
Abstract
The prevailing vehicle recognition technology is adversely affected by the environment such as complex traffic scenarios and weather conditions. This paper proposes a robust vehicle recognition model based on human memory mechanism named Memory-based Vehicle Recognition Model (MVRM). Motivated by the success of memory and attention mechanism, we explore some features of human visual attention model. Fusing short term and long-term memory modules together yield deeper architectures recognizing increasing complex environmental scenarios. Firstly, a rare motion feature has been introduced to measure the visual salience, which improves the accuracy of the visual attention mechanism. Second, a model of vehicle salient region recognition has been established. The results of experiments show that the dynamic vehicle recognition rate of MVRM is 77.10%, while its false recognition rate has only a nominal value of ∼4.5%. Furthermore, the model offers good recognition of vehicle targets under complex environment conditions related to weather and road traffic.
Introduction
Autonomous vehicles have ushered in a new era of development opportunity with the increasing number of vehicles worldwide [5, 18]. Vehicle recognition has become an important element of intelligent transportation systems (ITS). Vehicle detection based on an algorithm has been an emerging trend in recent decades. Vision-based algorithms can be classified on the basis of four factors: prior geometric features, stereo vision, template matching, and motion [23]. Ershadi et al. [17] proposed a method to identify, track, and count vehicles in dusty weather with a vibration camera using an improved background subtraction algorithm. Cai et al. [25] proposed a semi-supervised tracking algorithm based on depth representation and transmission learning, which suppresses the drifts generated during the tracking of a vehicle effectively. Li et al. [19] designed a system to identify and extract the visual tags of vehicles based on Internet of Things. The system was also capable of removing haze from an image for improved tracking and recognition of vehicles on urban roads. Hsieh et al. [8] proposed a method to divide the image of a vehicle into multiple grids and used an ensemble classifier for identification. Kafai et al. [12] employed hybrid dynamic Bayesian network to process the feature sets extracted from vehicles. Karaimer et al. [3] extracted vehicle outline information from multiple silhouettes for classification and cross-validation. Zhao et al. [11] used the index of vehicle model information to form a hierarchical clustering-based algorithm for classification of vehicles.
All these research studies highlighted the significance of vehicle detection, but the accuracy of algorithms in real time still needs to improve. Most importantly, these algorithms are not sufficiently robust for the complex road environment in China. In this regard, a vehicle target recognition system based on human memory is introduced in this paper. We proposed a hybrid model which capitalized on human memory and visual attention mechanisms for rare motion features. The system, which is based on the information-processing mechanism of a human brain for similar scenes and targets, is proved be more accurate in identifying vehicles in complex environments.
Visual attention model incorporating rare motion features
Rare feature computation
Traditional models of visual attention ignore the perception of human eye that a region in a moving object is noticed when its features are significantly different. Two factors determine the salience of a feature: the rarity of a feature in an image; and the close distribution of eigenvalues in space.
The rarity of a characteristic value in an image can be measured by calculating the number of times the feature appears in an image [26, 27]. If the grey level of a feature map is [0L - 1], I
k
is one of the eigenvalues. The probability of occurrence of each eigenvalue is
The spatial distribution density of eigenvalues is considered in this study. The number of pixels with the characteristic value of I
k
is n
k
. Furthermore, (x
i
, y
i
) are the coordinates of the i
th
pixel with its characteristic value. Subsequently, the centroid coordinates (x
c
, y
c
) of a pixel with a characteristic value I
k
is:
Based on the pixel coordinates (x
i
, y
i
) and the centroid coordinates (x
c
, y
c
), the average horizontal distance D
x
and the average vertical distance D
y
between the respective coordinates of pixel and centroid are calculated as follows:
Thus, the spatial distribution density of the eigenvalue D
k
can be calculated as follows:
Using both the characteristic rarity measure P (f (x, y)), and the spatial distribution density Df(x,y), the visual salience result SR (x, y) of the pixel (x, y) with the characteristic value f (x, y) can be calculated by Equation (4):
When there are numerous colour categories or similar proportions in an image, the salient regions obtained by using the measure of rare salience mainly focus on the edges or complex background regions where changes in visual features are sharp. Changes in the characteristics of the foreground target are relatively negligible, and therefore the prominence is inconspicuous. The significant area obtained by the significance measure of motion optical flow compensates for the defects in local significance measure to a certain extent, but it produces plentiful false detection and reduces the detection accuracy. Therefore, considering the advantages and shortcomings of the rare feature and moving optical flow characteristic, the two features are combined into a single feature known as rare motion feature. Combining the rare motion features into the same moving target area is the main objective of this study. This paper defines four merge rules.
Rule 1: The seed region has high similarity with the adjacent regions.
