
Abstract
Urdu is the most popular language in Pakistan which is spoken by millions of people across the globe. While English is considered the dominant web content language, characteristics of Urdu language web content are still unknown. In this paper, we study the World-Wide-Web (WWW) by focusing on the content present in the Perso-Arabic script. Leveraging from the Common Crawl Corpus, which is the largest publicly available web content of 2.87 billion documents for the period of December 2016, we examine different aspects of Urdu web content. We use the Compact Language Detector (CLD2) for language detection. We find that the global WWW population has a share of 0.04% for Urdu web content with respect to document frequency. 70.9% of the top-level Urdu domains consist of . com, . org, and . info. Besides, urdulughat is the most dominating second-level domain. 40% of the domains are hosted in the United States while only 0.33% are hosted within Pakistan. Moreover, 25.68% web-pages have Urdu as primary language and only 11.78% of web-pages are exclusively in Urdu. Our Urdu corpus consists of 1.25 billion total and 18.14 million unique tokens. Furthermore, the corpus follows the Zipf’s law distribution. This Urdu Corpus can be used for text summarization, text classification, and cross-lingual information retrieval.
Introduction
Text corpus is an essential requirement for the linguistic researches and Natural Language Processing (NLP) applications. The development in NLP and Information Retrieval (IR) tasks such as summarization, plagiarism detection, and cross-language information retrieval has increased the requirement of large scale corpora for low resource languages. In the past, researchers have built language based corpora for single or multiple languages like AsoSoft [1], ArabicWeb16[2], C4Corpus[3], and ClueWeb09[4].
Urdu is the official language of Pakistan and there are more than 170 million speakers of Urdu language in the world [5]. Despite a large number of Urdu speaking population, Urdu is still considered as a low resource language due to lack of large scale corpus to provide state-of-the-art NLP and IR systems. Furthermore, it has been shown that compared to English and other regional languages, Urdu has a very low proportion of Urdu content on the web [6]. For low resource languages, corpus building is a challenging task as it requires crawling the whole web that needs a lot of compute and storage resources. Furthermore, it requires some specialized language filters that will detect language information of crawled pages. Common Crawl is an organization that provides web crawls on a regular basis for the research community [7].
This work is an effort to build the corpus for the Urdu language which is a low resource language. For this purpose, we use Common Crawl Corpus (CCC) of December 2016 [7]. This dataset is 200+ TB in size. We analyze this data using Elastic Compute Cloud (EC2) [8] and Elastic Map Reduce (EMR) [9] services provided by Amazon Web Services (AWS) [10]. To build and analyze the corpus, we first extract the Urdu content from CCC via Compact Language Detector 2 (CLD2) [11] and then, examined its different features. First, we perform overall analysis and find statistics like top-level domains (TLDs) and second-level domains (SLDs) of corpus documents. Then, we examine its domains by finding domain categories and hosting locations. Next, we study multilingual characteristics of the corpus. We also take insights into resulting corpus by finding the distribution and diversity of content using Zipf’s law [12] and Urdu token filtration. Our major findings in this study are as follows:
The rest of our paper is ordered as follows: Section 2 provides the details of Common Crawl dataset. Next in Section 3, we discuss our methodology to build and analyze Urdu corpus. The results of our study are presented in Section 4. Then, we describe the linguistic features of Urdu corpus in Section 5. In Section 6, we summarize the related work. Finally, we conclude our study in Section 7.
Common crawl corpus description
For our study, we need a dataset that represents the whole web. However, crawling the web at the web scale is both time consuming and resource intensive. In general, search engines regularly crawl the whole web in order to keep up-to-date information but such crawled data is not freely available. For our study, we rely on CCC [7] which is freely provided by the Common Crawl organization. We select the CCC released in December 2016 for our analysis. In the past, CCC has been used to study different characteristics of the web and for building language models [13, 14].
