function is used to fuzzify the time series data, fuzzy logical relationships are established and defuzzification rule of the weighted average is applied to get crisp forecasts. The proposed fuzzy time series algorithm is presented as follows:
Compute the number of clusters c and prototypes v
i
. let c = k/2, then the number of clusters should not exceed the k/2 integer. Compute the prototypes {v1, v2, . . . , v
c
} using FCM approach. On the basis of already established c clusters and for prototypes ν1 < ν2 < … ν
c
, the mid points can be calculated as At this level, information granules are constructed. If v
i
represents the prototypes of subset A
i
, such that med (A
i
) = v
i
then upper and lower bounds for information granules are specified as l
i
and m
i
. Obtain the optimize intervals with unequal length for universe of discourse as [ue1, ue2, . . . ue
k
].
Where h
ji
is the smoothing or weighted constant for the current year of observed data series,
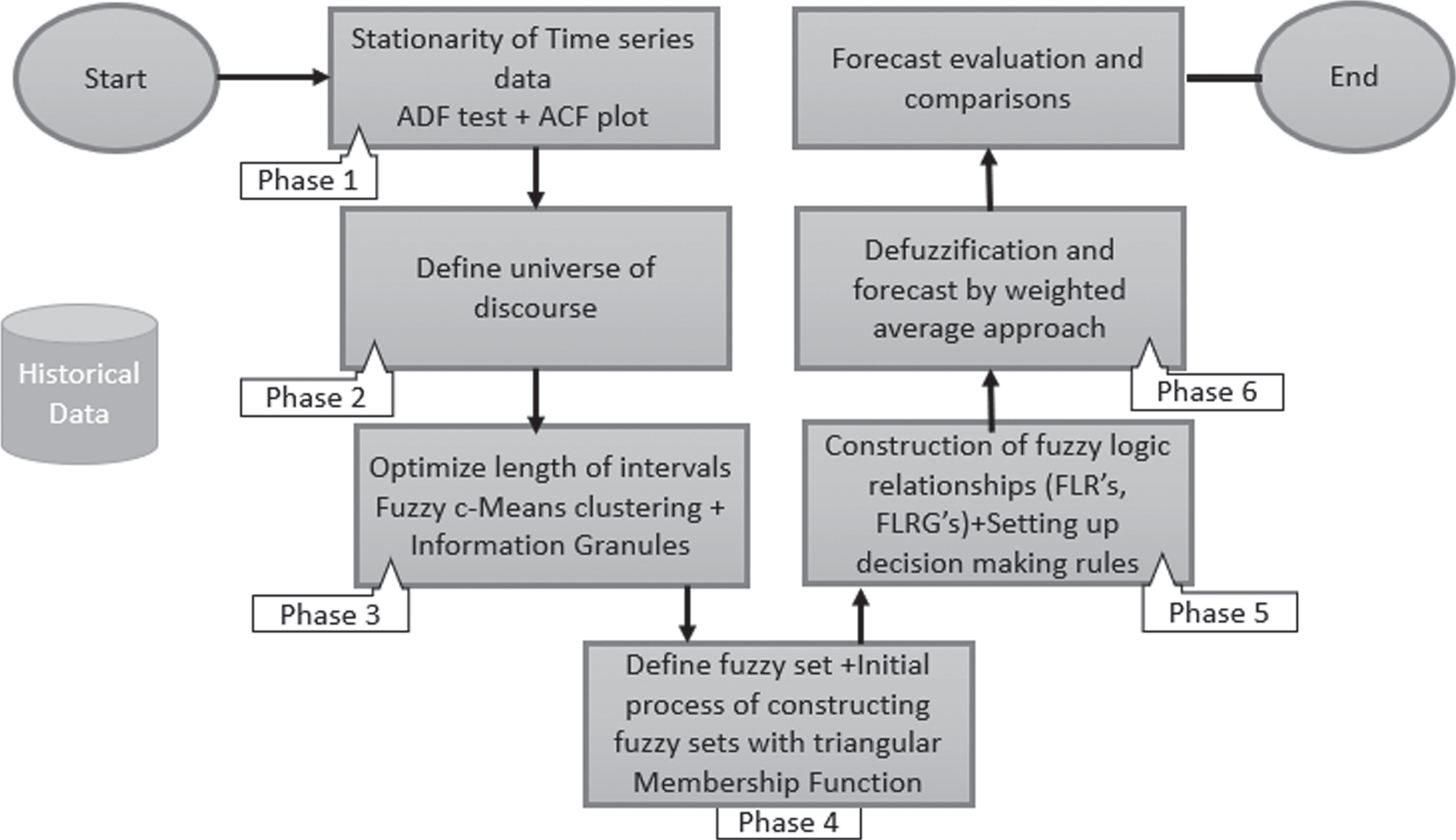
Architecture of the proposed fuzzy time series model.
