
Abstract
This paper presents the core algorithms behind DB-Query-Encryption, a proposal that supports private information retrieval (PIR) explorations. DB-Query-Encryption permits users for selectively retrieve information from a cloud database whereas keeping sensitive data terms secretive. As an example use case, a medical research institute may, as part of a sensitive data exploration, requisite to look up facts about an individual person from a cloud database deprived of reveling the person’s identity. The basic idea behind DB-Query-Encryption is to uses homomorphic encryption, which allows the cloud server to fulfill this request, whereas making it infeasible for the database owner (or a hacker who might compromised) to conclude the name being explored for, either which records are retrieved. The query, which retrieved the information, still secretive even if the spectator be able to search all the data over the cloud server and all the actions as they are being executed. Within that period, the query response produced by the cloud server is considerable smaller than the whole cloud database, making it more convenient when it is not feasible or appropriate for the user to transfer the entire database.
Keywords
Introduction
Sensitive information retrieval (SIR) is a powerful technique, which permits users to retrieve data from an untrusted cloud server without the server, or any malicious spy being capable to conclude what data the users is exploring.
SIR has many potential applications besides the medical research use case mentioned in the abstract. An enterprise may not want to disclose its confidential investigation whenever the company are going for to register a patent. Numerous queries into a map database may specify a certain geographical position by an oil drilling business or military units. An financier interrogating the stock market database for the worth of a certain stock desires to retain secretive the identity of the searched stock. Businesses that possess an enormous volume of proprietary data and mark it accessible to customers may possibly over as an auxiliary confidentiality feature the capability to exploring it using Sensitive Information Retrieval.
In 1995 [1] SIR was first time proposed. With respect to the proposal [1], an information in theory protected SIR solution will permanently needed communicating data at-least proportionate to the size of the database. In view of this, a number of way out projected in [1, 2], which include initial duplicating the database among more than one server, by which the transfer complexity was much lesser in between the user and the databases. All the mentioned solutions necessitate the servers not to connive to each other in direction to keep the query protected in communication. It might not be a convincing theory. Therefor a new concept was introduce [3, 4], in which a single-server computationally secretive SIR was existing, where the query secrecy hang on computational toughness expectations slightly than data theoretic safety. Since then Sensitive Information Retrieval (and more generally, Sensitive search) has been a most demanding field of research. In earlier years [5–8] there were numerous proposals of SIR systems has been introduced by the researchers.
DB-query-encryption concepts
In the DB-Query-Encryption [9] model, a user with a query desires to selectively explore data from a cloud database that has access to a 1 stream 2 of records. The query user, who supposed to identify the organization of the information, communicates to the query responder to in which fashion every record by means of a query schema file will be processed. This file stipulates to the Query responder how to extract the information and send back data from the cloud record. The query user has a secretive list of precise selector values known as the targeted selectors, and requests to acquire the received data for all records, the values which matched with the one of the among targeted selectors, but deprived of exposing the targeted selectors to the query query responder.
Suppose there is a situation where the records may have the rows of a table or view in the form of relational database, then the query schema have to stipulate for which one table column to be used as the selector field and for which table columns to be explore as the returning data. For all the information, which processed in this operation are not hidden from the query query responder, because the query query responder needs to operate on those. In this process, the selected values of the targeted selectors are secure.
DB-Query-Encryption processes in the following steps:
Query generation
The Query user produces an encrypted query file that will be directed to the Query responder. This file just contain the encrypted query. The substance of this file contains list of cipher text data, which securely retrieves the information around the targeted selectors. The query file moreover contains the query schema in plaintext manner. Within this process of generating the query, file a decryption key also generated. That decryption key securely kept by the query user for further steps in decryption of explored data after query.
Response generation
Once the query responder receive the query file, it process the query file with related records in the stream. For every selected record, the Query responder extracts its selector S and return information I based on the query schema, and then executes a cryptographic action that “inserts” I into an “encrypted buffer” that either keeps or rejects the data founded on the value of S. Here the Query responder executes the alike operation on all the selected records, whereas the homomorphic encryption procedure did not identify whether the data rejected or kept. Finally, the encrypted buffer is reverted to the Query user in a response file. For optimal usage of the memory and disk for processing a determined stream or a large database, the Query responder send back response files and flush off the encrypted buffer time to time. The capability to reject data defines that the response file that is send back to the Query user in the form of lesser data than the total amount of responses data.
