
Abstract
The regular fuzzy neural network (RFNN) is a kind of fuzzy neural network by fuzzifying the feed-forward neural network. The RFNN can directly deal with the language information and it has the merits of fuzzy system and neural network. It is presented a fast learning algorithm based on the extreme learning machine (ELM) for the RFNN in this paper. The RFNN referred here is a three-layer feed-forward fuzzy neural network and the connected weights in the RFNN are all fuzzy numbers. A simulation example is given to approximately realize the fuzzy if-then rules by the RFNN. The results show that the RFNN trained by the proposed algorithm has good performance and approximation ability.
Introduction
A fuzzy neural network can be obtained by fuzzifying a neural network [1]. The fuzzy neural network mainly divides into two kinds: fuzzy rule-based neural network and regular fuzzy neural network (RFNN). The fuzzy rule-based neural network, also called as neuro-fuzzy network, mainly aims to process numerical relationship [2, 3]. The fuzzy neural network in [3] in fact is a neuro-fuzzy network. The RFNNs in [4] are feed-forward fuzzified neural networks, which are defined from feed-forward neural networks by substituting fuzzified neurons for crisp ones. The topologic of the RFNN is similar to the feed-forward neural network, but the inputs, outputs and weights in the RFNN are all fuzzy sets. The internal arithmetic in the RFNN is based on the Zadeh’s extension principle. The RFNN is an important kind of fuzzified neural network and it can directly process fuzzy information or linguistic information. If a real system maps fuzzy inputs to fuzzy outputs, the RFNN can be used while not the neuro-fuzzy networks to realize such a system approximately [5]. Furthermore, the over fitting problem [6] can be solved by applying the RFNN. Hence, the RFNN plays an important role and it can’t be replaced by the neuro-fuzzy network in real applications.
It is a key problem to provide some efficient and fast learning algorithms for the RFNN. Lots of scholars propose different learning algorithms for the RFNN [1, 7–20]. Based on the types of fuzzy arithmetic used in the learning process, the RFNN’s learning algorithms mainly divide into two methods [1, 7]: the α-cut set learning algorithm and the genetic algorithm(GA).
The α-cut set learning algorithm is to apply the level sets of fuzzy numbers related, and the BP algorithm is used to adjust the endpoints of the level sets to determine the fuzzy weights and biases. Buckley and Hayashi et al. [8, 9] apply direct fuzzification to present the fuzzy delta rule. However, it cannot be used practically because of the lack of theoretic support. Ishibuchi et al. [10, 11] develop a fuzzy BP algorithm for real weights and biases based on finite level sets of the fuzzy sets related. However, a general fuzzy number cannot be determined by finite parameter collection. To avoid such a case, specifically, many authors restrict fuzzy weights and biases to be a given fuzzy set class [12–17]. Puyin Liu et al. [1] fully develop a rigorous theory for the calculus of ∨.nd ∧.perations and propose a fuzzy back-propagation algorithm and a fuzzy conjugate gradient algorithm for the RFNN.
Another learning approach for the RFNN is to utilize the GA [18–20] to minimize the error function and determine the fuzzy connection weights and bias terms. When using GA to complete the learning for fuzzy weights and biases, the fuzzy numbers related must be restricted to a small class, such as triangular or trapezoidal fuzzy numbers, so that they can be determined by a few of parameters related to the fuzzy number class. For instance, Aliev and Krishnamraju et al. [18, 19] employ simple GA to train the triangular fuzzy number weights and biases of a RFNN. They encode all fuzzy weights as a binary chromosome to complete the search process. The transfer function related is assumed to be an increasing real function. R.J. Kuo et al. [20] propose a continuous real-coded genetic algorithm to enhance the performance of the RFNN.
