
Abstract
Overlapping clustering algorithms have shown to be effective for clustering documents. However, the current overlapping document clustering algorithms produce a big number of clusters, which make them little useful for the user. Therefore, in this paper, we propose a k-means based method for overlapping document clustering, which allows to specify by the user the number of groups to be built. Our experiments with different corpora show that our proposal allows obtaining better results in terms of FBcubed than other recent works for overlapping document clustering reported in the literature.
Introduction
Clustering is the process of creating groups of instances such that, according to a metric, instances inside a group are similar among them; while they are dissimilar with instances in other groups. In the literature, several clustering algorithms have been developed using different techniques for different domains [8, 46]. Clustering has been widely applied in several areas as data analysis [28], data streams classification [30], image analysis [13] and image classification [27], marketing [29], segmentation [42], etc.
In last years, there has been an increasing interest in document clustering since it helps to analyze and organize textual data coming from different sources like the Internet [1], social networks [37], e-mails [25], recommender systems [41], opinion systems [15], etc. Several algorithms for document clustering, for example those proposed in [4–6, 47], build non overlapped clusterings. However, it is common that a document belongs to more than one category (for example themes or topics). For this reason, some document clustering algorithms designed to produce overlapping clusterings have also been developed [16, 39]. All these algorithms do not need, as input parameter, the number of clusters to build. However, they tend to produce a high number of clusters, which makes them little useful for document clustering. Therefore, in this paper, we propose a k-means based method for overlapping document clustering, the proposed method allows the user to specify the number of groups to be built. Our experiments using different corpora show that our proposal allows obtaining better results in terms of FBcubed than other works for overlapping document clustering reported in the literature.
The rest of the paper is organized as follows: Section 2 describes the related work. Section 3 introduces the proposed method. Section 4 shows our experimental results. Finally our conclusions and future work are provided in Section 5.
Related work
Document clustering is a research line that has been widely studied in the literature [2, 50]. In the last years, taking into account that a document can belong to more than one category (theme or topic), the overlapping of themes in documents has been considered by clustering algorithms. In this section, we briefly review the main overlapping document clustering algorithms reported in the literature.
Star [10] is an incremental overlapping clustering algorithm. The Star algorithm works with an undirected graph, where each vertex of the graph represents a document and edges between vertices represent the similarity among documents (using the cosine similarity function). From this similarity graph, a new graph called β-similarity graph is built by preserving only those edges having a similarity greater than a certain threshold β. The Star algorithm builds a coverage of the β-similarity graph by using star-shaped subgraphs, where a star-shaped subgraph is a graph in which there is a vertex called center and there is an edge between this vertex and the rest of the vertices in the graph, called satellites. Star follows a greedy heuristic for covering the β-similarity graph through star-shaped subgraphs. This is done by selecting highly connected vertices from the β-similarity graph, as the centers of the star-shaped subgraphs that would cover the β-similarity graph. The center vertices of the star-shaped subgraphs in the final clustering are stored in a list of centers named X. First, all isolated vertices in the β-similarity graph are included in the list X, since they are degenerated star-shaped subgraphs. Then, Star works in two steps, in the first step, the degree of each vertex of the β-similarity graph is computed and all non-isolated vertices are sorted in a list of possible center vertices L, in a descending order according the their vertex degree. In the second step, Star iteratively takes the vertex with the highest degree in L as the center of a star-shaped subgraph jointly with its adjacent vertices in the β-similarity graph as its satellites, to build a cluster. The vertices of the new star-shaped subgraph are removed from the list L and the center of this star-shaped subgraph is added to the list X. This process is repeated until a set of star-shaped subgraphs that completely covers the original graph is obtained. The clusters obtained in the list X are overlapped since a vertex can be adjacent to more than one center.
The Generalized Star algorithm (GStar), proposed in [36], is a generalization of the Star algorithm. In the first step, for building the list L, the degree of each vertex is computed but considering for each vertex v only those adjacent vertices that have a degree lower than the degree of v. Later in the second step, GStar proceeds as in the Star algorithm.
