
Abstract
Wireless mobile ad hoc networks (MANETs) have emerged as a key technology for next-generation wireless networking. Due to its advantages over other wireless networks, MANETs are undergoing rapid progress and inspiring numerous applications. However, many technical issues are still facing the deployment of this technology, and one of the most challenging aspects is the Bandwidth conserving Technology. To achieve this aspect this paper proposed a method for maintaining infrastructure of the network and mobility of nodes. This can be achieved by employing clustering to improve the stability of nodes by utilizing weight-based clustering algorithm. However, the mobility of the node is maintained by utilizing distributed scheduling works based on a priority based Distributed Scheduling to reduce interference so as to improve the throughput.
Introduction
Over the last few years, wireless data traffic has drastically increased due to a change in the way today’s society creates shares and consumes information. This change has been accompanied by an increasing demand for much higher speed wireless communication anywhere, anytime [1]. Recent Advances in portable computing devices and wireless communication technology have made it possible to stay connected anywhere anytime. In the near future users will be able to move freely and still have a seamless, Reliable, and high speed network connectivity. Portable computers and hand held devices will do for data communication through wireless networks, what cellular phones are now doing for voice communication [2, 3]. A wireless network is modeled as a set of nodes that send and receive messages over a common wireless channel [4]. There is significant interest toward the asymptotic capacity of the network when the number of nodes grows. The capacity scaling of wireless networks is subject to a fundamental limitation which is independent of power attenuation and fading models [5, 6].
Recent technological advances have resulted in the development of wireless ad hoc networks composed of devices that are self-organizing and can be deployed without infrastructure support. These devices generally have embedded storage, processing and communication ability. While ad hoc networks may support different wireless standards, the current state-of the- art will be mostly limited to their operations in the 900 MHz and the 2.4 GHz these are used in industrial, scientific and medical (ISM) bands [7, 8]. Ad hoc networks mostly refer to wireless networks where all network components are mobile. In an AHN there is no distinction between a host and a router since all network hosts can be endpoints as well as forwarders of traffic. In contrast with fixed infrastructure the AHNs require fundamental changes to network routing protocol, including multicast routing and packet forwarding [9, 10].
Likewise the Wireless ad hoc networks are of use when there is a lack of fixed communication infrastructure. Such situations might arise in calamity environments, sensor network applications [11, 12], and a variety of other civilian and military contexts. In many applications, multicast data transfer is more predominant than unicast data transfer. The data flows are routed between the clients and the gateways through wireless links, in a multi-hop fashion. A notable challenge in Wireless mobile node is to provide support for multicast applications that surged on the Internet during the past decade, such as file dissemination, video conferencing and live media streaming [13]. As the capacity of wireless devices continues to improve, an increasing number of multicast applications, such as wireless IPTV, Radio over IP, and Video conferencing, are being developed for mobile users. Recently developed technologies, like Wi-Fi and WiMAX, are excellent platforms that enable service carriers to provide multicast services wirelessly due to the platforms’ high capacity, wide coverage range and the broadcast nature of the wireless medium [14 –16].
Multicast services are a very popular bandwidth-conserving technology. It is an ideal communication paradigm for several application areas that require efficient support of group communication: for example, military operations, emergency and rescue missions, networked games, conferencing, and synchronization [17]. Multicasting is based on the increase of transmission in the Internet [18]. As the transmission range increases, the number of transmissions to deliver one packet from a given source to its destination is reduced. On the other hand, the quality of each wireless link deteriorates. These phenomena can be explained by the transport capacity, which is defined as the product of the transmission rate and the transmission distance [19]. The multicast sessions can be supported by a network, which has the total capacity and have to achieve the capacity in a simple and practical manner [20].
In proposed Method, for improving the network capacity, Dynamic clustering technique will be used. This technique will maintain the infrastructure and mobility of Nodes. To reduce the interference in the network, graph based scheduling technique will be used. By this method, interference of the network will be reduced and the network capacity will be improved.
Related works
Behrooz Makki, Thomas Eriksson [21] studied the capacity of Rayleigh-fading correlated spectrum sharing networks. They assumed perfect CSI available at the secondary user transmitter and receiver, the channel performance is investigated under different primary user outage probability and instantaneous or average received interference power constraints. The channel capacity was obtained under both adaptive and non-adaptive secondary user power allocation conditions. The results had considerable potential for data transmission of unlicensed users with limited degradation of the licensed user’s data transmission efficiency. Also, while the effect of fading channels dependencies was ignorable at low correlation values, as the channels correlation increased, the channel capacity was significantly reduced.
Quansheng Guan et al. [22] worked to improve the network capacity of MANETs with cooperative communications and have proposed a Capacity-Optimized CO operative (COCO) topology control scheme that considers both upper layer network capacity and physical layer relay selection. A discrete stochastic approximation approach was presented to solve the topology control problem when only imperfect channel knowledge is available. Simulation results have shown that cooperative communication techniques have significant impacts on the network capacity, and COCO is an efficient algorithm and performs well in MANETs with cooperative communications
Yixuan Li, Qiuyu Peng, and Xinbing Wang [23] investigated the multicast capacity for static ad hoc networks with heterogeneous clusters. They studied the effect of heterogeneous cluster traffic (HCT) on the achievable capacity. HCT means cluster clients are more likely to appear near the cluster head instead of being uniformly distributed across the network. Such a property is commonly found in real networks. By adopting max-min fairness, the minimum among all individual multicast capacities of clusters can be maximized. Since the minimal individual multicast capacity will not be maximized and also there work focuses on deriving the upper bound of the minimum individual multicast capacity in HCT, that provides the best performance for the minimum multicast capacity to attain in the whole network. They also found that HCT have increased minimum capacity for ad hoc networks. Also, the multicast capacity achieving scheme was provided to justify the derived asymptotic upper bound for the minimum capacity.
Mai Vu, Vahid Tarokh [24] proposed a method instead of considering a homogeneous ad hoc wireless network, they studied a cognitive network consisting of two types of users: primary and cognitive. The secondary spectrum licensing necessitates the study of such networks. In these networks, the cognitive users can opportunistically access the now-exclusive but underutilized spectrum of the primary users, without degrading their performance. Other scenarios in the network was two different networks operate concurrently are also applicable.
Huanlai, Xing, Yuefeng Ji, Lin Bai, Yongmei Sun [25] investigated how to minimize the required coding resources in network-coding-based multicast scenarios. An evolutionary algorithm (MEQEA) was proposed to address the above problem. Based on quantum-inspired evolutionary algorithm (QEA), MEQEA introduces multi-granularity evolution mechanism that allows different chromosomes, at each generation, to have different rotation angle step values for update. MEQEA significantly improved its capability of exploration and exploitation, since the optimization performance was no longer overly dependent upon the single rotation angle step scheme shared by all chromosomes. MEQEA also presented an adaptive quantum mutation operation that was able to prevent local search efficiently. Simulations are carried out over a number of network topologies. The results showed that MEQEA outperforms other heuristic algorithms and was characterized by high success ratio, fast convergence, and excellent global-search capability.
