
Abstract
Managing and Mining mobile sensor data has become a topic of advanced research in several fields of computer science, such as the distributed systems, the database systems, and data mining. The main objective of the sensor based applications is to make the real-time decision which has been proved to be very challenging due to the high resource-constrained computing and the enormous volume of sensor data generated by Wireless Sensor Networks (WSNs). This challenge motivates the sensor research community to explore new data mining techniques to extract information from large continuous raw data streams obtained from WSNs. Existing traditional data mining methods are not directly suited to WSNs due to the aggressive nature of sensor data and the presence of anomalies or outliers in WSNs. This work provides an overview of how traditional outlier detection method algorithms are revised and implemented in the application of Human Activity Recognition (HAR). Based on the limitations of the existing technique, a hybrid outlier detection method is proposed.
Introduction
Real-time applications of Wireless Sensor Networks (WSN) yield a vast amount of dynamic raw sensor data. This raw data can be utilized in many applications if transformed into usable information through data classification. However, WSN has challenging issues like limited power supply, random deployment, lossy communication environment, high failure rate...etc. These challenging issues make traditional data mining techniques unsuitable because existing data mining techniques are centralized and computationally expensive [4, 22]. Therefore, new algorithms have been developed and a few of the existing data mining algorithms have been modified to handle the data generated from sensor networks. This proposed work is focused on outlier detection and sensor data classification. Classification in sensor data is identifying the classes of events or observations on the basis of a training dataset [28, 38]. Classification is a popular issue in the field of information retrieval because it can be applied to a number of research areas, such as data classification, pattern recognition, image classification, text classification, web page classification etc. Still, almost all of these classification techniques are susceptible to outliers and endure a loss in efficiency due to the presence of outliers or anomalies in the dataset. Existing research works has proved that a dataset with less noise or outliers ensures improved classification results when compared to a dataset with outliers. An outlier in sensor networks is defined as an observation or a data point that is considerably dissimilar to or inconsistent with the remainder of the sensor data [2, 28]. Wireless sensor networks may include a huge number of sensors, the possibility of error is more than other traditional networks. These issues make WSN more liable to anomalies. Outlier points should be detected and removed as it intensely affects the sensor data analysis [21, 49]. Detecting and removing the outlier data points increases the standard of measured information and improves the robustness of the sensor data analysis under the presence of noise and defective sensors so that the communication overhead of unwanted data is diminished. In many applications anomalies are more attractive than normal data [14]. A very standard case where the attention gets focused on the anomalies or outliers instead of normal data or inliers is fraud detection in online transactions because it is more likely to detect the fraud details. With a relatively large number of features or attributes present in a dataset, it becomes a very difficult task to identify and remove the outliers present in the entire data set.
Now a day’s mobile sensor technologies are gaining interest in different research domains due to the use of significantly miniaturized electronic components, with low power consumption, which makes them ideal for applications in Human Activity Recognition (HAR) for both indoor and outdoor environments [1, 15]. These applications allow users to achieve a natural execution of any physical activity, while providing good results in practical applications, such as health rehabilitation, respiratory and muscular activity assessment, sports and safety applications...etc [23, 50]. However, in real time environments, the collected sensor data are affected by several factors related to sensor data alignment, data losses, and noise among other experimental constraints, affecting data quality and model accuracy. Nowadays mobile phones are equipped with an assortment of sensors like accelerometers, gyroscope and magnetic field sensors. In recent years many researchers started using smart mobile phones for human activity recognition [8, 24]. The Human Activity Recognition problem is computationally difficult because, unlike normal activities, the outlier data are extremely inadequate. Therefore, it is a challenging task to design an outlier detection and removal model that can improve the performance of an activity recognition system. Due to the aggressive and resource constraints nature of sensor networks the existing outlier detection and removal methods cannot be directly applied to the HAR model. The main intention of this proposed work is to develop an outlier detection method for sensor data for human activity recognition.
This article is organized as follows: section 2 gives related works, section 3 describes about motivations and contributions, section 4 explains about proposed methodology, section 5 formalizes to experimental setup for HAR, section 6 explains about experimental analysis, section 7 depicts about results and discussions and finally, the paper ends up with a conclusion and future research directions.
