
Abstract
The conventional fuzzy c-means (FCM) clustering method can be applied on data, where data features are crisp; however, when the features are fuzzy, the conventional FCM cannot be utilized. Recently, some researchers applied FCM on fuzzy numbers when the used metric has a crisp value. Since difference between two fuzzy numbers can be represented by a fuzzy value better than crisp one, in this paper, it is going to extend the FCM method for clustering symmetric triangular fuzzy numbers, where the used metric has a fuzzy value. It will be shown that the proposed fuzzy distance expresses the distance between two fuzzy numbers much better than crisp metrics. Then the proposed method has been applied on simulated and various real data, where it is compared with several new methods. The experimental results show better performance of the proposed method in compare to other ones.
Introduction
Fuzzy data analysis has been widely used in numerous fields including pattern recognition, data mining and image processing. Progresses in fuzzy mathematics have encouraged engineers and scientists in applied fields to present real models such as fuzzy image filtering [1], fuzzy clustering [2–10], fuzzy regression analysis [11, 12] and fuzzy classification [13, 14].
A fuzzy number (in compare to a crisp one) works better in declaring the difference between two fuzzy numbers [15–17]. For example the difference between “about 2” and “about 4” is better to be said “about 2” rather than “exact 2” (which is a crisp number). This idea is considered in some pattern recognition fields such as classification [18]. In spite of this advantage, calculation complexities dealing with fuzzy logic way have become a pitfall.
Nevertheless, all of the following reasons are the major points of the authors to focus on the triangular fuzzy numbers in this paper: The simplifications done on some kinds of fuzzy numbers like triangular, LR-type and trapezoidal numbers [19–21]; Frequently use of triangular numbers in processing dates and due times [22, 23]; Triangular fuzzy numbers belong to a typical class of fuzzy numbers, which can be regarded as a general form of the symbolic interval and the crisp numbers [7].
It must be mentioned, the method introduced here is applicable on the other kinds of fuzzy numbers by the same structure as well.
The rest of paper is organized as follows: preliminary discussions, i.e the conventional FCM clustering method (applied on crisp numbers) and some fuzzy conceps are considered in Section 2. In section3, a brief review of valid literature has been described. The proposed FCM clustering method to apply on symmetric triangular fuzzy numbers is presented in Section 4. Section 5 presents simulation results of the proposed method applied on simulated and real (Taiwanese tea, students and satellite images) fuzzy numbers. Finally the conclusion is given in section 6.
Preliminaries
As the proposed method is based on the conventional FCM, a description of FCM will be given concerning the special manner in which it is applied on crisp numbers. Then some fuzzy concepts are reviewed in this section for better understanding of the proposed method, which will be explained in the next section.
The conventional FCM applied on crisp numbers
One of the most widely used fuzzy clustering method is FCM [24, 25] which is the fuzzy equivalent of the nearest mean “hard” clustering method. The FCM clustering method assigns fuzzy memberships to each input number. The goal of the FCM algorithm is to minimize the following objective function with respect to fuzzy membership
where, X ={ x1, ⋯ , xk, ⋯ , xn } denotes the set of input numbers,
Using Lagrange function, we can minimize the objective function J (U, V) in (2.1.1) which is subjected to the constraints (2.1.3) and conclude the following updated function:
The membership degree
The support of
Here,
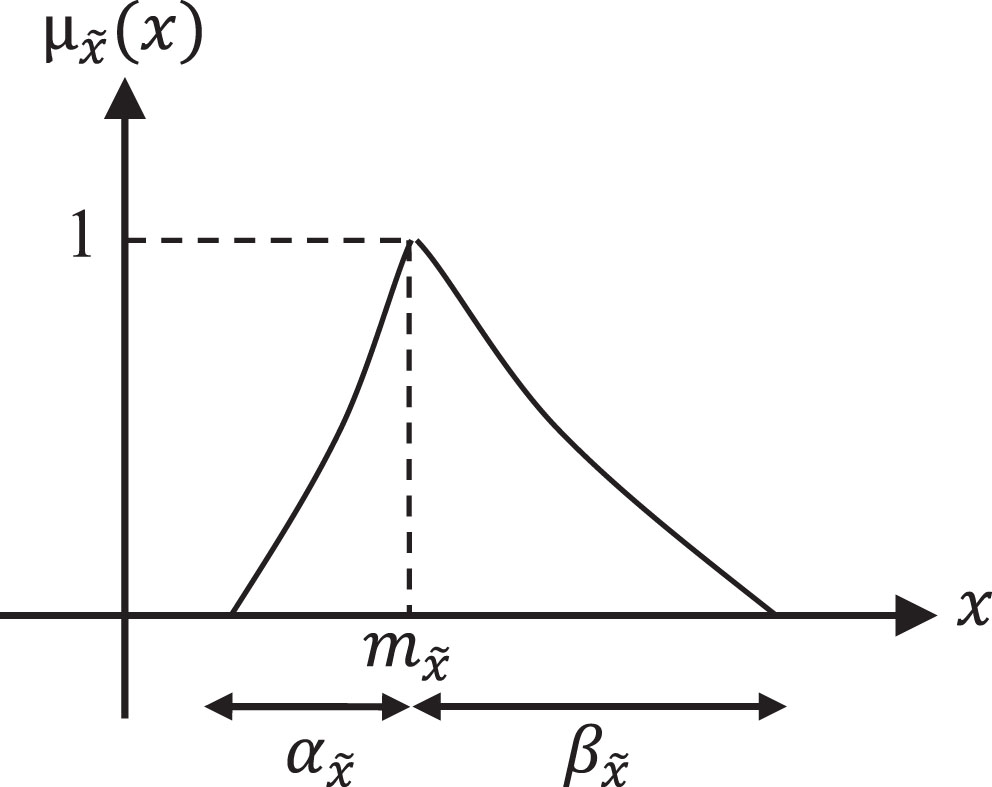
An LR-type fuzzy number.
