
Abstract
Time decay model (TDM) is frequently used for mining frequent patterns on data streams, because the information embedded in the data from the new transactions is particularly valuable. However, some existing methods on designing decay factor of TDM are random, so their results are unsteady. Some other methods focus on only 100% recall or 100% precision of algorithm, but the corresponding high precision or high recall is ignored. In order to balance high recall and high precision of algorithm, meanwhile, ensure the stability of the result, a novel average decay factor is designed. In addition, to further increase the weights of the latest transactions and reduce the weights of historical transactions, another novel Gaussian decay factor is proposed. Hence, based on an analysis of existing decay factors, this paper aims to design two novel decay factors and two novel TDMs. Algorithms based on these two TDMs are designed to discover frequent patterns over data streams. The methods of mining frequent patterns on high density or low density data streams are evaluated via experiments. This paper’s research findings show that the application of average time decay factor can balance the high recall and high precision of algorithm. And Gaussian decay factor can produce better performance than existing algorithms.
Introduction
Data stream is ordered, changing, massive and unlimited, so the knowledge it contains will change in time. Typically, recent transactions contain more valuable knowledge than historical transactions [1, 19]. Therefore, the process of mining frequent patterns on data stream emphasizes the frequent patterns which are generated by the recent transactions. For this reason, several models, landmark window models(LWM) [28], sliding window models(SWM) [9], and time decaying models (TDM) (also called damped window model) [26] have been used to find recent interesting information from datastreams.
The sliding window model and the time decay model are commonly used to discover patterns. The SWM captures a fixed number of recent transactions in a window, and it focuses on discovering the patterns within the window. Based on sliding window model, some methods are proposed to find frequent patterns [4, 27], high-utility patterns [8, 28] or sequential patterns [10, 16] over data streams. In the time decay model, each transaction is assigned with a weight that decreases over time. Therefore, in this model, recent transactions are more important than old ones. Some algorithms are proposed to find frequent patterns based on time decay models [9, 26]. The sliding window model is used to emphasize the frequent patterns mining in the recent sliding window, but the weights of all transactions in the window are the same. The time decay model distinguishes the weights between recent transactions and historical transactions within the window.
However, it is difficult to choose an appropriate decay function or decay rate for TDM. There are three ways to set the decay factor as follows. The value of the factor is defined as a random value in the range of (0,1] [14, 26]. This method to set the decay factor may cause instability of the results because of the different random values. The value of the factor is defined as a constant value which is irrelevant to the window size [3, 11]. Its disadvantage lies in the fact that the performance of algorithm may vary widely with the changing of window sizes. The value of the factor is defined as a boundary value. The upper or lower bounds are achieved with the estimation of 100% recall or 100% precision of algorithm [5, 15]. The defect in this way is that it can get high recall or precision, but with the low precision or recall.
Above all, based on TDM and SWM, the study of mining frequent patterns on data streams should focus on two things. The first one is to discover the relationship among several parameters: sliding window size, minimum support threshold, maximal support error threshold and decay factor. However, after the values of the first three parameters are determined, it is difficult to determine the value of decay factor. The second one is to balance high recall and high precision of algorithm and to ensure the stability of the results. In this paper, we summarize and analyze the existing ways of setting decay factors, and we propose two new factors. Our contributions can be summarized as follows: A new average decay factor faverage is proposed in order to balance high recall and high precision of algorithm. Another novel Gaussian decay factor is proposed to improve the weights of recent transactions and to reduce the weights of historical transactions in the sliding window. Meanwhile, we explore the close relation among decay factor f, variance δ and the sliding window size N. Two new kinds of TDMs based on f _ average and f _ gauss are proposed. Algorithms based on these two TDMs are proposed to mine frequent patterns on data streams of different data characteristics. Through an experimental study on real-world and synthetic data streams, these proposed algorithms show the potentials.
The rest of this paper is organized as follows: Section 2 presents background knowledge aboutfrequent pattern mining on data streams and the time decay model. Summary and analysis of three categories of setting decay factors is provided in Section 2. Two new decay factors and comparisons of different decay factors are introduced in Section 3. Section 4 describes the experiments and explains the experimental results to verify the reasonableness of novel decay factors. Section 5 concludes the work.
Related work
Preliminaries
A data stream DS =< T1, T2, …, T i , … > is a continuous and unbounded sequence of transactions, where T i (i = 1, 2, …) is the ith transaction. Let A = {a1, a2, …, a n } be a set of items in DS, and T i (i = 1, 2, …) is a subset of A. A transaction is a tuple, denoted as (TID, itemset), contains a unique transaction identifier TID and an itemset, as shown in Table 1.
Four transactions in a data stream
Four transactions in a data stream
In the applications of time-sensitive data stream, users are most interested in the recently arrived transactions, thus the sliding window model is suitable for such cases. A sliding window SW of size N contains the nearly N transactions in DS. A frequent pattern P = {p1, p2, …, p k } is also a subset of A. The frequency of P, denoted as freq (P), is the number of transactions in SW where P occurs. The support of P in SW, denoted as sup(P), is defined as freq (P)/N. P is a frequent pattern in SW if sup(P) ≥ θ, where θ (0 ≤ θ ≤ 1) is a minimum support threshold. P is a frequent closed pattern in SW, if P is a frequent itemset in SW and there exists no itemset Y in SW such that X ⊂ Y and freq (X) = freq (Y). In this paper, we will focus on mining frequent closed pattern over data stream on the basis of sliding window model and time decay model.
Due to the continuity and infinite, the knowledge contained in data stream may change over time. Under normal circumstances, the value of the recent transaction is more important than the historical one. Therefore, it is necessary to increase the weight of recent transaction. A TDM is developed to decay gradually the occurrence frequency of the patterns contained in the transactions with time [5].
