
Abstract
In recent years, action recognition techniques have played an increasingly important role in autonomous systems. However, the computational costs and precision of action recognition algorithms are still major challenges. Recently, a deep learning approach was proposed to obtain a higher accuracy, but large and deep neural networks have high computational costs. This paper presents a new approach that allows for a significant reduction in computational time while slightly increasing the accuracy. The contribution consists of two parts: a scalable feature extraction method (SFE) and a hybrid model of different classifiers. First, the SFE method is proposed for application to histogram orientation-based feature descriptors, such as the histogram of orientated gradient (HOG), histogram of optical flow (HOF), and the motion boundary histogram (MBH). An advantage of SFE is its ability to quickly compute features. Scalable feature extraction enables accurate approximation of features extracted from traditional image pyramids by efficiently using only the original image. Our method is inspired by a special data structure used for storing basic information of optical flow and image gradients, which are computed from the original image and then used to extract features across multiple scales of the feature region without recomputing the image gradients and optical flow. Second, we focus on a hybrid classification method based on a linear support vector machine (SVM) and hidden conditional random field (HCRF) model that improves the recognition precision. This effort shows that a combination of SVM and HCRF models provides a better accuracy than the traditional approaches. Experimental results illustrate that the proposed approach allows for both a significant reduction in computational time and an improved accuracy.
Introduction
In recent years, active recognition algorithms using vision sensors have played a key role in a variety of applications in modern systems. These important applications include autonomous systems related to robotics, automatic personal assistance, and intelligent transportation [9 , 28]. An action recognition task aims to identify several kinds of human or animal actions in various specific contexts [3, 8]. In principle, an action recognition task focuses on identifying one or more necessary human actions, rather than taking into account all activities. There are various challenges in predicting and recognizing representative behaviors, such as variety of possible activities, diverse fields of view, apparent difference, complex backgrounds, as well as occlusion. The challenge of autonomous action recognition is highlighted by the fact that even humans sometimes have trouble discerning differences in similar actions.
In several recent years, several contributions to autonomous action recognition have been proposed to address these challenges, such as [18, 29]. Some survey reports on the state of art of action recognition techniques were discussed and presented in the document [7, 32]. The literature briefly evaluated a few advanced methods successfully applied in action recognition systems. The advantages and limitations of methodologies were also pointed out. Besides that, some standard datasets are available online as benchmark data for competition, which were analyzed and evaluated, such as HMDB51 [13], OlympicSports [16], UCF50 and UCF101 [19]. Most of these datasets use RGB (Red, Green, Blue) color information, which provides a rich texture for feature extraction. In recent years, the use of local feature descriptors has attracted many researchers, such as [7 , 32]. Wang et al. [25] presented a method for transforming gradient-based features into spatiotemporal concatenations, using a Gaussian convolution to extract spatial location features, which improved the precision of the system relative to earlier works. The authors [18] proposed the use of an integrating technique to reject superfluous trajectories, that resulted from the camera motion, while still maintaining the effectiveness of the action prediction results. Some other groups focus on global feature descriptors [22]. The authors [22] investigated a hybrid classification model using a Support Vector Machine (SVM) and k-NN (k-Nearest Neighbor) algorithm utilizing the human silhouette and grids to construct the model of feature vectors. A method based on a graph model [30] was proposed for multiple learning instances. The authors used a graph to present the local information, which make it faster than previous subspace learning methods with added computational complexity.
In contrast, some research groups focused on a RGBD (Red, Green, Blue, Depth) database for action recognition, such as [12, 31]. They presented methods using a low- rank of tensor for automatic learning of subspace dimensions. Another research investigated a method to recognize actions using RGBD videos for improving the accuracy based on a discriminative relational feature learning method that discards homogeneous pieces in RGB images and utilizing depth information for classifying [12]. Various advantages and limitations of action recognition method using sequential RGBD images were analyzed and presented in document [31]. A new approach based on a combination of color and depth information was investigated, and found to result in an acceptable accuracy, even though it was computationally expensive. One of the fundamental approaches for improving the accuracy and adapting to different object sizes is to processes on multiple scales of the image, called image pyramids.
However, this task is computationally expensive because the feature information must be recomputed at every level of the image pyramids. For example, for histogram of orientated gradient (HOG) feature extraction, the gradient of image intensities and the histogram of oriented gradients of cells/blocks must be recomputed at each image scale. This paper proposes a novel approach to deal with this problem, which can be successfully applied using various feature extraction techniques, including the use of HOG, the histogram of optical flow (HOF), and the motion boundary histogram (MBH). Furthermore, a hybrid of classification and inference techniques is proposed for additional improvement of efficient action recognition systems.
Overview architecture
A typical action recognition system consists of several major tasks, as indicated in Fig. 1. In this architecture, we focus on improving feature extraction task and on the fusion of two layers of machines for classifying and inferring the transpired actions. In the feature processing task, we propose a fast method based on the ideal of features extracted from image pyramids, which can be accurately and efficiently approximated using the original image, which called the SFE method. This method is improved by the use of special data structures, which take advantage of the “integral image” method to reduce computational time of feature extraction. It is particularly noteworthy that our approach can be successfully applied to not only extract HOG descriptors but the HOF and MBH descriptors as well. The details of this approach are presented in the next section.
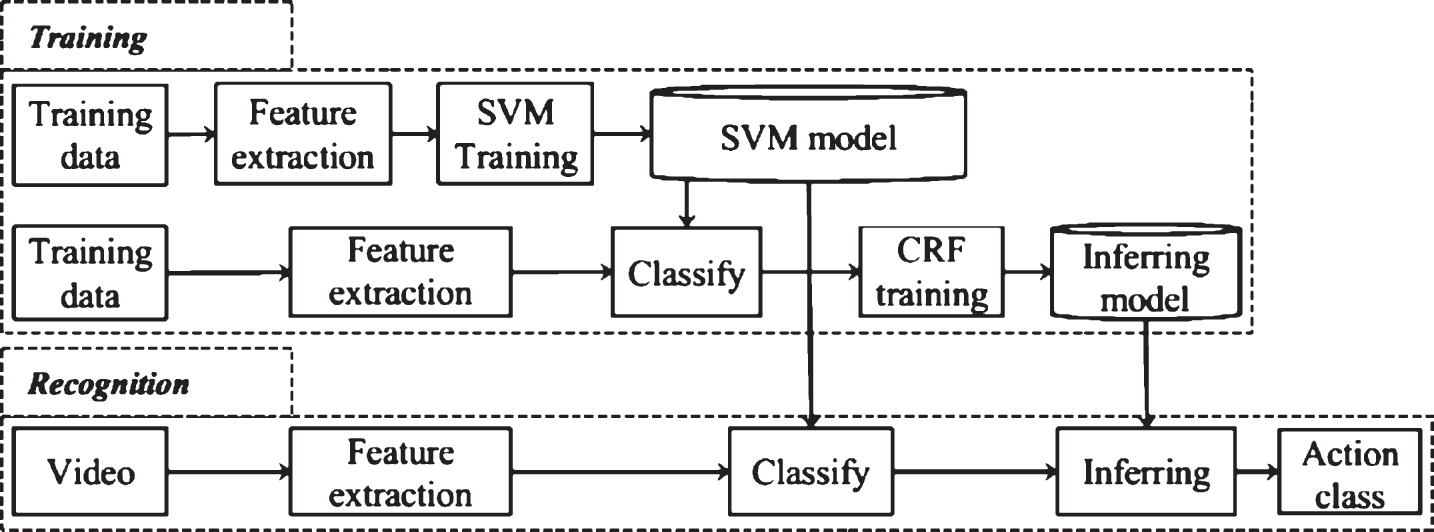
Overview of the architecture of action recognition processing.
On the other hand, there are many similar activities, which confuse clarifying engines, such as walking, jogging, running and so on. To deal with this difficulty, we proposed a hybrid recognition system based on a combination of SVM- based classification and the HCRF- based inference techniques. The SVM technique is applied to classify action classes using spatiotemporal features within a period of k frames. The final decision of the action is inferred using the HCRF technique. The proposed approach based on a hybrid recognition with SFE method results in a significant improvement of the accuracy rate and reducing feature processing time.
This section presents a novel method for the fast extraction of local features. In the following subsections, we demonstrate that HOG extraction using image pyramids can be accurately approximated by more efficiently using multiple scales of the HOG from only the original image. Then, we extended this approach to other feature descriptors based on histograms, which include the HOF and MBH descriptors.
Invariant HOG features from multiple-scale image
When applying the HOG technique to multiple image scales, instead of directly computing features from image pyramids, the features are extracted within multiple regions of different scale. This process is illustrated in Fig. 2. Fig. 2(a) presents the traditional approach of extracting features from multiple resolutions of an image, known as image pyramids. Fig. 2(b) presents the proposed approach to compute features, which uses only the original image resolution but with multiple region sizes, known as feature pyramids.
