
Abstract
In recent times, sentiment analysis research has achieved tremendous impetus on English textual data, however, a very less amount of research has been focused on Nepali textual data. This work is focused towards Nepali textual data. We have explored machine learning approaches and proposed a lexicon-based approach using linguistic features and lexical resources to perform sentiment analysis for tweets written in Nepali language. This lexicon-based approach, first pre-process the tweet, locate the opinion-oriented features and then compute the sentiment polarity of tweet. We have investigated both conventional machine learning models (Multinomial Naïve Bayes (NB), Decision Tree, Support Vector Machine (SVM) and logistic regression) and deep learning models (Convolution Neural Network (CNN), Long Short-Term Memory (LSTM) and CNN-LSTM) for sentiment analysis of Nepali text. These machine learning models and lexicon-based approach have been evaluated on tweet dataset related to Nepal Earthquake 2015 and Nepal blockade 2015. Lexicon based approach has outperformed than conventional machine learning models. Deep learning models have outperformed than conventional machine learning models and lexicon-based approach. We have also created Nepali SentiWordNet and Nepali SenticNet sentiment lexicon from existing English language resources as by-product.
Keywords
Introduction
Sentiment analysis is a natural language processing (NLP) task, it identifies the orientation of opinion in a piece of text using linguistic features to classify the text into either positive or negative class. In recent time, sentiment analysis has been very useful task in various domain. Various organization exploits sentiment analysis application to analyze the customer attitudes towards their product/services which helps them in order to take informed decision.
With the growth of user-generated textual content on the internet, the sentiment analysis research has achieved a tremendous momentum. Majority of research has focused on English text and quite less research has been carried out on Nepali language, possibly due to scarcity of accurate linguistic resources (such as stemmer, lemmatizer, POS tagger) to perform sentiment analysis.
Nepali is an Indo-Aryan language of the sub-part of Eastern Pahari, spoken by approximately 45 million people around the globe [1]. It is an official language of Nepal. Nepali is free word order language as compared to English, which increases the complexity in handling user-generated content. The scarcity of linguistic resources for Nepali language creates more challenges ranging from the creation, collection and generation of lexical resources and datasets. Lack of NLP resources increases the complexities of existing classification methods for Nepali text. In this paper, our work is focused towards these challenges. We have explored machine learning approaches and proposed a lexicon-based approach which utilizes linguistic features and lexical resource to identify the orientation of opinion features to classify the piece of text into either positive or negative class. Some Nepali sentiment lexicon (such as Nepali SentiWordNet, Nepali SenticNet) has been generated from existing English language resources (such as SentiWordNet, SenticNet) as by product. The lexicon-based approach utilizes these lexicons in addition to NRC emotion lexicon [21–22] to compute the sentiment polarity of a piece of text. We have studied both conventional machine learning models (Multinomial Naïve Bayes (NB), Decision Tree, Support Vector Machine (SVM) and logistic regression) and Deep Learning models (Convolution Neural Network (CNN), Long Short-Term Memory (LSTM) and CNN-LSTM) for sentiment analysis of Nepali text. We have also evaluated machine learning models and lexicon-based approach on tweet dataset related to Nepal Earthquake 2015 and Nepal blockade 2015. The tweets are generally about relief and shelter situation in earthquake. It is observed that lexicon-based approach achieved better precision, recall and accuracy performance than conventional machine learning models. Deep learning models have outperformed than conventional machine learning model and lexicon-based approach.
The rest of the paper is organized as follows: Section 2 presents the NLP research in Nepali language. Section 3 explains the machine learning-based approaches for sentiment analysis of Nepali texts. Section 4 presents the linguistic based approach for sentiment analysis of Nepali texts. Section 5 describes the experimental analysis. Section 6 presents the conclusion.
NLP Research in Nepali language
Sentiment analysis is an important area of NLP with comprehensive and growing literature. The majority of published literature is concentrated towards the English language, however, very less amount of work has been done for other scarce resource languages (SRL). SRL are languages for which availability of NLP tools (such as POS tagger, lemmatizer, and annotated corpora) are limited and under the developing phase. Nepali language is one such SRL.