The existing two learning algorithms of fuzzy neural networks have their shortcomings. The α-cut set learning algorithm has a complex computation process and needs to compute the iteration error cost function value. The genetic algorithm evolves slowly and falls into local-minimum and the training time is long. The two kinds of learning algorithms aren’t suitable to large-scale problems. The ELM proposed by Huang [21] is successfully used to train the feed-forward artificial neural network and applied in many fields [22, 23]. Lots of simulations show that ELM has good generation performance and high speed. Jan Chorowski et al. [24] present that the learning speed and average generalization performance of ELM are better than the BP learning algorithm and Support Vector Machine. ELM is an efficient method to simultaneously overcome the existing two algorithms’.isadvantages. Therefore the ELM can be used to adjust the endpoints of the level sets in order minimize the square error function and determine the fuzzy weights and biases of the RFNN.
Some scholars also present some fast learning algorithms based on the extreme learning machine for fuzzy neural networks in [3, 26]. However these works in [3, 26] are different from that in this paper. The fuzzy neural networks mainly divide into two kinds: fuzzy rule-based neural networks and RFNNs. The fuzzy neural networks [3] in fact is fuzzy rule-based neural networks which are also called as neuro-fuzzy networks. While the fuzzy neural network focused on this paper is a fuzzified neural network. The works in [25] refers to a type-2 fuzzy neural network while the fuzzy neural network in this paper is type-1 fuzzy neural network. It’s pointed out that the type 2 fuzzy systems can’t replace the RFNNs because the type 2 fuzzy systems are similar with type 1 fuzzy systems in the architectures and internal operations. The works in [26] refers to a uninorm-based fuzzy neural network while the fuzzy neural network in this paper is based on Zadeh’s extension principle. The RFNN mainly refers to max-min operation which is common and widely used in applications. Therefore RFNN is focused in this paper and it makes sense of providing a fast and convergent learning algorithm for the RFNN in favor of the real applications such as fuzzy inference.
This rest of the paper is organized as follows. Section 2 introduces the basic theory of the extreme learning machine. In section 3, the topologic structure of the RFNN is firstly presented, and then a learning algorithm based on the ELM (called as ELM-LA) is proposed for the RFNN. The simulations are given to show the excellent performance of the ELM-LA in section 3. Section 4 summarizes the study and discusses the future work.
Preliminaries
In this section, the basic theory of the extreme learning machine is simply introduced.
Extreme learning machine (ELM) is originally proposed in 2006 as a single hidden layer feed-forward network (SLFN) by Huang [21]. ELM presents a fast training solution for SLFN, which is very efficient and effective. In ELM, parameters are randomly assigned, and the output weights can be analytically determined by the generalized inverse operation.
For N samples
the output of ELM with L hidden neuron nodes is
where β
j
is the output weight from the jth hidden node to the output node;.w
j
∈.R
d
and b
j
∈.R are the input node parameters generated randomly;.G (w
j
, b
j
, x
i
) is the output of jth hidden node with respect to the input x
i
;.w
j
·.x is the inner product of w
j
and x. And g (·) is the activation function of hidden node. The activation functions g (·) can be sigmoid function as well as the radial biases, sine, cosine, exponential, and many other non-regular functions as shown in Huang [21]. For additive hidden node, G (w
j
, b
j
, x
i
) is given by Equation (2).
The G (w
j
, b
j
, x
i
) is defined by
for RBF hidden node. Then the training of the ELM model is to look for suitable equivalent to obtaining the minimum norm least squares solution of the system of equations as follows.
where the parameters (w j , β j ) are the weights and b j are the biases, which can be given by β = H+Y, where
is the hidden layer output matrix. H+ is the Moore-Penrose generalization inverse of H. Y = [y1, y2, …, y N ] T .
Compared with the conventional popular learning algorithms, ELM offers many significant advantages such as good generalization performance, fast learning speed, and ease of implementation. On the other hand, ELM also has inherent drawbacks such as unsteadiness derived from the randomness of input weights, and incompact network architecture. Moreover, ELM belongs to a black-box-type modeling approach, so it is not trivial to impose a priori knowledge such as periodicity, symmetry, or monotonicity in ELM.