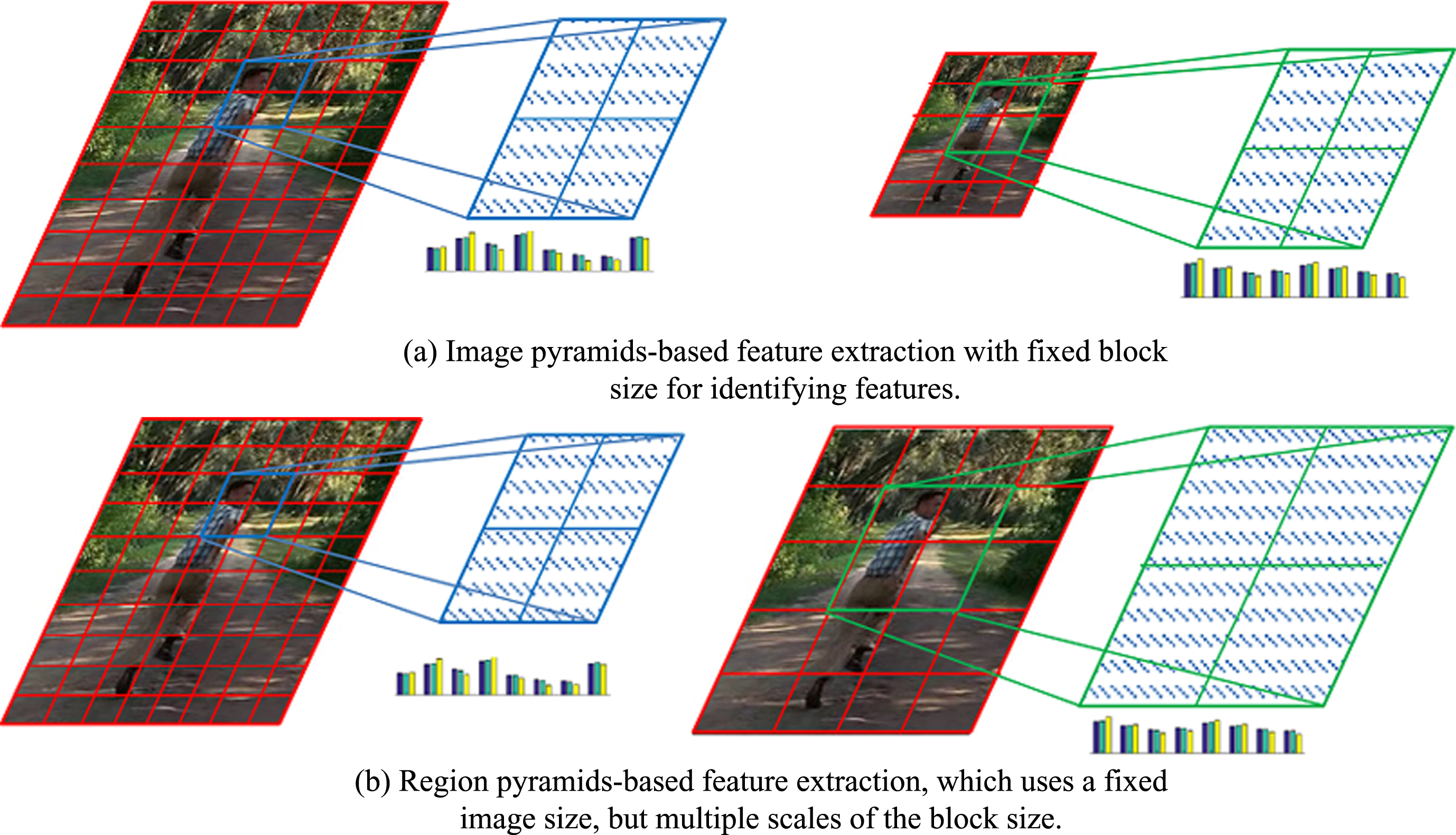
The two approaches for HOG feature extraction.
Our approach eliminates many redundant tasks inherent in the traditional methods, which must repeatedly process image pyramids of different resolution. An advantage of the new approach is that it avoids reprocessing intensity-based gradients and accumulating the gradient orientation at each scale level. Herein, we demonstrate that the gradient histogram- based features are almost invariant when resizing the image both in theory and practice.
First, a relationship of the features in image pyramids is explored by analyzing the gradient change when an image is resized to an upscaled or downscaled version. Obviously, a resizing task simply results in scaling an image at different resolution while the major contents and structures of the image are largely preserved. In a scaled image, the contents are interpolated their neighboring pixels, e.g. via nearest neighbor interpolation. Therefore, there is a relationship between the gradient of the original and resized images.
The gradient is given as ▽f = [g
x
, g
y
]
T
= [∂f/∂x, ∂f/∂y]
T
, where g
x
and g
y
are gradient components on the x and y axes, respectively. The gradients at a position (x, y) are
There are two operations which are typically preformed on image pyramids upscaling to a higher resolution and downscaling to a lower resolution of the image. The gradient transformation is inversely proportional to the scale ratio. The changing ratio of gradients in the original image is faster than that of the upscaled image while the gradient direction is almost exactly maintained. This fact can be proven by the following argument. Given that I
s
is a scaled image of I, with the resizing factor λ, then I (i, j) ∼ I
s
(λi, λj). The relationship of the derivative along the horizontal axis is expressed by
This research studied on how the scaling of the image affects the HOG, with the use of a weighted factor based on orientation voting. This means that each histogram bin is voted on with a score ranging from [0, 1] based on the bin directions instead of the gradient magnitude. Consequently, due to the relationship O s (λi, λj) = O (i, j), the histogram weighting is expressed by W s (λi, λj) = W (i, j). The sum of the oriented gradient from the original image within a region (h, w) and the one from scaled image within a region (λh, λw) is expressed as follows:
Therefore, the HOG within a region (λh, λw) from the scaled image can be approximated by the HOG within a region (h, w) from the original image as
The changing height to width ratio of the HOG converges to λ
2 for each bin of the HOG. Finally, the normal of the HOG is presented by
The above arguments show that the HOG from a scaled image can be approximated by the HOG computed from the original image. Ideally, the HOG distributions following this scaling criterion and their normalizations are invariant in scaled images. In practice, the gradient values changed slightly with the scaling transformation. The results show that the quality of image content is reduced when resizing an image due to the discrete interpolation of image intensities. Therefore, the image resizing process adversely affects the precision of recognition systems, experimental results illustrated in Fig. 10.
To prove that the HOGs from scaled images can be approximated by the HOG from the original image, we evaluated how the image scale relates to HOG distributions. For this task, videos of UCF101 actions were used to extract HOG features from the original frames, using both downscaled images (λ = 0.5), and upscaled image (λ = 2). Fig. 3(a) shows the probability density function (PDF) of HOG difference between scale image and original sample with the downscale and upscale factors are 0.25 and 4, respectively. The experimental results shown the difference of oriented histogram values in Fig. 3(a) with (mean μ ≈ 4.071, and standard deviation σ ≈ 0.049) and (μ ≈ 0.235, σ ≈ 0.006) for downscaling and upscaling, respectively. The normal feature vectors are converged to the ideal values with the standard deviations σ both equaling about 0.002. The HOG differences using the normal feature vectors converged to the expected value of 1 with variances approximately equal to zero. Thusly, the distribution of HOG features on the original image and that one on image pyramids with the same size ration are quite similar.
