
Abstract
This work presents a new model for the automatic synthesis of fuzzy classifiers, based on quantum-inspired evolutionary algorithms, which overcomes the difficulties inherent to the use of hybrid representations and the treatment of multiple objectives, both necessary for the synthesis of these types of systems. Without any a priori information about the classifier rules or any initial adjustment of individuals, the results obtained are comparable to those of other techniques that start from classifier populations previously adjusted to obtain good performance. According to the current trend, the aim was to build classifiers with good accuracy and simultaneous high interpretability of their fuzzy rule base.
Introduction
Evolutionary Fuzzy Systems (EFSs) are a successful hybridization between Fuzzy Systems and Evolutionary Algorithms [1]. Fuzzy Rule Based Systems (FRBSs) are an interesting tool for modelling real world systems, due to their humanly comprehensible representation of knowledge through inference rules. EFSs constitute a family of approaches that are built on top of FRBSs, whose components are improved by means of evolutionary learning and optimization.
The relevance of EFSs is demonstrated by the large amount of recent applications in several areas: Computing [2, 3], Remote sensing [4], Health [5–8], Financial [9–11], Industrial [12, 13], Chemical [14], Anthropology [15], Musical [16], Energy [17], Marketing [18], Ecology [19].
Interpretability constraints
Interpretability constraints
There is an extensive work on Multi-Objective EFSs (MOEFs) [25–28] that consider multiple goals in the optimization process, hence generating a set of non-dominated Fuzzy Systems that represent a trade-off between accuracy and interpretability.
One of the problems with the technique above is the progressive loss of accuracy when models become more complex. One of the reasons is that as partitions of input and output variables are based on a sense of linguistic meaning and are common to all rules, inaccuracies appear on the decision boundaries of the rules. In consequence, in the system’s pursue of exactness, the number of linguistic terms tends to increase. The excessive number of rules deemed necessary to make the system more accurate results in a loss of descriptive power.
Several evolutionary techniques have been applied to building EFSs, but none of them considers a new class, inspired by quantum computing principles, called quantum-inspired evolutionary algorithms (QIEAs) [29–32]. Since they support small population size and a very low number of generations [32, 33], these algorithms have achieved better performance in computationally intensive problems, such as the automatic synthesis of a complete FRBS.
QIEAs have been developed for different applications, providing better results than classical genetic algorithms with less computational effort: binary representation for combinatorial optimization problems [29]; real representation for numerical optimization problems [30, 32]; specific representation for ordering problems [33] and even hybrid representation (binary and real representation) applied to neuro-evolutionary models [31, 35].
QIEAs with binary representation have been applied to multi-objective problems [36–39]. A new model [40] that considers real representation and simultaneously deals with multi-objective problems mae use of the decomposition approach [41]. However, none of these models, with binary and real representations, focused on achieving a computationally efficient evolutionary algorithm for the synthesis of accurate and interpretable fuzzy inference systems.
The available representations (binary, real, ordering) are not fully adequate for representing discrete categories, which is important in the synthesis of a FRBS. Therefore, this work proposes a methodology for the automatic synthesis of fuzzy systems that addresses both accuracy and interpretability, is capable of dealing with categorical variables and makes use of a quantum-inspired evolutionary algorithm for computational efficiency. The resulting model is called QIEFC-MO – Quantum Inspired Evolutionary Multi-Objective Fuzzy Classifier with Real and Categorical representation.
This paper has four additional sections. The next one presents a brief overview of FRBSs synthesis and of Quantum-Inspired Evolutionary Algorithms. Section 3 describes in detail the proposed QIEFC-MO model. Section 4 presents the evaluation of the proposed model on different benchmark datasets and its comparison with other fuzzy-evolutionary models in the literature. Section 5 concludes the work.
Evolutionary fuzzy systems for classification
An FRBS consists of a knowledge base (KB), which includes the information in the form of IF-THEN fuzzy rules (the Rule Base – RB), and of the correspondence between fuzzy terms and values, known as Data Base (DB) [42]. It also comprises an inference engine module.