In this section, the architecture of the RFNN is presented at first. Next a fast learning algorithm based on ELM for the RFNN is proposed. At last simulations realizing the fuzzy rules and comparisons to other existing learning algorithm are given.
Architecture of the RFNN
The RFNN is fuzzified the feedforward neural network by substituting fuzzified neurons for crisp ones. In the RFNN the neurons are organized into number of layers and the signals flow from neurons of one layer to the neurons of the consequent layer. There are no interactions among the neurons of the same layer and no feedback loops in the RFNN. The architecture of a three-layer feed-forward RFNN is shown as Fig. 1. In this paper the three-layer RFNN is considered for simplicity sake. In general, any number of layers can be introduced.
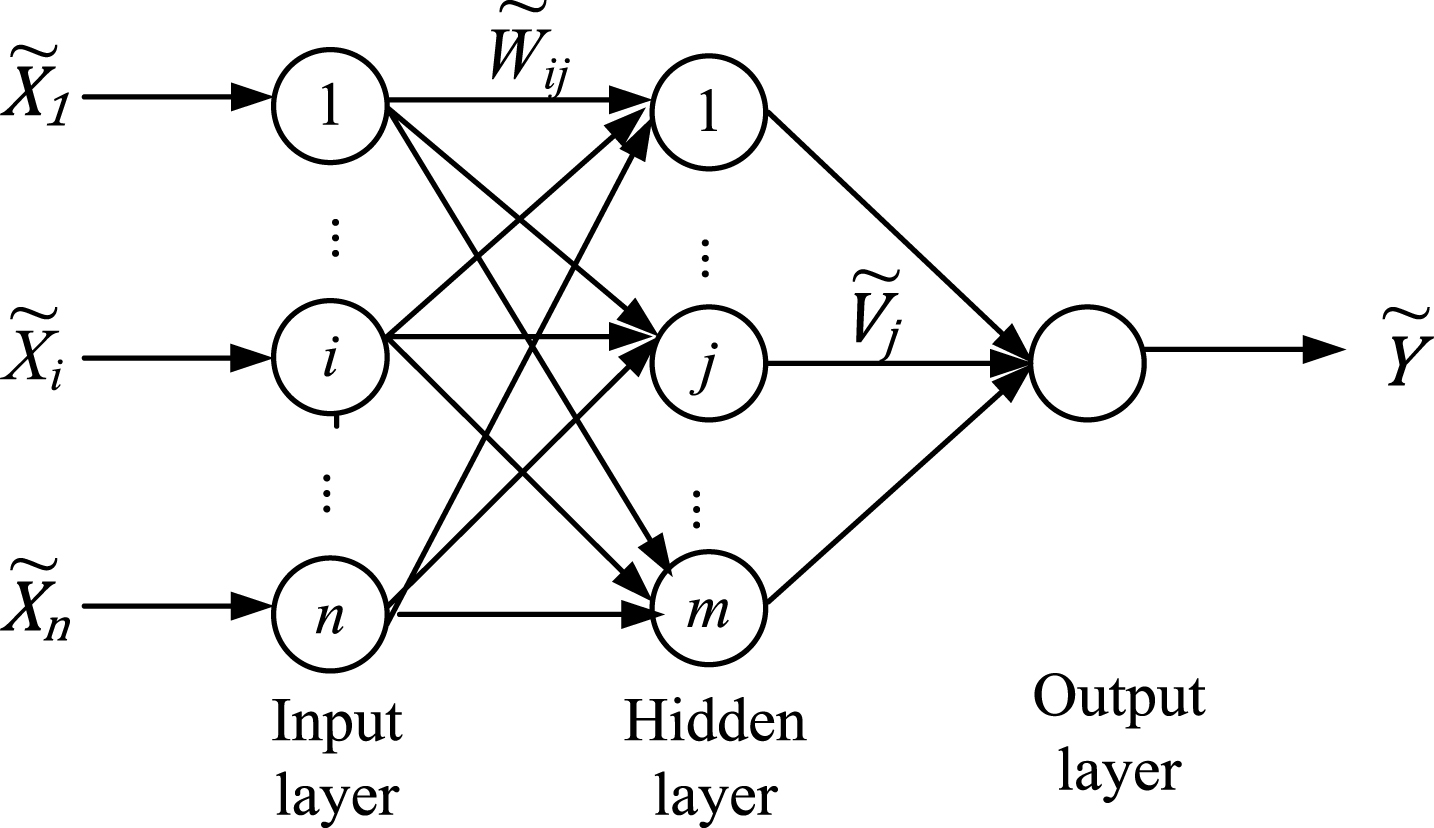
Architecture of the RFNN.
