
Abstract
Solution selection plays an important role in crowdsourcing and is an imperative work for requesters. However, to the best of our knowledge, there is few studies focus on the problem of solution selection, especially in crowdsourcing contests for innovative tasks. This paper aims to develop a methodology incorporating quality function deployment (QFD) with 2-tuple linguistic method to assist requesters to select the right solution from a large pool of potential solutions efficiently. The methodology includes three phases. The first phase, i.e. pre-selection, is to screen potential solutions by employing the rule of non-compensatory. The second phase is to construct relationships between requester’s requirements and solution features using quality function deployment (QFD), and further to determine the weights of solution features using 2-tuple linguistic weighted average operator and fuzzy weighted average method. The last phase is to evaluate the performance of potential solutions with respect to solution features, and further estimate their overall performance. Finally, an illustrative application case on the crowdsourcing platform-Taskcn is presented to demonstrate the implementation and effectiveness of the proposed approach.
Keywords
Introduction
The term “crowdsourcing” refers to a model that outsources tasks to a large and possibly undefined group of people. In recent years, it has attracted much attention from organizations [1], and gained in popularity for performing diversities of task [2]. Specifically, innovative tasks, such as product development [3], logo design [4], public transportation stop design project [5], and t-shirt design [6], as one of utmost task type [7, 8], its crowdsourcing has become an extremely promising domain of crowdsourcing [9]. Meanwhile, some crowdsourcing sites are structured as contests in support of publishing the tasks, such as InnoCentive, Crowd Flower, and Taskcn in china.
In crowdsourcing contests for innovative tasks, requesters publish a task with details of its requirements, awards, and expected duration. Potential participants who have interests and skills contribute to the task and submit their solutions. Finally, one solution which meets requester’s demands best is selected to carry out the task [10]. Generally, judging and choosing the best solution is the last step of crowdsourcing. Its result has directly great impacts on the quality of task completion and requester’s satisfaction. However, selecting the right solution is not an easy but a difficult work costing time and energy for requesters, because the number of submitted solutions provided by participants is always large and varying from each other in terms of features, contents, and forms. Requesters are required to evaluate each submitted solutions carefully and effectively.
Currently, in crowdsourcing systems, some approaches have been proposed to assess outcomes submitted by participants. The commonly used approaches are voting/rating mechanisms, text mining techniques, and machine learning approaches. For example, Ipeirotis et al. [11] presented an algorithm for evaluating and managing the quality of labeling process on Amazon Mechanical Turk. The algorithm is capable of generating a scalar score representing the inherent quality of each worker, allowing for separating the intrinsic error rate from the bias in worker answers. Le et al. [12] suggested an approach including an initial training period and subsequent sporadic insertion of predefined gold standard data in order to ensure quality of worker judgments. The experiment results on relevance categorization task on Amazon Mechanical Turk verified that the approach enables to ensure the accuracy of outcomes produced by individual worker. With regard to Le et al’s approach, Oleson et al. [13] noted that it has the weakness of requiring extensive collection of gold standard data manually, and further developed an algorithm to generate gold standard data automatically and ensure important gold properties as well. Besides, Burmania et al. [14] developed a reference set with predetermined ground-truth to monitor annotators’ accuracy and fatigue. By evaluating each worker’s quality in real-time and automatically stopping evaluation when worker’s quality does not meet the predetermined threshold, the system presented in the paper can help to collect accurate annotations.
The studies mentioned above mainly focus on simple tasks, such as image annotation and labels processing, and present some approaches to assess the quality of outcomes provided by workers. There is, to the best of our knowledge, few studies investigate the problem of solution evaluation and selection in crowdsourcing contests for innovative tasks. Unlike simple tasks which have one (or more) correct answer(s) out of a finite set of possible answers [15], there is no totally correct solutions for an innovative task. Consequently, it may lead to the models and approaches, such as gold-standard-based quality evaluation approach [11–13] and reference sets with predetermined ground-truth [14], cannot be applied to address the problem of solution selection in crowdsourcing contests for innovative tasks. New approaches are required to enable requesters to select qualified solutions appropriately and effectively. In the meantime, the following properties need to be considered while developing the approach. First, the aim of requesters is to select the best solution which has a higher satisfaction to meet their requirements. However, in practical, participants generally transfer these requirements described vague and implicit into the features of solutions that they developed. It may be more suitable and feasible to assess each solution against each solution feature rather than requesters’ requirements because the solution features are clear, concrete, and easy to be observed and assessed. Under this condition, to achieve the goal, we should comprehensively take into account the relationships between requesters’ requirements (RRs) and solution features (SFs) as well as the correlations among SFs that are always not independent. Second, during the process of evaluating solutions, linguistic labels rather than crisp number are commonly preferred by requesters to impress their opinions on the performance of solutions and relation degree between RRs and SFs. There is a need for proposed approach that can be able to deal with the imprecise and qualitative information. Third, due to the fact that the submitted solutions may be large, the approach is required to assess and select the right solution more effectively.
