
Abstract
Today’s world is facing threats from terrorism, for safety concerns system needs to strengthen security. Security is a challenging task and it can be strengthened by technology such as biometric and surveillance cameras. These technologies are deployed everywhere but it is the need of the days a strong automatic face recognition applications so they can be used to recognize the person in an unconstrained environment. In an unconstrained environment, images are affected by occlusion such as a scarf, goggle, random but these variations decrease the performance of face recognition. Also, the accuracy of face recognition depends on the number of labeled samples and variation available in the training dataset. But some applications of face recognition such as passport verification, identification of these applications have fewer training samples without or with very less occlusion hence, it is not enough to solve the issue of unconstrained conditions. This problem has been targeted by many researchers using an occlusion based training dataset where common variation exists in both training and testing datasets. This paper tackles the occlusion issues by designing a NonCoherent dictionary. The proposed dictionary is designed by two steps firstly it extracts the occlusion from the face image and secondly creates NonCoherent samples. The extensive experimentation is done on benchmark face databases and compared the results on state-of-the-art SRC methods by using NonCoherent and normal dictionary also compared the sparse coefficients of each method. The results show the effectiveness of proposed model.
Introduction
For the past three decades, face recognition has attracted more attention of researchers in computer vision due as it is the need of the day. Several face recognition based biometric systems and surveillance cameras are deployed in the home and corporate offices for an authentication purpose. In the present-day scenario, where the surveillance cameras are installed in the unconstrained environment, it is difficult to achieve images like in constrained environment. In unconstrained conditions, images are affected by occlusion such as scarf, goggle, and random. The subspace of the same person changes due to occlusion, when an image is acquired through surveillance camera it poses a complex problem in identification of a person.
Researchers have published numerous feature extraction method [1–4] and classification methods [6–9] for face recognition and have achieved state-of-the-art results in restricted condition. The existing methods work well in constrained environments and work weakly for unconstrained condition. The performance of face recognition in an unconstrained environment still needs improvement and hence it can be considered as an open issue for research. As the performance of the basic face recognition is highly sensitive to occlusion and needs a large number of training samples with a variation for better performance. Undersampled face recognition has the most important real-time applications where very few training samples of each person are available. Examples are law enforcement, passport identification, and authentication for various purposes. The undersampled methods are divided into three categories: The first category of methods is patched based representation [18], which divides the image into a number of patches. The second category of methods created virtual images of the training samples. The third category of methods [19] uses generic training dataset.
Recently, representation models have gained much attention in face recognition due to its ability to solve the issue of occlusion and noise. The models names as follows: Sparse representation based classification (SRC) [9], Collaborative representation based classification (CRC) [10], and Linear Regression based Classification (LRC) [11]. SRC [9] represents a test sample by a linear selection of dictionary atoms from all classes and select the class which produces minimum residual. The residual of representation model measured by using ℓ1-norm and ℓ2-norm. Sparse representation has achieved better performance among all representation models. SRC performs worst when each class has less number of samples to represent a test sample. Few researchers tried to resolve this problem. In Extended SRC (ESRC) [12], the author created an intra-variant dictionary by subtracting the centroid image of each class from its respective class samples. other SRC based methods also created intra-variant dictionary such as SSRC [13], SDR [14], S3RC [15]. But these methods fail to work under unconstrained environments like occlusion, expression and illumination variation.
This paper proposes a new NonCoherent dictionary which incorporates samples of occlusion variation. The existing study shows that the researchers have never discussed the issue of different colors and shapes of occlusion, they have considered same color of occlusion. Also they have reconstructed images by eliminating the occlusion, but reconstructed images can be loose discriminative features and results in poisoning effect. The aforementioned issue is tackled by designing a NonCoherent dictionary and dictionay design accomplished in two steps firstly it extracts the occlusion from the face image and secondly creates NonCoherent samples. The objective of this paper is to extract occlusion from a face image and design NonCoherent dictionary which handles different color and shape of occlusion. The substantial experimentation is done on benchmark face databases and compared the results on state-of-the-art SRC methods by using NonCoherent and normal dictionary also compared the sparse coefficients of each method. The experimental results on NonCoherent dictionary have shown better performance compared to the existing dictionary.
The remainder of the paper follows as. In section 2 review the existing method of sparse representation classification. Section 3 discusses Design of NonCoherent dictionary Section 4 gives detail experimental results and analysis. and lastly, section 5 draws the conclusion of the paper.