Mean absolute error (MAE)
It is the average absolute difference of actual and forecasted values. Its equation can be expressed as
Root Mean Squared Error is a measure of accuracy, used for comparison of different forecasting models by calculating forecasting errors of specific data set. It is written as
The proposed model is implemented on one of the food crops production data. The inspiration to utilize crop yield production data is that the estimation of food is one of the genuine issues because of vagueness in known and some obscure parameters. For this purpose, time series data of gram (chickpea) of Pakistan is taken from the website of the Food and Agriculture Organization of the United Nations. (http://www.fao.org/faostat/en/#data/TP).
Results and discussion
Description of the data regarding the production of gram pulse of Pakistan is presented in Table 1. The maximum figure for production of gram pulse in Pakistan was 868.3 thousand tons. The minimum value for production was 284.304 thousand tons in the period 1987–2013. The time series data of gram pulse is plotted in Fig. 2.
Descriptive statistics regarding production of gram pulse
Descriptive statistics regarding production of gram pulse

Production of gram pulse crop in Pakistan.

plot of ACF for production.
Number of effective unequal intervals to be estimated are 14, where c = 7 clusters. Then prototypes v7 are given as.
On the basis of already computed prototypes v7, the mid points x
g
are calculated as follows.
By following the instruction given in section 3, the subsets are established.
If v
i
represents the prototypes of subset A
i
(i = 1, 2, …, 7) then
Using the above information, upper and lower bounds for information granules Ω
i
are specified as l
i
and m
i
presented in Table 2. Obtained the 14 optimize intervals with unequal lengths given as.
Information Granules
Fuzzy sets established with the help of unequal length of intervals are computed as
Fuzzified Production
Fuzzy logical relationships of the fuzzified production
Fuzzy logical relationships Groups of the fuzzified production
For the production of year 1987, fuzzy set is F6 = < 493, {0.254} >. FLRG corresponding to F6 is F6 → F3, F14. Since the midpoints of the optimize unequal length of intervals Fu3, Fu6 & Fu14 are 362.775, 486.187 and 824.58 respectively then forecast for the year 1987 using Equation (3) is calculated as
Other forecasts are also computed in a similar way and are presented in Table 7. The comparison graph (Fig. 4) shows that forecasted values are very close to the actual values. Also, the proposed model is compared with the conventional statistical models on the basis of accuracy measures, MAE & RMSE by using the Equations (4) and (5). The results illustrated in Table 6 show that the proposed fuzzy time series model in this study generates better forecasts than other statistical models.