Let the decay ratio of frequency in the unit time is decay factor f (f ∈ (0, 1]). When transaction T i arrives, the decay frequency of a pattern P is denoted as freqd (P, T i ). When T arrives, freqd (P, T) is initialized to be 1 if it contains P, and 0 otherwise. Each time a new transaction arrives, freqd (P, T) is multiplied by a decay factor f. As the new transaction T m arrives, the decay frequency freqd (P, T m ) of P is calculated by Formulas 1 and 2. When the mth transaction T m arrives, r is 1 if it contains P, otherwise r = 0.
From the above formulae, it can be concluded that the decay frequency of pattern P is smaller than its original frequency, that is freqd (P) ≤ freq (P). For instance, set sliding window size N = 1000 and minimum support threshold θ = 0.01. If freq (P) ≥ θ × N = 10, P is a frequent pattern. However, let the decay factor f = 0.8, then freqd (P) <1/(1 - 0.8) =5 as calculated by Formula 3. That means no pattern can be mined out under the time decay model.
With TDM, some possible frequent patterns may be lost with only minimum support threshold. In order to reduce the number of missing possible patterns, frequent patterns and sub-frequent patterns need to be maintained during mining process. In addition, in order to reduce the cost of maintaining patterns, non-frequent patterns need to be abandoned. The definitions of frequent patterns are shown as follows. By this method, the possible error of lost patterns is no greater than the maximal support error ɛ [5].
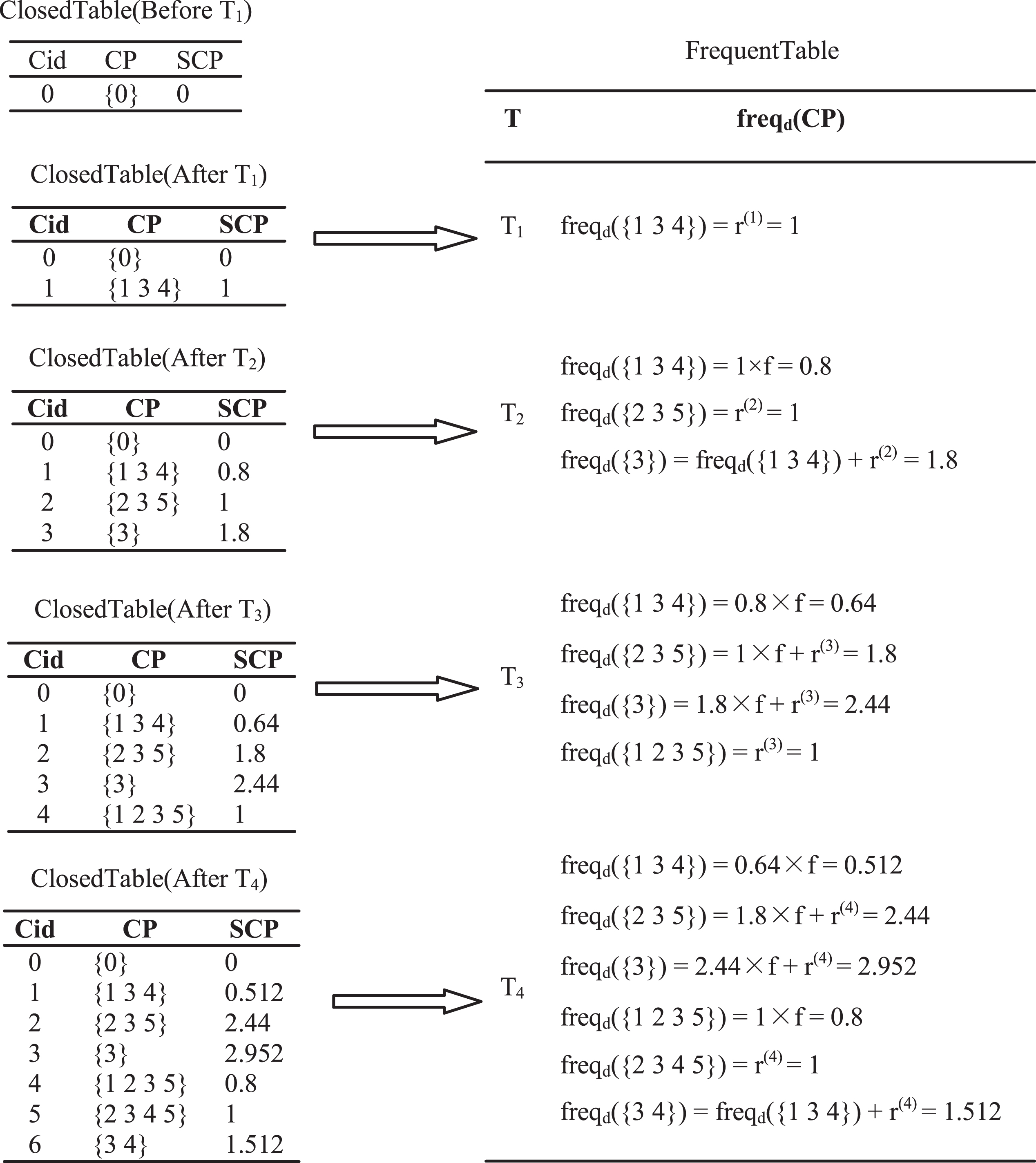
Mining frequent patterns on data stream based on TDM.
A decay function takes the initial weight and the age of an itemset. Therefore, the weight of an itemset in the sketch can decrease with time according to a user-specified decay function.
Recently, the commonly used decay function is like factor (f, x) = f x , where x is the age, and f is the decay factor. There are three types of values to set the decay factor f: user-specified value, constant value and variable value.
(1) Set the decay factor to a user-specified value in the range of (0, 1].