As shown in Fig. 1, the RFNN has multiple inputs and single output. The fuzzy connect weight between neuron i of the input layer and neuron j of the hidden layer is
The activation function of input layer and output layer are all linear f (x) = x. The target vector is
is presented to the RFNN and the input-output relation can be written as follows.
where
The level sets of the outputs in the RFNN have been analyzed clearly in [1] and it is omitted here. The error function of the RFNN is needed in the learning algorithm of RFNN in this paper. So it is simply introduced here.
It is assumed that
is a family of fuzzy pattern pairs for the RFNN.
From the definition of metric D (·, ·) and Corollary 1 [1], the following equation can be concluded if and only if sufficiently large γ ∈.N.
And it follows that
The square error function is defined for the RFNN as follows in Equation (7), which can be approximation of the corresponding mean square error as follows.
where
A learning algorithm based on ELM is proposed to get the α
k
- level sets
The detailed learning algorithm process based on ELM (called as ELM-LA) is presented for the RFNN as follows.
ELM-LA
According to the principle of the ELM, the weights
A simulation example is shown in order to examine the performance of the ELM-LA. The RFNN is used to realize a family of fuzzy IF-THEN inference rules approximately. A fuzzy BP algorithm for the three layers feed-forward RFNN is presented in [1]. The fuzzy BP algorithm [1] is classical and efficient, so the proposed algorithm in this paper is compared to the fuzzy BP algorithm in [1].
Fuzzy rules table
Fuzzy rules table
IF x1 is high AND x2 is high THEN y is high.
IF x1 is high AND x2 is low THEN y is medium.
IF x1 is low AND x2 is high THEN y is medium.
IF x1 is low AND x2 is low THEN y is low.
In the Table 1, only four rules out of 9 fuzzy rules are given and others are missing. The antecedent and consequent fuzzy sets “low”, “medium”.nd “high”.re fuzzy numbers defined on [0, 4], respectively. Denote “
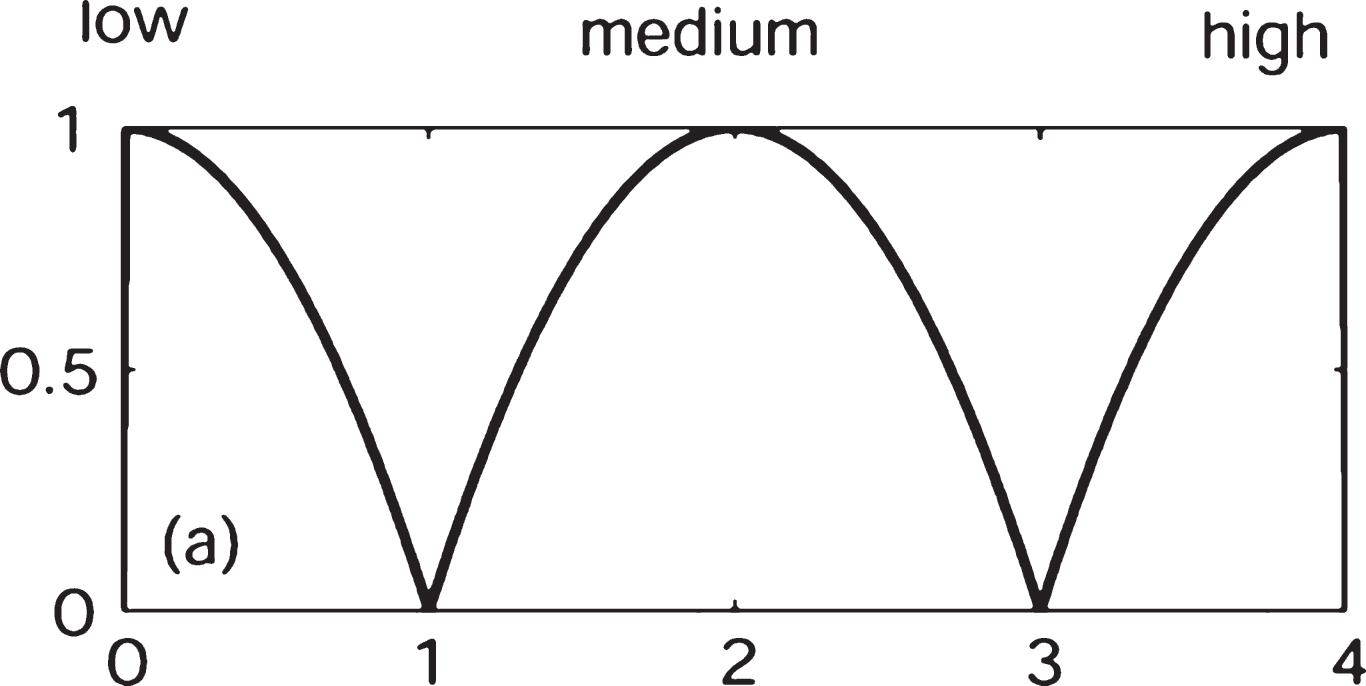
Membership curves of fuzzy numbers “low”, “medium”, high”.
