
Abstract
Case retrieval is a major step in case-based reasoning (CBR), which seeks the most similar historical case to correspond to the target case. However, the first step of similarity measurement is to determine the weights of attributes, which would affect the accuracy of the similarity calculation results. In this study, we propose a new method, called DEA-CBR that integrates the double frontiers data envelopment analysis (DEA) to determine the most similar historical case based on the similarity efficiency of each historical case. This proposed method is different from the traditional distance-based similarity measurement methods in that attribute weights are determined by DEA models without the need to be specified. The proposed DEA-CBR approach first defines attribute distances between each historical case and target case to calculate attribute similarity for each attribute. The maximum and the minimum similarity efficiencies of each historical case are then measured with DEA models and are geometrically averaged to measure the overall similarity efficiency of each historical case, based on which the most similar historical case can be determined. Two numerical examples are provided to illustrate the potential applications and benefits of the proposed DEA-CBR method.
Keywords
Introduction
Case-based reasoning (CBR) is an intelligent method that can solve new problems by referring to previous similar cases. It involves retrieving the most similar historical case from case base to provide solution for a new problem. In the past decades, CBR has been widely used in various areas, such as medicine [1], business [2], mechanical design [3], engineering design [4], emergency decision-making [5], and the like. For example, coal mine gas explosion is an unexpected event and causes serious harm to society. It is therefore very important to generate alternatives to deal with the explosion. Since the coal mine gas explosion has the characteristic of suddenness, the generation of alternative is often based on experts’ experience in emergency rescue. Obviously, it is appropriate to apply CBR to generate alternatives in emergency decision-making situation. Case retrieval is a crucial step in CBR. If the retrieved historical case is closely related to target case, the solution of the target case will be easy and effective, otherwise, the solution will be tough. Usually, the retrieval of historical cases(s) is achieved based on the weighted sum of attribute similarities or distances. Thus, attribute weights have significant effects on the retrieval results. For example, both historical cases and target case are assumed to be described by two attributes. Suppose that the attribute similarities between target case A and historical case B are 0.6 and 0.8, respectively, and that the attribute similarities between the target case A and historical case C is 0.7 and 0.7, respectively. If the attribute weights are 0.6 and 0.4, then the similarities between the target case and the two historical cases are 0.68 and 0.7, respectively. If the attribute weights are 0.4 and 0.6, then the similarities between the target case and the two historical cases are, respectively, 0.72 and 0.7. It can be seen clearly that the two different sets of weights lead to different results of retrieval. Obviously, case similarities are affected by the weights of attributes. Therefore, the determination of the attribute weights need to be objective. However, the existing case retrieval methods are almost based on distance or similarity, and the attribute weights should be determined in advance. It is argued that the determination of attribute weights is not easy. Moreover, decision is expected to be made objectively. In this paper, a new case retrieval method based on double frontiers data envelopment analysis (DEA) is proposed, which can determine the attribute weights automatically and objectively.
DEA, which is developed by Charnes et al. [6], is a method for evaluating the best relative efficiencies of a group of peer decision-making-units (DMUs) objectively by determining the most favorable input and output weights to each of the DMUs automatically. Chin et al. [7] has used DEA to determine the risk priorities of failure modes, which not only measures the risks of each failure mode effectively but also avoids determining the attribute weights. Wang et al. [8] has used DEA to determine the priority in the AHP and extended it to group AHP. Wang et al. [9] has proposed an integrated AHP-DEA methodology to assess bridge risk. Han et al. [10] has developed a DEA integrated artificial neural network method to optimize and predict the energy usage of complex petrochemical systems. Geng et al. [11] has proposed an improved DEA cross-model to analyze the energy and environment efficiency and apply it to case study [12]. In this paper, we focus on the case retrieval and employ DEA to evaluate the case similarities between historical cases and target case.
The primary contribution of this paper is to propose a method, called DEA-CBR, to determine the most similar historical case with the target case and to provide support for generating the solution alternative of the target case. In case retrieval, it is very important to determine the attribute weights, because it has great effects on the case retrieval results. Therefore, the existing case retrieval methods based on similarity or distance should determine the attribute weights in advance, while the proposed DEA-CBR method can generate the attribute weights automatically, which are determined by DEA models. Meanwhile, the DEA-CBR method measures the case similarities based on double frontiers DEA, which are proved to be reasonable [13], while most of the existing similarity measures can only determine the similarity from a single angle, i.e. distance or similarity. Furthermore, DEA is an objective evaluation method [14], so the proposed DEA-CBR method combines similarity measurement and DEA models can improve the objectivity of case retrieval.
