
Abstract
There is a lot of cultural heritage information in historical documents that have not been explored or exploited yet. Lower-Baseline Localization (LBL) is the first step in information retrieval from images of manuscripts where groups of handwritten text lines representing a message are identified. An LBL method is described depending on how the features of the writing style of an author are treated: the character shape and size, gap between characters and between lines, the shape of ascendant and descendant strokes, character body, space between characters, words and columns, and touching and overlapping lines. For example, most of the supervised LBL methods only analyze the gap between characters as part of the preprocessing phase of the document and the rest of features of the writing style of the author are left for the learning phase of the classifier. For such reason, supervised LBL methods tend to learn particular styles and collections. This paper presents an unsupervised LBL method that explicit analyses all the features of the writing style of the author and processes the document by windows. In this sense, the proposed method is more independent from the writing style of the author, and it is more reliable with new collections in real scenarios. According to the experimentation, the proposed method surpasses the state-of-the-art methods with the standard READ-BAD historical collection with 2,036 manuscripts and 132,124 manually annotated baselines from 9 libraries in 500 years.
Keywords
Introduction
Nowadays, most libraries and universities had digitized a vast number of historical documents that contain a lot of cultural heritage information that has not been explored or exploited yet. The information retrieval from images of handwritten documents is limited by the performance of actual engines, so its use has not been enhanced [1, 2]. The information retrieval in digital images of historical documents compromises the indexation and transcription process and, that can take years with manually processing. An example is the Transcribed Bentham project where 1,009 manuscripts were transcribed in 6 months employing 1,207 people [3].
Indexing and transcribing are extraordinarily complex processes on digital images of historical documents that deal with inherent properties such as variable interline spacing, overlapping and touching strokes of adjacent text lines. It is widely known that the accuracy of indexation and transcription process depends on how well the document lines have been localized and segmented [4]. The features dependent on the writing style of the author are described below and are showed in Fig. 1.

A real example of relevant handwritten text features related to the text line localization and segmentation task: bounding box (R), ascendant and descendant strokes; component overlapping, the body of characters (shadow text), interline space (P) and lower-baseline (dotted line).
Lower-Baseline Localization (LBL) is the first task in information retrieval from images of manuscripts where groups of handwritten text lines representing a message are identified. The LBL gives a degree of certainty to know in which part of the image the message is located. This information is useful for the Text Line Segmentation (TLS) task, where the particular text lines that must be extracted, grouped and limited [8].
Figure 2 shows an example of two baselines where the sense of the message change depending on whether one or two lower baselines are identified.

