
Abstract
The concern for the relationship between demographic changes and asset markets has increased from beginning of 2000. Many researchers analyze the relationship between demographic changes and asset prices through regression models. Most of these studies apply linguistic terms for each different phase of the life cycle (e.g. late working-aged, elderly, adult, and middle-aged) and then define a specific behaviour for each of these cohorts. Although these terms are vague, all the researchers define them as a crisp set with crisp partitions. Additionally, fuzzy regression methods have attracted growing interest from researchers in various scientific, engineering, and humanities area due to the ambiguity in real data. The motivation of this research is that it is rational to consider and apply fuzzy sets to interpret these linguistic terms instead of the crisp partitions. In this study, we propose and apply a new approach in order to calculate the fuzzy frequency for the linguistic term, which can be useful in any other demographic study. Moreover, new fuzzy regression models are developed. These regression models, that are able to consider both fuzzy and crisp regression coefficients are developed based on applying a fuzzy distance concept in which the distance between two triangular fuzzy numbers (TFNs) or between a TFN and a crisp number is a TFN. Multi-objective optimization helps us to find the results without any compromise. The models are solved using the mathematical programming solver LINGO-16 to derive the fuzzy regression coefficients. We apply these models in a numerical example also in a real case study (fuzzy input, crisp output) in which an investigation on the relationship between fuzzy demographic dynamics and monetary aggregates is made.
Introduction
Regression analysis is a widespread technique in various applications from engineering to humanities and medical sciences. Fuzzy regression methods can be applied to consider both crisp and fuzzy data, including an imprecise relationship among variables and/or measurements. According to Muzzioli, et al. [1], the aim of fuzzy regression is to incorporate all the vagueness embedded in the data, without losing the information that is inevitably overridden when the original data is arbitrarily modified or the lack of precision cancelled.
Due to ambiguity in real data, it was expected that fuzzy regression would be more prevalent in data analysis like other fuzzy techniques (e.g., Fuzzy Inference Systems, FIS) since the first approach was introduced by Tanaka, et al. [2]. However, a variety of fuzzy regression models have been proposed with different characteristics in different applications. In the common classification of fuzzy regression research, two basic approaches are the mainstream in fuzzy regression models [3], with a hybrid approach also being used. Possibilistic regression, based on a linear programming approach in order to minimize the fuzziness in the model [2, 4–7] Fuzzy least squares regression, which uses least squares of errors as a fitting criterion [8–12]. Hybrid methods, which use the possibilistic and/or the least squares approach in which other techniques might be considered along with them [13].
Other classifications could be useful due to the common characteristics of various FR methods. These have been developed in this decade, including the following papers: Classification based on fuzziness in input and/or output, (i.e., CIFO: Crisp Input Fuzzy Output [6, 15], FIFO: Fuzzy Input Fuzzy Output [16–19], FICO: Fuzzy Input Crisp Output). Classification based on whether fuzziness in the regression coefficients is allowed [6, 18], or not [20]. Classification based on fuzzy distance or a crisp index as the proxy of the fuzzy distances between output and real data [21–25].
Recently, the distance measures and uncertain information are considered by intuitionistic fuzzy sets. The main advantage of this fuzzy-sets approach is that it is able to consider complex attitudinal characters of the decision-maker by using order-inducing variables in the aggregation of the distance measures [26]. Other recent extensions of fuzzy sets have been developed to model imprecise/incomplete information or other ambiguous in decision-making problems could be applied in future research. (E.g. Type-2 linguistic [27], Pythagorean fuzzy set [28, 29], Attitudinal consensus [30], Hesitant fuzzy set [31] Intuitionistic fuzzy preference relations (IFPRs) and Interval-valued fuzzy preference relations (IVFPRs) [32].)
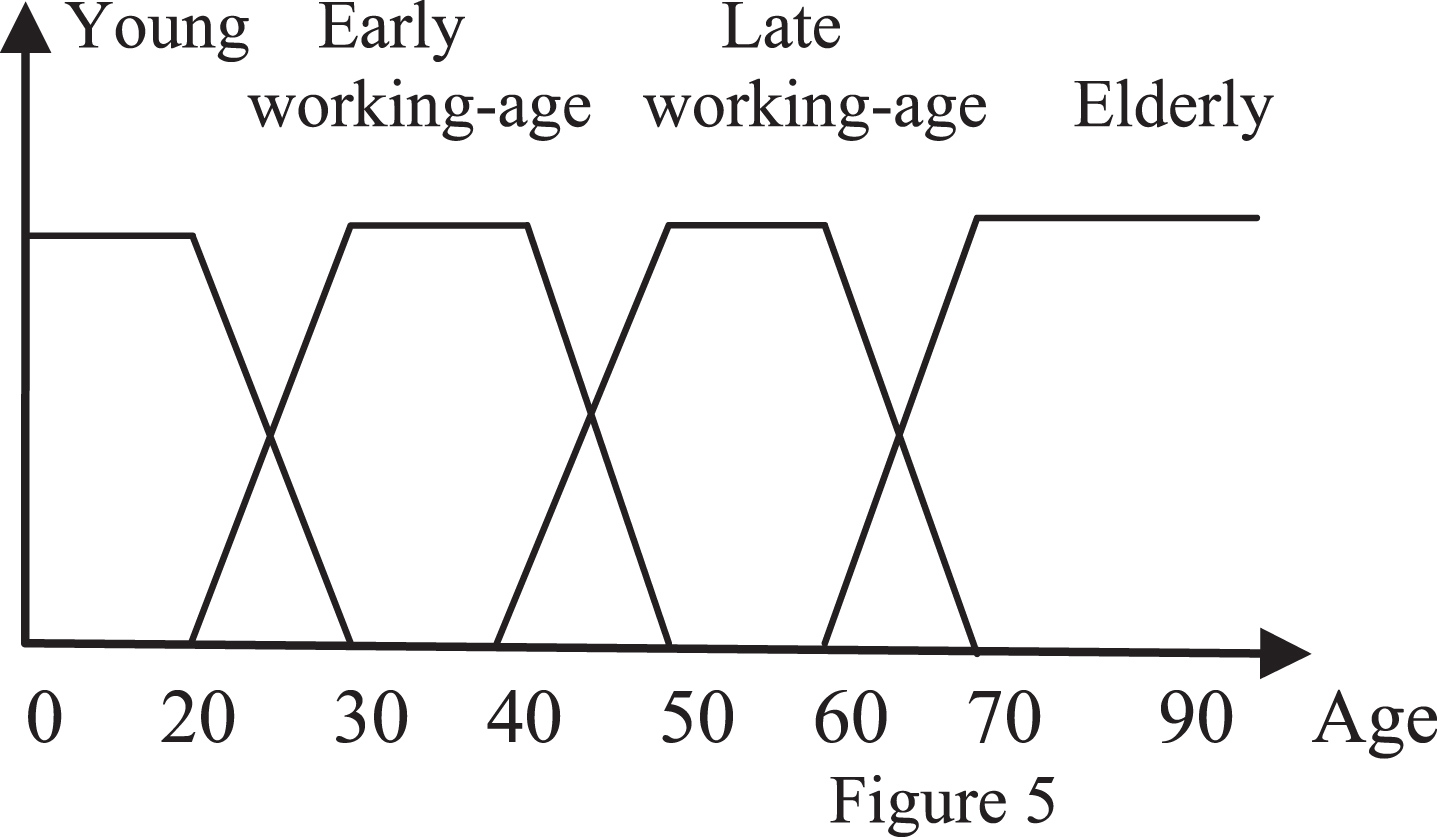
This research was conducted within a larger project analyzing the relationship between demographic factors and asset values, an area of research that has expanded greatly since 2000 involving researchers in economics, finance, actuarial science and related disciplines. Many researchers analyze the relationship between demographic changes and asset prices through regression models. Most of these studies apply linguistic terms for each different phase of the life cycle (e.g. late working-aged, elderly, adult, and middle-aged) and then define a specific behaviour for each of these cohorts. Although these terms are vague, all the researchers define them as a crisp set with crisp partitions. In subsection 5-1 we identify some of the different age definitions used in the literature.