Based on GStar, the CStar algorithm was proposed in [3, 34], in this algorithm, unlike GStar, the number of generated clusters is reduced. First, the GStar algorithm is executed and then those subgraphs (clusters) having all their vertices contained in other subgraphs are eliminated; these clusters are considered redundant clusters. An algorithm with a similar idea was proposed in [35].
Another extension of the GStar algorithm was reported in [31], called OCDC (Overlapping Clustering based on Density and Compactness), unlike GStar, in the first step, to sort the list of possible centers L, OCDC considers the average density and compactness of the vertices. Where, the density of a vertex v is computed as the number of adjacent vertices of v with a lower degree than v, while the compactness of a vertex v is computed as the number of adjacent vertices whose intra-cluster similarity is smaller than the intra-cluster similarity of v. The intra-cluster similarity of a vertex is the average of the similarity between this vertex and its adjacent vertices. In the second step, the list X is built in a the same way as Star but the vertices are ordered with respect to their average density and compactness. Finally, in order to reduce the number of clusters, if all the vertices of a star-shaped subgraph are contained in other star-shaped subgraphs the star-shaped subgraph is eliminated. According to the authors, OCDC obtains fewer overlapping clusters, with less overlap, than GStar.
In [33] an overlapping clustering algorithm, OClustR (Overlapping Clustering based on Relevance) is presented, which is based on OCDC, but, unlike OCDC, it sorts the list of possible centers L according to the average of the relative density and the relative compactness of a vertex. The relative density of a vertex is computed as the average of the density of its adjacent vertices, and the relative compactness is computed as the average of the compactness of its adjacent vertices. Afterward, it proceeds as the OCDC algorithm.
The DClustR algorithm [32] is a dynamic overlapping clustering algorithm based on OClustR. DClustR builds the clustering similar to OClustR, but, since DClustR is a dynamic algorithm, it allows adding or deleting documents without re-building the clustering from scratch. This is achieved through the detection of the connected components where the documents were added or deleted and then only the star-shaped subgraphs involved in these connected components are updated.
In [16], those words that co-occur within a document are considered as a concept. The overlapping clustering algorithm proposed by the authors starts by extracting all concepts from a text document collection and representing each document as a graph of concepts. In this graph the vertices are the concepts in a document and the edges connect a pair of concepts if the respective concepts have a significance value greater than a certain threshold. The significance value is computed as the number of documents where the concepts co-occur divided by the number of documents where they appear alone. Initially, each graph of concepts (document) forms a cluster, which is called cluster of concepts. Then, all pairs of clusters of concepts are joined iteratively, two clusters are joined if they share a certain percentage of concepts. While this process is performed, each cluster could be joined separately with different clusters, creating overlapping clusters. This process stops when no more concept clusters can be joined.
Parallel GPU-based implementations for the OClustR and DClustR algorithms were proposed in [39]. These implementations, called CUDA-OClus and CUDA-DClus, improve the efficiency of the sequential algorithms.
All the overlapping clustering algorithms above reviewed do not require as input the number of clusters to build. However, these algorithms tend to produce a high number of clusters, including groups with only one document, which is not useful in most applications. For this reason, in this paper, we propose an overlapping k-means based method for overlapping document clustering where the number of groups to build can be provided by the user.
Proposed method
Since the method proposed in this paper is based on the weighed overlapped k-means algorithm (WOKM), in section 3.1 we first describe the WOKM algorithm. Additionally, WOKM, like k-means, also depends on the initialization of centers, therefore in our proposed method, we propose to apply the k-Harmonic Means algorithm, described in Section 3.2, to face this problem. Finally, in Section 3.3, the proposed method is introduced.
WOKM algorithm
The weighted overlapping k-means (WOKM) algorithm was proposed in [14]. This algorithm is based on the k-means algorithm, but it builds overlapped clusters by introducing local weighting for each cluster.
