
Abstract
In order to overcome the problems of long execution time and low parallelism of existing parallel random forest algorithms, an optimization method for parallel random forest algorithm based on distance weights is proposed. The concept of distance weights is introduced to optimize the algorithm. Firstly, the training sample data are extracted from the original data set by random selection. Based on the extracted results, a single decision tree is constructed. The single decision tree is grouped together according to different grouping methods to form a random forest. The distance weights of the training sample data set are calculated, and then the weighted optimization of the random forest model is realized. The experimental results show that the execution time of the parallel random forest algorithm after optimization is 110 000 ms less than that before optimization, and the operation efficiency of the algorithm is greatly improved, which effectively solves the problems existing in the traditional random forest algorithm.
Introduction
Random forest is a relatively new machine learning model, which mainly refers to a classifier that uses multiple trees to train and predict samples. In machine learning, random forest is a classifier that contains multiple decision trees. The output category results obtained by random forest classifier are determined by the mode of the output category of individual trees. Generally, random forest classifiers need to go through many processes, such as feature selection and feature splitting, among which the selected feature is the original data input into the classifier. The splitting process is the process that the decision tree classifies the training data into two or more sub-datasets many times in the training process, in order to ensure the accuracy of random forest classifiers. In the actual work process, a forest consisting of decision trees is established in a random way. Each decision tree in a random forest is independent and has no correlation with each other. After obtaining a random forest, new samples are input into it and judged separately by each decision tree in the forest, and the classification results are obtained. Because of its fast training speed and high dimensionality, this random forest system is widely used in the field of regression and classification [1]. Many studies have shown that random forest classifier has better classification effect than single classifier. It can give the importance score of multiple variables and evaluate the role of each variable in classification. Continuing the application principle of random forest classifier, a random forest algorithm is proposed. Random forest algorithm introduces resampling basis based on the original classifier, which makes the application of random forest classification no longer limited to hardware equipment, and enlarges the application scope of the algorithm. Random forest algorithm is widely used in energy, genetic engineering, transportation, computer vision and other fields. At the same time, because of the importance of random forest algorithm to calculate attributes, it can be directly operated by computer to get the classification results of training sample data.
Since the introduction of random forest algorithm, research on the improvement of the algorithm has been constantly emerging. The main idea of the improvement and optimization is to introduce the new algorithm into the stochastic algorithm to improve the effectiveness of the algorithm [2]. Relevant scholars at home and abroad have obtained corresponding research results for this kind of research. For example, the feature selection of the algorithm is combined with the model combination and so on, to obtain the random forest hybrid algorithm. Multiple node splitting algorithms are used to form linear functions, and different splitting programs are combined in the same tree to improve the classification performance of random forests under some combination of coefficients. In addition, random forest algorithm based on semi-supervised learning, random forest algorithm based on category randomization and random forest algorithm based on adaptive classification are important research results of random forest algorithm in different neighborhoods. However, after a long period of research, it is found that the traditional random forest algorithm can not achieve the parallel classification of text samples and image samples, so the concept of distance weight is introduced to optimize the parallel random forest algorithm. Distance weight in computer field refers to the value on the path, which can be understood as the distance between nodes, and corresponds to the probability of the occurrence of binary coding [3]. By calculating the distance weights, the proportion of the corresponding decision tree nodes in the random forest can be obtained, and the distance weights can be used as parameters to get the classification results of training samples. Because distance weights are not limited by the form of training samples, it can calculate and process both text weights and image weights simultaneously. Therefore, the parallel operation of random forest algorithm can be realized while ensuring the classification effect.
Optimal design of parallel random forest algorithm based on distance weight
In order to solve the problems of the traditional random forest algorithm, the concept of distance weight is introduced to optimize the algorithm. In the process of optimization, we need to pay attention to the parallel classification. At the same time, we need to improve the classification accuracy of the random forest algorithm to the greatest extent. While ensuring the normal operation of the classification function of the random forest algorithm, it should combine text classification with image classification to improve the parallelism and operational efficiency of the random forest algorithm [4]. The optimal design flow of parallel random forest algorithm based on distance weights is shown in Fig. 1.