For instance, algorithm IncSpam [16] performs the mining of sequential patterns over a sliding window by using a lexicographical tree. And it reflects the greater importance of more recent information by means of a static decay function with a user-defined decay value of 0.999. Framework GUIDE [17] mines maximal high utility itemsets from data streams by assuming the decay factor as 0.9. DUF-streaming [14] uses the time fading window to mine frequent itemsets from uncertain data streams with setting time fading f to a user-specified value in the range of (0,1]. MPM [26] defines a damping factor, which is a real number ranging from 0 to 1. Then, the importance of transactions generated from data streams is determined by this factor. If time passes after a transaction arrives from a data stream, the importance of the transaction (frequency, utility, etc.) is multiplied by the factor.
Setting the decay factor to a user-specified value may lead to different function values. For example, let f = 0.9999, 0.999, 0.99 or 0.9 and x = 1, 100 and 1000, then the values of factor (f, x) are very different as shown in Table 2. If f = 0.999 (as in algorithm IncSpam [16]) and x = 1000, then factor (f, x) =0.90483289. While if f = 0.9 (as in GUIDE [17]) and x = 1000, then factor (f, x) =1.7479E - 46. The gap of these two decay function values is large. Therefore, setting f to user-specified values may cause unstable mining results.
Values of decay function factor (f, x)
Values of decay function factor (f, x)
(2) Set the decay factor to a constant value regardless of parameter N.
Chang [3] and Lee [13] define a decay factor by two parameters: a decay-base b and a decay-base-life h. A decay-base b determines the amount of weight reduction per a decay-unit and it is greater than 1. When the weight of the current information is set to 1, a decay-base-life h is defined by the number of decay-units that makes the current weight be b-1. Based on these two parameters, a decay factor f
d
is defined as shown in Formula 4 where b > 1, h ≥ 1, b-1 ≤ f
d
< 1.
HewaNadungodage [11] suggested that the half-life should be used to set the decay factor so as to mine frequent patterns over uncertain data streams. Half-life, which is denoted by t1/2, is the period of time which takes for a substance undergoing decay to be decreased by half. An exponential decay process can be described by the following Formula:
And the value of decay factor is shown as Formula 6.
These methods set the decay factor f without considering its relationship with the sliding window size. Therefore, with the change of the window size, the performance of algorithm may be quite different.
(3) Set the decay factor to variable value related to parameters N, θ and ɛ.
Some of the frequent patterns retrieved by stream mining algorithm are sub-frequent or non-frequent. To measure the quality of approximate mining results, two performance metrics recall and precision [5, 6] are commonly used. Given a set of true frequent patterns Q and a set of retrieved patterns O, then
Two conditions are used to set the decay factor. Firstly, assuming recall of the algorithm is 100%, all frequent patterns are discovered under the time decay model. Consider a situation in which only θ × N transactions contain the pattern P, then P is frequent for freq (p) ≥ θN. In order to get 100% recall, P should be selected even though the decayed frequency of P reaches its minimum. Theorem 1 shows a lower bound for the decay factor if 100% recall is assumed.
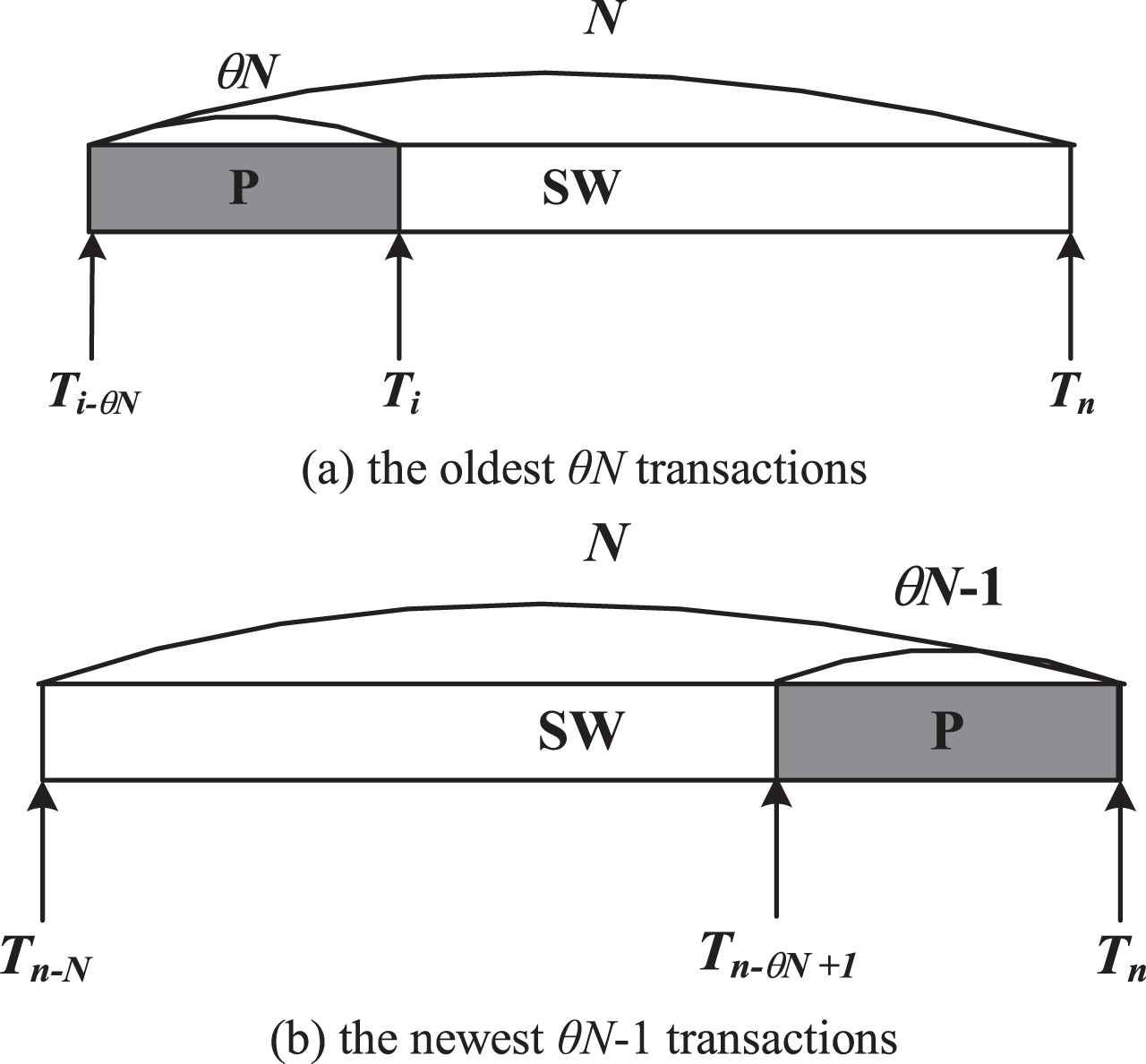
The model of mining a sliding window of data stream, (a) the oldest θN transactions, (b) the newest θN-1 transactions.
