
Abstract
Imaging techniques are the most rapidly growing area of computer vision, and the resolution has reached a new level. Super-resolution is a technique that enhances the resolution of images from the low-resolution input and help to accurately analyze and derive the data. Recently convolutional neural network are becoming mainstream in computer vision. Most existing CNN models based super-resolution either directly reconstruct the low-resolution input and then improve the resolution at the last layer, or another way is, to firstly enlarge the low-resolution input to high resolution (HR), then reconstruct the HR to obtain the desired output. These models encounter some major flows; large computational resources and losing information. In this paper, we adopt gradual process for training the CNN, to propose an efficient super-resolution model. The gradual strategy helps network to progressively magnify and reconstruct the LR image in each step, and thereby possibly avoid of losing information (second problem). In addition, we optimize the number of layers, add the residual network and skip connection to the proposed network to ease the difficulty of training (first problem). The proposed model not only achieves a compatible performance with the existing prominent methods but also, efficiently reduce the computational expenses.
Introduction
Image resolution describes the details of an image and the higher resolution targets needs more image details. Initially there was little interest in this technology, overtime with grows of technology; the need of resolution enhancement cannot be overlooked in many crucial applications, such as security surveillance [21], medical imaging [28], remote sensing [1, 14], object recognition [18, 32]. However, it is very difficult to resort the high-resolution images from a low-resolution input, because usually, the number of pixel in HR images targets are larger than LR images.
In essence, the idea behind image resolution is to combine the useful and non-redundant information which contained in the low-resolution cases to create a high-resolution image. Before taking the study further, a brief description regarding the degrading factors in image capturing is given. In the process of capturing the digital image, there is a natural loss of resolution that occurs by the optical due to limited shutter speed, noise that occurs during transmission or even within the sensor, and insufficient sensor density. Therefore, the effected images will e noisy, indistinct and deficient in resolution [11–15]. The best remedy could be super resolution methods. Many researchers have developed and design methods for solving the resolution problems in low-quality images. Deep learning-especially convolutional neural networks-are becoming a mainstream in many computer vision applications, and it considered to be the best solution for image resolution problem, due to the structure of deep learning which gradually learning the information of an image by cascading the CNN and nonlinear layers [27]. The first attempt at using CNN based on image super-resolution introduced by Dong et al. [4] termed as SRCNN.
They used only three convolutional layers in their network structure. A couple of years later, they [3] extended their work by increasing the number of filters and the size of filters with the fixed depth of CNN. These two experiments proved that deeper models not only hard to train but even failed to improve the performance. In contrast, many other researchers used deep network in their structure to improve the resolution of images. However, their observations convey that deeper networks which stand-alone based image super-resolution tend to degrade the performance and even not suitable for image super resolution problems.
The reason can be due to two problems. Naturally, with more layers of convolution, there is a significant threat to lose the image details, and the fewer image details, the less quality resolution (vanishing gradient problem). The second problem refers to computation and optimization that leads to the hard and lengthy training process. Practically, when any models contain more parameters, the network faces difficulty to train, even sometimes by adding more layers we face more training errors [5, 23]. Therefore the combination of deep CNN with the residual network will be expected to take advantage of the correlations between low resolution and high-resolution images, also adding skip connection would ease the gradient vanishing problem in the deeper network.
However most of the existing networks based SR adopting the following strategies. The first group approaches upsamples the low resolution input with a simple interpolation method such as bicubic at the initial step and then improves the resolution [7, 23]. The second group uses upsampling only at the last layer, typically using a sub-pixel convolution layer to recover the HR result. These methods dealt with some major flaws to achieve high quality. Based on above observations, in this paper, we tried to compensate the undesired behavior of deep CNN architecture in image super-resolution by optimizing the network structure.
Figure 1 shows the structure of proposed network. The proposed network consists of multistep upsampling layers that gradually reconstruct and improve the image resolution. The gradual network contains several subnetworks, in which, each subnetwork only train a small target magnification, and thus, more image details could be extracted in each step. To improve the training and reduce the hyper-parameters the residual network and skip connection has been added to the network which suggested by [7]. Indeed, the proposed structure in this paper is simple and provides superior accuracy performance compared with state-of-the-art methods. The overall contributions of this paper are in three folds: A convolutional neural network is presented for image super-resolution which gradually do upsampling and extracting features, while preserves all the image information. The network is an end-to-end architecture between low (input) and high-resolution images (target). To better train the network, avoiding of losing image details we propose to add skip connection to CNN layers between convolution and upsampling layers. We demonstrate that gradual upsampling helps the DeepCNN (where prudently combined with residual network and skip connection) in the classical computer vision problem of super-resolution and can achieve good quality with lower expenses time. We evaluated our original experiments on Set14 and BSDS100 image data. In addition, we compare with a number of recently published methods and confirm that our model still outperforms existing approaches using different evaluation metrics.
Related work
Due to the potential and widespread usage of high resolution images, and also the LR images are the formidable obstacle to display the reality, the super-resolution approach has been one of the most active research areas in the literature. The main advantage of SR approach refers to cost less and also the existing low resolution imaging systems can be utilized. Even we found that, currently, many applications which are based on image processing and computer vision and have a desire demand of high quality of display; they switched their image quality’s application to use super resolution technique [24–26, 30]. The convolutional neural network is successfully applied in wide range of computer vision areas, such as classification, recognition, detection, and super resolution. Since this paper proposed a deep CNN model for image super-resolution, thus, in this section we have given special emphases on the most recent prominent work based on deep learning in image super-resolution.