The function representing similarity between regions is defined in this paper. According to the similarity criterion, salient regions representing the moving targets are selected as seed regions, and the similarity function is used to measure the similarity between the seed and adjacent regions [1, 7]. A region is merged with the seed region only if its similarity value is greater than a set threshold [2]. The neighbourhood of a seed region Ri is defined as
Rule 2: The minimum distance between the adjacent and seed regions should be less than a threshold.
The Euclidean distance between two regions is approximately the distance between the largest circumscribed circles of two regions. The region adjacency relationship is shown in Fig. 1.
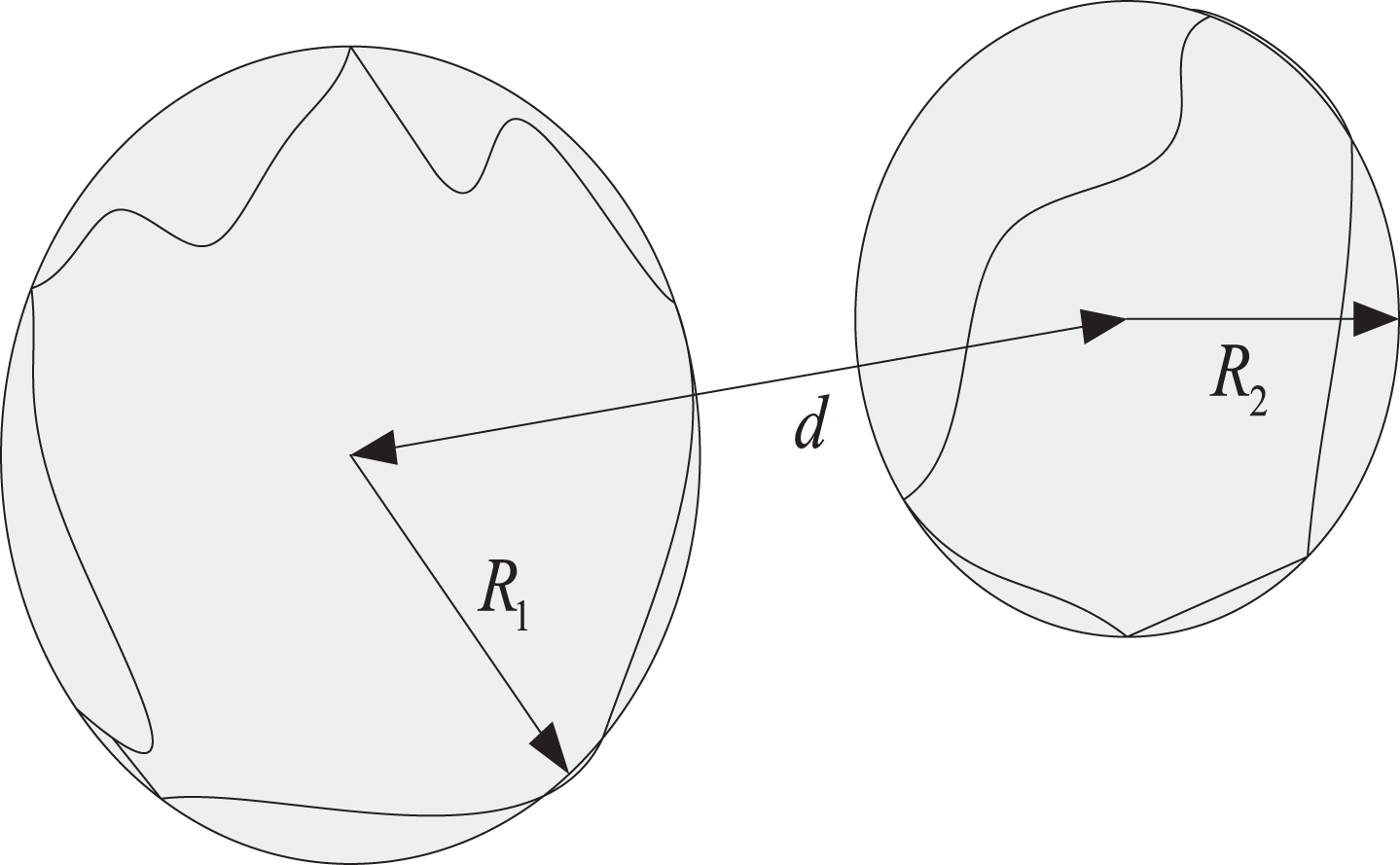
Region adjacency relationship.
R1 represents the maximum circumcircle radius of the seed region Ri, R2 represents the maximum circumcircle radius of the adjacent significant region Rj, and d is the distance between the centres of the two largest circumscribed circles. The variable γ determines the distance relationship between the two regionsas follows:
When γ satisfies a certain threshold, the two regions are considered to be close to each other.