Related works
This section explains various outlier detection techniques based on the methodology for WSNs. In statistical based outlier detection methods, based on a distance measure a data point is declared as an outlier if the probability of the data instance to be generated by the outlier model is very low [39, 51]. These techniques usually pose low communication and less computational complexity as they declare the most distant points as outliers based on data distribution. In nearest neighbor based outlier detection techniques, a data point is distinguished as an outlier when it is located far from its neighbors. These methods require the euclidean distance measure between each pair of data which prompts to most prominent computational complexity [38]. In clustering based outlier detection algorithms, data points are grouped to form clusters and the distance measure is utilized to identify outliers [7, 43]. In classification based outlier detection, support vector machine (SVM) and Bayesian network classification model are used [29, 37]. The computational complexity of cluster-based and classification based techniques strategies are more notable than statistical based techniques.
Human Activity Recognition is an emerging and challenging area of research [1, 40]. Many machine learning based studies exist on activity recognition that uses accelerometers [8, 29]. Much of the existing studies in activity recognition focused on major activities, such as sitting, standing, sleeping, running, walking and jumping [5, 50]. In HAR literature, studies were done both using a single sensor and a combination of multiple sensors. Few works proposed a physical activity monitoring system based on multiple sensors. These systems are able to recognize sitting, standing and lying body postures, as well as periods of walking with the aim of monitoring elderly people in their daily lives [16, 20], showed that use of multiple sensors is not helpful for significantly improving recognition for typical physical activities. Many works exist for outlier detection in the sensor network [13, 51] but further research is still needed, particularly in activity recognition.
Most existing HAR systems make the focus on human activities detection without considering data outliers. Though many machine learning based outlier detection techniques were proposed for various applications in WSNs, studies on outlier detection for human activity recognition in WSNs is rare. Based on the literature reviewed, the focus of this work is on outlier detection in wireless sensor networks for human activity recognition. An outlier detection method is proposed and evaluated on two datasets collected in various environments. The effect of outlier detection is empirically evaluated using standard classification methods.
Motivations and contributions
Real-world applications such as smart home monitoring, patient monitoring, sports activities and so forth have increased the accessibility of sensors and raised interest in Human Activity Recognition (HAR). Particularly, the prevalence of mobile devices, such as the smartphone with sensors, can offer advanced capabilities to recognize human activities in wireless sensor networks. However, the raw sensor data collected from the wireless source are quite often inaccurate and unreliable due to the design issues of sensors devices in terms of lifetime, energy, memory, bandwidth, computational power, dynamic nature of the network, and harshness of the node deployment environment. These inaccuracies are referred to as anomalies or outliers. A solution to ensure the eminence of mobile sensor data is detected and removes outlier data. Outlier detection is a particularly important task in various applications of wireless sensor networks [37, 42]. Recent researchers contribute to various outlier detection methods for sensor data. Applying traditional outlier detection methods on sensor data experience the ill effects of a high false positive rate, especially, when the collected sensor information is biased toward normal data while the anomalous events are rare. It is essential for a data analyst to detect outlier data in order to take proper actions. Human Activity Recognition is one of the application areas where more abnormal activities are present. This motivates us to explore outlier detection methods for HAR.
The basic idea of the proposed outlier detection method is to combine the advantages of two or more standard existing outlier detection methods. Authors in [11] proposed hybrid outlier method named FUCOD ((FUzzy Combination of Outlier Detection techniques) which combines distance based, density based, cluster based and distribution based outlier methods. Another hybrid approach named Pruning-based K-Nearest Neighbor (PB-KNN) was proposed by Yan. et al. which integrates the density-based, cluster based method and KNN algorithm to conduct effective outlier detection [45]. Two more hybrid combinations of density-based outlier detection method LOF with the clustering k-Means and the density based LOF, with the density based DBS can clustering results was proposed [46]. Aggarwal et al. in [2] in discussed outlier ensemble methods can solve the bias-variance problem and discuss many outlier combinations or aggregation methods. The above mentioned existing methods gave an idea to remove outliers using hybrid methods [2, 46]. These combination outlier detection methods can be applied to the classification model as well as to compare the performance of the classification model with outlier removed data set and without outlier removed dataset.