Junchao Ma et al. [26] identified the contiguous link scheduling problem in WSNs, in which a sensor node starts up only once to receive all the data from its neighbors, and thus can reduce the energy consumption and time overhead in the state transitions. Especially, if the topology is a tree, each node can start up only twice in one scheduling period. They also propose centralized and distributed algorithms with theoretical performance bounds to the optimum in both homogeneous and heterogeneous networks. The simulation results corroborate the theoretical analysis, and showed that the efficiency of our algorithms in terms of total energy consumption, throughput, and time delay. The graph method will be used for scheduling in proposed method.
Sapna B Kulkarni, Dr. Yuvaraju B N [27] designed Node connectivity, Energy and Bandwidth Aware Clustering Routing Algorithm. An efficient ENB cluster head selection algorithm based on the combination of important matrices Residual Energy (E), Node connectivity (C) and Available Bandwidth (B) is considered for election of the cluster head efficiently. The multimedia stream splits into multiple sub streams prior to transmission using Top-N rule selection approach algorithm. Shortest path multicast tree construction algorithm to transmit the real time traffic effectively among the nodes in MANETS. Using the cluster head as group leaders and cluster members as leaf nodes, a shortest path multicast tree is established. With the help of constructed shortest path multicast tree we are proposing Node connectivity, Energy and Bandwidth Aware Clustering Routing Algorithm. Even though, the proposed system reduced the power consumption and delay, it has lacked in security and computational overhead is high.
Enhancing network capacity in multicast MANET using dynamic clustering and distributed scheduling
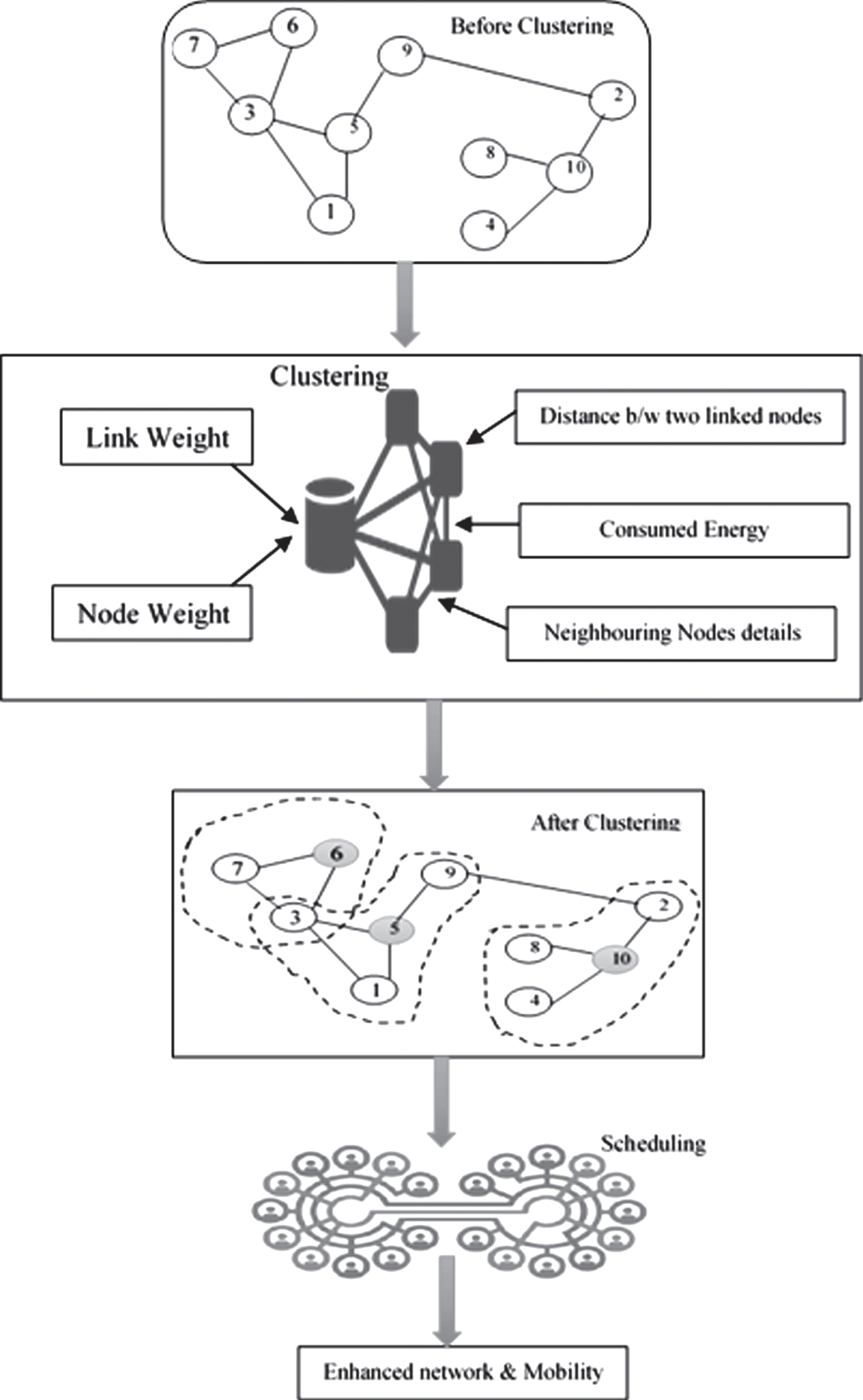
MANET is a very popular bandwidth-conserving technology. The main problem of multicasting in MANET is maintaining the mobility of nodes and infrastructure of network. In this work, we will concentrate on improving the capacity of the network by managing the infrastructure and mobility of node in multicast MANET. In MANET, nodes are usually dynamic in nature. In order to improve the capacity of MANET, we will maintain infrastructure of the network as well as the mobility of nodes. In this proposed section, we first present the system model consisting of a network model, then we formulate a dynamic clustering to maintain infrastructure of network and scheduling for transmission of data based on Distributed Scheduling to tackle the interferences in mobility of nodes. Dynamic clustering technique will be adopted to maintain infrastructure of nodes. The clustering technique will give an efficient topology management and also the lifetime of the network will be enhanced. After proper infrastructure maintenance, scheduling will do for transmission of data without interference of nodes by priority based Distributed Scheduling. The interference in the network will be reduced by this graph method. Therefore throughput will automatically improve and delay gets reduced in the proposed work. Ultimately the capacity of the multicast network will be enhanced.
The proposed approach encapsulates various tremendous tasks. Initially a network is formed by the nodes and the links can be represented by an undirected graph. Note that the cardinality of nodes remains the same but links always changes with the creation and deletion of links. So Clustering can be thought of as a solution for this problem. As the underlying graph does not show any regular structure, partitioning the graph optimally (i.e., with minimum number of partitions) with respect to certain parameters. The parameters utilized for employing clustering are Distance between two nodes, Details of neighboring nodes and Consumed Energy by nodes from the details gathered from parameters the Link weight and node weight should be estimated. After the estimation of the weights of nodes among multiple nodes and according to their weights a node is selected as the cluster head. By applying this method, node’s ability, amount of energy, and neighborhood contribution can be predicted in the best way. It also increases the accuracy of generated weights and selects the nodes with the best performance as the cluster heads. This method enhances the infrastructure of the network.