The rest of this paper is organized as follows. The next section introduces some background information on case retrieval and DEA. In Section 3, we develop a retrieval method by incorporating DEA to obtain the most similar historical case. In Section 4, a case study on emergency response is conducted to illustrate the use and effectiveness of the proposed method. Discussion and conclusions of this study are presented in Section 5 and Section 6, respectively.
Research background
Case retrieval methods: an overview
Case retrieval is the core of CBR systems. The most usual method in case retrieval is similarity measurement, which evaluates similarities between target case and historical cases. The commonly used approach to assessing similarity is the distance function including Euclidean distance [15], Manhattan distance [16], Gaussian distance [17], and so on. In addition, there are other approaches that can be used for case retrieval, such as neural network [18], rule base [19], decision tree [20], outranking relations [21]. The relation between the distance and the attribute weights is expressed as follows:
Many researchers have engaged in the studies in the determination of attribute weights. In existing studies, the methods for determining attribute weights can be mainly classified into two types: subjective methods [15, 20] and objective methods [23, 24]. The subjective determination of attribute weights is usually based on the decision-makers’ judgments or preferences, which leads to different attribute weights. Objective methods are based on some soft computing methods and also have some drawbacks. For example, the drawback of the genetic algorithm is its tendency to be trapped in local minimum value, and artificial neural networks (ANNs) require a large number of interconnected neurons to allocate connection weights to represent specific weight information. Therefore, new retrieval methods for considering how to evaluate the case similarities objectively and determining the attribute weights automatically are worth being studied.
The classic DEA model is first proposed by Charnes et al. [6] to evaluate the relative efficiency of DMUs with multiple inputs and outputs. Over the past decades, many important models have been proposed, such as BCC model [25], super-efficiency model [26], cross efficiency model [27]. However, the traditional DEA models measure only the optimistic efficiencies of DMUs, which are difficult to be discriminated from each. Therefore, Wang et al. [13] proposed the pessimistic efficiency model and suggested a geometric average efficiency model, which integrated the optimistic and pessimistic efficiencies of DMUs as the overall efficiency measure of DMUs. Using the geometric average efficiency model, all DMUs can be fully ranked and discriminated. We briefly introduce the geometric average efficiency model as follows.
Assuming that there are p DUMs, and the fth DMUs has s outputs y rf (r = 1, …, s ; f = 1, …, p) and t inputs x ef (e = 1, …, t), which are known and nonnegative. The efficiency of DMU f relative to the other DMUs is determined using the CCR model [6] as follows:
If there exists a set of positive weights that makes
The above CCR model is called optimistic efficiency model which measures the optimistic efficiency of a DMU by maximization within the range of less than or equal to one. The pessimistic efficiency model suggested by Wang et al. [13] measures the pessimistic efficiency of a DMU by minimization within the range of greater than or equal to one and is constructed as follows [28, 29]:
If there exists a set of positive weights that makes
Based on the above optimistic efficiency model and the pessimistic efficiency model, Wang et al. [13] proposed the geometric average efficiency determined by
In this section, we present a new case retrieval method based on double frontiers DEA, which can not only scientifically evaluate case similarities between target case and historical cases, but also avoid the determination of attribute weights. First, the formula to measure the attribute similarity is provided. Then, the similarity efficiency model is constructed using DEA models to obtain similarity efficiencies between historical cases and the target case. Afterward, the proper historical case(s) can be obtained by ranking the overall similarity efficiencies. In this study, we consider three formats of attribute values. The proposed case retrieval method for each format is presented as follows.
Similarity efficiency measure for real numbers
Suppose there are m historical cases denoted by C
i
(i = 1, …, m) and one target case denoted by C0. Both target and historical cases are described by multiple attributes. Let
For attribute
Let Sim
ij
denote the attribute similarity between historical case C
i
and target case C0 with regard to attribute
If every Sim ij (j = 1, …, n) of historical case C i is equal to 0, which means that there is a maximum dissimilarity between the target case and historical case C i , we will not consider this historical case C i when ranking the historical cases according to the similarity efficiencies.
Furthermore, the similarity function can be constructed based on the attribute similarity Sim
ij
. Let Sim
i
denote the similarity between historical case C
i
and target case C0, then the formula of is Sim
i
defined by [32] as
From Eq. (7), the weights of attributes need to be determined in advance. In this study, we determine the attribute weights using DEA models objectively.