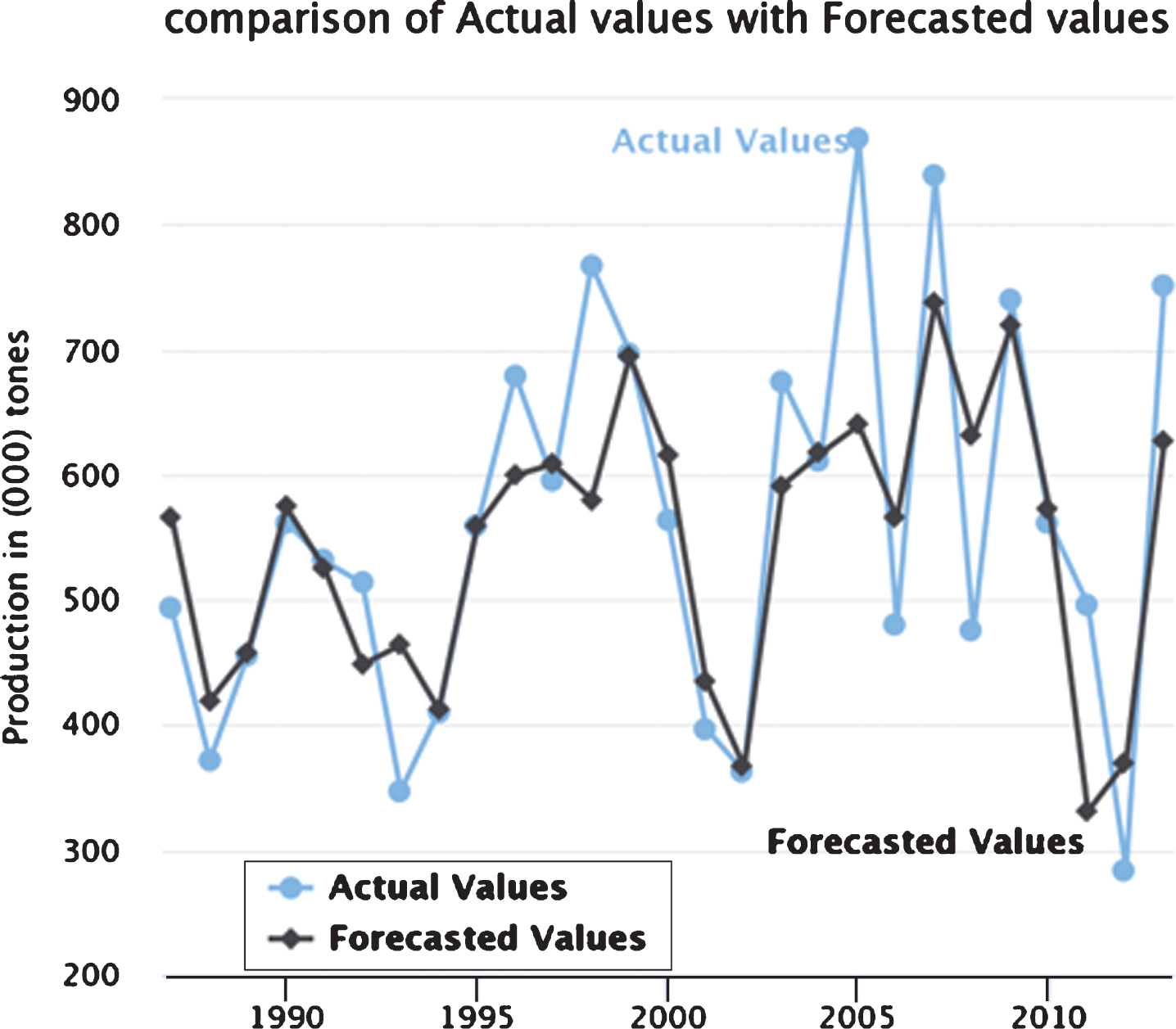
Comparison of observed values with forecasted values.
Model comparison with Statistical Models
Forecasted Production (000 tonnes)
Residuals are useful to see the model adequacy whether a time-series model is capturing enough information for accurate forecasting. A useful prediction time-series model must satisfy the following properties of residuals. Residuals are uncorrelated Have zero mean Have constant variance Normally distributed
The analysis illustrated in Fig. 5 with the help of R software describes that all information in data set is utilized by the proposed fuzzy time series model and all properties of residuals are satisfying in this residual analysis.