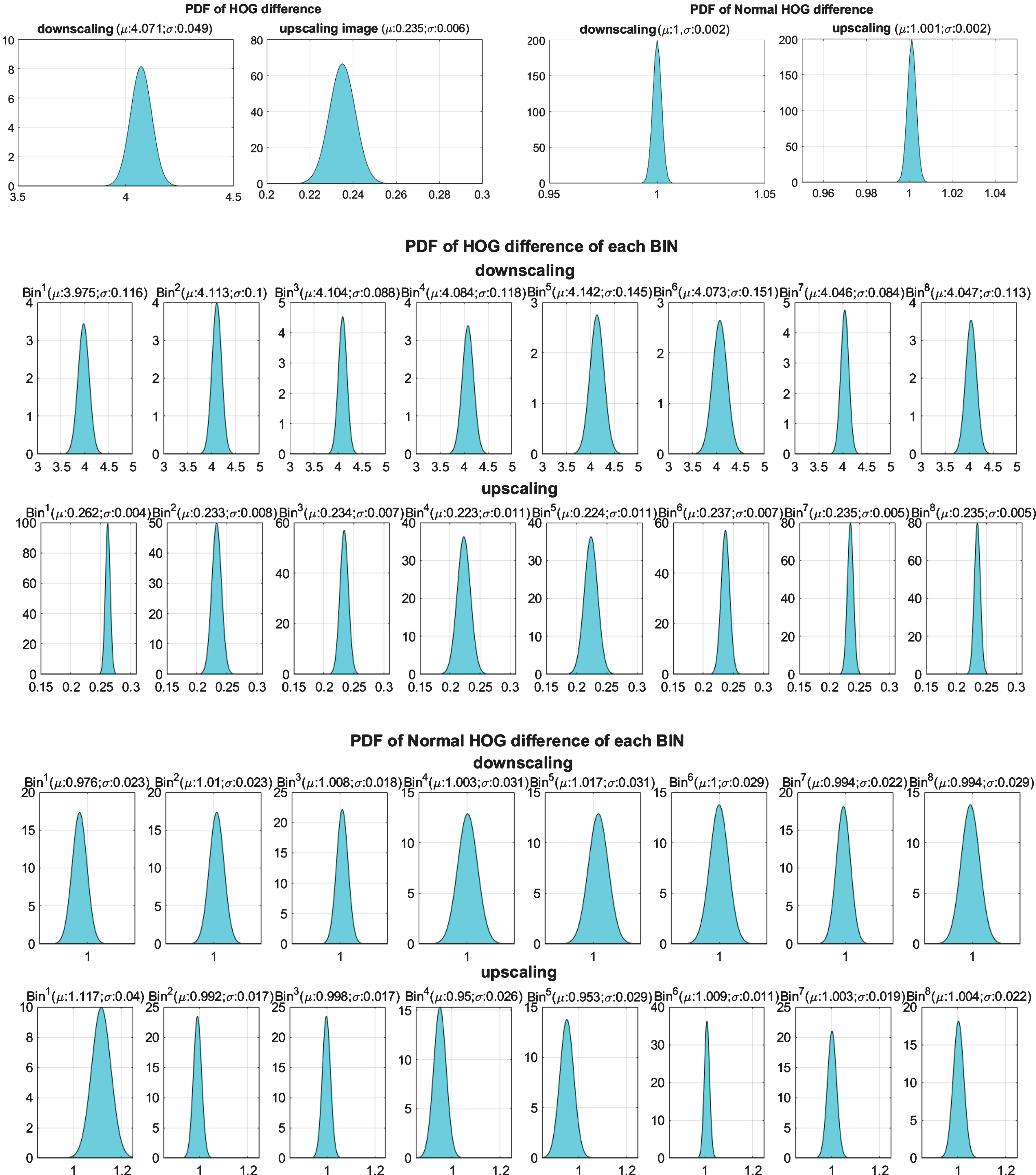
Distribution of changing ratio of HOG feature when downscale and upscale image.
Similarly, we also analyzed the distributions of each bin relating to the scaled changing ratio. The practical results in Fig. 3(b) show that the approximated value converged to the ideal value with μ ≈ 1 and a σ 2 < 0.001. Fig. 4(a) shows the quantitative results for the approximated features on the original images to the downscaled and upscaled image, with scaling factors λ of 0.5 and 2. The practical results also show that the HOGs of the downscaled images and the original images are more accurate than the ones for upscaled images. The experimental result shows that the approximated histogram based on the [0, 1] weight is superior to that one using the gradient magnitudes.
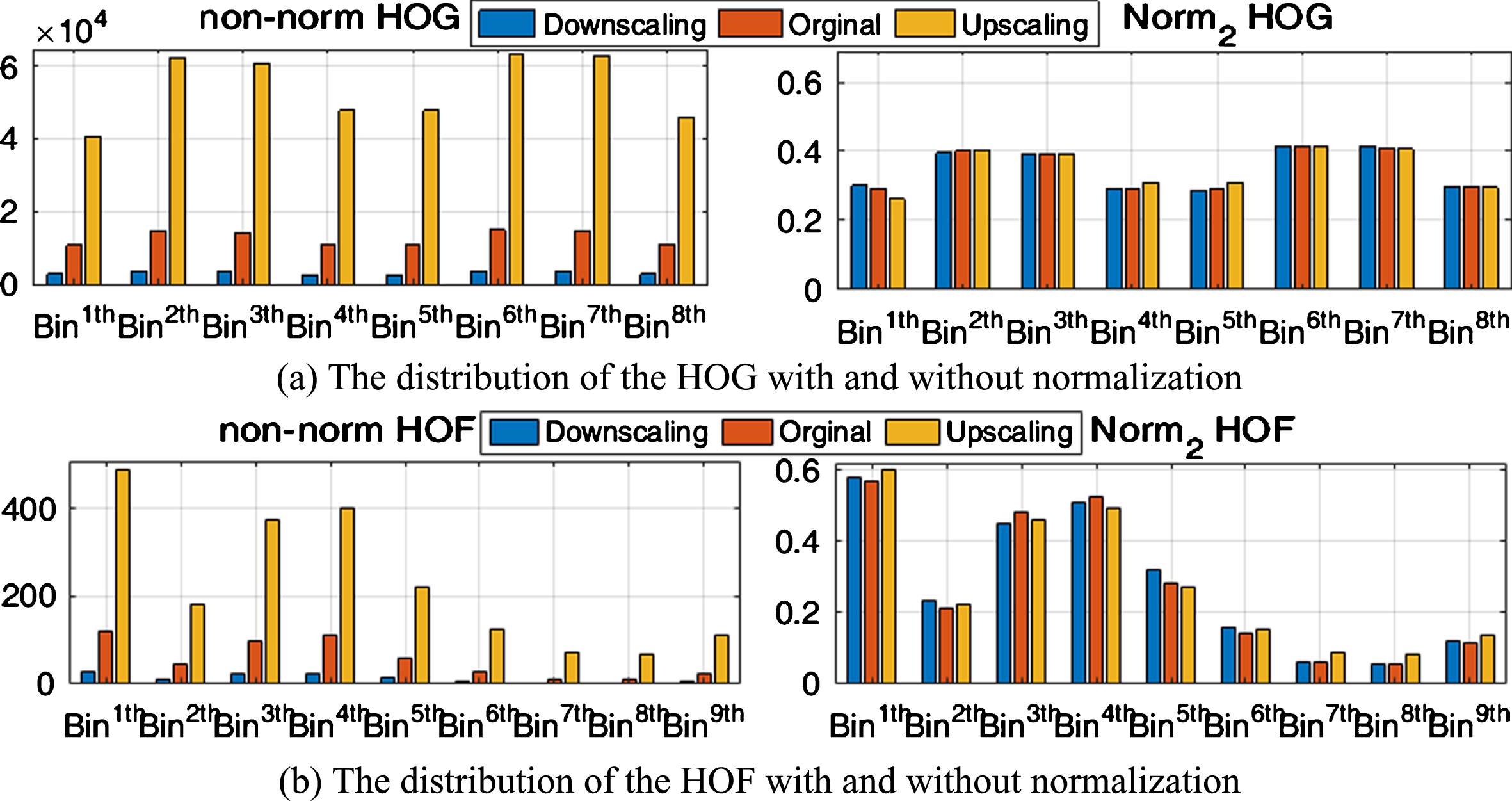
Invariant HOG and HOF features from multiple scales of images.
For both the theoretical argument and the empirical results, we see that the HOG based on multiple scales of image pyramids can be approximated by one based on the original image across multiple scale feature regions.
The most popular feature descriptors for action recognition are the HOG, HOF, and MBH. However, the primary difficulty in feature extraction using image pyramids is computationally expensive. In a manner similar to previous section, we extended the approximation of features of image pyramids to SFE for both HOF and MBH descriptors using only the original image. The optical flow method aims to compute a motion between two image frames, which are taken at times t and t + δt at every voxel position to obtain velocities from discrete image displacements. The optical flows between the two image frames, following an approximate constraint of constant intensity can be expressed as follows:
The changing ratio of optical flow in the original image is faster than optical flow in the upscaled image. Meanwhile, the optical flow direction is not changed.
Following the above argument, the SFE method based on the HOF, and MBH descriptors also vary faster than in the traditional approach. Fig. 4(b) shows the mean of each bin using the HOF description, which is computed from videos of UCF101 dataset. In this experiment, the first bin is represented by stable flow (with less motion than a defined threshold). The result in Fig. 4(b) illustrates that the distribution of the HOF extracted in image pyramids is similar to the scalable HOF extracted from region pyramids of the original image.
