
Abstract
The current online education platform has gradually replaced the traditional teaching mode and has become an efficient teaching method. Flipping classroom is a new teaching mode under the background of the rapid development of information technology. It is also an important way of multimedia network teaching. However, compared with the traditional teaching mode, teachers in the online teaching platform cannot judge the students’ psychological activities through the students’ state of mind, and they can grasp the students’ learning status through the teaching process. Based on this, based on the cloud computing platform, this study improves the data transmission effect and improves the algorithm according to the learning process of the online education platform. Moreover, this study combines support vector machine to construct a student state recognition system suitable for online education platform and conducts algorithm performance analysis through experiments. In addition, this study uses MKmeans algorithm, Kmeans algorithm and improved Kmeans algorithm, that is, K-mediods and Xmeans algorithm to compare the pre-processed final data sets. The research results show that the proposed algorithm is suitable for network teaching platform and has certain practical effects.
Introduction
Today’s social networks greatly facilitate people’s lifestyles. With the popularity of the Internet, people’s learning styles have also changed. Online learning is widely used because of its time flexibility and diversification of learning methods [1]. From the original traditional offline courses to online video courses to the current Massive Open Online Courses (MOOC), the change in learning style has made people’s learning life more colorful. As the most popular online learning platform today, the MOOC platform is well known for its online, open and large-scale features, and supports learning methods such as collaborative learning and seminar-based learning. The MOOC platform is easy to use, covers a wide population, and has the advantages of low cost, self-learning, and learning resource sharing [2]. The emergence of MOOC has also produced a large amount of educational data while changing the teaching and learning methods. Applying it to learning analysis is conducive to improving the quality of learning [3]. The purpose of learning analytics is to improve the quality of teaching and learning by collecting, counting, analyzing, and presenting learner-related data. As a research hotspot in learning analytics, cognitive diagnosis models have attracted more and more attention.
The flipping class is a teaching method for students to master the basic knowledge by self-study. In the extracurricular time, the information is obtained by using various teaching auxiliary techniques, such as video, website, mobile phone, iPad and so on. After understanding these basic knowledge, students take part in the classroom teaching activities and continue to study activities, thus making students more effective. Study effectively. The allocation time of classroom enables students to interact with teachers, and enhance students’ mastery of knowledge through teacher imparting. This is the unique feature of the overturned classroom, and teachers may spend a lot of time on the students, but the benefit of this is that the students’ questions can be solved in time
There are several ways of learning that can be reached today: school, online class, tutoring, simple knowledge quiz, and these forms of learning have their own specificity. The advantages of the school are obvious. First of all, there is a learning atmosphere. When everyone is seriously studying hard, we will be able to enter the learning state more easily, and we will have higher learning efficiency. Second, in the school, the teacher arranges the entire learning process, including lectures and tests. Moreover, we can learn better under the scientific arrangement, and if there is doubt in the study, we can promptly ask questions and get answers from the teachers. In addition, under the supervision of teachers and classmates, we will not easily produce lazy and lax. The disadvantage of school education is that it can only play a role when students are at school, and it can’t do anything when students are not in school, such as school and holidays.
There are currently many online course websites, such as Mutu.com and Netease Open Class. The advantage of online class is that it is highly targeted, and learners can learn what they want to learn. Moreover, learners can watch anytime, anywhere, not limited to time and place, only need to have a networked device. In addition, many courses have some free trial projects that can help users make choices. However, the form of online class is similar to school education. It only has unilateral lectures and cannot interact. Although the learner can leave a message, if the message is too much, the author will not have time to answer. Therefore, it is difficult to get answers when students have questions about a certain knowledge point.
Related work
Today’s social networks greatly facilitate people’s lifestyles. With the popularity of the Internet, people’s learning styles have also changed. Online learning is widely used because of its time flexibility and diversified learning styles [4], Was introduced to China in October 2013, and domestic famous universities such as Peking University, Nanjing University, Shanghai Jiaotong University and Fudan University joined [5]. Open edx is an open source online course developed by Harvard University and MIT. The purpose is to establish an online education sharing platform jointly organized by world-renowned universities to improve the quality of teaching and enable more people to learn the quality courses in the online education platform [6]. It was also introduced to the domestic Open edx in October 2013. Open edx has added such well-known universities as Tsinghua University, Peking University, Hong Kong University, Hong Kong University of Science and Technology, and 11 global universities including Kyoto University of Japan and Seoul National University of Korea also have joined Open edx. Unlike the previous two platforms, Open edx is completely free. Although the domestic MOOC platform started late, on the basis of the foreign MOOC platform, it has also made great achievements through the development in recent years [7]. The main domestic MOOCs include Xuetang Online, Chinese MOOC, Chinese University MOOC, and Good University Online [8].