Response decryption
As the Query user retrieves the response files; it will be decrypted with the help of decryption keys and extract all the returned data from those records that will permits from the filtering process. So final records included all those records which selector S matches one of the targeted selectors. Within this, the percentage of non-matching records might take as false positives, which is in small in figures. Supplementary evidence (ex.: a checksum of the record selector, or the selector itself) might include in the response data to permit the Query user to recognize and reject these false positives.
Homomorphic encryption
Encryption translates a plaintext p into a cipher text
Paillier encryption
DB-Query-Encryption comprises the optimizations techniques to the Paillier cryptosystem, which are included in [12]. In this section, we define the basic system only, deprived of those optimizations.
Paillier cryptosystem, uses the two large random prime number p and q of approximately of same size to compute the public key N =p.q. The decryption key consists of the factors p and q. now from the generated public key N we can enable the encryption process of plain text, whereas the decryption key required for decrypting the decrypted cipher text. This arrangement is alike to that of the extensively used RSA cryptosystem [13].
In Paillier cryptosystem the plaintext can have values in the range of {0, …, N-1}, whereas in the cipher texts will yield on values in the higher range {0, …, N2 -1} 3 . Therefore, in simple words, the cipher text will have twice the range of the plain text (with expansion factor 2). Meanwhile the protocol for DB-Query-Encryption includes transferring cipher texts, this proportion is an extent of exactly how efficiently bandwidth used to transmit data.
The bit length of N; determines the safety of the Paillier system; this consideration called the (Paillier) key size. Here “safety” determines the difficulty level of reversing the encryption process (i.e. exploring information 4 from cipher texts about the core plain texts) deprived of the decryption key. (Specifically, it should be challenging to conclude the decryption key assumed only the public modulus N.) [14, 15] determines the suggested key sizes with suggested plain text and cipher text sizes for three different safety levels 5 .
Encrypting a plaintext x encompasses producing an arbitrary value r
The “noise factor” r
N
efficiently hides the plaintext value x. To recovering the plain text, we requisite r to be an invertible component of
With the help of randomness approach the encryption process, generate different cipher text for the same plain text. In detail, the Paillier cryptosystem provides the following crucial semantic security property; where a unauthorized user (without the decryption key) cannot determine whether those cipher texts are generated from the same plain text or it generated from the another plain text.
The Paillier scheme contains following homomorphic property: For given two cipher texts E1 =
Inspite of using “ = ″ we are using “ ∼ ″,
For future use, we will correspondingly require the subsequent second homomorphic property:
This is essentially just a consequence of equation 2, since
Decrypting of cipher text is performed using the decryption exponent λ = LCM (p - 1 ; q - 1) , which can be calculated from the Sensitive key
6
. We also require the value w = λ-1 mod N . The values λ and w may be precomputed and stored as part of the Sensitive decryption key.We can now write down the formula for decrypting a given cipher text E = (1 + xN) r
N
mod N2 :
The main object to working of this equations is that Nλ is the “exponent” of the collection of units
Homomorphic encryption is one of the active field of the research, e.g. [7, 18], and from now on a lot of researcher proposed modified Paillier cryptosystem in view of the Sensitive information retrieval. Between all those proposals two proposals getting solemn attention are the Brakerski-Fan-Vercauteren [19] and Brakerski-Gentry-Vaikuntanathan [20] systems. These two approaches were based upon the principle of mathematical objects known as lattices. While the lattice-based approaches are still progressing, they assurance numerous possible benefits over the Paillier approaches:
Flexibility
The latest proposed approaches are fully homomorphic or at least somewhat homomorphic, by which the users can accomplish both addition operation as well multiplication operation over the core plaintext just by functioning with cipher texts. This can potentially permit surplus difficult SIR queries.
Speed
Methods such as the Number Theoretic Transform allow faster plain text and cipher text operations in convinced lattice-based schemes [21].
Post-quantum security
The improvement of an operative full-scale quantum computer, assumed by some researchers to be attainable within two eras away [22, 23], would fully break all present factoring-based cryptography, as well as the Paillier cryptosystem. In spite of important work, there are at present no recognized effective quantum computer-based attacks on well-designed lattice-based systems like proposed in [19] and [20].