The motivation of this research is that it is rational to consider and apply fuzzy sets to interpret these linguistic terms instead of the crisp partitions. In this study, we propose and apply a new approach in order to calculate the fuzzy frequency for the linguistic term, which can be useful in any other demographic study. Moreover, new fuzzy regression models are developed. These regression models, that are able to consider both fuzzy and crisp regression coefficients are developed based on applying a fuzzy distance concept in which the distance between two triangular fuzzy numbers (TFNs) or between a TFN and a crisp number is a TFN. Multi-objective optimization helps us to find the results without any compromise. The models are solved using the mathematical programming solver LINGO-16 to derive the fuzzy regression coefficients. We apply these models in a numerical example also in a real case study (fuzzy input, crisp output) in which an investigation on the relationship between fuzzy demographic dynamics and monetary aggregates is made.
This paper is structured as follows. In the next subsection, we discuss the problems with using crisp partitions and explain the two aims of this paper: first, we adopt a fuzzy distance for two TFNs as well as multi-objective mathematical programming approach in order to develop new fuzzy regression models in two different scenarios - A crisp-coefficient FR, and a Fuzzy-coefficients FR; second, we show a new aspect of FR models in order to be applied in demographic analysis. In Section 2, we introduce the concept of the fuzzy distance between two triangular fuzzy numbers, which is used in the subsequent analysis. In Section 3, the new Fuzzy Input- Fuzzy Output Linear Regression (FIFO-LR) models, which consider crisp and fuzzy regression coefficients based on the fuzzy distance in multi-objective optimization problems, are developed. An example and implication of the proposed models are also presented in this section. Section 4 deals with the new approach in order to calculate the fuzzy frequency for the linguistic term, which is applied in demographic studies as an independent variable. After that, in Section 5, a case study analyzing work by Nishimura & Takats [33] shows a practical application of our approach, in which we present an investigation on the relationship between fuzzy demographic dynamics and monetary aggregates in Canada versus Japan. The paper finishes with conclusions gathered in Section 6.
Discussion regarding the problems of existing approaches
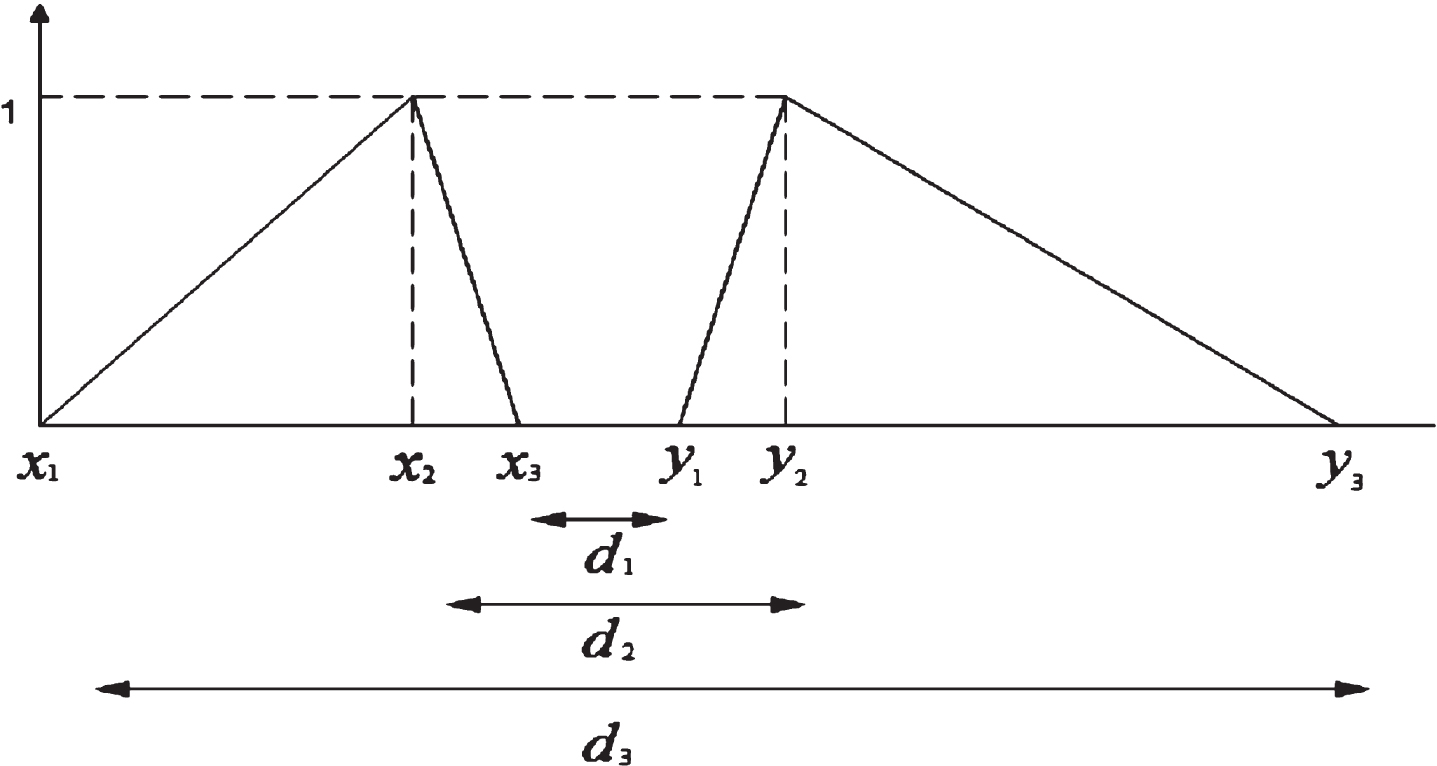
Consistency between the ambiguity of input and the ambiguity of output in a regression model is a critical issue. Most of the fuzzy regression techniques develop a model with a higher degree of ambiguity in order to fit its output to the actual output. This phenomenon is due to using a crisp measure as a proxy of distance in the fuzzy environment. However, the distance between two TFNs or between a TFN and a crisp number is a triangular fuzzy number [34–36].