The traditional DEA often produces too many zero weights for inputs and outputs, which leads to overestimated optimistic efficiency and underestimated pessimistic efficiency. To overcome this drawback, Chin et al. [7] proposed imposing a constraint condition as follows:
According to Chin et al. [7], we view each historical case as a DMU, its similarity with target case as an output, and assume a dummy input value of one for all the DMUs. Then, DEA models can be built to measure the maximum and minimum similarity efficiencies between the historical cases C i and the target case C0. By the study of Chin et al. [7], the similarity efficiency model can be formulated as
Taking into account the similarities in optimistic and pessimistic situations, the overall similarity efficiency
It is obvious that the bigger the geometric average similarity efficiency, the higher the case similarity. We can then rank the historical cases according to
We use interval number to express the uncertainty of an attribute value. For example, the value of ’the concentration of the residual O2’ in a coal mine gas explosion emergency is in the range of 23 to 28, and it can be express as [23, 28]. Let
Then, the maximum distance formula of d jmax is given by
Furthermore, according to the interval distance proposed in [33], the formula of Sim ij is given by
If all Sim
ij
= 0 (j = 1, …, n), then the historical case C
i
has the maximum distance from the target case C0 on all attributes
Let
As aforementioned, each historical case can be viewed as a DMU, each case similarity is assumed as an output, and one is assumed as a dummy input value for all the DMUs. According to the DEA models introduced in Section 2 and the DEA models proposed in Chin et al. [7], the maximum and minimum similarity efficiency models can be constructed as
Based on
The minimax regret approach (MRA) developed by Wang et al. [14] can be used to rank the interval numbers. According to the ranking, we can obtain the most similar historical case with the target case.
Emergency has also the characteristic of fuzziness, it is therefore very natural to use fuzzy linguistic variables to express the attributes. For example, the value of ’the concentration of CO2’ in a coal mine gas explosion emergency is either ’high’, ’medium’ or ’low’, and it can be expressed in the format of fuzzy linguistic variables. Let E = {e
h
|h = 0, 1, …, T} be the pre-established ordered linguistic term set, where e
h
denotes the (h + 1)th linguistic variable of the set E, and (T+1) is the number of the linguistic variables. Then, according to the study of [34], the linguistic variable e
h
can be expressed as the triangular fuzzy number
If the value of p
ij
is the fuzzy linguistic variable, it can be expressed as the triangle fuzzy numbers
Taking into account the logarithmic function as a decreasing function that has the same monotony with the attribute distance and attribute similarity, the formula of Sim ij is given by
Furthermore, we use Eq. (7) to express the attribute similarity Sim
i
. Then, we employ the similarity efficiency models of Eq. (9) and Eq. (10) to obtain the maximum and minimum similarity efficiencies. We use Eq. (11) to obtain the geometric average similarity efficiency
An emergency case is usually denoted by the hybridization of the real numbers, interval numbers, and fuzzy linguistic variables. For example, in a coal mine gas explosion, the value of ’the number of trapped personnel’ is [47, 53], the value of ’the affected area of the blast’ is 17m2, and the value of ’the concentration of CO’ is very good. It is necessary to measure the hybrid similarity ranking. When the attribute value is a real number or fuzzy linguistic variable, we obtain the value of Sim
ij
using Eq. (6) and Eq. (25), respectively, and Sim
ij
is a real number. When the attribute value is an interval number, we obtain the value of Sim
ij
using Eq. (14), and Sim
ij
is an interval number. To unify all Sim
ij
as one data format, we express all Sim
ij
as interval numbers. If Sim
ij
is a real number, then it can be expressed as Sim
ij
= [Sim
ij
, Sim
ij
]. Furthermore, we can obtain
In summary, the steps of the proposed method for case retrieval are given as follows:
Illustrative examples
In this section, we provide two examples to illustrate the effectiveness of the proposed method. In recent years, coal mine gas explosion emergencies occurred frequently in China, which brings serious losses of life and property. The coal mine companies and their related departments pay close attention to the problem of how to deal with the emergencies rapidly and effectively. When the emergency occurs, the decision makers often make an emergency response according to their historical experience. Hence, the method of CBR is very suitable for assisting the decision makers to generate alternatives.