Let χ = {x1, x2, . . . , x
n
} be a set of instances where each instance is described through p features. Let
The WOKM algorithm follows the idea of the k-means algorithm but optimizing the next objective function:
Since
where A i = {m j |x i ∈ C j }. In other words, φ v (x i ) is a weighted average of the cluster centroids where x i belongs to.
In (1) γi,v is computed as follows:
The parameter δ > 1 that appears in (1) is a parameter for regulating the influence of the local weighting.
Given k centers chosen from χ or randomly generated, and given the initial weights associated to the features v as λj,v = 1/p for v = 1, . . . , p and j = 1, . . . , k. The optimization of the objective function (1) is reached by iteratively performing the following three steps: Given where α
i
= 1/|A
i
|2.
These steps are repeated until the clusters do not change or a maximum number of iterations is reached. At the end, the WOKM algorithm obtains k overlapping clusters.
The k-Harmonic Means (KHM) algorithm was proposed by [48, 49], this is a k-means based clustering algorithm, which minimizes the harmonic average distances from all the instances to the centers of all the clusters. The harmonic average supplies a weight to each instance based on its proximity to each center.
Let
The centers are updated using the equation:
and w (x
i
) is the weight associated to each x
i
, which is computed as:
The KHM algorithm begins with k centers chosen randomly, each instance is associated to the cluster with the nearest center, next, KHM updates the centers using Equation 4, and the process is repeated. The KHM algorithm stops when the clusters do not change or a maximum number of iterations is reached.
As we have discussed in section 2, most overlapping document clustering algorithms reported in the literature have the drawback that they cannot be provided with the number of clusters to build, and commonly they tend to produce too many clusters, some of them containing just a single document. Therefore, in this section, we propose a method, which follows the k-means approach, for overlapping document clustering where the number of clusters can be specified a priori by the user. In Fig. 1, the workflow of our proposed method, called Harmonic Weighted Overlapping k-means (HWOKM), is shown.
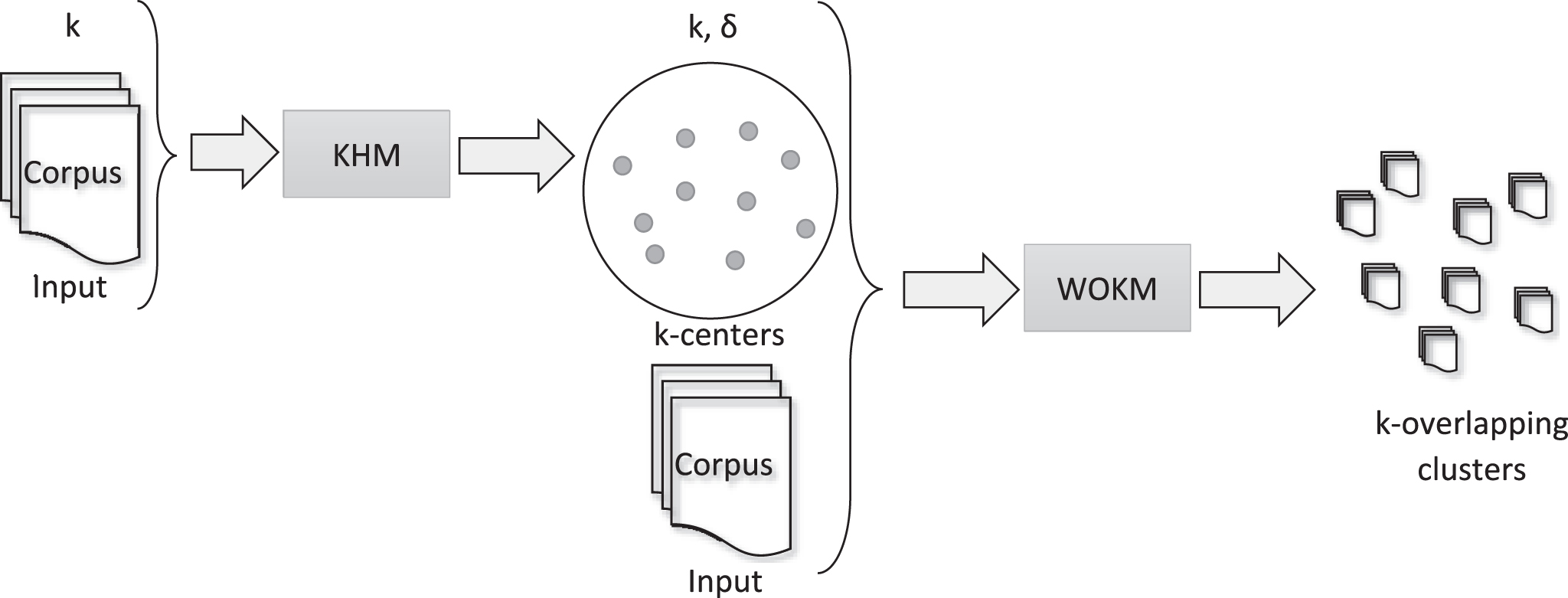
Harmonic weighted overlapping k-means.