NLP research in Nepal has started in year 2005 with the launch of Nepali Spell checker [2] and English to Nepali machine translation project named “Dobhase” [3]. Madan Puraskar Pustakalya in collaboration with Kathmandu University has taken this initiation to create the NLP resources for Nepali text. Nepali National corpus (NNC) of 14 million words has been constructed and annotated for both spoken and written data [1]. This corpus also has parallel speech corpus (English-Nepali and Nepali-English) as additional resource. The morphological analyzer has been implemented for determining the morpheme(s) of a specified derived or inflected word [3, 4]. The Universal networking language (UNL) Nepali de-converter which generates Nepali language and represents meaning sentence by sentence in logical form has been proposed in [5]. Hardie has constructed a collocation-based method for classification of Nepali postpositions [6]. For analyzing the structure of Nepali grammar, a system named Nepal Grammar Checker has been developed [7]. Parts of speech (POS) tagger for Nepali text has been built using support vector machine (SVM) [8] and first-order hidden Markov model [9]. To extract a specific information (such as names, places, time) from Nepali text, a Named Entity Recognition (NER) has been developed using support vector machine and semi-hybrid approach [10, 11].
Thakur and Singh have augmented a lexicon pooled with Naïve Bayes classifier for classification of Nepali news stories [12]. Gupta and Bal have built bootstrap approach for detecting sentiment in Nepali text [13]. Regmi et al. utilizes supervised machine learning classifiers for analysis of facts and opinion of Nepali text [14]. They also conducted a comparative study of classifiers. Some studies [12–15] are concentrated on classification of Nepali news articles dataset. Thapa and Bal have also applied supervised machine learning classifiers for sentiment analysis of books and movie reviews written in Nepali [16]. Machine learning approaches: Naïve Bayes and SVM have been used for mobile sms spam filtering [17].
In this paper, a lexicon-based approach has been implemented using linguistic formulation and lexical resources to identify an orientation of opinion features from a tweet and then compute the sentiment polarity of a tweet. We have also explored machine learning based approached for sentiment analysis on Nepali text. To our best knowledge, this is the first work that focused on tweets. We have also conducted a comparative study of different lexicon.
Machine learning-based approaches for sentiment analysis of Nepali texts
Conventional machine learning models
We have studied the most popular supervised machine learning classifiers for sentiment analysis on Nepali texts such as Multinomial Naïve Bayes (NB), Decision Tree, Support Vector Machine (SVM) and Logistic Regression. We have considered all these machine learning classifiers as baselines for a lexicon-based approach. Figure 1 shows the block diagram for the supervised machine learning classifiers. During the training phase, a feature extractor module extracted the Tweet Features as listed in Table 1 and converted each tweet input value to a Feature Matrix. Then, we have computed TFIDF of unigram, bigram, trigram after pre-processing the tweet by removing non-Nepali text, hashtags, URLs and repeated punctuation marks. We have added TFIDF of unigram, bigram, and trigram as a feature into a Feature Matrix. These features matrices and labels are given as input to the machine learning classifier to generate the model. The selection of Tweet Features are derived from previous studies [18–20]. During the prediction phase, the same feature extractor module extracts the Tweet Features and TFIDF unigram, bigram trigram from an unseen tweet and converts each tweet input to feature matrix. These matrices are given as input to the classifier model to predict the labels for unseen tweets. The scikit-learn python library has been used for implementation of Multinomial NB, Decision Tree, SVM, and logistic regression. The scikit-learn is a python library which provides machine learning classifiers to perform NLP tasks. All machine learning classifiers experiments are run with tenfold cross-validation.