Company A is a coal mine company in China. When a coal mine gas explosion emergency occurs, the company uses the CBR method to retrieve the historical cases and gives an emergency alternative quickly according to the most similar historical case. For this, this company creates a historical case base based on mine gas explosion in other companies in recent years. Company A collects 21 historical cases and identifies four attributes in the main problem, namely, the number of trapped personnel(X1, unit: person), the affected area of the blast (X2, unit: m2), the concentration of the residual O2 (X3, unit: %), and the concentration of CO (X4, unit: %). In the next, we will give two cases to illustrate the proposed method. In example 1, the data of collected attributes is real numbers. In example 2, the collected attribute data is mixed, i.e., real numbers, interval numbers and fuzzy linguistic variables.
Attribute values of the historical cases and the target case
Attribute values of the historical cases and the target case
Computational results of Sim ij concerning each historical case
Similarities for the coal mine gas explosion by the DEA-CBR method
The higher the ranking is, the more similar the historical case C i with target case C0 will be. Consequently, C10 is the most similar case according to the obtained ranking.
In order to express the feasibility and validity of the proposed DEA-CBR method, we use several methods to make comparisons with it. Firstly, the entropy weight method [35] is used to calculate the attribute weights. Then, the attribute similarities or distances are calculated by using three methods, i.e. Euclidean distance method (EDM), Gaussian distance method (GDM), Fan˛aŕs method (FANM) [5]. Furthermore, the case similarities are got by weighted average method and linear weighted method. Figs. 1 and 2 show the ranking of historical cases by CBR methods, i.e., EDM, GDM, FANM, DEA-CBR, under average weights and entropy weights.
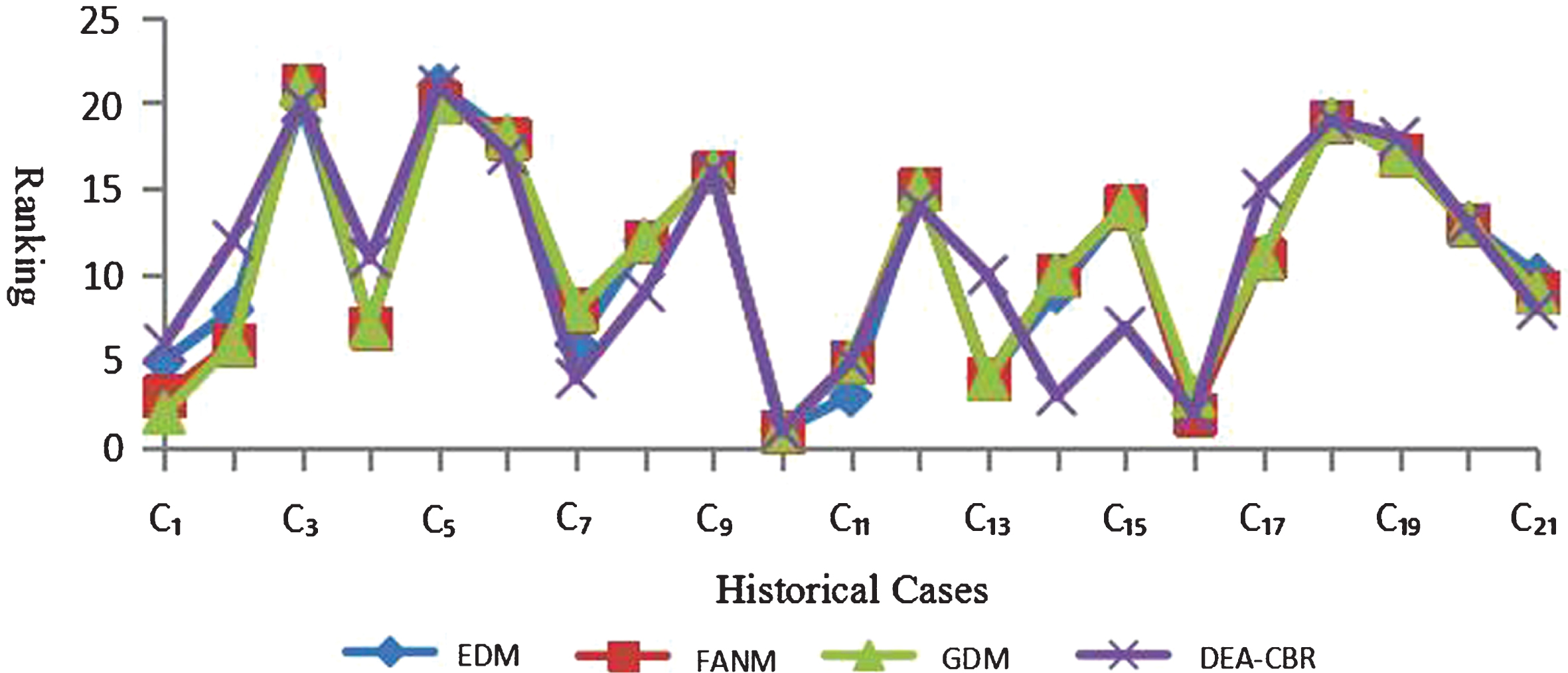
The ranking order of the historical cases under average weights.