Let
In the literature, the k-means algorithm has been extended for producing overlapping clusters, specifically we can find OKM [21], WOKM and OKMED [14]. In [9] an experimental comparison among the algorithms Overlapping k-means (OKM), Overlapping k-medoids (OKMED) and Weighted Overlapping k-means (WOKM) was performed. From this study, the authors concluded that the WOKM algorithm, described in section 3.1, performs better in terms of clustering quality than the OKM and OKMED algorithms.
On the other hand, it is well known that k-means suffers from the initialization of the centers problem, and this problem is inherited to the WOKM algorithm. For reducing this problem, in our method, we propose to take advantage of the ideas of [49], where the authors show that the use of the harmonic mean into the KHM algorithm allows obtaining good centers for the initialization of k-means [20, 23].
Thus, we propose using KHM to initialize the centers for WOKM, with the hypothesis that good centers for building good disjoint clusters would be also suitable for building good overlapping clusters. Thus, our proposed method first applies KHM on the input corpus, As result, KHM produces a set of k disjoint clusters. The centers of the clusters built by KHM are then used as initial centers for WOKM, which uses these centers jointly with the original corpus to produce a set of overlapping clusters.
A pseudocode of our proposed method is shown in Algorithm 1. From this pseudocode, it can be noticed that the complexity of the k-means algorithm is inherited to HWOKM.

In this section, in order to evaluate the efficacy of our proposal, we compare our proposed method against the overlapping k-means (OKM) algorithm [21], the weighted overlapping k-means (WOKM) algorithm [14], and the harmonic overlapping k-means (HOKM) algorithm [24]. This comparison was done in this way because our proposed method is based on WOKM, and thus a comparison against WOKM and the OKM algorithm, its predecessor, is mandatory. Additionally, we also include in our comparison to the OClustR algorithm, which is one of the most recent overlapping document clustering algorithms, and according to the results reported in [33], this algorithm creates fewer clusters than other overlapping document clustering algorithms of the state of the art. We did not include to the algorithm proposed in [16] in our comparison, since this algorithm was designed just for short texts (titles of papers).
Experimental setup
The datasets used for our experiments were taken from the Mulan repository: A Java Library for Multi-Label Learning that is an open-source Java library for learning from multi-label datasets. For our experiments, we choose ten document datasets. These corpora are from different domains, as web pages, laws, medicine, bibliography information and emails; containing from 978 to 87856 documents. The number of terms varies from 500 to 37187 and the number of classes varies between 26 and 983. A summary about the number of documents, terms and classes of the selected document datasets appears in Table 1.
Summary of the document datasets used in our experiments
Summary of the document datasets used in our experiments
3Directory codes. 4Subject matters.
The clustering results were assessed using the FBcubed measure [7], which is an external measure specially designed to evaluate overlapping clustering algorithms. For OKM and WOKM algorithms, the same random initialization was used. For HOKM and HWOKM methods, the k-centers obtained by KHM (using the same initialization used for OKM and WOKM) were used as initial centers.