We proposed (Nivetha, Venkatalakshmi; 2018) in [31] a proficient outlier detection and removal algorithm, Hybrid Outlier Detection (HOD) specifically useful in supervised classification problems. This hybrid model combines the advantages of two or more standard distance and density based outlier detection techniques. This hybrid outlier detection method is proposed to detect and remove anomalies or outliers in mobile sensor data with enhanced classification accuracy. In our existing work, we classified human activities, such as walking, jogging, standing, sitting, walking upstairs and down stairs. The experimental analysis for classification is carried on two different activity recognition datasets collected from various environments. The HOD method was implemented and tested with the Support Vector Machine (SVM) classifier and Radial Basis Function Neural Networks (RBFN) classifier. The performance of the SVM classifier is superior to RBFN classifier [31]. In order to further enchance the performance of HOD, an improved HOD (IHOD) method is proposed with SVM classifier.
The foremost focus of this proposed work is to evaluate various individual outlier detection methods for online and offline human activity recognition data over WSNs.
Proposed methodology
In this section, the proposed approach is explained in detail. Many recent works were developed on machine learning based activity recognition that is interested only in activity and did not care about outliers [20, 48]. In this proposed work, a variant of hybrid outlier detection approach is designed to detect outliers. The methodology consists of the following five steps Data collection: Two different datasets DS1 and DS2 are used for analysis. These two datasets differ in their properties such as a number of activities, instances, features, and environment used for data collection. Feature extraction: Raw continuous time-series data from the mobile accelerometer cannot be directly applied to the classification model. Therefore the collected data are subjected to a feature extraction process. The transformed dataset represented using feature extraction is used for further processing. Outlier Detection and Removal: The density based, distance based, cluster-based and the proposed improved Hybrid Outlier Detection methods are applied to both datasets DS1 and DS2. Classification: The extracted feature set is processed to Support Vector Machine (SVM) to classify the activity labels Evaluation: The various evaluation metrics are computed to show the effectiveness of the outlier removal in wireless sensor data for human activity recognition.
Hybrid outlier detection (proposed)
In our proposed hybrid approach, the dataset (DS) consists of activity samples which represent the activities performed where ‘xi’ represents the accelerometer readings and ‘yi’ represents the activity label for sample ‘i’. The accelerometer values in the dataset are transformed into feature set ‘S’. The input datasets are subjected to standard outlier detection methods (Oj). For the jth hybrid outlier detection method employed, the outlier score for each activity classes are calculated. In general, M-outlier score can be obtained from ‘K’ different outlier detection methods. In the second phase, the outlier scores stored in the vectors A0, A1...AM are averaged and sorted in decreasing order. The outliers are identified and removed using the standard Inter Quartile Range (IQR) method [44] with the following steps,
Step1. Find the first quartile (FQ) and the third quartile (TQ) of the averaged outlier scores
Step 2. Find the Inter Quartile Range (IQR) of outlier scores.
Step 3. Find LI = FQ - 1.5*IQR and HI = TQ + 1.5*IQR
Step 4.The outlier score values outside the interval (LI,HI) are declared as outliers.
The pseudo code of the proposed improved Hybrid outlier detection method is shown in Fig. 1.