The ranking order of the historical cases under entropy weights.
Based on the results in Figs. 1 and 2, we can see that there is no much difference between the four sets of case similarities rankings. A major difference between DEA-CBR and the other three methods lie in historical cases C4, C14 and C15. All the other historical cases are either ranked in the same order or have a very small gap. From Table 3, it is seen that the minimum similarity efficiency Sim4min = 1.6797 is a little small, the minimum similarity efficiencies Sim imin of historical cases C14 and C15 are great value. DEA-CBR considers both the minimum and maximum similarity efficiency, so the ranking is slightly different from the other three methods. The above observations show the applicability of the DEA-CBR.
Attribute values of the historical cases and target case for hybrid attributes
Similarity efficiencies and ranking
The smaller the ranking is, the more similar the historical case and the target case will be. Consequently, according to the obtained ranking, C16 is the most similar case.
In what follows, we use the hybrid similarity measurement [5] to calculate the similarities between the historical cases and the target case. First, let the attribute weights be {0.25, 0.25, 0.25, 0.25}, {0.5, 0.1, 0.3, 0.1} and {0.2, 0.1, 0.3, 0.4}. Then, we calculate the case similarities using the FAN method, and the methods are named FAN1, FAN2 and FAN3 respectively in views of the attribute weights. Finally, the ranking of historical cases are shown in Fig. 3.
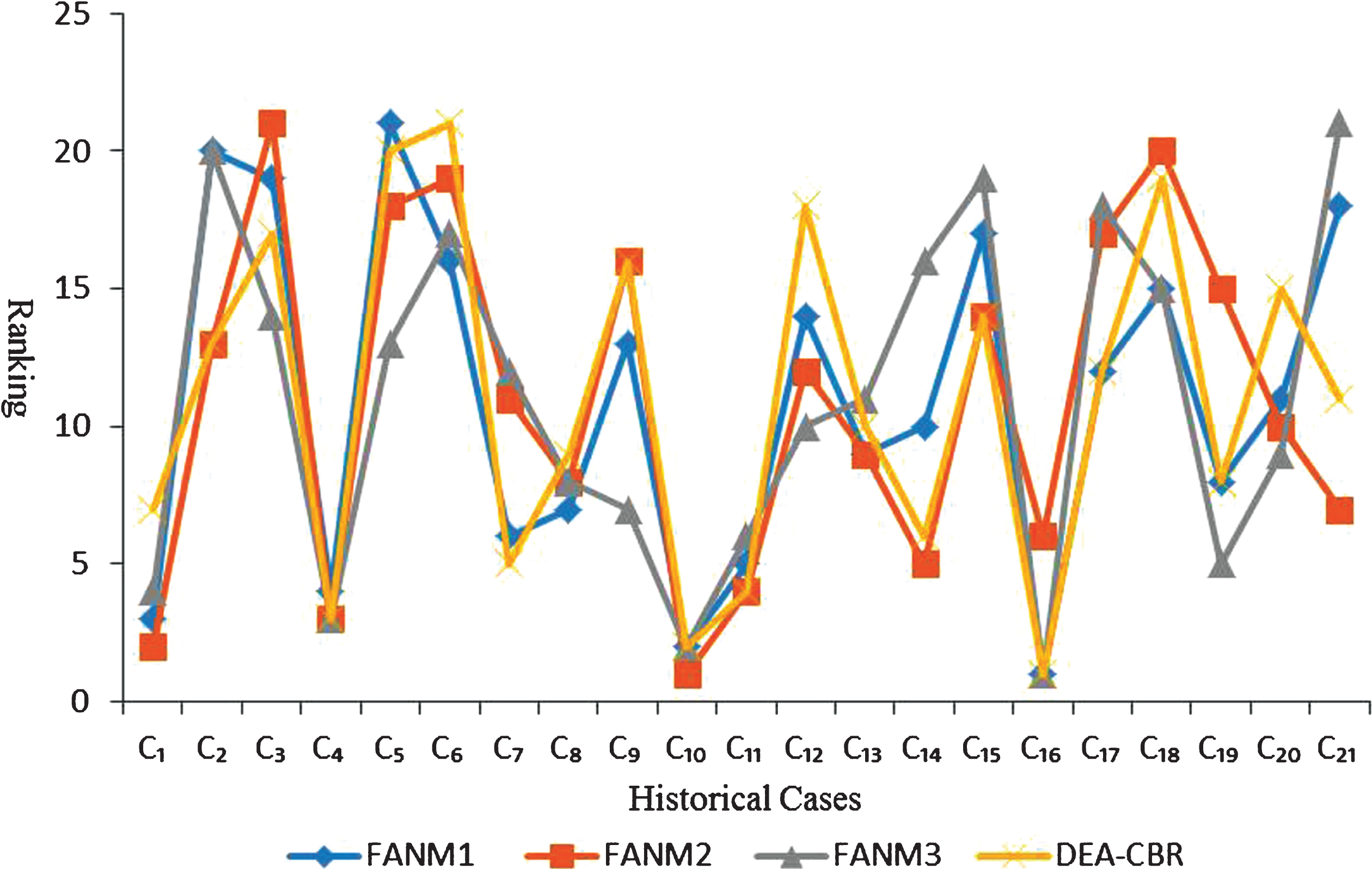
The ranking order of the historical cases under different attribute weights.
We can see from Fig. 3 that there is no much difference between the four sets of case similarities rankings. However, a major difference between the DEA-CBR and the other three FAN methods lies in historical cases C1 and C12. All the other historical cases have a very small gap in the ranking. From Table 5, we can get that the minimum similarity efficiencies
First, the DEA-CBR method is proposed to retrieve the most similar historical case with the target case. Compared with other methods, the proposed method can generate the attribute weights automatically. Meanwhile, the proposed method is more reasonable and objective for the case retrieval.
Second, the proposed method can provide decision support for decision makers. The most similar historical case can be gotten by averaging the maximum similarity efficiencies and minimum similarity efficiencies. And decision makers can give a better alternative by referring to the similar case. As can be seen from the illustrative examples, a most similar historical case can be obtained by using the proposed method. And the proposed method considers three formats of attribute values, such as real numbers, interval numbers and fuzzy linguistic variables. It takes a more comprehensive account of the formats of attribute values in the emergencies, and can better deal with the case retrieval in emergencies.
