
Abstract
This study both presents a novel methodology and compares the performance of computational intelligence techniques for the predictive modeling of the monthly potential for hydropower generation. Two different approaches are employed to forecasting energy generation: polynomial neural network and conventional artificial neural network (ANN). The first one technique is a deep learning type named group method of data handling (GMDH). And the second one is the multilayer perceptron (MLP) feed forward with back-propagation algorithm. The ANN dealt with two different optimization algorithms for training the model: Levenberg-Marquardt and Bayesian regulation. Rainfall data are used as inputs to feed the models. The performance of each model is scrutinized based on three statistical performance criteria. The results found that the computational intelligence techniques can model the dynamic, seasonal and non-linear behavior of the studied issue. The predictions from the GMDH method resulted in slightly better accuracy than the values obtained by the conventional ANN. The analyzes also showed that the values that determine the steady energy of the hydropower plant are well captured by the models. This feature makes the model an important tool for energy planning and decision making.
Introduction
Energy is fundamental to development. Each country uses its natural resources for energy generation. In many countries the matrix for electricity generation is highly dependent on water sources. In Brazil, e.g. 68% of the electric energy comes from hydropower plants [1]. Often the implementation of a hydropower plant is necessary, however it can cause significant environmental and social impacts [2, 3].
In the second half of the last century, Brazil deployed several plants with accumulation reservoirs, that is, those that form a bulky and very extensive lake, and thus allow the regularization of monthly or annual flow. However, because environmental reasons, currently the new hydropower plants projects consider only dams with no reservoirs or very small reservoirs, so that the water stored is significantly smaller and allows only the regularization of daily or weekly flow [4–6]. This kind of hydropower plant is named run-of-the-river scheme and because it has small reservoirs, the energy production is more susceptible to climate variability [7, 8]. For this reason, a run-of-the-river plant becomes very dependent on the natural flows of the river, which has a seasonal behavior, and therefore, during the dry season, suffer a significant reduction of the power generation. This characteristic makes it imperative to correctly determine the critical period that corresponds to the lowest energy generation and should define the steady energy of the plant, i.e. the maximum continuous power production.
Regarding the preliminary feasibility studies of a hydropower plant, which is a necessary component for the implementation of power plant designs [4, 6], an important approach of this study is the estimation of the potential for power generation. The main parameters employed to determine the amount of electric energy that a hydropower plant can generate are the river flow and the hydraulic head [7, 9, 10]. Although the hydraulic head is an engineering parameter dependent on the relief and the design of the plant, the traditional method for assessing the potential of a hydropower plant (HPP) considers the time series of a long-term flow measurements carried out using hydrological stations data.
In Brazil, the last frontier for the exploitation of hydroelectric energy is the Amazon region, where is estimated that more than 50% of the Brazilian potential for hydroelectric is found [11]. Therefore, in the next years, the implementation of several hydropower plants in the region is foreseen. The Brazilian regulation requires that previous studies for the implantation of a HPP employ discharge measurement data (flow) for a seventy-year time series, in order to capture with statistical security, the dry periods that define the steady energy [12]. However, many times is quite common there is no long-term streamflow dataset for the Amazonian rivers, and this can be a limiting factor for the estimation of the potential for hydropower generation with the necessary degree of confidence. Moreover, this can also compromise the success of the project that involves high amounts of financial resources and whose environmental and social impacts are extremely important, demanding maximum rigor for the project planning [13].
Regarding the difficulties frequently encountered in the Amazon region about hydrological data record, this work aims to present a methodology applied to the modeling of the monthly potential for hydropower generation using rainfall time series to aid in decision making before the implementation of hydropower plants projects. The atmospheric variables present a high complexity due their non-linear characteristics, that is why the chosen approach to modeling is the artificial intelligence.
The use of artificial intelligence techniques to solve complex problems has been very promising. In this sense, the present study also aims to perform a comparative analysis between the performance of both polynomial and conventional neural networks. The polynomial neural network employed in this study is a deep learning type named group method of data handling (GMDH). Since this method does not require prior knowledge of the expert to select the variables most relevant for use in the model entry layer, it is quite suitable for practical applications. In general, as the artificial neural networks (ANN) are suitable for small sample size learning [14], the multilayer perceptron (MLP) is also used. And the back-propagation algorithm (BPA) is used too, because for supervised training, the BPA can recursively adjust weights and biases to minimize error. The proposed methodology is demonstrated for a section of the Tapajós River, in the municipality of Itaituba, state of Pará, where the Brazilian government intends to install a Hydropower Plant (HPP) named Jatobá.
Machine Learning and Related Works
Group method of data handling (GMDH)
In the last decade, the use of computational intelligence techniques for modeling and predicting loads in power systems has been increasingly frequent [15] and one of the most promising methods that have shown promising results is the Group Method of Data Handling (GMDH). This approach is generally applied to short-term load forecasting [16–19] or modeling and forecasting of electricity consumption [20, 21]. There are many applications to diagnose and predict plant failure [22, 23], as well as to forecast rainfall [14] and stream flow [24], but this method has not yet been sufficiently explored and applied to predictive modeling of the potential for hydropower generation, especially in the Amazon region.
The pioneer of the GMDH technique was Ivakhnenko [25], but several other scientists carried out subsequent contributions and significant developments. GMDH consists of an inductive and self-organizing approach to mathematical modeling of complex systems [26]. This method is a robust and versatile technique and also considered appropriate to solve artificial intelligence problems such as identification, short and long-term prediction of random processes and recognition of patterns in complex systems [14, 28].
The characteristics presented by the GMDH and its diversity of uses are the features that lead the use of this algorithm for application in this methodology. Moreover, for selecting the most relevant input variables, due the ability to avoid problems with overfitting, and for objectively selecting the optimal model, all those advantages favored their choice.
The fundamental concept of the GMDH approach is to structure a feedforward multi-layered neural network, using hierarchically connected partial models, so that the best models can be selected through appropriate methods, and the bad models are discarded [29, 30]. Each layer consists of input variables pairs and one output variable (Fig. 1).
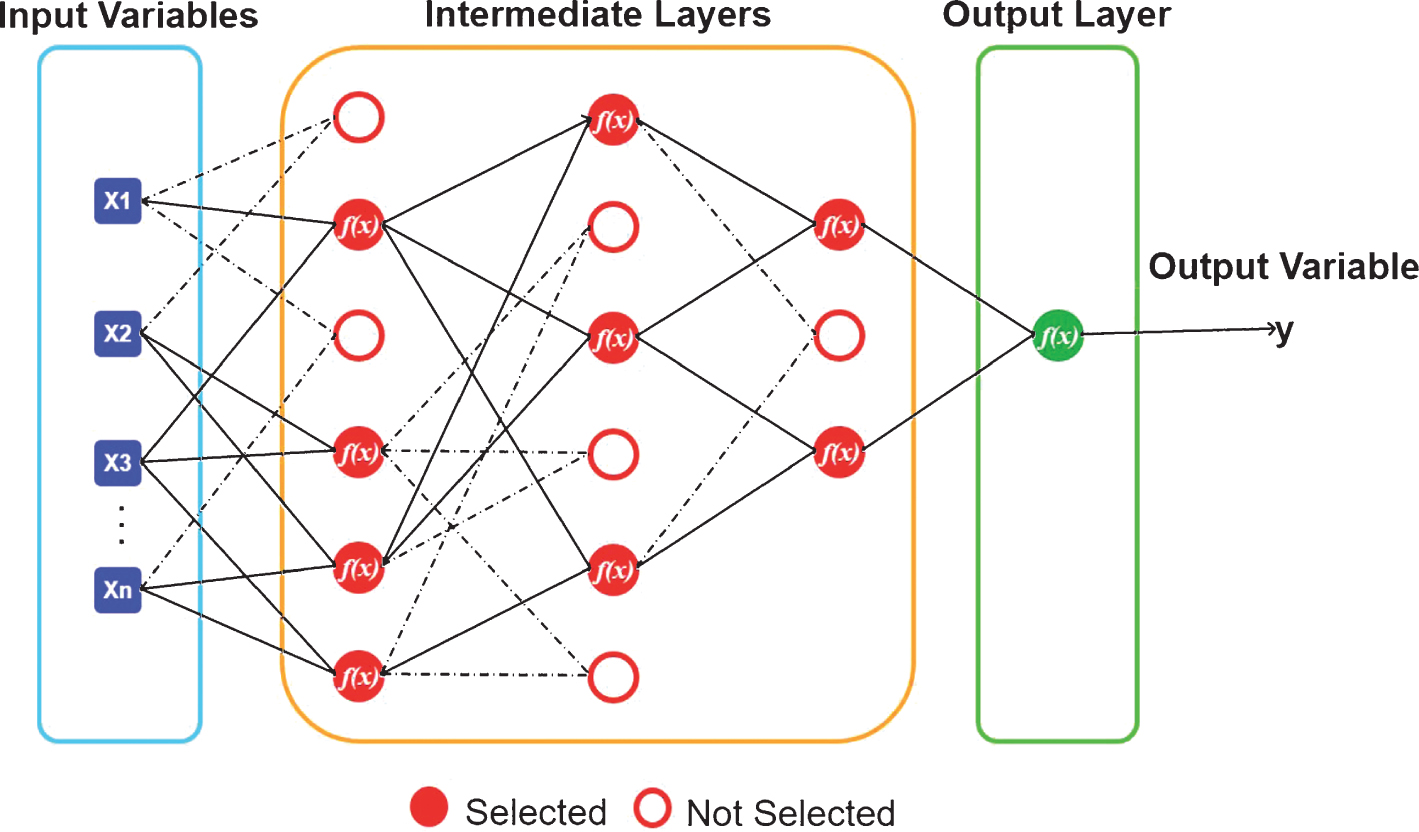
General architecture for a GMDH-type network.