Table 1 presents the overall statistics of the dataset. It consists of 2.87 billion web-pages and has a size of 200+ terabytes. Each web-page has three associated file types namely Web Archive (WARC), WAT, and WET. WARC file stores the raw crawl data and also contains information of complete HTTP header for both request and response. WAT and WET files contain meta-data and plain text information of the web-page. We note that HTTP request header contains information regarding IP address of the server and the URL of the web-page. Similarly, HTTP response header contains information of content type/size, HTTP version, web server type and document language, etc. Raw crawl data contains complete source code of web document that can be JavaScript, HTML tags, and text etc. We perform our analysis on 51200 WARC files. A sample of WARC response is shown below:
Common Crawl December 2016 data statistics
Common Crawl December 2016 data statistics
In this section, we discuss our methodology for analyzing our dataset. First, we describe details of distributed computing setup used in this paper. Next, we present our process of detecting multilingual content from the web-pages. Finally, we provide details of Urdu language corpus.
Amazon elastic mapreduce
Analyzing 200+ terabytes of data is one of the most challenging tasks that requires a distributed computing environment. For this purpose, we rely on Apache Hadoop platform [15]. CC corpus is available at Simple Storage Service (S3) provided by Amazon Web Services (AWS) [10]. We use EC2 and EMR services for data processing. EMR provides the MapReduce framework and EC2 provides computing services [9, 8]. The nature of our analysis demands a high-compute and memory-intensive environment. We use 13 c3.8xlarge EC2 instances where each instance has 60 GB memory and 32 cores. By default, each instance of c3.8xlarge is provisioned with 24 Hadoop mappers and 8 reducers. In addition, Hadoop streaming API with mapper and reducer written in Python language is used. In order to get main statistics of each document such as IP address, content type, web server type, and content length, we use WARC Python module in mapper script. This script also analyzes raw content of each document for natural language detection. Complete CC corpus was processed in 340 normalized instance hours of EC2 to extract the desired results.
Language detection
There are many open source tools available for natural language detection e.g., langid, langdetect, ldig, and Compact Language Detector 2 (CLD2) [11]. Langdetect is a language detection library provided by Google which can detect up to 55 different languages [16]. Langid is another Python language detection library that can detect up to 97 different languages [17].
For our analysis, we use CLD2 Language detection tool which is written in C++. It uses n-grams to classify different language scripts and is based on Naive Bayesian classifier. It can identify up to 161 different languages. We note that CLD2 accepts "UTF-8" encoded string and returns details of top three languages present in the content. In order to get the text of given web document, we remove HTML, JavaScript, and styling tags before analyzing it with CLD2. For this purpose, we have used Python re module. Figure 1 shows CLD2 output for three different input strings. In first case, input string is completely in Urdu language while in the second and third case bilingual and multilingual content is present. In each case, CLD2 has returned three levels of information i.e., content language, content bytes, and percentages. We note that in case where content of more than one language is detected, the order of language is decided on the basis of content bytes such that LG1 bytes > LG2 bytes > LG3 bytes .

CLD2 sample output for three different inputs.
In this section, we first present statistics of web documents and domains for the complete dataset. Next, we discuss different properties of the Urdu documents obtained from the Common Crawl dataset. Finally, we describe multilingual characteristics of Urdu corpus.
Overall web statistics
We start by analyzing different statistics of documents, domains, MIME types, content bytes, and language. As described in Section 2, our dataset consists of 2.87 billion web documents that correspond to 25.7 million different domains. To explore different MIME types such as text, image, etc., present in our dataset, we use information from the HTTP response headers for each web document. Our goal is to find the most dominant content types and web document sizes. Figure 2 shows document frequency against different content sizes with logarithmic bins for different top MIME types. As expected, text/html is the most dominant MIME type with a share of 97.9% in terms of document frequency and 97.8% in terms of content bytes. On the other hand, only 0.5% documents are of image type. Traditionally, crawling the whole web requires huge storage resources therefore crawlers in Common Crawl are designed to prefer documents with text content to save storage. In addition, we also observe that most of the web documents have content size between 8KB and 1024KB. Figure 2 also shows that for Urdu documents, we observe similar trends with much lower number of documents.

MIME types - document frequency vs. content length: y-axis=log scale.
