
Abstract
In the process of globalization, machine translation has undergone a long period of evolution and development. Although the development level of machine translation has been greatly improved, the quality of machine translation is still not very high, and it is difficult to meet the needs of users. Artificial intelligence is the science that studies the laws of human intelligent activity. The application of artificial intelligence technology in the English depression and depression, combined with the Internet and intelligent knowledge base, can develop English translation systems to solve the problem of English translation to a certain extent. Based on the above background, the research content of this article is a neural network-based artificial intelligence technology English translation system based on the intelligent knowledge base. This article is mainly based on the existing English-Chinese machine translation to find a more favorable method for English long sentence translation. By improving part-of-speech tagging and rules, the rules can match more sentence patterns to improve the quality of existing machine translations. This paper proposes an improved hybrid recommendation algorithm, and through experimental simulation, the results show that the accuracy of the algorithm is not very high. The highest is 35.64%. The possible reason may be that the k value is selected during k-means text clustering, or the N value recommended by TopN is not selected properly, but the hybrid recommendation is still better than ordinary collaborative filtering.
Keywords
Introduction
Robots are one of the most popular research directions, and involve the cutting-edge results of mechanical engineering, computing methods, artificial intelligence technology, computer technology, and other disciplines. With economic development and technological progress, the use of robots is not limited to mechanical processing plants. The scope of its use has been extended to the fields of medical diagnosis, military detection, aviation and navigation, and home services. The relationship between robots and humans is getting closer and closer.
As the Internet technology slowly developed, the exchanges between countries became closer and closer [1, 2]. And because of the different languages used in various countries in the world, a translation process is needed for the language, so the requirements for language translation are getting higher and higher [3, 4]. Therefore, the requirements for language translation are getting higher and higher [5]. In the modern information age, computers have been rapidly popularized, and they have played an increasingly important role in people’s daily lives [6, 7]. Similarly, we also hope to use a more convenient and fast way to communicate with computers, so machine translation came into being [8, 9]. Early machine translation systems were systems that used computers to translate one natural language into another, and were the focus and difficulty of natural language processing research [10, 11]. Shin describes DeepDive, a system that combines database and machine learning ideas to help develop KBC systems, and proposes techniques to make KBC processes more efficient. Shin observed that the KBC process is iterative, and Shin developed techniques to incrementally generate the inference results of the KBC system. Shin proposed two incremental reasoning methods based on sampling and variational techniques. Shin also studied the eclectic space of these methods and developed a simple rule-based optimizer. DeepDive includes all these contributions. We evaluated DeepDive on five KBC systems, and the results show that it can increase the speed of KBC inference tasks by two orders of magnitude, with a negligible impact on quality [12, 13]. Shang has established a logging data processing and interpretation knowledge base, which can be automatically updated according to relevant rules. Based on this, Shang has also established a related subsystem to initially implement the entire process of processing and interpretation of logging data in complex reservoirs, that is, From knowledge acquisition to intelligent optimization of parameters and models. The integrated software platform (CIFLog), which is the ultimate science and technology major project, is integrated and run on Natio. The processing and algorithm have proved to be scientific and effective [14, 15]. To solve the problems of excessive energy consumption and serious water quality in the wastewater treatment process, Qiao proposed a knowledge-based intelligent optimization control method for the wastewater treatment process. By memorizing the dynamic processing information of the multi-objective intelligent optimization algorithm, a knowledge model of the environment variable parameters and the optimal solution is established. The optimization algorithm is guided by the non-dominated solutions in the knowledge base, Combining local-oriented search and random global search strategies to improve the convergence of the algorithm and obtain higher quality solutions. Finally, experimental verification was performed on the international universal simulation platform BSM1. The results show that this method can reduce energy consumption under the premise of ensuring the quality of the effluent water [16, 17]. Yixing proposed a method for intelligently pushing numerical control design knowledge based on latent semantic analysis. A semantic matrix with descriptors and design knowledge with non-linear weight coefficients was established. The singular value decomposition was used to map the semantic matrix to a low-dimensional space. The requirements of design knowledge are extracted from the process model, and its fitness is evaluated. According to the personal interests of the designers, the filter rules for design knowledge are established, the push solutions for design knowledge are filtered, and the practical application of the method is illustrated by an example. [18, 19]. Compared with human translation, the accuracy and readability of machine translation is not very high, but machine translation has achieved good results in terms of scalability and practicability. In recent years, scientists at home and abroad have been committed to the research of machine translation.