After the network enhancement the mobility of the nodes should be maintained. For this purpose a scheduling process should be employed to reduce interference so as to improve the throughput. The scheduling process is employed by utilizing distributed scheduling. The distributed scheduling works based on a priority based Distributed Scheduling. This process manages the transmission of data and rectify the problems occurred due to interference. Thus by employing this proposed approach enhancement of infrastructure as well as mobility of the nodes are performed.
Network model
Initial phase of the proposed system comprise of a network model. The network model is formed by the nodes and the links can be represented by an undirected graph UG = (N, L), where N represents the set of nodes n i and L represents the set of links l i . Note that the cardinality of N (|N|) remains the same but |L| always changes with the creation and deletion of links.Clustering can be thought of as a graph partitioning problem with some added constraints. As the underlying graph does not show any regular structure, partitioning the graph optimally (i.e., with minimum number of partitions) with respect to certain parameters becomes an NP-hard problem. The neighborhood τn i of a CH n i is the set of nodes which are directly linked to it and which are in fact the nodes lying within its transmission range (R n i ).
This defines the degree of the node n
i
:
where dist (n
i
, n
j
) is the measured average distance between n
i
and n
j
Similar to, when a system is initially brought up, every node broadcasts its id which is registered by all other nodes lying within its transmission range. It is assumed that a node receiving a broadcast from another node can estimate their mutual distance by measuring the ratio of receiving power and transmission power. The node degree of a node n
i
is deduced as the cardinality of the set τn
i
:
More formally, we are looking for the set of vertices S ⊆ N (UG), such that the union of τv i where v i ∈ S, forms V (G) The set S is called a dominating set such that every vertex of UG belongs to S or has a neighbor in S. To meet the requirements imposed by the wireless mobile nature, a clustering algorithm is required to partition the nodes of the network so that the following ad hoc clustering properties are satisfied: (a) Every ordinary node has at least one CH as neighbor; (b) Every ordinary node affiliates with the neighboring CH that has the smaller weight; and (c) no two CHs can be neighbors. Next, we propose models for our algorithm.
Weight-based clustering algorithm (WBC) determines a weight for each virtual link between nodes. Based on the initial weights, final weights are determined for the nodes. According to final weights, cluster heads are chosen and decide on members of their cluster. It is possible to acquire the final weight of every node based on neighbor nodes’ features by determining the weight of links, while with previous methods each node’s final weight was determined just by its own limited features. The WBC consists of two phases: building the clusters and maintaining the clusters.
Link neighborhood contribution
The first factor for determining virtual links is the link neighborhood contribution. A node is a nominee to be the cluster head (CH) when it has more neighbors. When a node has more neighbors and it becomes a cluster head, the number of exchanges and energy consumption reduce. To include this factor, the neighborhood contribution of a node is calculated. Each node sends a Hello Message to introduce itself to the neighbors. When all messages are sent, each node finds out its neighborhood degree “d” which shows the number of nodes available in each node’s transmission range |TR (n) |. The neighborhood degree (d n ) is given by
Then (3) is divided by the neighborhood degree (d
n
) to assign equal share of neighborhood contribution to each node. Thus, link’s neighborhood contribution percentage is calculated according to
Figure 1(a) shows the neighborhood contribution of N and L links.
Proposed Frame work.
The second factor is the energy consumption by links. A node with higher energy consumption fails faster. When a cluster head depicts its energy, it fails and also shatters the whole cluster and its links and entails lots of maintenance costs. On the other hand, cluster heads have the highest responsibilities among other nodes. Therefore, they need and consume the highest energy in network and are more likely to drain the energy. As a result, when choosing the clusters their remaining energy needs to be concerned. Taking this factor into account, the nodes with the highest residual energy and the least consumed energy among their neighbors are selected as the cluster heads. The factor (E
L
) is given by
Where E N and E A are, respectively, consumed energy of nodes N and A (Fig. 1(c)).
Here the distance between two nodes are estimated. Shorter the distance between two nodes is, the less the energy consumption for transferring information between them. Therefore, for consuming less energy, while transferring information, a node with a shorter distance with its neighbors should be selected as the cluster head. In fact a cluster head with closer distance from its neighbors requires less energy for transferring information which increases the cluster’s stability. Here nodes locate in a cluster with short distances are selected. The distance between a node and its neighbor through its virtual links is calculated in two ways: by receiving the nodes coordinate from GPS, by sending packets and calculating transfer time.
If GPS coordination is utilized, the distance D L is calculated
By
where (X
V
, X
A
) and (Y
V
, Y
A
) are coordination of nodes A and V, respectively. Since connection channels between nodes do not have same bandwidth and speed, the speed factor needs to be included in acquired distance by
The distance can be calculated by sending packets and measuring the transferring time. Initially, a small packet is sent from one node to other one. A timer is set at the sender node to measure the time duration. The destination sends back the packet once it is received from the origin. The timer is sopped at the origin once the packet is received by the origin. This time duration is called as the transfer time. Longer transferring time indicates longer distance between the two nodes. The very time could be considered as distance factor (D L ). In this method the problem with the first method, that is, channel’s speed, does not exist. The acquired D L is considered as factor 4 (Fig. 1(d)).
The links final weight (W
L
) is calculated when the mentioned factors (D
L
, E
L
and P
N
) are acquired. Equation (8) calculates the final weight as follows:
Where W
1, W
2 and W
3 are the weights of each factor and determine the effectiveness of the corresponding factor in the final result on the condition that
Weight determination for each node is shown in Fig. 2.
Ad Hoc Multicast Routing Protocol Utilizing Increasing ID Numbers.
In this phase considering the weight of each node’s link and load balancing factor, the final weight of nodes is determined by adding up each node’s link weight and dividing the result by its neighborhood contribution factor from (10) and (11):
The origin weight should be reversed
This factor guarantees the nodes to be distributed fairly among clusters. Without load balancing a cluster may have 2 members, while another has 20 members. In this case, clusters are instable because a cluster has a high load and its cluster head has to spend more energy. Load balancing factor is applied on each cluster head to support only a limited number of nodes and distribute the load fairly among multiple cluster heads. In order to apply load balancing, a criterion called δ is determined. The δ represents the optimal number of nodes required to maintain load balancing in a cluster. The difference between the node’s neighborhood contribution difference (d
N
) and a suitable neighborhood contribution criterion (δ) is Δ
N
:
A bigger Δ
N
shows a bigger difference between node’s neighborhood contributions in an ideal situation. Therefore, the node’s final value is smaller. Finally, each node’s final weight (C
N
) is calculated by applying the load factor according to
After determining each node’s weight value, nodes send their values to their neighbors. Consequently, all nodes know their neighbors and their own values. Among its neighbors candidates recognizes itself and a node with the highest value is stipulated as cluster head. Candidates are collected and make a domain set. Member nodes in a domain set send messages to their neighbors and introduce themselves as the cluster heads. In this case one of three different situations occurs for nonmember nodes of a domain set: Nonmember nodes of a domain set receive introducing messages from a cluster head. In this case, the node joins the origin cluster. Nonmember nodes of a domain set introduce messages from a cluster head. In this case, the free nodes join a cluster head with highest value and introduce themselves to the cluster head as the gateway. Nonmember nodes of a domain set receive no message. In this case, a node with the highest value is chosen as the cluster head and others are the members.