If the two regions are close to each other and the motion vectors are approximately the same, then both the regions are combined according to the aforementioned rules considering that they are the same motion target regions.
Rule 3: If the above condition for merging is not satisfied, the adjacent salient region is defined as a new seed region for merging with salient regions that belong to the same moving target.
Rule 4: A region is discarded, if the number of pixels in that region is less than the set threshold value and cannot be incorporated into the seed region.
A region obtained according to the above rules is considered a salient region based on the rare motion characteristics of the target.
A pixel in the salient region obtained through the calculations of rare salience and optical flow field contains motion vector. For calculation purposes, the motion vector is denoted as d, which is represented by a set of mutually perpendicular vectors u and v:
The motion vectors d are projected at 0°, 45°, 90°, and 135° to obtain the vectors in these four directions.
Using the rare motion vectors obtained as above based on the center-surround computations, the corresponding four sets of rare motion salience map can be obtained [6, 14]. All the salience maps obtained in this manner are combined to obtain a unified salience map, using the human visual attention model. Each salient area in the final salience map is then studied using the competition mechanism [15, 22].
Human memory mechanism modelling
The current algorithms have a few limitations in recognizing a vehicle target under complex environments such as rain, snow, night, and shelter. For example, a fast algorithm has a low detection rate and an inability to handle occlusion of multiple vehicles. In contrast, an algorithm with a high detection rate is computationally intensive, but it exhibits inability to ensure real-time identification [13, 24]. Regardless of the completeness of a detection target or the changes in the environment of the target, humans can quickly and accurately identify the target. According to neurophysiology and cognitive science, the ability of humans to robustly identify targets and scenes of interest in complex environments is attributed to the well-established memory mechanisms. In recognizing a target, the information related to the target are extracted from memory. Subsequently, the memory mechanism matches the target with the existing memory mode to speed up the recognition of new things and adapt to the new environment [21].
Inspired by the processing of visual information by human memory mechanism, a model to recognize the saliency map of vehicle target (memory-based vehicle recognition model, MVRM) is proposed, which simulates the memory mechanism recognition of a vehicle target under complex scenes and conditions by using similar scenes, events, and modes experienced in the past [20]. While performing vehicle target detection, the MVRM itself can learn and store in real time, constantly adapting to changes in the scene.
The basic idea of this model is described below. Under the given input conditions, it is required to find a match for the current input in the empirical knowledge (memory space). The saliency map for a new frame is first compared to the features stored in short-term memory, and the vehicle is categorized based on comparison results. If the vehicle is identified in the saliency map, only the memory space needs to be updated; otherwise, the features need to be searched in long-term memory space to determine the vehicle category. The model is shown in Fig. 2.