Example of two output lower baselines (squared line) in a historical document with handwriting text that can be mistakenly interpreted as one.
One of the main differences between LBL and TLS task is that for the LBL task is important the step for locating the main structure of the document, it means the rows, columns, tables, and groups of text lines that have a meaning. In both tasks, the step for locating the body of characters and the step for locating the text lines are similar. In contrast to the LBL task, the TLS task has a step for segmenting the text line that it is more focused in to find a path that extracts full-text lines but including all the strokes of the characters.
The LBL task is so essential, that recently in 2017, the standard READ-BAD collection was explicitly published for task-focused LBL in historical handwritten documents [2].
An LBL method can be described depending on how the features of the writing style of an author with the steps as mentioned above are treated: the character shape and size, gap between characters and between lines, the shape of ascendant and descendant strokes, character body, and touching and overlapping lines.
The supervised LBL methods ignore most the writing style features, and they sometimes need the manual labeling of the body of characters [7]; however, the manual labeling is stochastic, which cause problems when trying to generalize. For automatically finding the body of characters, others supervised LBL methods only fill the gap between characters as part of the document preprocessing phase [7, 12]; and the rest of the features of the writing style of the author are left for the learning phase of the classifier [7, 12]. For such reason, supervised LBL methods tend to learn particular styles and collections.
In this paper, we present an Unsupervised Lower-Baseline Localization (ULowBloc) method for handwritten historical documents that explicit analyses all the features of the writing style of the author in five steps. In this sense, the proposed method is more independent from the writing style of the author, and it is more reliable with new collections in real scenarios. In addition, our method speeds up the processing of the document because it does not use an exhaustive analysis.
Our ULowBloc method is based on the fact that usually a document has fewer text columns than text rows (lines); therefore, the localization of the columns in a first instance should help to find initial groups of lines [13]. However, a mistake in this first step affects all the next steps. This first step is based on the fact that the localization of text columns is similar to the localization of text rows. This step uses the same techniques that are used to find the text lines (rows), but these are applied vertically.
The second step of our proposed method corresponds to the identification of the body of characters that is a previous step for locating the text lines (rows). This step is based on the fact that the characters with ascendant and descendant strokes, and with touching and overlapping components appear in a text line a lesser amount of times than the other characters; thus, it is possible with a filter to ignore the ascendant or descendant strokes if neighbor characters are different.
In the third step, the text lines can be located using the horizontal histogram of the output of the second step. For each body of characters, one text line must be located.
In the fourth step, the lower baseline of a body of characters is located adjusting smaller segments of lower baselines. This step is based on the fact that a segment of the lower baseline only depends on the characters in a small window. Therefore, the body of characters is divided into windows for estimating a lower-baseline segment.
In the last step, the lower baselines located are grouped according to the spaces that are larger than common spaces between words or between characters.
In our review of the state-of-the-art, unsupervised LBL methods were not found. For our proposed method, some of the best techniques used for the TLS methods were modified to automatically work with the conditions of the LBL task.
This paper consists of five main sections: first, we introduced the lower-baseline localization problem and the highlights of the proposed method. In Section 2, an overview of related works is presented. In Section 3, a detailed description of the proposed method is given. In Section 4, the experimental results are shown and analyzed. Finally, section 5 draws conclusions and future directions.
This section describes the state-of-the-art methods according to the involved stages to perform the LBL. The following subsections show the characteristics that affect the LBL task that has been applied to treat them in different stages.
The Section 2.1 briefly describes the related techniques for extracting columns from a document. The Section 2.2 defines the techniques for identifying the body of characters. The Section 2.3 presents the state-of-the-art techniques for locating the text lines. In the Section 2.3, the state-of-the-art for LBL task, is analyzed. And the last Section, the importance of the lower-baselines localization for the TLS task is demonstrated.
An LBL method can be described depending on how the features of the writing style of an author with the sections mentioned above are treated: the character shape and size, gap between characters and between lines, the shape of ascendant and descendant strokes, character body, and touching and overlapping lines.
Every stage has a different evaluation metric. The Localization of a middle line is evaluated by counting the incorrect hypothesis [14, 15]. However, the LBL is evaluated by calculating the distance between hypothesis and ground truth [2]. In the case of the TLS task, a comparison of bounding boxes is made with the Match Score metric [16].
Extraction of document columns
The first problem for locating lower-baselines is to find the structures and columns that the document contains. The techniques for locating and extracting text lines cannot be applied directly. Thus, the first step is to isolate the structures and columns for reducing the complexity of the identification of the body of characters.
There are three unsupervised approaches for extracting regions. The first one consists of grouping the connected components [17], the second one consists on the search of continuous lines [17]; and the last one, consists of extracting the projection profile of the manuscript [13].
The extraction of regions by the grouping of connected components has proven to be an effective technique for locating text lines that have a clear visual separation, but it has problems for separating columns with touching and overlapping lines.
The search for horizontal and vertical lines to segment columns presents good results in documents that contain tables, but only in these cases.
The extraction of regions by finding the lower valleys in a vertical projection profile (histogram of the ink) has shown that it can be applied to handwritten documents that contain tables or a clear separation between text columns [13].
On the one hand, the unsupervised techniques described above for finding columns are not robust when the document presents touching or overlapping lines. On the other hand, the supervised methods require a well-formed large training set of tagged templates to identify similarities between documents.
Identification of the body of characters
The identification of the body of characters has the objective, on the one side, to locate the text lines and, on the other hand, to avoid the touching and overlapping text lines. Manual labeling of the body of characters is used in supervised methods [7] (see Fig. 3a).