Related work
Initially, SRC [9] was introduced on face recognition by J Wright et al. in 2009. SRC finds the sparsest representation of a test image from the dictionary which is constructed by all the training samples and classifies test image to the class which gives a less residual error. SRC outperformed on corrupted and occlusion images but these types of variation samples must be in training data set. SRC had used training samples as dictionary atoms and its time complexity depends on the size of the dictionary. Let A = [A1, A2, . . , A
k
] ε
SRC needs a number of training samples including a different variant to gain high accuracy. Sparsity constrained ∥x ∥ 1 and signal fidelity ||y - Ax||2 are two important terms in Equation 1 and these term may vary the performance of sparse based face recognition. Several extended SRC versions have been developed by modifying sparsity constrained, signal fidelity term, dictionary and fusing new methods into SRC. The methods [16–18] had been developed by modifying sparse coefficient, [19] by dictionary and [5] by fusing existing methods into SRC. Several extended algorithms have been developed by modifying these two terms. The distribution of residual e = y - Ax may not properly follow Gaussian or Laplacian distribution when they are corrupted and there are other variations in images. Robust sparse coding (RSC) [22] induce new weight to the signal fidelity term ||y - Ax||2 of Equation 1 and show better performance on variant images. But still, RSC and many SRC based methods of face recognition require a large number of training samples with all required variation. Thus, to apply SRC for an undersampled face recognition new algorithm needs to be developed for the undersampled dictionary-based application. There are two ways to construct an auxiliary dictionary: the first method to create a dictionary by subtracting the centroid of each class from the samples of the same class or external samples [12, 13] and the second way to create a dictionary is by learning algorithm [19].
The fewer training samples can lead to misclassification for a disguised test sample. Authors in Extended SRC (ESRC) method proposed by Deng et al. [12] try to overcome undersampled problems. In the ESRC method, authors have introduced a new extra intraclass variant dictionary, which is created by subtracting the prototype or centroid of a class from the samples of the same class. The linear representation of Equation 1 is modified by introducing an intraclass dictionary G in Equation 2 [12] and this intraclass variant matrix that represents the local expression, environmental illumination, and occlusion of the face image.
ESRC method represents a test sample by two dictionary A and G. The only first dictionary A takes part in the classification process of a test sample and the second dictionary is not considered for classification because its atoms are not associated with any class label but it can be used to generate a more stable sparse vector. The extra variant dictionary is constructed from the variation of the samples of the same class but when variation is less in training samples then test sample may be classified as the other class. ESRC needs a number of training samples with wide variation otherwise intraclass variant dictionary may collapse. The aforementioned problem having less variation is solved by the same author with the help of new method called a superposed SRC method [13]. In this method, the first part of the dictionary atoms of each class is replaced by a single prototype or centroid of a class and intraclass variate dictionary constructed from set of generic samples of other dataset. However, this method does not provide a reliable classification due to the single prototype or centroid of each class. The centroid of each class is used to represent and determine the label of a test sample. Iliadis et al. [21] combined sparsity approach of ESRC with least square and proposed a new method, SR + RLS that first finds sparse coefficient x using ESRC and then constructs new small dictionary by selecting the dictionary atoms with respect to indexes of sparse vector which has nonzero value. In this method, the authors used two classification mechanisms to find a correct class instead of using any learning mechanism for a proper prototype of the respective classes. The SR _ RLS method has improved performance over ESRC but failed to resolve the issues of ESRC. Issues of ESRC are resolved by Jiang et al. by proposing the SDR [14] method that represents test sample by a collaboration of class-specific dictionary and the dense combination of the non-class specific dictionary (intraclass variation dictionary). ESRC has taken the variation from same class to represent a test sample, whereas SDR takes the collaborative variation of different classes. In SDR, first-class specific component is extracted from natural images. [12, 21] methods need to know in advance about test sample variation and require more variation in samples to create an intra-variate dictionary. The SSRC method uses a linear operation to construct a prototype for each class and hence method is not effective to tackle the nonlinear variation issues of face recognition. In case of single labeled sample per person (SLSPP), the existing methods have not shown performance up to the benchmark. Gao et al. [15] proposed S3RC method, which uses the ESRC framework with modification of gallery dictionary. S3RC has used two dictionaries namely: gallery dictionary and intra-variant dictionary. Intra variant dictionary helps to rectify linear variation and the gallery dictionary is used to reduce nonlinear variation. ESRC and SSRC methods did not use any learning mechanism to construct or learn gallery dictionary to resolve the nonlinear issue. S3RC has used probability-based GMM to find a single prototype for each class using labeled and unlabeled samples. The prototype of GMM has learned for each class using semi-supervised EM algorithm. Long-time ago the GMM has been used for face recognition but did not attract much attention in the field of face recognition. The reason is that it works on the distribution of pixel value and the distribution changes with respect to the variation of sample. Hence, may not possible to create a discriminative single prototype for each class.