This article uses the technical background of artificial intelligence to provide an artificial English translation system with good interactivity, friendly interface, strong personalization, universal, easy maintenance and expansion, and resource sharing. NET three-tier structure system, based on B/S mode, has good reliability and maintenance scalability. The innovation of this paper is mainly reflected in the research of artificial intelligence and the combination of English teaching, which makes some functions of the English translation system more perfect and humane.
Intelligent knowledge base and artificial intelligence technology English translation system
Intelligent knowledge base
An intelligent recommendation system is the main method to solve the problem of information redundancy [20, 21]. Based on the open-source search engine, this paper designs a shared knowledge base recommendation system based on the Spark platform. The related technologies involved are Spark, full-text search technology, and related technologies of recommendation systems [22, 23]. To meet the storage needs of large-scale data and achieve fast and efficient data access, HDFS came into being. It mainly divides files into discrete storage for easy management [24, 25]. Users will obtain data through the client, and the data nodes will respond to the user’s requests for addition, deletion, and modification, while the named nodes will maintain the HDFS settlement information, which is stored on disk. HDFS has designed two mechanisms for users to meet their needs for performance and fault tolerance. One is through redundant storage of data, which simultaneously writes data to local and remote storage systems, and the other is through redundant named nodes. The named nodes collaborate through shared logs, and switch when the active node fails [26, 27].
Full-text search is a kind of information retrieval technology, which has good versatility and practicability [28, 29]. It is mainly a retrieval technology based on the content information retrieval of literature data, not an external feature, and a query method based on text content [30]. At present, search engines have become an indispensable tool in people’s lives. According to statistics, Google has to respond to at least 3 billion user requests every day. Lucene/Solr uses a reverse index, which is a single mapping from keywords to documents. The index created in this way is called Inverted Index.
TF-IDF is a commonly used weighting technique for information retrieval and data mining. TF stands for Term Frequency and IDF stands for reverse file frequency. It is a statistical method to evaluate the importance of a word to a document in a file set or a corpus.
Among them,
Among them, n ij represents the frequency of the word t i in the text d j , Σ k n kj represents the total number of words of the document d j , |D| represents the total number of documents in the corpus, and |j : t i ∈ d j | represents the number of documents containing the word t i . TF-IDF is often used as a weighting factor for search information retrieval, text mining, and user modeling. Full-text search engines often use variants of the TF-IDF weighting scheme as a central tool for scoring, evaluating, and ranking the relevance of documents when users query. TF-IDF can be successfully used for stopword filtering in various subject areas, including text summarization and classification.
Unlike Item Based-CF algorithm, it determines whether items are similar or not does not depend on the user’s interest set. The content-based recommendation algorithm analyzes the content information of the items that the user has browsed to generate the user’s interest set, and uses the basic information of the item to find similar items to the user. Content-Based originates from the field of information retrieval, and the technology of obtaining text content is very mature. But because the content acquisition of audio and video has always been a difficult point, the Content-Based algorithm has not been widely used. But with the continuous breakthrough of image processing, speech recognition and other technologies, the Content-Based algorithm should dominate the recommendation field in the future. The text content analysis model in this paper is a Content-Based recommendation algorithm.
At present, search engines have become an indispensable tool in people’s lives. According to statistics, Google responds to at least 3 billion user requests every day. Lucene/Solr uses a reverse index, which is a single mapping from keywords to documents. An index created in this way is called an inverted index. As shown in Fig. 1.

Inverted index table.
In the figure, on the left is a sequence of strings, called a dictionary. On the right is a linked list of the document IDs containing the keyword, called the PostingList. Now when you want to query Spark, you can directly get the document ID containing the keyword Spark by searching the linked list as 2/3/11/23/94. Of course, if you want to query the literature that contains both Spark and Lucene, you only need to intersect the two linked lists. At present, the data structure of the inverted index is widely used, often used to deal with the retrieval of massive data, and it is now relatively mature.