Identification of the body of characters with a) manual labelling, b) smearing filter and c) energy map with alpha blending.
After using some image filtering mask or image blurring technique, some state-of-the-art methods aim to find connected components [10, 19] or to find a path that allows dividing some touching regions [15, 20].
In addition, other filters like dilatation [21] and smearing [18] fill blank areas between characters and words (see Fig. 3b) to extract the edges of each word and characters to generate regions that can be grouped. In both cases, these techniques are not robust for removing the ascendant and descendant strokes, see Fig. 3b.
In [12], it is proposed to use filtering by dilation in the input layers of a neural network to characterize the body of characters.
An energy map is another technique used for filling the blank spaces between characters and words. However, the energy map also increases the information in the interlinear space produced by the ascendant and descendant strokes. Recently, the energy map with the filter alpha blending technique has improved the identification the body of characters because the ascendant and descendant strokes are ignored in the body of characters [15], see Fig. 3c.
There are two principal techniques applied to the Text Line Localization (TLL). The first one consists of finding parallel lines with the Hough transformation [14] that it is enough for regular text lines, but it is not suitable for irregular text lines [5].
The second technique used for TLL is the projection profile extraction. The Projection Profile (PP) is a histogram that allows representing an image as a unidimensional vector in the direction of the writing [14, 22]. The PP is calculated by accumulating the value of the pixels corresponding to the writing ink [23], see Fig. 4. Projection profile is widely used in state of the art for text line localization on regular text lines.

Example of a) projection profile on a text line without touching lines and b) projection profile of a manuscript with touching lines. The dotted lines represent the separation between two text lines. The circles in Figure 4b show the touching lines with ascendant and descendant strokes.
Usually, the projection profile is focused in to locate the peaks (local maximums) for identifying the separation between each text line [14, 21].
Recently, a method focused on the valleys (local minimums) improves the TLL methods that are focused on the peaks (local maximums) [15]. Figure 4 shows an example of TLL using the valleys of a projection profile. The dotted line of the histogram in Fig. 4a shows that the lower valley drops to zero when there are not touching lines, ascendant or descendant strokes. However, in the second case (Fig. 4b) with touching lines, there are not valleys that reach zero. In addition, there is more than one peak for each text line, so it is not evident where there is a text line.
Some of the state-of-the-art methods use the body of characters to reduce the number of peaks when a projection profile is extracted [6, 20]. In Fig. 5a, the projection profile with global and local thresholds is shown. These methods need several parameters to obtain a correct normalization of the projection profile [6, 20]. An Adaptive PP [10, 24] and energy map preprocessing methods have been presented to improve PP technique [6, 20]. However, most of the methods based on the projection profile need of an empirical adjustment of several thresholds and parameters.
Figure 5a shows an example of local and global normalization thresholds for the projection profile. Even though the number of valleys is reduced, it still necessary to find a set of thresholds.

An example of energy map extraction with a) projection profile extraction of handwritten text with global and local thresholds; and with b) energy map with alpha blending method.
In modern notebooks, where there is a lower baseline printed as a guide in the paper, the Lower-Baseline Localization (LBL) is a trivial task.
In other cases, when there is not a guided line in the paper and where the writing style is regular in the text lines, the location of the middle line is enough. Regular text lines correspond to documents with text lines that have a similar width, in which there is a continuous and parallel separation between two neighboring text lines. There are two approaches for LBL task that can produce a middle line in the average location of the character body (see Fig. 6a) [5, 25] or a set of points that fits to the lower-baseline (see Fig. 6b) [2, 26].