Flow chart of optimization design of parallel random forest algorithm.
According to the main optimization steps in the graph, the basic operation parameters of the algorithm are first determined. On this basis, k samples are randomly extracted from the original training sample set N by playback method to generate a new training sample set. In addition, the test sample set needs to be extracted in the same way [5]. Then, k decision-making classification trees are generated according to the self-help sample set, and then a random forest is formed. The classification results of the new data are determined by the score formed by the voting of the classification tree. Its essence is an improvement of the decision tree algorithm, which combines multiple decision trees. The establishment of each tree depends on a sample extracted independently, and each tree in the forest has the same distribution. The classification ability of a single tree may be very small, but after randomly generating a large number of decision trees, a test sample can select the most possible classification by statistical analysis of the classification results of each tree.
Bagging extraction method is used to randomly extract data samples from original training data set D. In original data set D, two data types are included: text data and image data. Therefore, different selection methods are adopted for different data types [6]. The basic principle of random selection of training sample data is shown in Fig. 2.
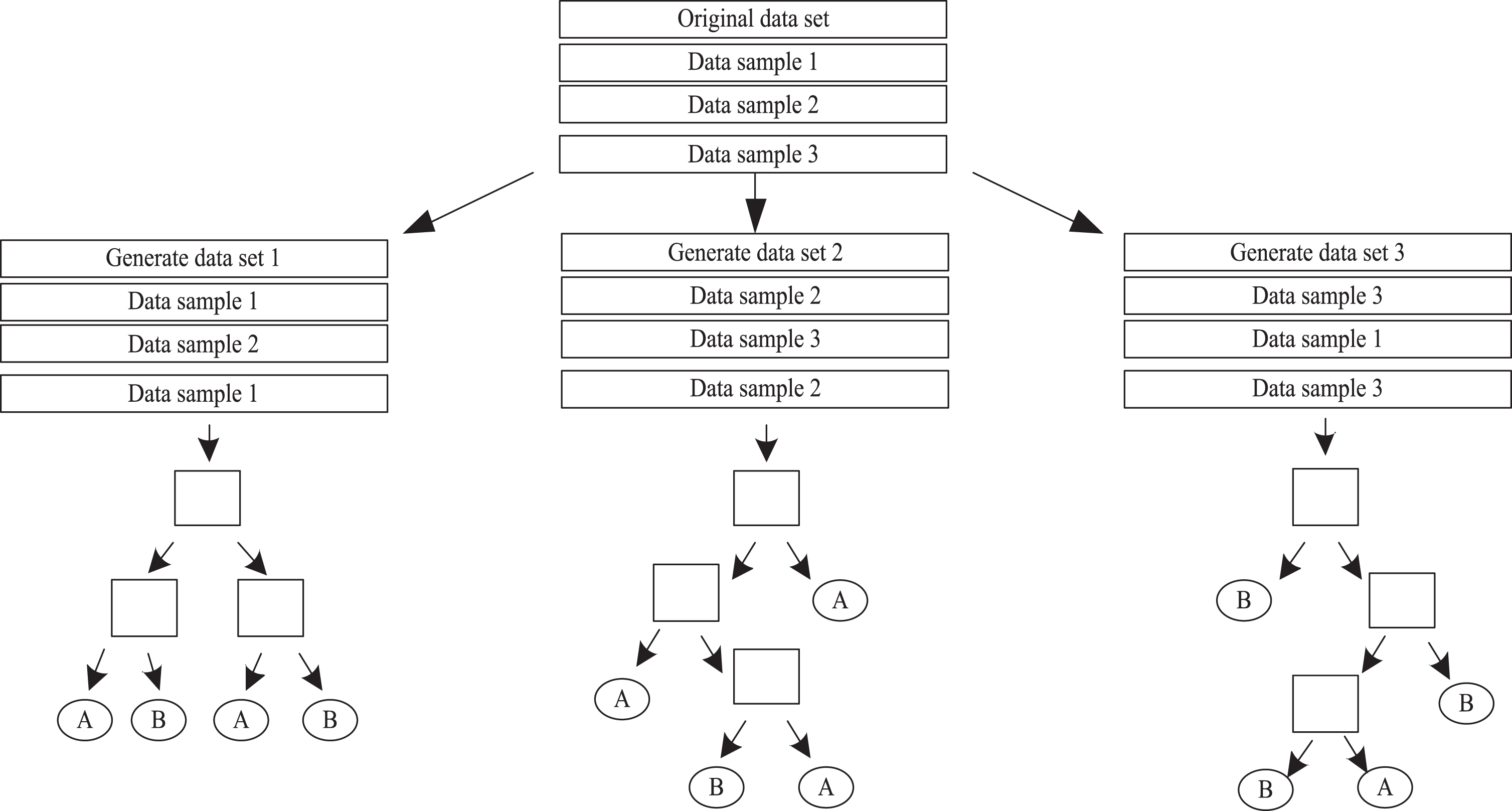
Diagram of random data selection principle.
Before the random selection of text data, we firstly need to select the extracted attributes and data parameters. Let S be the attributes system corresponding to the original data set. The system can be represented by formula 1.
Where, U represents the universe, A represents the intersection of conditional attributes and decision attributes set of text data, f is the information function of decision attributes, and V represents the range of corresponding selected attributes [7]. Then any text data to be selected in the original data set can be expressed as m ij , and the corresponding selection parameters of the text data are:
In the formula, C and D represent the set of conditional attributes and decision attributes respectively. Based on the calculation results of parameters obtained from formula 2, the selected data volume of training sample data set is determined and numbered according to different data types. The numbering results are shown in Table 1.
Types of training text data