Let
In all of the fuzzy distance definitions, d
u
will increase with increasing ambiguity of
As the first aim of this paper, we adopt a fuzzy distance for two TFNs as well as multi-objective mathematical programming approach in order to develop new fuzzy regression models in two different scenarios - A crisp-coefficient FR, and a Fuzzy-coefficients FR. We also show that these models are able to cover both prevalent crisp least-squares regression and possibilistic FR.
For crisp data, FR models are particularly useful when an ordinary regression model is not appropriate because it is impossible to verify distributional assumptions or derive a valid statistical relationship. However, as the second aim of this paper, in our case study, we show a new aspect of FR models in order to be applied in demographic analysis. Most of economic theories such as the life-cycle theory [37] use linguistic terms for demographic variables (e.g., population of young people, working-age people). In this paper, we introduce a fuzzy approach to quantify the frequency of these linguistic terms - as fuzzy demographic factors - in order to be applicable in the economic empirical tests. In the case study, this approach, along with the proposed fuzzy regression models are applied to investigate the demographic impact (as a fuzzy independent variable) on the monetary aggregates of Canada and Japan (as the response variable).
The distance for two triangular fuzzy numbers (TFNs)
The distances for two fuzzy numbers can be categorized in two main clusters: The crisp distances: These types of distances explain the crisp values as a proxy of the distance between two fuzzy numbers. They were introduced earlier and have been used in clustering, ranking fuzzy numbers, and regression analysis. The fuzzy distances: These distances introduce a fuzzy distance for normal fuzzy numbers. Voxman [34] introduced a fuzzy distance for the first time. He also stated how it is possible for the distance between two fuzzy numbers to be a crisp number.
Chakraborty & Chakraborty [35] proposed another fuzzy distance in which the general fuzzy number was calculated by LR- Type fuzzy number. Sadi-Nezhad, et al. [36] introduced another fuzzy distance which is applied in fuzzy clustering [38, 39]. Based on their definition, we apply the fuzzy distance for two triangular fuzzy numbers as follows:
Figure 1 shows this fuzzy distance.
Scenario 1: Fuzzy input- Fuzzy output linear regression (FIFO-LR) with crisp coefficients based on fuzzy distance
A linear combination of the explanatory variables is assumed in FLR analysis. A sample of n observations,
The fuzzy linear function to be estimated is as follows:
Where
Where
We define triangular fuzzy number
Where d
l
i, d
m
i and d
u
i are respectively the left point, centre and right point. According to the definition1, d
l
i, d
m
i and d
u
i are as follows:
Model 1: A least squares fuzzy regression model with crisp regression coefficients
A quadratic programming with linear constraints model based on the least squares fuzzy regression approach leads to
This fuzzy objective function is converted to a multi-objective as follows Chen & Hwang [40]:
The final solution of a rational decision maker (DM) is always Pareto optimal, thus we can restrict our consideration to Pareto optimal solutions techniques [41]. Multi-objective models with fuzzy coefficients are always an NP hard problem, and they are especially difficult for nonlinear programming [42] or fuzzy random variables [43, 44]. We suggest the global criterion method in order to consider all objectives as a single objective. However, interactive approaches such as trade-off based methods are more preferable if the DM is available and willing to be involved in the solution process and direct it according to her/his preferences [41]. Model 1, as a crisp quadratic programming with linear constraints model, considers all the aspects.
We define
Model 2: A linear programming model with crisp regression coefficients
In order to develop a linear programming model, we define
Model 2 is a linear programming model in which
Similar to the scenario 1, a linear combination of the explanatory variables is assumed in the FLR analysis in this scenario. A sample of n observations, , is the base of this relationship. Where for observation i,
The fuzzy linear function to be estimated is as follows:
Where
Determining the regression coefficients is a two-stage process. The first stage determines the sign of the
Model 3: A least squares fuzzy regression model with TFN regression coefficients
Similar to the first model, we define
As mentioned in the previous section, using a wide range of regression coefficients makes a worse fit. If one uses the same objective function of model 1 or 2 in model 3, the results of model 3 will not change materially in comparison to scenario 1.
To illustrate the suitability of the proposed fuzzy regression models for solving different types of fuzzy regression problems, we explore an example that is discussed in [22]. This example is a two dimensional linear regression with non-symmetric fuzzy input and fuzzy output. It is noteworthy that all of the previous researches has applied a crisp criterion in order to compare the goodness of fit for the total error between methods, and none of them applied a fuzzy distance. Our proposed models do not have any restrictions with respect to non-symmetrical data, negative input and output, negative intercept, and/or other regression coefficients.
This example includes fifteen observations, which are shown in Table 1.
Fifteen fuzzy observations (input and output are TFNs)
Fifteen fuzzy observations (input and output are TFNs)
Models 1, 2, and 3 are solved using the mathematical programming solver LINGO-16 to derive the regression coefficients. These three fuzzy regression models are as follows:
Table 2 depicts the fuzzy distance between the real fuzzy observations and the fuzzy output for all the fifteenth cases. Figures 2–4 show the output of these models and the fifteen real observations.
The fuzzy distance between the real fuzzy observation and the FLR output
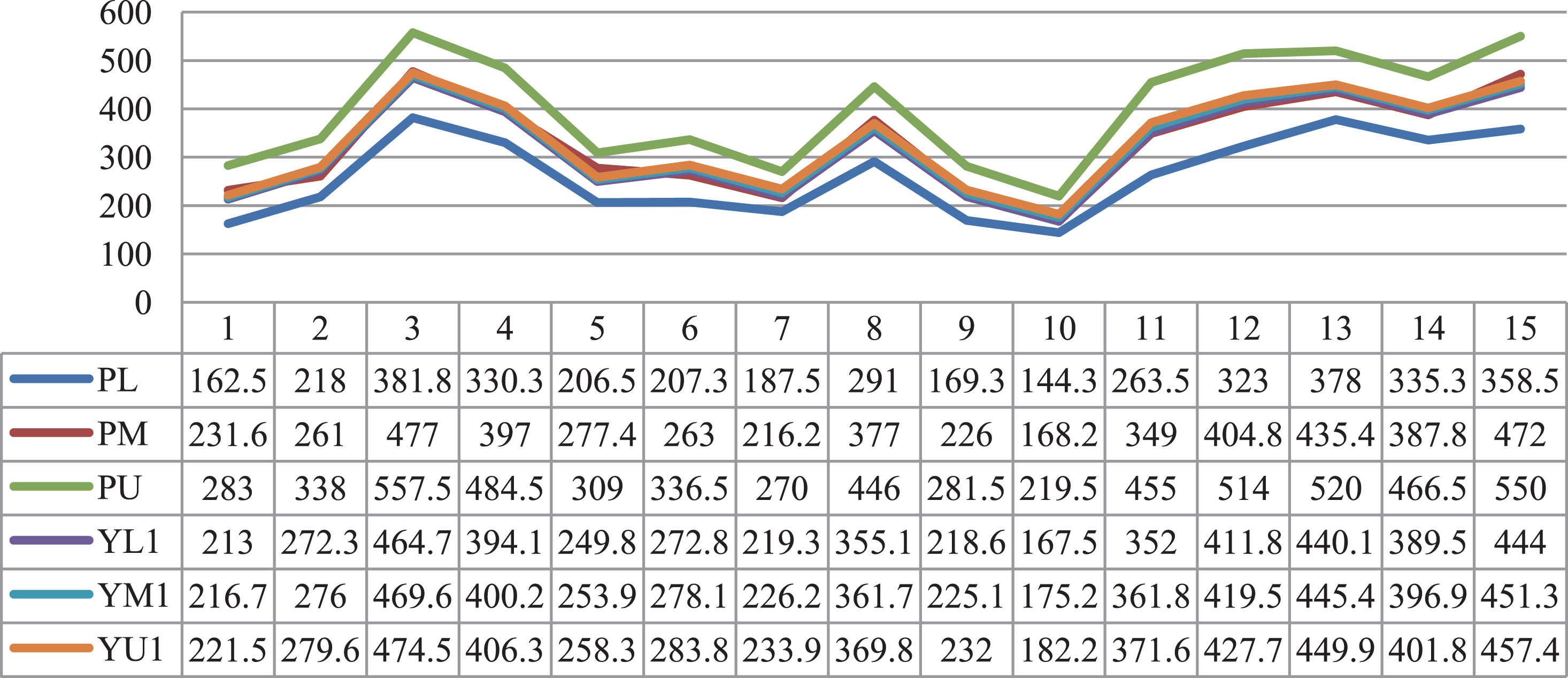
The output of model 1 and the real observations.