Xuetang Online is a large-scale open online course developed by Tsinghua University on the basis of Open edx. It aims to share the high-quality teaching resources of world-renowned universities and continuously innovate teaching models to improve teaching quality [9]. Xuetang Online advocates student-centered teaching and learning, and actively uses online educational resources to promote hybrid teaching model innovation. Its purpose is to enhance learning by combining different learning methods of online and offline. The school class divides the course into a classroom mode, an autonomous mode and a payment mode for different learners to learn. The school’s online wisdom teaching tool rain class allows teachers to push course pre-study courseware containing course videos, test questions, and voices to the student’s mobile phone, so teachers and students can exchange feedback in a timely manner. At the same time, teachers can answer students’ questions in real time through the barrage in the classroom, which greatly enriches the traditional classroom teaching methods. Chinese MOOC is a Chinese MOOC platform jointly developed by Peking University and Ali in 2015. The platform is a secondary development based on the source code of TopU school. The main courses of the Chinese MOOC platform are Chinese courses, of which the majority of Peking University courses. Its purpose is to provide excellent teaching resources for Chinese people around the world to serve Chinese people all over the world. The courses in the Chinese MOOC are more standardized than other domestic courses, which will reduce the difficulty of teachers’ construction [10]. In the Chinese MOOC, students conduct course study, course community, and notes through video, courseware, and test questions. Good University Online is a high-level Chinese MOOC website developed by Shanghai Jiaotong University in 2014. The purpose is to enable domestic learning enthusiasts to learn the best university courses, so that everyone can go to a good university, and provide quality courses for the majority of learning enthusiasts, and to achieve the sharing of teaching resources and the mutual authentication of credits in domestic universities. At the same time, the platform is open to Chinese people all over the world, hoping to promote and spread China’s excellent traditional culture. Good university online promotes students’ learning and communication through homework evaluation and flipping classrooms and improves students’ initiative in online learning. Moreover, it enhances the teaching interaction between teachers and students by flipping the classroom, and also provides online and offline mixed teaching services for colleges and universities [11]. The Chinese University MOOC is an online education platform jointly developed by the Higher Education Society and NetEase in 2014. In the Chinese University MOOC, students learn through video courses, test questions and participate in forum exchanges, and teachers can participate in online counseling by participating in forums to answer questions, correct homework, and exchange discussions. It aims to provide a better learning environment for domestic study enthusiasts [12]. At the same time, the purpose of the Chinese University MOOC is to provide the Ministry of Education’s national boutique open courses to domestic learning enthusiasts through the platform, and to create MOOC courses for well-known Chinese universities. The value of the Chinese university MOOC is to provide free quality courses for all learners who want to study in China [13].
Basic principles of differential evolution algorithms
The biggest feature of the DE algorithm is the generation of new individuals by mutation. For each individual between these populations, Finally, it is vector-added to another separate vector. Later, this new mutant population replaces the individuals of the original population with a certain crossover probability to form a new population [14]. The final step is a one-to-one competition comparison based on greedy strategies. That is to say, each newly generated individual is compared with its own parent individual, and then individuals with higher fitness values survive. The surviving new individual repeats the above operation until the population is completely converged. Figure 1 provides a brief introduction to the flipping classroom:
Flipping classroom.
The differential evolution algorithm is somewhat similar to the genetic algorithm. The difference between the two is that the differential evolution algorithm is performed under the premise of real coding. In the whole process of the algorithm, the variation and the crossover operation are not the same, and the concept of greed and maintenance is maintained. The following part is to solve the problem of minimization of nonlinear functions, so as to introduce the DE algorithm [15]. First, the flow of the algorithm itself is given a basic understanding, and then this nonlinear function is used to solve its minimum problem. The problem is expressed in the form of min f (x), and the specific steps are as follows:
(1) Initialize population and parameters
Population NP, variable x range of values, dimension of variable x, value of variation factor F, value of cross-factor CR, initial population evolution algebra t = 0 is set. Then, the value of the 0th generation, each individual, and each dimension of the initialized population is generated according to the constraint of (1).
(2) Mutation operation
The mutation operation is also an important operation step of the DE algorithm. In the initial population, three different individuals are randomly selected, and the selected three individuals are not the same as the current individuals. Therefore, the size of the population should be guaranteed to be NP ⩾ 4. Two of them were selected as the initial operation standard, and the values of x (x1, x2, x3, ⋯ , x
D
) of two individuals were obtained to calculate the difference vector. The calculation formula is as shown in Equation (2):
r1, r2 represents the index number of 2 individuals randomly selected. The two individual vectors under the index number are subtracted to obtain a difference vector D. Then, the difference vector D is used to perform the calculation of the mutated individual, as shown in Equation (3):
In the formula, r3 is the index number of the individual who has not calculated the difference vector in the three individuals, and F is the variation factor, which is in the range of [0, 2], which is one of the main control parameters in the DE algorithm. F is called variation factor in this paper and is also called the scaling factor. The main function is to control the scaling of the difference vector. The more xr1andxr2 are the same, the smaller the result of the difference vector will be. We assume that these scaling factors remain the same and have less interference, regardless of the circumstances. That is, during the whole evolution period, when the value is further away from the optimization value, the disturbance amplitude will be automatically reduced, so that the convergence speed of the population becomes faster. That is, the Equations of (2) and (3) are combined to obtain the variation operation formula as shown in Equation (4):
Figure 2 is a schematic diagram of the variation operation of the DE algorithm in two dimensions.

Schematic diagram of the DE mutation operation corresponding to the two-dimensional objective function.
(3) Cross operation
For the purpose of cross-operation, the DE evolutionary algorithm is to improve the diversity of individual populations, which is similar to the mutation operation of genetic algorithms. The main practice of cross-operation is to randomly combine all components of V and X [16] to obtain corresponding adaptive individuals. That is, in order to ensure the evolution of the target individual x
i
(t), the candidate individual U
i
(t + 1) of the target individual must ensure that at least one dimension component of the test individual U
i
(t + 1) is contributed by the variant individual v
i
(t + 1). For other determinants of the dimensional component, it is mainly judged by CR. For other determinants of the dimensional component, it is mainly judged by CR. For this experiment, each dimension component U
ij
(t + 1) (variation vector V, target vector x) is calculated according to Equation (5).
In the formula, v ij (t + 1) represents the j-th dimension component after the t-th generation of the i-th individual in the population, and rand (j) represents the random value of the jth-dimensional component in k. CR is the crossover factor, and k is one of all dimensions selected, which is used to determine that at least one dimension of the test individual is from the variant individual. x ij (t) represents the j-th dimension of the t-th generation of the i-th individual in the population. Then, by using the constraint of the above formula, the value K of the test individual U after the cross operation of the t + 1-th generation individual can be calculated, that is, U i (t + 1). Figure 3 shows the cross-operation of the DE algorithm when the objective function is six-dimensional. In the figure, i [1, NP] ; j [1, D] ; CR [0, 1].

Schematic diagram of the DE cross operation corresponding to the six-dimensional objective function.