According to the similar selection principle, the training samples of image data are obtained. Because the sampling process is replaced, the samples of the same sub-training set will appear repeatedly, and then the decision tree is constructed using the sub-training set. In addition to the basic training sample data set, the corresponding test data set needs to be established.
Parallel preprocessing of training data set
Restricted by the acquisition environment and methods, the results of random selection of training sample data will be noisy to some extent. In order to ensure the classification quality of random forest algorithm, it is necessary to pre-process the initial selection results [8]. Different preprocessing methods are used for two different data types of texts and images, taking text data as an example. The result of any selected training sample set is recorded as L, and the noise data in the sample data set is calculated by formula 3.
In formula 3, η is the average noise value in the original training set and e i ′ is the marked error rate. Then, the calculation results in formula 3 are taken as data parameters to realize the continuous denoising of data until the value of η0′ is 0.
Generally speaking, the image data in the original data set is stored in jpg format, but there are other formats of image information, and the size of the selected image information data is also different [9]. In order to ensure that the image information data can be interoperable, it is converted into the representation of pixels and input into formula 4 to achieve a unified conversion.
Where, the mean value and standard deviation of data set are represented by μ and σ respectively.
A parallel random forest model is constructed when the training sample data are selected. The construction of the model can be roughly divided into two steps. Firstly, a single decision tree is generated based on the training sample data, and then a random forest is obtained according to the set split mode. In order to optimize the random forest and realize the function of parallel classification, control parameters are set in the process of building the model to control the splitting and growth of decision tree [10]. The structure of parallel random forest is obtained as shown in Fig. 3.

Structure of parallel random forest.
The result of attribute calculation in training forgetting book is λ ij . M attributes are randomly selected from λ ij to form a stochastic feature subspace X, which can be used as the splitting attributes of the current node of a single decision tree and keep M unchanged during single decision-making and the process of random forest generation [11]. On this basis, the concurrent construction process of a single decision tree is obtained as shown in Fig. 4.