On the other hand, except for the probability of a quantum computer, the Paillier approach has few benefits over existing lattice-based homomorphic encryption approach, so there may be exciting tradeoffs to deliberate when selecting among different approach:
Known security
Factoring-based cryptography has been everywhere for much longer and has withstood important for a much longer time.
Lower expansion ratio
The expansion ratio for existing lattice-based approach is at least quite a few times longer than that of the Paillier approach, therefore, Paillier approach consume lesser bandwidth to transfer the similar quantity of information.
Whereas DB-Query-Encryption at present only uses the Paillier cryptosystem, provision for a lattice-based approach is being developed.
SIR with homomorphic encryption
With the concept of Paillier approach, we can now answer the basic problems in SIR: suppose a query Responder with a list of indexed data elements x1, …… , x n , how can a query user explore the i - th element x i from the query Responder without disclosing i to the query Responder? For this, we neglects the insignificant solution where the query Responder simply just sends the complete list to the Query user. We assume that the list elements are representable as plain texts within the Paillier approach, i.e.0 ≤ x j ≤ N - 1. The solution for the problem, we are explaining here derives from [24] and is the preliminary idea of the DB-Query-Encryption protocol.
The Query user initially generates a Paillier modulus N and the linked decryption key, and then formulates a list of n cipher text values E1, …… , E
n
, where E
i
(conforming to the secret index i) is an encryption of the plain text value 1 and all the further values are encryptions of zero:
We calls it as the query components.
The Query user refers the public modulus N and the well-ordered list of query components E1, …, E
n
to the Query Responder, while possessing the decryption key (factors of p and q) Sensitive. Because of the randomized function of Paillier encryption approach, the E
i
will be indistinguishable to the query Responder from entirely arbitrary cipher texts. Note the significance of semantic safety subsequently there are recurrent encryptions of the sample plain text (zero) but they will all be dissimilar, seemingly entirely arbitrary values. In specific, the query Responder will not be capable to tell which record relates to the plain text value of 1. The query Responder now adjusts an accumulator R ← 1(a Paillier cipher text value) and apprises it for respectively element in the list x1, …… , x
n
:
When the Query user decrypts this value the user acquires the preferred element x
i