In the cases of irregular text lines or complex-structure documents, such as historical documents, it is necessary to apply an LBL method [11, 27]. Irregular text lines correspond to the handwritten text, in which an irregular or even touching neighboring lines are presented. Figure 6 shows an example of regular and irregular text lines.
On the one hand, the problem of locating text lines is that the ascendant and descendant strokes make challenging to find a pattern in the separation between two text lines. On the other hand, it is not easy to ignore the ascendant and descendant strokes because they depend on the author and style of writing. Therefore, in the state-of-the-art a set of thresholds must be pre-defined to ignore them [6, 21].
Supervised LBL methods are style, alphabet, and language-dependent [28]. The supervised learning methods [27] require a large collection of sample for the training stage. For example, in [7] for training a convolutional neuronal network, the size of the ground-truth baseline is increased with smaller sub-images of the original manuscript that are extracted and relabeled.
There are some semi-supervised methods for lower-baseline detection that require human intervention [11, 25]. Semi-supervised methods need a manual adjustment of the training stage to estimate the lower baselines based on a blurred image [9, 11]. These methods show the baseline hypothesis to be corrected by a human [29]. After that, the method is retrained using human corrected baselines. The intervention of the human is crucial for labeling a new sample of data.
It is worth keeping in mind that the output of the LBL task is used to segment text lines. Segmenting a text line requires that, once the lower baseline is located, the path that allows all the characters of a text line to be extracted correctly is searched (see Fig. 7). The result of the text line extraction is an irregular polygon that contains the bounding box of each text line. It is important to consider the ascendant and descendant strokes in a TLS method because an incorrect segmentation of the bounding-box would generate problems in the indexing or transcription stage.

A human text line trace by the finding of a path between two neighboring text lines.
The TLS unsupervised technique that divides the manuscript image into windows shows that can be modified to irregular text lines [10]. However, this technique does not consider touching lines in its solution. This technique is based on the fact that a point of the lower baseline only depends on the characters in the context. Therefore, the body of characters is divided into windows for estimating a lower baseline point.
The proposed ULowBloc method analyses the writing style features of a document in five steps that are described as follows (see Fig. 8):

The general process of the proposed WEM method. The input an image of the manuscript and the output is the located lower-baselines.
Document column extraction is necessary to facilitate the LBL to isolate the columns that contain an image of a manuscript. For this step, we propose a document column extraction guided by an energy-map extraction and a projection profile characterization (see Fig. 9). The extraction of columns with a projection profile with a vertical extraction of the energy map can avoid the touching and overlapping lines, and the ascendant and descendant strokes. The objective of the identification of the body of characters is to remove the ascendant, descendant strokes, and touching lines. For this step, we propose to apply a horizontal energy map extraction not only to highlight the features of body of the characters but also to attenuate the upper and lower descendants (Fig. 10). For the localization of the text lines, we propose to use the horizontal projection profile of the horizontal energy map of the above step to locate the body of characters. The initial limit of a body of characters is detected when the valley (value of zero in the histogram) in the PP change to a greater value and the final limit when the value reaches to zero (Fig. 11). The lower baseline is located finding a set of points that better fit at the lower baseline of the character body. For this stage, we propose to divide the horizontal energy map into windows (Figs. 12 and 13). This step is based on the fact that a segment of the lower baseline only depends on the characters in a small context. Therefore, the body of characters is divided into windows for estimating a lower baseline segment. In the last step, the columns that were not detected in step 1 are extracted using the statistical information of the space between characters, words, and columns. A complex document section with more than one text column. This document is from UCL_Bentham_SetP subcollection of the training dataset of TRACK-B.

Manuscripts may contain more than one column of text. Therefore, the first step of the proposed method is to locate the columns of text in the document. For this step we apply the next 6 techniques: Vertical extraction of energy map Binarization of energy map Extraction of vertical projection profile from binarized energy map image Indexation of all valleys that reach zero and its width Elimination of valleys outside of the standard deviation Extraction of columns with the previously detected valleys
The vertical projection profile of Fig. 9 allows searching of sets of valleys with a value equal to zero and removing some valleys outside the standard deviation. In this example, it is possible to extract the two columns from the document.
Identification of the body of characters
We propose to extract the energy map for the first stage of the proposed method to fill the blanks between characters and words (see Fig. 10).