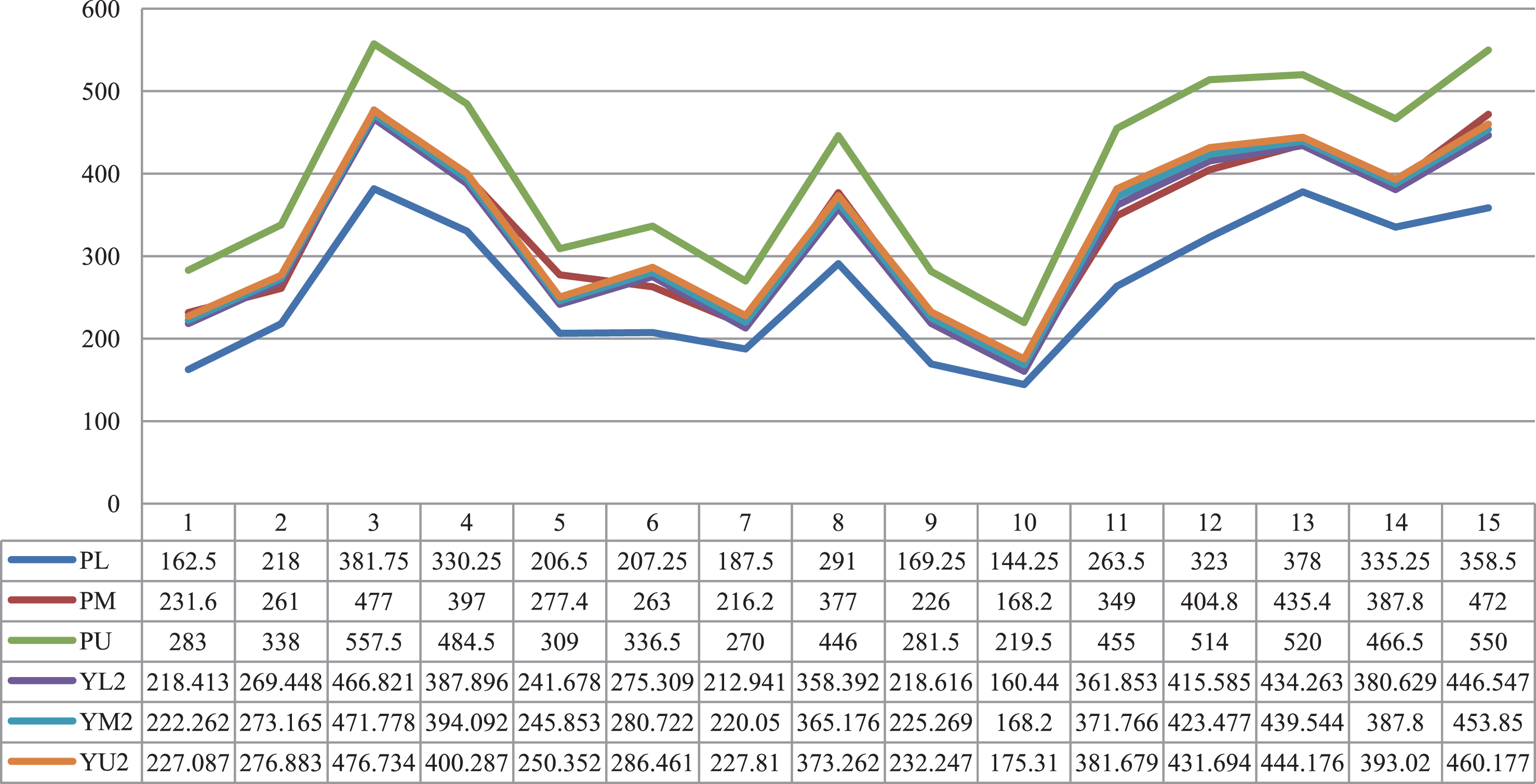
The output of model 2 and the real observations.