The general mathematical formulation that solves the connections between input and output variables can be explained by the polynomial function theory named Kolmogorov-Gabor polynomials [31, 32]:
In each set of learning data which includes both the dependent variable y, as well as the independent variables x1, x2, . . . , x n , the data sample is separated into training subset and test subset. From the n input variables, combinations using two variables are generated for all input variables, to form pairs that constitute the units that will integrate the first layer. For all units are estimated some weights parameters using the training subset.
A criterion is defined as a comparison metric between the partial models and the expected result, to select the best partial models, discarding those that do not meet the criterion of choice. The selected partial models become part of the first layer, and the predictions of the first layer units are set as new input variables that will feed the next layer and thus build a multilayer structure by applying the previous steps. When the selection criterion of the partial models is no longer met, the addition of new layers is finished and the unit of least error in the highest order layer is chosen as the final model.
In general, a neural network can be understood as a structure formed by a set of interconnected processing units, in which each processing unit, named an artificial neuron, has an activation function [33]. Multilayer Perceptron (MLP) consists of a type of feed forward neural network composed by an input layer and output layer, in addition to at least one layer of intermediate neurons, named the hidden layer, which is responsible for the nonlinearity of the MLP networks allowing that be able to solve complex problems, just like the real problems [34], as showed in the Fig. 2.
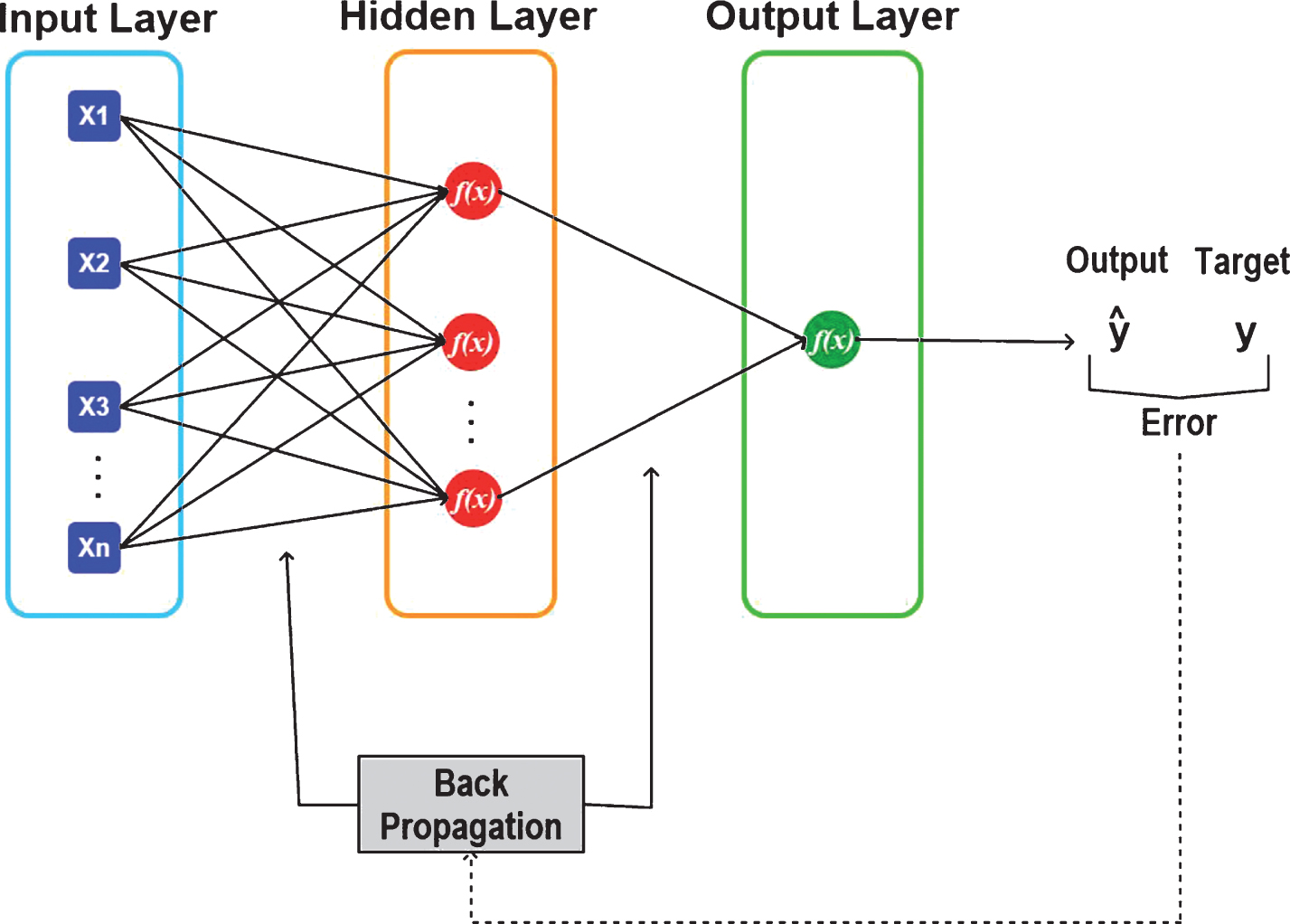
– MLP scheme with back-propagation algorithm.
The training of the MLP networks requires the use of an algorithm that allows to establish an optimal set of weights for the network. The most widely used learning algorithm for non-linearly separable tasks is error back-propagation algorithm (BPA) [35, 36]. The problem encountered during the training of an MLP is that with the inclusion of one or more intermediate layers, the error of these layers is not known, although it is necessary to adjust the weights. But this issue can be solved with BPA, which performs a recursive propagation of errors.
As learning is supervised, the goal of BPA is to adjust weights so that the error between the desired and calculated output is minimized. This process occurs from the error between the sample pairs of input and output ANN data, consisting of two phases: forward and backward. The forward phase is used to find an output from the input values of a given pattern, that is, the signals are propagated in the progressive sense (from the input layer to the output layer), finding the signal output and error, but keeping the weights fixed. The backward phase compares this output with the desired output and recursively updates (from the output layer to the input layer) the values of the weights of the connections of the neurons of the structure [33, 35]. The error is determined according to the rule of weight adjustment (generalized delta rule) [37, 38]:
BPA can be applied to any network that uses a differentiable activation function and supervised learning, being based on the gradient descent. The training process is performed based on trial and error, so one of the problems of the algorithm is its training time. The rate of updating of weights is what influences this time. If the set rate is too low, the network consumes too much time for training. On the other hand, if the rate is high, the network can converge in a short time interval, but when another input is presented, the network may become unstable, resulting in unreliable results. For this reason, this work tested the application of two algorithms for BPA optimization: Levenberg-Marquardt and Bayesian regulation.