In view of above conditions, this paper develops a methodology with three phases for solution selection in crowdsourcing contests for innovative tasks. The first is pre-selection stage. The purpose of this stage is to screen a set of solutions that meet the minimum requirements so they can be qualified as the potential solutions and will be evaluated in the next two phases. In the second phase, we construct the relationships between RRs and the potential solutions features by using the house of quality (HOQ), the first matrix in QFD. Afterwards, the weight of each SF is determined by considering the importance of RRs, the inner dependencies of SFs, and the relations between RRs and SFs. Therein, 2-tuple linguistic method [16–18] which allows to reduce the loss of information is employed to represent, process, aggregate flexible information. The last phase is to assess the performance of each potential solution with respect to each SF by using 2-tuple linguistic variables. The priority of each solution is further determined by aggregating its local score against on each SF and its weight. The final evaluation results enable requesters to select the appropriate solution to carry out their tasks.
The rest of this paper is organized as follows. In the next section, the QFD and 2-tuple linguistic method are illustrated in order to provide a base of knowledge. Section 3 presents the methodology consisting of three phases to address the problem of solution selection in crowdsourcing contests for innovative tasks. Subsequently, in Section 4, an illustrative application case is conducted to demonstrate the implementation and feasibility of the proposed approach. Section 5 will discuss advantages and disadvantages of the proposed methodology comparing with other related methods. Finally, we conclude the paper in Section 6.
Preliminaries
This section will illustrate the QFD and 2-tuple linguistic method introduced in this paper in order to make the study as self-contained as possible.
Quality function deployment
The QFD is an important approach of developing product which integrates customer needs throughout the total process of product development [19, 20]. It offers tools for transferring customer needs into technical requirements, and further into part characteristics, process plans and production requirements [21, 22]. The QFD not only provides a structure approach for quality-driven product development, but also has advantages in prioritizing and defining information to be transformed from customer requirements to specific stages of product development.
The QFD is implemented by employing four matrices [23], which are product planning, part deployment, process plans, and production planning, respectively. Each matrix is corresponding to a stage of product development cycle. This paper mainly concentrates on HoQ, the first matrix in QFD. Generally, a typical HoQ is composed of seven parts, i.e., customer needs (CNs) and their relative importance, technical attributes (TAs) and their correlations, the relationships between CNs and Tas, competitive benchmarking and prioritized technical descriptors and targets, respectively [21]. The HoQ matrix is shown in Fig. 1.
CNs, which are also called customer requirements or customer attributes, are the initial inputs in HoQ. They offer the company a guideline to estimate what characteristics that product should possess. The first step of constructing a HoQ matrix is to investigate, identify, and determine CNs. With respect to the CNs, their importance must be assessed to assist companies to determine the priority of each CN to be satisfied. Some methods, such as AHP and simple direct rating, can be employed to measure their importance.
TAs, which also refer to product features, design requirements, or technical requirements, are the product requirements that have directly relations with CNs. They reflect how well the developed product matches with CNs. Commonly, TAs are interrelated rather than independent from each other [24]. To account for interrelations among TAs and facilitate informed trade-offs, their inner independencies are marked in the roof of HoQ matrix [22].