For this case, all the frequent patterns will be discovered if the minimum decay frequency can be ensured to be no smaller than (θ - ɛ) N. So, the following condition should be satisfied:□
According to the inequality of arithmetic and geometric means [5] as shown in Inequality 11, the Inequality 12 can be concluded. For inequality 10 and Inequality 12, we can get Inequality 13.
The upper bound of decay factor can be obtained by assumed 100% precision. Therefore the maximal decay frequency of non-frequent pattern P needs to be taken into account. That means the newest θN - 1 transactions contain P as shown in Fig. 2(b). If P is excluded from the mining result no matter how large the decay frequency of P is, then none of the other non-frequent patterns will be selected. Theorem 2 shows the upper bound for the decay factor in case of assuming 100% precision.
To ensure that P will not be discovered, the Inequality 16 should be met.
For fθN-1 > 0, then the following can be get.
These ways set the decay factor with considering the relationship between f and window size, minimum support and maximal error, so the scalability of the result is good. The common method sets f to lower bound with assuming 100% recall [5]. The shortage of this method is the low degree of decay and the low precision of algorithm because it only takes the 100% recall of algorithm into consideration.□
Existing methods which set the decay factor to user-specified value, constant value or boundary value of assuming 100% recall or 100% precision of algorithm are as shown before. Shortcomings of these methods are: (1) the former two methods do not consider the relationship between decay factor and other parameters; (2) the latter may get high recall or high precision and corresponding low precision or low recall.
In order to balance high recall and high precision, we proposed two novel ways to set the decay factor. Firstly, set the decay factor to average way with assuming 100% recall and 100% precision. Secondly, to further increase the weight of new transactions and reduce the weight of historical transactions, we proposed Gaussian function method to set the decay factor.
Average decay factor
This section focuses on the parameters: the sliding window size N, the minimum support threshold θ (θ ∈ (0, 1)) and the maximal support error ɛ (ɛ ∈ (0, θ)). How is the value of the decay factor f determined? Common ways usually set the decay factor to boundary values f1 and f2, as shown in Formula 18 and Formula 19. The value f1, which is known as the lower bound of decay factor, can be achieved by assuming 100% recall of algorithm. The higher bound f2 can be attained by assuming 100% precision of algorithm.
Because recall and precision cannot be 100% simultaneous, a balance of both two values should be considered when setting f. The first novel decay factor based on the average value of higher and lower bounds is proposed in this paper, which is called f _ average as shown in Formula 20. Because value 1 is much smaller than value
it (value 1) can be negligible. Therefore, Formula 20 can be simplified to Formula 21. Value f3 is the average of f _ recall and f _ precision, so the recall and precision of algorithm should be balanced in theory. Meanwhile, it avoids the randomness of setting the decay factor.
In order to further investigate the ways to set the decay factor, let us change Formula 1 to Formula 22. The function factor (f, x) is the decay function as shown in Formulas 22 and 23. Where parameter x = m - i, i is the time of T i arrived (i = 1, 2, …, n, …, m) and m is the time of current transaction T m arrived. Let set D represent the accumulation of factor (f, x), when T m arrived the values in D are shown in Expression 24.
The forms of above decay functions are similar to factor (f, x) = f x . The trends of decay function values with f _ recall, f _ precision and f _ average changing over time are shown in Table 4. The values of f _ recall are the highest and the values of f _ precision are the lowest, while values of f _ average are between them.
In order to add the weights of recent transactions and reduce the weights of historical transactions further, the second novel way to set the decay factor on the basis of Gaussian function
is proposed in this paper. It means setting decay function as
To make decay function meet the characteristic of f ∈ (0, 1], constant value A is added. When the new transaction T
m
arrived, the value of decay function should be 1, and decay function should associate with sliding window size N, so we set parameters the mean μ = 0 and the variance δ2 = B × N, B = 1, 2, 3… Then, decay function is as follows:
where A > 0, B = 1, 2, 3…, N > 0. This decay function satisfies the Definition 2. Therefore, the usage of this decay function is reasonable. In conclusion, the Gaussian decay factor is shown as f4 in Formula 25.
Decay factors f_recall, f_precision and f_gauss
The trends of decay function values with different decay factors changing over time are shown in Table 4. The values of f _ gauss are higher than f _ precision and lower than f _ recall in recent time. But in historical time the values of f _ gauss may be lower than both of them. It means that the degree of fade with f _ gauss in recent transactions is lower than the degree of fade with f _ precision. But the degree of fade with f _ gauss is higher than the degree of fade with f _ precision in historical transactions. Therefore, to set the decay factor to f _ gauss can improve the weights of new transactions and reduce the weights of old transactions.
The commonly used decay factors include: f _ d [3, 13], f_halflife [11], f_recall and f_precision [5]. This section shows the comparison between two novel decay factors we proposed and these four decayfactors.
At first, let us integrate the decay factor factor (f, x) and get a new formula as shown in Formula 26. Parameter x = m - i is the time distance between i and m, i is the time of T i arrived (i = 1, 2, …, n, …, m) and m is the time when current transaction T m arrives. There are six kinds of decay functions as shown in Formula 26. When f = f _ d, f _ halflife, f _ recall, f _ precision and f _ average, its form is like the power(f, x). And f = f _ gauss, its form is like the Gaussian function.