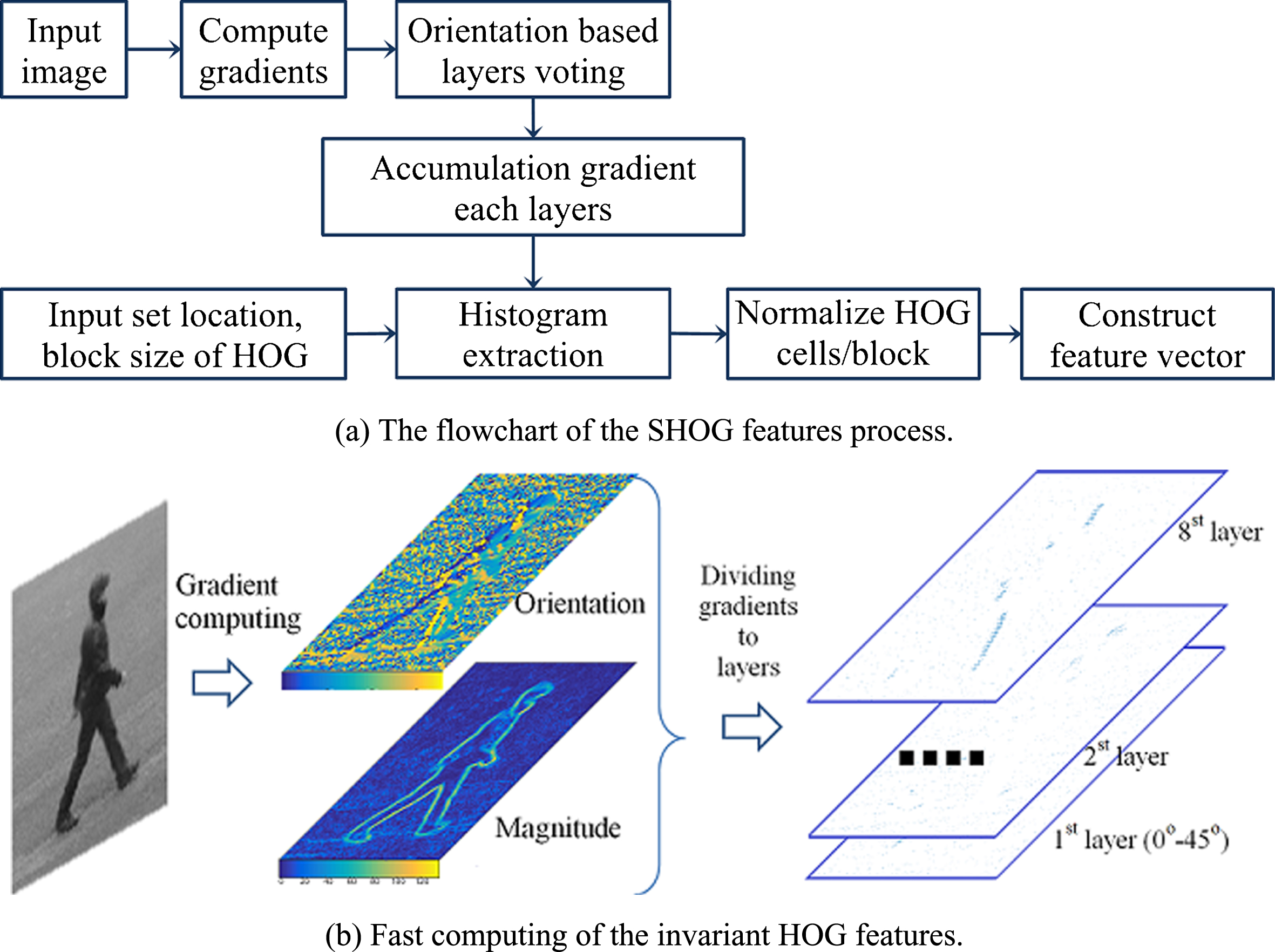
This subsection presents a new approach for the fast computation of histogram-based feature descriptors. Without loss of generality, we describe a method, applied to HOG features, called a scalable histogram of orientated gradient (SHOG). Then it is extended to apply to the HOF, and MBH feature descriptors. The SHOG feature is briefly presented in Fig. 5(a). The gradient value at each pixel of image is computed using discrete derivatives. The filter kernels
The invariant HOG and HOF features from multiple scales of images.
The basic idea of the method is the use of orientation-based accumulation, which supports the computation of histograms within different region sizes parameterized by the time variable. The HOG within an arbitrary region is computed by accessing the accumulative sum gradient table (AS) four times. In accordance with the characteristics of the accumulative sum table, the gradients are separated into layers based on their orientation, with each layer organized into an AS table. That mean that each AS table is the histogram of gradients with respect to each orientated interval, which votes for each bin of the HOG. For example, in this application each 45 degrees of signed orientation corresponds to one layer, as illustrated in Fig. 5(b). Finally, the HOG within any region size only requires four operations, multiplied by the number of oriented gradient layers, e.g., 4 operations/layer ×8 layers.
The gradient magnitudes are separated into 8 tables based on their oriented angles. The orientations of gradient are used with [0, 360] degrees, in conjunction with 8 bins, with 45 degrees/bin, as depicted in Fig. 5(b). Each gradient table is used to compute an accumulative sum gradient histogram following each bin. In total, eight AS tables are used for the processing of the HOG. The accumulative sum of oriented gradients of the k
th
layer is computed and stored in the AS
k
table, as follows:
To inherit the previously computed elements of the AS table for fast computation of the AS, three neighboring elements of AS (i, j)
k
are combined with the current local gradient to result in an AS (i, j)
k
value, as follows:
Then, a histogram of the k
th
bin within a region (x, y, w, h) is extracted using the AS tables as follows:
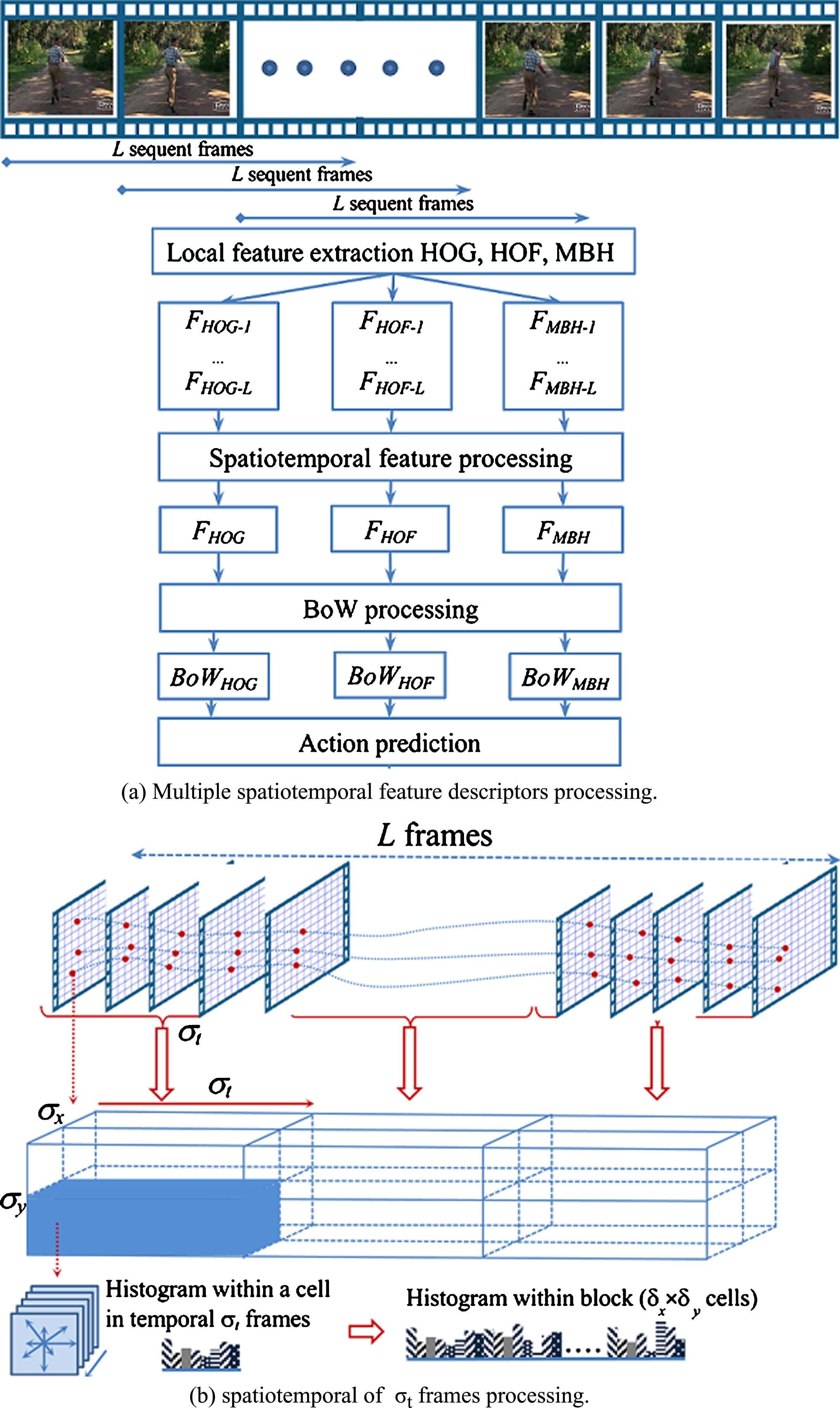
The low-level feature descriptors have many applications in pattern recognition. There are notable advantages in the use of low-level descriptors, including their robustness under different geometric properties, complex backgrounds, independent machine learning algorithms, and tractable filters. There are some major tasks in the extraction of feature description. First, it is necessary to determine feature locations, to provide a rich structure for robust tracking. Optical flow is computed using a pair of sequent frames. In this process different kinds of feature descriptors are extracted at detected locations. This process is iterated for the following pairs of frames. The feature locations are tracked within an interval of frames, which covers an action cycle. For the end of each action cycle, spatiotemporal features are extracted using consecutive images. These features are fed to next step of action prediction processing. Similar to previous contributions [23], this study focuses on widely accepted feature descriptors such as the HOG, HOF, MBH, and the motion trajectory. An overview of the feature extraction process is presented in Fig. 6(a).