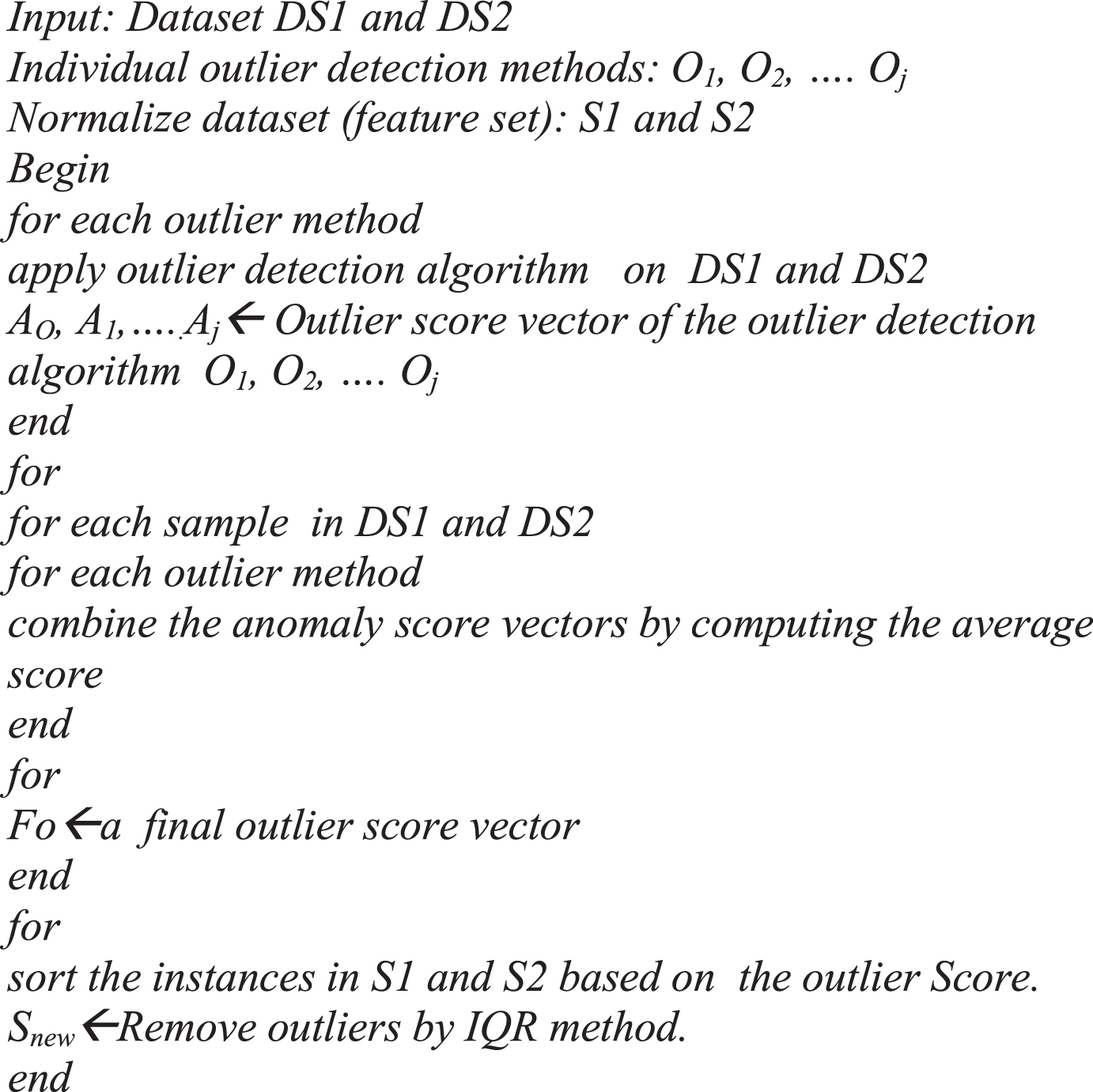
Pseudo code of improved Hybrid Outlier Detection (IHOD).
The data set for outlier detection are collected and preprocessed for classification. The steps involved in data collection and preparation are described in the following section. To improve and establish a comparative baseline for hybrid outlier methods, we decided to use the same two datasets DS1 and DS2 from our existing work [31]. The DS1 is the offline HAR dataset available in UCI machine learning repository. The DS2 is constructed in a real time environment using MATLAB MOBILE package. MATLAB MOBILE package can obtain data from built-in sensors from the android device.
Feature extraction
Standard classification techniques cannot be applied directly to the accelerometer data. Instead, the raw time series data are transformed into examples. The data in both data sets DS1 and DS2 are divided into ten - second segments and features were generated based on the two hundred readings contained within each ten - second segments. Next informative features were generated based on the two hundred raw accelerometer readings, where each reading contains x, y, and z the value corresponding to the three dimensions. A total of forty-six summary features were generated, though these are all variants of just six basics features.
The description of the datasets DS1 and DS2 used for outlier detection and activity classification obtained after feature extraction is given in Table 2. The features obtained for DS1 and DS2 are described in Table 2. After feature extraction process feature selection techniques or ensemble of feature selection methods can also be employed to select the most relevant attributes or classes [35, 52].