Values of D with different decay factors
Values of D with different decay factors
The values of these six kinds of decay factors with time changing are shown in Table 4 where parameters are: N = 10K, θ = 0.05, ɛ = 0.1 × θ, b = 2, h = 10000, B = 1, 2, and3. From this table it can be concluded that (1) when setting f = f _ recall and f = f _ d, there are tiny degree of fade of historical transactions with time changing as shown in Table 4. (2) When setting f = f _ halflife, there is a great degree of fade of historical transactions. (3) When setting f = f _ average, the degree of fade is between f = f _ recall and f = f _ precision. (4) When setting f = f _ gauss, the degree of fade of recent transactions is lower than f _ precision and f _ average. But the degree of fade of historical transactions is higher than these two. In other words, the feature of f _ gauss emphasizes the importance of recent transactions and reduces the importance of the historicaltransactions.
Two novel TDMs based on f_average and f_gauss are described as Expressions 27 and 28. The value of f _ average is affected by parameters sliding window size N, minimum support threshold θ, and maximal error rate ɛ. The value of f_gauss is affected by parameters sliding window size N and B. Compared with some existing decay factors, the value of f_average is between f_recall and f_precision in order to balance the high precision and the high recall of algorithm. The character of f_gauss is that it leads to the lower degree of fade on recent transactions and higher degree of fade on historical transactions than some existing decayfactors.
Figure 3 shows the process of generating frequent patterns based on the two novel TDMs we proposed. Each group data in Fig. 3 means < {CP} (SCP)>, where CP is the frequent itemset and SCP is the frequency of CP. There are five transactions, the first four transactions shown in Table 1 and another new transaction T5 = {1 3 4 7}. It is different from Example 1. Instead of updating the whole ClosedTable, it updates the itemsets associated with the new transaction. For instance, the itemset <{1 3 4} (1)> is generated after transaction T1 arrived and it only needs to be updated after transaction T5 arrived. The frequency of {1 3 4} is updated to (1 × f4 + 1) which uses the value f4 as weight. Compared with Example 1, this proposed algorithm can reduce the time complexity when mining frequent patterns on data stream.
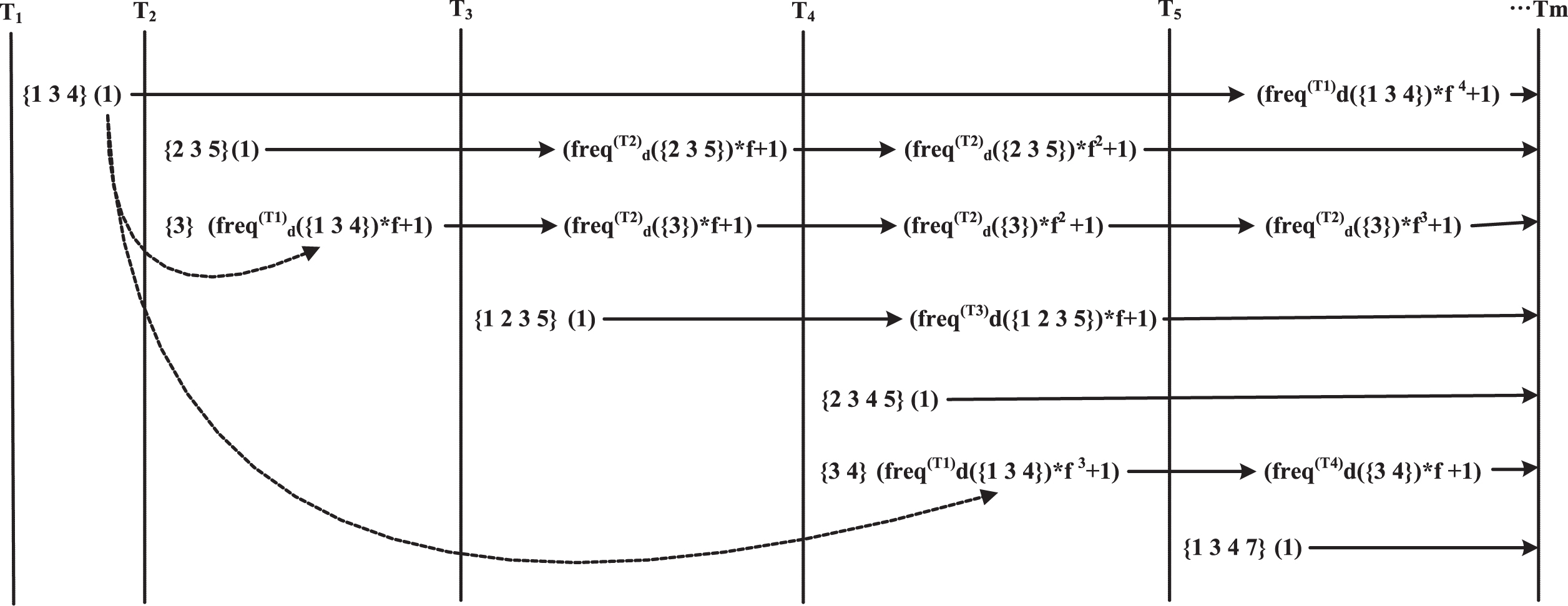
Frequent patterns mining by proposed algorithm TDMPDS.
The method we propose is called TDMPDS(TDM-based frequent Pattern mining over Data Streams). It includes adding new transactions into sliding window and dropping old transactions from sliding window. Algorithm TDMPDSADD(T m ) is used to process the new transaction T m , including in two main steps.
if o is a new frequent itemset then add it to ClosedTable.
else update the frequency of o.
Algorithm TDMPDSREMOVE() is used to drop historical transactions. In order to improve the work efficiency and reduce the work time, it processes old transactions in each P steps. That means if time m % P = 0, then call the function TDMPDSREMOVE(). Its main work is to drop the non-frequent itemsets from ClosedTable.