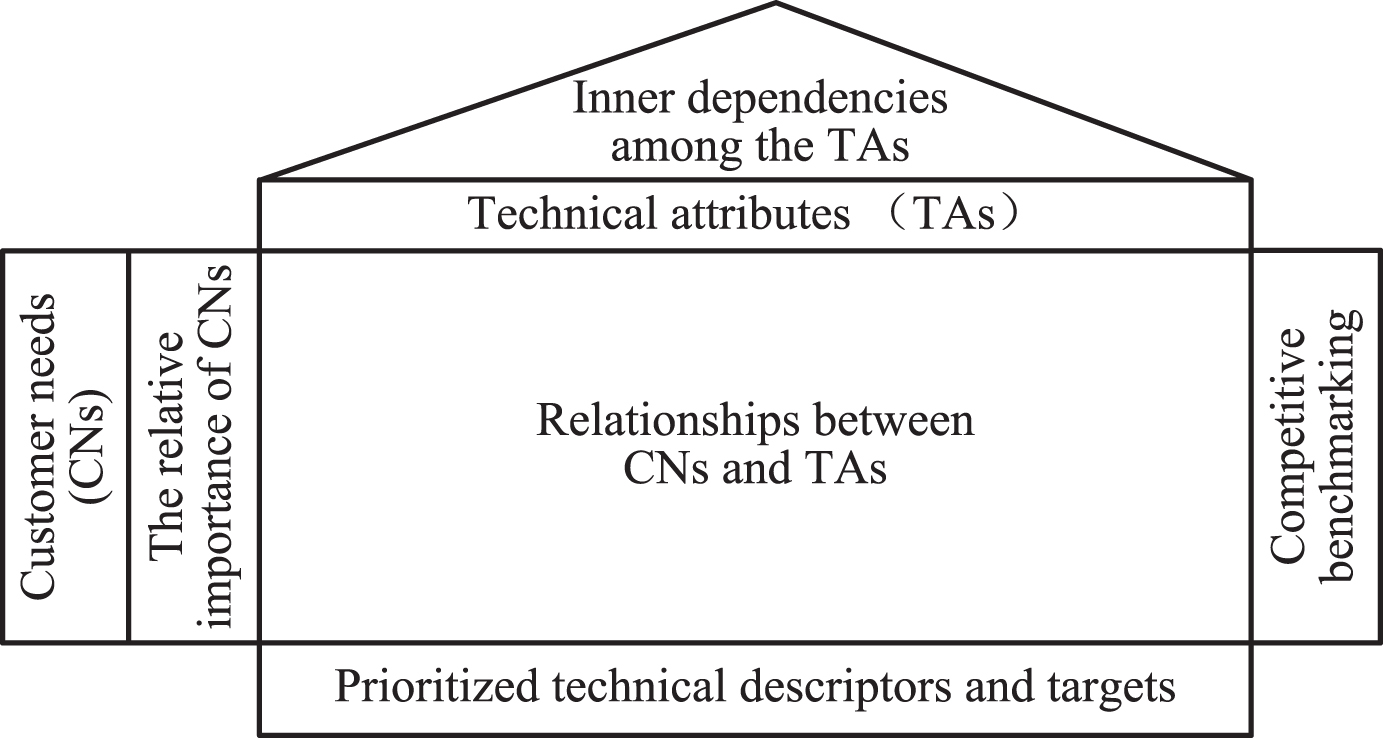
House of quality matrix.
The relationships between CNs and TAs are presented in the body of HoQ matrix, which is used to illustrate how much a TA affect a CN. Generally, linguistic variables and fuzzy linguistic methods are employed to measure the correlation degree between them [2, 19].
Competitive benchmarking is used to compare the performance of a product in terms of CNs with those of its competitors. Prioritized technical descriptors and targets are used to identify the relative importance of TAs with respect to CNs. The more important of a technical attribute, the more attention it will be got in the process of product development.
For some situations with qualitative aspects that are difficult to assess employing exact and precise values, we prefer to use inaccurate words in a natural language, such as “very likely”, “nearly”, and “probably so”, to express our evaluation information and opinions. To model and deal with the qualitative information, the fuzzy linguistic method [25] is a very feasible approach and has been proved to be useful in many problems [17, 26–28]. In this paper, the 2-tuple linguistic method will be introduced to deal with fuzzy linguistic information. The method [16–18, 29] is a continuous model of representation of information avoiding the loss of information and lack of precision in the aggregation process. To define it, the 2-tuple linguistic variables representing linguistic information and the 2-tuple linguistic computation operators that transform and aggregate linguistic information are presented as follows.
(1) Definition of 2-tuple linguistic variables
Suppose S ={ s0, s1, …, s u } is a finite linguistic term set with odd cardinality, where s i ∈ S is ith linguistic term. All terms distribute on a scale which a total order is defined, s i ≤ s j ⇔ i ≤ j.
Let β be a numerical value representing aggregation result of linguistic symbolic, where β ∈ [0, u] and β∉ { 0, …, u }. Then a transformation function (Δ) is defined to realize transfer between 2-tuple linguistic variables and numerical values [17]:
Where round (•) is the usual round operation. s i has the closest index label to “ β”. “ α” is the value of the symbolic translation, where i ∈ [0, u] and α ∈ [- 0.5, 0.5).
Meanwhile, a 2-tuple linguistic variable (s
i
, α) can also be transferred into numerical value β ∈ [0, u] by the following equation.
By using symbolic translation process mentioned above, we can transform 2-tuple linguistic variables into its equivalent numerical value β and vice versa. Furthermore, linguistic information can be expressed by means of the 2-tuple linguistic variable denoted as (s i , α i ), where α i is a numerical value indicating the distance between the original result β and the central value of the closest term s i . For example, the linguistic term s i can be converted into a 2-tuple linguistic variable by adding a value zero as symbolic translation, i.e. s i ∈ S ⇒ (s i , 0).
