
Abstract
In many areas of professional development, the categorization of textual objects is of critical importance. A prominent example is the attribution of authorship, where symbolic information is manipulated using natural language processing techniques. In this context, one of the main limitations is the necessity of a large number of pre-labeled instances for each author that is to be identified. This paper proposes a method based on the use of n-grams of characters and the use of the web to enrich the training sets. The proposed method considers the automatic extraction of the unlabeled examples from the Web and its iterative integration into the training data set. The evaluation of the proposed approach was done by using a corpus formed by poems corresponding to 5 contemporary Mexican poets. The results presented allow evaluating the impact of the incorporation of new information into the training set, as well as the role played by the selection of classification attributes using information gain.
Introduction
Classification refers to the task of assigning a set of objects to two or more predefined categories. In many areas of professional development, such as the attribution of authorship, the categorization of new objects is of critical importance. Unfortunately, in most cases this process is expensive and time-consuming. Thus, there is an avid interest in the development of new technologies and approaches which can achieve an automatic classification, especially for the case of textual objects [1].
A typical approach to build a text categorization system in general consists in manually assigning a set of documents to categorize. In this case the hierarchies or thematic areas are assigned by an expert. However, this process is usually very expensive, since there is a need for an expert for each area or application for which the classification is to be carried out; also, a change of area requires new experts to define the categories or documents that belong to each category as well as the rules that allow decisions on new documents to be classified [2]. Because of this, the most commonly used approach nowadays is to use information retrieval techniques and machine learning to produce a classification model [3–5]. Learning-based systems are also faster to build with respect to rules-based systems or language models.
Authorship attribution is the task of identifying the author of a given text. It can be considered as a classification problem, where a set of documents with known authorship are used for training, and the aim is to automatically determine the corresponding author of an anonymous text.
Applications of authorship attribution include plagiarism detection (i.e. college essays), deducing the writer of inappropriate communications that were sent anonymously or under a pseudonym (i.e. threatening or harassing e-mails), as well as resolving historical questions of unclear or disputed authorship. Specific examples are the Federalist papers [6] and the forensic analysis of the Unabomber manifesto [7].
In this paper presents the application of a web-based self-training method in a non-thematic classification task, namely, authorship attribution. In order to evaluate the performance of my approach in severe conditions, I focus the experiments on poem classification where documents are usually short and both their vocabulary and structure can differ significantly from predominant web language.
The rest of the paper is organized as follows: in section 2 a brief state of the art of attribution of authorship is presented. In section 3 the methodology implemented in this work is presented in detail. The result obtained are presented and, finally, the conclusions and future work are outlined.
Authorship attribution
The first programs for similarity and plagiarism detection were developed by Halstead [8] and McCabe [9]. Subsequently, the Wise program [10] was developed to compare line by line using Levenshtein’s distance (chain similarity). Then, Gitchell and Tran [11] worked based on the analysis of the tree generated by a program. More recent works [12] also use latent semantic analysis (LSA). And, even more recently, some proposals have been implemented to detect similarity in computer programs, for example, in Karel language [13]. An example is the “Moss” program [14], which compares two programs according to the similarity of their “fingerprints.”
The measure of cosine or its modification, the soft cosine [15], which allows taking into account the similarity between characteristics in a vector space model, is also often used to measure similarity. In the present work, on the other hand, I note that the use of n-grams (sequences of words or characters) as characteristics for classification is actually suitable in tasks related to machine learning for texts. There are other options such as syntactic n-grams [16], integrated syntactic graphs [17], tree editing distance [18], among others, which can be used in the vector space model [19].
In contrast to previous works, this paper does not propose another document representation for authorship attribution, instead it describes a new semi-supervised learning method that allows working with small training sets. As expected, my web-based self-training classification method may be applied along with all these kinds of features. However, given that my interest is to have a general approach for authorship attribution that allow analyzing documents of different sizes and domains, I have decided to mainly explore the use of word-based features, in particular, n-grams.
Methodology proposed
Given that there is not a standard data set for evaluating authorship attribution methods, I had to assemble my own corpus. I have a corpus formed by 353 poems of 5 contemporary Mexican poets namely Efraín Huerta, Jaime Sabines, Octavio Paz, Rosario Castellanos, and Rubén Bonifaz. Everyone with particularly unique writing style. Table 1 resumes some statistics about this corpus.