In order to compare the pros and cons of different methods to set the decay factors, real and synthetic data streams are used in this paper. The first one is high density data stream msnbc which has high frequency of pattern. It describes the page visits of users who visited msnbc.com on September 28, 1999 from UCI
. Visits are recorded at the level of URL category and are recorded orderly. There are 989,818 transactions and the average length of transactions is 5.7. It is a high density and highly similar data stream. The second one is Kosarak which is a low density data stream. The frequency of pattern in this data stream is low. This is a very large dataset containing 990,000 sequences of click-stream data from a Hungarian news portal. The dataset in its original format can be found at http://fimi.ua.ac.be/data/. The third one is Bmswebviewhttp://www.philippe-fournier-viger.com/spmf/index.php?link=datasets.php (http://archive.ics.uci.edu/ml)
Several methods to set the decay factors of the four algorithms are compared with each other in this paper. (1) Set f to f _ d with parameters b = 2 and h = 10000 as used in algorithm estDec [2], denoted as estDec|f _ d. (2) Set f to f_halflife with parameter t = 1 as used in algorithm UHS [11], denoted as UHS|f _ h. (3) Set f to lower bound as used in algorithm SWP [5], denoted as SWP|f _ r. (4) In order to balance recall and precision of algorithm, set f as f_average in the proposed algorithm TDMPDS, denoted as TDMPDS|f _ a. (5) To emphasize the importance of the recent transactions and reduce the weights of historical transactions, set f as Gaussian decay factor with mean μ = 0 and variance δ2 = B × N, denoted as TDMPDS|f_g.
Set minimum support θ = 0.06 and 0.001 for mining out the majority of frequent patterns. The former is used to discover frequent patterns on high density data stream and the latter is used on low density data stream. Let maximal support error ɛ = 0.1 × θ, and sliding window size N = 1000, 2000, 3000 and 4000.
Performance
The first experiment analyzes the parameter B of Gaussian decay factor. Figure 4 shows the performance of algorithm TDMPDS on high density data stream msnbc. The comparison among parameters B = 1, 2, 3 can achieve the best precision and the worst recall if B = 1, and the best recall and the worst precision are obtained by B = 3. The analysis of performances under different sliding window sizes shows that, if B = 3 the optimal performance of algorithm and the most balanced recall and precision are achieved as shown in Fig. 4(c). The performance is followed by setting B = 2, while the maximum gap between recall and precision of algorithm is obtained with setting B = 1. Dealing with the low density data stream Kosarak, it can also get similar conclusions.
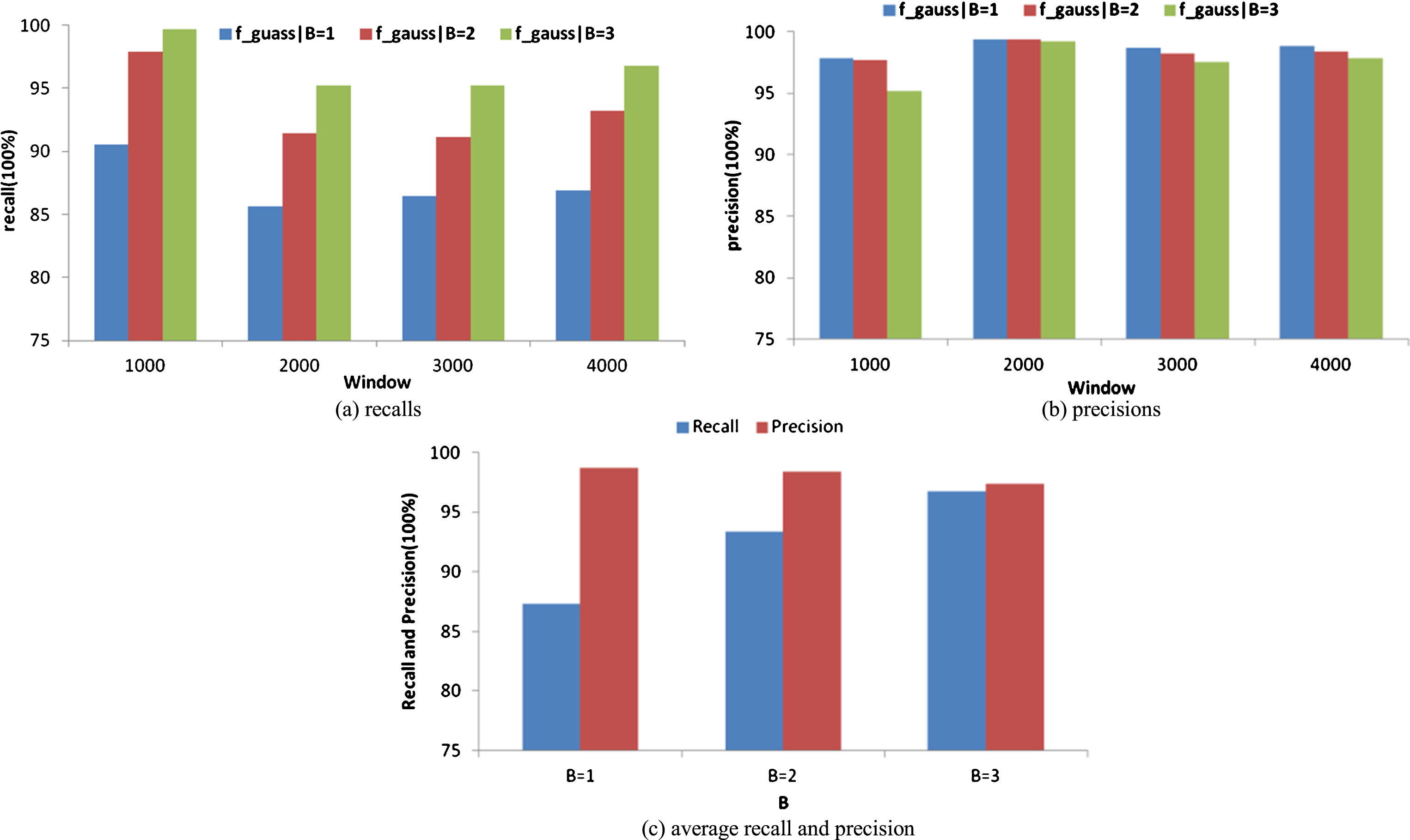
Variation of recall and precision with different Bs and windows on msnbc, (a) recalls (b) precisions (c) average recall and precision, (a) recalls with different windows (b) precisions with different windows.