in the list. To understand why this is the situation, we can practice Properties 2 and 3 to trail what is processing through the accumulator. The preliminary value of R is 1, which is a appropriate encryption of the zero plain text. For each repetition of the loop except for the i-th one, the query element E
j
being used is
We can visualize this procedure as in Figure 1. The metaphor of a box used to signify a cipher text comprising data. Figure 1(a) shows a sole box demonstrating the cipher text accumulator R from the query Responder’s opinion of observation. This box has n diverse cells, with each element x
j
being concentrating to its individual cell by its equivalent query element E
j
. Only the i-th cell is “real” (i.e. can hold data, because
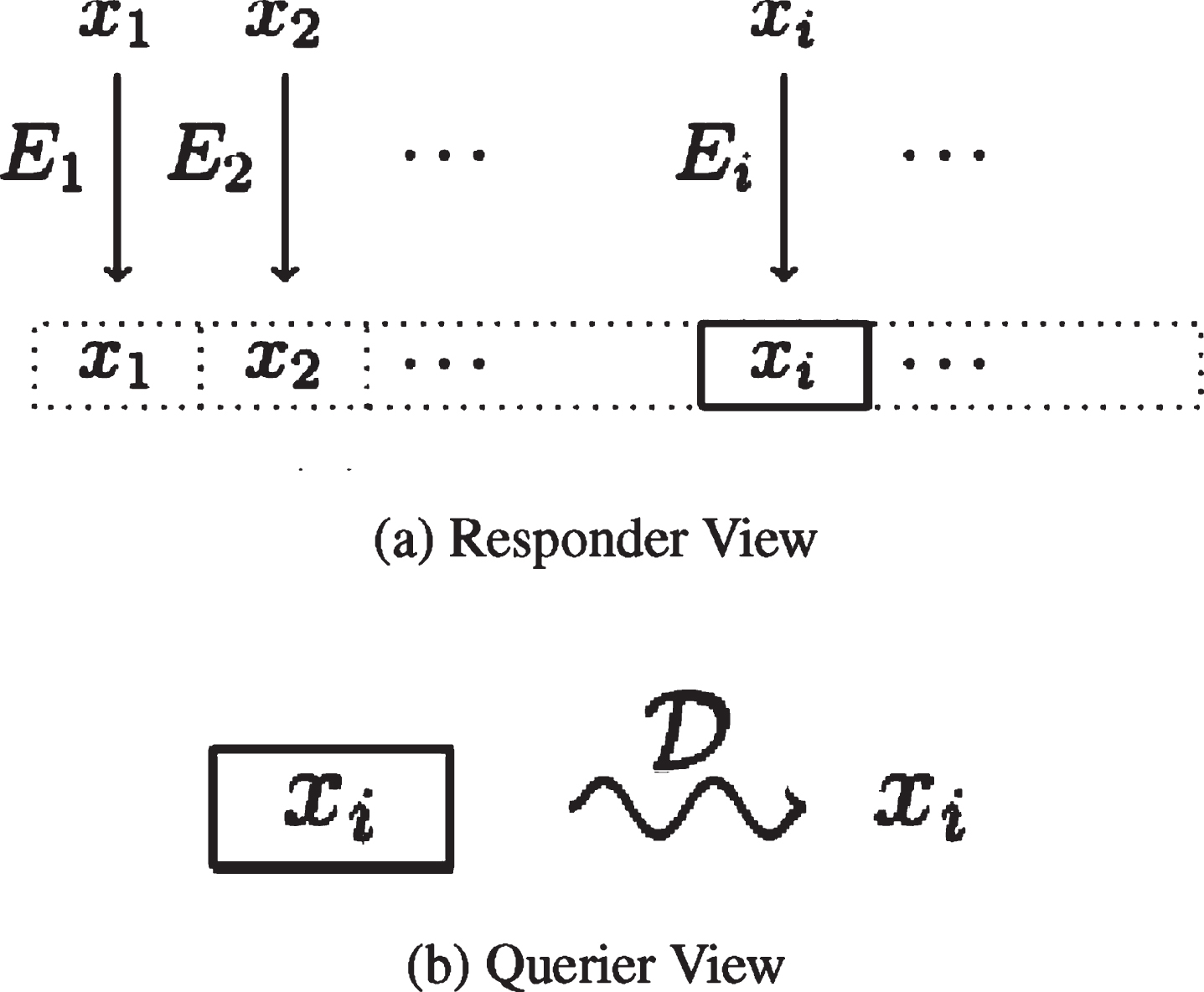
Basic SIR Filtering.
This section defines how DB-Query-Encryption encompasses the basic Sensitive Information Retrieval clarification in Section 4 to handle numerous equivalent records and numerous targeted selectors, as defined in Section 2. We construct upon the exposition in [25], which lays out the algorithms for the novel Pirk scheme. During this section, we delight the records as a stream of selector-return data pairs (T, D).
In view of researcher’s suitability, we comprise here a table 2 “table of notation”. Those expressions which are not previously presented, will be clarified with table 2.
Paillier Cryptosystem key size and respective plaintext and cipher text sizes for three different safety levels
Paillier Cryptosystem key size and respective plaintext and cipher text sizes for three different safety levels
Table of Notation
The simple explanation in Section 4 handles data indexed from 1 to n. To handle extra general selector places where the total of promising selector values is enormous or limitless (e.g. full names of users), DB-Query-Encryption usages a hash function7 H to translate selector values into numbers, alike to the method proposed in [27]. The outputs of H are ℓ-bit numbers, where the parameter ℓ is defined as the hash length. The encrypted query file now comprises 2ℓ cipher texts E0, …, E2ℓ-1, each conforming to one likely output value of H. This displayed in Figure 3. For each record, the hash of the selector (the full name in this sample) now concludes which query element E j to use, and thus which cell the yield data drives into. The list of query elements was organized using “Smith, John” as the targeted selector, so E7 is an encryption of 1 and corresponds to the only “real” cell in the image.
Since each cell can only comprise one data item, it is necessary to pick a large value for ℓ to reduce the possibility of hash collisions. However, since each E j is characteristically numerous hundred bytes long (Section 3.1), ℓ cannot be bigger too much deprived of creating the query file excessively large. Therefore, there may be a applied upper bound on ℓ of about 20 or so.