As can be seen from the analysis in the above figure, the crossover operation is not only the next step of the mutation operation, but also a further change to the mutation operation, in essence. The individual produced by the mutation operation is mixed with different degrees of different dimensions of the target individual to obtain new individuals. However, the degree of new individual changes is controlled by the crossover factor, so both the crossover and the mutation operations affect the convergence of the DE algorithm.
(4) Selection operation
The selection operation is essentially a “greedy” choice mode, that is, greedy choice of a better individual. From the experimental analysis, it can be known that the selection operation is mainly to judge the fitness value of the individual, and when the individual fitness value is high, it is selected to enter the next generation population. Therefore, it is necessary to compare the fitness values of the generated individuals and the target individuals separately and carry out greedy selection according to formula (6) and put the superior individuals with high fitness values into the next generation populations [17].
Its formula is as follows:
In the above formula, fitness is a function that calculates the fitness value of an individual. Taking the solution of the minimum value of the function as an example, the individual fitness function can be calculated by adding the sum of the squares of the individual dimensional components. Then, the square sum of the dimension components of the new individual and the original individual is judged, and the individual with the smallest square sum value is selected as the new individual to be put into the population.
The core problem of ant colony algorithm and DE algorithm is how to balance the exploration ability and development ability of the algorithm. On the one hand, increasing the diversity of the population will make the DE algorithm search in a wider range, which will enhance its exploration ability and improve the reliability of the algorithm. On the other hand, providing a search direction through a good individual can find the optimal individual more effectively, which will increase its development speed and increase its efficiency [18]. Generally speaking, in order to balance the exploration ability and development ability of the algorithm, more search resources are invested in the vicinity of the good individual neighborhood, in order to improve the search efficiency and ensure the diversity of the population and avoid falling into the local optimal solution.
The F value, that is, the variation factor value, the magnitude of the value can determine the degree of interference of the difference vector to the base vector, so it is a key factor for population convergence performance and diversity. When the F value is small, the population diversity is reduced, the algorithm is easy to fall into local optimum, and the convergence performance is poor. When the F value is large, the convergence speed becomes very slow. Therefore, the value of the variation factor F should be specifically analyzed according to the problem that needs to be optimized. In general, the value of F is distributed between 0 and 1 [19]. It is recommended that the initial value of F be 0.5. If the population diversity is found to decrease during the algorithm iteration, the F value and NP value can be adjusted to maintain the diversity of the population. The optimal solution is obtained for the minimum value of the function. The design parameter rules are: the population quantity is NP = 100, the variable x takes the value range [- 50, 50], the variation factor F is the variable, and the constant value is taken between [0, 1], and the crossover factor is CR = 0.6. Ten experiments will be performed under the maximum evolution algebra G = 1000. The experimental results are shown in Table 1:
Experimental results of DE mutation operation
Experimental results of DE mutation operation
Table 1 shows the 10 sets of experimental data in the case where the remaining parameters are unchanged and only the variation factor F is changed. It can be clearly seen from the experimental results that the minimum number of modern numbers t can be roughly classified into three categories: t value is too small, t value is moderate, and t value is too large. In this paper, the minimum number of modern numbers corresponds to the optimal solution of the function minimum problem to solve the modern number, and the three classes of t values correspond to: The function here is in the process of convergence, and the result is that the convergence is too early, and the local optimal solution is easy to obtain; The obtained optimal solution conforms to the convergence condition and can be used as the final solution of the function; The convergence speed of the function is too slow and the efficiency is too low. It affects various aspects when solving the actual problem and cannot be used as the optimal solution of the function.
By combining the initial population number and the variable x value range, and the experimentally obtained optimal solution algebra for comprehensive analysis, the solution with t value less than 150 is classified into the first category: The function converges too early and falls into a local optimal solution, and the corresponding variation factor F takes a value of 0.1–0.5. The solution with a value greater than 150 and less than 350 is classified as Category 2: The obtained optimal solution accords with the convergence condition and can be used as the final solution of the function. The corresponding variation factor F takes a value of 0.6–0.8. The solution with a value greater than 350 is classified as Category 3: The convergence speed of the function is too slow, the efficiency is too low, affecting various aspects when solving the actual problem, and cannot be used as the optimal solution of the function. The corresponding variation factor F is 0.9–1.0.
Through experiments, it is found that the final result is that the best range of variation factors is 0.6–0.8.
Research on cross-strategy
The cross-strategy of the DE algorithm is divided into two categories: the first type is an exponential cross, which means that the cross-probability distribution in the cross-operation step satisfies the exponential form. The second type is binomial intersection, which means that the cross-probability distribution in the cross-operation step satisfies the binomial form. In the previous section, the DE algorithm uses the second type, the two-type cross. When the rand (j) value is less than or equal to the CR value, the corresponding component of the experimental individual takes the component of the mutated individual. When the rand (j) value is greater than the CR value, the corresponding component of the experimental individual takes the component of the original target individual. However, the exponential crossover is completely opposite to the binomial crossover. When the rand (j) value is less than or equal to the CR value, the corresponding component of the experimental individual takes the component of the original target individual. When the rand (j) value is greater than the CR value for the first time, the corresponding component of the experimental individual from the j dimension takes the component of the mutated individual. In the experiment, it is found that the binomial crossover is better than the exponential crossover. Therefore, the binomial crossover strategy is also adopted in this paper. The difference is that this paper seeks the optimal cross-probability factor value by changing the value of the cross-probability factor multiple times. The values of the crossover factors are discussed below.