Next, compare the pros and cons of different decay factors of the four algorithms over high density data stream msnbc. Let B = 3, the performances of algorithms are shown in Fig. 5. It can be concluded that: (1) performances of algorithm are less influenced by sliding window sizes for TDMPDS|f_a andTDMPDS|f_g. (2) It gets almost 100% recalls for SWP|f_r and estDec|f_d. However, the corresponding precisions are the lowest two. (3) The highest precision is obtained by USH|f_h. But the corresponding recall is the lowest. (4) The recall for TDMPDS|f_a is lower than recall for SWP|f_r, while the precision is higher than it. (5) Average value of recall and precision for TDMPDS|f_g is optimal compared with other ways.
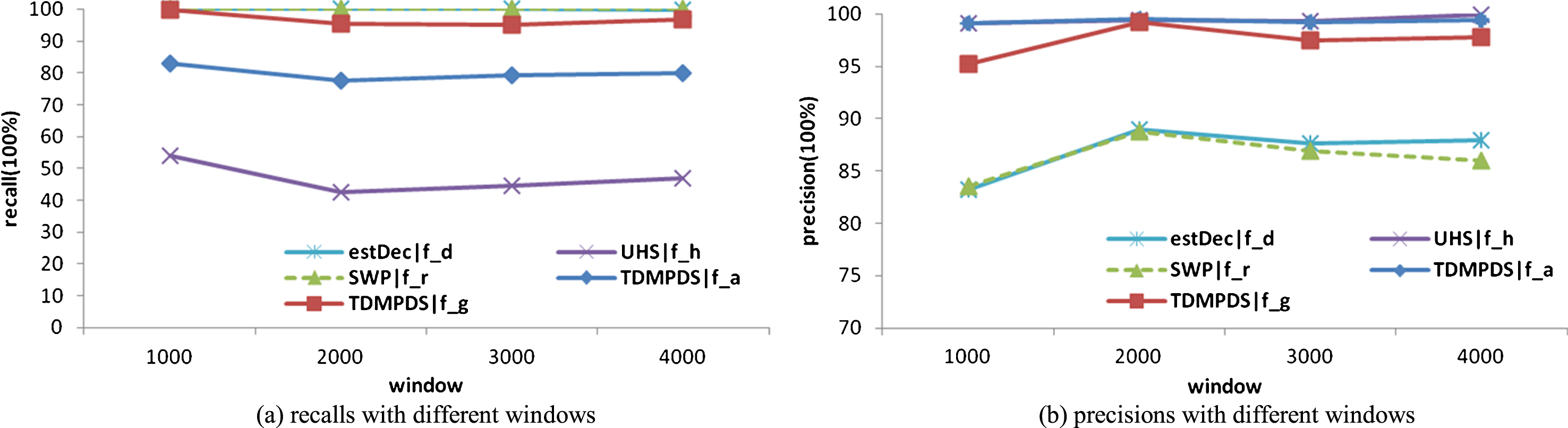
Performance comparison for different methods on msnbc, (a) Kosarak (b) Bmswebview.
To sum up, in Figs. 5 and 6, the performances of algorithms on msnbc ranging from being excellent to poor are: TDMPDS|f_g ⟶ estDec|f_d ⟶ SWP|f_r ⟶ TDMPDS|f_a ⟶ UHS|f_h. In detail, the performances for estDec|f_d and SWP|f_r are almost the same. The average of recall and precision for UHS|f_h is 21% lower than SWP|f_r, the performance for TDMPDS|f_a is about 3% lower than SWP|f_r, and the performance for TDMPDS|f_g is about 5% higher than SWP|f_r.
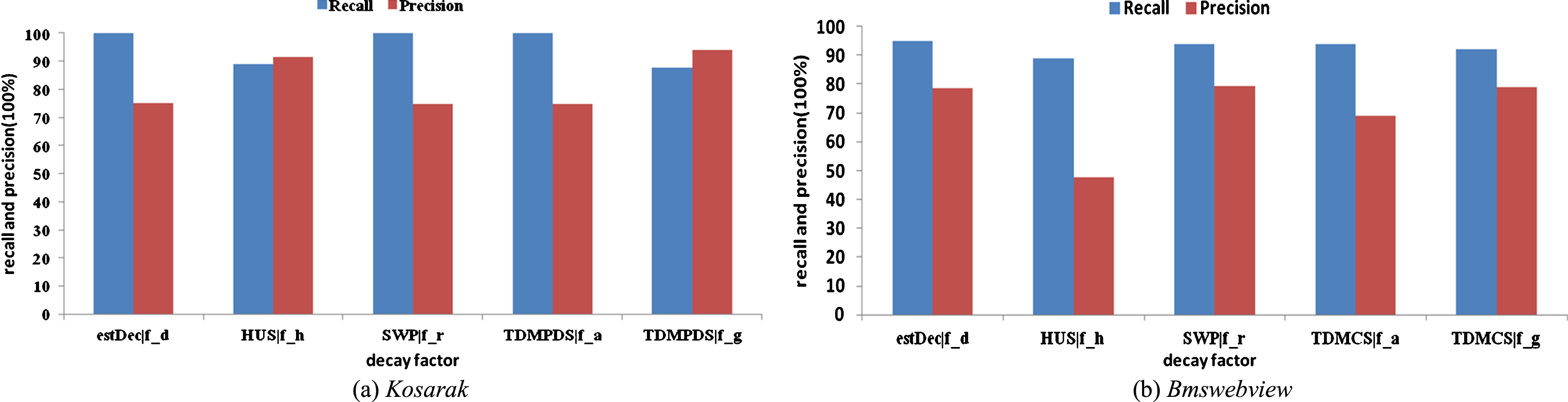
Comparison of average recall and precision for the different methods on Kosarak and B mswebview, (a) recalls with different windows (b) precisions with different windows.