(2) Computation of 2-tuple linguistic variables
Assume that (s
i
, α
i
) and (s
j
, α
j
) are two 2-tuple linguistic variables, the computation of them are described as follows [17]: Algebraic operation:
where ⊗ and ⊕ are the symbolic of multiplication and addition operations. Negative operation: Neg ((s
i
, α
i
)) = Δ (u - (Δ-1 (s
i
, α
i
))). Comparative operation: if Δ-1 ((s
i
, α
i
)) > Δ-1 ((s
j
, α
j
)), then (s
i
, α
i
) is bigger than (s
j
, α
j
). If Δ-1 ((s
i
, α
i
)) = Δ-1 ((s
j
, α
j
)), then (s
i
, α
i
) and (s
j
, α
j
) represent the same information.
To handle the situation of the computational results be out of the scope of s u , we can extend the granularity u large enough [30], and the semantic of the terms out of linguistic term set do not be considered since the operation results only appear in computation [31].
(3) Aggregation of 2-tuple linguistic variables
For 2-tuple linguistic variables, some existing aggregation operators, such as arithmetic mean, weighted average operator, and linguistic weighted average operator, can be extended to process them. Arithmetic mean: suppose a 2-tuple linguistic variable set x ={ (r1, α1), …, (r
n
, α
n
) }, their 2-tuple arithmetic mean
Weighted average operator: suppose a 2-tuple linguistic variable set x ={ (r1, α1), …, (r
n
, α
n
) }, and ω ={ ω1, …, ω
n
} be their associated weights, then the 2-tuple weighted average
In this section, a methodology with three phases is firstly developed for solution selection in crowdsourcing contests for innovative tasks. They are solution pre-selection, weighting of solution features, and solution evaluation and prioritization.
Solution pre-selection
In crowdsourcing systems, innovative tasks, unlike simple tasks, are complex and require specific skills, knowledge, and experience of participants [10, 33]. Different participants with different levels of skill, reputation, and motivation may develop various solution varying from each other in terms of quality [15, 34]. For the solutions owning low quality may be proposed by unqualified or cheatable participants, they do not have great values for requesters. To improve the efficiency of solution selection, it is a feasible way to conduct per-selection initially that aims to screen solutions meeting minimum requirements.
Currently, basic screening rules of compensatory, non-compensatory, and lexicographical, are commonly applied to deal with the problem of alternatives ranking and selection such as supplier selection [35–38]. In the first case, decision making units (DMUs) are assessed against each criterion. A bad performance of a DMU on a specific criterion can be compensated by high performance on other criteria, and therefore its overall performance will reflect this. On the contrary, decisions making on the basis of non-compensatory rule assumes that no compensation for a DMU that does not satisfy a minimum requirement of a specific criterion. In the third case, the criteria for DMUs evaluation are first ranked, and the DMUs meeting the requirement of the most important criterion are selected to evaluate further.
In the phase of solution pre-selection in this paper, the main purpose is to screen the solutions meeting basic requirements proposed by requesters so they can be selected as potential solutions and moved on to the next phase. Base on the above view, the screening rule of non-compensatory is more appropriate than the other two rules to perform solution pre-selection. The solutions do not meet minimum requirement of a specific criterion will not be considered further. For an innovative task, the criteria used for solution pre-selection are basic and minimum demands which are obtained from requesters. These demands are commonly focus on the whole performance of each submitted solution.
Weighting of solution features
In this phase, a HoQ model for solution selection in crowdsourcing contests for innovative tasks is constructed at first. Then 2-tuple linguistic method and fuzzy weighted average method [35, 39] are used to determine the weight of each SF.
(1) Construct the HoQ model for the solution selection problem
The initial step of constructing the HoQ model in this paper is to identify RRs and SFs. In general, RRs always be published initially by requesters in a crowdsourcing contest along with expected duration and awards. It is noted that some other RRs may be added by requesters as time goes on. In this paper, these RRs with different priorities are collected and regarded as inputs in HoQ.
Afterwards, participants start to design or develop their solutions according to RRs from the most importance to the least. To a certain extent, the features of a submitted solution are derived from RRs, and RRs in turn are reflected by these features. On the basis of the view, this paper tries to identify SFs as follows: first, requesters collect all the potential solutions screened in the first phase, and extract features that most solutions possess. Second, some participants who have a good performance in performing the task are invited to collaborate with requesters to identify SFs as well, because they know the solutions well and may have a better understanding about SFs and their relations with RRs than requesters [40, 41]. By communicating and interviewing, requesters can acquire participants’ opinions on the SFs estimated initially and other added SFs. Finally, requesters summarize and sort out the SFs which are going to be viewed as criteria for solution evaluation.