While the standard back-propagation uses the gradient descent as a method of approximation the minimum of the error function, the Levenberg-Marquardt (LM) algorithm uses a Newton approximation [39]. This approximation is obtained from the modification of the Gauss-Newton method by introducing the parameter μ, according to the equation:
Regularization is a generic name for methods involving the modification of the performance function of neural networks, which is usually the sum of the squares of training errors, and aims to improve its generalization capacity [41]. Eventually, data used as input from a neural network may not be as clean as desirable, and such a noisy condition may lead the training data set to an overfitting. Thus, the approach employing Bayesian regularization can improve the generalization ability of the neural network and present a better model performance. In the Bayesian approach the performance function can be optimized by treating the synaptic weights and biases of the network as random variables with specific distributions, such that the objective function F is defined as
The Bayesian structure is a technique that allows to automatically determine the optimum parameter. This method causes the parameter to be selected using only the training data, without having to use separate training and validation data. The Bayesian structure considers a probability distribution over the weighting space, representing the relative degrees of reliability in different values for the weights. The weight space is initially assigned to some previous distribution. Let D ={ xm, tm } the training data set of the target input pair. After the data are obtained with the Gaussian additive noisy assumed at the target values, the posterior probability distribution for the weight p (w|D, γ) of the ANN can be updated according to the Bayes rule:
If a uniform prior density p (γ) is assumed for the regularization parameter γ, then the posterior probability maximization is obtained by maximizing the probability function p (D|γ). Since all probabilities have a Gaussian form, it can be expressed as
The flowchart of the process that defines the general methodology for developing the non-physical models to simulate the potential for hydropower generation is presented in Fig. 3.
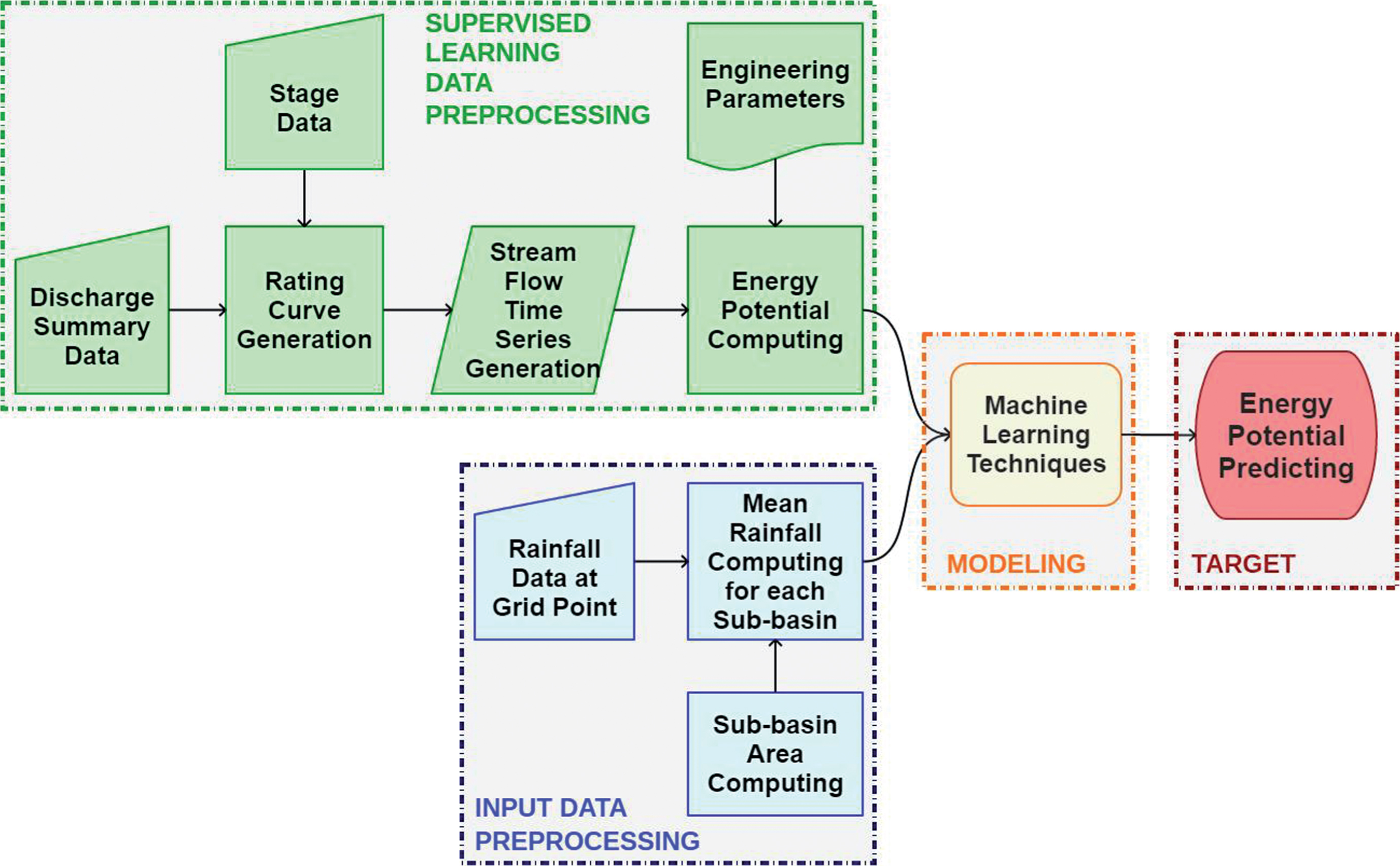
Process to forecasting the potential for energy generation.
Initially, summary discharge and stage data are processed to generate a rating curve that provides the stream flow time series. Stream flow dataset are converted into potential for hydropower generation by means of a mathematical equation that employs design parameters. The rainfall volumes in grid point are weighted for each sub-basin, generating a rainfall series per sub-basin. Finally, the rainfall data per sub-basin and the actual potential for hydropower generation are both introduced into a supervised network to modeling the potential for hydropower generation. The detailed description of each step of this process is presented following.
At the measurement section of a river, stage gauge is used to measure the daily river height, i.e., the stage of the river. On the other hand, the discharge summary information consists of streamflow measurements taken during periodic field campaigns at a river section. The discharge measurements allow establishing a relation between stage and streamflow. This relationship is necessary for the systematic obtaining of the streamflow, no need of direct measurement. The stage-streamflow relationship is established graphically through the so-called discharge curve or rating curve of the section [44]. The rating curve is just an equation fitted to the streamflow measurement data (discharge summary).
Rainfall dataset
The rain has a strong relation with the streamflow and can be more easily obtained by both surface and orbital sensors. On the other hand, the rainfall presents large variability in time and space, which characterizes rainfall as a climatic variable of non-linear behavior. The precipitation information used in this research are available from the Climate Prediction Center / National Centers for Environmental Prediction (CPC / NCEP), whose dataset has global coverage in a 0.5° latitude ×0.5° longitude regular grid [45, 46]. This dataset is a combination of two kinds of data: a gauge-based (surface observations) analysis of daily precipitation and estimates of rainfall by satellites using the microwave and infrared channels. The period of coverage starts from January 1979 to the present day.
The daily rainfall data for each grid point was processed to obtain the mean monthly precipitation in each drainage area, i.e., the sub-basin of interest. The mean precipitation was determined using the methodology proposed by Thiessen [44, 47], as determined by the expression below:
The potential for power generation of a hydropower plant is estimated using the following expression [5, 48]:
The application of the GMDH method in this investigation considered the implementation of the multilayered iteration algorithm (MIA) with polynomial transfer functions. The MIA was considered appropriate for this research because it allows working with a large number of variables, which in turn requires the analysis of a large number of partial models combinations [49].
First, the partial models were compared based on bias, and then retrained based on total training and test data. The decision to cease training is adopted after comparing the relative error of the training layer with the minimum error of the layer. When that difference reaches a value lower than epsilon, then the training was terminated. The epsilon is the reference threshold of the training stop condition, whose value is 0.001.