Handling multiple selectors via slicing
DB-Query-Encryption makes well-organized use of bandwidth and permits better query elasticity by permitting several targeted selectors inside the same query. To handle τ targeted selectors, we preference a bit width b (the chunk size) and use plaintexts of the form
Query generation is improved to handle slicing as follows. Symbolize the τ targeted selectors by T0, …, Tτ-1. For nowadays assume that their ℓ-bit hash values are different. The query elements E0, … E2ℓ-1 are now selected so that each E
i
is moreover an encryption of a power of two 2
jb
(i.e. a 1 in the j-th plaintext “digit” location) or an encryption of zero:
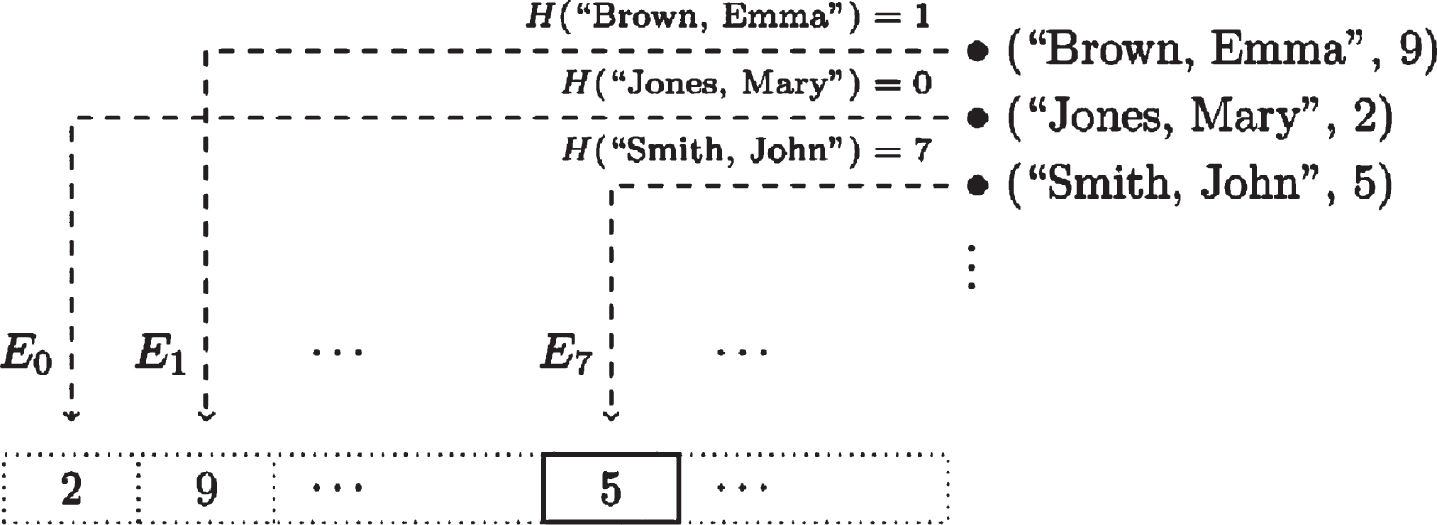
Handling large selector space via hashing (Responder view).

Handling multiple selectors.
This scheme would still work even if some of the targeted selectors have the same hash value, but the Query user would need additional information to determine which selector the recovered data corresponds to, since that information is no longer determined by the digit position alone. DB-Query-Encryption tries to ensure that different targeted selectors have different hash values if possible by using a randomly generated 32-bit hashkeyk as part of the input to H. If a hash collision occurs, a different hash key k′ is tried, up to a certain maximum number of tries.
To handle return data that are longer thanb bits, the data splits into b bit chunks that are handled sequentially with separate cipher text accumulators. New accumulators are created as necessary. A counter used for each of the 2ℓ possible selector hash values to track which accumulator to use next to store a chunk of data for that hash value (Figure 4).