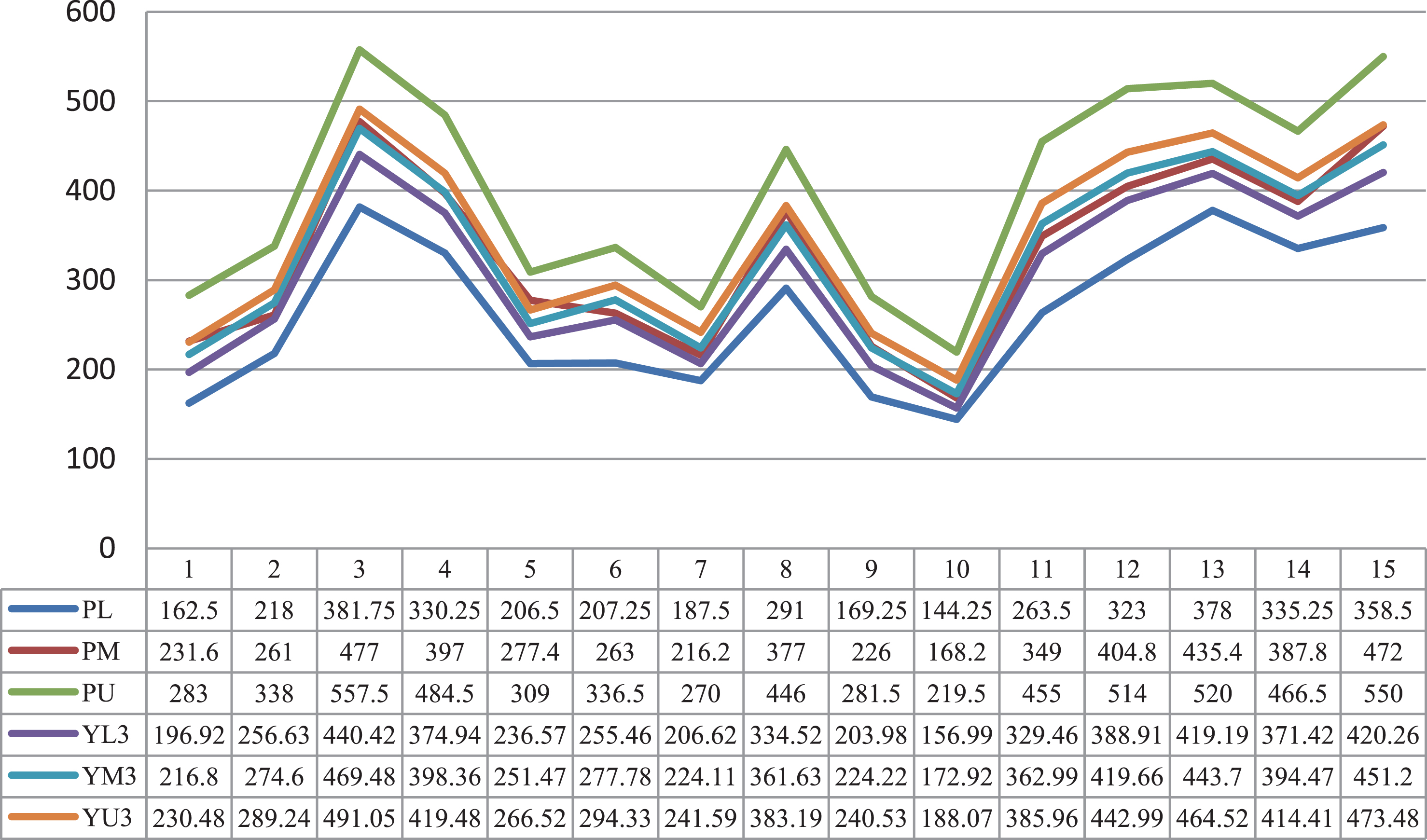
The output of model 3 and the real observations.
Because the input is fuzzy, it is a great advantage for the decision maker to consider real fuzzy distances in her/his fuzzy regression model without any compromise.
There are several ways to measure the cardinality of a fuzzy set, extending the classic one in different ways. (Some of them have been employed for calculating the accomplishment of quantified sentences 1 and it is not related to this study.) The most common approaches are the scalar cardinality and the fuzzy cardinality of a fuzzy set. The first approach claims that the cardinality of a fuzzy set is measured by either integer or real means of a scalar value; whereas the second approach assumes the cardinality of a fuzzy set is just another fuzzy set over the non-negative integers. Among the latter, it is common to consider that the cardinality of a fuzzy set must be a fuzzy number, i.e., normalized and convex. Fuzzy numbers are one of the best choices for representing restrictions like linguistic quantifiers, and their arithmetic is that of restrictions.
Scalar cardinalities
De Luca & Termini [45] who named this as the power of a finite fuzzy set proposed the scalar cardinality. The power of a finite fuzzy set A is given by sum of the membership degrees of the fuzzy set A. Accordingly, the scalar cardinality of fuzzy set
A: Ω⟶ [0, 1] is defined as the sum of the membership degrees of finite fuzzy set A.
|A| is called the sigma- count of A. Zadeh [46], a pioneer of fuzzy sets, investigated the concept of sigma count for fuzzy sets and its applications [47].
The real problem with scalar measures is that they are not really suitable for providing precise information about the cardinality of a fuzzy set. Using a scalar measure of the cardinality is like using a crisp set for representing a fuzzy set. That is, we are losing information for the sake of obtaining a simpler and more easily manageable measure. The problems with this approach are either that it is not always representative, or that it loses too much information.
Fuzzy cardinalities
“Note that the cardinality of fuzzy sets, especially in the case of finite fuzzy sets, has many applications. Generally, the cardinal theory of fuzzy sets can be used in all situations, where one wants to compare sizes of families of elements satisfying a certain property or to count the number of elements in a family that satisfy a certain property. Whereas, the property is not precisely specified, which means, one cannot surely decide that the property is true or false for considered elements. (e.g. to be young, tall, clever, or rich for certain families of males and females). For instance, measuring sizes of finite fuzzy sets can be used in fuzzy querying in databases, expert systems, evaluation of imprecisely quantified statements, aggregation, decision making in fuzzy environment, metrical analysis of gray images, calculation of histograms of colors and dominant colors [48].”
However, there are many ways of counting fuzzy sets. One of them is introduced as an example where the cardinality of a fuzzy set is defined to be k to a certain degree. According to this approach the fuzzy cardinality of a fuzzy set A is defined by
Example 1 depicts how to calculate the fuzzy frequency for one of the linguistic terms in a specific year based on the fuzzy cardinality.
Example 1
Let the Early working-age population set is defined based on Fig. 5, and the age-structure of the population at the life-stage between t-1 and t follows Table 3. Now, calculation of the fuzzy frequency (the number of elements in the Early working-age population as a fuzzy set) is as follow. (Table 4)
The Early working-age set (year t)
Calculation of the fuzzy frequency
*The number of people belong to set of
From Equation (11), it is concluded that the fuzzy cardinality |A|
f
is a fuzzy convex set and the possibility [49] that A has at least k elements is:
Where j =
Note that |A| f (k) = Poss (|A| = k), where Poss denotes a possibility measure and operator “∨” is a t-conorm (or s-norm) operator e.g. max-operator.
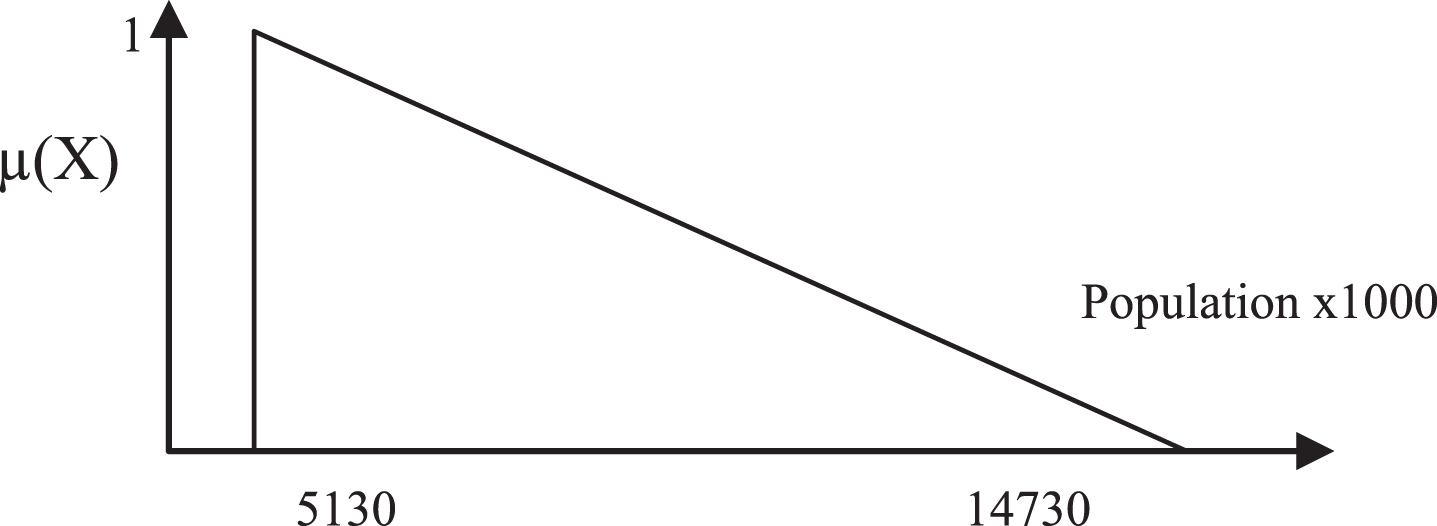
Although the result in Fig. 6 is a discrete fuzzy set, one might use it as a Triangular or LR Fuzzy Number in the model.