The ignition pulse time of the presynaptic neuron can trigger an activation function. In the Spiking neural network, this activation function is derived from the observation of biological brain neurons. Therefore, the Spiking neuron model looks for activation functions that conform to the shape of the activation voltage in biological neurons. In this section, the calculation of the SRM0 model is performed using the following formula:
Among them,
Among them, u (t) is the voltage value of the post-synaptic neuron at time t, η (t–tˆ0) is the refractory period function, wj is the synaptic weight corresponding to the j-th pulse, and
According to the assumption, τ1 = 2τ 2, then according to the nature of the exponential function,
Then:
Similarly, when:
Have:
The development of human thinking requires the support of data. We do need to collect data. According to the needs of the plan, we collect data on a highly selected basis. Among other factors, what facts should we pay attention to, which facts should we ignore and which facts are value, which facts are worthless, and most importantly, thinking is to form a plan and reflect on the value contained in the plan. In a machine made by humans, the concept of thinking and the work of the human brain are melted internally. The thought is melted in the machine because humans naturally put our way of thinking into the machine during the development process, without any tools like Computers have brought such a profound influence, and even if they think of it as a kind of imitation, they can easily be transformed into a method of developing character and values. If we authorize someone to let him teach us how to think, we may also authorize him to teach us what to think, when to start and when to stop thinking. What we do is teach the church to analyze human thinking and analyze it. Structure, strength and proper use.
(1) C/S architecture
Among them, C stands for Client and S stands for Server, so the C/S architecture is the client-server architecture, as shown in Fig. 2.
C/S architecture diagram.
It fully schedules the performance of clients and servers, allocates scheduling resources reasonably, and reduces system overhead costs. The responsibilities of the client and the server are assigned. The client is generally used to deal with the specific needs of the user. The user issues his instructions by accessing the client. The client communicates the user’s instructions to the server through the network. Instructions, storage management distribution data, maintenance platforms, etc. After the server executes the instructions, the obtained data is returned to the client through the network, and the user obtains the required data through the client to complete the round of requests.
The C/S architecture has the following advantages: The high utilization rate C/S architecture can perform some functions when the network is offline, and does not depend entirely on the network. It makes full use of resources and can be sent to the server after the local client completes some operations, which greatly reduces the pressure on the server and optimizes the running speed. The client with strong security has a specific user and is implemented between the server and the server. The face-to-face connection makes the security of information transmission stronger, and it is not easy to lose data.
(2) Multi-Threading Technology
Thread is the main part of the process. Thread is responsible for the execution of a small piece of program in the process. A process needs multiple threads to support it together, and the threads do not interfere with each other. The multi-threading technology is an implementation of concurrency, which allows users to feel that multiple tasks are executing at the same time through the CPU’s scheduling calculation. This is not simultaneous. The CPU’s operation switching speed is very fast. Several tasks switch back and forth quickly and differently, so that users do not feel the delay at all. When a thread finishes executing and sleeps, other threads can continue to execute and use resources in the process. Therefore, the multi-threading technology makes full use of system resources, which greatly enhances work efficiency. Thread roughly includes the following five states: New state (New): After a thread object is created in the process, the thread is in the new state. Ready state (Runnable): After the thread is created, the thread is in an executable state, and the CPU will call the thread at any time. Running state: When the thread is called by the system CPU, it enters the running state. But when the thread in the running state is called the yield () method, it will fall back to the ready state. Blocked: There are three blocking situations: waiting for blocking, synchronous blocking, and other blocking. The blocking state is that the thread does not continue to consume the CPU at this stage, and the execution is stalled. It is not possible to regain CPU resources until the thread returns to the executable state again. Dead: The thread’s life cycle has ended due to various reasons.
(3) HTTPS Protocol
Secure Hypertext Transfer Protocol (HTTPS) is HTTP wrapped by SSL. It transmits via the HTTP protocol, and the transmission method of the HTTP protocol is too open, and its transmission is easy to be cracked. Therefore, putting the SSL coat on the HTTP protocol fundamentally solves the problem of insecure transmission. Compared with the HTTP protocol, the HTTPS protocol with the SSL jacket has the following characteristics: Content encryption: Multi-encryption is used to prevent the middleman from directly viewing the transmission content and third parties cannot eavesdrop. Identity verification: When the client and server are transmitting, they will interfere with the certificate to prevent the identity from being impersonated, thereby ensuring the security of the transmission. 3) Protect data integrity: HTTPS protocol can effectively prevent the transmission of content from being lost or tampered with by middlemen. It has a check mechanism, and once the transmission content is tampered, both sides of the communication will immediately find out.