Feature Extraction of HAR datasets
Feature Extraction of HAR datasets
Description of datasets
The main goal of this experimental analysis is to compare the performance of the proposed hybrid outlier detection methods with existing methods for human activity recognition. Three experimental analyses were conducted with datasets DS1 and DS2. The first analysis aimed at detecting the outliers using three standard outlier detection methods such as distance-based, density based and cluster based K-means methods. The second experimental analysis attempted to detect the outliers using the hybrid outlier detection method. In order to have a deeper level of analysis for the proposed hybrid method, two different hybrid methods are employed. The first method is IHOD1, obtained by combining the distance based and density based outlier detection methods. In IHOD1, distance based KNN- OD is employed first and the outlier score for each activity sample is calculated based on the distance measure. The calculated outlier score is stored as a vector (A0). Similarly, LOF based density OD method is employed and the outlier score for each activity sample is calculated based on the density score. The calculated outlier score is stored as a vector (A1). In the second phase, the outlier scores stored in the vectors A0 and A1 are averaged. Then the final outlier score values are sorted in descending order. Now the outliers are removed using IQR method. The second method is improved hybrid outlier detection method-2 (IHOD2) is obtained by combining all the three outlier detection methods, distance based - KNN, density based - LOF and clustering based K-means outlier detection methods. In the proposed hybrid method HOD2, KNN- OD is employed first and the outlier score for each activity sample is calculated based on the distance measure. The calculated outlier score is stored as a vector (A0). Similarly, LOF- OD based method is employed and the outlier score for each activity sample is calculated.The calculated outlier score is stored as a vector (A1). K-means cluster method OD is then applied to calculate the outlier score as a vector (A2). In the second phase, the outlier scores stored in the vectors A0, A1and A2 are averaged. Then the outlier’s scores are sorted in decreasing order and outliers are removed using IQR method. The outlier detection methods are implemented using the Rapid miner tool. The default parameter values available in the Rapid miner tool are used in the implementation. The values of ‘K’ can be specified as the number of neighbors for distance based and density-based methods. First, we choose a random value of K = 10 for all the outlier detection methods and the proposed method is repeated with various K values such as 5, 20, 30, 40, 50, 100. For cluster-based methods, the optimal number of clusters is determined using the standard the silhouette method. In K-means clustering, silhouette method is used to find out the optimum value for a number of clusters (K). It is used to measure how close each data point in a cluster is to the neighboring data points in the clusters. The value of silhouette lies in the range of [-1, 1]. Higher the value better is the cluster formation.
The number of clusters for DS1 and DS2 is determined as 12 and 8 as in Fig. 2. The confusion matrix obtained for activity classification without outlier detection, KNN, LOF, K-means, IHOD1 and IHOD2 of dataset-1 (DS1) is shown in Tables 3–5. The confusion matrices of all outlier detection methods for dataset DS2 are shown in Tables 7 and 8. The third experimental analysis is done to classify the acivity labels of all OD methods using the standard classifier Support Vector Machine (SVM) on the two datasets. The reasons for choosing SVM in human activity recognition is, they do not include a set of rules understandable by humans [37, 39].

The optimal number of clusters for DS1 and DS2 using Silhouette methods.
Comparison with existing work
Confusion Matrix of without OD and KNN-OD for DS1
Confusion Matrix of LOF - OD and K-means cluster based OD for DS1
Confusion Matrix of IHOD1 and IHOD2 for DS1
Confusion Matrix of without outlier detection, KNN - OD, and LOF - OD for DS2
Confusion Matrix of K-means cluster based OD, IHOD1 and IHOD2 for DS2
In addition to misclassification rate obtained from confusion matrix of classification results, various performance measures such as, classification accuracy, precision (or) correctness, recall (or) detection rate, time and space complexity are evaluated on DS1 and DS2.