So far reviewed the existing methods based on sparse representation. Some researchers worked on the detection and elimination of occlusion and it plays a big role to reconstruct the new image. Y. Li et al. proposed a new technique [17] to eliminate occlusion from the face image. The occlusion elimination is carried out in two steps: first occlusion detection and other is image reconstruction. Downsampled SRC has used to detect occlusion and reconstruct the image by linear reconstructive subspace. Then, the reconstructed samples are used for the face recognition process. S. Zhao et al. proposed a DLSR [16] method, which tackles the issue of occlusion, this method divides an image into four blocks, so dictionary can be converted into 4-subdictionary. The unit dictionary is added to each subdictionary to estimate the occlusion pixel and it is detected based on the portion which has a maximum value. In DLSR method, authors do not describe that if the occlusion is available in two blocks then how to reconstruct the image and other one is an estimation of occlusion pixel. D. Lin et al. have proposed a method [20], which detects occlusion of the face by measuring the skin color area ratio (SCAR). This method is not effective because skin color can be changed due to different illumination and light effects. To tackle the problem of occluded face recognition with undersampled data, a better method based on SRC have been proposed which can deal with occlusion of different colors.
As has already been observed in the review that at the existing SRC based methods need more variation in training samples or external samples to create intra class variant dictionary. In most of the existing methods, researchers have created common intra variant samples for all classes. So, it is shared by all training samples and many individuals having similar features may be misclassified. To resolve this problem, a NonCoherent dictionary is created. The proposed approached is depicted in Fig. 3. The proposed approached is categorized into three parts: 1. Extraction of occlusion 2. Design of NonCoherent dictionary and 3. Recognition.
Extraction of occlusion
The face is a complex image where detection and extraction of occlusion is difficult task. The Performance of face recognition could not be affected by 5% of occlusion but more occlusion can reduce the performance. The occlusion can be handled in two ways: first the image is reconstructed by removing occlusion and second by adding occlusion variation in training samples. In this paper, second approach has been used to tackle the occlusion issue. The face is mostly occluded by goggle and scarf but sometimes it might be occluded by random occlusion.
Occlusion due to scarf and goggle
Goggle and scarf almost occupied 20% and 40% space of face respectively. Mouth and eyes of face image are detected by the voila Jones algorithm [23] and identify whether the test image is occluded or not. Existing work [26–29] have considered same color of occlusion but it may not be the same in a practical scenario, hence occlusion color is detected by the frequency of pixel. The process of extraction of goggle from face image as shown in Fig. 1 and it is extracted using Algorithm 3.1.3. The goggle reflects the intensity of source light, hence some part is missing while the extraction of occlusion as shown in the third row of Fig. 1. The morphological operations have been used to fill the missing and remove unwanted parts using Equation 3, 4, and 5.

Extraction of goggle from the face image.
The random occlusion is occurred due to different obstacle and it is difficult to find out from the face image. From the previous work [26–29], it is observed that the authors did not consider the shape and color of the occlusion but in a practical scenario, it might be possible. Generally, a face has only two colors: hair and skin color, so it is possible to form two clusters. If random occlusion is available in an image, then it can be formed 3 clusters as shown in Fig. 2.

Cluster1 a. Input Image b. Clusters c. Object in cluster 1 d. Object in cluster 2 e. Object in cluster 3.
Figure 2 have shown how to extract occlusion from the face image. For random occlusion, input images are taken with different colors and shapes. Then apply Algorithm 3.1.3 to extract occluded segment or component from the face image as shown in Fig. 4.d.