An example of removed descendant and ascendant strokes using an energy map extraction. Every group in the energy map allows aiming the search in the body of characters. Every region in figure 10b represents a body of characters.
The energy map extraction is used as a preprocessing step for increasing the information in the character body and also reducing the information in the interlinear space. After the energy map is extracted, the locating of the lower baseline is less complicated, as it is shown in Fig. 11.
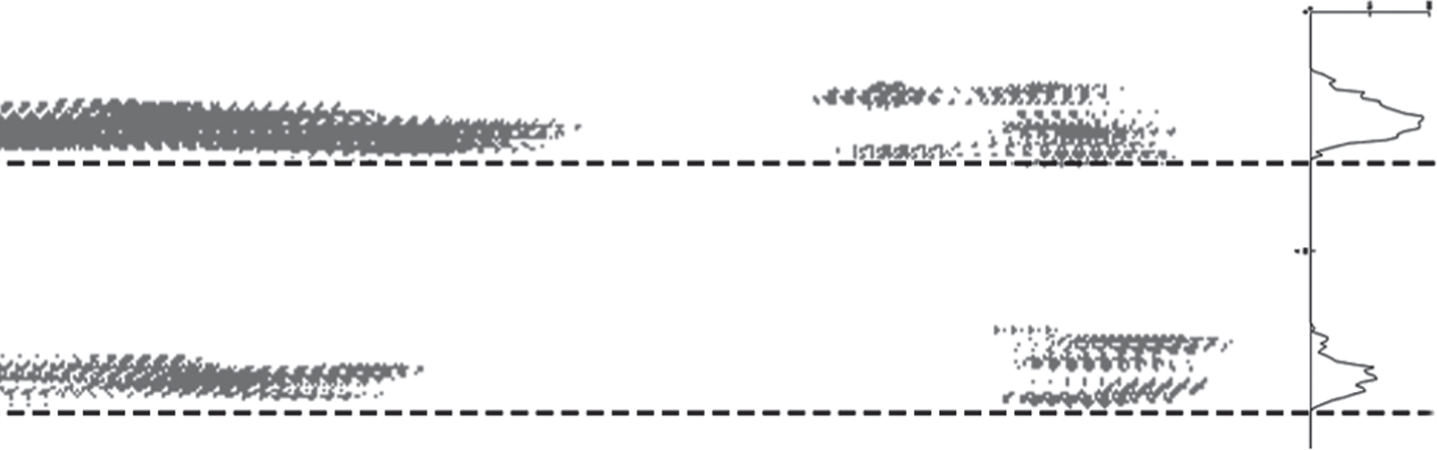
The global location of character body (dotted lines) estimated using the end of the found valleys. As it can see, the dotted lines do not fit at the lower-baseline.
The energy map is generated when the image of the document is smoothed or translated (see Fig. 10). The used energy map extraction applies an alpha-blending proposed in [15]. First, the alpha blending is applied to the image to obtain an energy map. After that, this image is binarized to reduce local minimum values.
Alpha blending is a simple method for transparently overlaying two images [23], I
BG
and I
FG
, within a window size (w). The original image I is covered by the slice image, whose transparency is controlled by the value ∝ in the form:
High-energy regions (most black regions) correspond to the body of characters and low-energy regions correspond to the interlinear space. Figure 10 shows an example of regions with high-energy and low-energy. The resulting energy map is binarized to remove the lower energy regions corresponding to ascendant and descendant strokes.