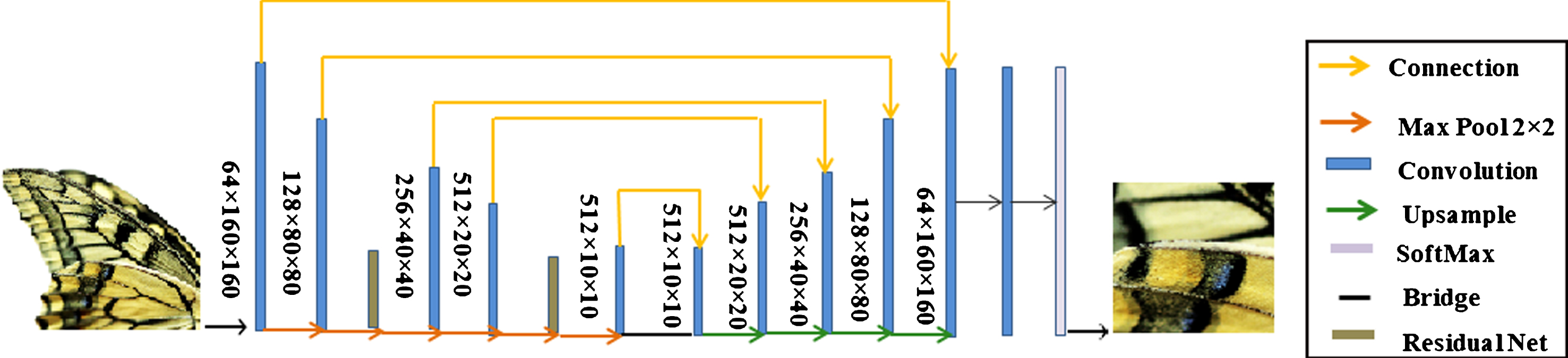
The Pipeline of the proposed deep network.
Dong et al. [3] proposed the deep convolutional neural network for the image super-resolution by using 2 to 4 CNN layers, termed as (SRCNN). They experimentally proved that the deeper models are not suitable for image super-resolution, while, using a CNN with larger filter size is better than deeper layers. A few years later, the authors attempt to improve SRCNN and made it faster which is termed as FSRCNN [4]. The FSRCNN used transposed CNN in place of normal CNN to easily and quickly process the low-resolution input. They experimentally proved that RAISR and FRSCNN’s models are 10 to 100 times faster than other prominent Deep Learning based image resolution. Contrary, Kim et al. [7] proposed a very deep CNN contains 20 layers with a long skip connection to discover the residual image termed as (VDSR). Their model outpaces the SRCNN which proposed by Dong et al. [4]. Deeply recursive convolutional network is another method that is proposed by Kim et al., for image super-resolution problem [8]. The model has a deep recursive depth 16, and 20 convolution layers, which shows the model dealt with the huge number of parameters.
In order to minimize the number of parameters, they share the CNN’s weight, and hence they successfully mitigated the training problem of deep CNN and achieved the significant performances. Yaniv Romano et al. [15] proposed a shallow model instead of deep with a fast learning technique. Their model called “Rapid and Accurate Image Super Resolution” and it can classify the input image patches based on their patch’s angles, strengths and coherence then map the low-resolution input to high-resolution targets by the clustered patches.
The other Deep Learning-based Image resolution methods are deep Residual Encoder-Decoder Networks (RED) which is proposed by [13]. RED is based on residual learning and contains symmetric convolution as encoder and deconvolution as decoder layers. In addition, they use skips connections to connect every two or three layers. This structure leverages the capacity of the model to train, up to 30 layers and achieves the acceptable performance. However, in this paper we used the advantages of existence methods and tried to improve the image quality as well as the training process.
Based on existing observation, SR methods based convolutional neural network outpaces the other techniques. Hence, as far as super-resolution is concerned and is a severe demand from many industry, the pioneering work such as CNN will be as fresh as 2014 [2–4, 8]. The initial start is one CNN layer and then increases the number of layers. We keep continuing up to reach the desired result, and once it stopped improving performance, then we used other features such as activation, dropout, and batch normalization. Ultimately after several trials, we select the best structures and hyperparameters as our final model which will suit for image super-resolution task. Figure 2 is depicted to show the difference of proposed model over the exiting methods in what we follow.
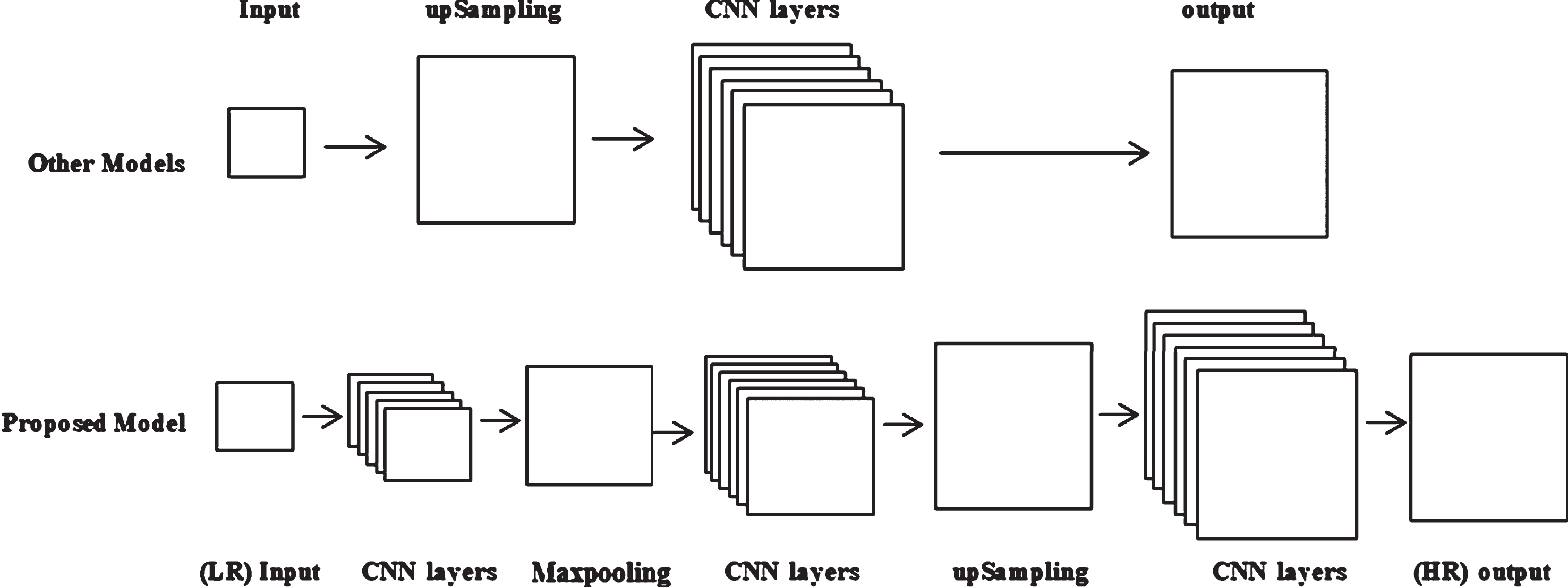
Overall Structure of difference between the other models and the proposed model.