In general, it is difficult to determine the time or the number of frames required for a human to perform each action cycle. For example, an action occurs in a half of a second with a video frame rate of 24f/s, means there are 12 frames required for performing an action. This period should entirely cover an active interaction. In the experiment, a trial and error examination are used to determine the number of frames for an action cycle. With predefinition of frame rate, L is a number of frames, which covers the active interaction of that consists of an action. Therefore, feature locations are tracked within L frames. Similarity to [23], 3D feature descriptors are processed over a spatiotemporal interval of σ t frames, as depicted in Fig. 6(b).
The input image is divided into cells with size (c w , c h ), where c w , c h are the width and height of cells, respectively. A block of features consists of σ x × σ y cells. Dense optical flows are extracted using the Farneback algorithm from [4]. This technique is appropriate to real-time application for the extraction of a dense optical flow.
Each interval of L frames is divided into n subsequent intervals. Feature descriptors within σ t frames are represented spatiotemporal features, where the number σ t is defined as a divisor of L, n = L/σ t . In Fig. 6(b), the first row is presented as L frames with n subset of σ t frames, and the second row illustrates spatiotemporal features, which are extracted at a feature location.
Hybrid of classifiers for action prediction
BoW processing
In this work, the bag of words (BoW) framework is proposed for the hybrid classification application to reduce the dimension of feature descriptors and distinguish feature classes. Usually, multiple local descriptors are high dimensional and have a strong correlation. Therefore, it is obtaining a manageable processing time with high accuracy poses a great challenge. There are some main steps for constructing a BoW dictionary. Sequential frames are matched, resampling local features. Due to a variety of action situations and environment conditions, the number of features extracted at every frame is different. These features range a few to thousands of benchmarks. Furthermore, the task to make distinguishing and low dimension features is an essential criterion for improving the accuracy and speeding up the processing time. Most often, certain kinds of feature descriptors are concatenated for constructing the BoW dictionary. In this study, the individual descriptor is used for generating an individual dictionary. There are reasons for this approach: first, the low dimension of the descriptor provides for the fast construction of the BoW dictionary. Second, each kind of descriptor is comprised different of physical and geometric properties, for example, the HOG presents gradients of illumination and the context of the object while the HOF presents the optical flow properties.
Construction of the dictionary begins with a given a set of feature vectors in high dimensions {x
i
|x
i
∈ R
n
, i = 1 . . m}, where k is the word number of the BoW dictionary. The dimension number n is dependent on the kinds of descriptors. For example, 32 elements concern to HOG feature, which consists 32 elements for each POI. Then, spatiotemporal features are extracted within a period of σ
t
frames. The feature volume is defined as σ
x
× σ
y
× (L/σ
t
) elements. The objective is construct the BoW dictionary with k words to minimize the potential function within the available computational time. The greedy method is one of the most popular approaches to reach minimized functional cost. However, the greedy algorithm encounters issues with the computational complexity. Due to huge size of the data and high dimension, the method in document [1] is used to generate initial words of the BoW dictionary. They are chosen in a specific way to easily obtain the error criterion.
There are many approaches for matching and extracting the BoW feature, such as linear searching, the greedy method, brute-force matching, sum of squared differences (SSD), random sample consensus (RANSAC), and so on. In this study, feature locations are extracted based on the fast approximate nearest neighbors (FANN) [15] matching algorithm. The FANN method is provides an elegant solution for fast feature extraction. In [15], the authors have investigated many different algorithms for approximating the nearest neighbor search on a large dataset with high dimensionality. The experimental results [15] also demonstrated that it achieves a high accuracy, which was evaluated based on the percentage of points for the correct nearest neighbor using the hierarchical k-means tree and multiple randomized kd-trees. The vocabulary size of the BoW dictionary uses for matching is an important consideration. The objective is an optimization problem for finding the closest word in the dictionary, which is formed, as follows:
The BoW based feature B (b
1, b
2, . . , b
k
) is a vote of all samples to BoW dictionary. Finally, the extracted feature vector is normalized using the following:
Nowadays, the SVMs have been widely and successfully applied in recognition tasks across many applications. This approach is based on a given the training set, which consists of D = {(υ
i
, y
i
) |i = 1 . . . n}, where υ
i
is a feature vector of an action sample and the label y
i
indicates the class action. The traditional SVM training solves the primal optimization problem for a maximum margin hyperplane. The maximal margin hyperplane is solved based on a quadratic programming problem as follows
After the training step, the model parameters are stored, e.g. the coefficient b, the set of support vectors with respect to their label {(υ
i
, y
i
) , i = 1, . . , ns}, as well as the positive Lagrange multiplier coefficients {α
i
|α
i
≥ 0, i = 1 . . . ns} with ns is representing the number of support vectors. This experiment uses the Gaussian radial basis function (RBF) kernel, which is defined as
The output probability of the SVM classification is computed by
Spatiotemporal feature extraction.
Flowchart of hybrid classification for action prediction.
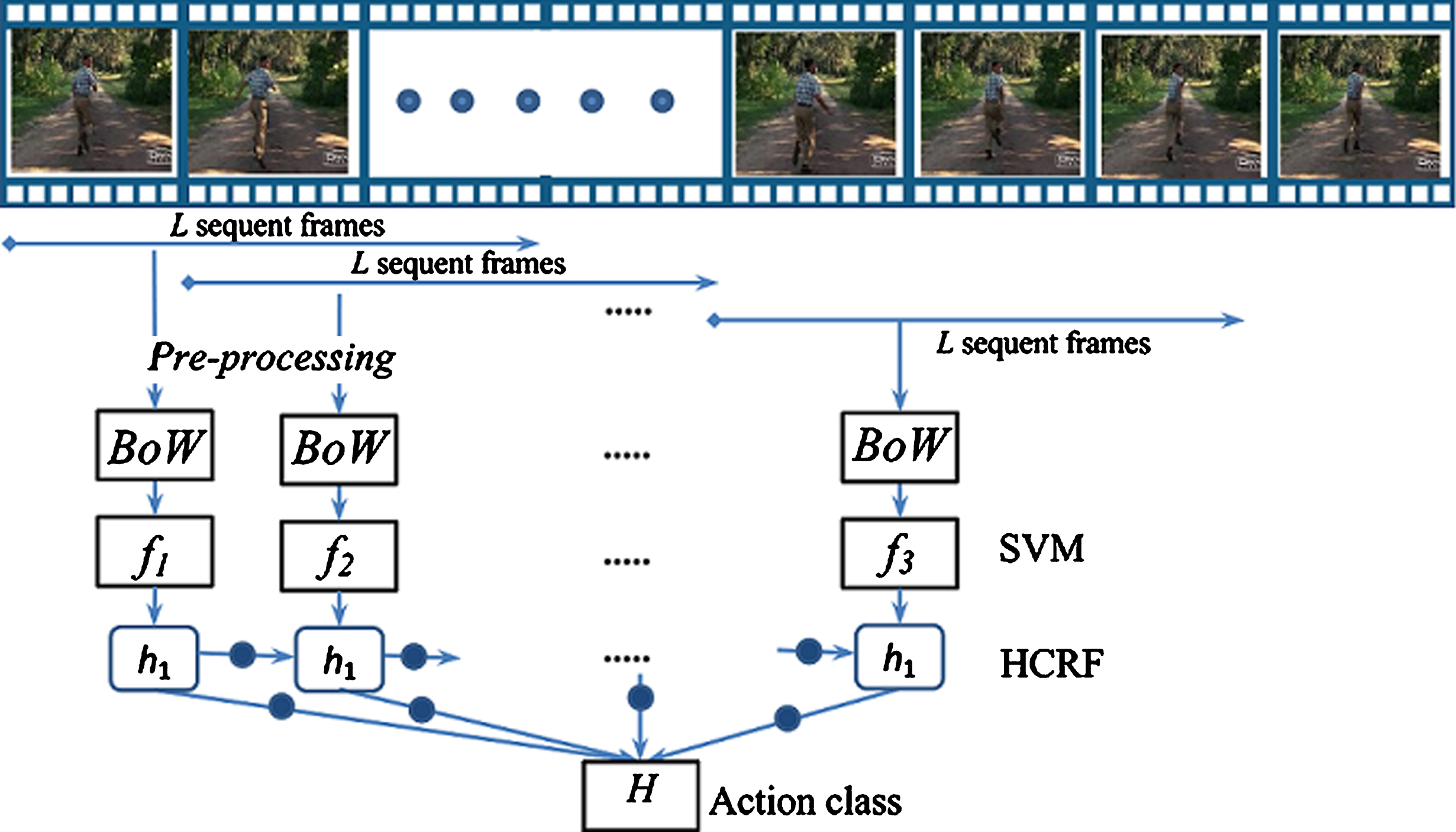
We used HCRF for inferring sequent actions. This method allows for the recognition of different activities in the video. In this approach, the probability of the output SVM is used as a raw detection of each independent L-frame. The HCRF infers an action based on the set of previous statuses in which the current action transpired. An input observation for the HCRF is represented as a sequence of observations from the SVM outputs. This is organized as a chain of action with the hidden labels Y, which represent action states, thus supporting inferences from given observations. The overview the flowchart of hybrid classification for action recognition is briefly presented in Fig. 7.