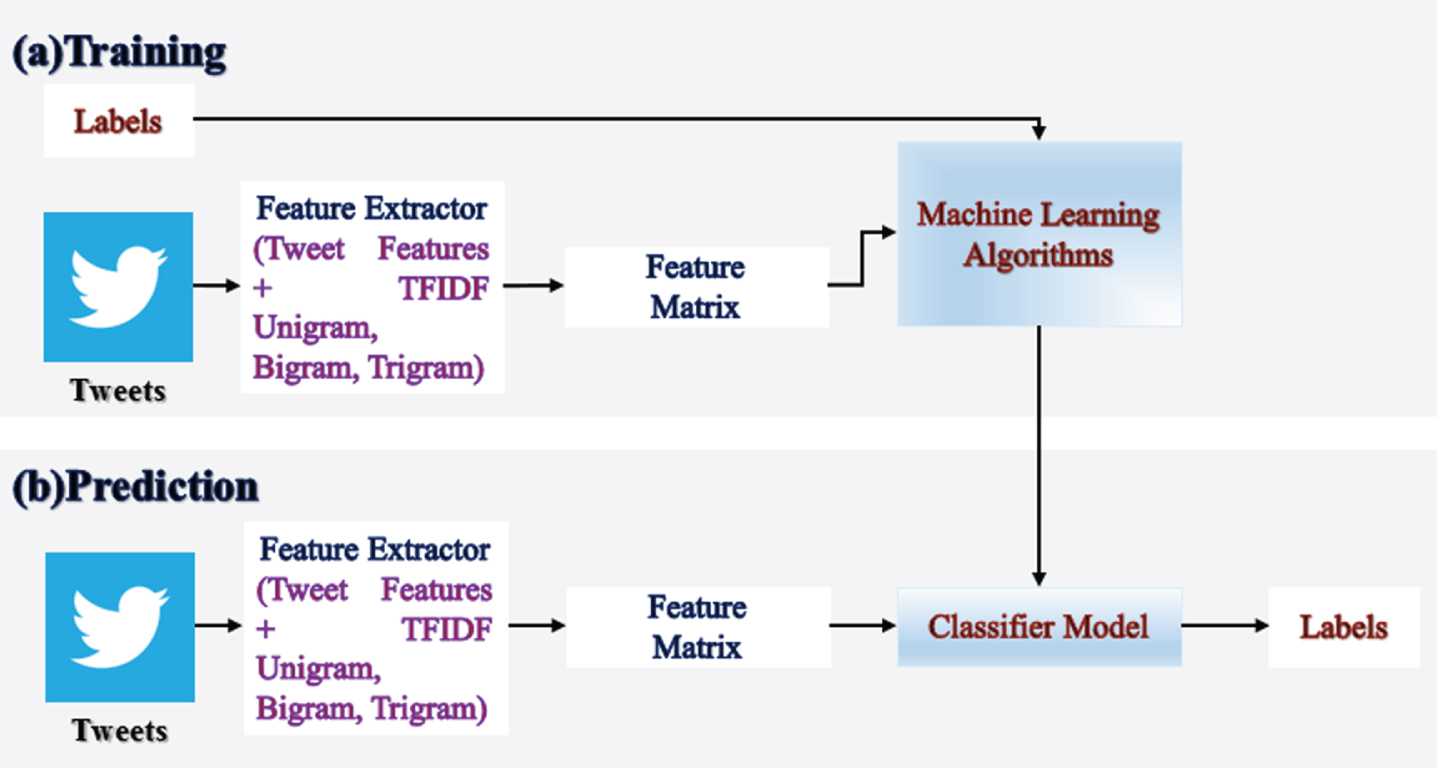
Block diagram for supervised machine learning approaches.
Tweet features
Convolution neural network (CNN)
Recently, CNNs have achieved remarkable results on sentence classification task [25–29]. It converts the words of sentence into vector that can be used as input as shown in Fig. 2. Figure 2 shows the architecture of CNN for sentiment analysis. This model is inspired by Zhang & Wallace [30]. The model has three regions: R1 for bigram, R2 for trigram and R3 for four gram, each region has two filters. Filters are used to perform convolutions on input tweet matrix and create variable length feature maps. Max pooling layer is applied over each feature map to get univariate feature vector. Next is to concatenate all six univariate vectors to a single vector. The softmax layer gets single vector as input and classify the sentence. Table 2 shows CNN model configuration description.