Before explaining the proposed model, it is expedient to briefly descript the challenges of existing CNN based SR methods for better understating the work. Technically, the deeper the CNN, the results should be more accurate. However, as a results from the previous methods the deeper networks deal with three main issues; overfitting, losing information in deep layers, and a huge model [6, 19]. Moreover, the researchers of SR based deep networks noted that, they suffered with training problems, especially the exploding/vanishing gradients problem. Distinguish from other methods in this paper we propose a SR methods which has a deep network in order to extract more subtle image details (as before discussion, more details given better resolution) and also, with deep layers we want to give specific advantage to the proposed model that the input images can be of any size and the algorithm is not patch-based.
To address the current issues and compensate the undesired behavior of deep CNN, the direct upsampling process is substituted by gradual upsampling and we try to accurately optimize the number of layers (possibly deep layers). Another issue that we encounter in using deep networks is the huge number of parameters. In this paper we try to reach to the far fewer parameters from the existing methods by adopting a residual learning [19, 24] and skip connection [13, 18], which can control the number of parameters in depth network. Moreover, most of existence Deep CNN models based on image super-resolution follows two strategies: some approaches firstly enlarge the low-resolution input to high resolution and then reconstruct the HR inputs [2, 17]; other approaches directly reconstruct the low-resolution image then at the last layer recover the high-resolution target [4, 28].
The proposed architecture technically is different with the current approaches. We aim to gradually enlarge & magnify the image in a multistep process to obtain and extract all the subtle details & information in order to improve the image qualification and resolution. Since the quality and resolution of the images highly depend on the image details. Note that, more image details, better image resolution. The rectification layers are added after each convolution and upsample layers. The structure of proposed model has shown in Fig. 1 and also the difference of proposed model over other existence models are depicted in Fig. 2. In our proposed network we didn’t consider pooling since it ignores some of the useful image information which may crucial for the super-resolution tasks. Structurally, convolutional layers act to extract the features by preserving the important components of objects in the image. Most of the times, the imperative contents of the image will be lost during the training process in the deep network. Therefore we tried to solve the problem by using gradual upsampling strategy. The basic structure of the model is as follow. For extracting all features of the images, the entire outputs of the hidden layers are merged to the Upsampling network as Skip Connection.
After merging all of the extracted features blocks of CNN have been used to recreate the details of the image. The output of final CNN layer is the square of scale factor image, and finally, the up-sampled original image is predictable by including these outputs to the up-sampled image created by upscaling. Consequently, the novelty of the proposed deep CNN model is to use gradual upsampling and residual strategy with skip connection for learning from the low resolution input to get a high resolution image. This network twice has been used in the proposed model. In the earlier works, the image up-sampling was generally used as their input for the CNN based models. As shown in Fig. 1 it also looks inefficient to extract the features from an up-sampled image rather than using the original size image. In the proposed model there are two levels of feature extraction before and after the upsampling.
Moreover, there are also some hidden layers for concatenation of each pair block of networks. The first novelty of this model is to extract features before and after upsampling and secondly have hidden layers between each pair block of convolution layers. The number of convolution layers in the proposed model is less than other approaches meanwhile; skip connection and residual learning also have been used in the model to reduce the computational cost and the processing time. Moreover, in this paper, we experimentally show that very deep networks considerably improve super-resolution performance. In Fig. 4, we set the network depth from 5 to 20, and by increasing the depth, the performance will be better.