Next, we examine web content of different languages present in our dataset. For this purpose, we count documents for each language as detected by CLD2. Table 2 presents top ten languages with reference to document frequency. As expected, we observe 2.48 billion (86.49%) documents have content in the English language. Moreover, the Russian language has a share of about 8.61%. Similarly, other major European languages such as German, French, Spanish, and Italian have a share in the range of 2.43-5.2% with a total of 471.18 million documents. In addition, we focus on the content present in the Perso-Arabic script. We found that languages such as Arabic, Persian, and Urdu have very low rank of 19, 24, and 67, respectively. Collectively, these languages have 47.34 million documents (1.68%). Finally, we filter out 1.28 million documents having Urdu content for our further analysis.
Language rank with respect to frequency
To analyze Urdu content, first, we find the size distribution of Urdu documents. Next, we explore the top-level and second-level domains of Urdu web documents. Finally, we analyze the domains of Urdu documents by finding hosting location and categories.
Document size
To better understand the different characteristics of Urdu documents, we start by examining the content size of 1.28 million web-pages. We found that most of Urdu web documents have content size between 16KB and 256KB with peak at 64KB. This is similar to the overall results presented earlier, however, Urdu web-pages are of limited content size. Figure 3 shows the document frequency for different bin sizes.

Urdu document frequency vs. content length (KB).
Next, we examine each URL and extract top-level and second-level domains. We also count their frequency along with content size in bytes. Overall, we found 23297 different domains for Urdu documents. Our goal is to ascertain content rich domains in terms of frequency and bytes. Table 3 shows statistics of top eight TLDs and SLDs. We observe that . com domain is the topmost TLD with 48.99% and 51.69% with respect to frequency and bytes, respectively among all Urdu domains.
Top-level and second-level domains statistics - Freq.=Frequency
Top-level and second-level domains statistics - Freq.=Frequency
As Urdu is the national language of Pakistan, we expect to see . pk domain as the second highest TLD, however, surprisingly ir domain is at 2nd rank with 14.94% documents and . pk is at 5th rank with 2.77% documents. We note that Urdu and Persian languages have many words in common therefore it is likely that Persian web-pages with short content are considered as Urdu by CLD2. We will explore this discrepancy in detail in the next section where we describe our multilingual analysis.
Similarly, we investigate the second-level domains. We observe that urdulughat has the highest rank with respect to frequency, however, blogspot has contributed highest amount of bytes with 10.49% bytes. This difference stems from the fact that urdulughat is an Urdu dictionary website that shows meaning of words whereas blogspot contains articles with lengthy content. In addition, Wikipedia, urdu2eng, geourdu, and urduvoa have 4-5% of documents. We note that in case of SLD, the "Other" category indicates a long tail of Urdu domains.
In order to investigate the domains which are rich in Urdu content, we calculate the average Urdu content percentage for each domain. Figure 4 shows the cumulative distribution function (CDF) of average Urdu content percentage. We observe that 39.57% domains have less than 1% average Urdu content. Similarly, only 20% domains have average Urdu percentage greater than 8%. Furthermore, 0.28 million (23.8%) documents have less than 1% Urdu content.

CDF of average Urdu percentage per domain.
Here, an interesting question arises that how the distribution of documents and domains varies when we increase the average percentage of Urdu content. Figure 5 shows normalized percentage of documents and domains with respect to average Urdu content percentage. On the x-axis we have 20 bins and each bin represents the normalized number of documents and domains in that bin. We observe that there is a sharp decrease from 1 to 10%. One possible reason for this behaviour is the multilingual support by many domains. For 30-60% of Urdu percentage, number of documents and domains is almost the same. By applying a filter of 50% of Urdu content, we have only 30% (0.36 million) documents and 5% (1150) domains, respectively. On the higher end, for 95% Urdu content, only 74 thousand documents and 248 domains are available. Interestingly, domains greater than 50% can be used as seed for focused crawling to build language resources for Urdu.