Clusters maintenance phase
This phase starts immediately after creation of the first cluster. This phase is activated when one of the following problems occurs. WBC algorithm has a solution for each problem. A node leaves its cluster range: In this case, the node needs to join a new cluster. The node that leave the cluster sends a message to cluster heads in its transmission range. When a cluster head is ready to accept the node, it sends back a message and declares its value. By comparing received values from multiple clusters (if any), the node joins a cluster with the highest value. Cluster head fails as a result of discharged battery: In this case, two actions are possible: (a) nodes join the other cluster heads through the process explained in part 1; (b) choosing a new cluster head among survived nodes and inviting other nodes to the new cluster. Member nodes fail as a result of discharged batteries: In this case, the cluster head removes dead nodes from its members list. Then, it sends messages to member nodes and checks for their effectiveness and other changed features. If no message is received back from a node, the node is either dead or out of cluster’s range. Therefore, the node is removed from the cluster’s members list. Cluster heads interfere: In this case, values of two interfered cluster heads are compared and the one with higher value is chosen as the cluster head. Then, the nodes of the lower valued cluster head join the new cluster. Among nodes which are not members of the new cluster head will be chosen based on their values and others will join it.
Distributed scheduling algorithms
As wireless sensor networks are self-organized and distributed, centralized algorithms could not be used without a predefined leader. Therefore, it is necessary to design efficient and scalable distributed algorithms. In this phase, two distributed algorithms, distributed scheduling and distributed scheduling with efficient delay is proposed.
Distributed scheduling
In the distributed scheduling, we use a random order rather than a global decreasing order of the weights, and we assume that there is a contention-based MAC (e.g., B-MAC) available for a node to compete for the channel and to obtain an interference-free contiguous link scheduling. The distributed scheduling is simple and efficient so that each sensor node can run the scheduling with less computation. The distributed scheduling is shown in Algorithm 1.
Input: A communication graph UG = (N, L).
Output: A valid contiguous link scheduling.
1: while a valid contiguous link scheduling is not obtained do
2: Each node v i that is not yet scheduled monitors and competes for the channel.
3: if node v i obtains the channel then
4: v i assigns the smallest w i consecutive time slots sequentially to its incident links which do not interfere with the links that have already been scheduled. Suppose link l j,i incident to v i is assigned time slot t j .
5: v i broadcasts the assignment information to the nodes that are in the interference range of v i , and these nodes could not transmit in the v i time slots due to the interferences.
6: Each node v j adjacent to v i broadcasts the assign-ment information to the nodes that are in the interference range of v i , and these nodes could not receive in time slot t j due to the interferences.
7: else
8: v i waits for a random time.
In the distributed scheduling algorithm, a node v i first competes to obtain the channel, then assigns the smallest consecutive time slots for its incident links without interferences using the first-fit heuristic same as the centralized scheduling. After that,v i and its neighbors should notify the nodes in their interference ranges the time slots they could not use. For node v i , it broadcasts the assignment information to the nodes that are in the interference range of v i , and these nodes could not transmit in these w i time slots because their transmissions will interfere v i ’s packet reception in these w i time slots. For each link l j,i incident to v i , time slot t j is assigned. Node v i then broadcasts the assignment information to the nodes that are in its interference range, and these nodes could not use time slot t j to receive packets because their packet receiving will be interfered by v i ’s packet transmitting in time slot t j .
Distributed scheduling with efficient delay
In the TDMA sleep scheduling, a node stays in the sleep state for most time, and periodically starts up to check for activity. As a forwarding node has to wait until its next-hop neighbor starts up and is ready to receive, the message delivery delay will increase. When packets are forwarded from an incoming link to an outgoing link, they could only be forwarded to the outgoing link in the next period T if the incoming link is scheduled to be active after the outgoing link. This kind of delay will accumulate at every hop in the network, which may lead to a long latency. A sample network is illustrated in Fig. 5a. As a line topology, the data is transmitted from v 5 to v 1 along the line. If links e 1, e 2, e 3, e 4 are assigned time slots t 1, t 2, t 3, t 4 respectively (Schedule 1), the time delay for a packet transmission from v 5 to v 1 is almost 3T, as shown in Fig. 5b. However, if links e 1, e 2, e 3, e 4 are assigned time slots t 4, t 3, t 2, t 1 respectively (Schedule 2), v 5 could transmit the data to v 1 in one period T. In order to reduce this delay, we schedule the links from bottom to top, that is, a node with a higher depth should be scheduled earlier. Hence, a node v i can only be scheduled until all the children nodes of v i are already scheduled. The algorithm is described in Algorithm 2.
(Distributed-delay)
Input: A communication graph G = (V, E).
Output: A valid contiguous link scheduling.
1: while a valid contiguous link scheduling is not obtained do
2: Each node v i that is not yet scheduled monitors and competes for the channel if all the children nodes of v i are already scheduled.
3: if node v i obtains the channel then
4: v i assigns the smallest w i consecutive time slots sequentially to its incident links which do not interfere with the links that have already been scheduled. Suppose link l j,i incident to v i is assigned time slot t j .
5: v i broadcasts the assignment information to the nodes that are in the interference range of v i , and these nodes could not transmit in the w time slots due to the interferences.
6: Each node v i adjacent to v i broadcasts the assignment information to the nodes that are in the interference range of v j , and these nodes could not receive in time slot t j due to the interferences.
7: else
8: v i waits for a random time.
From the above algorithm the scheduling problems in the network during data transmission are rectified.