This fact is illustrated in Fig. 2 through an example.

The fuzzy smaller concept for
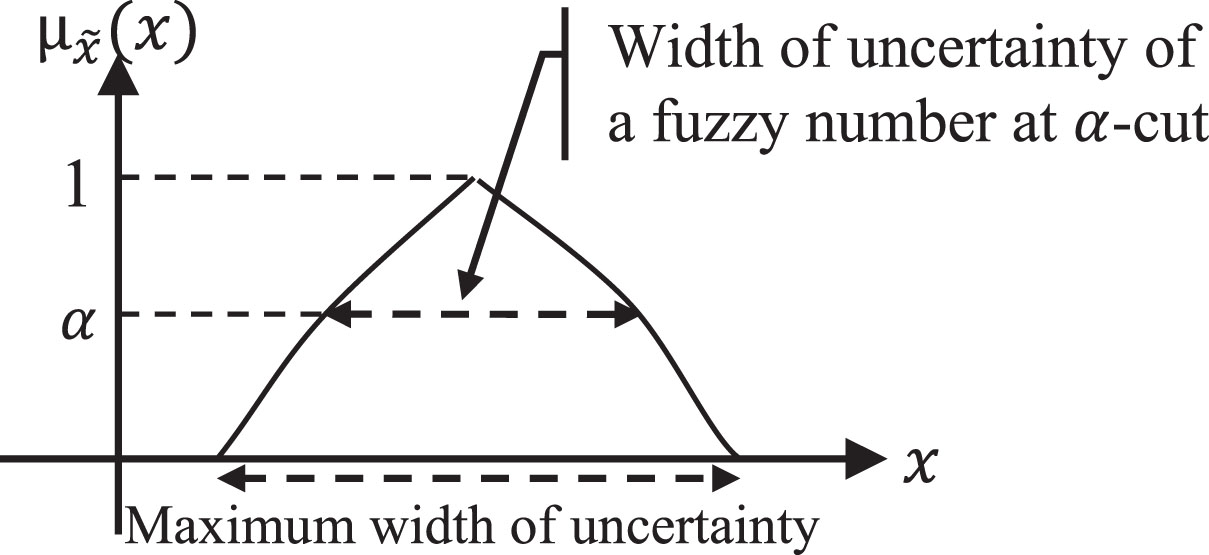
Width of uncertainty.