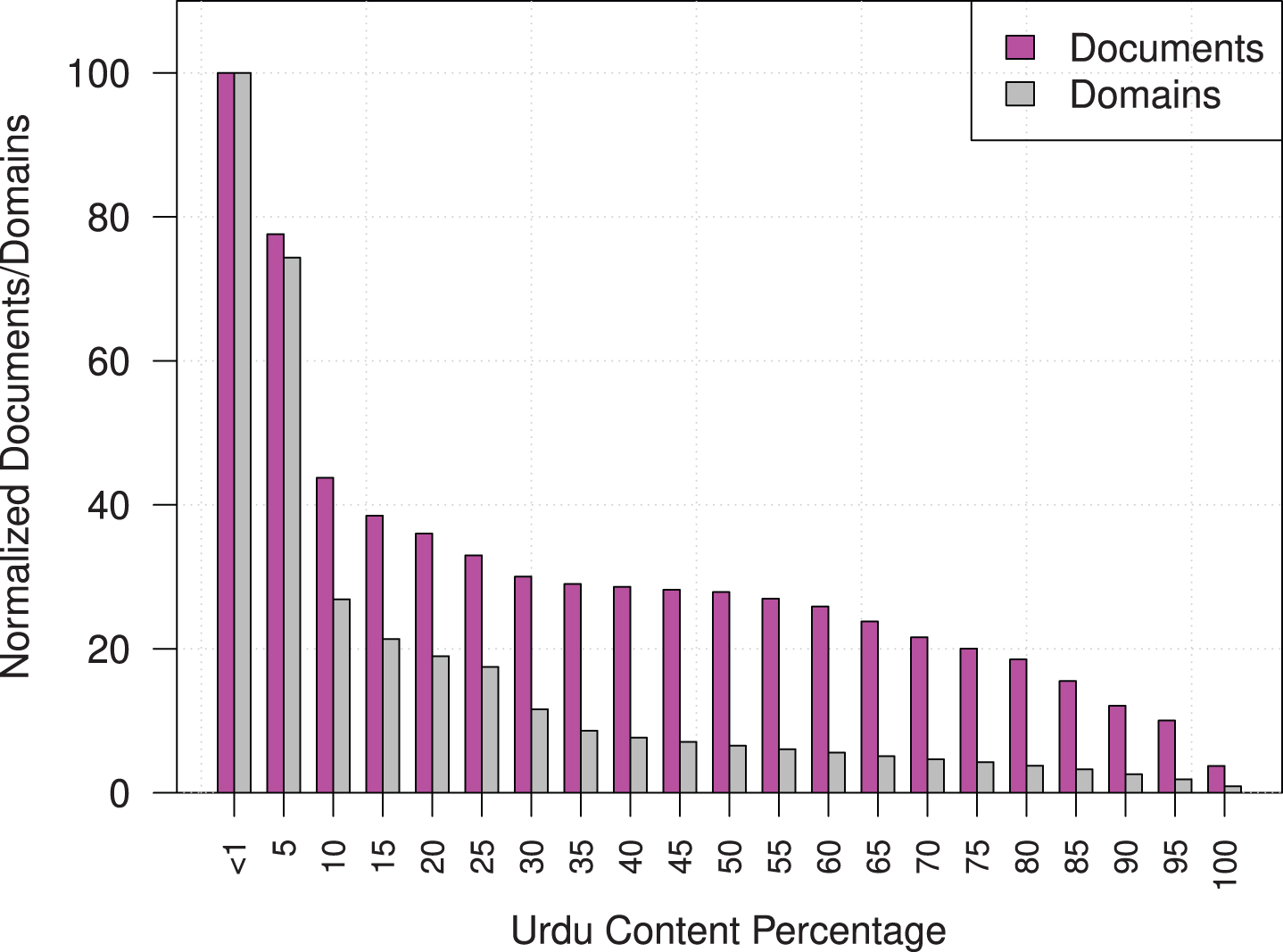
Urdu content percentage of domains and documents.