The MIA can combine four types of polynomial transfer functions, as shown below:
The rainfall data for each single seven sub-basins are the input for the models. And they are lagged in up to twelve months, totaling up to 91 inputs. The dataset was separated into two independent samples. The first one, built with 33.33% to the training/validation set, i.e. 120 observations. And the second using the 66.66% remaining, i.e. 240 observations, which were used to test the model. The training/ validation dataset was divided into training and validation subsets as follows: training, validation, validation, validation, training, validation,..., training, validation, validation, validation, training, so that the last value is belonging to the training subset.
The neural network models with BPA were also designed using the same set of 91 input variables as previously described. The activation function adopted was the hyperbolic tangent. The architectures tested for the network showed that only one hidden layer was sufficient to model the potential for hydropower generation [50]. Two algorithms were tested for BPA optimization: Levenberg-Marquardt and Bayesian regulation. The tested configurations used from 1 to 90 neurons in the hidden layer, learning rates ranging from 0.01 to 0.5, momentum range from 0 to 0.9, and initial weight configurations were tested. To avoid overfitting the learning phase was interrupted in 100 iterations. The learning was stopped from the increase of the MSE. The learning data set was divided into training sample (80 observations) and validation sample (40 observations). The built models were validated based on the MSE of the validation set.
Model evaluation metrics
Evaluating the ability of the model is fundamental to define its application potential. For this, the following metrics are used to quantify the model performance: correlation coefficient (R), mean absolute error (MAE), and mean absolute percentage error (MAPE).
Correlation coefficient – R
The correlation coefficient (R) is a measure that indicates the association degree between two or more variables, whose interval of occurrence is limited between the – 1 and+1 values [51]. A correlation is considered weak when it reaches values below 0.6, obtained through the formulation below:
The absolute mean error (MAE) consists of an arithmetic mean for the absolute values of the deviations between the members of each pair. This is a common measure to evaluate the accuracy of predictions for continuous predictors [52] and can be determined using the following equation:
MAPE consists of a measure of error size in percentage terms and is used as an estimate of the accuracy of a forecast.
Site location
The proposed methodology for modeling the potential for hydropower generation was tested for the Jatobá HPP. The Tapajós River basin is in the Brazilian states of Pará, Mato Grosso, Amazonas and Rondônia, and belongs to the Amazon River basin. The Tapajós River has approximately 2,000 km long, is born in the Mato Grosso state, from the confluence of the Juruena and São Manuel Rivers, also known as Teles Pires, and flows into the Amazon River, already in the state of Pará [53]. The total area of the Tapajós river basin has 764,183 km2, the relief ranging highlands to regions of hills and plateaus, whose altitude varying from 51 meters to about 900 meters [54]. The Tapajós River basin (Fig. 4) can be subdivided into seven smaller sub-basins, which have a drainage area that has a direct influence on the Jatobá HPP. The HPP Jatobá is situated approximately 1 km downstream from the town of Jatobá [54]:
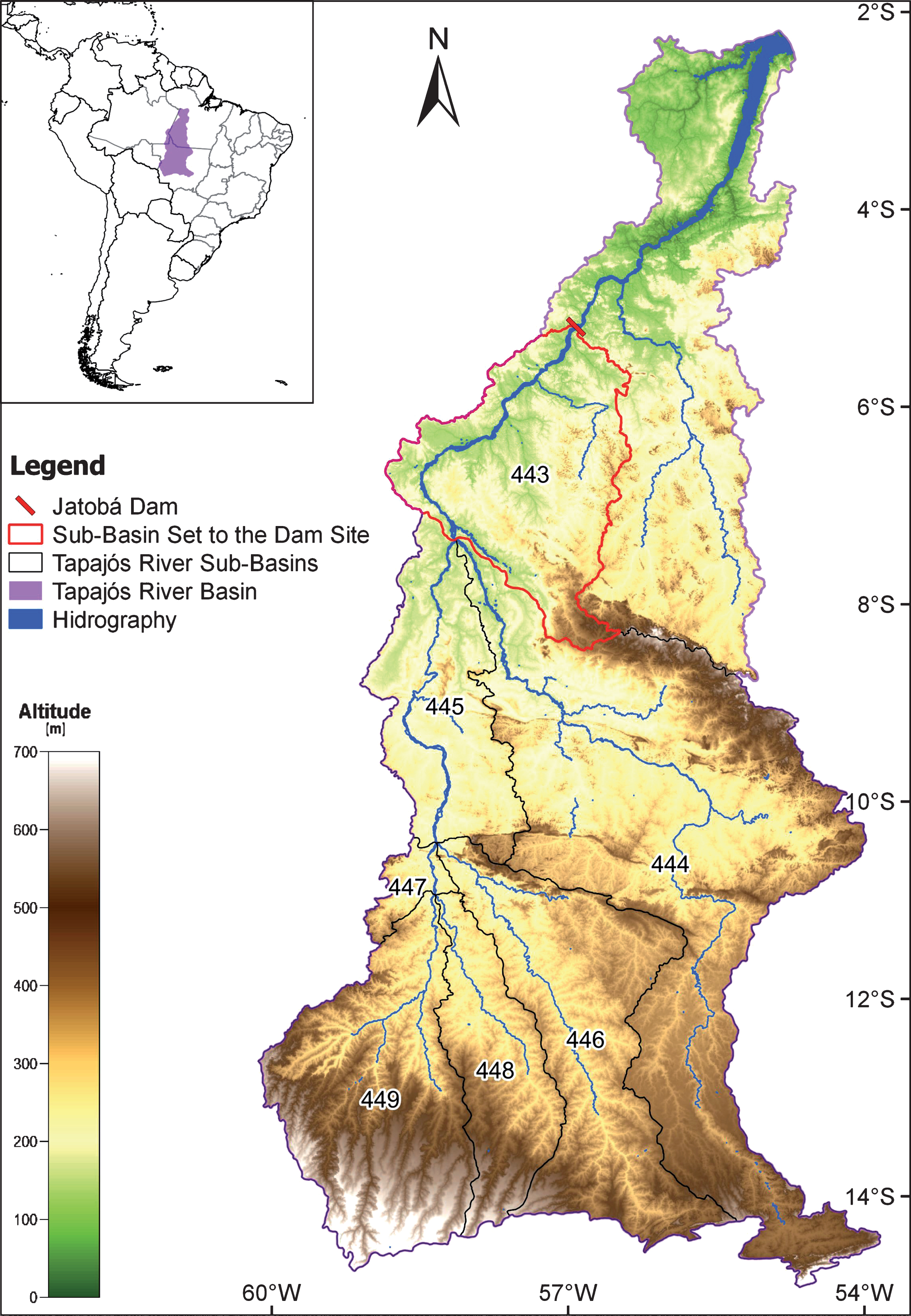
Tapajós River basin. The numerical codes presented in the delimited areas represent the sub-basins that compose the main basin of the Tapajós River. The sub-basins 443, 444, 445, 446, 447, 448 and 449 set the drainage area of the Jatobá HPP.
This research used discharge summary data from Jatobá hydrological station (code 17650000), which is located at the municipality of Itaituba, Pará state. These data are made available by the National Water Agency (Agência Nacional de Águas - ANA) and cover the period from 1984 to1997.
The gauge height data comprise the period from 1984 up to the station decommissioning, which took place in 2013. Generally, ANA provides along with the discharge summary data, the rating curve for the river section. However, in this case, as there is no official rating curve published for the Jatobá station, it was necessary to develop an equation for the calculation of the stream flow series.
The determination of the rating curve (Fig. 5) to obtain the time series of flow at Jatobá it was executed by launching the discharge summary data in a calculation spreadsheet. Then, data fit functions were defined in polynomial form, exponential form, among others. The coefficient of determination (R²) was adopted as a criterion to select the best-fit function adapted to the river’s behavior, thus selecting a polynomial function of degree 2. Thus, using the rating curve and the monthly height gauge data, we can generate the time series of the monthly mean discharge at Jatobá. Then the discharge data are used in Equation (12) to determine the monthly potential for the hydropower generation, as will be detailed later.