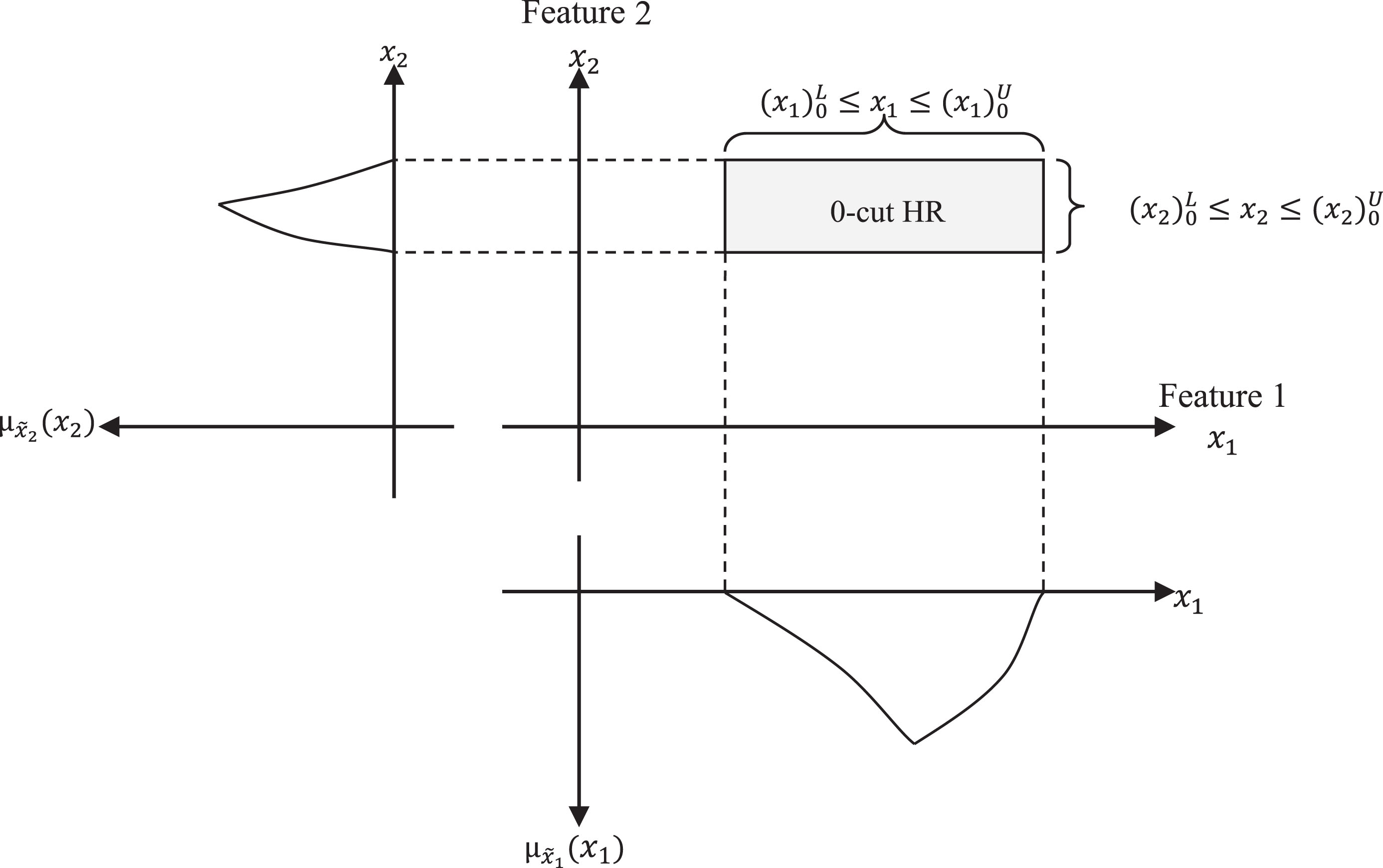
0-cut HR of a 2-dimensional fuzzy number
There are various papers to apply FCM on the non-crisp (fuzzy) numbers [2–8, 28–30]. They can be summarized in one structure as Fig. 5, where the mapping function changes respect to influenced fuzzy number type and utilized metric definition [8].
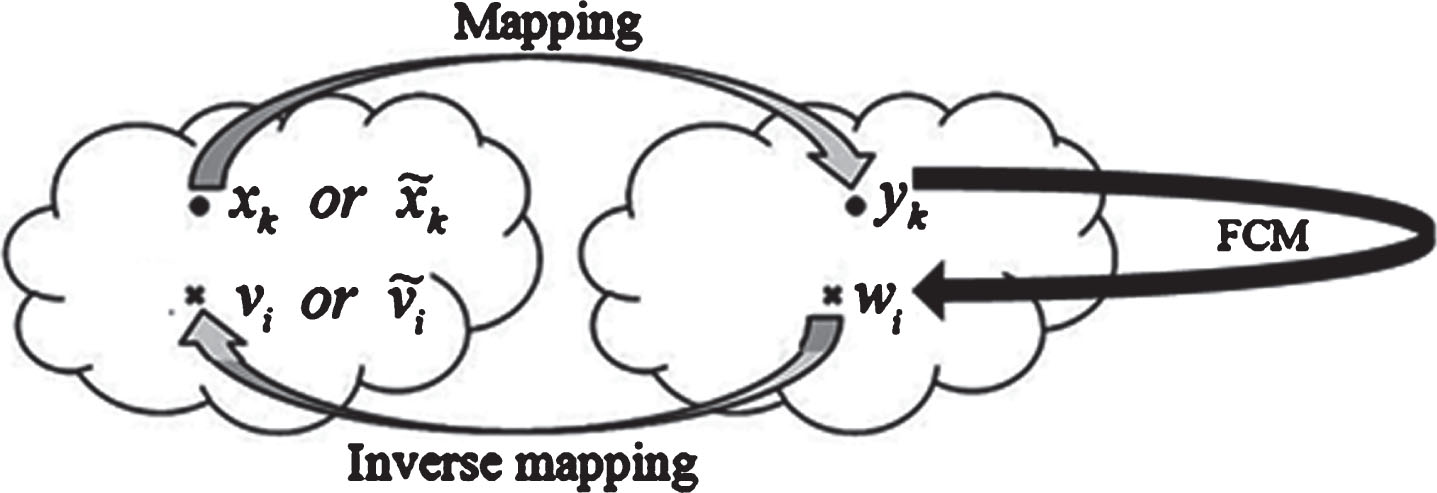
FCM applying on any crisp and non-crisp numbers in one structure [8].