Experimental environment
The English translation system uses two computers in the development process, which are used as the client and server respectively, and its hardware environment is shown in Fig. 3. This system is developed based on Java language. The software development is also divided into two parts: client and server. The software environment is shown in Fig. 4.

System development hardware environment diagram.

System development software environment diagram.
This system adopts B/S three-tier architecture. The B/S structure, namely Browser/Server (browser/server) structure, is a structure that improved and developed the C/S structure with the rise of Internet technology in the 1990 s. The C/S structure generally uses a two-tier structure. The front end is the client, that is, the user interface (Client), which accepts user requests and requests to the data service. The back end is the server, which accepts client requests to calculate data and submit the results. Back to the client, each client of this structure needs to install the corresponding client program, which has weak distribution functions and poor compatibility, so it lacks generality and has greater limitations. The B/S structure came into being. The B/S structure only installs and maintains a server, and the client uses a browser to run the software. In the B/ S three-tier architecture, almost all business processing is completed on the Web server. The client only needs to be installed. W browser can be used, without any other installation and configuration work, truly achieve “client-side zero maintenance”. Users can directly access WebServer through Web browser for business processing.
The knowledge base includes two aspects: firstly, submitting and controlling knowledge, and secondly, storing knowledge according to the expert model, making the knowledge base easy to maintain. In the English teaching assistant expert system, the knowledge base stores two kinds of knowledge: a static knowledge base and dynamic knowledge base. The static knowledge base refers to the fixed morphology and grammar in English learning. After careful communication and summary by domain experts and knowledge engineers, it is stored in layers in the static knowledge base. For example, there are two major knowledge modules in English, namely vocabulary and grammar. Vocabulary is divided into verbs, nouns, pronouns, adjectives, adverbs, etc. Grammar is divided into tense, subject-predicate agreement, sentence pattern, subjunctive mood, independent components, etc. Dynamic knowledge base refers to the rules entered by domain experts, which can be added, modified, and deleted. The system has the characteristics of causality, logic, process, and structure. Therefore, the system adopts a rule-frame-based hybrid knowledge expression method. This can make full use of the advantages of these two types of knowledge expression, learn from each other, and enhance the ability of knowledge expression. Improve inference efficiency. The knowledge acquisition process of the English expert system is the process of acquiring knowledge in the English field. Knowledge is performed in the order of description, observation, and acquisition: Description: Knowledge engineers interact with English experts. Propose a structured description of English knowledge in this system; observation; knowledge engineers without obstructing the work of English experts, observe the domain experts in the actual problem-solving environment, and understand the methods and steps of English experts to solve practical problems: Get: In the mutual communication between knowledge engineers and English experts, some key problem-solving form evaluations can be obtained, which enables knowledge engineers to conduct interactive searches for the required English knowledge. The English knowledge acquisition of this system is passive. After the knowledge structured processing of knowledge engineers and English experts is completed, a knowledge acquisition module needs to be established to acquire knowledge.
Function and performance test
After the English writing translation training system is developed, the function of the system must first be tested. The main functional test examples are shown in Table 1.
English translation system test case list
English translation system test case list
In the process of experimenting with the performance of the English writing translation training system, the performance of the system is measured by using the read and write throughput, the number of system responses per second (QPS value), and the memory consumption rate. The basic process of this experiment is to send requests from the client to the server indefinitely. If the server responds successfully, it continues to add requests to the server. The control group of this experiment is the traditional Socket system. Throughput refers to the amount of data the system manipulates in a unit of time. Therefore, the read and write throughput refers to the amount of read and write operations performed by the system in a unit of time. Generally speaking, the read and write throughput of the system reflects the quality of the system’s concurrent performance. In this experiment, the total number of bytes of the server’s response to the request from the client divided by the total time of the response is used as a measure of throughput, and the unit of time in seconds. The experimental test results are shown in Fig. 5.