After the extraction of the energy map is necessary to locate the lower-baselines, in this case, we propose to use the start of the valleys in the projection profile as the text line location (see Fig. 11).
This step is based on the fact that the valleys represent the interlinear space and the peaks represent the body of characters. Figure 11 shows that the beginning of two valleys (when the value of the Vertical PP changes to zero) represents the end of a body of characters.
For the localization of the text lines, we propose to use the horizontal projection profile of the horizontal energy map of the above step to locate the body of characters. When a valley (value of zero in the histogram) in the projection profile change to a greater value represents the initial limit of a body of characters, when the value reaches a valley represents the final limit of this body of characters (Fig. 11). In this stage, the body of characters is distinguished between the interlinear space.
Localization of lower baselines
The body of characters is divided into windows to find a set of points that better fits to the lower-baseline. To estimate the location of the lower-baselines, the energy map was divided into n windows.
The height of the body of characters from the middle of the valleys is calculated to get the lower-baseline localization. This process is repeated in each window to get the lower-baseline localization of every window.
The calculated points that better fits to the lower-baselines are shown in Fig. 12. The result of this last step is the lower-baseline coordinates represented in Fig. 13.
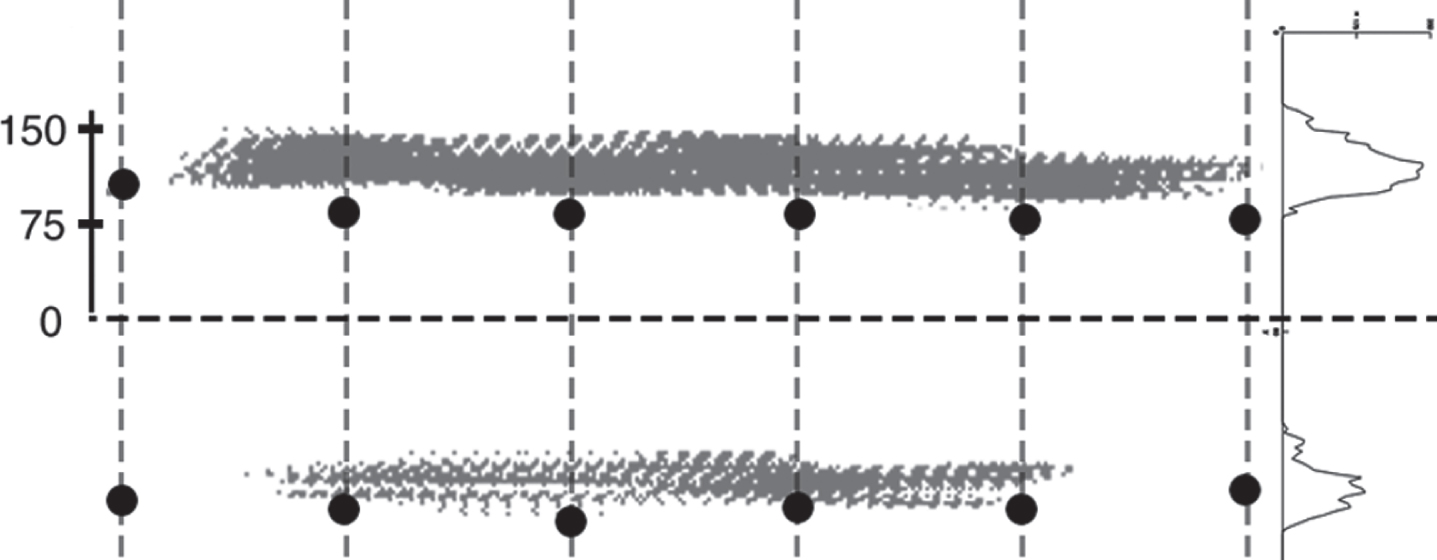
Lower-baselines extracted with proposed ULowBloc method.