The value of the cross factor
Through several experiments, the influence of the value of the cross-probability factor on the function solution is proved. Similarly, for the minimum value of the function, the optimal solution is sought, and the design parameter rules are: The population number is NP = 100, the range of variable x is [- 50, 50], the variation factor is F = 0.5, and the cross-probability factor is a variable ranging from 0 to 1, and the maximum evolution algebra is G = 1000. After that, 10 experiments will be carried out, and the experimental results are shown in Table 2:
Experimental results of DE cross operation
Experimental results of DE cross operation
Table 2 shows the 10 sets of experimental data in the case where the remaining parameters are unchanged and only the variation factor F is changed. It can be clearly seen from the experimental results that the minimum number of modern numbers t can be roughly classified into three categories: t value is too small, t value is moderate, and t value is too large. In this paper, the minimum number of modern numbers corresponds to the optimal solution of the function minimum problem to solve the modern number, and the three classes of t values correspond to: The proportion of the parents is too large, and the diversity of the population is not obvious; The optimal solution obtained meets the condition and can be used as the final solution of the function; The proportion of mutated individuals is too large. In essence, this situation is easy to ignore the global optimal solution, so that its convergence accuracy is correspondingly lowered.
The initial population size, the variable x range of values, and the evolutionary algebra corresponding to the optimal solution obtained by experiments are comprehensively analyzed. When the value of t is less than 250, the corresponding solution is divided into the first category. The experimental individuals have fewer dimensional components, which makes the population diversity decrease and the local optimal solution is easy to obtain. At this time, the crossover factor ranges from 0.1 to 0.3. When t ranges from 250 to 350, the corresponding solution is divided into the second category, and the global optimal solution as the final solution can be obtained, and the diversity of the population can also be guaranteed. At this time, the crossover factor ranges from 0.4 to 0.6; When the value range of t is greater than 350, the corresponding solution is divided into the third class. The mutated individuals occupy more dimensional components and the population diversity is good, but the algorithm may ignore the global optimal solution, which leads to the accuracy of the algorithm. At this time, the crossover factor ranges from 0.7 to 1.0. Through experiments, it is found that the final result is that the best range of variation factors is 0.4–0.6.
The state of the system is considered to be the three most basic state of motion that can be estimated by the student’s eye movement record, which reflects the cognitive process that the student attempts to accomplish through vision. Moreover, a student will alternately be in one of the states in a class. Our system tracks the status of each student as they watch the online course and uses this to estimate what type of cognitive behavior they may be doing.
In order to efficiently process the input face image and derive the learning state of the student in real time, we design the whole process as a four-part process pipeline as shown in Fig. 4. This design is determined by the real-time operating characteristics of the system, and it also helps to take advantage of the multi-core concurrency of modern computer processors to speed up processing.

Overview of the modules of the system pipeline.
Figure 5 shows all the work that our system needs to do before making a judgment about a learner’s learning state at a certain time. In order to highlight the extraction process of the information contained in the data, we only show the various intermediate data of each stage of the pipeline in the figure.

The process of obtaining a learning state estimate.
The purpose of the experiment is to classify learners according to the characteristics of learners’ cognitive ability, so that learners’ groups with different cognitive ability levels can be obtained, and the referenced data can be given for teachers’ targeted education. First, Xmeans is used to get the optimal k value. After that, the final datasets were clustered using MKmeans, Kmeans, K-mediods and Xmeans clustering algorithms, and the clustering effect was analyzed by contour coefficients as shown in Figs. 6–10. Finally, the clustering results are used to analyze the cognitive ability grouping.
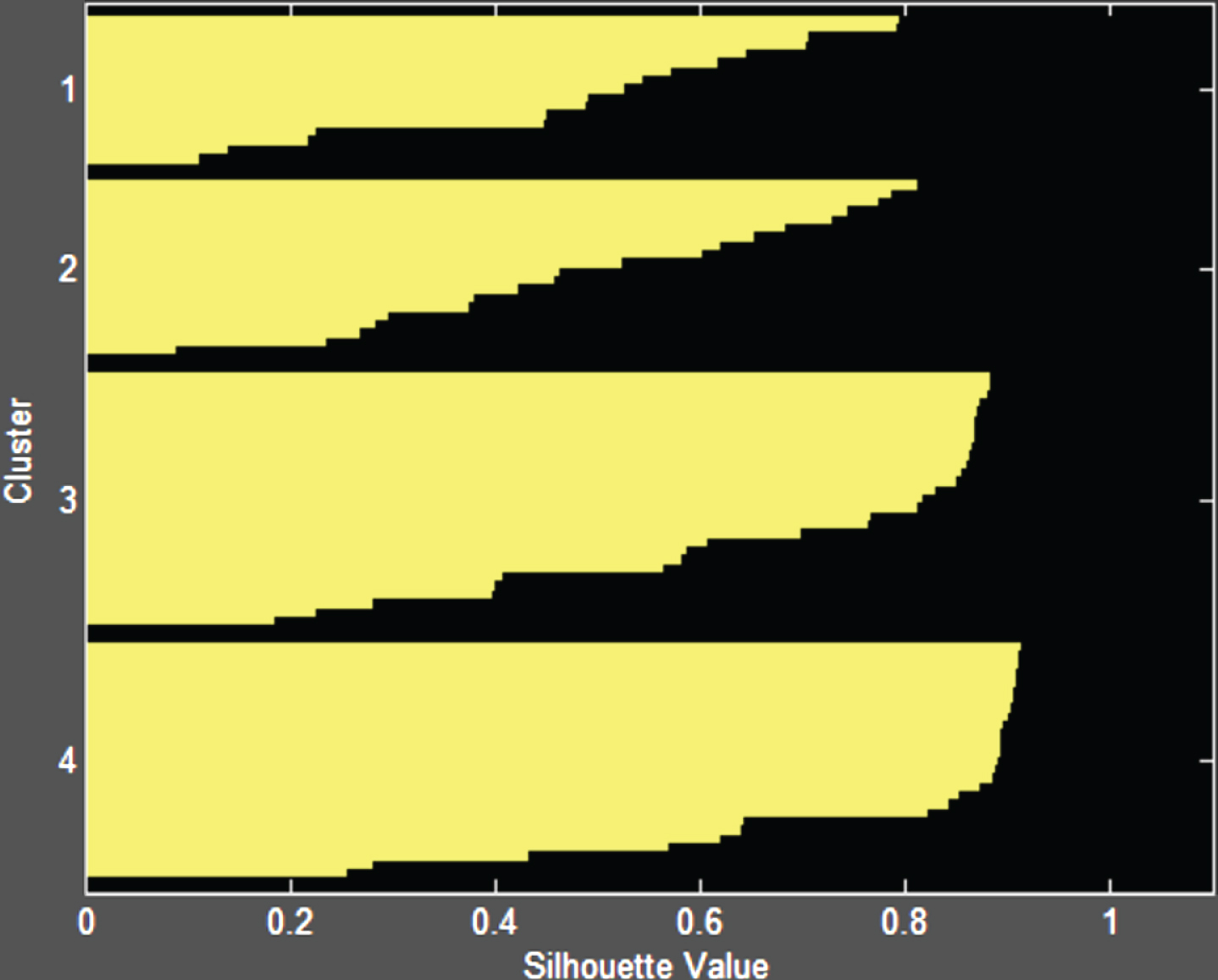
Contour coefficient of MKmeans.