The performance of a fuzzy rule-based classifier depends on an appropriate partitioning of the input space [43]: if poor (few terms per variable), many patterns may be wrongly classified; if too refined (many terms per variable), many rules will not be generated due to the lack of training examples. To overcome this, several parallel classification systems have been adopted, each with a different level of partitioning. This results in efficient classifiers, but with an excessive number of rules. Therefore, [44] proposed a genetic selection of rules (see [45]), where a reasonably small and efficient subset of rules is selected from the original set. In [46], rules were generated by a genetic algorithm (unlike the previous method that started from a predefined set).
The use of a predefined database structured in a way that is humanly understandable may compromise the efficiency of the classifier by the rigidity of the decision limits established in the definition of the DB. Thus, [45] stresses the importance of the DB and RB learning process occurring simultaneously, even at a high computational cost.
A significant aspect of the FRBSs synthesis process, presented in [46], is the use of the Michigan architecture [43]. This is necessary because the larger the number of input variables, the greater the genetic representation of a rule and the representation of a complete RB (whose representation would hardly be supported by a single individual). However, as noted in [47], systems based on Michigan architecture tend to produce good rules but may not lead to a good quality classifier.
An extension to [46] proposed a predefined (and small) number of rules to represent the entire RB in a single individual (Pittsburgh architecture) [48]. The resulting smaller number of rules is beneficial in terms of interpretability. However, the representation of the entire RB in a single individual greatly increases the search space of the optimization problem. Therefore, in order to attain an EFS that learns simultaneously the DB and RB, a less computationally intensive evolutionary algorithm is fundamental.
QIEA as multimodel Estimation of Distribution Algorithms (EDA)
EDAs are stochastic optimization techniques that explore the space of potential solutions by constructing and sampling explicit probabilistic models, associated with promising solutions [49]. EDAs were successfully applied to solve problems of large search spaces and high complexity [50–56], and in most of those applications no other technique would outperform them.
EDAs typically work with a population of candidates for solving a problem, starting with individuals generated in accordance with a uniform distribution over the solution space (all possible solutions are equiprobable). The population is then evaluated on the basis of their performance and a subset of the best individuals is selected. The algorithm produces a probabilistic model that resembles a probability distribution, which statistically portrays the characteristics of the solutions, with predominance of the best one, within the space of solutions. New solutions are generated by sampling the distribution encoded in the model. These are incorporated into the population – in some cases completely replacing it. The process is repeated until a stopping criterion is reached.
QIEAs are evolutionary algorithms that use concepts of quantum computation [57]. In a QIEA, probabilities related to each possible state are used to describe the system’s behaviour. The quantum genes encapsulate the set of probabilities of occurrence of each of its possible states (usually the values 0 or 1). Logic operations that emulate quantum ports are performed by Q-gates. Examples of QIEA with a binary representation can be found in [29].
In an evolutionary process with quantum inspiration, a quantum gene (Q-bit in a binary representation) represents a set of probabilities related to the possible states of the classical gene; a quantum individual is a sequence of quantum genes and a quantum population is a set of quantum individuals. A classical individual is the result of the observation of a quantum individual and a classical population is a set of classical individuals.
Due to the probabilistic treatment, a QIEA can be considered as a type of EDA [57]. When adopting a quantum population with only one individual and performing multiple observations in each generation, a QIEA completely resembles an EDA [58].
Some variants of QIEA have been proposed [30] for numerical optimization problems. These are based on real-number representation and present some differences when compared to the original QIEA (based on binary representation). In that approach [30], a pair of values, consisting of the mean (ρ) and the width (σ) of a square pulse, was proposed to represent a gene, enabling the association with a uniform probability density function. In their evolutionary process, operators capable of modifying ρ and σ are used to reflect the predominance of a numerical value observed in good individuals of a classical population. In practice, it is an algorithm more like an EDA than the QIEA initially proposed (binary representation), but making use of multiple probabilistic models (the quantum individuals).
The evolutionary operators presented in [30] act on parameters of probability distributions (quantum individuals), rather than on parameters of classical individuals, which resembles the way the evolutionary process of the QIEA initially proposed [29] acts on Q-bits (which in some way denotes probability distributions).
The finding that QIEAs are multimodel EDAs is presented in [59], where the superiority of QIEAs over EDAs without dependency treatment is discussed. In addition, it is shown in [60] that the propagation of constructor blocks in simple genetic algorithms is less efficient than in QIEA.