Fuzzy clustering is an important tool for discovering data structure. The fuzzy c-means (FCM) algorithm [25], the best-known clustering algorithm, has been used in a wide range of engineering and scientific disciplines such as medicine imaging, bioinformatics, pattern recognition, and data mining. Hathaway et al. [2] proposed a new distance definition for fuzzy LR-type data and applied FCM on them. Yang et al. [3] described a class of fuzzy clustering procedure for fuzzy data. Considering most of fuzzy clustering techniques, that imposed on crisp data based on the concept of membership function which use the idea of fuzzy set theory, Yang et al. [3] derived new types of fuzzy clustering procedures dealing with fuzzy data, called fuzzy c-numbers (FCN) clustering. They construct these FCNs especially for LR-type, triangular, trapezoidal and normal fuzzy numbers. Yang et al. [4] also presented fuzzy clustering algorithms for a combination of symbolic and fuzzy data features. Besides, they gave a modified dissimilarity measurement for symbolic and fuzzy data and then applied FCM clustering algorithm on these combined data types. Finally, they applied suggested clustering algorithm to real data with combined feature variables of both symbolic and fuzzy data. Hung and Yang [5], also suggested a kind of fuzzy clustering algorithm, called the alternative fuzzy c-numbers (AFCN), for LR-type fuzzy numbers based on an exponential distance function. On the basis of the gross error sensitivity and influence function, this distance has been claimed to be robust with respect to noise and outliers. Hence, the AFCN clustering algorithm is more robust than FCN presented by Yang et al. [3]. Yang et al. [6] applied a mixed-variable fuzzy clustering algorithm, called mixed-variable fuzzy c-means (MVFCM), for cell formation (CF) in Group technology (GT). A fuzzy clustering algorithm for triangular fuzzy numbers is studied by Rong et al. [7]. They introduced a new distance between triangular fuzzy numbers using three interval number parameters, and proved that the presented distance is a complete metric on the set of triangular fuzzy numbers. Consequently, based on this new distance, they presented two fuzzy c-means types of clustering algorithms to deal with triangular fuzzy numbers. Finally Hadi et al. [8] suggested Vector form of fuzzy c-means (VFCM) that simplified the FCM clustering method applying to non-crisp numbers. They showed that the VFCM method is a simple and general form of FCM that applies the FCM clustering method to various types of numbers (crisp and non-crisp, with different correspondent metrics) in a single structure, and without any complex calculations and exhaustive derivations. They also suggested the meta-fusion, that uses fuzzy (symbolic-interval) numbers to demonstrate the output of (multi panchromatic satellite images) fusion process in order to multi images segmentation [30]. They showed this fusion method and conventional FCM method applying on the fuzzy results of fusion process leads to better performance. Wang et al. [10] presented a fuzzy-based customer clustering algorithm with a hierarchical analysis structure for heterogeneity and high-dimension of customers’ characteristics. They developed a fuzzy clustering algorithm based on Axiomatic Fuzzy Set to group the customers into multiple clusters. Wang et. al. also, presented an approach to optimize the vehicle routing problem based on customer fuzzy clustering with similar characteristics under a hierarchical analysis structure [9].
In the overviewed clustering-based researches, the distance between two fuzzy numbers is assumed to gain a crisp value [2–8, 30]. Considering the distance of two fuzzy numbers as a fuzzy number (not a crisp one), the conventional FCM clustering method objective function (in fuzzy state) has been utilized in the proposed method. Therefore unknown parameters in the proposed method are found through minimizing a fuzzy objective function. It will be shown that the crisp metric (e.g. the Yang distance [3, 5]) is unable to express the distance between two triangular fuzzy numbers as well as the proposed fuzzy metric.