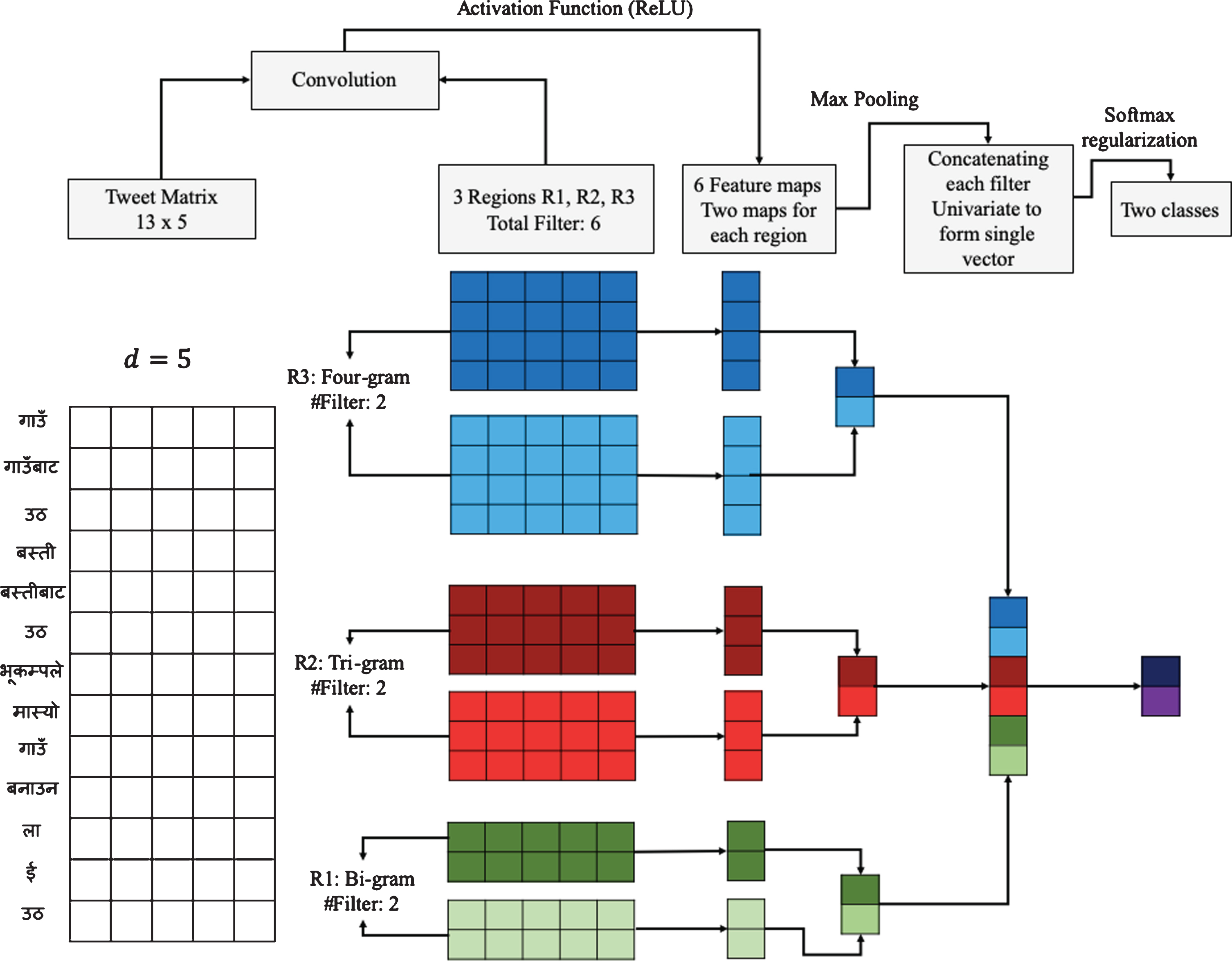
CNN architecture for sentiment analysis.
CNN model configuration description
2https://fasttext.cc/docs/en/crawl-vectors.html. 3https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ne.300.bin.gz.
LSTM are widely used for sentiment analysis task [31–34]. LSTM network was developed to overcome the drawback of Recurrent Neural Network (RNN) that is vanishing gradient and exploding gradient. In LSTM model, gates are used to control the memorizing process. Figure 3 illustrates the LSTM architecture for sentiment analysis. It comprises of six layers: Tokenize Layer, Embedding Layer, LSTM layer, Fully connected layer, Sigmoid activation layer and output layer. Tokenize Layer: This layer is compulsory step for converting words into token i.e. integer. Embedding Layer: In this layer, word tokens are converted into embedding of specific size. LSTM Layer: It can be explained by hidden state and number of layers. Fully Connected Layer: It maps LSTM layer output to required output size. Sigmoid Activation Layer: It converts all output values between 0 and 1. Output: The final output of the network is sigmoid layer output.

LSTM architecture for sentiment analysis.
Table 3 shows the LSTM model configuration parameters description.