QIEA and multi-objective treatment
According to [61], most of Multi-Objective EFSs (MOEFs) are in some way based on the NSGA-II [62] structure, which indicates that this technique can be considered as a reference. It is important to note that the ability of NSGA-II to generate sets with good Pareto front representativeness and good diversity in the solution space (through the manipulation of crowding distance) is a feature that goes against the basic mechanism of EDA (narrowing promising regions in the search space). While the former promotes the breadth of results (because it values the diversity of solutions), the latter concentrates them in regions of the objective space. However, for QIEAs, which are multimodel EDAs, this conflict does not occur, since QIEAs deal with several probabilistic models that are simultaneously refined. The existence of multiple models allows each of them to be oriented towards a small segment of the Pareto front, guaranteeing the diversity of solutions at the frontier promoted by the NSGA-II.
It is possible to combine the rapid convergence of evolutionary algorithms based on probabilistic models with the NSGA-II’s ability to generate sets of solutions near the Pareto border with good diversity. This work proposes combining QIEA with some functionalities of NSGA-II. The merge of the NSGA-II with the QIEA with binary representation has been considered in [36], but has not been applied to cases with real number representation.
In this work, the NSGA-II composition (for multi-objective treatment) is implemented with a QIEA-R, based mostly on [30], and with a proposed extension to also incorporate categorical representation.
Automatic synthesis of the evolutionary fuzzy classifier
This section presents the proposed Evolutionary Fuzzy Classifier model based on QIEFC-MO. This is an extension of the QIEA-R presented in [30] for multi-objective optimization, with the additional capability of representing categorical variables, which is fundamental for the optimization of the fuzzy DB.
The proposed model follows the Pittsburgh approach, as in [48], where the computation cost is reduced by the use of a quantum-inspired evolutionary algorithm. In order to consider accuracy as well as interpretability in the evolutionary process of the fuzzy inference system, the proposed quantum-inspired evolutionary algorithm incorporates the NSGA-II approach to deal with a multi-objective optimization. Figure 1 presents an overview of QIEFC-MO, considering a single quantum individual (in practice, this operation occurs for multiple quantum individuals, as a multimodel approach).
Overview of the QIEFC-MO.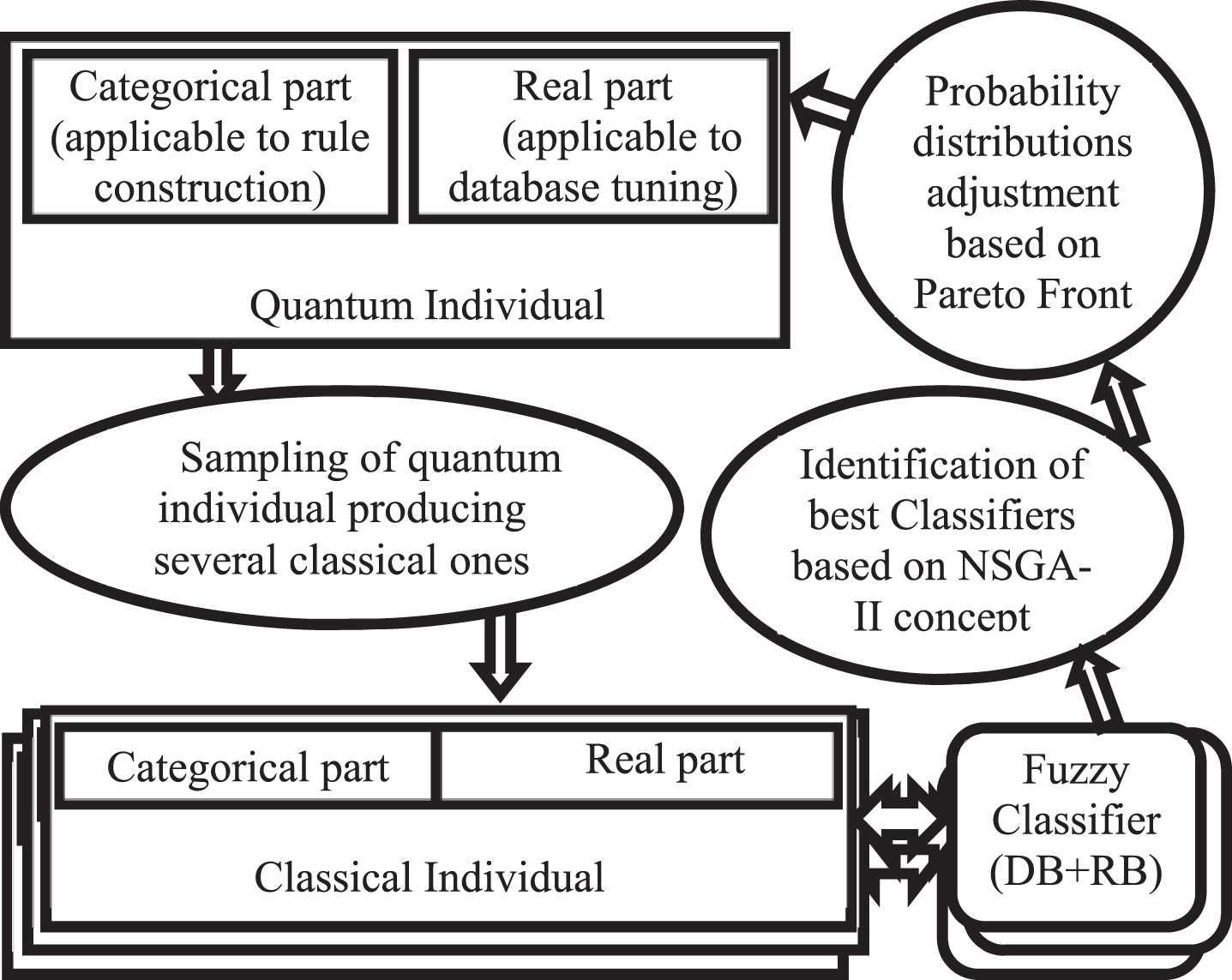
The proposed model is based on the QIEA-R combined with the multi-objective facet of NSGA-II. The following considerations apply:
It is necessary to produce several classical individuals to have enough elements composing a good representation of the Pareto front. If only a few quantum individuals are used, few diversified classical individuals will be produced, since each quantum individual tends to narrow in a promising region of the search space, converging to a point. Each quantum individual in a generation produces (through a sampling process) more than one classical individual and only the classical individuals generated by that quantum individual are used for their quantum update. Only good quality individuals are used for updating quantum individuals – those that are on the Pareto front until then obtained (according to the NSGA-II mechanisms of identification of representatives of the Pareto front). If a quantum individual does not generate at least one individual at the Pareto front, it is not updated; therefore a non-narrow pulse remains throughout the evolutionary process until it produces an element at the Pareto front. A quantum individual may already have generated a classical individual who was part of the Pareto front (having thus been narrowed), but other quantum individuals may have generated better classical individuals in subsequent generations, so that the first quantum individual is no longer the generator of a classical individual belonging to the Pareto front. This quantum individual is again expanded, thus guaranteeing good exploratory capacity. The heuristic to update quantum individuals is based on classical good quality individuals for the multiple objectives (identified by the use of NSGA-II), which represents a significant difference in relation to the heuristic proposed in [30]. Those good quality individuals are used to update the position of the square pulses in the same way as in [30] but with an exponential narrowing of the pulses.
Extension of the QIEA-R multiobjective for automatic synthesis of fuzzy classifiers
The FRBS construction technique considered here is based on multiple partitioning [48]. Classifiers thus obtained have few efficient rules with few antecedents. As mentioned before, the approach of learning the KB as a whole, with a high level of DB and RB comprehensibility, represents an optimization problem in an extensive search space. The model presented in Section 3.1 has been extended to include categorical representation, in addition to the standard real representation of the QIEA-R.
As shown in Fig. 2, building the fuzzy classifier consists of two basic steps: Formulation, which generates fuzzy rules premises, and Association, which assigns the best suited consequent to each premise. The first stage combines antecedents (which demands an optimization process dealing with discrete or categorical representation) that produces rules with a predefined DB that is submitted to a tuning process (optimization process dealing with real-number representation). Then, the second stage associates one of the M available classes to each premise.