According to the collected RRs and SFs, we present the HoQ matrix for the solution selection problem which is shown in Fig. 2. Therein, RRs ={ rs1, rs2, …, rs i , …, rs m } is a set of requesters’ requirements, and SFs ={ sf1, sf2, …, sf j , …, sf n } is the set of identified solution features.

The HoQ for the solution selection problem.
In Fig. 2, w i (1 ≤ i ≤ m), v ij , and t lj (1 ≤ l, j ≤ n) denote the relative importance of rs i , the relationship score between rs i and sf j , and the inner dependence value between sf l and sf j , respectively. In this paper, linguistic variables and 2-tuple linguistic method are used to represent, process, and aggregate subjective assessment information given by requesters. For the sake of simplicity, a uniform linguistic term set S ={ s0, s1, …, s u } is defined for evaluation. It is noted that other multi-granularity linguistic term sets can also be used in this paper in order to reflect different backgrounds and expertise of requesters. For the multi-granularity linguistic term sets, they can be transferred into a defined linguistic term set by using a transformation function so as to aggregate all evaluation information and further obtain final evaluation results [17, 42].
Subsequently, using linguistic terms in S, requesters are requested to evaluate the importance of each RR, the relationships between RRs and SFs, and inner dependencies among SFs. Regarding evaluation results represented by linguistic terms, we can transform them into 2-tuple linguistic variables by employing the transformation function (Δ). As a result, we can obtain evaluation results denoted as 2-tuple linguistic variables given by each requester.
Let
Where K is the number of requesters who involving in solution assessment and selection. ω
k
is the weight assigned to kth requester, and 0 ≤ ω
k
≤ 1,
(2) Determine the weights of solution features
The weight of each SF is impacted and determined by the importance values of RRs, the inner dependencies of SFs, and the relationship measures between RRs and SFs. Since they are represented by 2-tuple linguistic variables, 2-tuple linguistic weighted average operator [17, 27] incorporating fuzzy weighted average (FWA) [35, 44] are employed to compute the overall weight of each SF.
Firstly, the relationships between RRs and SFs should be modified and normalized by multiplying the inner dependencies among SFs [17, 43], i.e.
Where
Benefiting from Equation (9), the weight of each SF can be computed as follows [17, 44]:
Where y j is the weight of sf j .
This phase will firstly assess the performance of each potential solution with regard to each SF, and further determine their overall performance and prioritize them.
(1) Assess the performance of potential solutions
Suppose PS ={ ps1, ps2, …, ps
g
, …, ps
G
} be the set of potential solutions, where G is the number of solutions. For each potential solution, requesters are required to evaluate the performance of it against each SF. For simplicity, linguistic terms in S is provide to requesters to evaluate each potential solution. Consequently, the assessment results given by requesters can be characterized as follows:
Where
(2) Prioritize and select solutions
Through 2-tuple linguistic weighted average operator, we can estimate the overall performance of each potential solution by aggregating the local performance of it with respect to SFs and the local weights of SFs, i.e.
Where p g is the overall performance of ps g .
Then we can prioritize all solutions according to their evaluation values. Since only one solution in crowdsourcing contests can be selected as the win one, the solution with the highest value is selected on the basis of the rules of 2-tuples comparison to carry out the task.
In order to demonstrate implementation procedures of the proposed methodology and its feasibility, this section will briefly introduce a case of solution selection in crowdsourcing contests for innovative tasks. The case is conducted on Taskcn, the most widely used Chinese online crowdsourcing market that was founded in 2006. On Taskcn, innovative tasks, such as logo design, website design, article editing, and advertisement design, are important and major tasks posted by requesters and contributed to by participants. By the end of July 29, 2017, Taskcn has accumulated 62,679 tasks, with rewards totaling CNY 40,963,920. Additionally, there are 3,657,540 registered workers on Taskcn, and about 273,108 workers have won at least a reward.
The innovative task in the case is a logo design for a bilingual kindergarten named “zhisheng” which was published on Taskcn. The requirements of the task are the designed logo should reflect characteristics of modern kindergarten (rs1), logo’s color and shape should satisfy preferences of children who ages are from two to six years old (rs2), embody meanings of the kindergarten’s name, i.e. gain knowledge every day and grow up happily every day (rs3), original (rs4), concise and full of energy and hope (rs5). Furthermore, the reward of the task is CNY 300, and interested participants are asked to submit their solutions in 21 days. Finally, there are 2122 workers browse the task, and 35 solutions are received.
Regarding to the received solutions, we adopt the proposed methodology in this paper to evaluate them and further select the most suitable one. The procedures of selection are given below.