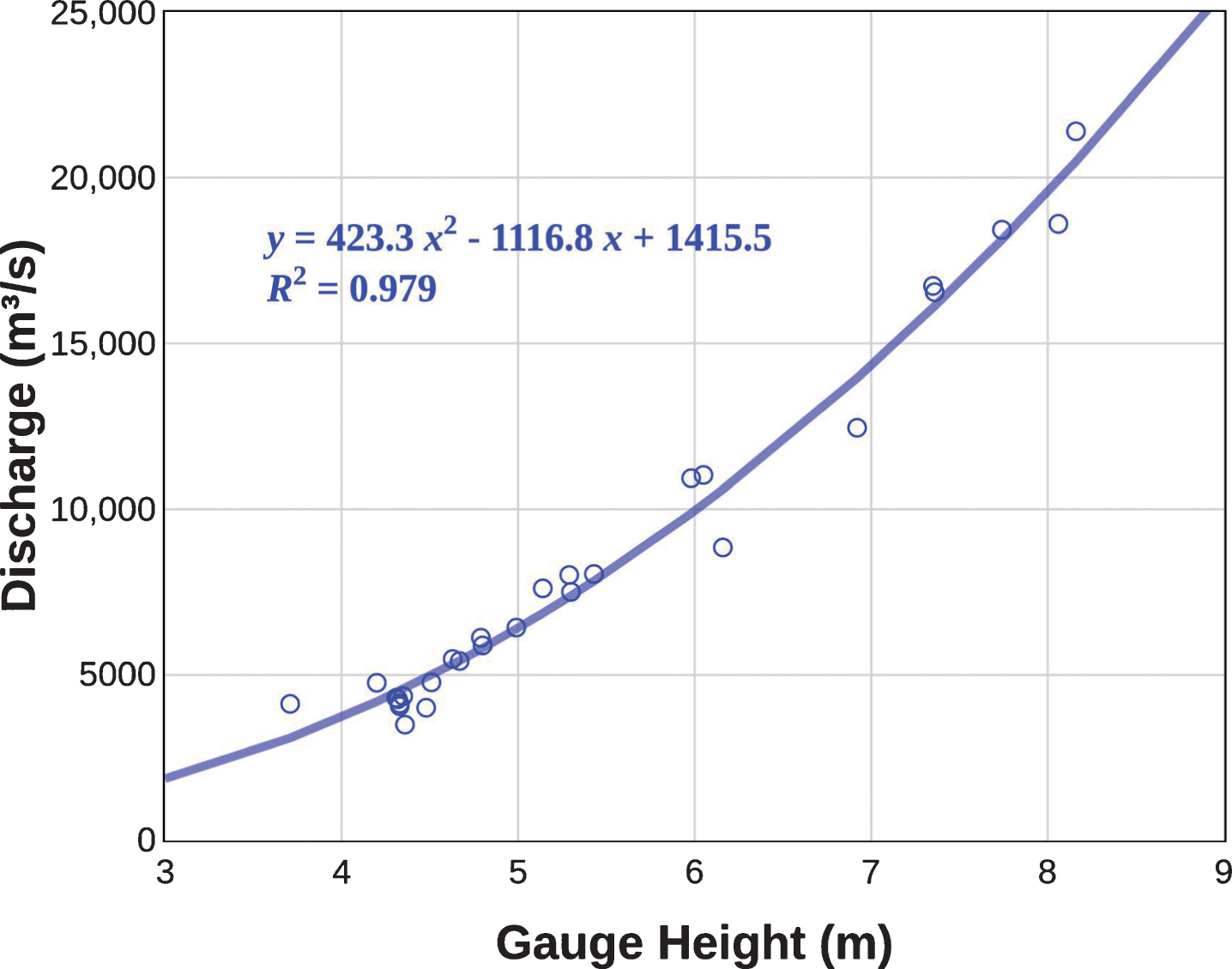
Rating curve to the Tapajós River at Jatobá gauge station.
The calculation of the river basin area and each grid point area (Fig. 6) was performed using the Quantum Gis geoprocessing software. Thus, the mean monthly rainfall time series was obtained for each the seven sub-basins of the Tapajós River that influence at Jatobá. This rainfall data are the input to the models to simulate the potential for hydropower generation. The sub-basin area 443 has been reduced from the original size and adjusted to the point where the dam will be installed. The new form adopted by sub-basin 443 considered the topography of the site and the drainage network, henceforth referred to as the Jat sub-basin (443 adjusted).
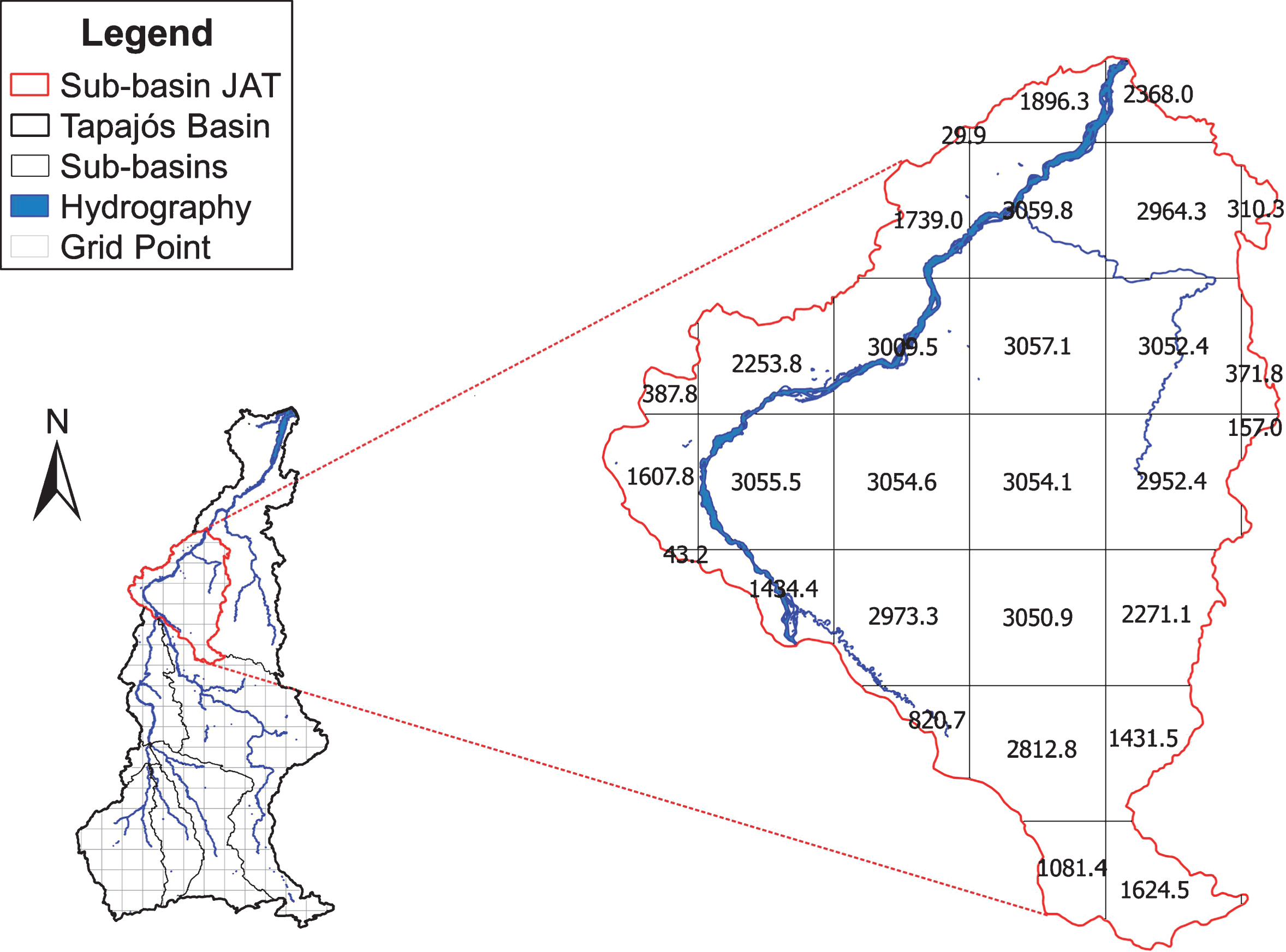
Area calculation for each grid point (in km2).