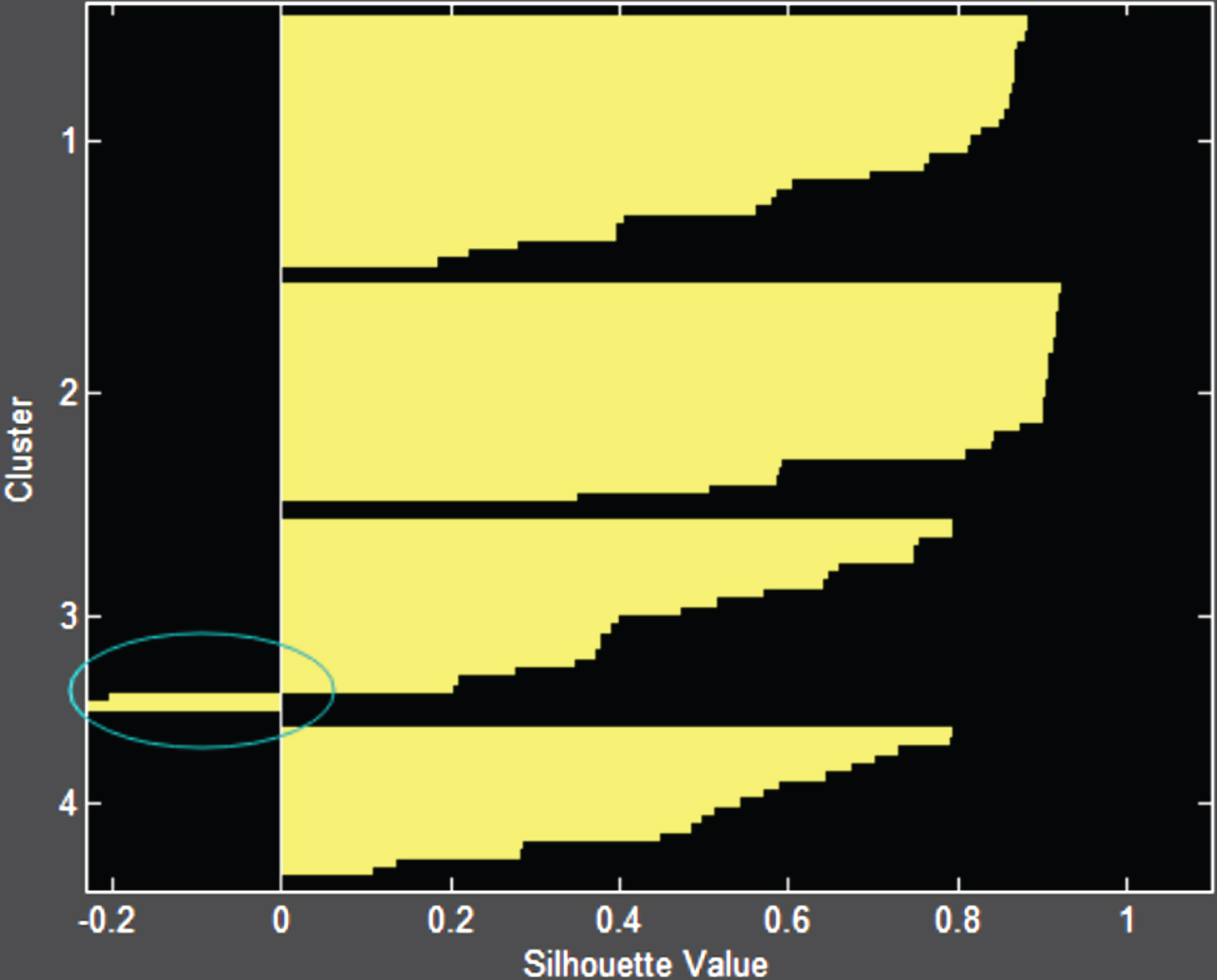
Contour coefficient of Kmeans.

Contour coefficient of Xmeans.