The examples of deleted solutions.
Through pre-selection, as a result, there are 14 solutions do not satisfy the minimum requirement of one or more criteria, and will not be considered further. The rest 21 solutions, which denoted as {ps1, ps2, …, ps21}, are moved to the next phase.
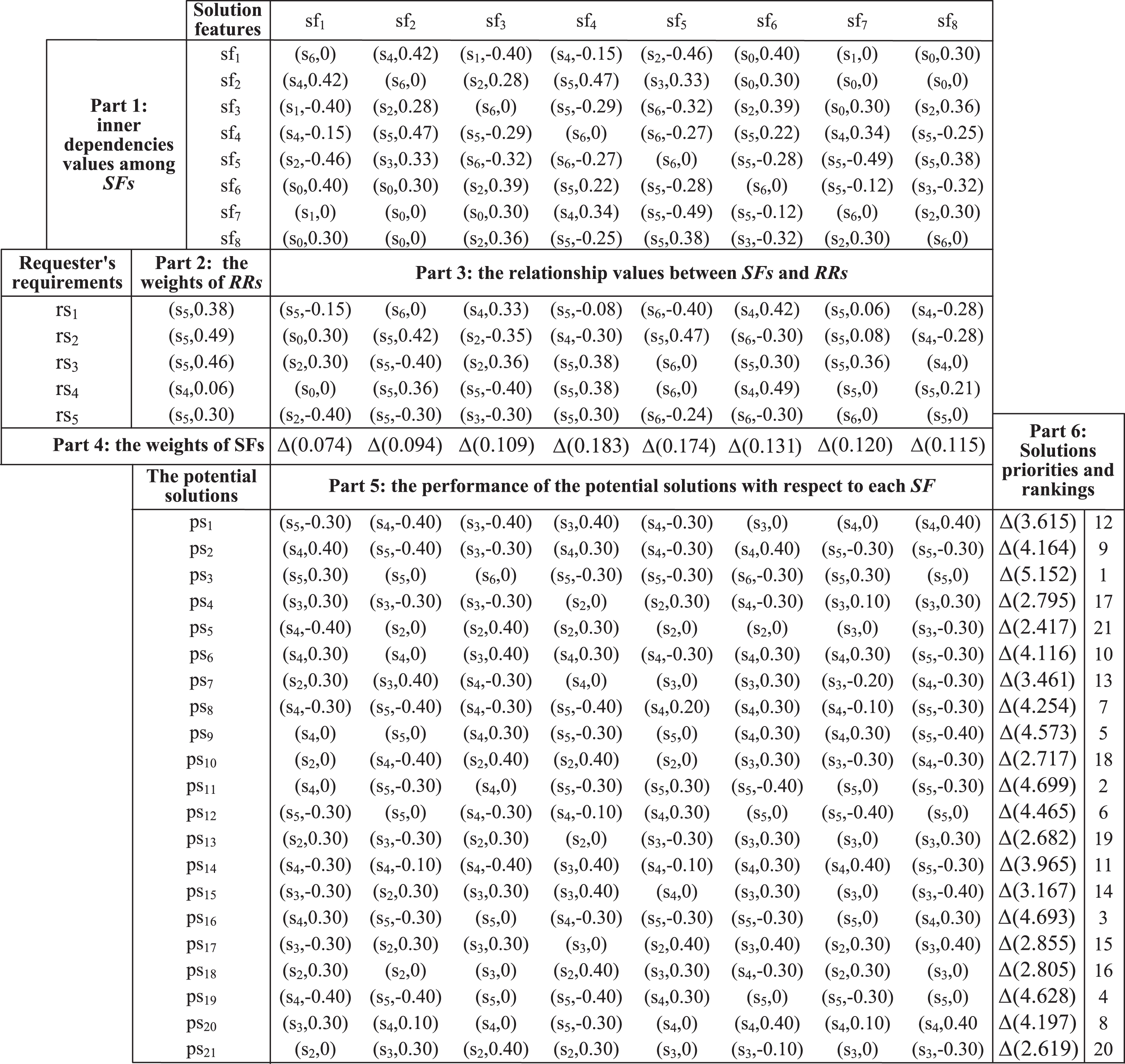
The HoQ model and evaluation results in the case.