To verify that our results are statistically significant, the Wilcoxon signed rank test [45] was applied. This test is a non-parametric test for the comparison of two small samples. The samples were obtained through ten executions of each algorithm with different initial centers. The Wilcoxon test was computed using the Keel (Knowledge Extraction based on Evolutionary Learning) software [45], which is an open source Java software tool for different knowledge data discovery tasks.
The implementations of OKM, WOKM and OClustR were provided by the authors of [9, 33], the implementation of KHM taken from the Speech Processing Toolbox for MATLAB. The experiments were performed on a server with an Intel Xeon E5540 2.67 GHz processor with 4 physical cores and 12 Gbytes of RAM running the Linux operating system, Ubuntu distribution.
In this section, we show the results obtained in our experiments with the document datasets shown in Table 1. The columns in Table 2 show the results of the different clustering algorithms evaluated in our comparison, while the datasets used in this experiment appear in the rows. Each entry in Table 2 represents the average FBcubed of the ten executions of the algorithm in the respective column using the dataset in the corresponding row. For each dataset (row), we highlighted in bold the highest result corresponding to the algorithm (column) that obtained the best result in terms of FBCubed.
FBcubed results of the evaluated overlapping document clustering algorithms over the datasets of Table 1
FBcubed results of the evaluated overlapping document clustering algorithms over the datasets of Table 1
The results reported in Table 2 were obtained by fixing k as the number of classes for the respective corpus which appear in the last column of Table 1. The value of the parameter δ in WOKM was fixed as δ = 2, as suggested by [9]. Additionally the OClustR algorithm requires as parameter the value of β, for building the β-similarity graph. For determining this value, we tested different values between 0.1 and 0.5 (as suggested in [33]) with increments of 0.1, and we chose β = 0.4, since this value got the best results of FBcubed.
From the results in Table 2, we can see that in general, our proposal gets better results than the other algorithms. The column of HWOKM has most of its values in bold.
Another important point that deserves a discussion is the that our method by using KHM, for determining the initial centers for WOKM, assumes that good centers for building good disjoint clusters are also suitable for building good overlapping clusters. From the results in Table 2, we can conclude that in general this assumption is true, since if we compare WOKM and HWOKM, we can see that when HKM is used for determining the initial centers of WOKM (see column HWOKM), this gets better results that using random initial centers (see column WOKM). The same happens if we compare OKM and HOKM. In both above cases, there are a couple of datasets where the use of HKM does not allow get the best results. Explaining the reasons of this fact requires a deeper study which is out of the scope of this paper.
On the other hand, since OClustR finds by itself the number of clusters, Table 3 shows the number of clusters generated for each dataset. As it can be seen in this table, the number of clusters built by OClustR is too big regarding the number of real classes in each corpus (see last column of Table 1).
Clusters obtained by the OClustR algorithm
Additionally, we performed a statistical comparison among the results obtained by our proposed method and those results of the second best algorithm, WOKM, through the Wilcoxon signed rank test with a level of significance of α = 0.95 and this test shows that in most of the cases the advantage of the results of HWOKM against WOKM is statistically significant, see the last column in Table 1, where “+” means that HWOKM was statistically better than WOKM; and “equal” means that there was not statistical significant difference.
In this paper, a new method for overlapping document clustering was introduced, which uses an overlapping clustering algorithm (WOKM), which can be provided with the number of clusters. Our proposed method uses a set of good center initialization produced by the KHM algorithm to build good overlapping clusters. Experiments were performed on several document datasets, with overlap, comparing the results of our proposal against different overlapping document clustering algorithms proposed in the literature. Based on our results, we can conclude that the proposed algorithm HWOKM allows obtaining better overlapping clustering results, in terms of the FBcubed measure, than all other evaluated document clustering algorithms.
As future work, we will develop a fast method for deterministically determine the initial centers for the WOKM algorithm.