The second experiment deals with low density data stream Kosarak and Bmswebview, the performances of algorithms are shown in Fig. 6. The performances of algorithms on Kosarak ranging from being excellent to poor are: TDMPDS|f_g ⟶ TDMPDS|f_a ⟶ UHS|f_h ⟶ estDec|f_d ⟶ SWP|f_r. In detail, the performances for estDec|f_d and SWP|f_recall are almost the same. The performances of algorithms on Bmswebview ranging from being excellent to poor are: SWP|f_r ⟶ TDMPDS|f_g ⟶ estDec|f_d ⟶ TDMPDS|f_a ⟶ UHS|f_h. In detail, the performances for TDMPDS|f _ g and SWP|f_r are almost the same.
The third experiment processes synthetic data streams, the performances of algorithms are shown in Fig. 7. Four data streams with different lengths of transactions or patterns are used, including: T10I4, T10I5, T10I10 and T20I5. Therefore, the performances of algorithms ranging from being excellent to poor are: TDMPDS|f_g ⟶ estDec|f_d ⟶ SWP|f_r. In detail, the performances of estDec|f_d and TDMPDS|f_a are almost the same, and the average values of recall and precision of UHS|f_h are lower than other algorithms.
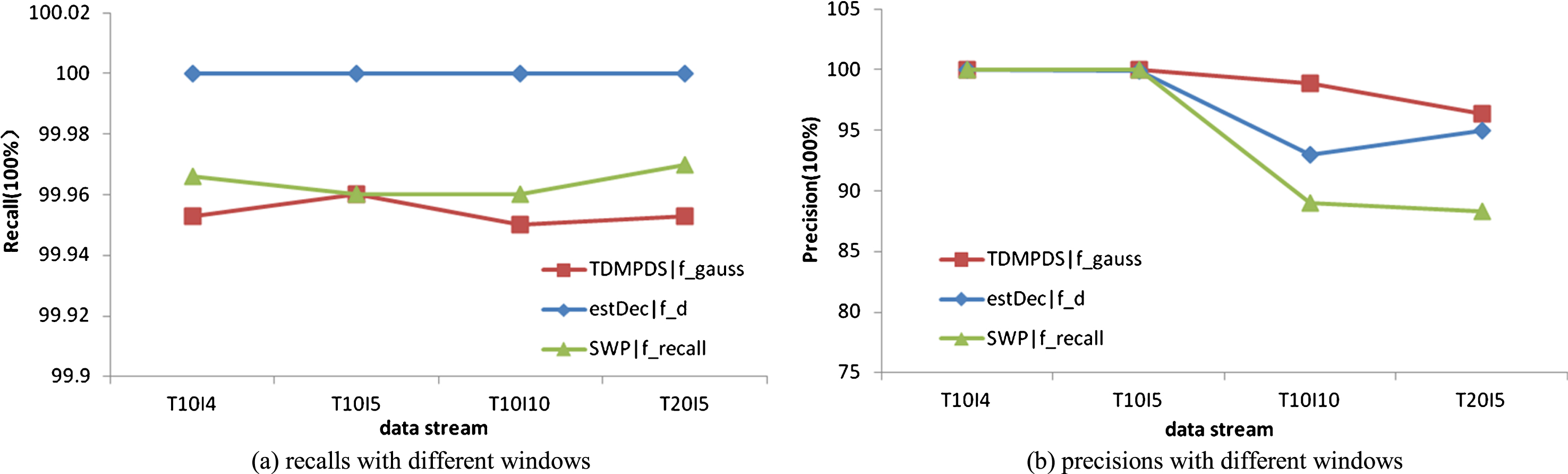
Performance comparison for the different methods on synthetic data streams.
From all the experiments above mentioned, we can draw the following conclusions: The changing of sliding window size has less influence on the performances of algorithms with f_a and f_g. The high recall can be achieved when f is set as f_r or f_d. But there are many possible non-frequent patterns in the result because of low precision. The high precision can be achieved when f is set as f_h. But some possible frequent patterns may be lost for the low corresponding recall. Compared with setting f to boundary value, the novel method which sets f = f _ a can get more balanced recall and precision. With Gaussian decay factor and setting parameters mean μ = 0 and variance δ2 = B × N, it obtains good performance of algorithms. Therefore, it is reasonable to set the decay factor in this novel way. Experimental results show that the usage of Gaussian decay factor can get optimal performance of algorithm in terms of both real and synthetic data streams compared with some classical methods.
The efficiency of time decay model depends on the ways to set the decay factor. Existing ways that set the decay factor to user-specified value, constant value independent of window size, or variable value with assuming 100% recall and 100% precision. This paper has summarized the existing methods and analyzed their disadvantages, then proposed two novel ways to set the decay factor. The first method is the average decay factor f _ agerage which can balance high recall and high precision of algorithm. The second method is the Gaussian decay factor f _ gauss which is based on Gaussian function, and detailed discussions on setting the parameters are also provided. The Gaussian decay factor further highlights the importance of the recent transactions and reduces the importance of historical transactions. Meanwhile, two kinds of TDMs based on f _ agerage and f _ gauss are proposed in this paper, and they are used to discover frequent patterns on real and synthetic data streams. The analysis of experimental results shows that the two decay factors we proposed are better than some existingmethods.
Footnotes
Acknowledgments
Project supported by National Nature Science Foundation of China (61563001) and Ningxia Natural Science Foundation (NZ17115).