Related to action prediction from spatiotemporal image, there are some approaches, which were proposed such as stream CNNs with 2D/3D convolutional kernels based action recognition and some improve performances [5 , 27]. Most of them used characteristic features based on RGB as appearance data combining with optical flow feature as motion information. Meanwhile, some authors focus on CNNs with 3D convolutional kernels, which achieved high performance compared to 2D-CNNs by using the large-scale video datasets. 3D-CNNs are achieved effectively because such 3D convolution is used to directly extract spatiotemporal features from sequent images. Some authors investigated and showed that 3D-CNNs based on the input of optical flows give a higher level of performance compared to directly input from RGB image. The main problem is that it could not also achieve the highest in compared to the approach based on combining RGB and optical flows.
In this study, we proposed a new approach for action recognition based on a hybrid of DNN model for feature extraction and SVM classification. The DNN model is basically based on multiple channels of 2D-CNN and some inception block layers, which support for taking advantages of local feature and global feature extraction. The overall 2D-CNN model for feature extraction is illustrated in Fig. 3. This system is constructed based on the basic of inception architecture to implement the feature extraction process, as illustrated in Fig. 6. There are many kinds of CNN architectures such as AlexNet, GoogleNet, Microsoft ResNet, VGG16, VGG19 and so on. Inception architecture is a well-known model developed base on the GoogLeNet [20]. The input layer is defined with the size 240×320×15, which is appropriated to image size (240×320 pixel) of video data within a spatial episode length of 15 frames. The output size depends on the number of action classes, for example, 101 action classes for UCF101, 51 action classes for HMDB51. The network architecture is quite similar to GoogLeNet. In each inception, the depth concatenation layer is used to concatenate output of all branches of inception graph channels. After the last inception block, the average pooling layer is used to down-sample then they are fed to fully connectional layer. The fully connected layer is connected from dropout layer through it and fed to Softmax layer, which supports for final classification to output.
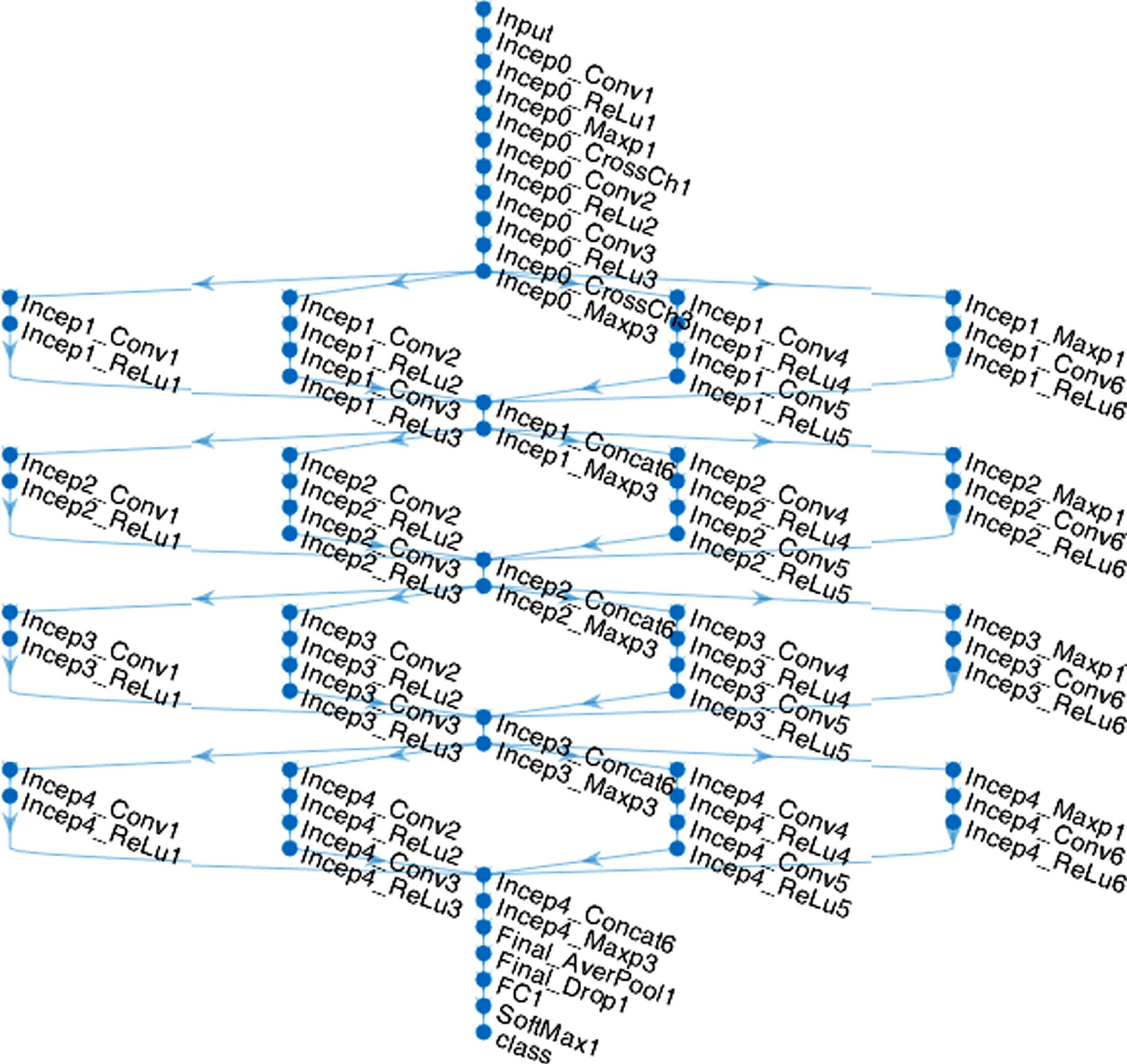
The flowchart of DL architecture.
The proposed method is evaluated using four datasets, which consist of the HMDB51 [13], OlympicSports in [16], UCF50 and UCF101 [19] datasets. The HMDB dataset consists of 6, 849 clips, which is categorized into 51 action classes. They were collected from various sources, such as YouTube videos. Videos were uniform with a frame rate of 30fps and video a resolution of 352 × 256 pixels. The Olympic Sports Dataset contains videos of athletes engaged in different Olympic sports. The dataset contains 16 sport classes: the high jump, long jump, triple jump, pole vault, discus throw, hammer throw, javelin throw, shotput, basketball lay-up, bowling, tennis serve, platform diving, springboard diving, snatch, clean- jerk, gymnastic vault. The UCF50 dataset contains 50 action categories. They are retrieved from YouTube for realistic actions under a variety of camera motions, object appearances and poses, object scales, viewpoints, cluttered backgrounds, and illumination conditions. UCF101 is an extension of the UCF50 dataset. UCF101 set consists of 13, 320 videos, which are clustered into 101 action categories. This is the most challenging commonly- used dataset to date with unconstrained environments. Action video of the UCF dataset have a diversity of properties which are largely similar to the UCF50 dataset. These videos were uniform with a frame rate of 25fps and video resolution of 320 × 240 pixels.