The proposed method
As mentioned earlier, the reason of adapting triangular fuzzy numbers as the affected elements for clustering is to use them frequently in processing dates and due times [22, 23]. Note that, triangular fuzzy numbers belong to a typical class of fuzzy numbers, which can be regarded as a general form of the symbolic interval and the crisp numbers [7]. Furthermore, in the case of having symmetric triangular fuzzy numbers, which is mentioned in section 2.2, computations become very simple. Therefore we choose symmetric triangular fuzzy numbers to analyze the proposed method as well [11, 12].
Let
where
If we define
where | · | applies element absolute value on a vector. The mentioned distance definition
It can be that equation (3.4) satisfies all metric conditions. However, this metric do not change the used squared distance in the proposed FCM cost function (equation (3.1)) and
If
where
The corresponding Lagrange function of (0.6) is as follows:
To obtain the optimal solution, the following conditions should be satisfied:
where k = 1, ⋯ , n, i = 1, ⋯ , c, j = 1, ⋯ , p and
However, the mentioned case is not our major concern, so we will not examine it any more.
Considering the relation c < n, which is common in the clustering method, with equation (4.10), we can conclude that βi,j > 0, therefore (4.11) results in
Finally, we can summarize the proposed method and write its semi-code through the following steps:
Let
In the proposed fuzzy distance,
number like
For simplicity, suppose
To make it more simple, let
Hence for two fuzzy numbers
While in the proposed method and with fuzzy distance definition (4.4) we have:
It can be proved that there not exist
Even using the defuzzifying process (see equation (4.6)), in the condition of repeating the procedure, just like Yang distance, it will result in the following equation:
As it can easily be seen, the equality condition depends on K parameter. On the other hand, since the proposed method is a clustering algorithm and clustering is an unsupervised partitioning method (when all input numbers are known and there will not be any unknown test data in clustering methods) therefore, the range of input numbers would be accessible. Since K parameter can be selected by the user, we select it in a way that the satisfied
In this section, the performance of the proposed method will be examined using some fuzzy numbers through two subsections. In the first subsection we use the proposed method for clustering simulated fuzzy numbers. In the next subsection, the proposed method is applied on Taiwanese tea dataset to detect their grades. Consequently, the Yang method is applied on Taiwanese tea dataset and the results of the two clustering methods, the proposed one and the Yang method, will be compared.
Simulated fuzzy data clustering using the proposed method
In the first subsection, to make demonstration easier, a 2-dimensional data is used. The cores of the fuzzy numbers are shown by small directional triangles in the fig.s. Moreover, only the 0-cut HR of each triangular fuzzy number is shown in the fig.s to make it clearer. The resulted centers in each fig. are indicated by directional triangles that have magenta cores and cyan screens.
Generating 6 fuzzy numbers, we obtained the clustering results for the proposed method for c = 2 and θ = 2. Figure 6 shows the results for K = 0, 0.3, 0.6, 1, 2 and 10 respectively. Table 1 shows the fuzzy membership grade of input numbers for two resulted centers corresponding each value of K parameter. As it can be seen, for the best performance; 0 ⩽ K ⩽ 1. For K > 1, as the centers recede from input numbers, the input numbers get the same membership values for each center. This is due to the increase of vagueness in the proposed method as the K parameter takes a larger number. Obviously, this fact can be easily seen through equations (4.14) and (4.15), where by increasing K, the second term of numerator and denominator in (4.14) and the second term of numerator in (4.15) increase with respect to the corresponding first term resulting in an increase in the vagueness of the proposed method.

Resulted clusters for K = 0, 0.3, 0.6, 1, 2 and 10.
Membership values of input numbers to the clusters
In this sub-section, we are going to use the proposed method for clustering Taiwanese tea, the defined dataset in [5]. Furthermore, the performance of proposed method will be compared with Yang FCM which is called FCN (see [3, 5]).
Tea has become an important agricultural product in Taiwan and there exist currently 20,000 ha of tea farms with an annual production of 21,000 tons. Different types of tea produced in Taiwan include green tea, Paochong, Oolong and black tea. Recently, Paochong and Oolong varieties have cornered the other two markets. Because the tea varieties and prices are numerous and complicated, many consumers have been confused. To give consumers a better understanding of Taiwanese tea, the Taiwan Tea Experiment Station (TTES) has been making serious attempts to formulate an evaluation system for tea quality. Generally speaking there are four criteria used to evaluate tea quality: appearance, tincture, liquid color and aroma.