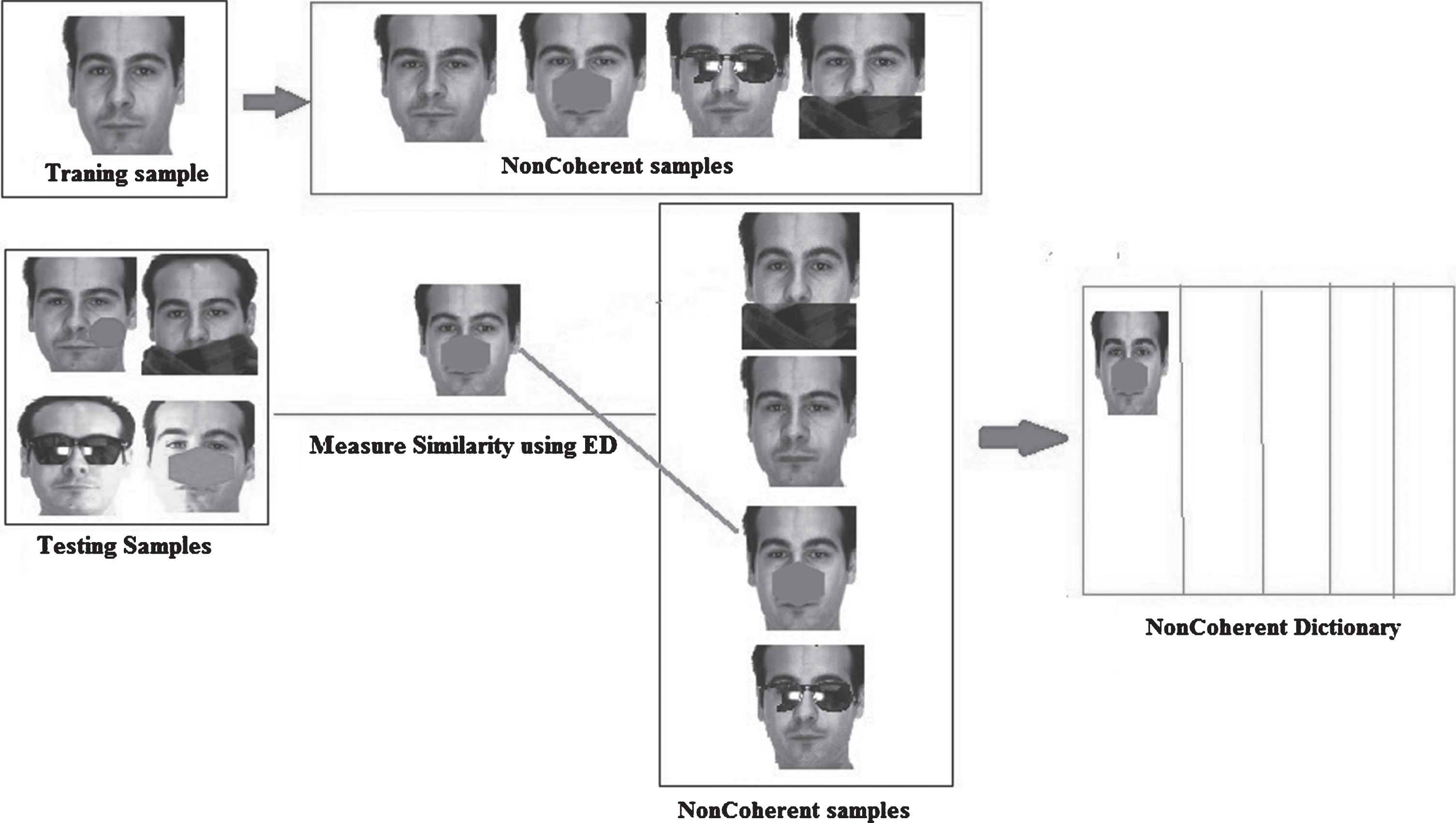
Model to design a NonCoherent dictionary.

AR face dataset samples of one individual a. Neutral face b. Illumination c. Goggle occlusion d. Scarf occlusion.
The extract the occlusion based on pixel values. Initially apply kmean clustering on image to create different clusters.
Let c1 . . . c
k
initial cluster centers and each pixel of image assign to its closest cluster c
i
. k is a number of clusters needed to be formed. mask
i
holds the pixels of cluster i and assigned unique label to all pixels using Equation 15. d is a number of pixels in an image. For each cluster c
i
, update its center by estimating the mean of all the points x
j
that have been assigned to it.
where, Count _ Component be the number of segments present in each cluster. Count _ Pixel _Component is the number of pixels avilable in segment.