Classification accuracy
The classification accuracy rate is high for both datasets using IHOD1 and IHOD2 methods when compared to individual outlier detection methods. Confusion matrix for activity classification without outlier detection, distance-based KNN, density based LOF, cluster-based K-means OD, IHOD1 and IHOD2 methods with SVM classification are shown in Tables 4–8 for DS1 and DS2. In Tables 6 and 8, the misclassification rate of IHOD1 and IHOD2 gets reduced to 8.04 % and 8.14 % for DS1 and 6.26 % and 6.24 % for DS2 for SVM, which is less when compared to individual OD methods. Misclassification rate is reduced considerably for classifiers with individual outlier detection methods than classifier without outlier detection. This is because of the outlier methods are employed to remove the noisy instances. Among the individual outlier detection methods employed, density LOF based outlier detection method has a low misclassification rate and the overall classification accuracy rate is very high for IHOD1 & IHOD2. The classification accuracy for DS1 and DS2 for K = 10 is calculated from the misclassification rate using Classification Accuracy = 100 - Misclassification rate, and shown in Table 9. To find the optimum K value, classification accuracy for K = 5, 10, 20, 30, 40, 50, 100 for the standard dataset DS1 is shown in Fig. 3. From the results Obtained it is very clear that proposed hybrid methods have high classification accuracy than other methods and when K = 50, the hybrid methods achieve high accurcy than K = 5, 10, 20, 30, 40, 100.

Classification Accuracy of ODM’s for K = 5, 10, 20, 30, 40, 50, 100 for DS1.
Classification Accuracy for K = 10 (DS1 and DS2)
Precision (or) Correctness is defined as the proportion of the number of correctly classified activities to the total number of activities classified. From the results in Fig. 5, it is found that the SVM methods without outlier removal lead to low precision for DS1 and DS2. This implies that a large number of outliers have a negative impact on the precision of the classifier. Among the individual OD methods, the classifier proves the highest precision for IHOD1 and IHOD2 compared to other individual outlier detection methods used for DS1 and DS2. For DS1, the precision of SVM is 92.11. % for DS2, the precision of SVM is 93.8% with IHOD1. For DS1, the precision of SVM is 92.5% and for DS2, the precision of SVM is 92.24% with IHOD2. Also, the results prove that the classifier with hybrid outlier detection method has a strong relationship to activity classification than the classifiers with individual outlier detection methods. In general, hybrid outlier detection based classifiers predict the activities very accurately with high correctness.
Recall (or) Detection rate (or) Completeness is defined as the proportion of the correctly classified positive activities to the total number of positive activities. From the results in Table 10, it is found that the SVM methods without outlier removal lead to low detection rate for DS1 and DS2. This implies that a large number of outliers have a negative impact on the detection rate of the classifiers. Among the individual outlier detection methods, the classifiers show the highest detection rate for density-based outlier detection method irrespective of the datasets used. Among all outlier detection models employed, hybrid methods predict the maximum activities with high recall value. For DS1, the hybrid method IHOD1 obtained a high detection rate of 89.38% and IHOD2 obtained a high detection rate of 89.31%. For DS1, the hybrid method IHOD2 obtained a high detection rate of 89.57% and for DS2, the hybrid method HOD2 obtained a high detection rate of 89.71%.
Precision and Recall for DS1 and DS2
Precision and Recall for DS1 and DS2
Receiver operating characteristics (ROC) curves are used for comparing the performance of the classifiers visually. ROC curve is plotted using a false alarm rate in X-axis and detection rate in Y-axis. From the results in Tables 4–8, misclassification rate, precision, and recall values show that SVM with hybrid outlier detection methods performs better for all OD methods irrespective of datasets. In addition to various quality metrics evaluated so far, the performance of SVM with outlier detection methods is also evaluated visually using ROC curves. Analyzing the ROC curves of datasets DS1 and DS2 from Figs. 4 and 5, it can be observed that the hybrid outlier detection method IHOD2 combined with SVM classifier out performs hybrid outlier detection method (IHOD1). Furthermore, it can be observed that applying SVM on the original dataset (with outliers) has the much worse ROC curve than SVM with hybrid methods. Similarly, when the proposed methods (IHOD1 and IHOD2) was able to alleviate the effect of noisy features more effectively. From the results obtained, it is found that among all the OD methods, the hybrid outlier detection method based prediction models perform well in all aspects. IHOD2 serves an excellent role to make the outlier detection process than IHOD1 because of its compound combination of three OD methods. Among the datasets used, a drastic increase in the detection rate and precision is observed for DS2 before and after outlier detection. The possible reason for this might be due to the environment used for data collection and the quality of sensing device used. Also, the outliers may occur in an environment with clutter and variable lighting.