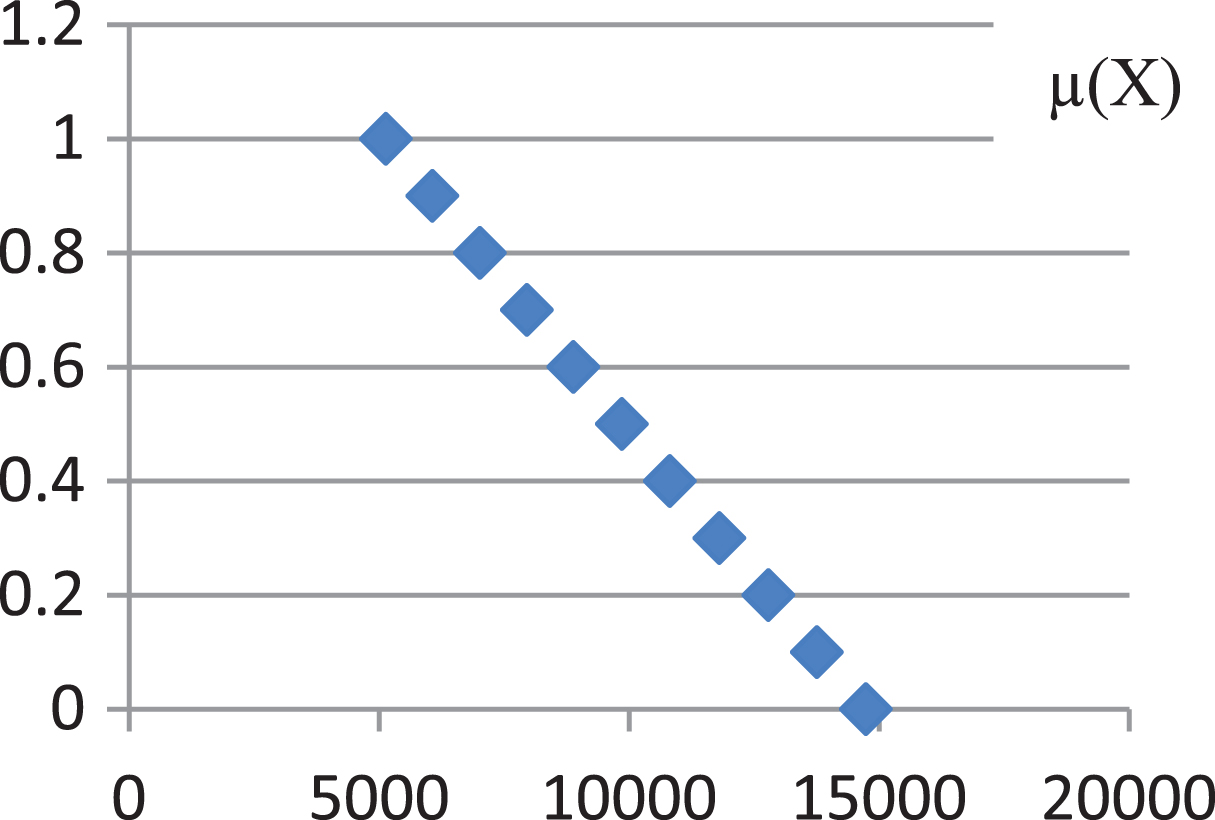
A discrete fuzzy set.
In this case, Early working-age at year
Introduction to demographic studies based on the life-cycle theory
Demographic studies have encompassed a number of various factors since it started in a modern sense in the 17 century by John Graunt. Demographic trends are very smooth, they do not contribute to the short run noise but they are a natural candidate to capture the information that emerges in the long-run. These factors assist researchers to study every kind of dynamic population behaviour and their changes over time. Specific age intervals are noteworthy from economist and financial specialist point of view.
Based on the life-cycle theory [37], a consumer aims to smooth consumption over his lifetime by making appropriate saving/dissaving decisions. As a result, the portfolio choices over different phases of the life-cycle imply a strong imbalance between demand and supply of capital. A number of theoretical models look at the possible link between demographic dynamics and financial asset returns, in particular, the link between age and financial asset returns. Most of these studies claim that a significant relationship between demographic dynamics and asset returns is plausible; however, the magnitude and hence the quantity of this for financial markets are not clear. Therefore, the empirical studies take a leading role in this regard.
According to Roy, et al. [50], school entry age, labor market entry age, age at marriage, age at child-bearing, and retirement age all differ across countries relative to similar cohorts a decade ago. In general, people are spending more years in education, entering the labor force later, delaying marriage and child rearing, and enjoying longer and more uncertain post-retirement periods. As a result, they suggest the need to redefine the age ranges traditionally used to explain asset prices and economic variables in the future.
Moreover, the demographic variables included in the all the previous models were selected in line with other existing empirical work. Most of these empirical studies apply linguistic terms for every different phase of the life cycle (e.g. late working-aged, elderly, adult, and middle-aged) and then define a specific behaviour for each of these cohorts. Although these terms are vague, all the researchers define them as a crisp sets with crisp partitions like 20–40, 40–64, or 65 + . Is it rational to consider that an investor’s behaviour changes at exact ages (i.e., 20, 40, 64, 65), or is a better approach to apply fuzzy sets in order to interpret these linguistic terms?
A list of the different definitions for age intervals, which are considered as independent variables, comes in the following.
Set of three linguistic terms (young, middle age, and old age) and their related ratios [51–56]
Set of four linguistic terms, People aged 0–14, People aged 15–39, People aged 39–64 years, and People aged 65+ are named young, low middle age, high middle age and old age respectively [57–60]
Seven age groups with 10-year intervals i.e. (age < 20, 20–29, 30–39, 40–49, 50–59, 60–69, 70 < age) [60–62]
Fifteen age Groups with 5-year intervals i.e.