For the sake of simplicity, a linguistic term set with seven terms, i.e. S = {s0 : Null, s0 : Very Low, s2 : Low, s3 : Medium, s4 : High, s5 : Very High, s6 : Total}, is presented for three requesters to assess the importance of RRs, the inner dependencies among SFs, the relationship between each RR and each SF. In practice, with ever increasing of amount of solutions and their features, it is hard for requesters to indicate precisely the linguistic evaluation information on the above three aspects using the given linguistic term set in advance. The numerical value α provides flexibility for requesters to applying the linguistic terms. For example, a requester may think that the relationship between sf1 and sf2 may be very high (the defined linguistic term is s5) but less than s6, and thus their inner dependence value can be presented using 2-tuple linguistic variable (s5, 0.2). Furthermore, it is noted that the inner dependence between two features is symmetric. A feature has the strongest dependence on itself, their dependence value is (s6, 0). If there is no dependence between lth and jth feature, their dependence value would be (s0, 0).
For instance, the evaluation outcomes given by the three requesters about the importance value of rs1, the relationship value between rs1 and sf1, and the inner dependence between sf1 and sf2 are ((s5, 0.2), (s5, 0), (s4, 0.3)), ((s5, 0), (s4, 0.2), (s5, 0)), and ((s6, 0), (s5, 0.3), (s4, 0)), respectively. In this paper, we assume that the weights of the three requesters are 0.4, 0.3, and 0.3. By using Equations (6–8), we can obtain aggregation results for w1, v11, and t12:
Meanwhile, we can also determine the importance of five RRs, the inner dependencies among eight SFs, and their relationship values. All the computation results are presented in Fig. 4.
Benefiting from the above matrix, the weight of each feature can be calculated incorporating the importance values of RRs. For example, by employing Equation (10), the weight of sf1 is computed as follow:
Also, the weights of the other seven features can be got, i.e. Δ (0.094), Δ (0.109), Δ (0.183), Δ (0.174), Δ (0.131), Δ (0.120), Δ (0.115), respectively. They are presented in part 4 in Fig. 4.
In the meantime, the performance scores of other solutions can be obtained and presented in part 6 in Fig. 4.
In this section, we compare the proposal in this paper with other related studies in order to demonstrate the advantages and disadvantages in our proposal.
Essentially, solution selection in crowdsourcing contests for innovative tasks belongs to multi-criteria decision making (MCDM) problems. The method of AHP or other methods combining AHP are the most widely used approach. For example, Kilincci et al. [45] proposed fuzzy AHP to address supplier selection problem in a washing machine company. Hadi-Vencheh et al. [26] developed an integrated method of AHP-DEA to deal with the problem of multi-criteria ABC inventory classification. Therein, AHP is applied to determine the weights of criteria, and DEA is employed to determine the values of the linguistic terms which are used to assess each item under each criterion. Ju et al. [46] evaluated emergency response capacity by fuzzy AHP and 2-tuple linguistic method, and Santos et al. [47] segmented suppliers depending on a model based on 2-tuple linguistic representation and AHP. In these two studies, 2-tuple linguistic variables are used to represent experts’ opinions and AHP is used to determine the weights of criteria and overall score of each item. Conducting pairwise comparisons is an imperative step when implementing the methods mentioned above. However, obtaining pairwise comparisons in this paper may become quite complex because the number of submitted solution in a contest is large. Moreover, to assist requesters to select the solution which meets their requirements, this study takes RRs, the inner dependencies among SFs, and the relationship between RRs and SFs into account. It may lead to the AHP method or other approaches, such as fuzzy AHP, fuzzy TOPSIS, and fuzzy VIKOR, that assume the mutual independencies among criteria may not suitable to determine the weights of SFs properly.
The QFD employed in this paper is common and widely used method connecting customer demands/requirements and design alternatives/requirements. A lot of studies focus on scoring customer requirements, measuring design requirements, and determining the relationships between customer requirements and design requirements by combining QFD with other techniques. For example, integrating QFD and DEA to measure the relative importance of design alternatives or design requirements aiming to satisfy customer requirements and other additional factors, such as cost, environment, and producer constraints [23, 48]. The proposed approaches in these studies offer valuable insights to determine the scores of RRs, SFs, and their relationships in this paper. However, they mainly are used to handle the information in QFD, but cannot used to determine the priorities of solutions with a large number. Furthermore, to our knowledge, the QFD also are integrated with other methods such as AHP [42, 49], TOPSIS [50, 51], ANP [52, 53], and DEA [21, 54], etc. to address MCDM problems. As previously mentioned, the AHP, ANP methods which require to carrying out pairwise comparisons to derive the weights of criteria or scores of alternatives cannot be applied to deal with the problem of solution selection in this paper.