In order to find hosting country of domains, we use MaxMind Geo IP location database [18]. As some Urdu domains have . pk TLD, we also find Geo IP location of these domains along with complete Urdu domains having at least 1% Urdu to exclude noise. In overall analysis, it was found that Urdu domains are hosted in 75 different countries and considerable domains are hosted in Iran that was quite unexpected. In order to observe this trend with different percentages of Urdu content, we decide to explore with minimum of 1% and 5% Urdu content. Figure 6 shows these statistics both for complete Urdu domains and . pk Urdu domains at two level of Urdu percentage.
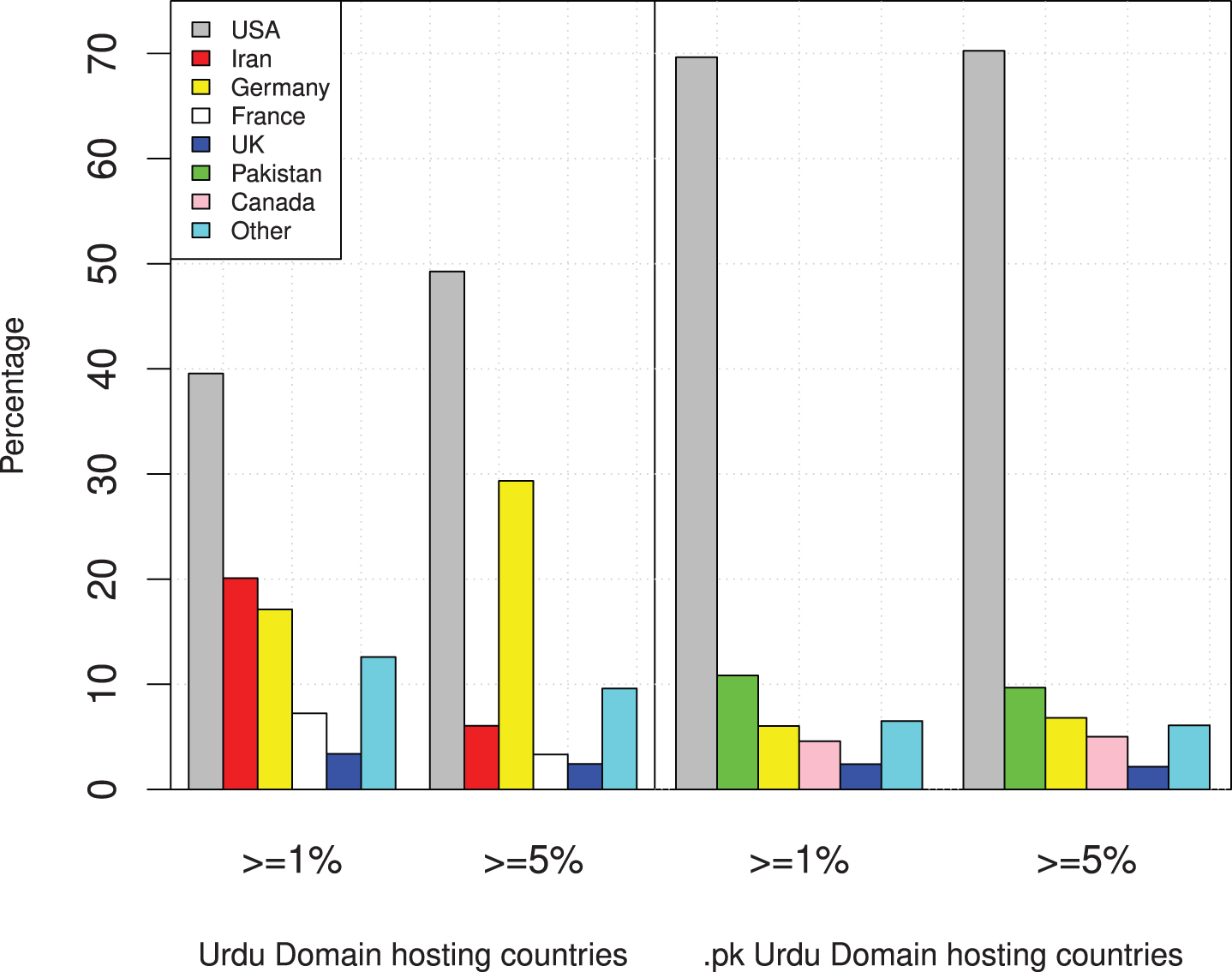
Domain hosting countries statistics for at least 1% and 5% Urdu.