This case study intends to introduce and apply fuzzy sets for the linguistic terms that are mentioned in the life-cycle theory. Consequently, this study has to employ fuzzy frequency for every cohort and develop a fuzzy model based on fuzzy demographic factors. In this real case study, we investigate the impact of the demographic changes on monetary aggregates in Canada and Japan. Moreover, this section deals with a new approach in order to calculate the fuzzy frequency for the linguistic terms, which are applied in demographic studies as independent variables. In particular, this study is based on Nishimura & Takats [33] in which the size of the working-age population during a demographic transition raises the Marshallian K, the ratio of a broad monetary aggregate such as M2 to nominal GDP. This is a real application of the fuzzy input- crisp output case.
To investigate the impact of demography on the money supply, as in Nishimura & Takats [33], we use the following regression for Canada and Japan:
In order to determine the impact of the size of the working-age population as the fuzzy demographic factor on monetary aggregates in Canada and Japan we follow these steps.
Defining the working-age set as a linguistic term through fuzzy sets
Preparing data
Calculating the fuzzy frequency and fuzzy demographic factors for the linguistic term in each year
Applying the fuzzy regression models 1 to 3,
Solving the models and interpreting the results
Defining the working-age set as a linguistic term through fuzzy sets
Let X be a linguistic variable with the label “life-cycle” (i.e., the label of this variable is “life-cycle,” and the values of it will be called “Age”) with U = [0, 100]. The terms of this linguistic variable are again fuzzy sets. (They could be called late working-age, elderly, adult, entire, middle-age, and so on.) The base-variable u is the age in years of life. μ(X) is the rule that assigns a meaning, that is a fuzzy set, to the terms. Figure 8, shows the working-age set as a linguistic term through continuous fuzzy sets; however, we calculate them yearly or assume them as TrFNs (Trapezoidal Fuzzy Numbers).
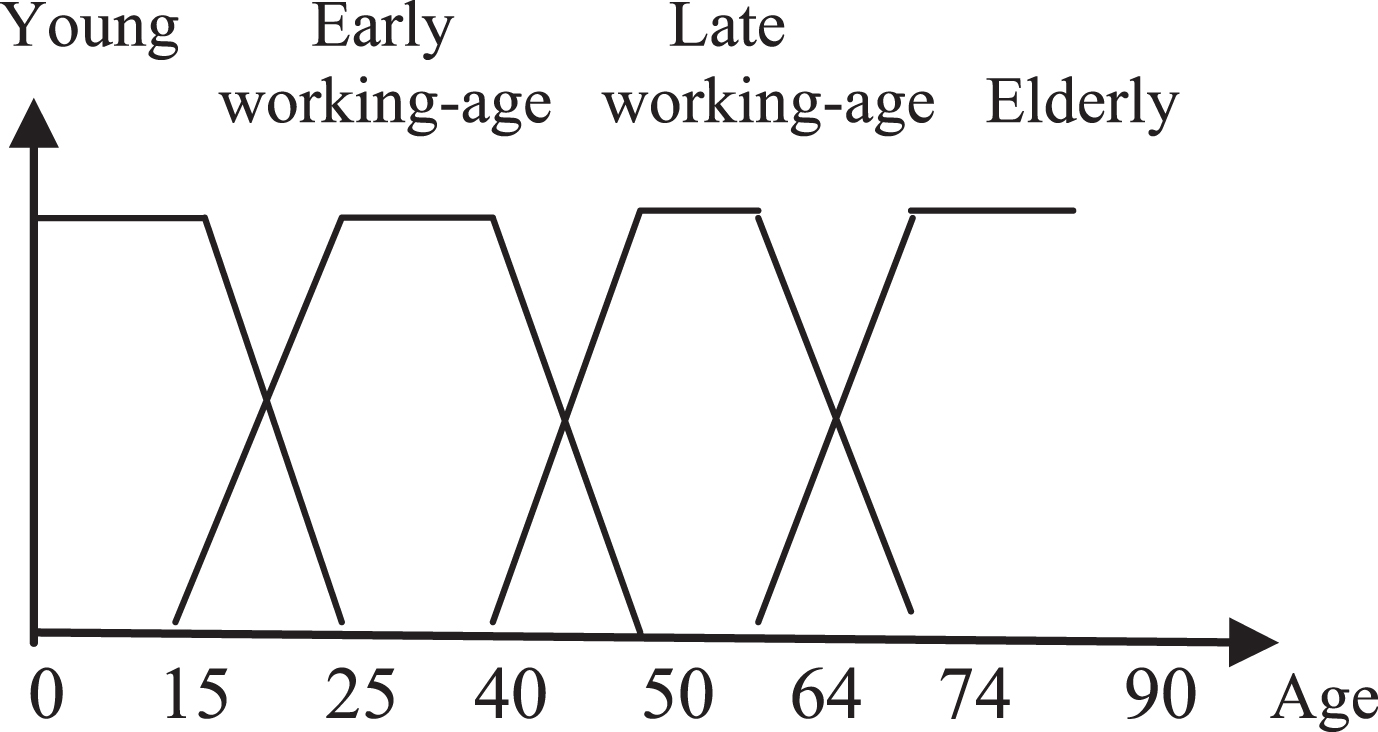
Working-age set = Early working-age set U Late working-age set.
We use data for the postwar period as it is the longest period available.
Yearly demographic data (1950-2012): come from the UN Population Projections database.
The Marshallian K- the ratio of money supply to nominal economic output M2 (1970-2015 for Canada and 1980-2015 for Japan) is used for the money supply i.e. cash, checking deposits and near money where near money refers to savings deposits, money market securities, mutual funds and other time deposits.