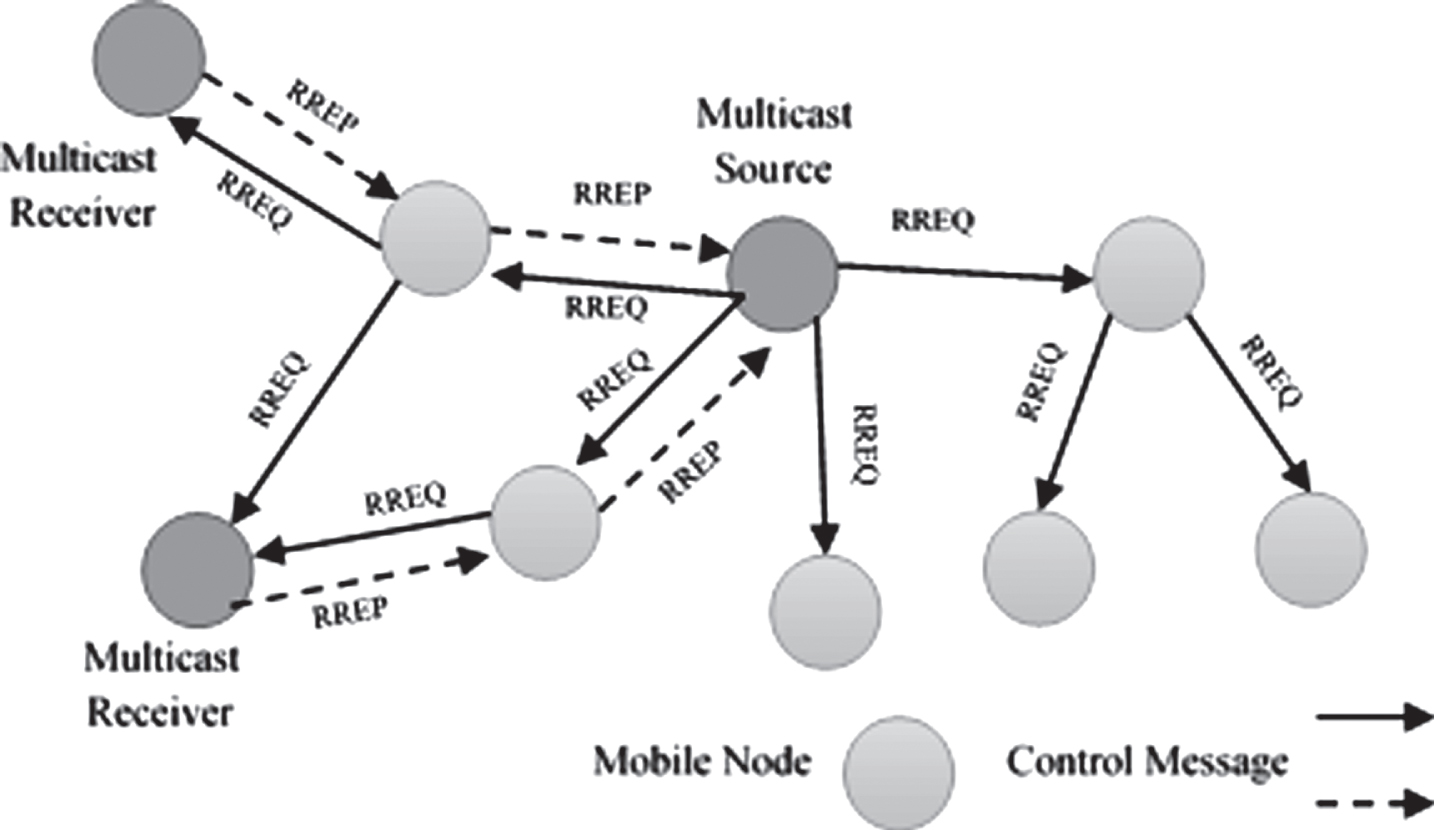
Ad Hoc Multicast Routing Protocol Utilizing Increasing Id Numbers (AMRIN)
AMRIN is an on-demand protocol that constructs a shared multicast delivery tree (Fig. 2) to support multiple senders and receivers in a multicast session. AMRIN dynamically assigns an ID number to each node during each multicast session. Based on that ID number, a multicast delivery tree rooted at a special node with Smallest-ID (Sid) is originated, and the ID number escalate as the tree expands from the Sid. Generally, Sid is the source or the node that initiates a multicast session.
The first step in AMRIN protocol operation is the selection of Sid. If there is only one sender for a group, the Sid is generally the source of the group. In case of multiple senders, a Sid is selected among the given set of senders. Once a Sid is recognized, it sends a NEW-SESSION message to its neighbors. The contents of this message holds Sid’s multicast session member ID (msm-id) and the routing metrics. Nodes getting the NEW-SESSION message generate their own msm-ids, which are higher than the msm-id of the sender. If a node receives multiple NEW-SESSION messages from different nodes, it keeps the message with the superlative routing metrics and calculates its msm-ids. To join an ongoing session, a node evaluate the NEW-SESSION message, determines a parent with the smallest msm-id, and unicasts a JOIN-REQ to its potential parent node. If that parent node is already in the multicast delivery tree, it responds with a JOIN-ACK. Otherwise, the parent itself tries to join the multicast tree by sending a JOIN-REQ to its parent.
If a node is unable to observe any potential parent node, it executes a branch reconstruction (BR) process to rejoin the tree. BR consists of two subroutines. BR1 should be carried out when a node has a potential parent node for a group (as discussed above). If it does not realize any potential parent node, BR2 is executed. In BR2, instead of sending a unicast JOIN_REQ to a potential parent node, the node broadcasts a JOIN-REQ that comprises of a range field R to specify the nodes till R hops. Upon link breakage, the node with the prominent msm-id tries to rejoin the tree by executing any of the BR mechanisms. AMRIN detects link disconnection by a beaconing mechanism. Hence, until the tree is reconstructed, packets could possibly be dropped.
Result
For a better comprehension of our algorithm, we take an example where the topology is arbitrary and the network is composed of 30 nodes. A node can hear broadcast beacons from the nodes which are within its transmission range. The proposed work demonstrate the proposed algorithm with the help of Fig. 3. An edge between two nodes in Fig. 3 signifies that the nodes are direct neighbors of each other.