LSTM model configuration description
Generally, CNN may be incapable to extract long distance dependency but it can identify local information from sentences. This limitation of CNN can be addressed by LSTM through sequentially modelling texts around sentences. Figure 4 shows the CNN-LSTM architecture for sentiment analysis of Nepali texts. This model is inspired by Jin Wang et al. [35]. CNN-LSTM model has been widely used for sentiment analysis tasks [36–38].This model comprises of eight layer. Tokenize Layer: This layer is compulsory step for converting words into token i.e. integer. Embedding Layer: In this layer, word tokens are converted into embedding of specific size. Convolution Layer: It perform convolutions on input tweet matrix and create variable length feature maps Max-pooling layer: It subsample the output of convolution layer by removing the non-maximal values. LSTM Layer: It will utilize the ordering of features to learn the sequence of input. Fully Connected Layer: It maps LSTM layer output to required output size. Sigmoid Activation Layer: It converts all output values between 0 and 1. Output: The final output of the network is sigmoid layer output.

CNN-LSTM architecture for sentiment analysis.
Table 4 shows CNN-LSTM model configuration parameters description.
CNN-LSTM model configuration description
We have used have used Keras 4 , Genism 5 and TensorFlow 6 python libraries for the implementation of all three deep learning models. Before applying any model on tweet dataset, we have preprocessed the tweet by removing non-Nepali text, hashtags, URLs and repeated punctuation marks. Moreover, we have run all deep learning models with tenfold cross validation.
Methodological approach
As we have investigated in the last section, machine learning approaches for the sentiment analysis of Nepali text. The conventional machine learning classifiers prior requirement is labelled training set to perform the sentiment analysis. In order to remove this requirement, we have designed lexicon-based approach. The lexicon-based approach for sentiment analysis is focused towards the assumption that the contextual sentiment orientation of any document, sentence or aspect is the aggregate of the sentiment score of each word or phrase or feature (such as adjective, adverb adjective combination, or adverb adjective adverb verb combination) present in that specified text. The pre-requisite for lexicon-based approach are lexical resources, parts of speech (POS) tagger, and a good method for computing contextual sentiment score of a feature. However, Nepali is a SRL and there are no standard POS tagger and lexical resources available for Nepali language. Therefore, we have used dictionary-based approach to identify POS from text. To detect the opinion feature from a piece of text, we have created a sentiment lexicon with the help of dictionaries: Nepali to Nepali Dictionary and Nepali to English dictionary; and existing English sentiment lexicons such as SentiWordNet and SenticNet. Figure 2 shows the block diagram of proposed work. The approach takes tweet as an input, pre-process the tweet by removing non-Nepali text, hashtags, URLs and repeated punctuation marks, extract the feature using Nepali to Nepali dictionary and compute the sentiment polarity of a tweet with the help of Nepali sentiment lexicons (Nepali SentiWordNet, Nepali SenticNet, Domain Specific Sentiment Lexicon) and NRC Emotion Lexicon as shown in block diagram. NRC emotion lexicon is created by Saif Mohammad [21, 22] for the English language. It is a collection of words and their association with eight basic emotions (anger, fear, anticipation, trust, surprise, sadness, joy, and disgust) and two sentiments (negative and positive). They have also released this lexicon in other languages including the Nepali language. So we have used the Nepali version of NRC Emotion lexicon for the lexicon-based approach. This lexicon has 12 field: 1. English Word, 2. Nepali Word 3. Anger, 4. Fear, 5. Anticipation, 6. Trust, 7. Surprise, 8. Sadness, 9. Joy, 10. Disgust, 11. Positive, 12. Negative. Out of these 12 fields, we have used four fields: English word, Nepali Word, Positive and Negative fields. The value of positive and negative field is either 0 or 1. The details about the creation of Nepali Sentiment lexicons is discussed in next Section 4.2.
Algorithm for computation of sentiment polarity
This section explains the algorithm for the computation of sentiment polarity. The pre-processed tweets are fed as input to the computation of sentiment polarity algorithm.