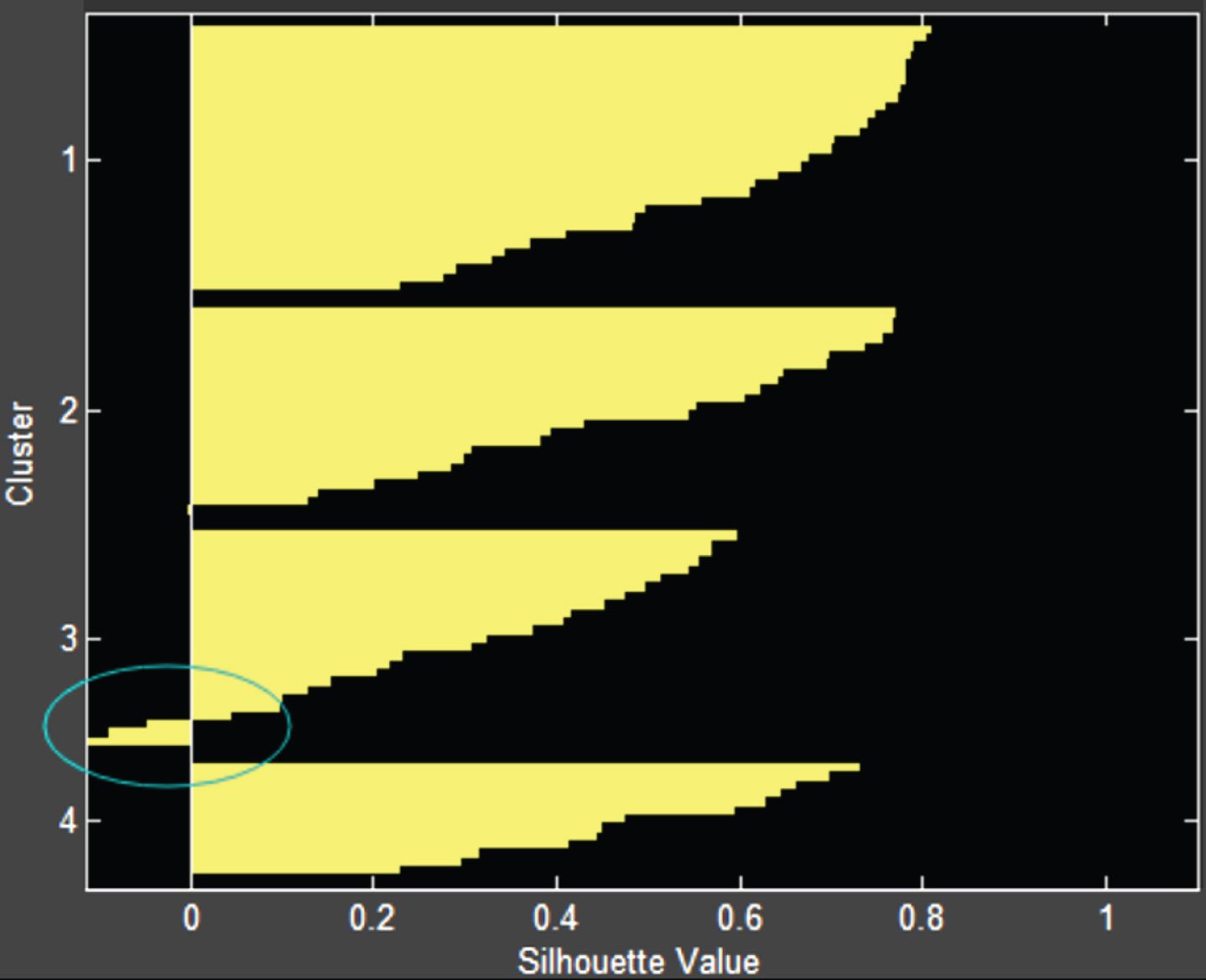
Contour coefficient of K-mediods.
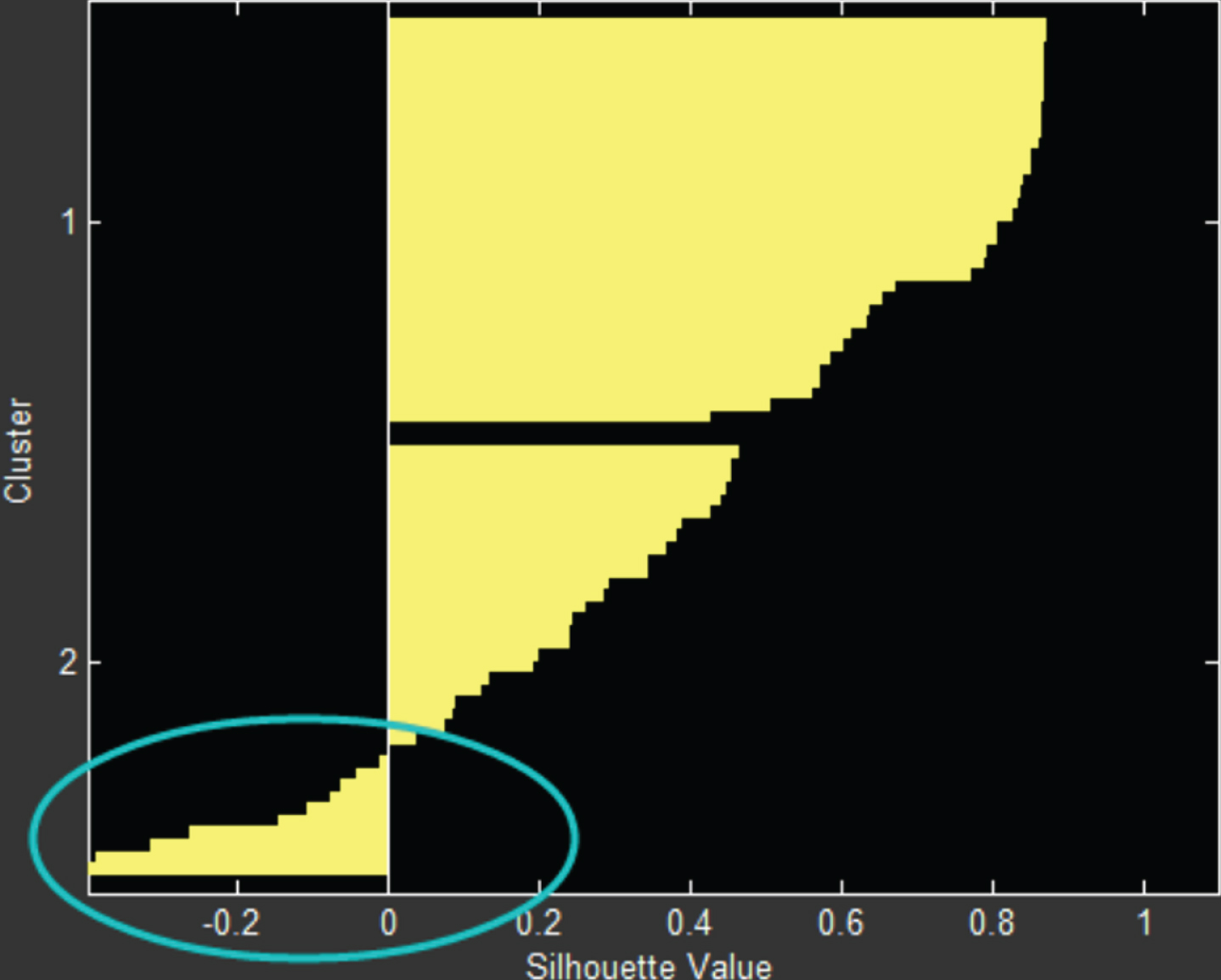
Contour coefficient of Kmeans.