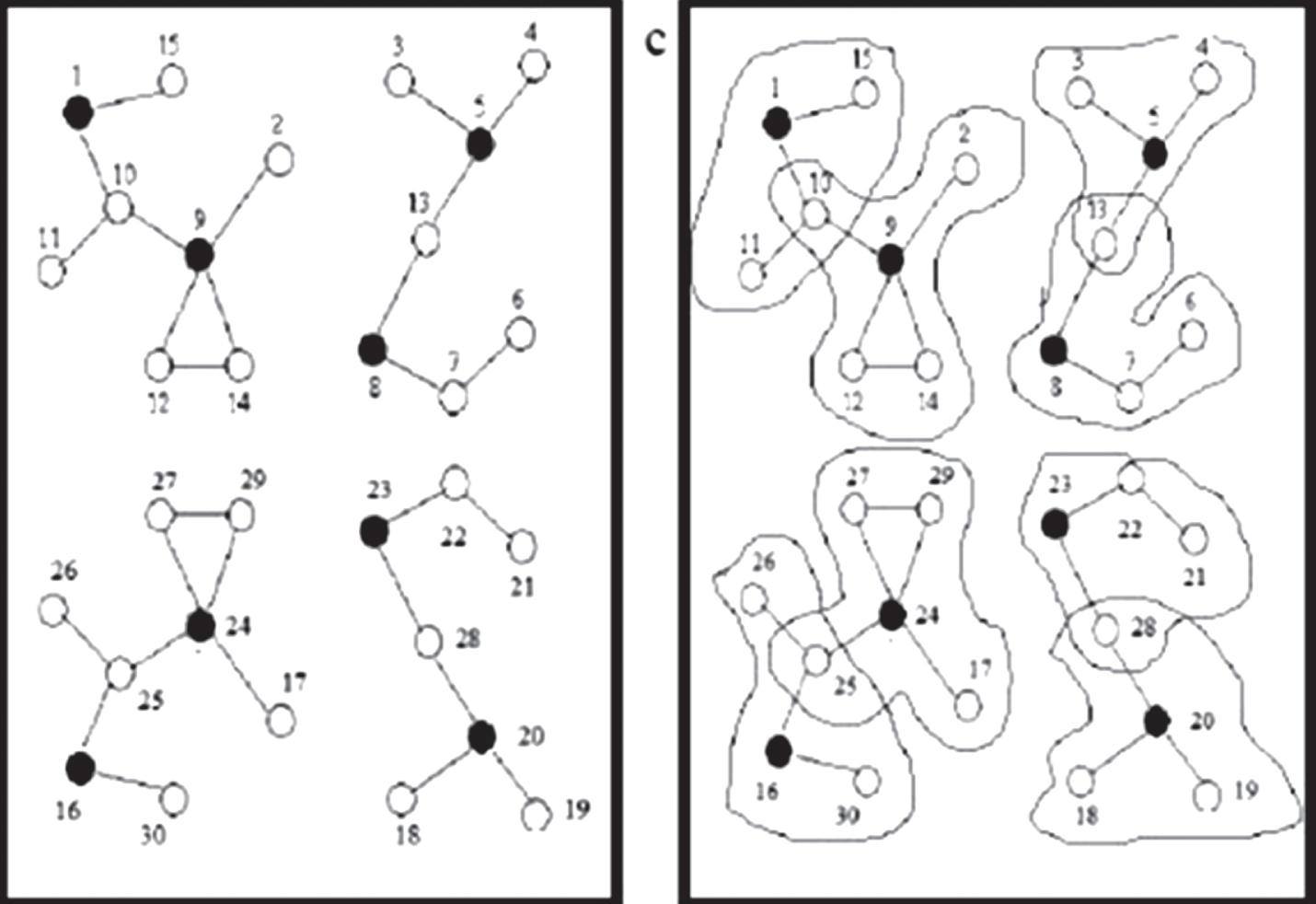
Clustering of nodes.
After computing the weights of each node. The cluster heads are appointed according to the weight each clusters are represented under a cluster head. This clustering of nodes is shown in Fig. 3
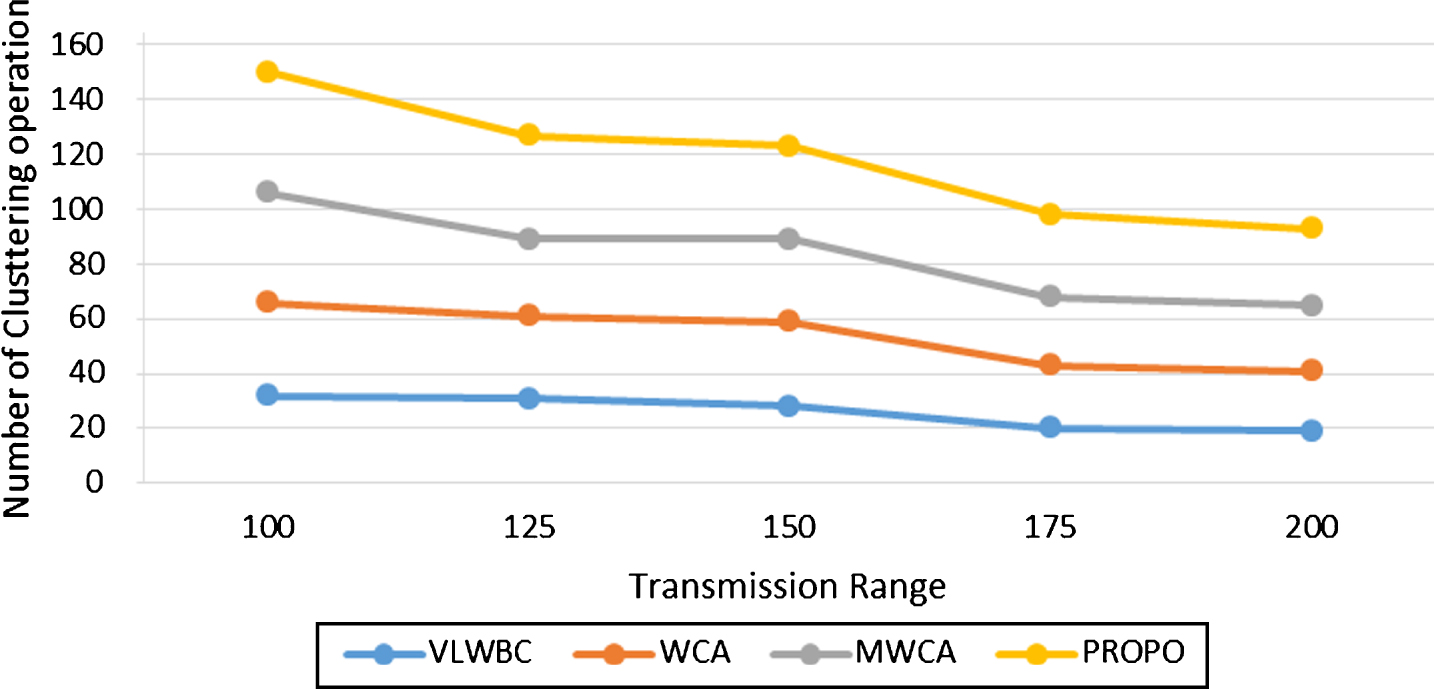
First, the clusters’ life time which indicates their stability is calculated. Then, the consumed energy of the network’s nodes is investigated and at the end the number of clustering and re clustering operations is evaluated in Table 1. Finally, the effectiveness of the algorithm and the stability of produced clusters are compared to other algorithms. All factors have been investigated based on transmission rate variation. Increasing the nodes’ transmission range increases the number of neighbors. Therefore, each node is able to cover a larger range. As the number of nodes is important in choosing cluster heads, any change in transmission range will affect the other factors.
Number of clustering with different range
Consumed energy by the node for transferring information during a specific time period is called network’s consumed energy. The lower the amount of consumed energy in the nodes, the longer the lifetime of the nodes and the more stable the clusters. This value is expressed in term of m j . Table 2 shows features of simulation. Consumed energy is calculated based on variation of transmission range. Figure 4 is a diagram obtained from these experiments. It is obvious from Fig. 5 that a lower energy has been consumed in VLWBC algorithm compared to the other algorithms. At starting point WCA algorithm shows a good performance in Fig. 6, but as the transmission range increases, it leads to a lower performance. The reason is that the energy consumption by the nodes has direct effect on determining the node’s weight in the proposed algorithm. Furthermore, the cluster heads and their member nodes are chosen with optimal distance. Therefore, they can transfer information with minimal energy dissipation. Since load balancing factor has not been applied in MWCA algorithm, the number of members of the cluster heads is not fair and there is no balance in the distribution of nodes among the cluster heads. Consequently, the energy consumption is high in MWCA algorithm. Table 2 shows a comparison in two areas of the graph and the difference of consumed energy.