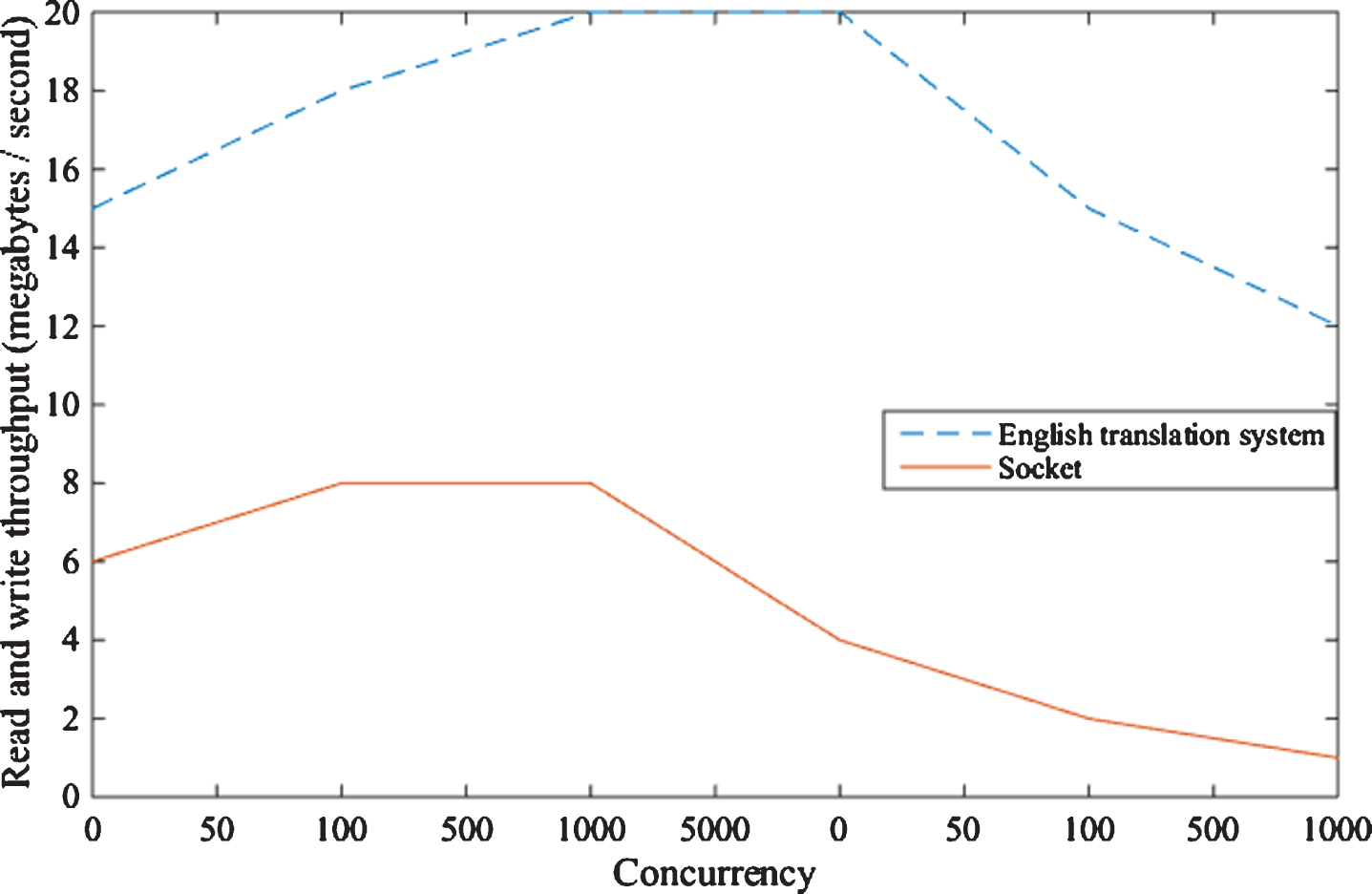
Comparison of throughput experiments between this system and traditional Socket system.
As can be seen from the figure, the throughput of the traditional Socket system is about 7MiB/s when the concurrency is about 100 times, and the throughput of this system is higher than the highest throughput of the traditional Socket system when the concurrency is about 10,000 times. The throughput of this system can be up to 20MiB/s. It can be known from the throughput experiments that the performance of the system in the throughput performance test is better than that of the Socket system in the control group.