As shown in Fig. 6, the contour coefficients of the MKmeans algorithm, the contour coefficients of all categories tend to be 1, and the contour coefficients do not tend to the category of – 1. It shows that all samples are classified into the optimal category, indicating that the MKmeans algorithm works well.
Figure 7 above is a contour coefficient diagram of the Kmeans algorithm. It is found from the figure that the contour coefficients of some data of a class tend to be – 1, indicating that this part of the data is not classified into the best class, that is, the performance of the Kmeans algorithm in the final subset of EPM education data is not good.
Figure 8 is a contour coefficient diagram of the improved algorithm Xmeans of the Kmeans algorithm. It is known that the contour coefficients of some of the data of one of the classes tend to be – 1, that is, the performance of the Xmeans algorithm in the final subset of EPM education data is not good.
Figure 9 is a contour coefficient diagram of the improved algorithm K-medoid of the Kmeans algorithm. It can be inferred that the contour coefficients of some of the data of one of the classes tend to be – 1, so it can be inferred that the performance of the K-medoid algorithm in the final subset of EPM education data is not good.
In order to classify learners according to the characteristics of the learner’s knowledge mastery, a group of learners with different degrees of knowledge is obtained, which provides a reference for teachers to group different levels of knowledge. The session dataset of the knowledge model does not meet the external evaluation criteria, so the internal evaluation criteria contour coefficients are used to evaluate the clustering quality.
First, Xmeans is used to determine the optimal k value, which is 2, as shown in Fig. 10. After that, the final datasets were clustered using MKmeans, Kmeans, K-mediods and Xmeans clustering algorithms, and the clustering effect was analyzed by contour coefficients as shown in Figs. 10–13. Finally, the clustering results are used to analyze the cognitive ability grouping.

Contour coefficient of Xmeans.
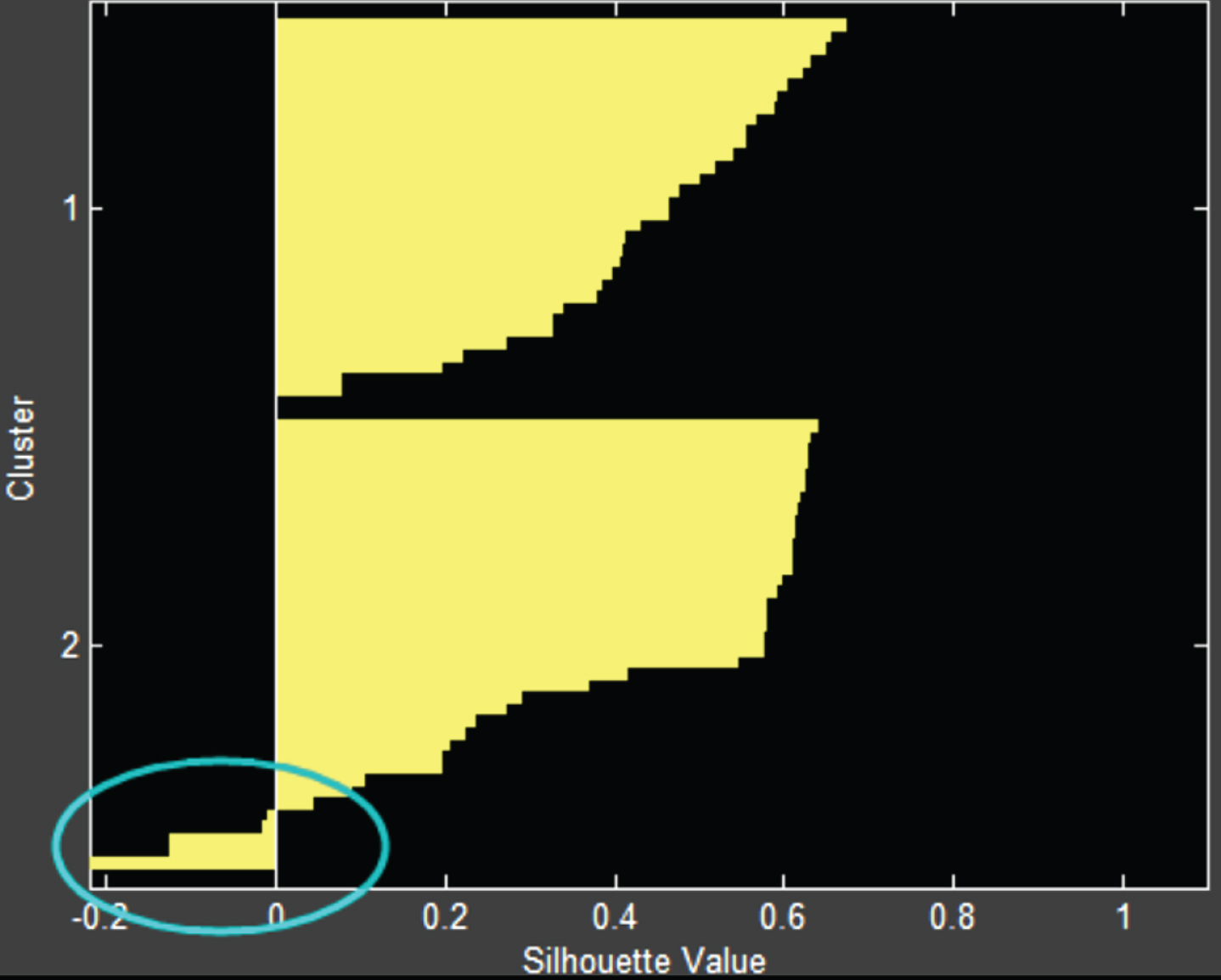
Contour coefficient of MKmeans.