Sincetea evaluation is always judged by experts, its quality levels are described by terms: perfect, good, medium, poor and bad. These five quality levels cause an inherent ambiguity in human perception. Since fuzzy sets are proper for describing ambiguity and imprecision in natural language, these terms can be defined using triangular fuzzy numbers as follows: X
perfect
= (1, 0.25, 0)
T
, X
good
=(0.75, 0.25, 0.25)
T
, X
medium
= (0.5, 0.25, 0.25)
T
, X
poor
= (0.25, 0.25, 0.25)
T
and X
bad
= (0, 0, 0.25)
T
. These representations are shown in Fig. 7. Because tea evaluation varies by the criteria of each individual expert, 10 experts were assigned to evaluate each kind of tea and assign the quality levels of perfect, good, medium, poor and bad to the four criteria of appearance, tincture, liquid color and aroma. For each criterion, a fuzzy arithmetic average was used to obtain a fuzzy number and then perfect, good, medium, poor or bad labels were assigned to that fuzzy number. The final evaluation data is shown in Table 2. Let

Five triangular fuzzy numbers for a particular criterion.
Here the input numbers are fuzzy triangular but, our proposed method is applicable to the samples of which features are symmetric triangular fuzzy numbers. Therefore, we approximate each input member by the nearest corresponding symmetric triangular fuzzy number as follows [5]:
Now, we apply the proposed method and FCN to cluster resulted Taiwanese teas symmetric triangular fuzzy numbers assuming θ = 2 and c = 5. Furthermore, in the proposed method we assign two values for K ; 0.01 and 0.3. Resulted clusters centers and membership values of each tea type in clusters are obtained in Table 2 for each clustering method.
Proposed clustering method and FCN applying over 69 types of Taiwan tea tree
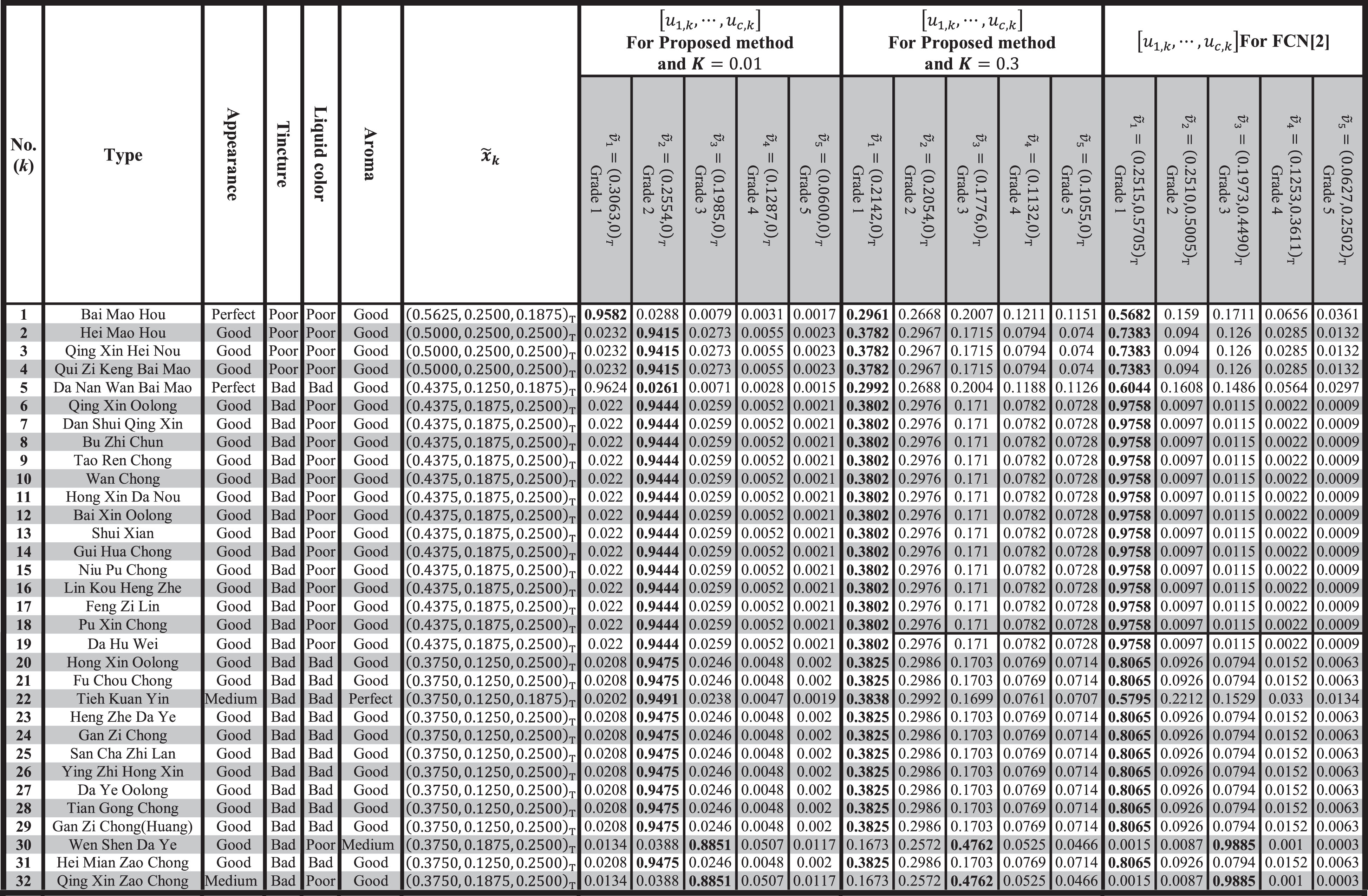
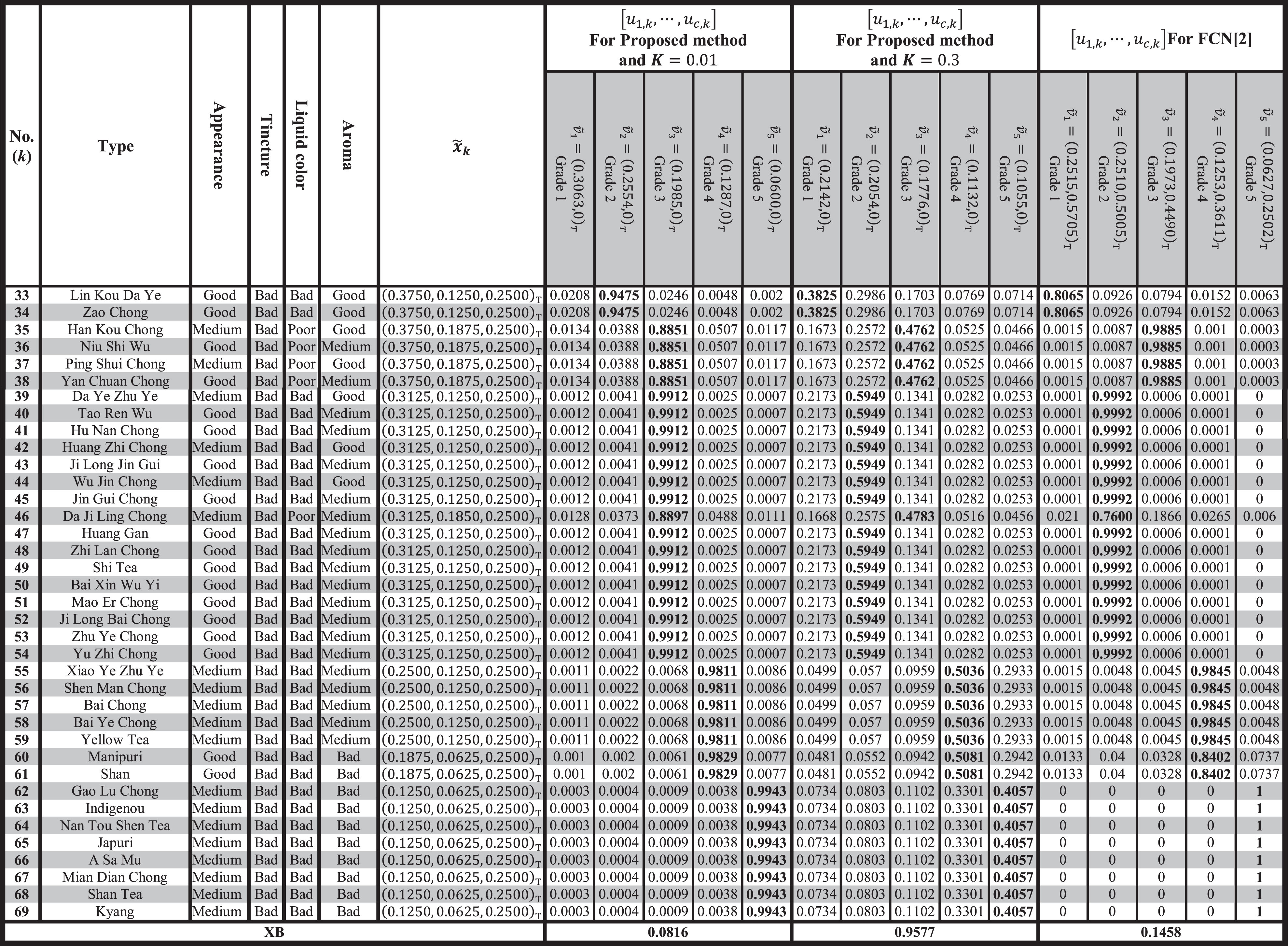
It must be mentioned, in order to achieve a valid K, in the proposed method, where
Making a full search in the mentioned intervals, it can be concluded that there is no K > 0 to satisfy the above equation.