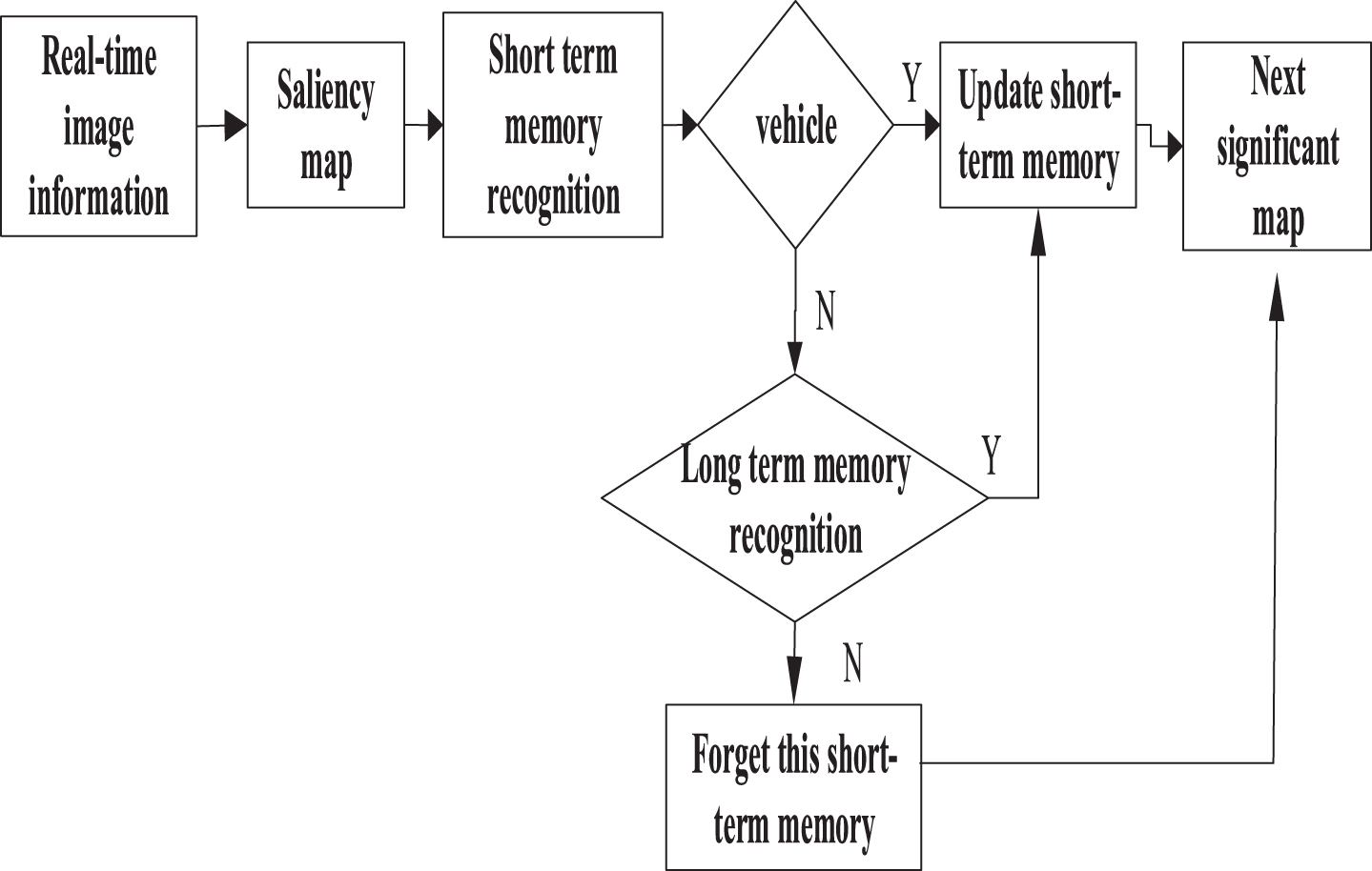
Target recognition based on human brain memory.
MVRM is defined as a quadruple: 〈Si, Mt, Cog, Rul〉.
Si, which represents significant graph information, Pos and Feat, is the basic processing unit of MVRM, where Pos indicates the position of the saliency map and other information, and Feat indicates the feature of saliency map.
Mt (Memory type)=〈Sm, Lm, Output〉 represents the type of information storage. Sm represents short-term memory, Lm indicates long-term memory, and Output represents system output.
Cog (Cognitive)=〈Sc, Lc〉 indicates the cognitive behavior of target recognition and memory space update. Sc represents short-term memory cognition, and Lc represents long-term memory cognition.
Rul(rule)=〈rulesc,rule1c〉 represents the behavior specification for the system to update the memory space. Furthermore, rulesc represents the rules of behavior when Si is matched in short-term memory space, and rule1c represents the rules of behavior when Si is matched in long-term memory space.
Pos (position) represents current location of the saliency map and area of the smallest circumscribed rectangle of the significant image. Because the trajectory of the vehicle is continuous, the prominent position of the adjacent two-frame vehicle can also be approximated as coincident. By comparing the saliency map with the information stored at the location of the saliency map in short-term memory, it is possible to determine whether the target in the current saliency map is the same vehicle.
Feat (feature) represents the features of a saliency map, including the contours of the target in the saliency map and gray values. By comparing Feat with the information stored in long-term memory, it is possible to determine whether the target contained in the saliency map is a vehicle target.
Information storage type: Mt
Sm (short-term memory) is a location in the previous frame for a collection of vehicles, which can simulate human short-term memory. Assuming that there are n salient regions in the saliency map of the previous frame and the salient regions of the ith region are denoted by pj, then Smcan be expressed as (11):
While processing the saliency map of the next frame of image, it is first determined whether the saliency map substantially coincides with the position of the vehicle in the previous frame or not. If coincident, it is considered that the target of the saliency map is a vehicle, and Sm is initialized to empty.
Since the vehicle is a rigid structure, its shape is relatively fixed; hence, even the minimum circumscribed rectangle of the vehicle satisfies certain constraints. The vehicle target geometry model has the following constraints:
(1) The geometry of the model should satisfy certain constraints. The inner product of vector ab and vector cd in the trunk section of the vehicle needs to be controlled within a certain range; the ratio of the length of segment ab to the length of segment cd needs to be within a certain range, without being too wide.
(2) Assuming that da,db,dc, and dd represent the lengths of the sides of the vehicle geometry model, J represents the sum of them:
Because the length relation of the four edges of the geometric model has a range, the value of J needs to be limited to a certain range.