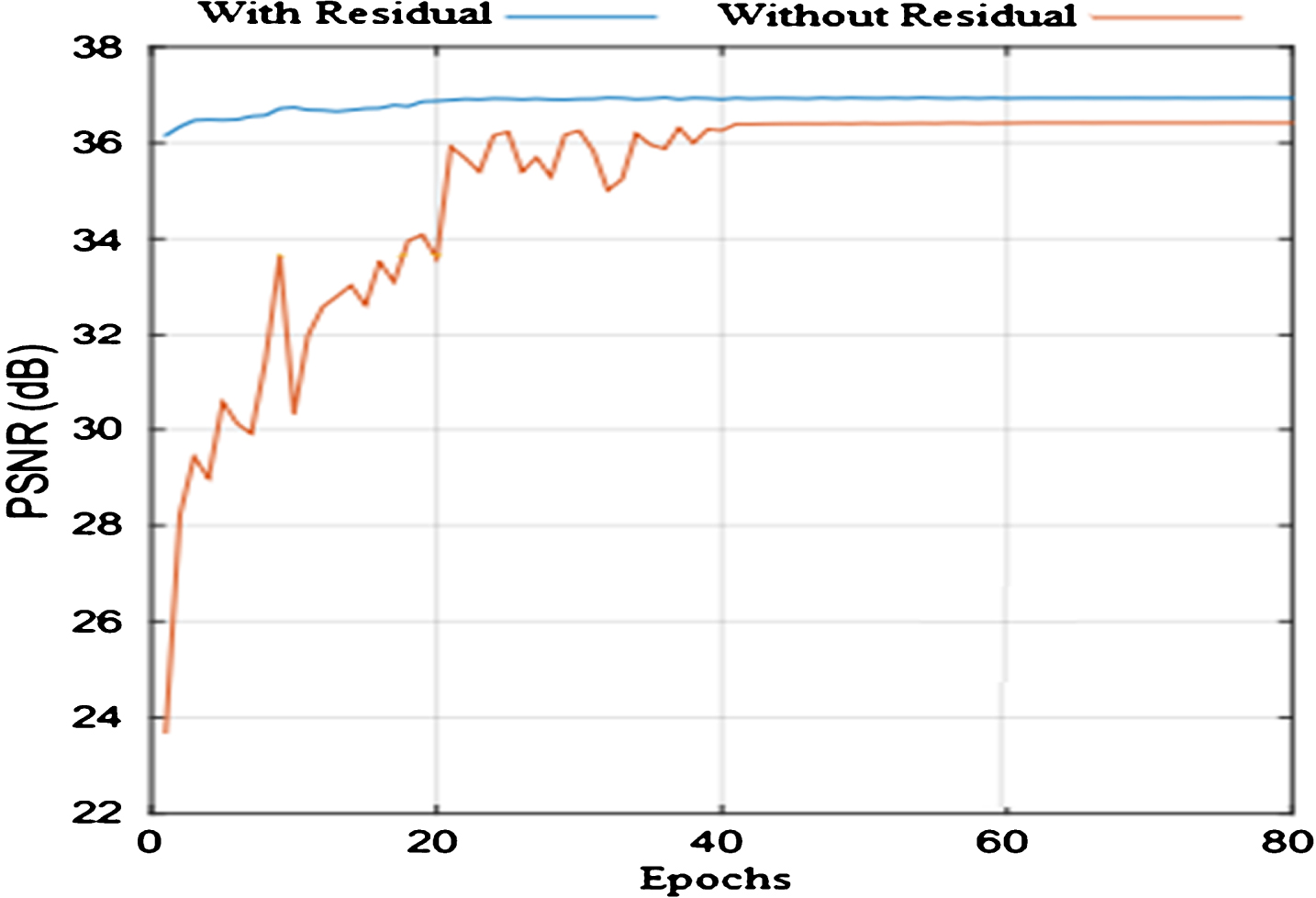
Residual networks quickly reach desired performance, while with-no-residual networks after many epochs reach maximum performance.
The proposed network conceptually consists of several interdependent components. Input layer: the input layer is a convolution layer which is activated by ReLU. For a low-resolution input X in size of (m
LR
, n
LR
), we can compute the input layer as:
X is the low-resolution image (input), and ’*’ is the convolution operation. Win and bin are the sizes of weight and bias. In this paper, the range of filter size is from 64 to 512 with the 3×3 size of the input layer. Moreover, in the proposed model all the convolutions are computed with zero-padding, thus it has a result in invariant resolution.
where X
l
is the input of the layer L and
The output of this calculation will be a Y high-resolution image. W
o
p and b
o
p are in the size of 3×3×64×1, and 1×1 respectively. According to [28], while employing a CNN for super resolution, pooling or subsampling are not appropriate since they causes to discard and losing the image details. Therefore, the pooling layers are usually avoided in super resolution a method which again has its weakness; and overfitting may occurs. Hence, in this paper, by proposing gradual upsampling we tried to solve this undesired downside. In addition, the low resolution input X is gradually & progressively reconstructed in R steps. The upsample resolution in each step can be formulated as Let assume we have a low-resolution image with the [m
HL
, n
HL
] size, and we want to find the upsample resolution of the jth step:
Term D (.) indicated as the round-down function.
CNN models are able to set a highly nonlinear regression problem. As we noted before, about different CNN strategies in super-resolution; but gradual upsampling in CNN architecture not very commonly used in image SR models. Following equation has given for the training pairs of low resolution and high-resolution images: XLR, YHR indicates the low-resolution and high-resolution image respectively. We aim to predict the target YHR through; {X
LR
, Y
HR
}
i
, i = 1, 2, …, k and CNN mapping the XLR to YHR by mapping function f (X
L
R). The CNN based mapping function process will be learned as:
The PSNR and SSIM comparisons
(Scale Factor ×2, ×3, ×4). The best performance is stressed italics and the second best performance is stressed in bold.
To achieve a better efficacy and solving the training difficulty, we combined the CNN architecture with a residual network that suggested by [7, 13]. Similar to the structure of [20], since the input and the output images are very similar, we define the residual Image as YHR – XLR (where most of the values are small or zero). The object function of proposed image resolution cans is formulated as:
As the low-resolution image in input and high-resolution image in output are very similar, and thus we need to learn their residual information and then skip the similarities, thereby residual network can improve the network process.
To evaluate the performance of the proposed model for image super-resolution two set publicly available image datasets have been used. The reports have given in Table 1 and Figs. 4–7. In this section we discuss two important properties in super resolution models. One property is the depth of network. We proved that for SR models depth of network is very important, since the deep network can grab more details, and the more details can provide a better resolution. The second property can be regarding the residual learning. We show that combining the residual learning to the CNN could improve the training process much better than the standard CNN. In following subsections, we have given the details of implementations.