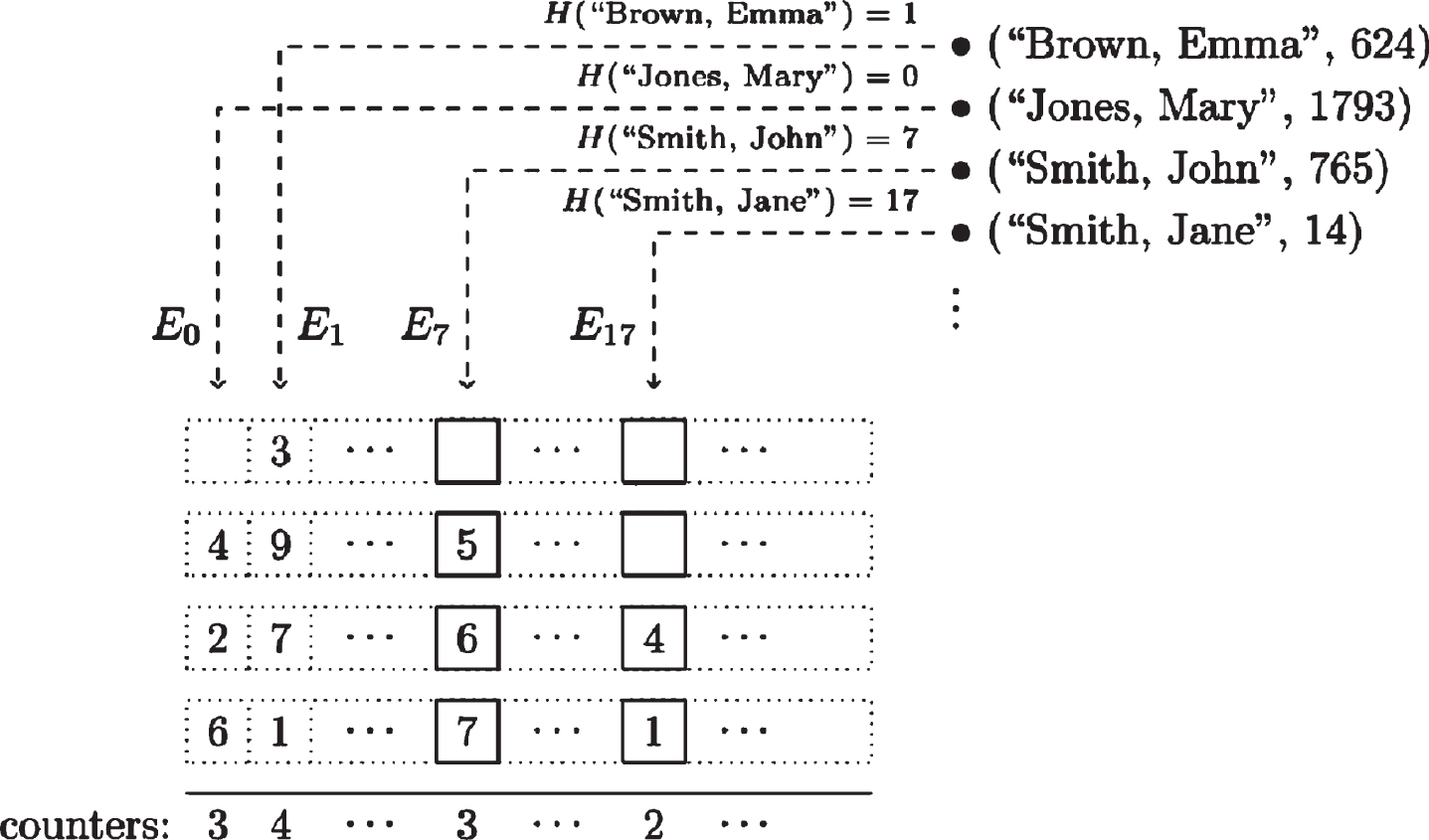
Chunking (Query Responder view).
If (T, D) is a data record and H (T) happens to match the hash value of one of the targeted selectors T j , then the return data D will be included in the DB-Query-Encryption response. This is called a false positive. Since the selector hash function H has a limited output range (ℓ-bit values only), this is expected to occur in practice for a small percentage of records. The rate at which this is expected to happen for non-matching records (T ∉ { T j }), known as the false positive rate, depends on the various parameters and the nature of the database. If we expect selector values to be very diverse, so that the hash value is more or less uniformly random, then a random non-matching selector has a τ/2ℓ chance of having the same hash value as of the targeted selectors. (For example, for τ = 100 targeted selectors and hash length ℓ = 20 we would expect roughly 1 in 10,000 of all non-matching records to be retrieved.) In general, the false positive rate can be reduced by increasing ℓ (thus increasing the size of the query file), or (with lesser effect) decreasing τ.
The user should ensure that the return data allows the Query user to decide whether or not it is a false positive. DB-Query-Encryption provides an option to prepend to the return data a 32-bit auxiliary hash value Haux (T) of the selector. During response decryption, the Query user compares this second hash value included in the return data with the expected value Haux (T j ) and silently drops the data if the hash values do not match.