There are notable advantages of the SFE approach. First, the basic information, such as intensity gradient and optical flow are computed one time from the original image and then they are reused for multiple scales of the feature region, which have equivalents on the different image pyramids with fixed feature regions. In the traditional approach, for each level of image scale, these gradients and optical flows must be computed again. Therefore, our approach is necessarily faster than the traditional feature extraction approach. Secondly, our proposed approach results in an accuracy that is comparable to the more computationally intensive state-of-the-art approaches.
Result on computational time
In the experiment, we evaluated and compared our approach to the traditional approach on the same kinds of feature descriptors. Instead of using multiple scales of feature regions on image pyramids to extract features, the proposed method extracts SHOG from the original input image with pyramids of the feature region. Herein, both of the approaches extract features at the same feature locations. Feature locations are transformed to obtain corresponding locations between both methods. Instead of resizing the image to a lower resolution, we increase the cell size on the original image without re-computing the image gradients, as illustrated in Fig. 2, with the computational time presented in Fig. 9.
Fig. 9(a) shows a comparison of results of computational time for computing the gradient and oriented accumulation of the HOG descriptor. Fig. 9(b) shows the time for oriented histograms using the gradient result from the previous step (accumulative gradient layers). Fig. 9(c) presents the evaluated results on the computational time versus the scanning stride. The computational time is significantly reduced when the scanning stride is small. The practical results clearly illustrate that the SHOG approach is faster than the traditional method.
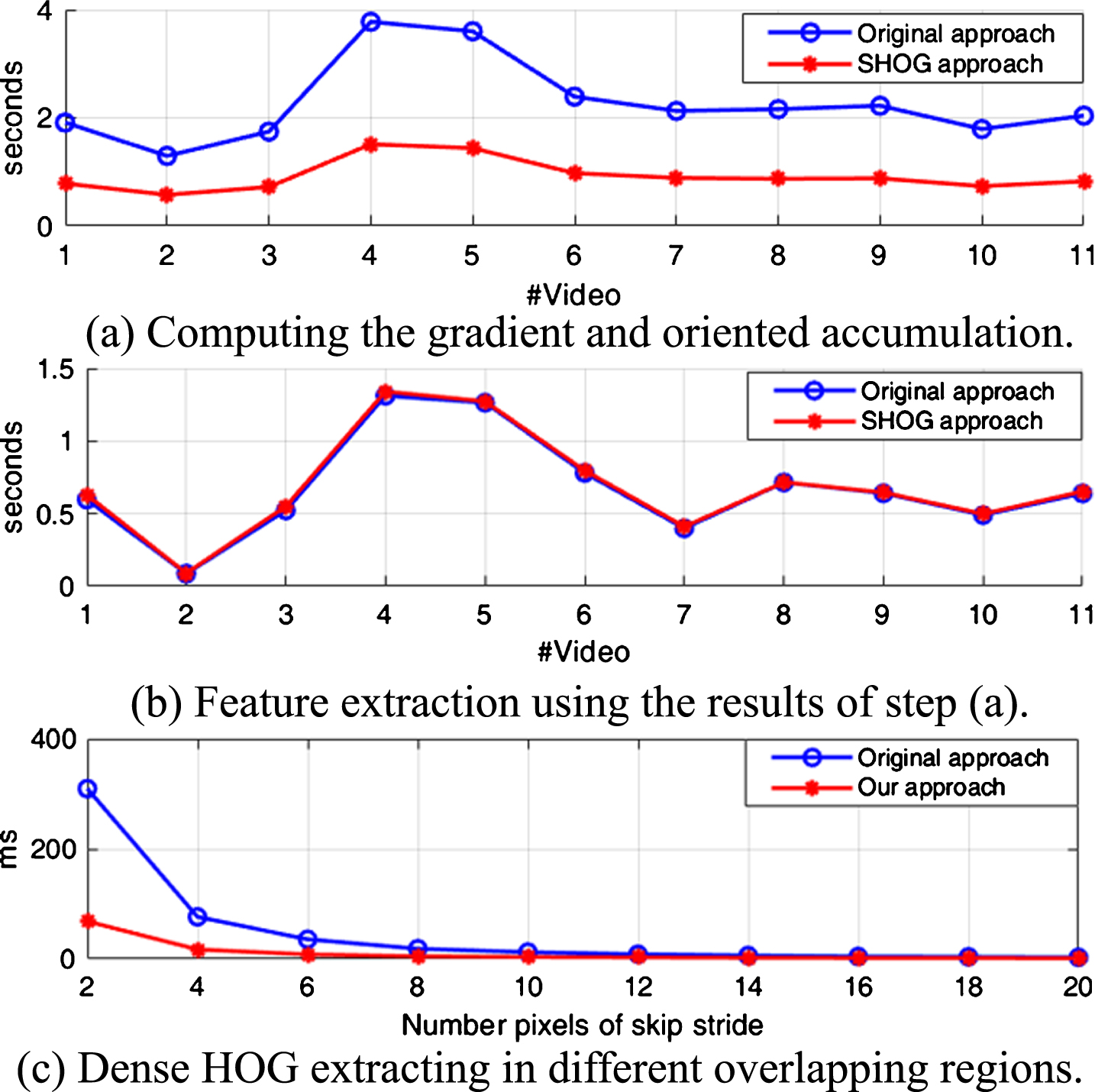
The evaluation results using the computational time criterion.
In this study, we evaluated how the method affects the recognition accuracy. The experiment was conducted on four datasets, as described in the first paragraph of this section. Usually, the task of resizing the image results in a reduced quality and texture detail of the images. Eventually, this reduces the accuracy of the system. To evaluate this accuracy reduction, we conducted an experiment on the Olympic Sports, HMDB51, and UCF datasets using the traditional feature extraction method, which uses image pyramids, and our SFE approach which uses only the original image with pyramids of feature regions. The results are shown in Fig. 10 and Fig. 11. The confusion matrix results in Fig. 10 shows that some sensitive actions producing in a low rate of prediction for both approaches. The results in Fig. 11 were achieved using about 60% samples/class for training and 40% samples/class for testing to compute accuracy rate of the recognition model. The results show that our proposed approach products higher accuracy than the traditional method.
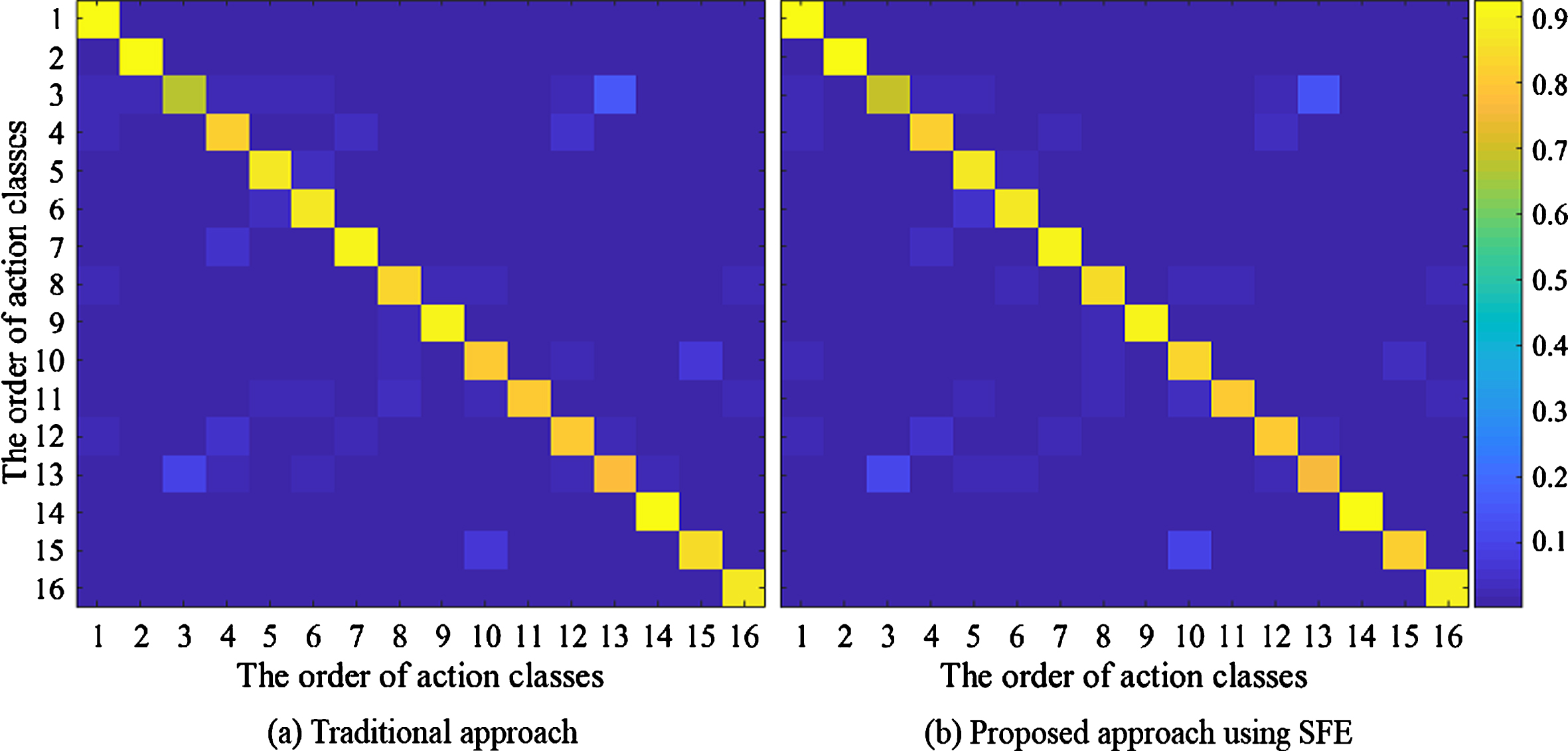
Confusion matrices of results on OlympicSports data.