(3) The diagonal length of the geometric model of the vehicle target means the size of the car in a certain sense, and therefore some constraints need to be satisfied.
Lm (long-term memory) represents a collection of characteristic information of vehicles learned by sample training, thus simulating human long-term memory. In this study, linear support vector machines (SVMs) are used for training and learning. The basic idea of training and learning based on an SVM is that if the characteristic model of the vehicle target is known, its characteristic vector can be obtained from the training set. According to the training picture, a feature vector can be represented as (xi, yi), i = 1, 2, 3, …, n, where xi represents the feature vector obtained from a feature model, and y
i
indicates whether the image is a positive or negative sample. If the training picture is a positive sample, yi = -1, and if it is a negative sample, yi = -1; furthermore, n represents the number of training samples. For a dichotomous problem, it is easier to obtain its loss function as:
The optimal weight vector k* and the optimal bias β* can be calculated using the expressions as follows:
Short-term memory is a complex system of information storage and processing that controls the direction of information flow. In contrast, long-term memory can be considered as a large and complex information base, which has relatively large capacity and long retention time. It stores conceptual information such as empirical knowledge. The stored information can be recalled to recognize various models and to solve various problems. Recognition of vehicle targets using short-term memory needs to consider only the location information of the salient map, while that using long-term memory needs calculation of the outline of the saliency map, grey value, and other information. Therefore, recognition using long-term memory is more time-consuming. Accordingly, short-term memory is first used to recognize the target, and in case it is not successful, then the long-term memory is used. This approach can help shorten the time taken for target recognition and is more conducive for a real-time recognition.
After recognizing the salient regions using the MVRM model, the salient regions not associated with the vehicle target can be removed, and then the significant regions of the vehicle targets can be obtained. Assuming that m significant regions with vehicle targets are obtained, the output can be represented as:
In this expression, si indicates that the ith salient region in the saliency map (output) contains the vehicle target.
Sorting represents the order of position features of the salient regions in short-term memory. For consistency with the focus shifting strategy of the human visual attention mechanism, the position information of the significant map saved in Sm is sorted according to the salience of the significant regions. The higher the ranking, the better the match.
Sc_ Matching represents the matching rules between the elements in Sm and the regions of significant map to be recognized. Assuming that the central coordinates of the minimum circumscribed rectangles of the significant region to be matched are w(wk,wy) and the area of the minimum circumscribed rectangle is Sw, the corresponding significant area in Sm is pi, the center coordinate of its minimum enclosing rectangle is Pos(pk,py), and the area of minimum circumscribed rectangle is Sp. If Equation (20) is satisfied, the matching area is considered as the vehicle target,
Sc_ Update represents the update process for Sm. If the elements in Sm are not found to match with current frame, then the update is skipped. Considering the tolerance, the elements in Sm store 10 frames of information. Similar elements in the memory space are merged by the current nearest frame, and thus, the number of elements in Sm is less than the sum of the elements of the 10 frames.
Comp_ Memrepresents the competitive memory behavior in Sm. When a new pi is required to be stored while Sm has reached its maximum capacity, there would be a competitive memory. We assume that the saliency region of the current frame is more important than the previous significant region; in the same frame, regions with higher saliency are easier to remember than regions with lower saliency.
Lc_ matching represents utilization of the results of the trained samples in a long-term memory space to recognize the target within the significant region of the input.
Lc_ Update represents the information update in the long-term memory space. If the target in the salient region is recognized as a vehicle, the vehicle information is input into the long-term memory sample, and the sample is trained to realize the update of the long-term memory space.
Based on the aforementioned analysis, the sequential steps of MVRM are as follows:
step 1: Sm is initialized to empty;
step 2: The first salient area of the saliency map in the first frame image is identified by Lm, and the salient location recognized as a vehicle is stored in Sm. The position of the elements in Sm is sorted by saliency of the saliency map;
step 3: The new prominent position of the input is identified by Sm. If the vehicle target is not found in significant area, the process is shifted to step 6;
step 4: Capacity of Sm is assessed. If the capacity is full, then Comp_ Mem is executed;
step 5: Sc_ Update for Sm,Lc_ Update for Lm, then the process is shifted to step 3;
step 6: Lc_ Matching by using Lm;
step 7: If Lc_ Matching determines that there is a vehicle in this significant area, the process is shifted to step 4; Otherwise, it is shifted to step3.
Vehicle recognition based on MVRM is shown in Fig. 3.