Let A = [A1, A2, . . . . , A k ] is a dictionary which contain all samples of training data set. k is a number of a person or classes in the training data set. In this section, Design a NonCoherent dictionary from NonCoherent samples which consist of goggle, scarf and random occlusion.
Design NonCoherent samples for each class
let A
i
= [Ai,1, Ai,2, . . . . , Ai,N] represent the set of samples that are belongs to the i
th
class of training data set. Each class has N number of samples. Created different NonCoherent samples from each sample of all classes using Alogithm 3.1.3. Let
Measure similarity between test image and NonCoherent sample
Need to represent compact and discriminative dictionary, so by creating NonCoherent samples, it increases the size of the dictionary. Here, the main intention is to reduce the size of the dictionary, hence, the most similar 2N samples selected from the (N * p + N) NonCoherent samples. Euclidean distance has been used to measure the similarity between test image y and NonCoherent samples of a class. Let
The NonCoherent dictionary is created by combining 2N most similar samples from all classes, which is estimated by Equation 11. Let D
ncoh
= [DNC1, DNC2, . . . . , DNC
N
] be the NonCoherent dictionary. The linear system equation can be optimized by Equation 12.
A test sample is assigned to the class that minimizes the residual error. Sparse representation assumes that the samples from the same class lie on the same subspace. Hence, test sample y classified based on minimal residual or the class which has more number of nonzero entries in sparse coefficient vector
Where, r
i
(y) is a residual of test sample y with respect to the i
th
class,
This section, provides the experimental results on benchmark face database AR [24], LFW [25] to demonstrate the performance of the NonCoherent dictionary. For the experimentation consider two databases because they have more variation for occlusion than the other databases. The results are compared using NonCoherent and normal dictionary on state-of-the-art SRC methods such as SRC, ESRC, SSRC,SR _ RLS, and SDR. The aforementioned methods have shown good results on AR and LFW databases because they have considered half of the images for training and remaining for testing as well as test and train dataset share a common variation. This experimentation, we have considered neutral images for training and occluded images for testing, and both the dataset does not share common variation Hence the experimental results of these methods are showing less compared to their published results. Validation is done using NonCoherent dictionary by testing the experiments on samples with scarf, goggle, mixed scarf+goggle, and random occlusion with different shape and color. The image resolution 50 × 50 is considered for experimentation.
Section 4.1, introduces the publically available face database; Sections 4.2, 4.3, and 4.4 explain the experimental result of a scarf, goggle, and random occlusion. Section 4.5, analyzes the experimental results.
Face database
AR database
AR [24] database contains color 4000 images of 126 individuals having 26 samples of each individual. These images are captured with a variety of illumination, occlusion, and facial expression. The samples of an individual have been shown in Fig. 4.
LFW
The LFW [25] face database images that are taken from the web of 1680 individuals. These images are varying in illumination, pose, expression and different background. LFW database is a benchmark for face recognition applications. The samples of an individual have been shown in Fig. 5.

LFW face dataset samples of one individual.
Total 100 individuals of AR database, 1 individual has 12 samples, select randomly 2,3,4,5, and 6 neutral samples per individual for training and 6 samples occluded with scarf samples per individual for testing. The performance of the scarf occlusion samples have tested and results are depicted in Table 2.
Experimental results on AR database with scarf occlusion
Experimental results on AR database with scarf occlusion
Experimental results on AR database with goggle occlusion
The Scarf occludes almost 40% of the face part, it is difficult to recognize on the basis of remaining 60% pixels. SRC based methods required similar occlusion samples in dictionary, hence its results getting reduces. A NonCoherent dictionary provides all variations that are required for better performance of SRC methods.
Total 100 individuals of AR database, 1 individual has 12 samples, select randomly 2,3,4,5, and 6 neutral samples per individual for training and 6 samples occluded with sunglass per individual for testing. The performance of the scarf occlusion samples have tested and results are depicted in Table 3.
Experimental results on AR database with scarf and goggle occlusion
Experimental results on AR database with scarf and goggle occlusion
The Sunglass occludes almost 20% of the face part, and it changes the variation of whole pixels, hence the results of SRC based methods reduces. A NonCoherent dictionary provides all variations that are required for better performance of SRC methods.
Total 100 individuals of AR database, 1 individual has 12 samples, Select randomly 2,3,4,5, and 6 neutral samples per individual for training and 12 samples occluded with sunglass and goggle per individual for testing. The performance of the scarf occlusion samples have tested and results are depicted in Table 4.