Flow chart of tree-building of parallel random forests.
According to the gain rule of a single decision tree, every non-leaf node is dichotomized, and the current items to be classified are divided into two subsets to achieve the growth of the decision tree. The specific parallel splitting process is shown in Fig. 5.

A forward splitting diagram of a single decision tree.
Assuming that a single decision tree consists of n continuous data, there must be n-1 splitting points. The expected classification information of any training sample in the random forest model is defined as:
Where, Pi is the probability that the sample belongs to type C [12]. Then, according to the calculation result of attribute λ
ij
, the data set corresponding to a single decision tree can be divided into multiple itself, and the corresponding data splitting gain can be expressed by formula 6.
If all the samples contained in the current node belong to the same category, or the number of samples covered by the current node is less than Gain (λ ij ), the forward splitting process is stopped [13].
The purpose of decision tree grouping is to effectively solve the problems existing in traditional algorithms, that is, when the number of decision trees in random forests is large, the algorithm will continue to train along with the cycle iteration, resulting in the gradual reduction of the diversity of samples in the number of decision-making, reducing the classification accuracy of sample data, leading to the fact that the training process can not continue [14]. In order to solve the above problems, a single decision tree is grouped and numbered according to the way in Fig. 6a, taking four decision trees as an example.

Results of decision tree grouping.
Figure 6a shows that each grouping result consists of three different decision trees, and there is only one different decision tree in any two grouping results. Using the result of classification, the labeled samples can be numbered and voted, and the high implicit confidence samples can be obtained. The numbered samples can be added to the new training sample set to realize an iteration process of random forest algorithm [15]. The correlation between the new decision tree formed by one time of iteration and other decision trees is calculated. If the results show that the difference between the new decision tree and other decision trees is small, the decision tree needs to be removed to ensure the diversity and difference of the results of the decision tree grouping. Let v
i
and v
j
respectively represent the attribute values of the newly generated decision tree corresponding to the original training sample. The concrete expressions of the two are as follows:
In the formula, a
k
denotes the parameters of attribute values corresponding to continuous attributes in adjacent boundaries, TF is the proportion of attribute values in corresponding attribute columns, and its calculation formula is as follows:
In formula 8, iP,T denotes the number of occurrences of attribute values in the column of attribute T, while ∑
L
iL,T denotes the total number of occurrences of attribute values [16]. In addition, variable IDF corresponds to the inverse attribute frequency of an attribute value, whose specific value can be calculated by formula 9.
Formula 9 shows that D is the total number of attributes in the training sample data set corresponding to the decision tree, and {T : p
m
∈ D
n
} represents the number of attributes in the decision tree that contain the attribute value p
m
. By substituting the calculation results of formula 8 and formula 9 into formula 7, the specific values of v
i
and v
j
can be obtained, and then the similarity between attribute i and attribute j can be calculated by formula 10.
The correlation between two decision trees can be judged by solving formula 10. The greater the result of r calculation is, the higher the similarity between decision trees is [17]. Setting the similarity threshold between decision trees is 0.75, if r is greater than the set threshold, it needs to remove the corresponding similar decision tree, otherwise it does not need to remove it and enter the next iteration cycle.
A random forest is formed by combining the single decision tree constructed according to different grouping methods and arranging it according to the form in Fig. 7.