Number of Clustering with different Range.
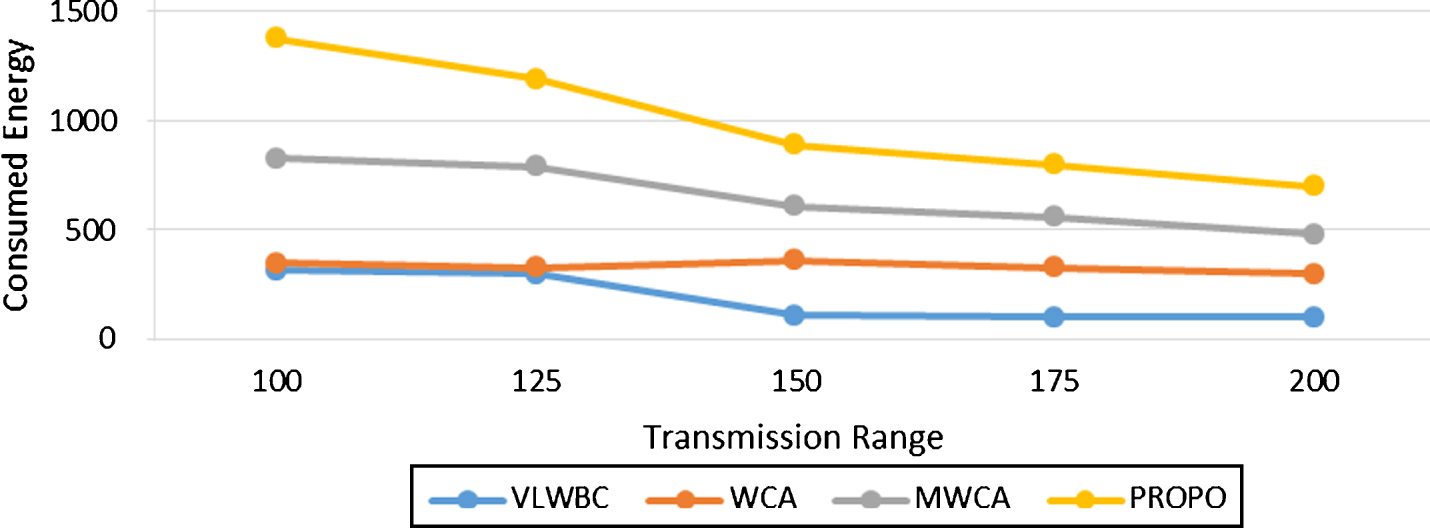
Consumed Energy with increase in Transmission Rate.

Transmission range ratio.
Consumed energy with increase in transmission rate
In Table 3, for the heterogeneous networks, we randomly deploy 300 nodes in a square area of 100 m _ 100 m, and we vary the transmission range ratio of the maximal transmission range to the minimal transmission range,
From the results shown in the above figures, it can be distinguished that from the various existing algorithms the proposed method execute significantly by providing magnificently by managing the network and mobility of the nodes.
Transmission range ratio
Data delivery rate
Average delivery latency
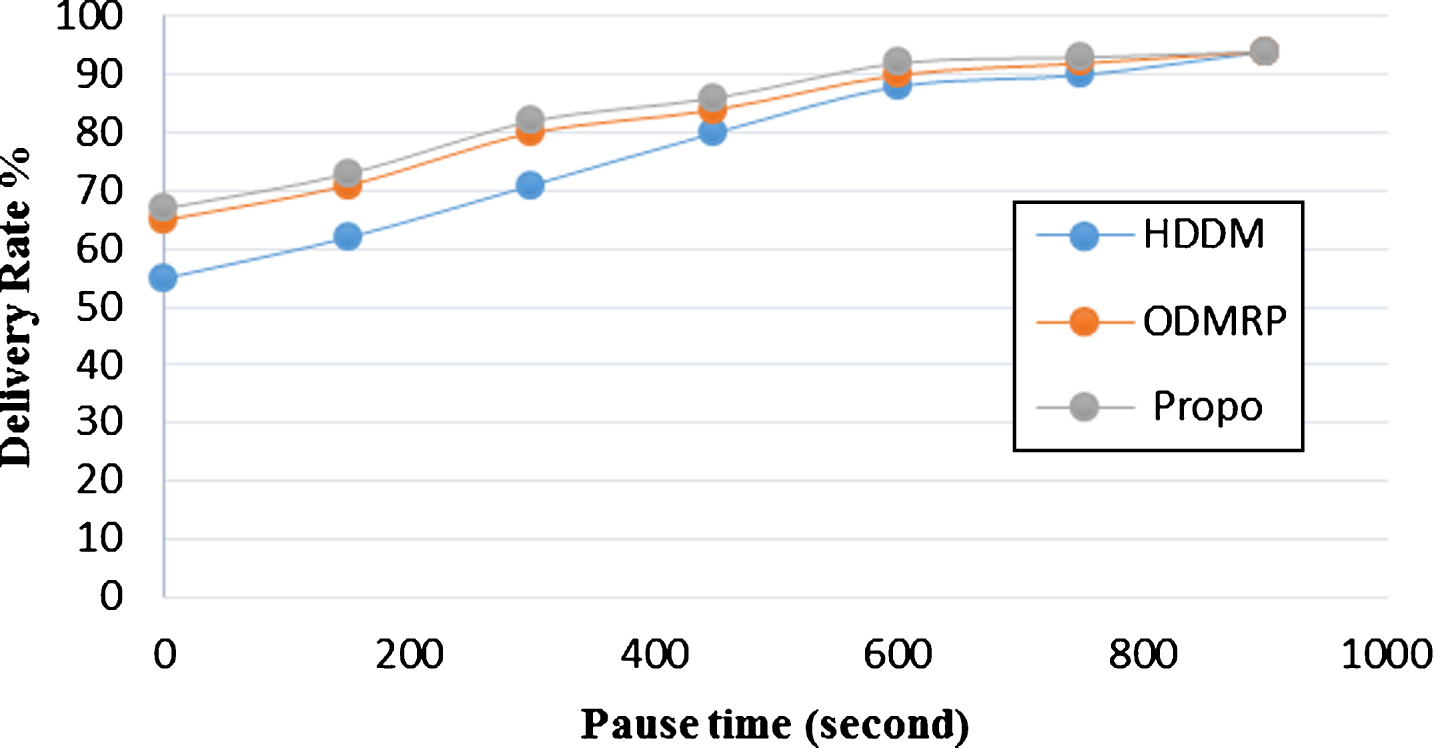
Data Delivery Rate.