ROC of DS1.

ROC of DS2.
The time complexity of the proposed hybrid algorithm depends on the size of the dataset (s), the size of the attribute set (a) and a number of detection algorithm combined (n). The algorithm has a time complexity of O (a*n*s) in the worst case. To demon strate the scalability of the hybrid algorithm proposed, Figs. 6 and 7 shows the execution time of two hybrid algorithms for two different datasets as the size of the dataset is increased. As can be seen the execution time of both algorithm increases with increase in the size of datasets. However, the individual outlier detection algorithm increases its execution time dramatically with the increase in the size of the dataset. However, the individual outlier detection algorithm increases its execution time dramatically with the increase in the size of the dataset. In contrast, the proposed hybrid algorithm increases linearly. The above analysis shows that IHOD1 and IHOD2 are linear to the size of the dataset, which makes this algorithm to have good scalability. Hence, it can be claimed that hybrid OD method proposed is scalable and suitable for very large datasets in real time applications.
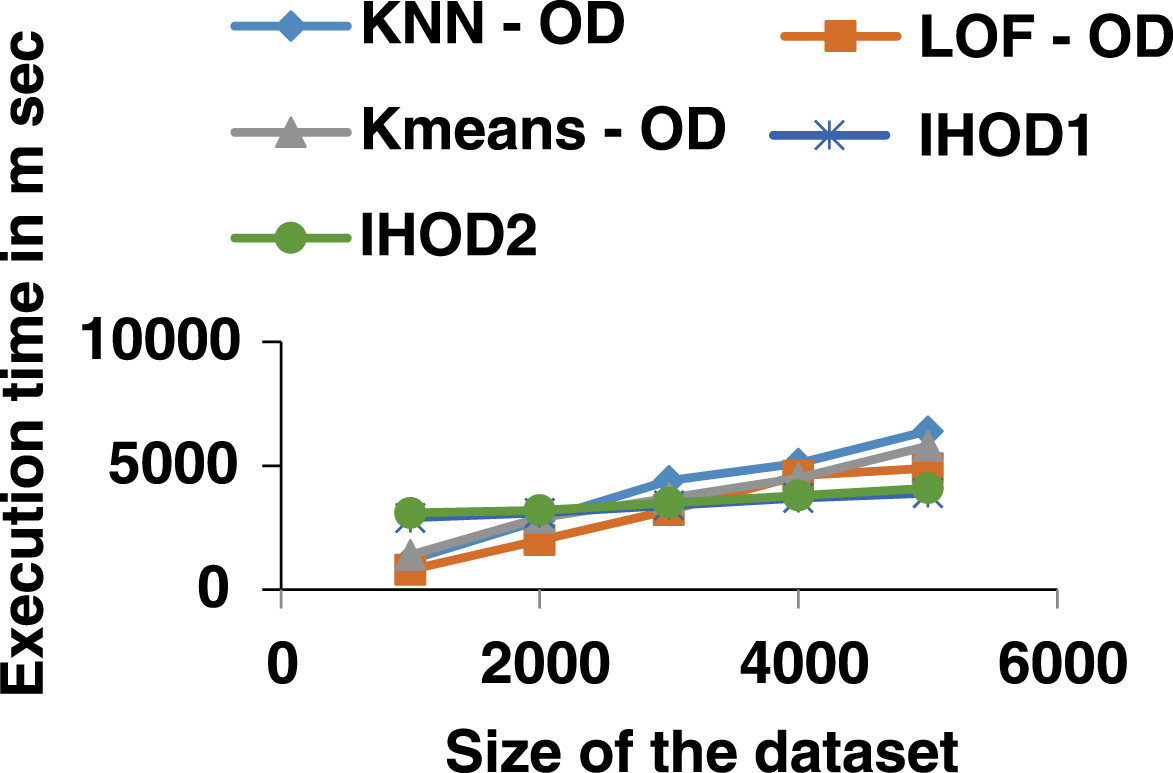
Time and Space Complexity of DS1.