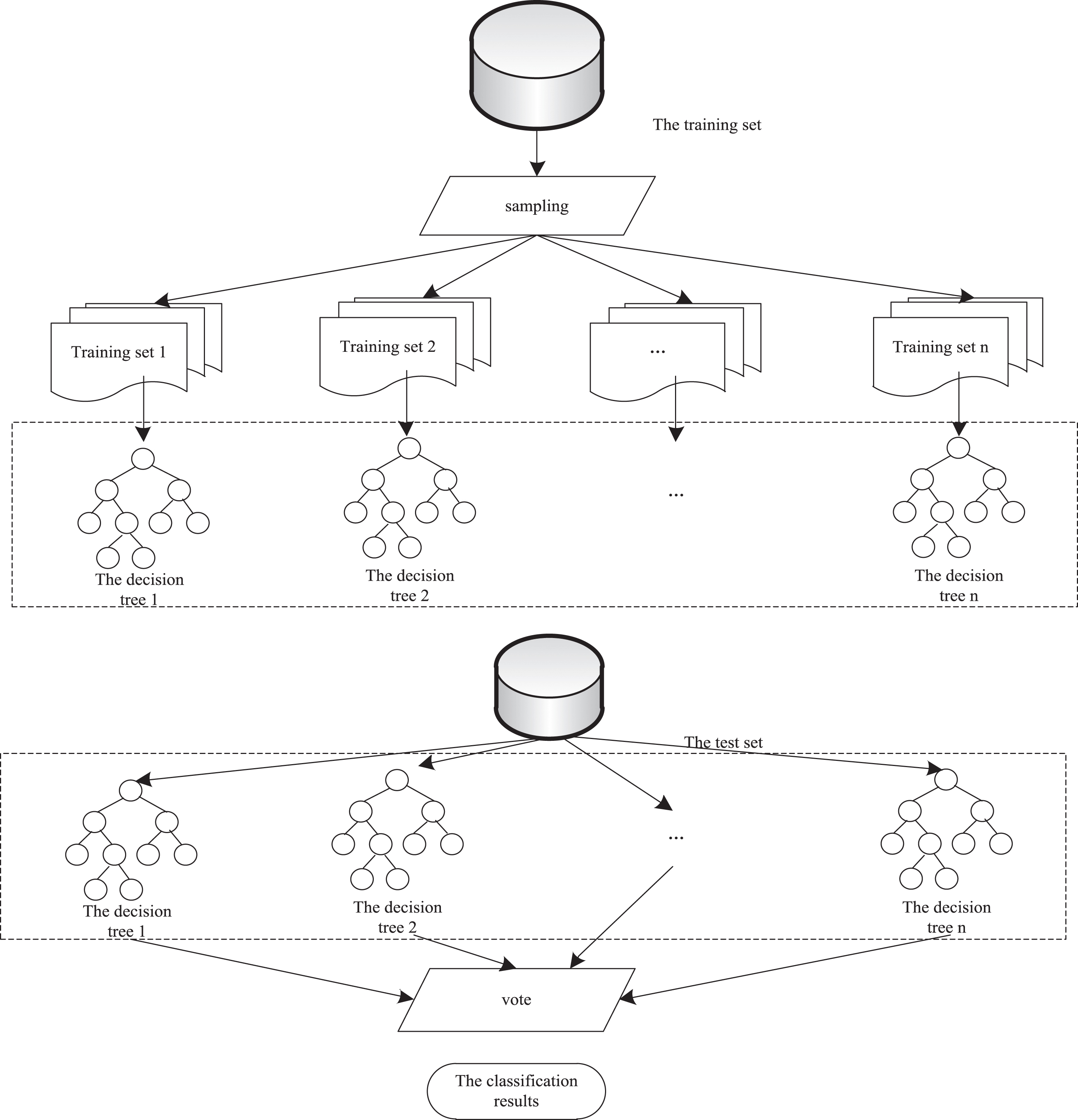
Schematic diagram of random forest formation results.
According to the grouping and classification results of N decision trees, the classification results with the most votes are selected by casting, that is, the final classification output of the algorithm [18].
Based on the established random forest model, the distance weights between decision trees and the weight of leaf nodes in a single decision tree are calculated respectively, and the weighted optimization of the random forest model is realized on the basis of the calculation results. The distance weights of image data and text data are defined respectively as w p and w t . The calculation of w p is mainly based on the gray level and chroma of the image, while w t is composed of Boolean weight and word frequency weight. The specific parallel computing flow of distance weights is shown in Fig. 8.