Lower-baselines extracted with proposed ULowBloc method.
This step has the aim to find columns in the text lines that were not detected in the first step. A column of this stage is identified by a space that is larger than a normal space between the words that depends on the writing style. In a document, there are a great number of separations corresponding to the spaces between words or characters. Therefore, the standard deviation allows differentiating between them.
In Fig. 14, lowest valleys of the vertical projection profile are highlighted. In Fig. 14, the spaces between words (dotted line) are smaller than the spaces between the two lower-baselines (squared line).
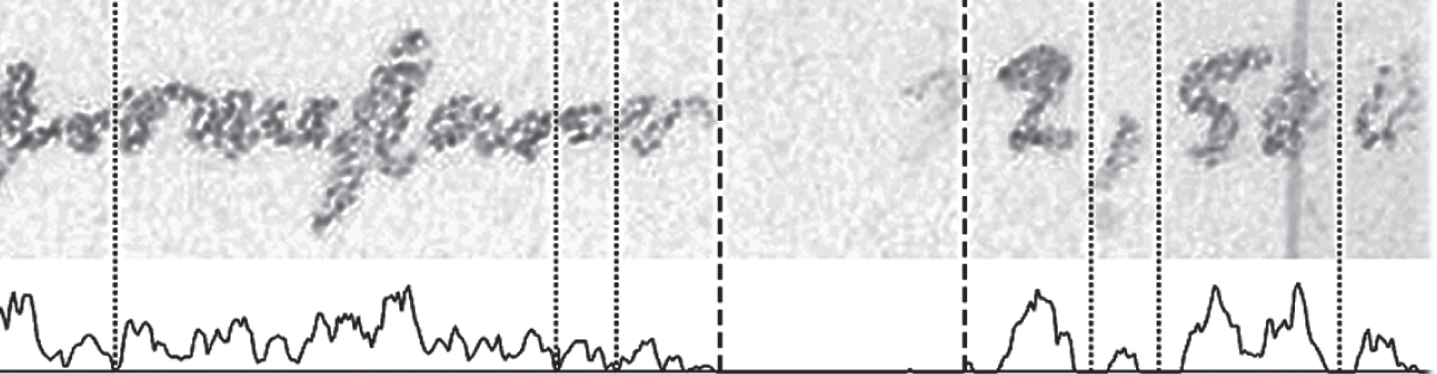
Text line example with two lower-baselines. According to the ground truth, the text line contains two lower-baselines.
The extraction of the vertical projection profile allows extracting the statistical information of the spaces between characters, words, and columns. A considerable irregularity between the space between characters and words determines where there is a column.
The algorithm to identify the text columns is described below: Calculation of the writing angle of the text lines [30]. Extraction of the projection profile with direction to the writing angle of the text lines. Calculation of the size of all the valleys that reaches zero. Calculation of the standard deviation of the size of the valleys.
The evaluation section is divided into three sections, the first section describes the standard dataset used for lower-baseline localization, the second section shows the procedure for the evaluation, and the third section shows the comparison of our proposed WEM method against with the state-of-the-art methods.
Dataset
The Competition on Baseline Detection (cBad) is proposed to compare methods with the standard corpus READ-BAD collection to the localization of lower baselines in handwritten documents. The ground truth data is publicly available. The standard READ-BAD collection contains images of historical documents of a period of 500 years [2]. The documents of the dataset were written between 1470 and 1930 years with an amount of 2,035 images from 19 libraries. This dataset was created because there is a necessity of datasets in new challenges that have complex page layouts, a greater variety of writing styles, different periods of times, and different origin places. The READ-BAD dataset has a wide variety of degradations, paper type, as well as different resolutions and orientations.
The dataset is divided into training and testing set. The training set has 216 labeled images for TRACK-A and 270 images for TRACK-B. The testing set contains 513 images for TRACK-A and 974 images for TRACK-B.
The ground truth data is publicly available. It is important to note that for evaluating the proposed method, only the test set was used because the proposed method is unsupervised.
TRACK-A and TRACK-B are used to evaluate the LBL task with simple and complex documents, respectively. Documents of TRACK-A contains only one text column, a similar length for each paragraph, and a similar inclination for the lines. In contrast, the documents of TRACK-B contain complex documents with annotations on document borders and more than one text column. In addition, TRACK-B has some complex documents with tables, multi-column text, and irregular text lines. Figure 15 shows an example of a document of the TRACK-A and TRACK-B.