Residual learning and skip connection
Skip connection can reduce the vanishing gradient problems in the deep networks and enhance the feature extraction. Based on the recent researches on SR we observe that the deeper network in image SR will degrade the performance. Thus integrating residual network and skip connection to the network will make an easier training process. Figure 3 is an example of residual architecture used in this paper. Our skip layer is different from [6] because we use skip connections as a bridge to pass the image details from convolutional layers to upsampling layers, thus in this case has beneficial to recover the image details. Then the feature maps are passed to the next layer after rectification for further assessments. The current methods in literature share a key idea: link the input data and the final reconstruction layer in SR. However they only adopted a single skip connection which may not fully explore the advantage of skip connection. It is essential to build many skip connections between layers to effectively train a very deep network, and thus in this work we use several skip connection in the residual network to improve the network structure.
From other side, the degradation of training accuracy specifies that, not all the systems are similarly easy to optimize. Because the existing evidence indicates that a deeper network should not produces the higher training errors, but experimentally there is a higher errors in deep networks as well, if we couldn’t properly optimize the network.
The concept of residual learning has been used in many applications [5] but it has not been widely applied in the CNN-based super-resolution methods. In this paper we address the degradation problem by adopting residual learning in the network. In Fig. 3, we have shown the details of residual unit which contains two convolutional layers and one skip connections in a single residual. We combined CNN with residual learning and skip connection to improve the network structure and ease the training process. As we indicated in Fig. 1, in the proposed model we used two residual units with the above details. We have evaluated two networks; with residual learning and without residual learning.
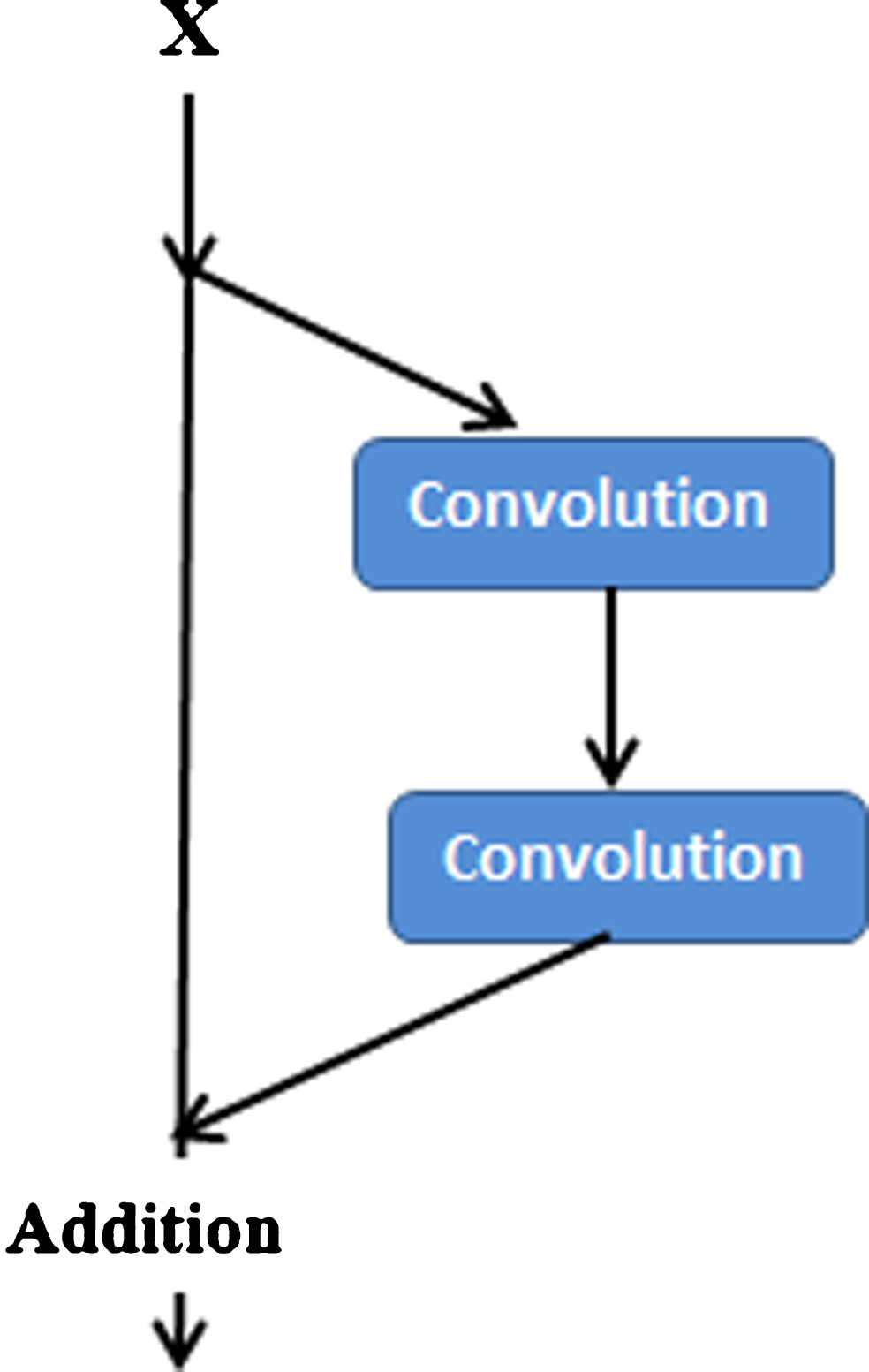
The architecture of residual unit.
Figure 4 shows the effect of residual learning in the DeepCNN architecture. In Fig. 4, we didn’t evaluate for all scale factors, we just used scale factor 4, with an initial learning rate 0.004.