Experimental results on AR dataset with random occlusion
Experimental results on AR dataset with random occlusion
The occlusion changes the discriminative feature of an image. The existing work of SRC methods concluded that as a number of training samples increases respectively performance also increases But in case of occlusion it seems stable and does not affect by a number of training samples. The proposed dictionary provides all variations that are required for better performance of SRC methods and the results also increase as training samples increases.
Total 100 individuals of AR database, 1 individual has 14 samples, Select randomly 2,3,4,5,6, and 7 neutral samples per individual for training and 7 samples for testing and it is occluded manually with different colors and shapes. The performance of random occlusion samples have tested and results are depicted in Table 5.
Experimental results on LFW database with random occlusion
Experimental results on LFW database with random occlusion
Total 40 individuals of LFW database, 1 individual has 9 samples, Select randomly 2,3,4,5,6, and 7 neutral samples per individual for training and remaining samples for testing and it is occluded manually with different colors and shapes. The performance of random occlusion samples have tested and results are depicted in Table 6
The occlusion of the test image increases misclassification due to unaware of its position, color, and shape. Test images are occluded manually with different colors and shapes of 5% –30% as shown in Fig. 6. The occlusion is detected by Algorithm 3.1.3. The results of the NonCoherent dictionary is impressive and shown in Tables 5 and 6.

Random occlusion.
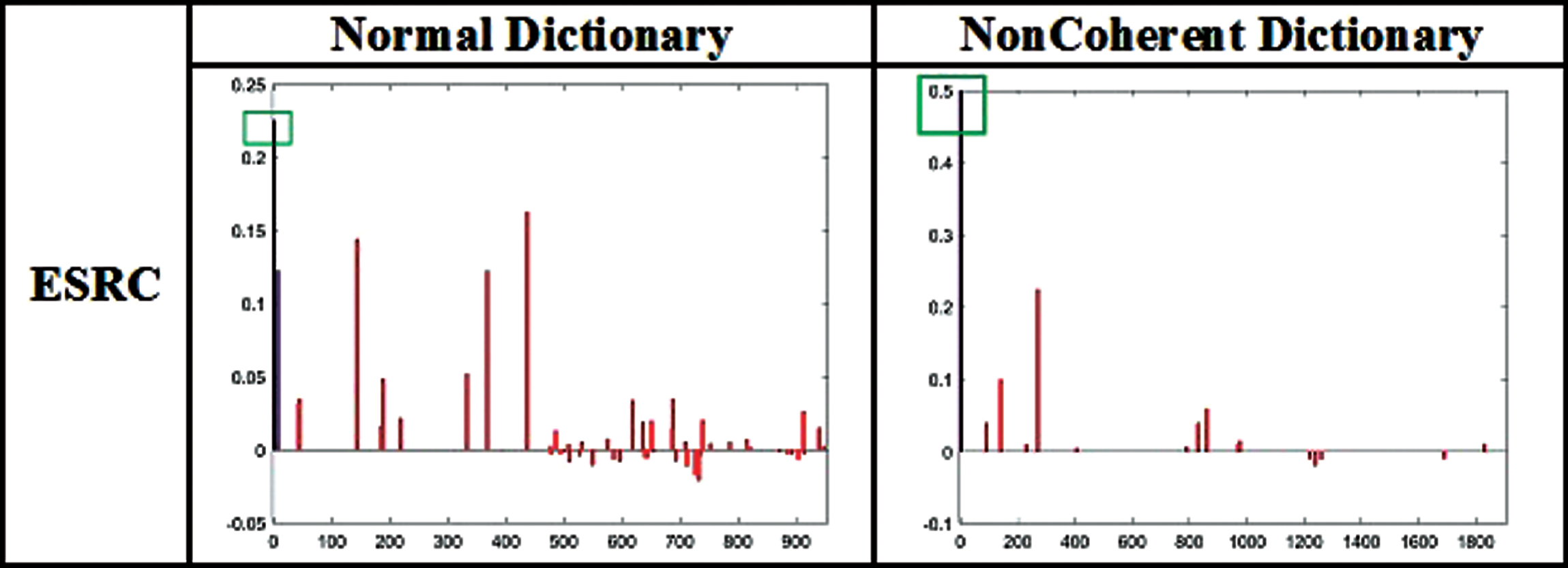
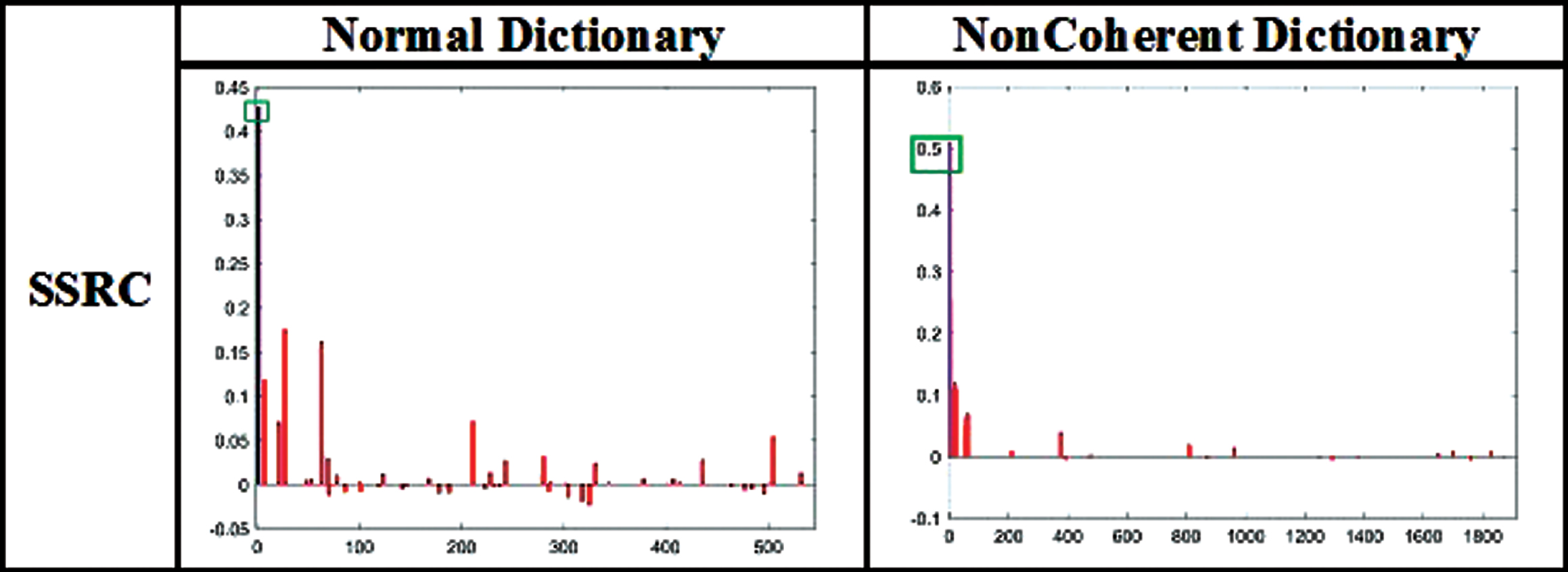
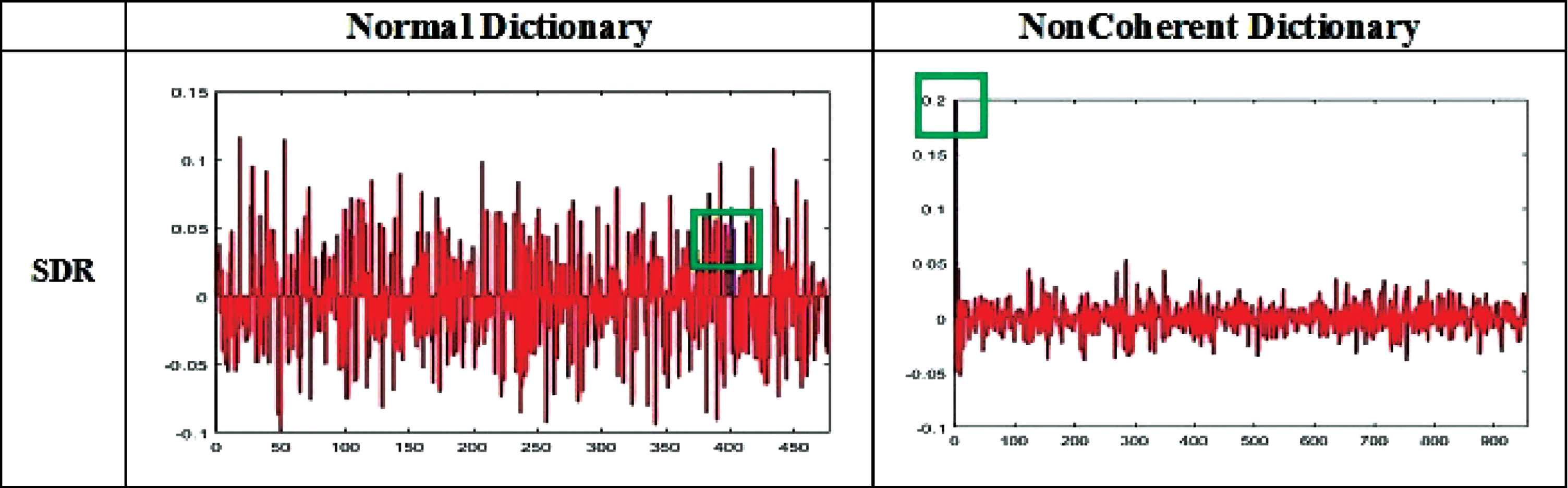