We observe that 40% Urdu domains are hosted in the USA with at least 1% of Urdu. This figure increases to 70% for a minimum 5% Urdu for USA. This behaviour is opposite for Iran which is second in hosting Urdu domains. We can see that as Urdu percentage threshold is increased, website hosting in Iran decreases from 20% to 5%. This strongly confirms our earlier observation regarding the overlap of Persian and Urdu language. Similarly, Germany is the 3rd country that hosts Urdu domains and its contribution goes from 18% to 29% with increase of Urdu percentage. Other prominent countries where Urdu domains are hosted are France, UK, and Canada. For Urdu domains having . pk TLD, we observed similar trend of countries when we change Urdu percentage from 1% to 5%. USA is hosting maximum Urdu domains (70%) while Pakistan is the second with 10% domains. Other observed countries are Germany, Canada, and UK. One reason that most domains are hosted in USA for both cases is that most reliable hosting companies are located in USA. Additionally, our domain hosting analysis highlights that we cannot correlate Urdu content hosting with the geographical location where the language is mostly spoken or written.
In order to provide reliable web services and better performance, host systems are connected to more than one network. This strategy is also used for load balancing. While finding the total number of domains, it was found that some domains are multi-homed. So we decided to find IP based Geo locations of those domains for each IP. We observe that about 7% Urdu domains are multi-homed and 92% are single-homed. Out of these 7% multi-homed domains, 25% are hosted in France, 14% are hosted in Netherlands and Portugal and almost 13% are hosted in Spain, Ireland, and Russia. Details of countries that have multi-homed domains are shown in Table 4.
Multi-homed Urdu domain hosting countries
Multi-homed Urdu domain hosting countries
In order to find top categories of Urdu domains, we pick top 100 Urdu domains with highest document frequency that contains about 88% of total Urdu documents. We manually assign a category to each domain. Table 5 presents details of each category. Our analysis shows that about 21% of domains belong to the news category. It is followed by entertainment category with 16% share. Other well known categories are portal, education, and shopping with 11%, 8%, 7%, and 5% shares, respectively.
Urdu websites top categories
Urdu websites top categories
We start the analysis of multilingual web-pages by finding most frequent combinations of Urdu content with other languages. Next, we analyze the language order and web-page size of multilingual documents.
Urdu combinations with arabic, english, persian
Multilingual content is one of the key features of the web. Websites are often offered in multiple languages so that people speaking different languages can take advantage of the information. Next, we explore combinations of different languages in Urdu documents. As CLD2 returns maximum of top three languages for each document, it can help to find top language combinations with Urdu. We select English, Persian, and Arabic as three other languages to explore different combinations. Furthermore, we select top six combinations involving Urdu content. For instance, "Urdu,English,Arabic" combination means Urdu, English, and Arabic are found as first, second, and third language, respectively. We analyze Urdu documents with at least 1%, 5%, 10%, 15%, and 20% Urdu content.
Figure 7 shows complete details of Urdu combinations with other languages. We can see that "Urdu-only" documents percentage increases as we move from 0 to 20% of Urdu. A similar trend is observed from "Urdu-English" combination. In our analysis, we have also observed two other combinations of Urdu, Arabic, and English. In first combination, Arabic is LG1 and in second, it is LG3. Those documents where Arabic appears as LG1, decreases in frequency as Urdu percentage increases from 0% to 20% while in the second case it increases. We believe this is due to the presence of large number of Urdu speakers in the middle-eastern countries.

Language combinations at different Urdu percentages.