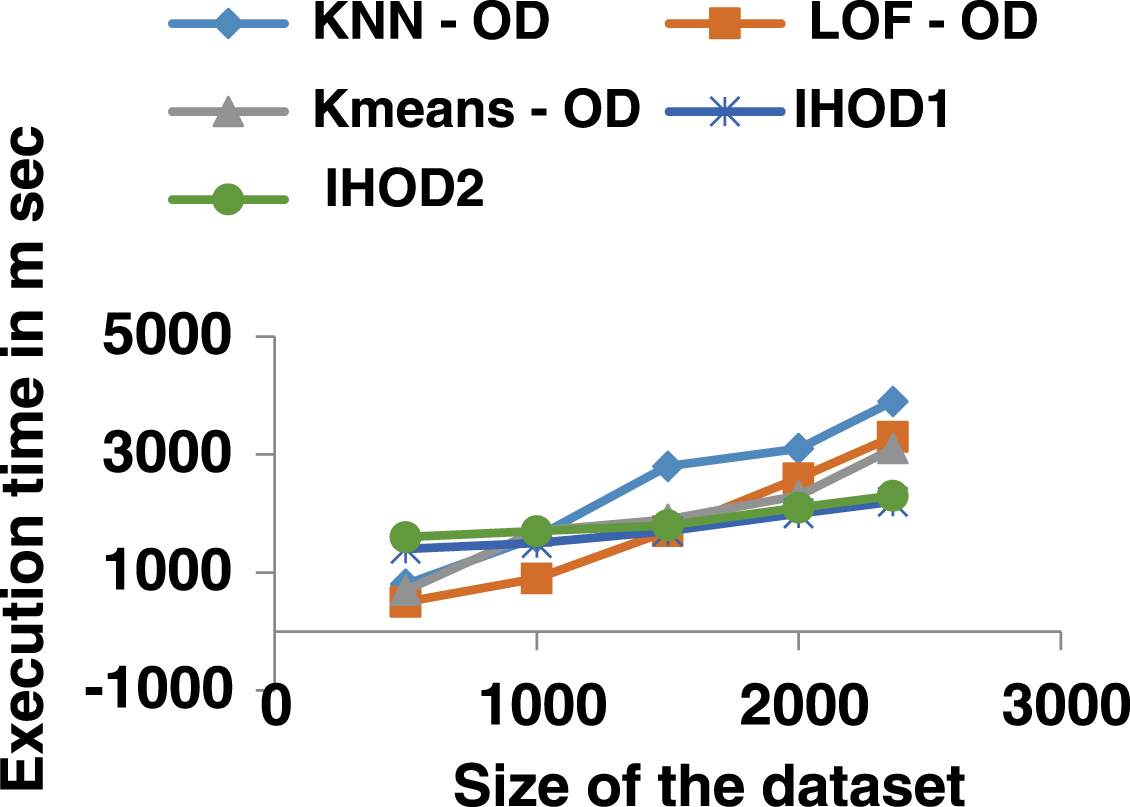
Time and Space Complexity of DS2.
A comparative analysis is made with existing methods and shown in Table 11. Results obtained show that classification accuracy for IHOD1 and IHOD2 is high than other existing methods.
Comparison of Existing Methods
The improved Hybrid outlier detection approach for combining outlier detection algorithms was proposed. Experiments on two datasets indicate that the proposed improved Hybrid outlier detection method can result in much better detection performance than the individual outlier detection methods. The general nature of the proposed work allows that the combining schemes can be applied to a number of combinations of outlier detection algorithms. Despite the fact that performed experiments have provided confirmation that the proposed technique can be exceptionally effective in the anomaly detection and classification accuracy is increased using outlier detection methods. The future work is expected to completely describe them particularly in extensive and high dimensional databases with feature selection or feature reduction methods. This proposed work can be used to detect abnormal activities of human in home monitoring and health care monitoring. The following are some possible threats to the validity of the proposed method. This work was carried out in a class imbalance condition. A suitable sampling method may be adapted to balance the distribution before employing the outlier detection. For online data collection, we should take into account the various hardware limitations. Though a reasonable number of activities are recorded, the performance of the proposed outlier detection methods must be analyzed by increasing the number of activities further. The performance of the proposed method must be analyzed for an application other than monitoring daily human activities.