In oppose to existing methods based super resolution [2–4, 21], we proved that, the shallow models (where there is a few number of layers) are not suitable for image super-resolution.
With the increasing number of layers, we can grab more image subtle details and information (Fig. 5). As we discussed before, in image SR, the image details are very important, with more we can get better resolution results. Usually, the image information between the low resolution and high resolution in deep layers will be lost. Therefore, this can be a very challenging task, since the image information has a close relationship with their resolution.
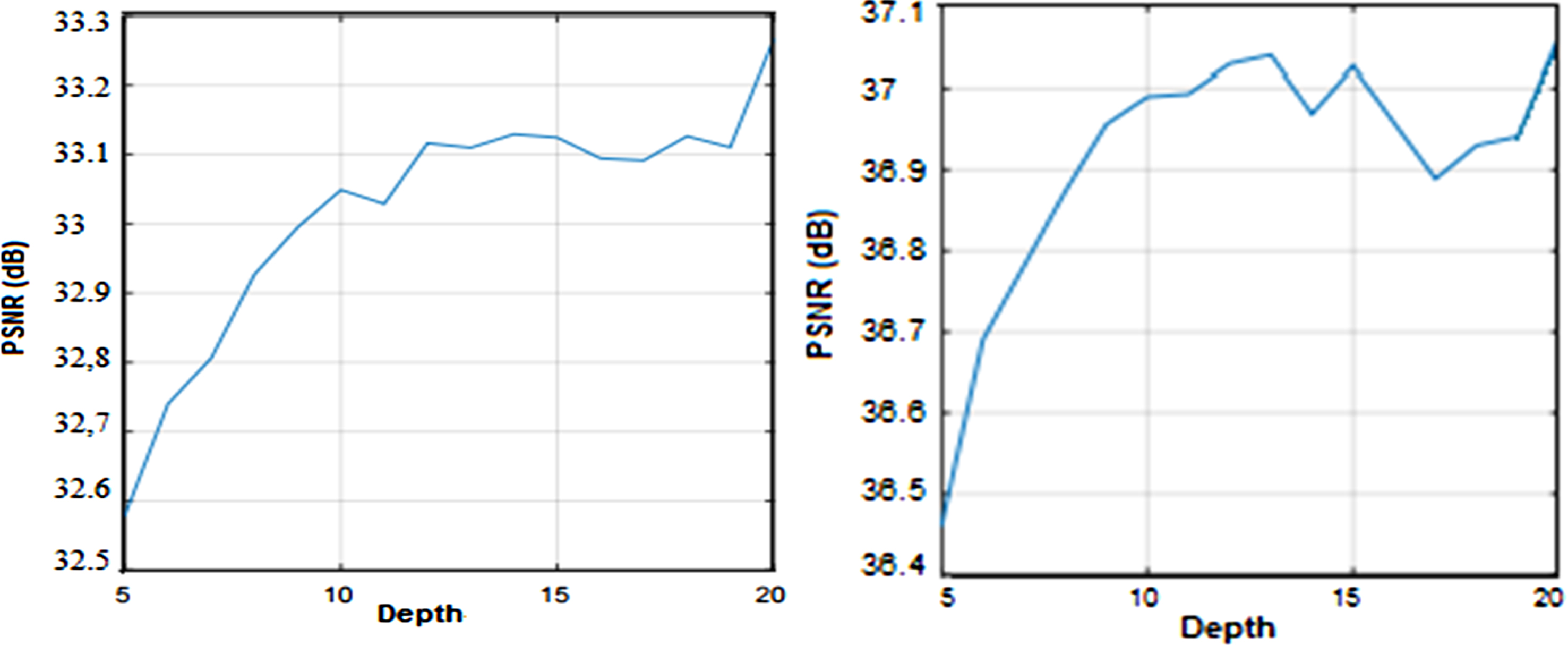
Depth vs Performance (Scale Factor ×2 & ×3).
To successfully achieve the high-resolution image from the low-resolution image, we propose to use the deep convolutional network with the gradual upsampling structure (multistep upsampling). Figure 5 shows thee performance evaluation via depth of network. We train the network in depth of 5 to 20. For all the layers we used the same filter size of 3×3. The receptive field of first layer is 3×3, while for the next layers, it increases by 2. Therefore, for the N number of layers the receptive field can be computed by (2N + 1)×(2N + 1) for both the height and depth. Its size is proportional to the depth. In a large receptive field, the network intends to use more contexts to predict the image details. For the SR, collecting and using more details, providing better resolution.