Example of a) a simple document and b) a complex document for LBL task.
In the first part of the section, the output of an example image of our proposed ULowBloc method is shown. In the second part, ULowBloc is compared with the state-of-the-art methods in LBL task.
The scheme evaluation used is recognized as a standard evaluation protocol [2, 27] defined as a percentage of shared structure between a baseline hypothesis (HyY) and a baseline ground truth (GT) controlled by a fixed threshold. The evaluation method consists in comparing all the points in the lower-baseline hypothesis to all the points in baseline ground truth. (See Fig. 16). Thus, the evaluation metric needs a manually defined ground truth [2].

Example of ground truth baselines (continuous lines) and baseline hypothesis (dotted lines).
As Fig. 17 shows, our proposed method locates all the lower-baselines that are too similar to the ground truth with complex and simple documents. In the case of a complex document, Fig. 17a, two main columns of text lines were detected by the first step, but the third line in the right column was divided by the fifth step.

However, our proposed method presents problems to detect some short lines with isolated characters and with overlapping lines, see Fig. 18.

An example of unallocated lower-baselines by our proposed method is shown.
For the experimentation stage, only the training set for TRACK-A (simple documents) and TRACK-B (complex documents) is used. The original evaluation scheme proposed for the LBL task for the READ-BAD dataset was used for evaluating the methods [2, 27] in terms of precision (P), recall (R) and F1-score (F1). For obtaining F1-score, the recall and precision values are divided by the number of Ground Truth (GT) lines to count the short text lines as the same importance of the longest ones. The short text lines contain essential information in the context of historical documents, e.g., dates.
For the cBad contest, five teams were training and testing their methods that works in a supervised way. Four of them are based on neural networks DMRZ [7], BYU [31], LITIS [12], and IRISA [27]; and the other uses the random decision tree forest method UPVL [27]. IRISA [29] preprocesses the document for identifying the body of characters by applying a dilation filter. The other works use the training set without preprocessing.
Table 1 shows the comparison of our unsupervised proposed method to all the methods for the TRACK-A. In this case, our proposed method obtains the first ranking position and outperforms all the supervised methods with F1-score.
Global comparison of F1-score on standard READ-BAD TRACK-A dataset [27]
Tables 1 and 2 shows only the systems that participated in both tasks with the same system, because there is not a system that make an automatic classification of the kind of the document in order to know if the manuscript is simple or complex.
Global comparison of F1-score on standard READ-BAD TRACK-B dataset [27]
In Table 2, the comparison of our unsupervised proposed method, with the (supervised) methods for the TRACK-B is presented. In this case, our proposed method is in the first ranking position followed by the supervised DMRZ-3 method in F1-score.
The DMRZ [7] methods implement deep learning. The DMRZ methods and IRISA [29] methods requires additional manual labeling and validation made by the human in order to know if the manuscripts contains more than one column, leading (quantified into small, normal or large), it is landscape, or it is empty image [7] but, in a real scenario in a real scenario the human will not be selecting if a manuscript is complicated or not.
The proposed method does not need a training sample or manual adjustment of its parameters and shows fast processing time.
Cultural heritage information in historical documents can be explored by automatic methods. For information retrieval, the location of the lower baseline allows identifying groups of handwritten text lines of images that represent a message.
In this paper, we present an unsupervised LBL method that explicit analyses all the features of the writing style of the author. In this sense, the proposed method is more independent from the writing style of the author and, it is more reliable with new collections of real scenarios. According to the experimentation, our proposed method obtains the first ranking on TRACK-A and TRACK-B of the state-of-the-art methods with the new standard READ-BAD historical collection with 2,036 manuscripts and 132,124 manually annotated baselines from 9 libraries in 500 years.
In this paper, we performed the separation of the LBL problem into five subproblems. Each of the characteristics and difficulties of subproblems was individually treated. The proposed ULowBloc method is the first method that explicitly measures some writing features of a document to solve the LBL task.
The standard READ-BAD dataset has two samples to validate, one for TRACK-A and one for TRACK-B, the proposed method works for both.
The experimentation stage allows identifying which lower-baselines errors are produced by our proposed method (see Fig. 18). As future work, it is necessary to focus on tiny lower-baselines to improve the proposed method. On the contrary, it is more complicated to know how to improve a supervised method, because all the work is left to the classifier.
Each of the processes of the proposed method works individually and can be applied to other tasks so, they can be individually evaluated.
According to the experimentation stage, the proposed method is robust against different types of paper and writing styles and achieves better results than deep learning approaches [7, 12]. Usually, supervised methods require considerable additional human labeling, correction, effort yielding only slightly higher baseline localization precision. It would be interesting to evaluate the proposed method with more complex documents that contain tables, text columns, and groups of text lines to know the particular features of each step.