In the simulations, fuzzy arithmetic in the RFNN is approximately performed by interval arithmetic on h-level sets (i.e., α-cuts for α = h) of each fuzzy number. Six level sets in the learning phase are used in this paper. In the RFNN, let γ = 5,
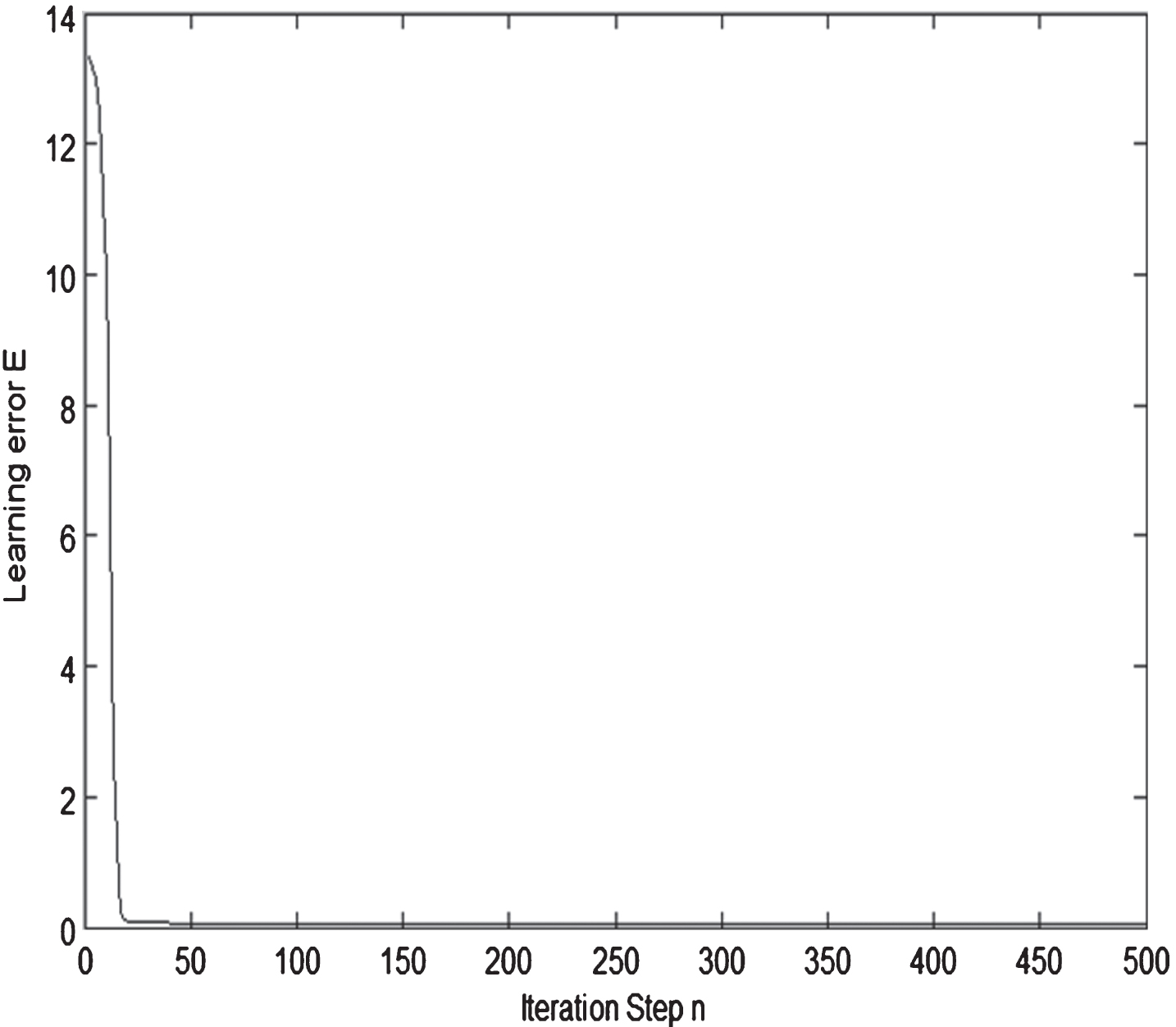
Using ELM-LA, the RFNN Corresponding to the input patterns in the training set can be learned. The actual outputs of the RFNN trained by the ELM-LA are shown as in Table 2. The error function curve of ELM-LA is shown as Fig. 3.
Error function curve of ELM-LA.
The cut set of the target outputs and the actual outputs
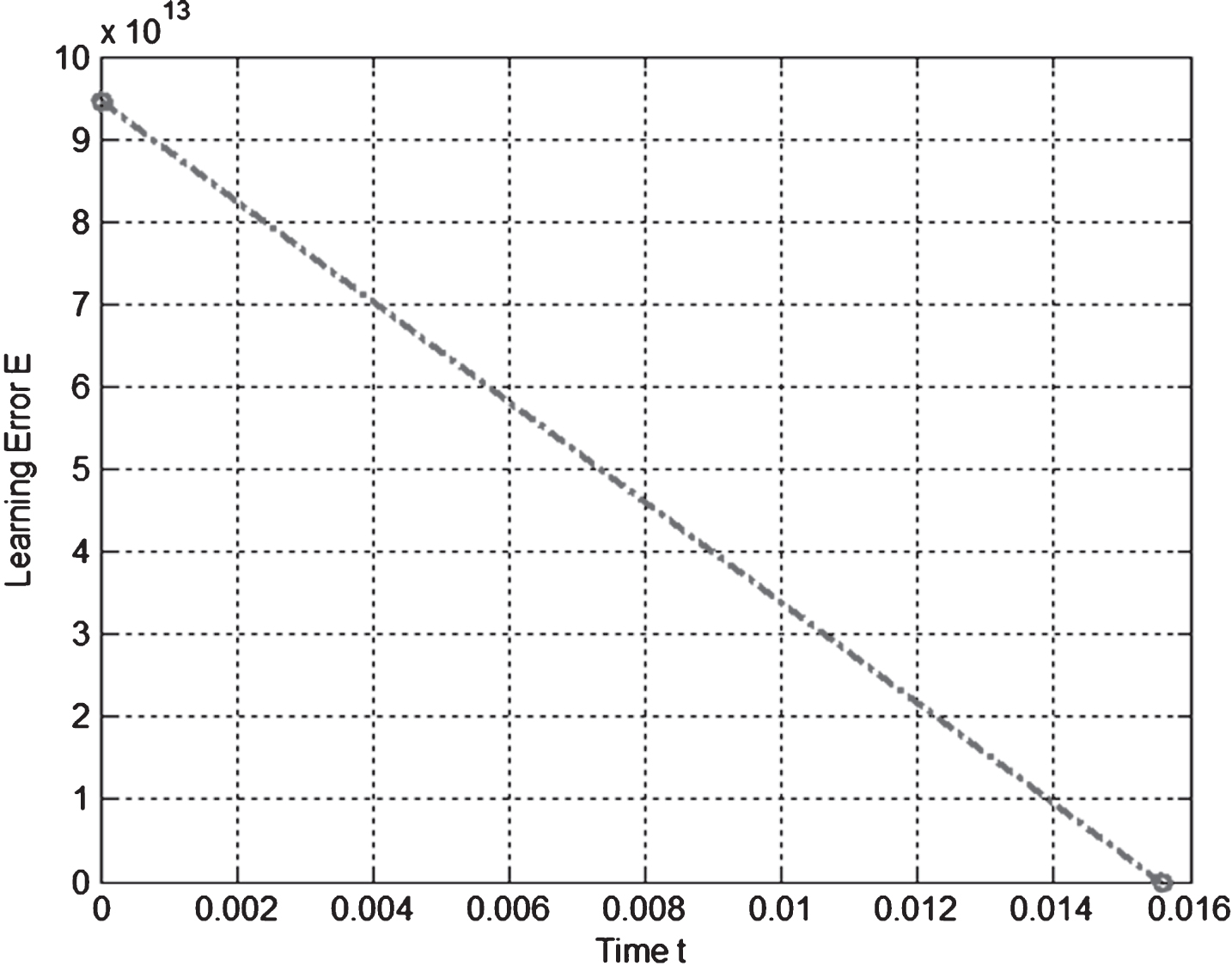
The performances between the ELM-LA and the fuzzy BP algorithm are compared here. The same fuzzy IF-THEN inference rules are realized by the RFNN trained by the fuzzy BP algorithm. The mean square error and the system running time are compared in Table 3.The error function curve of the fuzzy BP algorithm is shown in Fig. 4. It is Obvious that the ELM-LA in this paper is fast and can get better square error performance than those of the fuzzy BP algorithm. This is because the ELM-LA in this paper needn’t iteration in the learning process.
Error function curve of fuzzy BP algorithm.
The performance comparison between Algorithm 1 and Fuzzy BP algorithm
It is presented a learning algorithm based on ELM for the three-layer feed-forward RFNN in this paper. The learning algorithm is constructed by developing a theory for differentiating I/O relationships of the RFNN. In the simulation example, the RFNN trained by ELM-LA can approximately realize a family of fuzzy inference rules. The simulation results show that the RFNN trained by ELM-LA can get better performance than that by the Fuzzy BP algorithm. The further research for the learning algorithms based on ELM includes applying them to design other FNNs.
Footnotes
Acknowledgments
This work is supported by the National Natural Science Foundation of China (Grant No. 61402227, 61502407, 61772178, 61672447), the Project in Hunan province department of education (Grant No. 16C1546) and the project of Xiangtan University (Grant No. 11kz/kz08055). This work is supported by Key Laboratory of Intelligent Computing &.nformation Processing (Xiangtan University), Ministry of Education and the Key disciplines of Hunan Province Computer science and technology.