Corpus statistics
Corpus statistics
In general, the corpus comprises short poems with only 20 sentences per poem on average; the number of words per poem is 175, while the number of different words in each one is 57 on average; and, again, all of them correspond to Mexican contemporary poets. In particular, I was very careful on selecting modern writers in order to avoid the identification of authors by the use of anachronisms. Figure 1 shows the general scheme of my semi-supervised text classification method. It consists of two main processes. The first one deals with the corpora acquisition from the Web, whereas the second one focuses on the self-training learning approach [20].
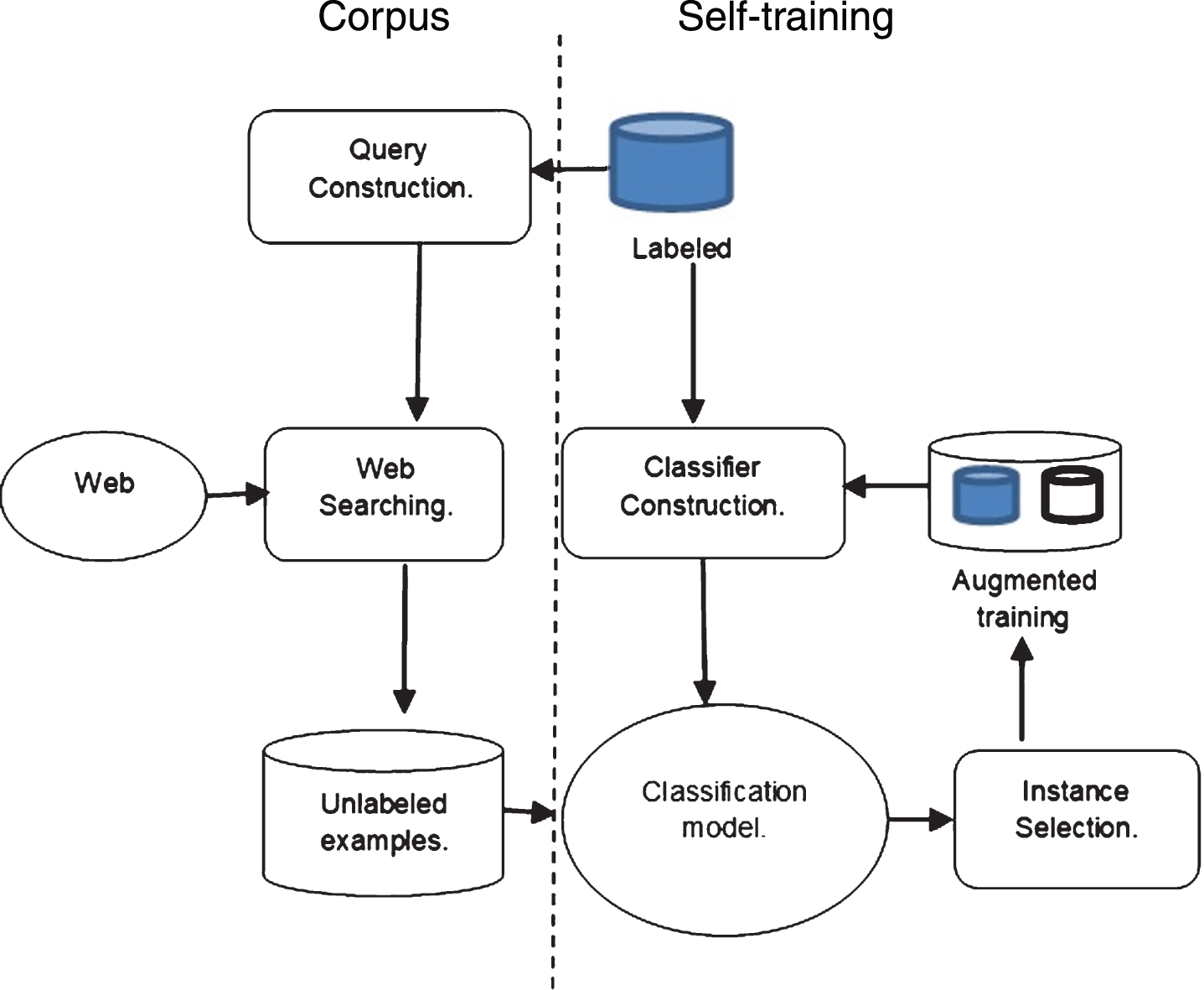
General overview of the classification method.