Putting it all together
We now put the preceding ideas together and encapsulate the primary algorithms used in DB-Query-Encryption. The Query user first generates a Paillier key pair N, p, q as in Section 3.1, then runs Algorithm 1 to create the query. The input to Algorithm 1 includes the Paillier public key N and a list of targeted selectors {T0, … , Tτ-1 }, and the process returns a hash key and a list of query elements. The algorithm uses the Paillier encryption operation
1:
2:
3:
4: H ← Hℓ,k
5:
6: h j ← H (T j )
7:
8:
9:
10:
11:
12:
13:
14:
15:
16:
17:
1:
2: H ← Hℓ,k
3: c ← 0
4:
5: c i ← 0
6:
7:
8: h ← H k (T)
9: D0 ∥ … ∥ Ds-1 ← D
10:
11:
12: Y t ← 1
13:
14:
15:
16:
17:
18: c h ← c h + s
19:
20:
21:
Algorithm 2 encapsulates the query response generation process as the Query Responder processes the query against the data stream
1:
2: H ← Hℓ,k
3:
4:
5:
6:
7:
8: R j ← {}
9:
10: D ← Xst,j ∥ Xst+1,j ∥ ⋯ ∥ Xst+s-1,j
11:
12: extract included auxiliary hash value haux from D
13:
14: R j ← R j ∪ {D}
15:
16:
17:
18:
19:
20:
Distributed Processing
The Responder’s work can be distributed amongst multiple processors to increase throughput. The method described here is an elaboration of the method in [25, 28].
By regarding the power
(where the d
i
are plaintext values coming from data chunks) as a matrix product of a row vector times a column vector:
The work to compute this vector-matrix product can be parallelized by partitioning the query element indices 0, …, 2ℓ - 1 and/or the column indices 0, …, r - 1 into subranges. The work for separate subranges can be performed independently.
1:
2: H ← Hℓ,k
3: w← ⌈ 2ℓ/m ⌉
4:
5: H j ← { jw, …, min { (j + 1) w, 2ℓ - 1 }}
6:
7:
8: i ← H (T)
9: j← ⌊ i/w ⌋ (j, i, D)
10:
11:
12: initialize M to a
13:
14: c i ← 0
15:
16:
17: D0 ∥ … ∥ Ds-1 ← D
18:
19:
20:
21: Mi,c i +t ← D t
22:
23: c i ← c i + s
24:
25:
26:
27:
28:
29:
30: Y t ← 1
31:
32:
33:
34:
35:
36:
The modified procedure is shown as Algorithm 4. This version also assumes that the return data has a fixed size of sb-bit chunks. To divide the work amongst mprocessors P0, … Pm-1, we split the range of possible hash values 0, …, 2ℓ - 1 into m disjoint ranges
This time we use a fixed number r of ciphertext accumulators (the matrix width). Records (T, D) that do not fit into the accumulators (c H (T) + s > r) are discarded for this iteration of the algorithm and must be reprocessed by the next iteration.
Conclusion
In this paper, we have introduced the core concepts and algorithms behind DB-Query-Encryption system that supports Sensitive Information Retrieval queries. These algorithms include the Paillier homomorphic encryption scheme as well as the algorithms for query generation, response generation, and response decryption. The algorithms are highly parallelizable, so DB-Query-Encryption can handle large databases with high throughput on distributed systems. The algorithms are also tunable via parameter selection to enable optimizations for specific query conditions. With support for a lattice-based encryption scheme to be added in the near future, DB-Query-Encryption will become even more efficient in addition to achieving post-quantum security.
Footnotes
The algorithms used in DB-Query-Encryption can be adjusted to handle more complex data flows with numerous sources.
This could be a finite stream, e.g. the rows of a database table, or a stream that runs indefinitely, e.g. a Medical Research topic.
He usable decrypted cipher texts are the values in {1... N2- 1} that are relatively prime to N.
For case, fully recovering one or more than one plaintexts, or decisive whether two dissimilar cipher texts characterize the identical plaintext.
The safety level calculated in terms of the predictable calculation effort it receipts to breakdown the system. Even though not sanctioned by the U.S. NIST for protective U.S. federal government information [![]() ], safety levels underneath 112 bits might nonetheless be satisfactory for few applications.
], safety levels underneath 112 bits might nonetheless be satisfactory for few applications.