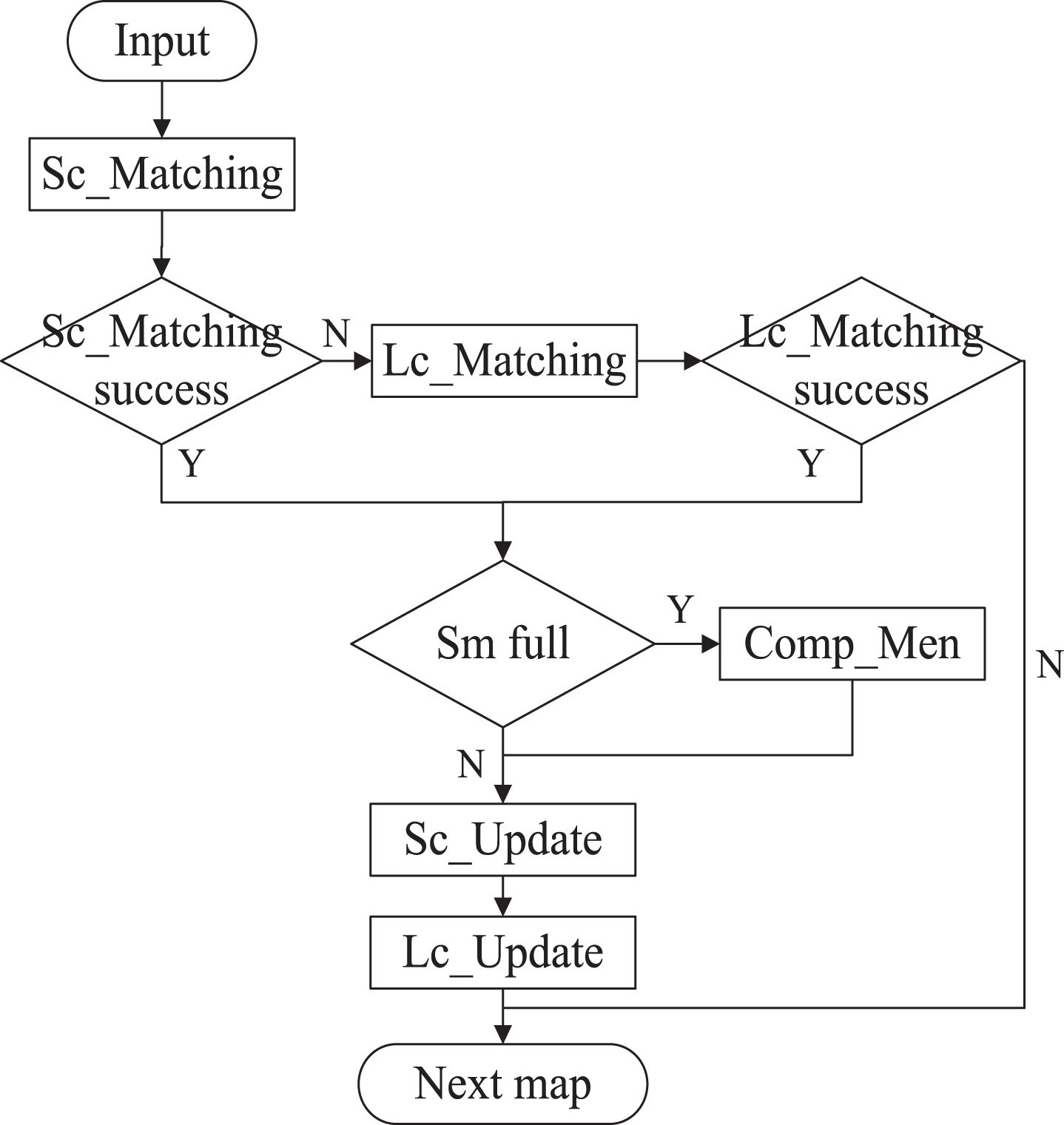
MVRM flowchart.
Experiment of saliency map acquisition process for moving vehicles
The video frame consists of several cars in comprehensive experiments scenarios. MVRM maintains memory stacks which allow for joint rare environment factors. The recognition process is described as follows: Fig. 4(a) shows the video frame; Fig. 4(b) shows the extraction of image features; Fig. 4(c) is the rare motion feature; Fig. 4(d) is a saliency map synthesized after the fusion of the rare motion features of the target, and the recognized saliency map is marked with a rectangle; Fig. 4 (e) shows the moving target; Fig. 4(f) shows the vehicle identified by MVRM.

(a)-(f) MVRM identification of vehicle.
The identification result is mapped to the original image, and the final recognition result is marked with a yellow rectangle. The result is shown in Fig. 5.

Vehicle identification results.