The Corpora Acquisition process considers the automatic extraction of unlabeled examples from the Web. In order to do this, it first constructs a number of queries by combining the most significant words for each class; then, using these queries, it looks at the Web for some additional training examples related to the given classes. The Query at the web where constructed according to the method shown in [21].
For the development of this work, two classification methods were used: Bayes and Support vector machines (SVM). The Bayesian classifier is considered as part of the probabilistic classifiers, which are based on the assumption that interest amounts are governed by probability distributions, and that the optimal decision can be made by reasoning about those probabilities along with the observed data. The Naive Bayes algorithm uses the training set to estimate the parameters of a probability distribution that describes the training set. The category with the highest probability is the assigned category. On the other hand, in geometric terms, SVM can be seen as the attempt to find a surface (σ
i
) that separates positive examples from negative ones by the widest possible margin. The search for σ
i
that meets the minimum distance between it and an example of training is maximum, is performed across all surfaces σ1, σ2, … in the A-dimensional space that separate the positive examples from the negatives in the training set (known as decision surface). The best decision surface is determined only by a small set of training examples, called
An experiment was designed that allowed us to appreciate mainly two things. First, the impact that classification accuracy has on the incorporation of new unlabeled information, coming from the web, to the training set through an iterative process. Second, the performance of the classification systems when making the selection of characteristics that will be used as classification attributes (IG>0).
For the evaluation of the experiment, two standard classification methods were used namely Bayes and SVM. Accuracy and recall were used as performance evaluation measures.
The corpus was divided in two data sets: training (with 80% of the labeled examples) and test (with 20% of the examples). The idea was to carry out the experiment in an almost-real situation, where it is not possible to know in advance all the vocabulary. This is a very important aspect to take into account in poem classification since poets tend to employ a very rich vocabulary.
In this work, I used n-grams as document features. I mainly performed two different experiments. In the first one I used bigrams as features, whereas in the second one I used trigrams. In each case, experiments were performed calculating the information gain with the purpose of having a comparison of the impact of the information gain on the accuracy of classification.
Table 2 shows the results corresponding to the first five iterations of the method. As can be observed, the integration of new information improved the baseline results. In particular, the best result was obtained at the second iteration when using bigrams. Arguably, this behaviour was due because bigrams are better suited to look for the most used collocations of an author from a small corpus. An additional experiment was carried out for both for the baseline and for the iterations performed, considering only the atrobits with information gain (IG) greater than zero (those attributes that serve to distinguish between classes, in thematic classification), the results are shown in Table 2.
Accuracy percentage after the training corpus enrichment
Accuracy percentage after the training corpus enrichment
Figure 2 show the results obtained using as classification attributes unigrams, bigrams, and trigrams using Bayes and SVM respectively for each of the iterations performed using the proposed method. As you can see, Bayes allows to have a better result of classification using the corpus of poets. With both Bayes and SVM the best result is obtained in the second iteration.

Left Bayes, Right SVM (blue:1-gram, red:2-gram, green:3-gram).
From Fig. 2, we can observe that, starting from baseline, the accuracy improves in iterations 1 and 2 and then decreases (with Bayes and SVM) this is because the incorporation of unlabeled information from the web is too much compared to the size of the original training corpus and this generates a bias in the training sets with respect to the original class. That is, 2400 snippets are downloaded and from there 60 are selected that will be incorporated into the training set in each iteration (In 5 iterations, 12,000 additional unlabeled examples are downloaded). In iteration number 3, 180 unlabeled instances have been incorporated into the training set which represents more than 50% of the size of the original corpus, that's, as of this iteration the amount of unlabeled information coming from the web is more than the information that was originally available to decide which poet wrote a particular poem.
Figures 3 and 4 s show the results obtained by each iteration and by poet for Bayes and SVM respectively. The baseline is also shown, in order to see the impact of incorporating new information in each iteration.

Results obtained for the attribution of authorship using Bayes.