The system’s QPS value is also one of the criteria that reflect the concurrency performance of the system. In this experiment, the total number of requests processed by the system in a period divided by the size of this period, the unit of time in seconds. The experimental results are shown in Table 2.
QPS performance test comparison between this system and the traditional Socket system
QPS performance test comparison between this system and the traditional Socket system
The QPS value of this system is 125, and the QPS value of the Socket system is 25. This system is 5 times the QPS value of the control experimental group. This system is far superior to the Socket system of the control experimental group in performance testing. With the concurrency as the independent variable and the memory consumption as the dependent variable, the two experimental groups are compared. The test results are shown in Fig. 6.

Experimental comparison of memory consumption rate between this system and traditional Socket system.
According to the test results, in general, when the arguments are the same, the memory consumption of this system is smaller than the traditional Socket system. When the number of concurrency is small, the contrast between the two experimental groups is not very large. With the increase in the number of independent variables, the gap between the two experimental groups has gradually become apparent. With the increase of the number of concurrent socket systems, the memory consumption of traditional socket systems has increased rapidly, while the memory consumption of this system has been slowly increasing. Therefore, in the comparison experiment of memory consumption, the performance of this system is much better than the traditional Socket system.
To help analyze the rationality and effectiveness of the comprehensive method, this article provides the correct Chinese translation. And this paper uses the BLEU value machine translation quality evaluation method. BLEU was proposed by IBM in 2001. The main idea is that the similarity between professional human translation and machine translation is the better. This method uses the number of consecutive words in the Chinese translation as a starting point to analyze the similarity and distance between the measured translation and the standard translation. Among them, the quality of the translation of unsegmented sentences and sentences segmented by regular expressions is compared, as shown in Table 3:
Comparison of undivided translation and divided translation
Comparison of undivided translation and divided translation
As can be seen from Table 3, the BLEU value of the sentence without segmentation is much smaller than the BLEU value of the translated segmentation by regular expression. After applying the improved regular matching method, the BLEU value of the translation is about 4.3% higher than the BLEU value of the directly translated source sentence. However, some rules in the regular matching method still have certain problems, which affect the quality of the translation, so this method needs to be improved. The long sentence segmentation experiment results are shown in Fig. 7.
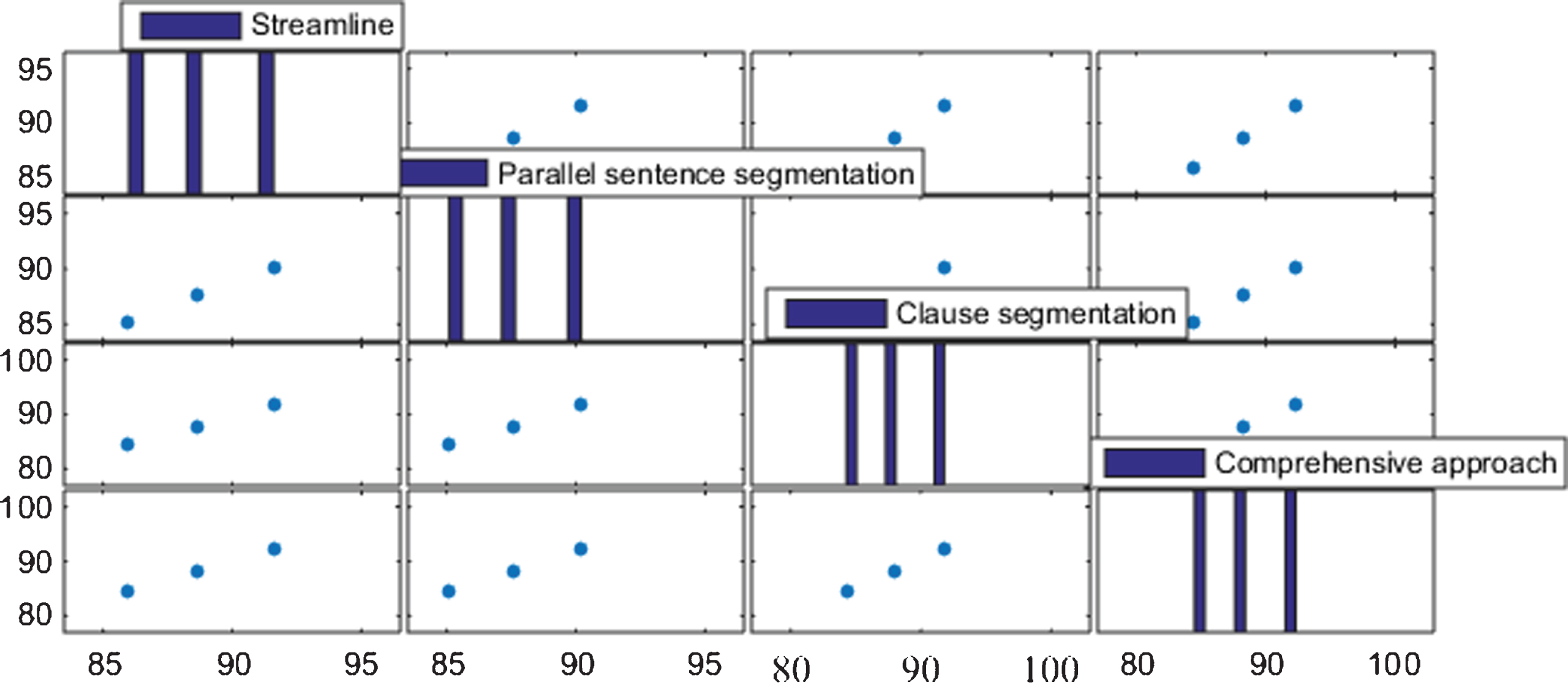
Experimental results of long sentence segmentation.