In order to validate the recognition performance of MVRM model in complicated road environments, the recognition of a vehicle was verified experimentally for different conditions such as traffic, weather, etc. The experimental data were derived from vehicle-borne video clips, downloaded from the network, showing vehicles moving in different traffic scenarios and weather conditions. In order to build a long-term memory library for vehicle recognition, the images containing vehicles appearing in different scenes were intercepted, thereby collecting 821 images of vehicle targets as well as 945 images of non-vehicle targets. All the images (1766 samples) were normalized into the standard image of 64×64. The entire set of 1766 images containing positive and negative samples were trained, and the visual features of the vehicle targets were built on the MATLAB platform. The characteristic vectors of vehicles were extracted to generate the long-term memory storage information of MVRM.
Figure 6 is the result of vehicle target recognition using the MVRM model for a number of traffic scenarios and weather conditions. It can be observed that the algorithm has a strong recognition performance for close-range vehicle targets. The recognition is found to be satisfactory even for a complex environment, but there are a few missed detections and false identifications. The reasons are listed as follows: First, the vehicle target may be too far away from the camera such that it appears too small in the image to recognize. Second, the vehicle target may be blocked by other objects in the image.

Vehicle recognition results under different scenarios. (a) Urban road, (b) Curve, (c) Night, (d) Rainy weather, (e) Highway, (f) Snow weather.
MVRM model exhibits memory learning abilities, and it can enhance the accuracy of vehicle target recognition by updating the short-term and long-term memory spaces constantly. The improvement of vehicle recognition accuracy owing to the MVRM model was mainly demonstrated in the long-term memory space. To verify the learning ability of MVRM model for long-term memory, 500 positive and negative samples were used to test the MVRM model in this study. The long-term memory space of the model was updated after verifying an image in order to simulate the memory process of the MVRM model. The recognition effect of the model was verified for every 50 images, and the learning ability curve obtained for the MVRM model is as shown in Fig. 7.
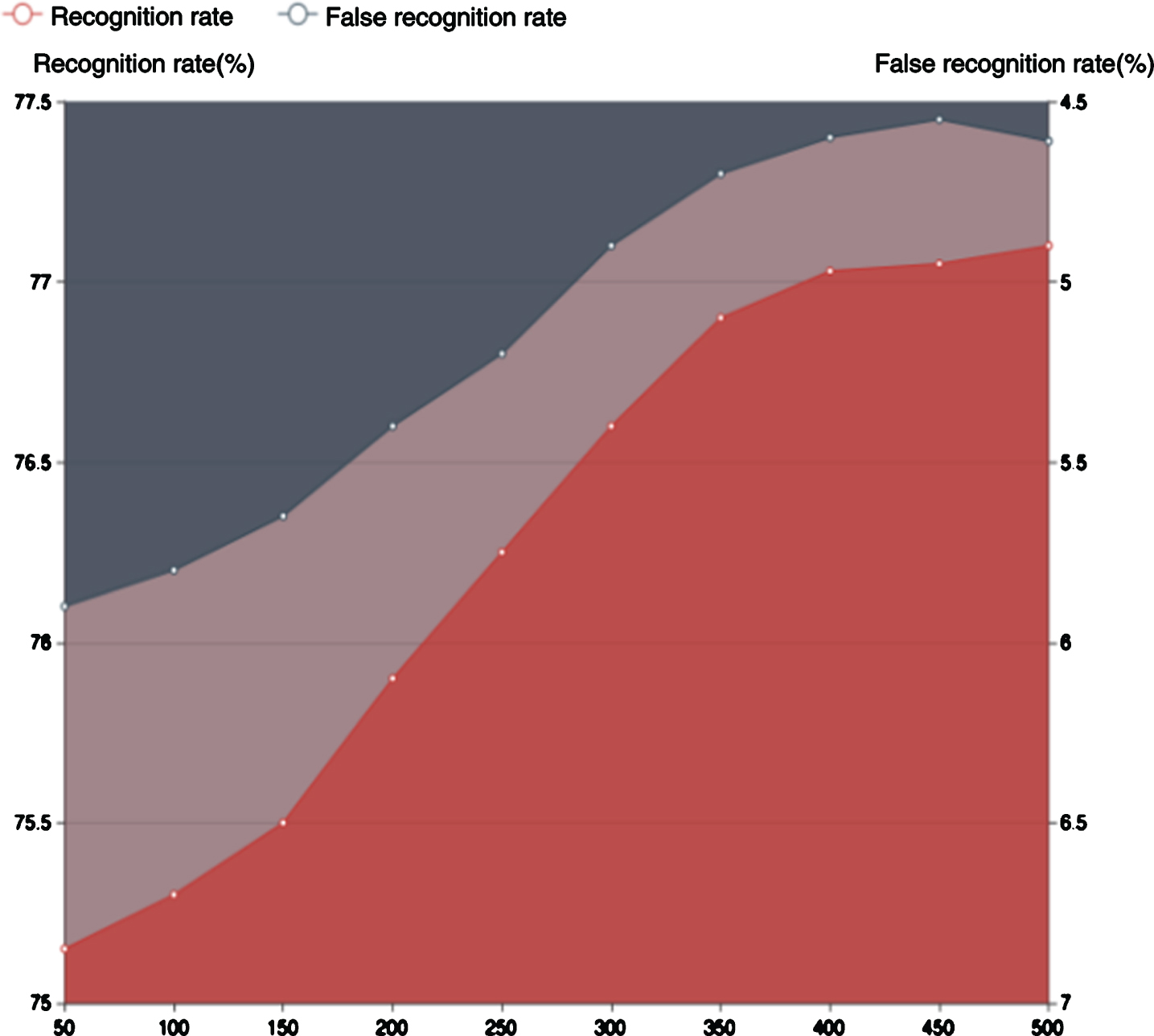
Memory learning curve.