The specific engineering parameters are obtained from the design of the plant, as provided by the Energy Research Company (Empresa de Pesquisas Energéticas - EPE). They considered 35 meters for the hydraulic fall and 95% efficiency for the turbine-generator set. The values are replaced in Equation (12) for generate the time series of mean monthly potential for energy generation ranging the period from 1984 to 2013.
To this paper several setups were tested for both GMDH and ANN. The best architecture obtained for the GMDH-type polynomial network selected 16 variables to build the model from 91 possible input variables, according to the following combinations: P-JAT (1) , P-JAT (8) , P-JAT (10) , P-444, P-444 (1) , P-444 (3) , P-444 (10) , P-445, P-445 (2) , P-445 (9) , P-447, P-447 (9) , P-448 (2) , P-449, P-449 (2) , P-449 (9) , where the indices in parentheses show the time lag used. The activation functions employed were linear, linear covariance and quadratic. About the ANN models, the Levenberg-Marquardt algorithm, here called ANN-LM, had the best performance using 6 neurons in the hidden layer. While the ANN using Bayesian regulation algorithm, named as ANN-BR, obtained better results using 9 neurons in the hidden layer.
Table 1 shows the results of the models for the training and validation phases using some objective metrics of performance evaluation. Regarding the correlation (R) between the observed and simulation dataset, all the models showed good skill, with a slight advantage for the GMDH and ANN-BR, which reached 98% correlation. However, ANN-BR showed the lowest mean absolute error. By this criterion, the GMDH obtained inferior performance, although the difference between all the models was very small. On the other hand, the lowest percentage error (7.92%) was obtained by the GMDH, followed by ANN-BR (8.36%) and then ANN-LM (9.53%), respectively. Thus, the GMDH model obtained better performance for the R and MAPE criteria, while the ANN-BR model obtained the best performance for the R and MAE criteria. And the ANN-LM model showed worse performance for all evaluation criteria.
Results for models’ evaluation (training/validation)
Results for models’ evaluation (training/validation)
In order to complement the understanding of Table 1, Fig. 7 presents a scatter plot. Regarding the distribution for the learning data (training and validation) around the best fit line, the ANN-BR model showed better correlation and lower dispersion in relation to the actual data, whose coefficient of determination was 0.9729.
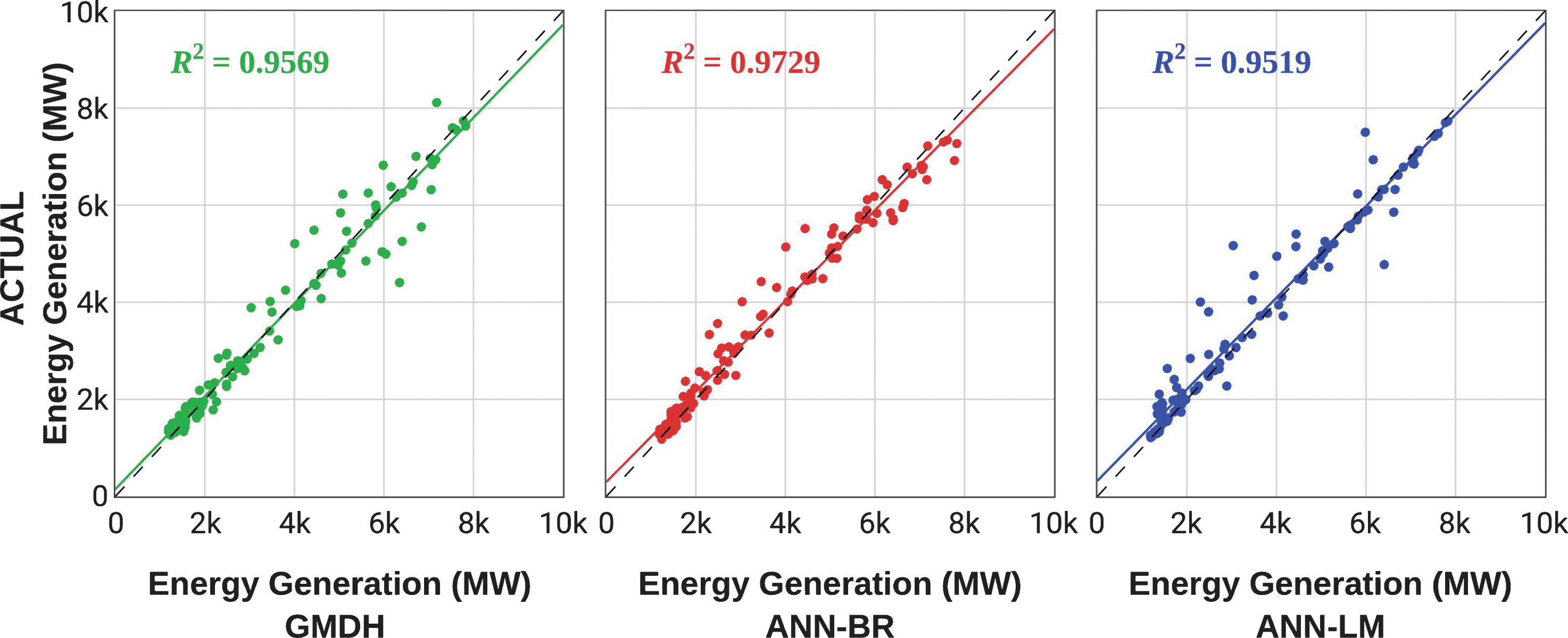
Agreement between the training/validation and actual data set.
The coefficient of determination consists of a measure about how much the independent variable(s) can explain the variation of the dependent variable. The models ANN-LM and GMDH also obtained good adjustments with the respective coefficients of determination, 0.9569 and 0.9519. However, the data simulated by these models showed greater dispersion. The dispersion of the data is not uniform along the different ranges of values, as will be discussed later.
The simulation for the learning dataset (training/validation) is shown in Fig. 8. In general, the models managed to good capture the seasonal behavior of the variable, showing great performance during the training phase. Although the extreme values of the series present large deviation, the found error is reduced, characterizing the good performance of the algorithms during the learning process.

Comparison between actual and training/validation values.
The ANN-LM model stands out for presenting an almost perfect fit for the training dataset (first 80 observations) and large variance for validation (last 40 observations), characterizing the difficulty for generalization of the model and overfitting tendency, with overestimation of the data. This behavior can be explained by the small number of observations for the training set and many variables (91) in the input layer. For such conditions, the smaller the number of neurons in the hidden layer, whatever the architecture adopted for the ANN-LM network, the number of parameters to be estimated will always be much higher than the number of observations. Many parameters against few observations for training reduce the network’s generalization ability by not capturing the complexities in the patterns between the input variables and the target, often leading to an overfitting [55]. This can explain the lower performance of the ANN-LM model compared to the others.
The performance of the ANN-BR model was similar throughout the learning phase, denoting better capacity for generalization. This behavior differs from the previous model because the regularization technique leads the biases of the parameters to the direction in which values are more probable. Therefore, this technique tends to reduce the variance of estimates in the cost of introducing biases [55].
Finally, the GMDH model also presented regular behavior throughout the training phase, being favored in this case by choosing the input variables of greater relevance for the modeling, optimizing the learning and avoiding the overfitting.
Figure 9 shows that the simulated data may have a greater or lesser dispersion depending on the range of simulation values. Thus, Fig. 9 presents a statistic that shows the limitation and distribution of model error for four different ranges of values: less than 2000, between 2000 and 4000, between 4000 and 6000, and greater than 6000. Since the relative error is strongly dependent on the actual data, it provides an idea of the forecast accuracy.