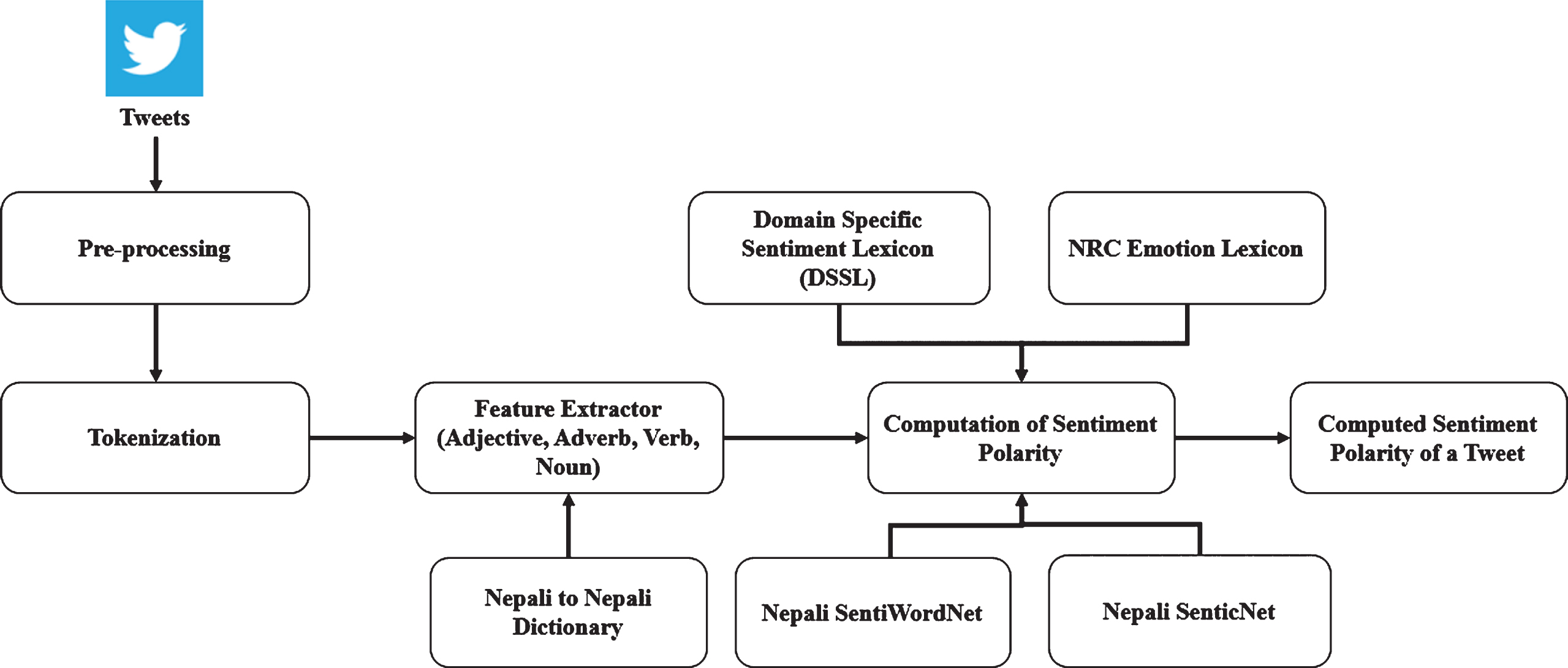
Block diagram for Lexicon-based approach.
The algorithm first tokenizes each pre-processed tweet and compute unigram, bigram and trigram through findNGrams function to create a feature vector. The next step is to identify the opinion feature from the feature vector and then compute the sentiment polarity with the help of created lexicons (Nepali SentiWordNet, Nepali SenticNet, DSSL) and NRC emotion lexicon. We are using Python Pandas library.
In the pseudo-code, score df is a pandas data frame which will store word (W), frequency (F), sentiment (S), and parts of speech (POS). In the pseudo-code, getSentimentScore is a function which will take word and POS as input and return sentiment score of the input word. The pseudo-code of the algorithm is given below:
Creation of dataset
There are no appropriate annotated datasets, and other lexical resources available to perform sentiment analysis on the Nepali language. Therefore, we have built a dataset of 600 positive and 600 negative tweets. For the creation of dataset, first, we have downloaded the tweets regarding Nepal Earthquake 2015 (duration: 25-04-2015 to 25-05-2015) and Nepal Blockade 2015 (duration: 15-09-2015 to 31-12-2015) from a Twitter (Downloaded on 30-03-2018). The Nepal Earthquake occurred on 25-04-2015 with magnitude 7.8. According to the report, more than 8702 people died in that earthquake. People have suffered from the scarcity of critical resources such as medicines, water, epidemics, and other life-threatening diseases. The Nepali Blockade 2015 started from 23-05-2015, it was an economic and humanitarian crisis. It has affected people of Nepal and its economy very severely. We have crawled around 4200 tweets related to Nepal Earthquake and 800 related to Nepal Blockade. These 5000 tweets were given to three annotators (graduate students) for labelling. The annotators were asked to label each tweet with sentiment polarity identified in the tweet text. The annotators have identified some tweets which contain English text in between the Nepali text (For example: “ Chinese
Chinese  ,
,  ! #BackOfIndia”) and some tweets contain English words written in Nepali text (For example: “
! #BackOfIndia”) and some tweets contain English words written in Nepali text (For example: “ ). We have removed such tweets. The quality of annotation has been measured by two standard agreement parameters: Inter-Indexer Consistency (IIC) [23] and Cohen’s Kappa [24]. Out of 5000 tweets, 600 tweets are found to be positive and 600 as Negative. Table 5 presents the dataset description which we have used for evaluation purpose.