Figure 8 shows the boxplot of Urdu content percentage for SNG, LG1, LG2, and LG3 to highlight the variance. We also provide the percentage of documents at the top. For example, only 11.78% of these documents are detected as SNG. However, these documents have higher Urdu content percentage with 94% median. We note that in case of LG1, 25.68% documents have median Urdu content percentage of 72%. Our results show that although considerable number of documents have Urdu as LG2 and LG3, however, they have very low percentage of Urdu content. The key takeaway from this figure is that domains present in SNG and LG1 should be preferred for fetching Urdu rich content for building language models and information retrieval systems.

Language order and Urdu percentage: first language (LG1), second language (LG2), third language (LG3), and single language (SNG) with percentage >=1.
Figure 9 shows complete distribution of Urdu documents in terms of web-page size. We show three bins for web-page having sizes in the range of 1-16KB, 16-256KB, and 256KB+. Each bin contains percentage of documents having Urdu as single language (SNG), first language (LG1), second language (LG2), and third language (LG3). We find that for short web-pages up to 16KB, 54% documents are SNG. This behaviour is mostly due to the presence of large number of web-pages from Urdu dictionary urdulughat . info, Urdu web portal urdupoint . com, and Urdu ur . wikipedia . org.

Percentage of Urdu document frequency vs. content length for Urdu as first language (LG1), second language (LG2), third language (LG3), and single language (SNG) with percentage > = 1.
However, with moderate size web-pages in the range of 16-256KB, we observe percentage of documents with LG1, LG2, and LG3 has similar share ranging from 32-39%. For this bin, only 2% documents are SNG. Finally, web-pages with higher content length is dominated by LG2, and LG3 with share of 48% each. These results are consistent with our earlier results presented in the Fig. 8.
In this section, we first describe the algorithms used for duplication detection. Next, we analyze the diversity of our Urdu corpus using token analysis.
De-duplication
Clean corpus is an essential requirement for performing NLP and IR tasks. The performance of models for tasks such as summarizing, text classification, Part Of Speech (POS) tagging, and information retrieval highly depends on quality of corpus. De-duplication is a process of detection of duplicate documents from the corpora. The task of duplicate detection is an essential part in web corpora generation as this information is used to create more efficient use of data storage space, detection of plagiarism or to decrease the size of same index entries in data retrieval.
Considering the applications of de-duplication, we perform duplication detection on the content of documents after removing HTML and JavaScript tags. We perform duplicate detection in two stages. First, we label exact duplicate documents by finding and comparing the cryptographic algorithm, Message-Digest 5 (MD5) [19] values of content of documents. In next step, we use Apache Solr implementation of near duplication algorithm using fuzzy hash algorithm TextprofileSignature [20] to label documents with near duplicate contents in our corpus. We index the content of documents in Apache Solr 6.6.2 with TextprofileSignature duplication enabled. Solr generates the hash values of each document using duplication algorithm and we use generated hash values to compare and label the near duplicate documents.
The duplication results show that 8.58% documents are exact duplicates in our corpus and after removing exact duplicates, we further analyze corpus for near duplicates. The result shows that 12.35% documents are near duplicate. We examined the duplicate pages in detail and found that pages are labeled as duplicates due to website archival. Websites archive their pages on different URLs and the crawler fetched both pages resulting in duplicate documents.
Token analysis
The quality of corpus lies in the size and the diversity of the content. So, we decide to analyze the diversity of corpus by finding distribution of words. First, we extract Unigram, Bigram, and Trigram tokens from the corpus. After that, we analyze the distribution of tokens by applying the Zipf’s law [12]. Zipf’s law states that if we assign ranks to all words of language according to their frequencies in some long text, then the resulting frequency-rank distribution follows a very simple empirical law and plot of log (rank) vs log (frequency) will produce a straight line with slope -1. We also investigate the richness of Urdu in corpus by finding the Urdu tokens in corpus. We use Unicode range of Urdu characters to detect and eliminate the non-Urdu tokens from the corpus [21]. We check each character’s encoding in token and if any character’s encoding was out of the range of Urdu Unicode, then it was considered as non-Urdu token.