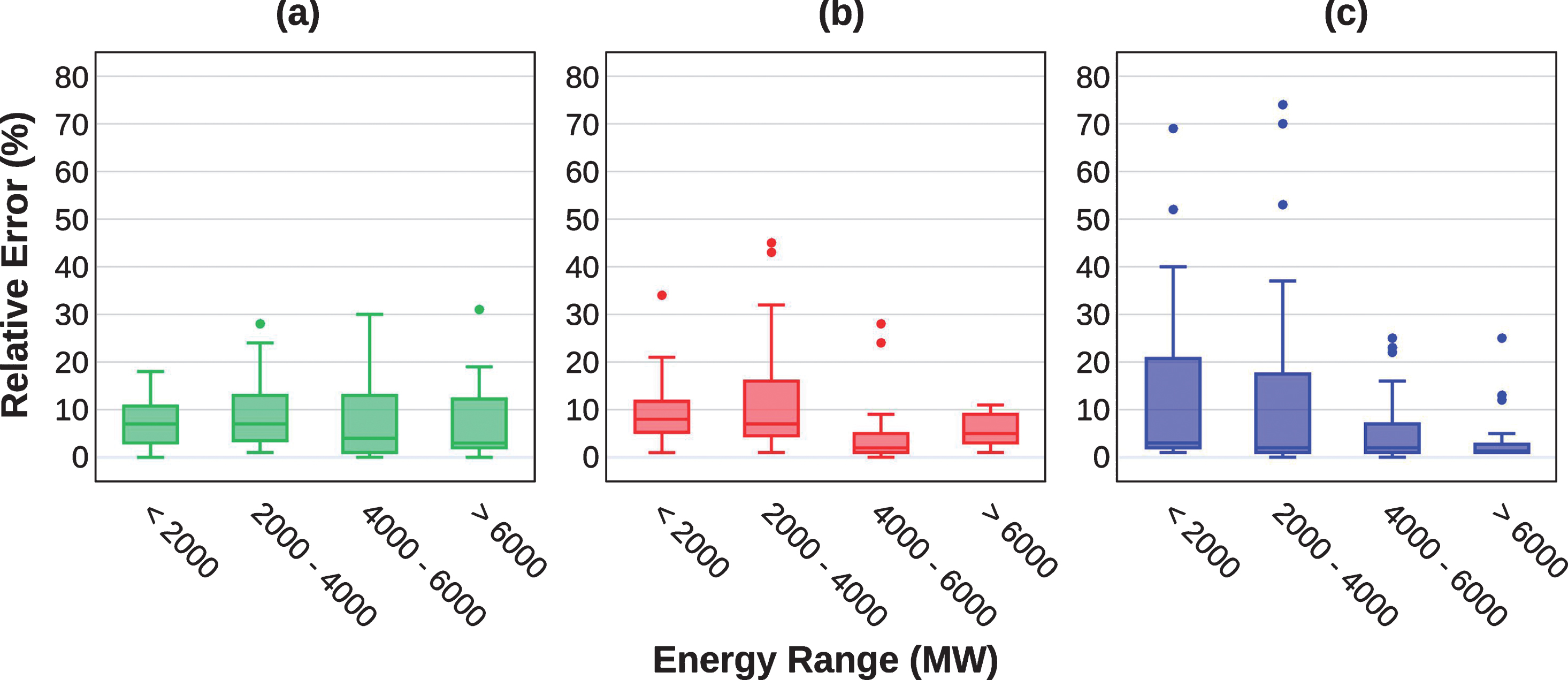
Relative error by energy band for the training/validation data set. (a) GMDH, (b) ANN-BR and (c) ANN-LM.
The first interval (<2000) is the most important for the forecast because it is associated with the minimum values, which should define the steady energy of the plant. Therefore, it is fundamental that the models present consistent behavior in this range. The GMDH model showed a symmetrical distribution for the relative error on the range less than 2000, centered in 7% (median) and with maximum 18%, and a small dispersion, all of them desirable conditions. For the second category (2000-4000) the error remained centered at 7%, but the dispersion was higher. In the following interval (4000-6000) the relative error distribution was quite asymmetric, with error reaching up to 30%. For the last interval that corresponds to the maximum values, there was an asymmetry increased and except for the outlier, the maximum relative error was below 20%.
Regarding the ANN-BR model, the error distribution was quite symmetrical for the lower interval, with error centered at 8% and outside reaching 21%, although one outlier occurred. For the following interval (2000-4000) there was marked asymmetry and large dispersion, with outside above 30%. On the range of values between 4000 and 6000, the ANN-BR showed its best performance, with a maximum error less than 10% and low dispersion, although two outliers were observed. And for the highest values, the relative error was around 5%, with low dispersion and variations of up to 11%.
The third model, ANN-LM, although it presented very small errors during the training, the validation phase clearly negatively influenced the overall performance of the model during the learning, making the error present large variation, especially in the first two classes of intervals, reaching up to 40% error. While in the last two interval classes, even with error reduction, especially for maximum values, many outliers still occurred.
Thus, during the learning phase, the GMDH model presented better accuracy for prediction values below 4000 MW, while the ANN-BR model obtained better accuracy for values above 4000 MW.
In relation to the test dataset, which is used to provide an unbiased evaluation of an adjusted final model, Table 2 presents the results of the accuracy of the developed models. The GMDH model presented the best performance compared to the others, although only slightly superior to ANN-BR. These indicators show that the GMDH model presented better capacity for generalization, because its performance during the test phase obtained a lower variation compared to the training phase, maintaining a good accuracy, with 0.95 correlation coefficient, 443 MW for the mean absolute error and only 12.34% mean percentage error.
Results for models’ evaluation (test)
Figure 10 shows the adjustment curve between observation and prediction for the test dataset. ANN models presented lower capacity for generalization, with greater dispersion of the data and obtaining 0.88 and 0.83 coefficient of determination for the Bayesian regularization and Levenberg-Marquardt algorithm, respectively. The GMDH model reached the highest coefficient of determination, 0.90, meaning that the variables selected for the input layer can well explain the dependent variable and therefore the curve was fine fit on the scatter plot.

Agreement between the test and actual data set.
The models’ skill can best be seen in Fig. 11, which refers to the test subset. In general, the models’ performed a good skill, highlighting the excellent simulation for the minimum values, specially to GMDH and ANN-BR. Clearly, there were underestimates of the peaks occurred for the year 2005 up to 2009, and from 2012 to 2013. Probably this behavior is associated with the dataset of the CPC. In general, for regions with poor rainfall coverage, and it happens in Amazon region, the grid point data of the CPC tend to underestimate the severe events with too voluminous rainfall due to convective precipitation [56]. Therefore, it is very likely that a noisy input data has led to larger errors during the simulation of the energy maximum peak. However, the possible underestimate of the peaks, while not desirable, does not compromise the feasibility studies of the project which is based on the critical point.