). We have removed such tweets. The quality of annotation has been measured by two standard agreement parameters: Inter-Indexer Consistency (IIC) [23] and Cohen’s Kappa [24]. Out of 5000 tweets, 600 tweets are found to be positive and 600 as Negative. Table 5 presents the dataset description which we have used for evaluation purpose.
Dataset description with annotation results
Dataset description with annotation results
The sentiment lexicons have been extensively used for the designing of sentiment analysis approaches. Sentiment lexicon is a lexical sentiment dictionary where for each word there is a sentiment score representing positive, negative and neutral behavior of word. Many sentiment lexicons have been created/generated for the English language but not for the Nepali language. As best of our knowledge there is no sentiment lexicon publicly available for the Nepali language. We have created three sentiment lexicons: 1. Nepali SentiWordNet, 2. Nepali SenticNet, and 3. Domain Specific Sentiment Lexicon (DSSL) using Nepali to Nepali dictionary (NND), Nepali to English dictionary (NED), SentiWordNet and SenticNet. The name of NND is “Nepali Brihat Shabdkosh” 7 . NND contains 7126 words with Nepali parts-of-speech (POS) and its meaning in Nepali. With the help of Nepali language experts, all Nepali POS has been converted to equivalent English POS. NED is extracted from Android APP named “Nepali English Dictionary v1” 8 . NED comprises of 40126 words with equivalent meaning in English but it doesn’t contain POS of words. SentiWordNet is a publicly available lexical tool for opining mining. In SentiWordNet each WordNet synset has three scores: positive, negative and objective score. In order to retrieve the sentiment score of a particular word from SentiWordNet, a weighted average scheme has been used. This score varies between –1 to +1. SenticNet is concept oriented sentiment analysis tool, and it is also publicly available. In SenticNet, for each word, the sentiment score lies between –1 to +1.
For the creation of Nepali SentiWordNet, NND, NED and English SentiWordNet have been used. Nepali SentiWordNet lexicon contains eight fields: (1) Word in Nepali, (2) Nepali POS, (3) Equivalent English POS, (4) meaning in Nepali, (5) Meaning in English, (6) Word found in SentiWordNet, (7) SentiWordNet POS (8) sentiment strength. The following steps have been applied for building a Nepali SentiWordNet:
In pseudo-code, NepaliSentiWordNet is pandas data frame which contains eight field about which we have mentioned in the above paragraph.
Creation of Nepali SenticNet process is similar to the process of creation of Nepali SentiWordNet. Each entry in Nepali SenticNet contains seven fields instead of eight because English SenticNet does not contain the POS of word/concept. Seven fields of Nepali SenticNet are: (1) Word in Nepali, (2) Nepali POS, (3) Equivalent English POS, (4) meaning in Nepali, (5) Meaning in English, (6) Word found in SentiWordNet, (7) sentiment strength. The following steps have been applied for building a Nepali SenticNet:
DSSL has been created for Earthquake and blockade domains. The objective behind the creation of this lexicon is to take into account the maximum number of phrases and slang words used in the Nepali language to portray sentiment with respect to Earthquake and blockade domains. This dictionary has been created from 4200 Nepali tweets regarding the earthquake and 800 Nepali tweets regarding blockade. These tweets were given to three different students who speak and write Nepali and were asked to extract positive, negative and slang words used in these tweets. Each entry in DSSL has two fields: (1) Nepali Word (2) Sentiment Polarity. The sentiment polarity for positive word is 1 and –1 for negative word and slang word. Table 6 presents lexicon details.