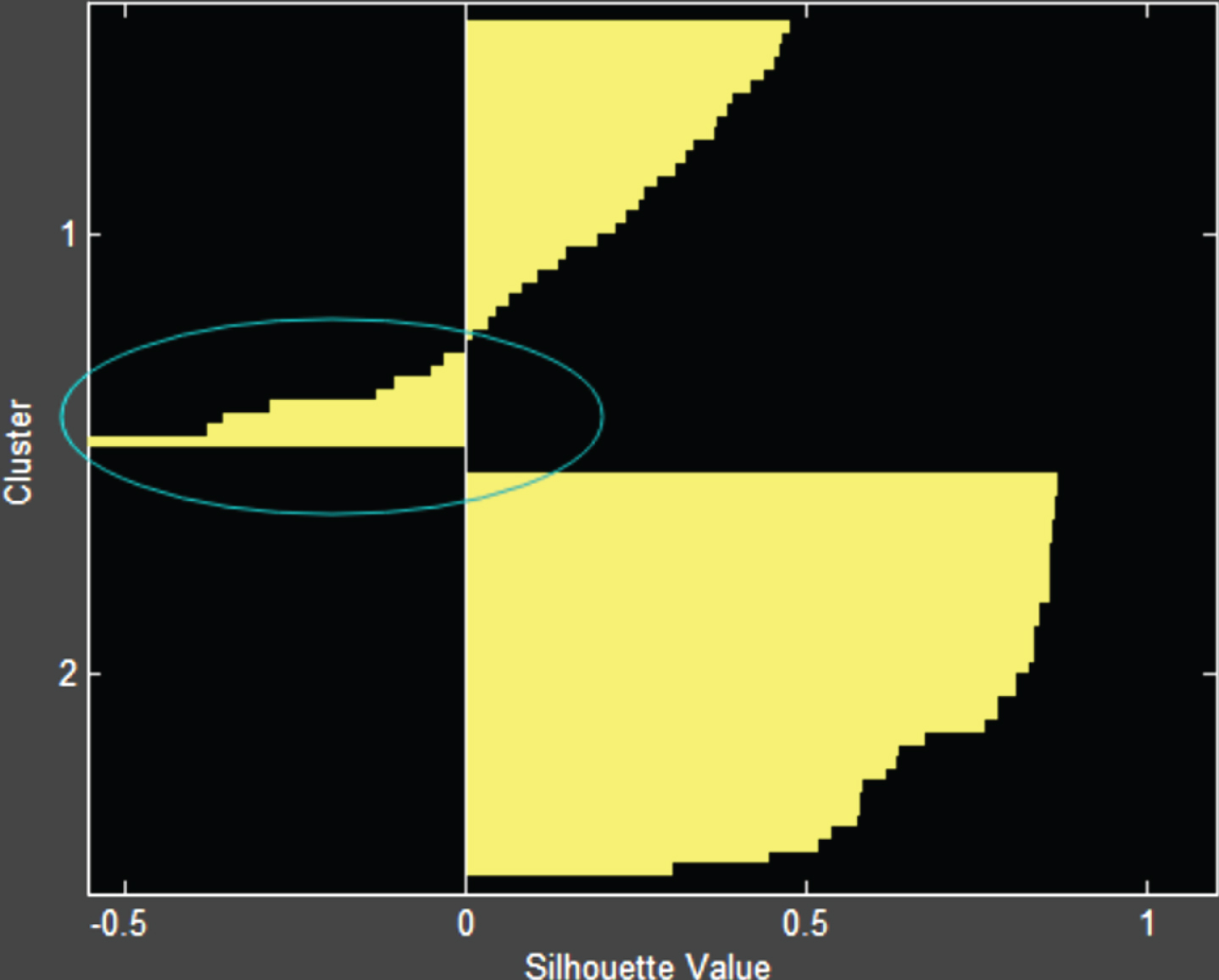
Contour coefficient of K-mediods.
Figures13 show the contour coefficients of the four algorithms, that is, Kmeans, Xmeans, MKmeans and K-mediods, respectively. It is found from the figure that all four algorithms have a phenomenon in which the contour coefficients of some data in a class tend to be – 1. It can be intuitively found from the four graphs that the part of the MKmeans algorithm whose profile coefficient tends to – 1 is less, and its tendency is lower. Therefore, it can be shown that the MKmeans algorithm is superior to the other two algorithms.
In the differential evolution algorithm, the reason for generating the mutated individual is to add a random deviation perturbation above the basis vector, that is, the individual of the mutation operation is generated by adding a random perturbation factor to the basis vector. The system designed and developed by this study can detect the student’s line of sight change in the student’s face image obtained from the camera. Through the timing, direction and displacement of the line of sight change, we can obtain the line of sight change record of the learner in a given time period in real time. Using the collected line of sight change records and the previously trained classifiers, we can classify different line of sight changes into different eye movement patterns and use this model to estimate the student’s learning state at any given time. The pre-processed final data sets were compared experimentally with MKmeans algorithm, Kmeans algorithm and Kmeans’ improved algorithm, that is, K-mediods and Xmeans algorithm respectively. EPM’s final data set does not meet the F-measure external evaluation criteria. Therefore, this paper uses the internal standard contour coefficient analysis to compare the quality of clustering results. The research results show that the algorithm has good effect and can be applied to the online education platform.
Footnotes
Acknowledgment
This work was supported by the National Social Science Fund Projects& Educational Science Planning Subject: Research on the practice of flipped classroom based on cloud platform in university teaching (No. CIA150193).