Parallel computing design of distance weight.
According to the design results in the graph, the text distance weights and image distance weights are calculated in parallel, and the formula for calculating image distance weights is as follows:
On this basis, the weighted optimization of the initial random forest algorithm is realized through the following steps. Firstly, the basic parameters of the original algorithm are determined, and the initial values of the number of predicted samples N and the number of random attributes m are randomly set up. In the established random forest model, the distance weights are calculated by formula 11. The optimization steps of weighted random forest are expressed by formula 12.
The values of i are p and t respectively, and the corresponding distance weight calculation results are substituted into formula 12 to calculate the corresponding results of the model [20]. Finally, all decision trees in random forests are iterated as fitness values, and the parameters of the model are determined, and then the weighted optimization of the original random forest model is realized.
The optimization results of parallel random forest algorithm based on distance weights are input into the computer in the form of program code. Parallel random forest optimization algorithm is realized through four steps: parallel initialization of random forest, parallel simulation and calculation of label error rate, parallel selection of high confidence samples from unlabeled training sample set and parallel updating of decision tree. At the same time, the parallel classification results of text data and image data are obtained. The output interface of the results is shown in Fig. 9.

Classification results interface of random forest algorithm.
In order to detect and optimize the performance analysis experiment of parallel random forest algorithm design based on distance weights, the corresponding experimental environment is built as a common room environment, and an open source platform is installed in the experimental computer. The experimental computer is equipped with 2.40 GHz Intel dual-core CPU with 8 G memory. The installed open source platform operating system is Fedoral 14 Linux 64-bit, and the JDK is jdk1.6-u21-x64. Comparing the execution time of the optimized algorithm with that of the pre-optimized algorithm, we can judge whether the optimization result is effective according to the execution time of the optimized algorithm. The program code corresponding to parallel random forest algorithm is input into the experimental computer, and the execution interface is shown in Fig. 10.