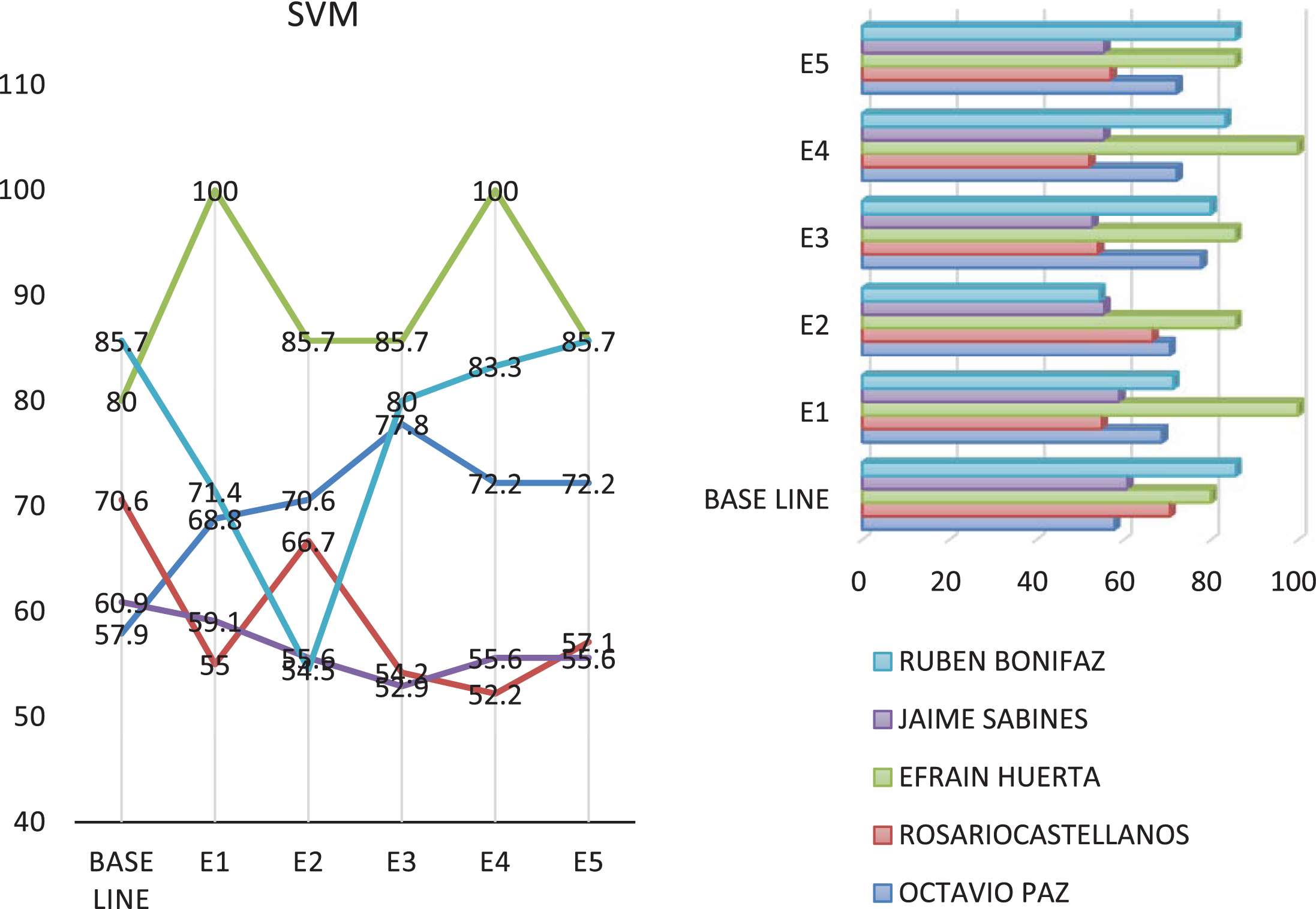
Results obtained for the attribution of authorship using SVM.
In this figures we can see that the incorporation of unlabeled information helps to improve the accuracy of classification in the case of Bayes an improvement is achieved for all classes, while in the case of SVM the incorporation of unlabeled information from of the web is harmful in most classes.
In spite of being preliminary results, it is surprising to verify that it is feasible to extract useful examples from the Web for the task of authorship attribution. Our intuition suggested the opposite: given that poems tend to use rare and improper word combinations, the Web seemed not to be an adequate source of relevant information for this task. That is, each author has preference topics and this information facilitates the poem classification.
The proposed method for authorship attribution, which uses n-gram features and a semi-supervised learning approach, could outperform most common approaches for authorship attribution. Furthermore, my method, contrary to other approaches, is not too sensitive to the size of the texts and the collection, and avoids using any sophisticated linguistic analysis of documents.
The proper identification of an author, even from a poem, must consider both stylometric and topic features of documents. Therefore, it is clear that n grams can be used as classification attributes.
Finally, from the results obtained and shown in Table 4, it can be seen that the selection of attributes that have information gain greater than zero (IG>0), this is those attributes that help us distinguish one class from another in the thematic classification, does not help identify the writing style of poets.