In order to consider economic output, the nominal GDP (current US$) and GDP at market prices (constant 2010 US$) is used. (1960-2015)
We use logarithmic differences in M2 as a percentage of the nominal GDP over the full period
We use data from 1970 to 2012 for Canada and 1980 to 2012 for Japan, which are a common period for all variables. Figure 9-a and 9-b depict yearly changes in the natural logarithm of the fuzzy size of working-age population for Canada,
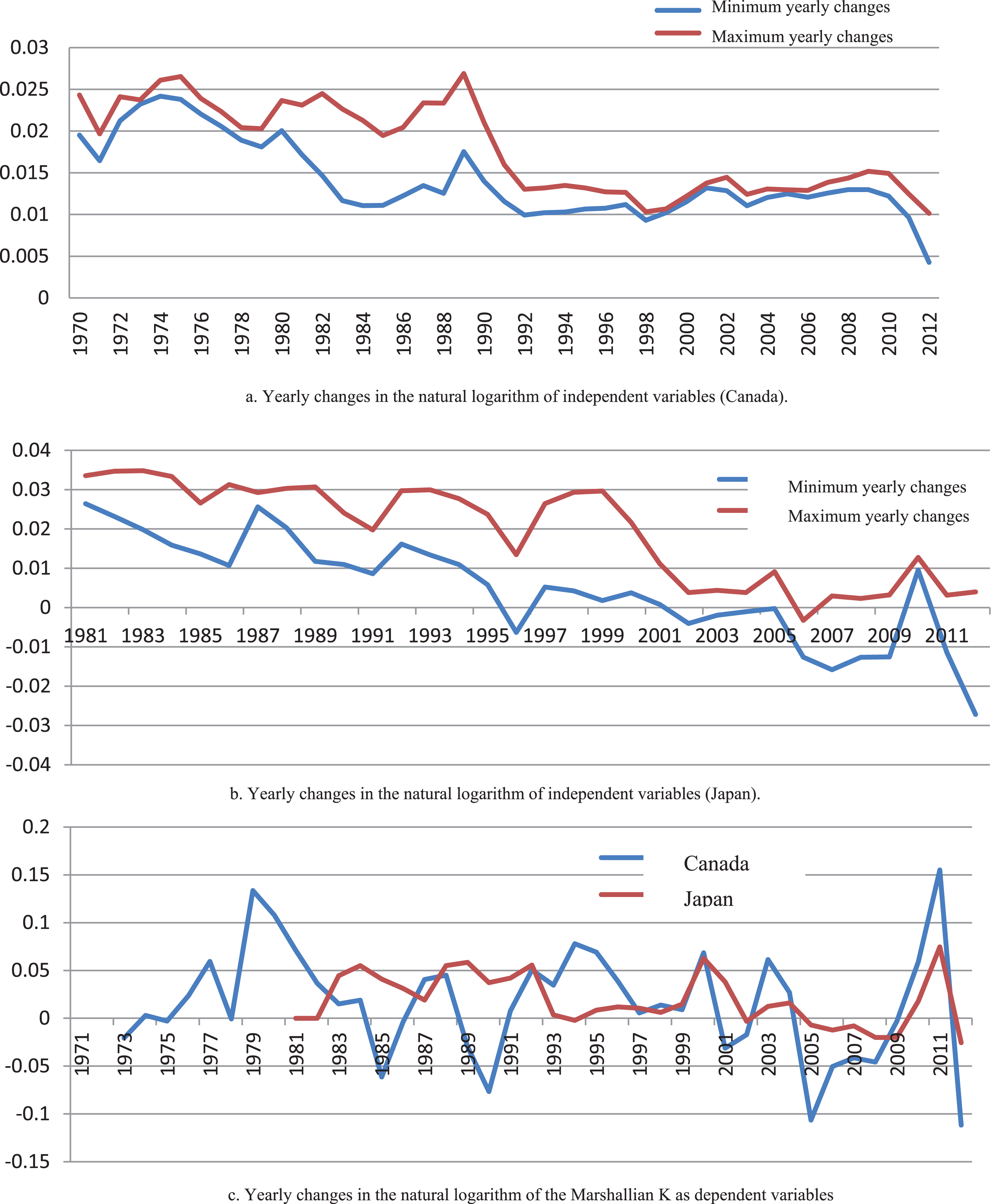
a) Yearly changes in the natural logarithm of independent variables (Canada). b) Yearly changes in the natural logarithm of independent variables (Japan). c) Yearly changes in the natural logarithm of the Marshallian K as dependent variables.
To calculate the frequency of the working-age in every year we use the age-structure of the population at the beginning of each year, which is the population at each life-stage between t – 1 and t. Then, it is possible to calculate the fuzzy frequency 3 for the fuzzy sets in our case, working-age. Section 4 clarifies this step through an example, and we provide logarithmic differences of fuzzy population.
Applying the fuzzy regression models
Using the data prepared as described and the mathematical programming solver LINGO-16, results of the models are shown in Table 5. 4
Results of the proposed fuzzy regression models
Results of the proposed fuzzy regression models
Because of using the natural log for the independent and dependent variables in the reference model [33], Triangular Fuzzy Number
Nishimura & Takats [33] claim that demography does explain a substantial part of the long-run variation in the Marshallian K based on a panel regression analysis. Whereas, in our fuzzy models, there is not a strong evidence for Canada. Neither is there strong evidence using crisp models. On the other hand, demography (late working age) does explain a substantial part of the long-run variation in the Marshallian K for Japan. However, they also mentioned that “in many advanced economies, demographic factors will stop contributing to money supply growth and will start to reduce the Marshallian K.”
In particular, due to the results of Table 5, the elasticity of Marshallian K with respect to fuzzy working-age population is zero
In order to figure out a possible relation between Marshallian K as the dependent variable and any characteristic of size of fuzzy working-age population – wL, wM, and wU- as the independent variable, we use three crisp linear regression analyses separately for wL, wM, and wU for and use three crisp linear regression analyses for Japan. Table 6- depicts the results of these analyses. It shows that there are not any significant evidences regarding this relation for Canada but there are significant linear relations for Japan.
The results of crisp regression analyses between Marshallian K and wL, wM, and wU
In this paper, we apply a new approach in order to calculate and apply the fuzzy frequency for the linguistic terms related to the size of working-age population, which will be more robust in comparison to the crisp partitions. This approach could be useful for any other demographic factors e.g. school entry age, labor market entry age, age at marriage, age at child-bearing, and retirement age in the economic studies. We have also reviewed the relevant articles on fuzzy linear regression and provided a new approach to determine fuzzy or crisp regression coefficients through three different models based on fuzzy distance. We have applied the models using an example and a case study. Besides the rationality of these models, due to the quadratic programming, our approach matches the observed and predicted values reasonably well.
The results obtained in this work indicate that fuzzy regression with fuzzy distance can effectively enhance forecasting under ambiguities in economic studies. There are several advantages of the proposed methodology. First, the basic principle of the fuzzy distance is rational and simple, yet can provide deep insight into characteristic ambiguity in real data. Secondly, these fuzzy regression models are useful when one faces a combination of crisp and fuzzy data simultaneously. Thirdly, the proposed models do not entail complicated decision-making about selecting the proper objective function. Thus, decision makers are able to trade off between the weights of d l , d m , and d u and select other objective functions in order to lead to improved forecasting results.
We have also presented two fuzzy models that show the demographic changes are not associated with changes in monetary aggregates in Canada but they are in Japan. In particular, the size of the fuzzy working-age population during a demographic transition does not impact on the ratio of money such as M2 to nominal GDP, the Marshallian K for Canada. In contrast, the size of the late fuzzy working-age population during a demographic transition is associated with a change in the ratio of money to GDP for Japan.
Although fuzzy frequency for the linguistic terms constructed in present research for the first time should be helpful in real world problems, a detailed comparative analysis by using other approaches is necessary for solving similar problems of manufacture, finance, economic, and actuarial science area in future.
Footnotes
Acknowledgments
The authors acknowledge the support received from the following sponsors: SSHRC, the Canadian Institute of Actuaries, the Institute and Faculty of Actuaries, the Society of Actuaries, the University of Kent, and the University of Waterloo; as well as the co-applicants for the SSHRC grant: Lori Curtis, Miguel Leon-Ledesma, Jaideep Oberoi, Kathleen Rybczynski, Pradip Tapadar, and Tony Wirjanto.
The authors would like to thank the anonymous reviewers for their constructive suggestions.
3 Determine the number of elements of a set i.e. working-age
4Model 2 is not recommended in this special case due to its sensitivity to cases with negligible changes. In this case study, logarithmic periodic change is the dependent variable.