Table 6 provides the Urdu token distribution. The result shows the large size and diversity of corpora with 1.25 billion total and 18.14 million unique tokens. However, the filtration of non-Urdu tokens shows the huge contribution of non-Urdu tokens in the corpus. To find the reason for this behaviour, we investigate the corpus in detail and find out that our corpus contains many frequent non-linguistic tokens (HTML and JavaScript code tokens). We also found that writing script overlap of Perso-Arabic languages i.e., Persian, Arabic, and Urdu was partly a reason for non-Urdu content. We plan to discuss these challenges of content selection and language vocabulary overlap in our future work.
Urdu corpus tokens statistics
Urdu corpus tokens statistics
The Zipf’s law distribution of corpora is given in Fig. 10. The result shows that corpus slope falls suddenly after 0.01 million frequency. We investigate the corpus tokens and found that most common words such as stop words, non Urdu words, and verbs show a large frequency compared to other tokens which create this behaviour. The straight line shows the predictive behaviour of Zipf’s law and it shows that Common Crawl Urdu corpus follows the Zipf’s law distribution.

Zipf’s law distribution of word n-grams of Urdu corpus.
For the evaluation of diversity and effectiveness of corpora, researchers have used state-of-the-art metrics. Authors create multilingual corpus using Common Crawl and find duplicates using hamming distance to find the effective documents in corpus [3]. The result shows that 32% documents were duplicates in corpora which shows the importance of de-duplication in corpus analysis. Similarly, in [22], authors analyze the quality of corpus by finding the Zip’s law distribution of non-aggregated English text. The results provide the ground to claim the validity of Zipf’s law on English text. The similar effort is done in [23] to find the reliability of Zip’s law on the Arabic language.
Researchers have built the low resource language corpora by developing language focused crawlers. In [3], authors have developed the multilingual corpus using Common Crawl data and developed their language focused crawler. They create the corpora of 12 million pages with 10.8 billion tokens from 53 different languages. Similarly, the study performed in [2], focused on fetching the Arabic content only by prioritizing Arabic web-pages during crawling. This experiment produced a corpus of 150.9 million web-pages from 768K domains.
Web content classification in the regional context is another important research area. In [24], authors have found that English language web content is still more pervasive, however other European languages are also increasing with time. For this study, they focused on words frequency in web content for English and other languages over multiple years. In [13], researches have also studied WWW and measured nine web characteristics from page level to website level. They have found top ten languages of corpus using open source languagedetection library [25]. They have observed that most web documents are in English and other top languages are French, German, Russian, and Spanish. This was the first study of WWW in multilingual context with some language detection library
In [1], authors have analyzed the content of Common Crawl Corpus, published books, and magazines to introduce the first Kurdish text corpus that consists of 0.45 million documents and 188 million tokens. Similarly, authors in [6] have used CCC to understand the regional context of WWW and have shown many region-based statistics. They measure the distribution of language in web-pages using open source language detection module CLD2 and found that English language web content is still more pervasive in WWW. They also found the distribution of Asian languages in the world-wide-web.
Conclusion
In this paper, we made an effort to build a corpus of the Urdu language using freely available CCC. For this purpose, we have analyzed the CCC of December 2016 via Amazon EC2 and EMR services. Out of 2.87 billion documents of the dataset, we filter 1.2 million Urdu documents from 23k domains using language detection tool CLD2. We further analyze the domains for TLDs and SLDs and observe that . com, .ir, . org, and . info are top TLDs while urdulughat and blogspot are top second-level domains in terms of document frequency and bytes, respectively. The language analysis of corpus provides the overlap of Urdu with Arabic and Persian which is expected because Urdu is written in Perso-Arabic script. In addition, in case of multilingual content, the Urdu language percentage varies from 60% to 86% when appeared as the first language. Our Urdu corpus has 1.25 billion total and 18.14 million unique tokens. Moreover, the corpus follows the Zipf’s law distribution. In future, we plan to conduct a longitudinal study on Urdu web content growth to gain more insights.
Footnotes
Acknowledgement
This research work was funded by Higher Education Commission (HEC) Pakistan and Ministry of Planning Development and Reforms under National Center in Big Data and Cloud Computing.