The recognition rate of the vehicle target is found to increase as the MVRM model is updated until it reaches a steady level of 77.1%. With increasing number of test images, the rate of false identification of MVRM also shows a downward trend. This figure illustrates the enhancement of the recognition ability of the MVRM memory space model and the following aspects: (1) The MVRM model is robust as it is observed to adapt to the changes in motion scenes according to memory ability; (2) The recognition rate increases more than the false identification rate, and both the rates are almost stable near a fixed value, which confirms the stability of the model.
The MVRM model is analysed in this section. The recognition effect of MVRM model is verified by relevant experiments and compared with other advanced vehicle recognition methods. MVRM model is compared with three typical target recognition algorithms: the contourlet transform and SVM methods (Method I) [10], the gradient pattern and sparse representation algorithm (Method II) [9], and the methods based on weighted evidence theory and artificial fish swarm (Method III) [4]. The contourlet transform is multi-resolution in analysis, multi-directional, anisotropic, and so on, and can capture the contour features of an image effectively. Under common scenarios, the method based on contourlet transform and SVM can achieve a high recognition rate. In case the target attitude and ambient light change violently or there is an object similar to the target in the background, etc., the recognition offered by the gradient pattern and sparse expression algorithm is expected to be better. The methods of weighted evidence theory and artificial fish swarm can perform good real-time recognition without training and learning. In this study, the MVRM algorithm is compared with the aforementioned algorithms of high detection rate for recognition effect analysis.
The statistics of the recognition rate and false recognition rate as well as the calculated results of efficiency of these algorithms are shown in Table 1 and Fig. 8. Fig. 9 shows the ROC curve of vehicle target detection by these methods in a complex environment.
Detection efficiency
Detection efficiency
The results observed from Fig. 8 are summarized as follows: (1) For vehicle targets with complex environments, the MVRM has the lowest rate of error recognition. This result indicates that MVRM is more adaptive to complex environments than the other three methods; (2) Although the recognition rate of the MVRM model for vehicle target is not the highest, its value (77.1%) is very close to the highest recognition rate observed (method I, 78.5%). As the recognition rate is more than 75%, it is expected that the MVRM can satisfy all practical requirements in respect of this parameter.

Recognition performance.

Comparison of vehicle recognition effect.
The following observations are evident from Table 1: The training time of the MVRM model is much shorter than those of method I (the highest recognition rate) and method II, and the training performance is only slightly worse than that of the shortest training time method III; The real-time detection of MVRM model is slightly slower than those of methods I and II; however, as its training time is the shortest, the speed of detection and recognition can collectively satisfy the real-time requirements. Overall, considering the recognition rate, error rate, and real-time performance of vehicle targets in complex environments, the MVRM model is observed to be the most advantageous.
In this study, a vehicle saliency map recognition model for complex scenarios based on human memory is proposed for vehicle recognition. The model is inspired by the cognitive process of human memory mechanism for visual information processing. MVRM revealed collaborative memory mechanism and training feedback for vehicle recognition. It is used to express the information processing mechanism of the human brain for similar scenes, events, and patterns experienced in the past. Combining the advantages of short-term memory and long-term memory in identifying a vehicle target, it can effectively help shorten the time taken for target recognition and improve the recognition efficiency, which is conducive for real-time recognition. Comprehensive experiments under different environment show that the dynamic vehicle recognition rate of the model is 77.10%, and the false recognition rate is 4.5%. The model offers good recognition efficiency for various weather conditions and complex traffic scenarios, and has good noise immunity. In future work, we hope to extend MVRM to incorporate other scenes, such as metro train obstacles recognize and eliminate systems, prevent accident from happening.
Footnotes
Acknowledgments
This work was supported by National Key Research and Development Plan (2017YFC0804807); Beijing Municipal Commission of Education Social Science Foundation (SM201810005002).