Schematic diagram of random forest algorithm code.
In the input program code of random forest algorithm, random forest () is the processing code of the training set thus generating the decision tree. species is the name of the column in the prediction data set. iris [ind==1] represents the training set for generating the decision tree. ntree is the number of decision trees generated, and nperm is the number of repetitions when calculating importance. Then the experimental data to be classified is prepared. The data of the original experimental data set comes from UCI database, and the results of extraction are shown in Table 2.
Experimental data sets
In order to analyze the classification performance of random forest algorithm before and after optimization, the comparison index is set as execution time, and the classification results obtained before and after optimization are input into the analysis software to get the change of execution time, as shown in Fig. 11.
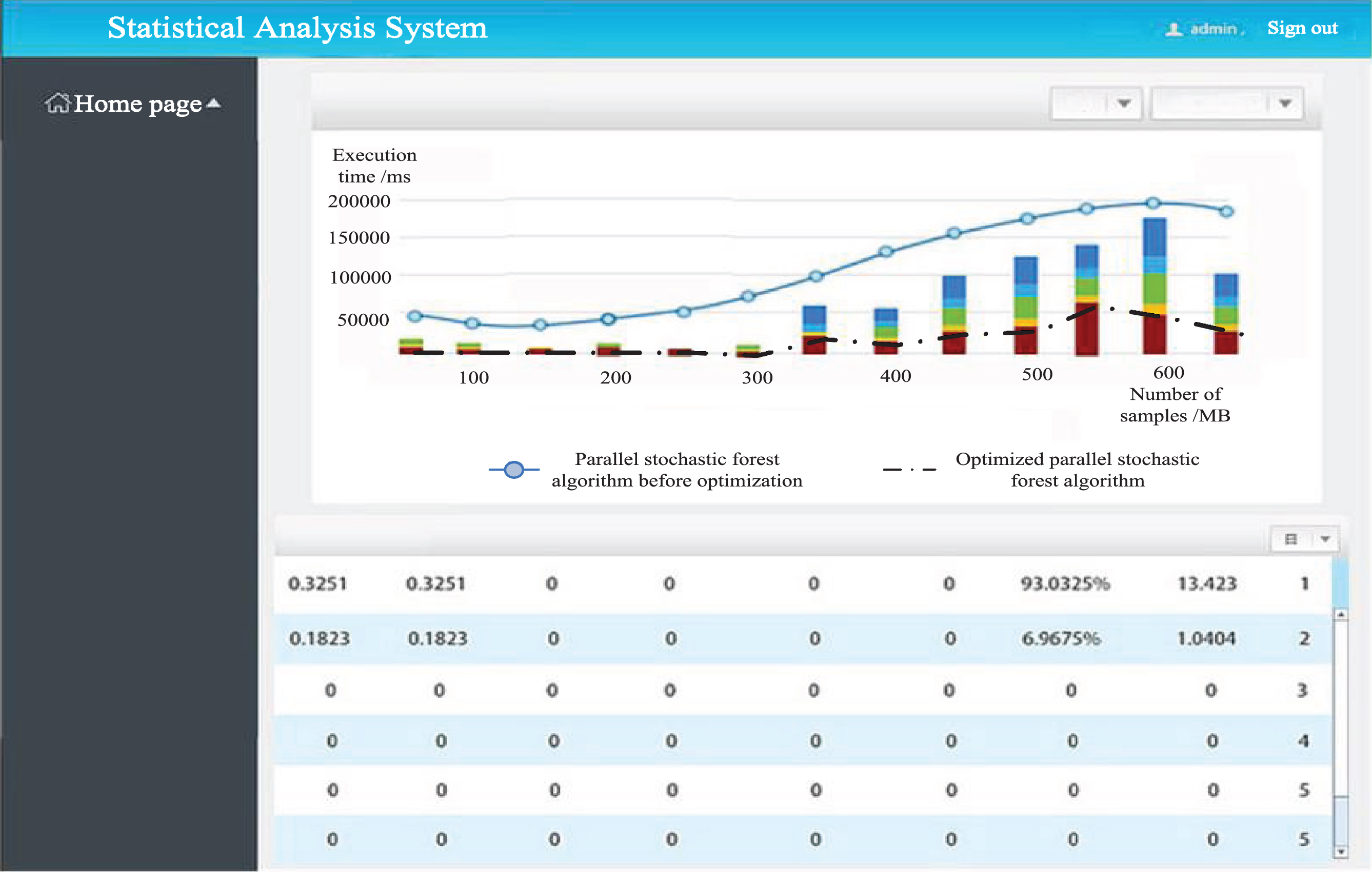
Comparison of experimental results.
The curve in the figure is the change curve of execution time obtained by the third-party analysis software. It can be seen from the figure that the execution time of the optimized random forest algorithm will increase with the increase of sample number. By calculating, the average execution time of the optimized random forest algorithm is 13000 ms, while the average execution time of the optimized random forest algorithm is 20 000 ms. Because the optimized random forest algorithm can be realized and implemented, the row classification operation saves 110 000 ms of execution time.
Considering the classification performance of single decision tree and the correlation between decision trees in random forest algorithm, the traditional random forest algorithm is optimized with the goal of speeding up the execution speed. The following conclusions are proved theoretically and experimentally. Compared with the random forest algorithm before optimization, the random forest algorithm based on distance weight optimization has higher execution efficiency, and the execution time is shortened by 110 000 ms compared with that before optimization. Through the optimization and implementation of the algorithm, the problems existing in the traditional algorithm are solved by parallel way. The results show that the random forest algorithm based on distance weight optimization has fast execution speed, can better meet the requirements of operation, and has high practicability.
Footnotes
Acknowledgments
This work was supported by National Natural Science Foundation of China under grant No. 71503277.