We have used Signal-to-Noise Ratio (PSNR) and Structure Similarity of Index (SSIM) as evaluation metrics in our experiment. In this section, we have given the details of the proposed model and the hyper-parameters used in this work. We assume the low-resolution image as XLR, and the goal is to achieve a high-resolution YHR output in multistep magnification. In each step, the low-resolution image
Generally, in super resolution techniques the average of mean squared error
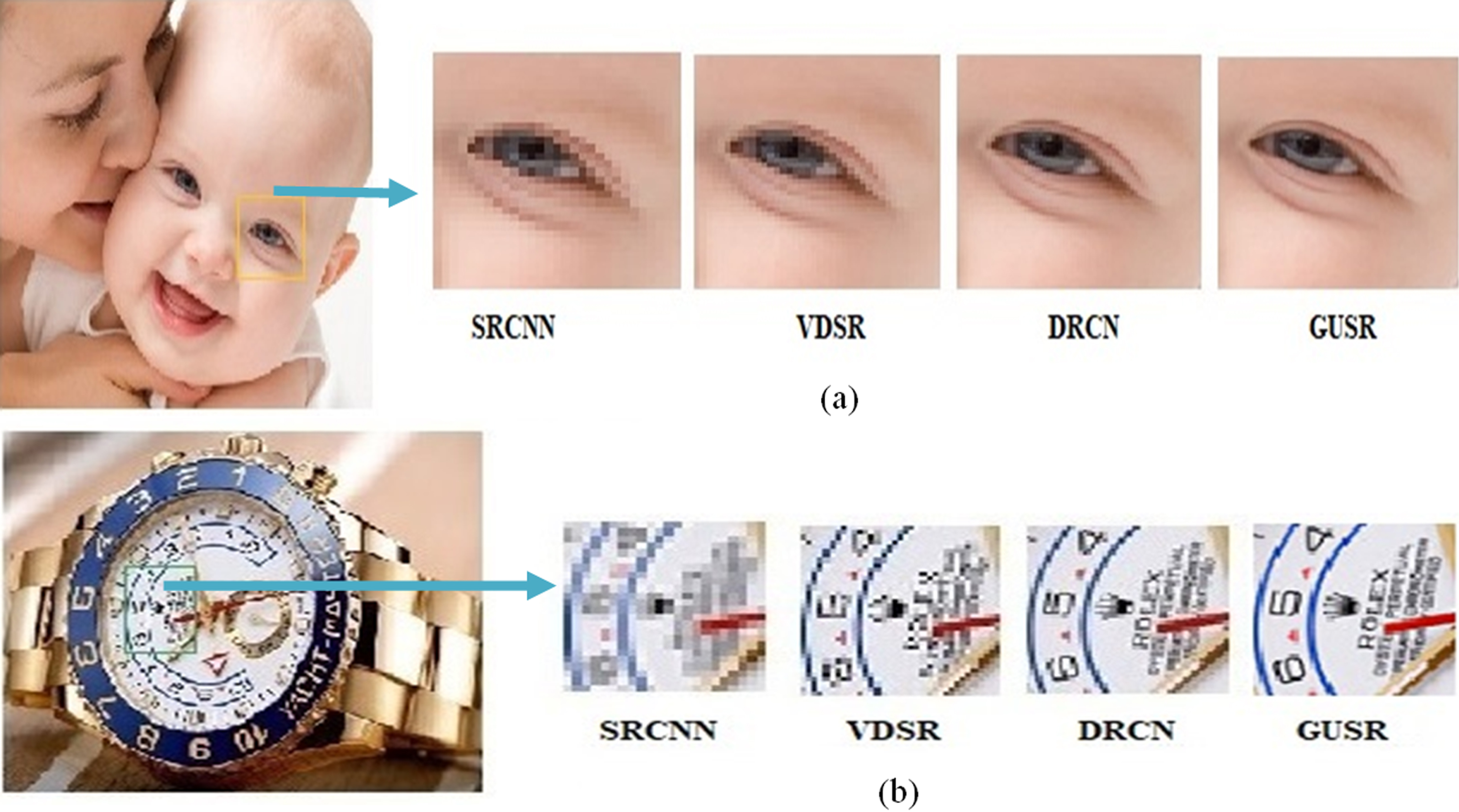
×3 scale factor upsampling result for different SR models.
Since this work is centralized to improve the image quality with reasonable time consuming, and also we have used different platform and libraries to evaluate the baselines, thus, it is not fair to compare the results based on execution time. However, to show effectiveness of our proposed model we have calculated the PSNR over execution time in scale factor 3 and the results exposed in Fig. 6. The baselines used in this paper are thoroughly selected and we tried to uses deep and shallow models to effectually show the performance of our model. We used six well-known baselines and analyzed their performance based on different scale factors; SRCNN [2], VDSR [7], DRCN [8], RED [13], FSRCNN [4] and RAISR [15]. Moreover, Fig. 7(a) and (b) shows the performance of our proposed model over Set14 datasets based on 3 scale factors. The zoom-up area is marked, and the HR results also given.
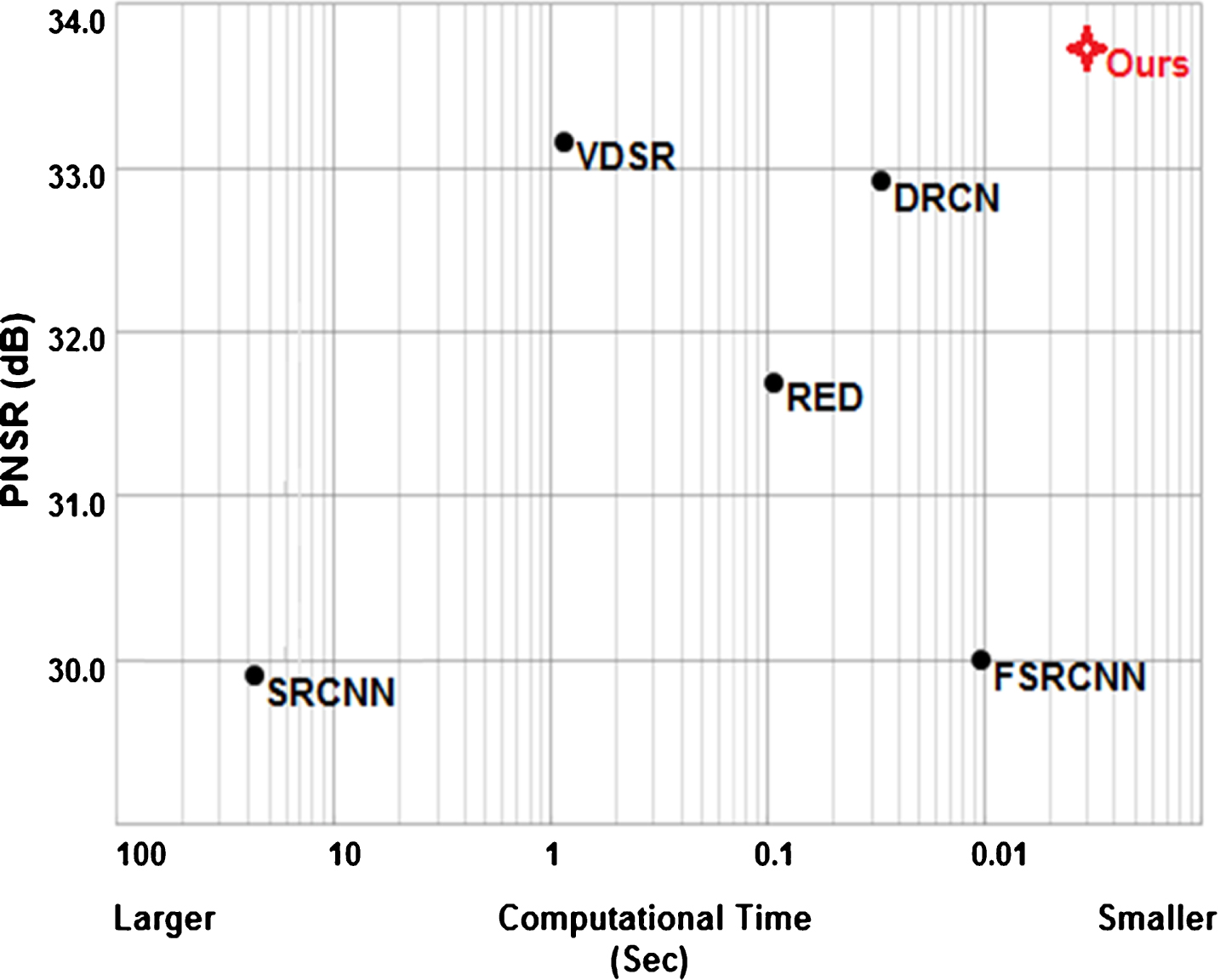
Computational times over PSNR. Noted that, this figure is based on set 14 dataset, with ×4 scale factor.
The residual CNN with a skip connection makes the proposed architecture a fully residual deep CNN. Therefore, it directly employs residual properties inside and across levels and hence grants the opportunity of building a deeper network with higher accuracy. Note that the proposed network is not only much deeper in comparison with other existence approaches but also a fully residual network due to skip connection which makes the network more robust and accurate.
The advantage of using residual network with skip connection is given in Fig. 3. We have used two residual units in our architecture, in which each residual units contains two convolution and one skip connection.by using this trick we will get the network more robust and smooth which is important in resolution problem. Furthermore, by using gradual upsampling strategy we can progressively improve the quality of the low-resolution image without information loss, and more worthy, this strategy helps us to reduce the execution time at optimal level. We proved our claim in Fig. 6.
As it observed from Fig. 6, our proposed model outpaces the baselines in execution time metric. The proposed strategy enables us to significantly reduce the evaluation times while keeping the results competence with baselines. The second best performance based on time execution reduction goes to VDSR and DRCN, which both are the new techniques in image super resolution. Compares to other methods, FSRCNN has a small execution time however, its performance in PSNR is weak and not considerable. Figure 7 is an example that shows the quality and clarity result of our proposed model