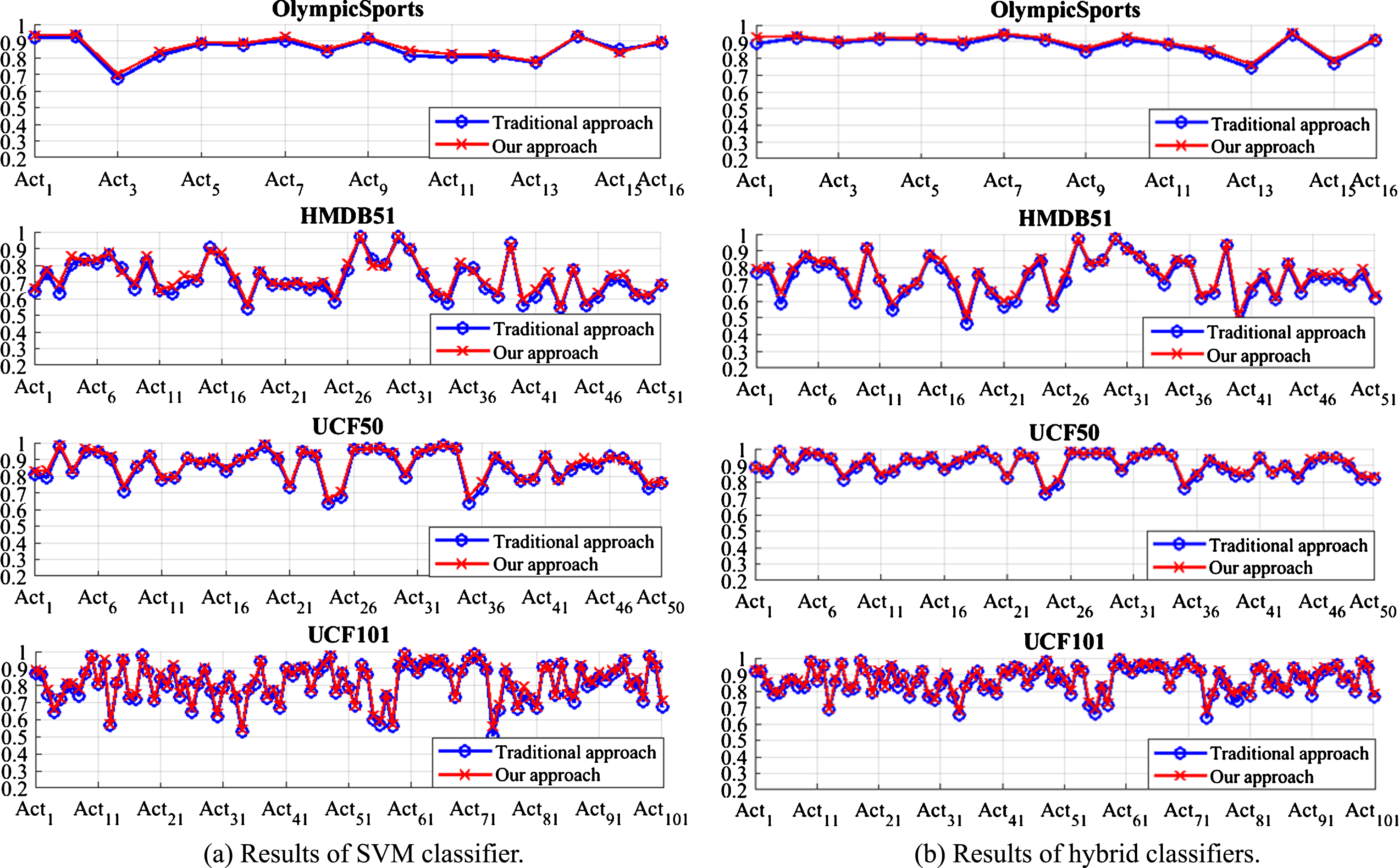
Comparison on accuracy of the traditional and our approach.
Effective measures: There are some measurement to evaluate the effectiveness of methods, depending on an objective of proposed systems. Our study use an accuracy criterion (ACC) for recognition rate of each individual action. Accuracy in this context is referred to recall as the true positive rate or sensitivity. Mathematically, accuracy rate of class i
th
(ACC
i
) can be expressed base on the number of true positive samples (TP
i
), the number of false negative samples from class i
th
(FN
i
) as follows:
Table 1 summarizes the accuracy of our proposal approach, as compared to the traditional method. The first row shows the evaluation result of the action recognition using only the HOG descriptor. The experimental results prove that the HOG descriptor significant outperforms the HOF and MBH methods. Especially, the MBHy descriptor has less accuracy than other descriptors. Our action proposal approach, based on a combination of all feature descriptors, is better than any individual approach. The evaluation result using any individual descriptor also illustrates that our method is superior to the traditional approach.
Comparison accuracy results on four datasets with the use of individual descriptor and a combination of all descriptor
Table 2 shows a comparison of the accuracy rate using the four above datasets. In our approach, hybrid classifier based on unsupervised and supervised machines using spatiotemporal feature descriptors, are applied for action recognition. The results of other methods in Table 2 are provided from the original papers [24] and our method is provided by the experiments. The results of [24] were evaluated on two scenarios of with human detection and without a human detection task. The experimental results showed that our approach outperforms the others on the HMDB51 and UCF101 dataset, which consist of more action classes.
Action recognition accuracy on four datasets with different methods and with our method
Experiment results using hybrid of DL and SVM showed that accuracy of the system can be reached to 88.1% in average on the UCF101 dataset. The result shows that the approach based on hybrid machines is outperformer that single machine SVM using spatiotemporal features. However, it has higher time consumed. Meanwhile DL+SVM does not result higher accuracy for the HMDB51 and Olympics sports dataset as showed in Table 2. Therefore, the proposed approach for spatiotemporal feature extraction is appropriate to apply to the general condition of realistic activities. The experiments also show that some similar action, e.g. interactive motion, unintelligible, short motion of trajectory often result low precision. Meanwhile, some kinds of actions, e.g. intelligible, long motion, which often result high precision. The details of top 5 action categories resulting the best and worst recognition rates are shown in Table 3.
The best and the worst recognition score of action classes
This paper presents a solution for improving action recognition based on the SFE method using hybrid discriminative models. In this approach, the local features can be extracted from multiple scales of feature region of the original image instead of using traditional image pyramids. This technique supports a one-time calculation of the basic feature information at a single scale of the original input image. A spatiotemporal- based feature descriptor further characterized the relative geometry between partial motions, providing an important distinguishing signal that differentiates the descriptor from other classes. This descriptor proved robust for discriminating actions, leading to effective disambiguation of similar actions. Our simulation and experiments illustrate that the proposal approach makes it possible to extrapolate feature descriptors using using a coarsely sampled set of feature region scales to match computationally intensive image pyramids. To evaluate the proposed approach, we studied the performance on four benchmark datasets. Experimental results showed that our approach outperformed on the accuracy of earlier works, while considerably decreasing the required computational time.
Footnotes
Acknowledgments
This research is funded by Vietnam National Foundation for Science and Technology Development (NAFOSTED) under grant number 102.05-2015.09.