As a percent of occlusion increases in test images then SRC methods decrease the performance. Less than 5% of occlusion can not affect the performance of face recognition. NonCoherent dictionary is more effective for random and contiguous occlusion and Algorithm 3.1.3 in Section 3.1.3 has successfully identified the occlusion with shape and color. The comparison of the sparse vector of SRC method on random occluded sample is illustrated in Fig. 7. SRC classifies the correct class using NonCoherent dictionary whereas misclassified using a normal dictionary. It is found that the sparse vector of predicted class is high and has very few nonzero coefficients using NonCoherent dictionary. Square box in Fig. 7 indicates the sparse value that is used to predict the class. The comparison of sparse vector of ESRC and SSRC are shown in Figs. 8 and 9 respectively. These methods classified a test sample correctly using both the dictionaries. In the case of the normal dictionary, a sparse vector is dense in the region of the intra-variant whereas sparse vector is very sparse in case NonCoherent Dictionary, it means variation of NonCoherent samples has more similarity. The coefficient values are high in the predicted class by using a NonCoherent dictionary. SR _ RLS method estimates the coefficient on a newly constructed face dictionary, which is created with the help of nonzero sparse coefficient of ESRC. A NonCoherent dictionary classifies the correct class whereas normal dictionary misclassify. But in this method coefficient is spread across all classes using proposed dictionary. The comparison of sparse coefficient of this method on random occluded sample is illustrated in Fig. 10 and this figure concludes that NonCoherent dictionary have more sparsity. Similarly, SDR also predicts the correct class using a NonCoherent dictionary. NonCoherent dictionary sparse coefficient of correct class is higher than other incorrect classes whereas it is vice-versa in the case of normal dictionary. The comparison of sparse