Lexicon details
Lexicon details
The performance of all models has been evaluated through standard performance measures: Accuracy, Precision, Recall and F-measure. The macro-averaging method has been applied for the calculation of precision and recall. All machine learning models and lexicon-based approach have been evaluated on tweet dataset D. Table 7 shows the results of conventional machine learning models and deep learning models. From Table 7, it is observed that the majority of approaches have obtained nearly 60% accuracy and SVM with features (TFIDF (Unigram+Bi-gram+Trigram)+Tweet Features) has achieved maximum accuracy of 63.25% which is better among all the machine learning approaches.
Results of machine learning approaches on dataset D
Results of machine learning approaches on dataset D
From Table 7 it is also observed that the CNN+pretrained word2vec model has achieved better results than all other models. Moreover, deep learning models have outperformed than Conventional machine learning models.
The lexicon approach has been evaluated on each of the four lexicons: 1. Nepali SentiWordNet, 2. Nepali SenticNet, 3. NRC Emotion lexicon and 4. Domain specific lexicon independently and then on the combination of two and three lexicons as shown in Table 8. It is observed from Table 8 that Nepali SentiWordNet and Nepali SenticNet achieves 19% and 17.8% precision respectively because of the presence of limited words related to the earthquake and blockade domain. NRC Emotion lexicon and DSSL have outperformed than all other lexicons. NRC emotion lexicon has more words than Nepali SenticNet and Nepali SentiWordNet whereas DSSL dictionary is created with objective to take into account maximum number of phrases and slang words related to earthquake and blockade domain. The combination of two lexicon has been tried to take the advantage of each lexicon. It is also observed from Table 8 that combination of NRC emotion lexicon and DSSL have outperformed than all other combinations of two lexicon. We have also evaluated the approach on combination of three lexicon. From Table 8 it is seen that combination of NRC Emotion lexicon, DSSL, and Nepali SentiWordNet achieved slightly better results than the combination of NRC Emotion and DSSL. This combination has also performed better than conventional machine learning models. Moreover, it is observed that deep learning models have outperformed than conventional machine learning model and lexicon-based approach.
Lexicon-based results of dataset D
In this paper we have explored machine learning approaches and proposed a lexicon-based approach using linguistic features and lexical resources to perform sentiment analysis for tweets written in Nepali language. Nepali is a SRL language and there are no standard POS tagger and lexical resources such as Nepali sentiment lexicons available to perform sentiment analysis on the Nepali language. Therefore, we have used dictionary-based approach to identify POS from the text. We have also created Nepali sentiment lexicons with the help of Nepali to Nepal Dictionary, Nepali to English dictionary and existing publicly available English sentiment lexicons such as SentiWordNet and SenticNet. Furthermore, we have created three sentiment lexicon: Nepali SentiWordNet, Nepali SenticNet, and DSSL as by-product of this work.
The lexicon-based approach takes a tweet as input, pre-process the tweet, identify the opinion feature from the text and compute the sentiment polarity using sentiment lexicon. We have investigated both conventional machine learning models (Multinomial Naïve Bayes (NB), Decision Tree, Support Vector Machine (SVM) and logistic regression) and deep learning models (Convolution Neural Network (CNN), Long Short-Term memory (LSTM) and CNN-LSTM) for sentiment analysis of Nepali text. The machine learning models and lexicon-based approach have been evaluated on Nepal Earthquake 2015 and Nepal Blockade 2015 tweets.
It has been observed that combination of three lexicons: NRC Emotion lexicon, DSSL, and Nepali SentiWordNet have achieved better result than the independent lexicon and other combination of lexicons. Also, this combination has outperformed than Conventional machine learning Models. Deep learning models have outperformed than conventional machine learning model and lexicon-based approach. We believe that the performance of lexicon-based approach can be improved further by increasing the size of lexicons. The conventional machine learning classifiers result can also be enhanced by increasing the training size of data. Similarly, the deep learning models result can be improved by increasing the training size of data and by applying transfer learning approaches. Moreover, the lexicon-based approach is fully scalable and adaptable to any domain. Also, this approach can also be extended for other SRL. The only effort required will be to construct lexical resources for that SRL.