Third, the proposed method is developed to retrieve the similar historical case effectively. However, it fails to take into account other fuzzy formats, such as intuitionistic fuzzy number, hesitant fuzzy number.
Conclusions
This paper presents a new case retrieval method based on double frontiers DEA. In this method, the maximum and the minimum similarity efficiencies are obtained. Afterwards, the overall similarity efficiencies are calculated and the proper historical case(s) can be retrieved according to the obtained overall similarity efficiencies. Furthermore, illustrative examples are conducted to demonstrate the practical use of the proposed method. Compared with the existing methods for case retrieval, the proposed method has the distinct characteristic as discussed below.
The proposed method measures the case similarities by the geometric average similarity efficiencies, which is the first to use DEA models for evaluating the case similarities. The results using the proposed method would be more objective because DEA is an objective evaluation method [30]. Especially, DEA models can generate the attribute weights automatically. So, the proposed method does not need to determine the attribute weights in advance, while most of the existing retrieval methods should determine the attribute weights beforehand. In addition, the proposed method considers three formats of attribute values, such as real numbers, interval numbers and fuzzy linguistic variables. It takes a more comprehensive account of the formats of attribute values in the emergencies, and can better deal with the case retrieval in emergencies. Finally, two emergency cases have been examined using the proposed DEA-CBR method, demonstrating its feasibility and validity. It is expected that the method developed in this study may have more potential applications in the near future.
For future research, there are still some issues that need to be explored. For example, there are other formats of fuzzy data in practice, such as intuitionistic fuzzy numbers, hesitant fuzzy numbers, and so on. Besides, decision maker’s psychological behavior may also to be considered in case retrieval.
Footnotes
Acknowledgments
This work was partly supported by the National Natural Science Foundation of China under the Grant No. 61773123, Humanities and Social Science Foundation of Chinese Ministry of Education under the Grant No. 16YJC630008, Fujian Natural Science Foundation of China, No. 2017J01513.