To calculate the amount of fuzziness in clustering results, the following validity index is proposed:
In the k-means clustering method of which the clustering method is crisp and fuzziness value is equal to zero, we have XB = 0. When the fuzziness in the clustering results increases, the index XB grows up. Therefore, in the FCM clustering method and when
The corresponding grades of each tea type using three methods are bolded in Table 2. It can be easily observed that choosing K = 0.01, the proposed method becomes the “nearest mean “hard” clustering method (k-means)” applied to tea fuzzy numbers (because the corresponding fuzziness validity index XB is 0.0861, which is near to zero) and taking K = 0.3 it becomes a fuzzy c-means clustering method (because the corresponding fuzziness validity index XB is 0.9577, which is near to one), in which the vagueness of the proposed method increases as K parameter takes a larger number. However, the FCN works as a “nearest mean “hard” clustering method (k-means)” on tea fuzzy numbers (because the corresponding fuzziness validity index XB is 0.1458, which is near to zero). As a conclusion it can be inferred from above that the proposed clustering method is a general form of FCN concerning the change in the K parameter.
After testing the proposed method on several datasets, it is possible to formulate some conclusions on the value of K parameter as:
The proposed method
In the Table 2 last column, the proposed method has been compared with FCN method [2] and the results show that the proposed method (by adjust k) is a global mode for fuzzy clustering.
The student dataset [28] consists of six students and four attributes. Table 3 shows the corresponding fuzzy data. Wen et al. [29] implement the SCA for the data set and then single linkage hierarchical algorithm on the final data. They achieve two well-separated clusters and hence the optimal cluster number c* is 2. The clustering results show that the data points 1, 2 and 4 belong to cluster 1 and the data points 3, 5 and 6 belong to cluster 2. That is, Tom, David and Jane belong to cluster 1 and Bob, Joe and Jack belong to cluster 2. They find that (i) the members of cluster 1 have high marks in Mathematics 2 and Physics and the moderate mark in Mathematics 1, (ii) the members of cluster 2 have very lower mark in Mathematics1, moderate mark in Mathematics2 and higher mark in Physics. In the sense, the students in cluster2 have bad performance in Mathematics.
Student dataset
The proposed method has been tested on the student dataset too. Table 4 shows the result for two different values of k. It can be seen for k = 0.05 two clusters has been achieved: the members of cluster 1 have higher average marks in mathematics (Tom, David and Jane) and the members of cluster 2 have higher average marks in physics (Bob, Joe and Jack) and for k = 0.4 the result is fuzzy clustering which obtained in [29].
Resulted overall accuracy (OA) and Kappa (Ka) indices in the accuracy assessment of proposed method and other literature results
To demonstrate the efficiency of the proposed method, its performance is evaluated in segmentation of land-cover using satellite images. For this purpose two panchromatic satellite images Geoey-1 (with 0.5 m spatial resolution) and IRS-P5 (with 2.5 m spatial resolution) are utilized that are located in south of Iran, with geographical location of 26.67–26.8 N and 56.04–56.06 E. These images are resampled and registered together and have same size (1000*1000 pixels) [30].
To obtain the ground truth (GT) data for accuracy assessment, as same as [30], the correspondent map is used where four classes (sea with black DN, main road with new and dark asphalt, sidetrack with old and bright asphalt and building’s roof with white DN) are selected and labeled to 1, 2, 3 and 4 respectively; according to DN increasing manner. Table 4 shows the simulation results of proposed (with K = 0.11, obtained by trial and error method) and comparing methods where overall accuracy (OA) and Kappa (Ka) validity indices are utilized.
In the aspect of complexity analysis, the proposed method for each K-parameter value is as same as the conventional FCM method [37, 38]. Since, to get the best K-parameter the rial and error method (by varying from 0 to 1) is utilized in this paper and wide range values of K-parameter must be evaluated, the overall complexity of proposed method is very large and multiple value of conventional FCM method, depending on number of utilized different K-parameter values.
In this paper, we applied FCM clustering method on symmetric triangular fuzzy numbers based on the definition of a fuzzy distance between two fuzzy numbers. We used fuzzy smaller concept for symmetric triangular fuzzy numbers and defined a fuzzy metric for them. Similar to the conventional FCM, we found the unknown parameters in clustering process by minimizing a fuzzy objective function using a wellknown defuzzification procedure. It is proved that the proposed fuzzy distance expresses the distance of two fuzzy numbers better than crisp metric (the Yang metric [3, 5]). It is shown that the proposed method is a general form of FCN [3, 5], base on the changes in the proposed method parameters.
K parameter in the proposed method has been obtained with trial and error method and this is main problem in this work. In the future research, this parameter can be obtained with smart algorithm systems. It is to be noted that, the proposed algorithm is potential to apply in other wide datasets too.