over other methods. We used the maximum scale factors which is 4 in Fig. 7. By comparing the magnified edges of the selected area, following observations can be getting. For the Fig. 7(a) which the area around the eye has been selected the result of SRCNN and VDSR blur in comparison with DRCN and the proposed model GUSR. For the Fig. 7(b) Firstly, the texts on the watch are almost lost for most of the models during scale factor 4×. Secondly, the two-deep learning networks, the DRCN and the GUSR, can build sharp edges for 4×SR. Finally, the proposed GUSR achieves clearer and sharper results as compared to other models.
Once again we alluded to the plus points and the limitations of the proposed GUSR. The layer by layer upsampling and feature extraction could decrease the problems of the straightforward training upsampling. Additionally, the proposed model could quickly get trained and then progressively optimize the weights. As compared to the VDSR [7] and DRCN [8], the gradient clipping approach which is not used in the GUSR but still has high speed converged due to residual layer performance. The proposed GUSR specifically proposed for the SR scenario and does not have good performance for other image reconstruction issues like denoising. Last but not the least, as it is shown in the image 7 (b) the proposed GUSR does not have significant performance on the text and it is not able to properly recover the missing text components. Therefore, for the future work, we planned to use the advantaged of the model which proposed by Ledig et al. [10] to fulfill the limitation of the proposed model. The advantages of our proposed model are depicted in Table 1 and Figs. 6 and 7. Table 1 shows the qualitative performance of the proposed model over several well-known methods in super resolution on the different scale factors. The best performances over the different datasets are highlighted in red color, and the second best performance highlighted in blue color.
Conclusion
We proposed an efficient deep convolutional neural network for super-resolution method termed as Gradual upsampling SR (GUSR). The proposed network simply contains an input layer, multi-scales upsampling & convolutional layers, and an output layer. More specially, the proposed model enables us to control the execution time at the optimal level. Note that, for the fair comparison, our two networks have a same architecture and number of layers. The first network is plain and without using residual network, and the second networks contains two residual networks. The result of both networks has given in Fig. 3. The proposed model eases the training process with no information loss. By optimizing the network structure, the feature maps of our method are fed to the upsampling layer by skip connection. Using these structures, our model is able to achieve state-of-the-art performance with less computation cost. Experimental results on two representative image datasets demonstrate that the proposed GUSR can improve the image resolution and also produce competitive results over other prominent methods in super-resolution task.
Footnotes
Acknowledgments
This research was supported by NSFC, China (No: 61603171) and 863 PlanChina (No.2015AA042308).