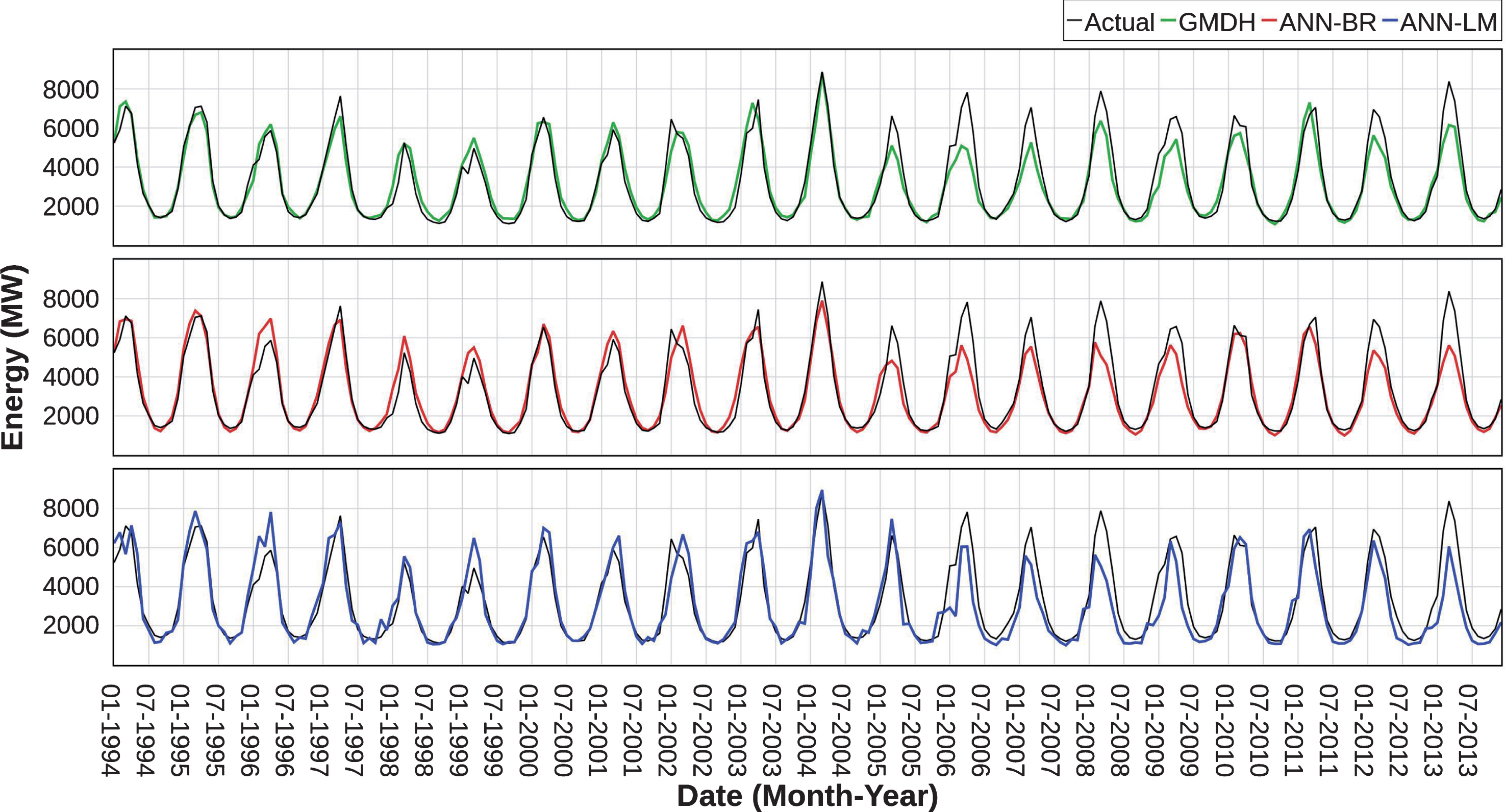
Comparison between actual and testing values.
Such as the learning phase, during the test period the error of the models was higher for the higher values of power generation but presented low values for the minimums. For the precursor studies that define the potential for the power generation of a hydroelectric plant, especially those of the run-of-the-river type, it is fundamental to determine the critical points of lower natural flow from the historical data, which correspond to the lower generation of energy and should define the steady energy of the plant, i.e., the maximum continuous production of energy.
From the test dataset, Fig. 12 shows the variation of the relative error by range of values. For the lower range, the GMDH model presented better performance than the others, with an average error around 8%, but very close to the ANN-BR model. In relation to the following classes, the mean error varied between 11% and 17% for the GMDH model, while the ANN-BR model showed a constant average error around 12%, but with greater variability, even with some outliers. In the second and third categories of values there was alternation of better performance between ANN-BR and GMDH. While in the latter category both the models, GMDH and ANN-BR, achieved very similar performance. The ANN-LM model presented lower behavior, with a large interquartile range and the worst performance comparing to all classes of values.
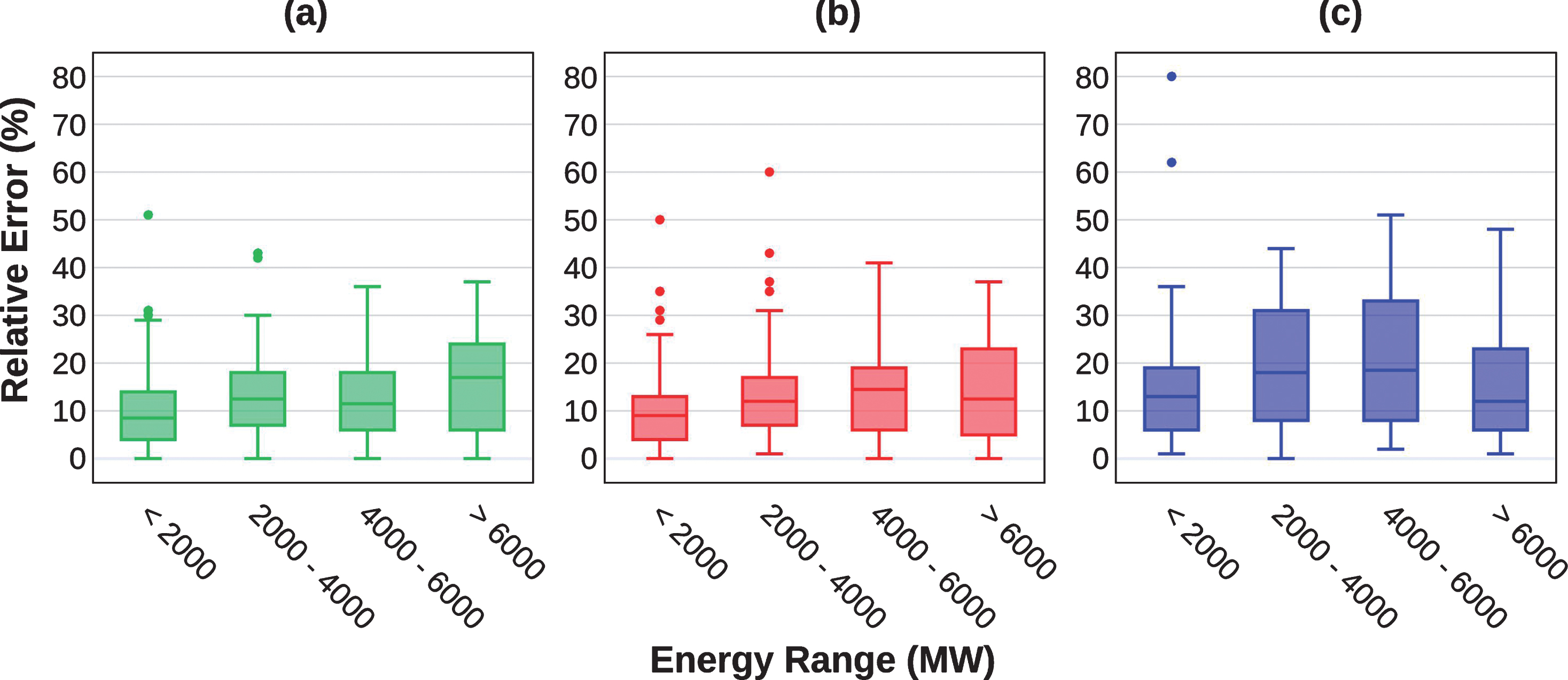
Relative error by energy band for the test data set. (a) GMDH, (b) ANN-BR and (c) ANN-LM.
The coefficients of determination and correlation indicated a strong relation between the chosen independent variables (monthly mean precipitation) and the dependent variable. This allowed us to model the potential for hydropower generation to achieve high dexterity. About the simulation error, both learning and forecast results obtained satisfactory error rate.
The machine learning approach proved to be a successful and robust tool able to model with high dexterity the power generation of a hydroelectric enterprise in the Amazon, from the rainfall regime.
The modeling of the potential for hydropower generation was studied using the GMDH and ANN techniques. The three GMDH, ANN-BR and ANN-LM algorithms were used to build the polynomial and MLP neural network architectures. The prediction of energy potential, especially for the critical period of generation, performed better with the GMDH approach, although Bayesian regularization achieved quite close performance.
The ANN-LM showed to be inadequate for the studied purpose, presenting low ability for generalization and, therefore, large dispersion of data and less accuracy.
The self-organizing feature of the GMDH network showed to be very appropriate for selecting the best-input arguments of the network to optimize the model result. The performance of the GMDH network showed a good skill, especially to safely capture the critical points.
Finally, this methodology ensuring statistical safety in its results, which will allow a better prior evaluation of the energy potential predicting by the project. It can improve the planning of scenarios, especially those related to the natural variability of the rainfall behavior. It can reduce the operational costs, especially those associated to the field activities for flow measurements and maintenance of hydrometric stations. In addition, it can generate synthetic time series of the potential for energy generation, covering periods without local observation of the stream flow, allowing to extend the historical data to assist in the preliminary and sequential studies of the plant.