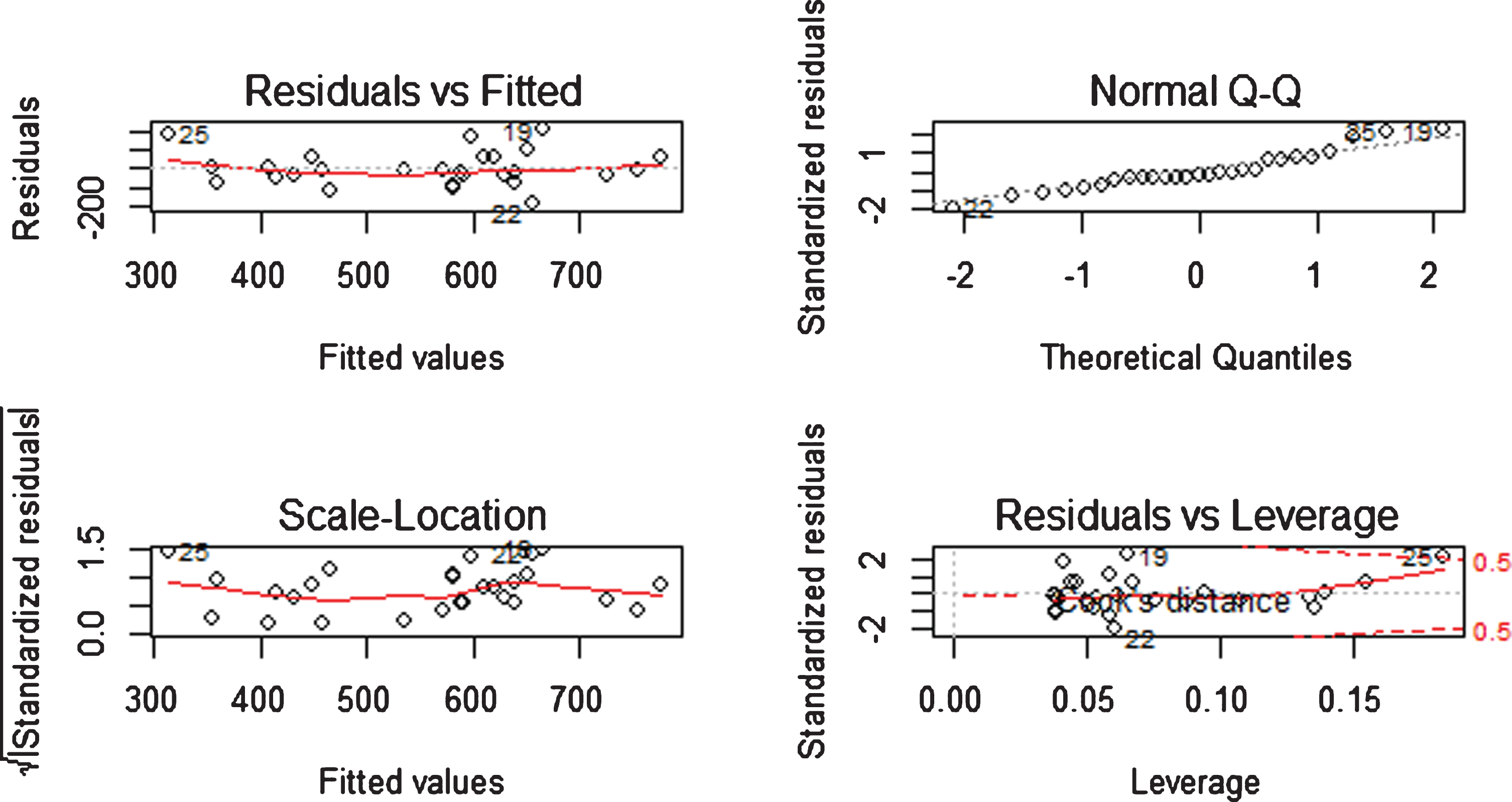
Plot of residuals for production data.
In our paper, a new fuzzy time series method based on FCM, information granules and a new weighted average approach is proposed. The most significant advancement in the study is that the relationship among data series is considered in the clustering environment. Firstly, the extreme observations which may cause an interruption to generate accurate forecasts are eliminated and continue the process with stationarity in data series. Optimize the length of intervals are obtained using FCM and information granules theory. A unique weighted average formula is fitted which utilize the all fuzzy logical relationships to get the crisp forecasts. There is the requirement for future research to expand the current work on developing the more significant multivariate FTS model.
Footnotes
Acknowledgments
We would like to thank the referees and the journal editorial team for providing valuable advice that improved the quality of the original manuscript. This work is supported by National Nature Sciences Foundation of China (11671104).