It can be seen from the values in Fig. 7 that the recall rate at each step has achieved good results, and the application of the comprehensive method has improved the accuracy of sentence segmentation. However, the accuracy of the comprehensive method is not very high. So the method needs to be further improved.
The hybrid recommendation algorithm proposed in this paper is compared with User Based-CF and Item Based-CF algorithms. The comparison of processing performance is shown in Fig. 8.

Algorithm execution time comparison.
Experimental results show that the overall speed of the proposed hybrid recommendation algorithm is faster than the UserBased-CF and ItemBased-CF algorithms. And with the increase in the number of users, the execution speed is also much faster than the other two. Reflects the advantages of hybrid recommendation, which can complement each other. Under different proportions of the test set, the results were averaged after 3 executions. It can be seen that the hybrid recommendation algorithm proposed in this paper has higher accuracy than the other two, almost 5% higher in any proportion. With the reduction of the training set, the Precision of the three is not optimistic. The reason may be that the data becomes sparse and the model is not trained enough, but the hybrid recommendation is still better than ordinary collaborative filtering. The improved hybrid recommendation algorithm proposed in this paper is superior to the CF algorithm in all indicators. But the accuracy of this algorithm is not very high. The highest is 35.64%. The possible reason may be the selection of k value in k-means text clustering, or the improper selection of N value recommended by TopN.
The English translation system designed in this paper uses a combination of production and frame-based knowledge expression methods, uses uncertainty reasoning technology, and artificial neural network design. Based on the characteristics of English, it studies the implicit knowledge base, knowledge expression, and knowledge-based on neural networks. The acquisition and training of samples using the BP network produced ideal neural network parameters and constituted a learning English translation system.
Research on parallelization of recommendation algorithm based on spark. This paper studies a hybrid recommendation system based on text content analysis and user behavior labels. Besides, to solve the problem of mass user data processing, Spark, a memory-based computing framework, is introduced to implement the parallelization of recommendation algorithms. An experimental analysis of related algorithms. The improved hybrid recommendation algorithm is analyzed experimentally, and the performance difference of the traditional CF algorithm is compared with the algorithm evaluation index.
In the machine translation system, the rule-based machine translation method is relatively intuitive, it can express some language knowledge better, and the scalability of the rule granularity is relatively strong. Although the comprehensive method adopted in this paper has achieved good results, because of the rulemaking problem, this method has a lot of room for improvement.
Footnotes
Acknowledgments
This work was supported by the key projects of scientific research in universities in Anhui province 2019: On the Translation Strategies of Chinese Classics of Science and Technology from Functionalist Approaches: Taking the English Version of Brush Talks from Dream Brook as an Example. Project Number: SK2019A1121.