coefficient of this method on random occluded sample is illustrated in Fig. 10. From figure we can conclude that NonCoherent dictionary is showing proper result. Comparison of sparse coeffient using normal dictionary and NonCoherent dictionary on SRC. Comparison of sparse coeffient using normal dictionary and NonCoherent dictionary on ESRC. Comparison of sparse coeffient using normal dictionary and NonCoherent dictionary on SSRC. Comparison of sparse coeffient using normal dictionary and NonCoherent dictionary on SR _ RLS. Comparison of sparse coeffient using normal dictionary and NonCoherent dictionary on SDR.


This paper proposed an algorithm for occlusion extraction and design a NonCoherent dictionary which incorporates different occlusion variation. This dictionary improves the performance of occluded face recognition. The dictionary is designed in two steps: first step is to detect and extract the occlusion from the test image using proposed an occlusion extraction algorithm. The second step is to create NonCoherent samples that help to design NonCoherent dictionary. The performance of the proposed dictionary has tested on different occlusion databases and shown remarkable improvement over existing dictionary. The results of state-of-the-art SRC methods outperformed using NonCoherent dictionary and also compared the sparse coefficient of occluded sample. In case of NonCoherent dictionary, sparse coefficient value is higher and predicted a correct class. In future try to extract occlusion which is similar to skin or hair color and reduced time complexity.
Funding
This study was funded by the Ministry of Electronics and Information Technology (India) (Grant No.: MLA/MUM/GA/10(37)B).
Conflict of interest
The authors declare that there are no conflicts of interest regarding the publication of this paper.
Footnotes
Acknowledgment
The work was supported by Visvesvaraya PhD scheme, Govt of India.