In the following simulations, the network field size is 2500 m×2500m, containing 400 mobile nodes. All the nodes follow the random waypoint mobility model with speed range of 1 m/s to 20 m/s. We vary the mobility with different pause times as 0, 60, 120,…, 420, 600, and 900 seconds. To avoid the initial unstable phenomenon in random waypoint model, we let the nodes move for 3600 seconds before starting any network traffic, which lasts for 900 simulation seconds in each simulation run. For the multicast traffic, the source of multicast session generates packets at a constant rate of 2 packets per second. Each packet is 512bytes.
We are particularly interested in the scalability of the protocols. The following metrics are used for comparing protocol performances. Data Delivery Rate: Percentage of data packets delivered to the receivers. Average Delivery Latency: Packet delivery latency averaged over all packets delivered to all receivers.
In this simulation, we choose to implement the DDM protocol, based on hierarchical multicast schemes are also implemented. One is the hierarchical DDM multicast which is named as HDDM, the other one is ODMRP. For fairness of comparison, AMRIN is used as the underlying unicast protocol for both hierarchical DDM protocol and ODMRP. In HDDM protocol, the minimum and maximum allowed size of each sub-group are 9 and 20, respectively. For performance references, we also run simulation with a mesh based protocol, ODMRP.
Figure 8 shows the results for average delivery latency and the variance among the groups in the network. This measure supports the situation when the Data Delivery ratio is small. For this situation, the significant phase of packets which are delivered is the distance between the source node and destination node. If those packets travel the shortest distance of hop, then the latency for packet delivery will be small. When there are more number of multicast groups, the average delivery latency is expanded in both of the HDDM and ODMRP protocols while compared to AMRIN protocol. On account of modest number of expansive classes, Topology-Aware Partition Method is apt for making each and every smaller groups just comprise the neighboring mobile nodes. In the case of more number of smaller groups, the members of a sub-group become more widely spread in the network. This outcomes in additional hops for the process of delivering packets at the Low-level Multicast classes and so the delay for packet delivery is increased. The proposed frame work derives the following conclusions. When there are more multicast groups in the network, AMRIN has quick drop in all performance metrics. When there are more groups, dynamic partitioning becomes less effective. Thus the improved performance of the AMRIN is verified.
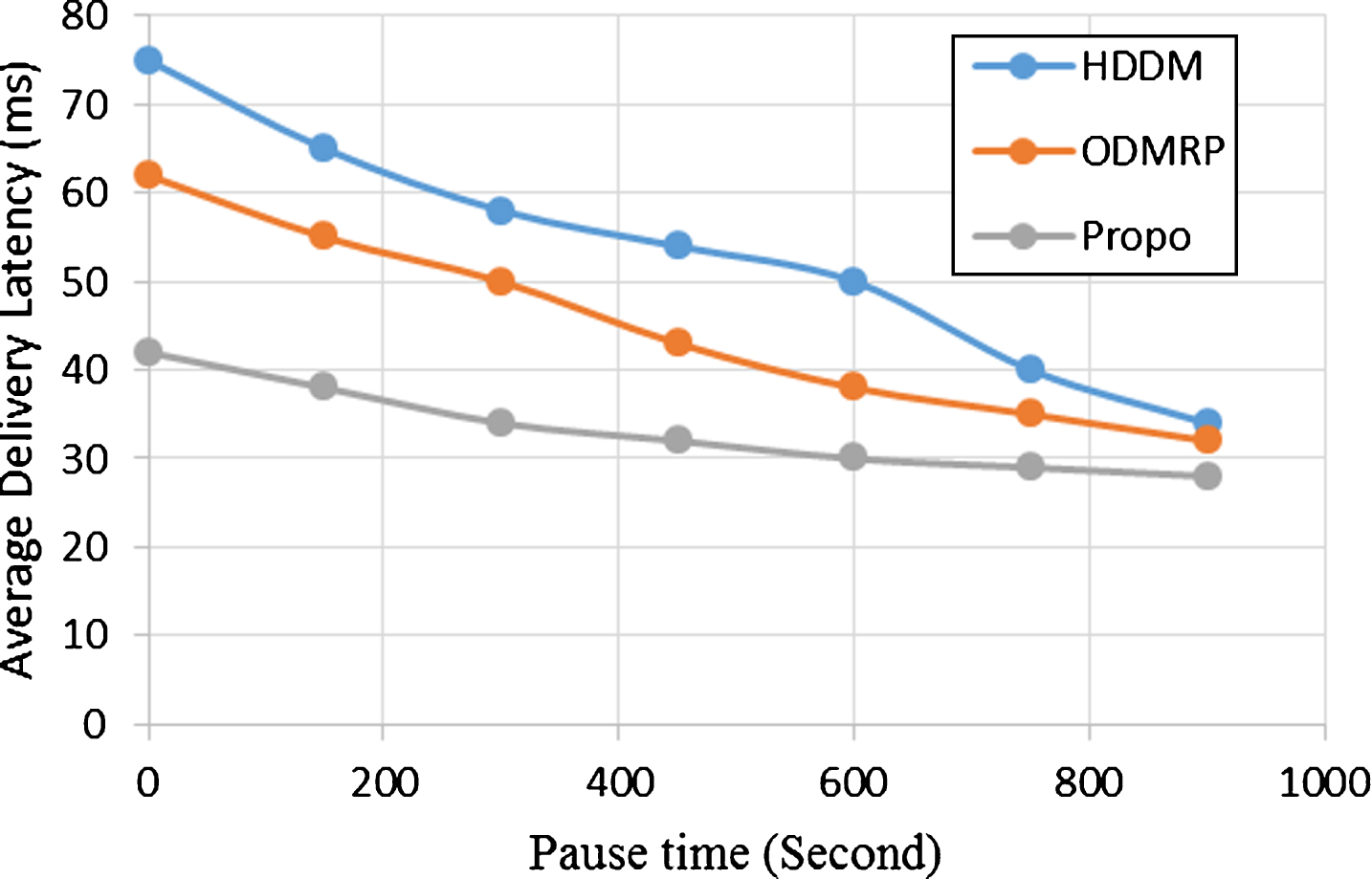
Average Delivery Latency.
We have considered the problem of constructing a framework for dynamically organizing mobile nodes in mobile ad-hoc networks into clusters where it is necessary to provide robustness in the face of topological changes caused by node motion, node failure and node insertion/removal. By derived the proposed model, which were thereafter combined to get profit of their benefits. WBC algorithm has been proposed for clustering MANETs. The virtual links weight for every node is calculated based on weight of links and nodes. By this proposed WBC network stability improved. Sequentially by employing scheduling using Distributed Scheduling method mange the transmission of data without interference. The performance evaluation in multicasting reveals the improved data transmission rate by proposed work. Thus by employing this proposed approach the bandwidth conserving should be achieved. WBC and Distributed scheduling had the higher availability in comparison with other methods and continued to function with a high probability when some components are not available.