To the best of our knowledge, the proposed methodology in [21, 22] is similar, to some extent, to the QFD and 2-tuple linguistic method developed in this paper. These two studies all employed QFD to construct the relationship between customer needs and supplier assessment criteria and their inner dependencies. In [21], an imprecise DEA is used to compute the lower and upper bounds of weights of supplier assessment criteria based on evaluation information in the QFD. In [22], multi-granularity linguistic term sets and 2-tuple linguistic method is used to represent and aggregate experts’ evaluation information presented in QFD to determine the weights of supplier assessment criteria and suppliers priorities. Comparing with the two studies, our research differs from them in the following aspects: (i) The methodology in this paper includes pre-selection phase considering the practical condition of the large number of submitted solutions. Pre-selection plays an important role in the process of solution selection and has several merits: first, reducing the risk of selecting some unqualified solutions in the pool of potential solutions. Second, reducing the workload, time, and energy the requesters must spend to evaluate and integrate information about the performance of each solution with respect to solution features. Third, reducing the risk of neglecting a few qualified solutions in the evaluation and selection phase. By screening each submitted solution with requester requirements in a systematic and transparent way, requesters may not exclude some solutions intuitively and directly and decrease the chance of losing good potential solutions. (ii) For the methodology developed in [21], there is a need to solve the amount of LP models that is equal to the number of alternative users. Consequently, it is a heavy workload of calculation when the number of alternative users is large. On the contrary, our methodology is simple, easy to use, and applicable to complex MCDM problems with a large number of alternatives. (iii) Unlike Karsak and Dursun’s approach adopts multi-granularity linguistic term sets to express various opinions of experts who may vary from each other in cultural and educational background, this study introduces 2-tuple linguistic variables (s i , α i ), which s i denote linguistic terms and α i ∈ [- 0.5, 0.5) represent uncertainty degrees of requesters in qualifying a phenomenon using the given linguistic term set in advance. It may enable requesters to assess and calculate more easily without transforming multi-granularity linguistic term set into a uniform linguistic term set. (IV) Linguistic terms are all used in these two studies to present decision makers expressions. Karsak et al. [22] transform them into triangular fuzzy numbers and then 2-tuple linguistic variables to deal with them, which possibly result in information loss and distortions to some degree. This study utilizes 2-tuple linguistic weighted average operator to aggregate linguistic evaluation information, which does not require such transformation between linguistic terms and fuzzy numbers.
Not unlike any modeling approach, the methodology put forward in this paper exists the following disadvantages: In this paper, we prioritize potential solutions and select one with a total highest score. However, the performance of the selected solution is unlikely to have the highest scores on all the features. The future study will focus on extracting the highlights of each submitted solution and combining them together to form a new solution for requesters. During the process of solution selection, more than one requester may involve in assessing solution performance, the importance of requirements and their relations with solution features. Under the situation, non-cooperative behaviors exhibiting by requesters probably occur due to their different interests and preferences [55, 56]. This study aggregates requesters’ evaluation information representing by linguistic variables by using 2-tuple linguistic weighted average operator but does not take non-cooperative behaviors by requesters into account. In section of discussion, we do not provide the illustrative examples and numerical analysis to verify the merits and demerit of our proposal comparing with other related studies because the structures and procedures used in different approaches are different. This paper only demonstrates advantages and disadvantages of our methodology comparing with some other MCDM approaches. Future study will try to develop some criteria to compare the proposed approach with other related methods.
Conclusion
In crowdsourcing contests for innovative tasks, selecting the right solutions plays an important role in the process of crowdsourcing tasks for requesters. This paper develops a methodology with three phases for solution selection. The first phase is to screen the solutions meeting the minimum requirements. The second phase is to determine the weights of solution features using QFD, 2-tuple linguistic method, and fuzzy weighted average. The last phase is to evaluate the performance of potential solutions and aggregate them with the weights of solution features. To summary, the proposed methodology in this paper enables to incorporate the relationships between requester’s requirements and solution features, and also the inner correlations among solution features in determining the weights of solution features, which is helpful for achieving higher satisfaction to meet requester’s requirements. It also utilizes the advantages of 2-tuple fuzzy linguistic representation to capture human thinking style and to express requester’s vague and subjective opinions. The 2-tuple linguistic weighted average operator is used to aggregate fuzzy linguistic evaluation information avoiding the problem of loss of information. Furthermore, implementation process and results of the illustrate case show that the methodology including three phases proposed in this paper is easy to use, simple, and suitable for requesters to seek the best solution from any number of submitted solutions in crowdsourcing contests for innovative tasks.
Footnotes
Acknowledgments
This work was supported by the National Natural Science Foundation of China (No. 71802002), Key Project of Academic Humanities and Social Science of Anhui Education Department (No. SK2017A0120), the Science Research Starting Foundation of Anhui Polytechnic University for Talent Introduction (No. 2016YQQ008), and the Scientific and Technology Research Program of Chongqing Municipal Education Commission, China (No. KJQN201800832). The author would like to thank the anonymous reviewers and the editor for their constructive comments and suggestions.