Production of a classifier from an individual – two simultaneous evolutionary processes presented in dashed lines: lateral tuning of DB and antecedent combination for each rule of the RB.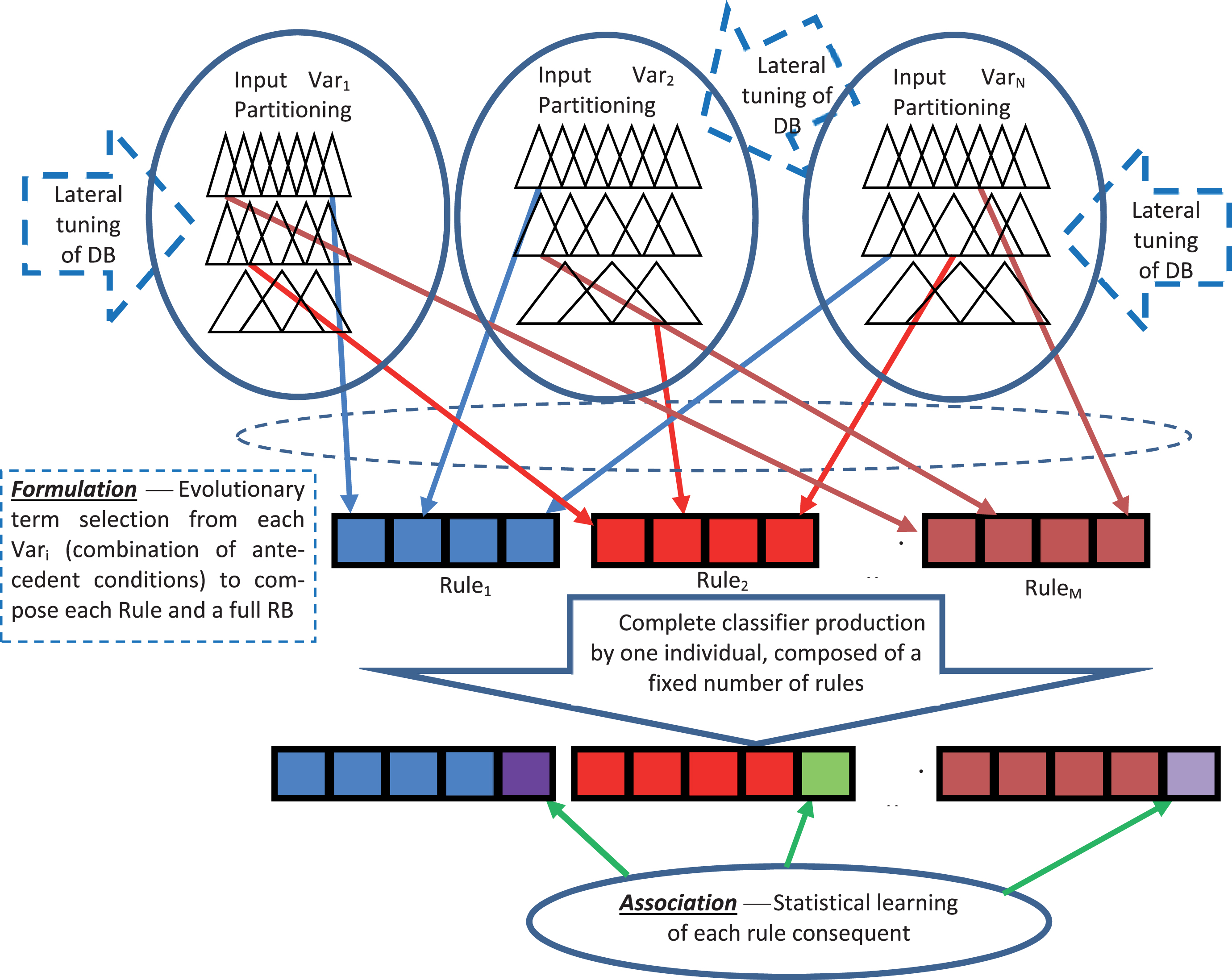
A relevant aspect in the FRBSs synthesis is the affinity between candidate sets to compose the rule antecedents. Consider that a given input attribute is partitioned into three (”low”, “medium” and “high”), five (”very low”, “low”, “medium”, “high”, “very-high”), and seven symmetric sets (”very-low”, “low”, “medium-low”, “medium”, “medium-high”, “high” and “very-high”), as shown in Fig. 3.
Three regions of interest for an input variable, partitioned in 3, 5 and 7 triangular fuzzy sets symmetrically disposed.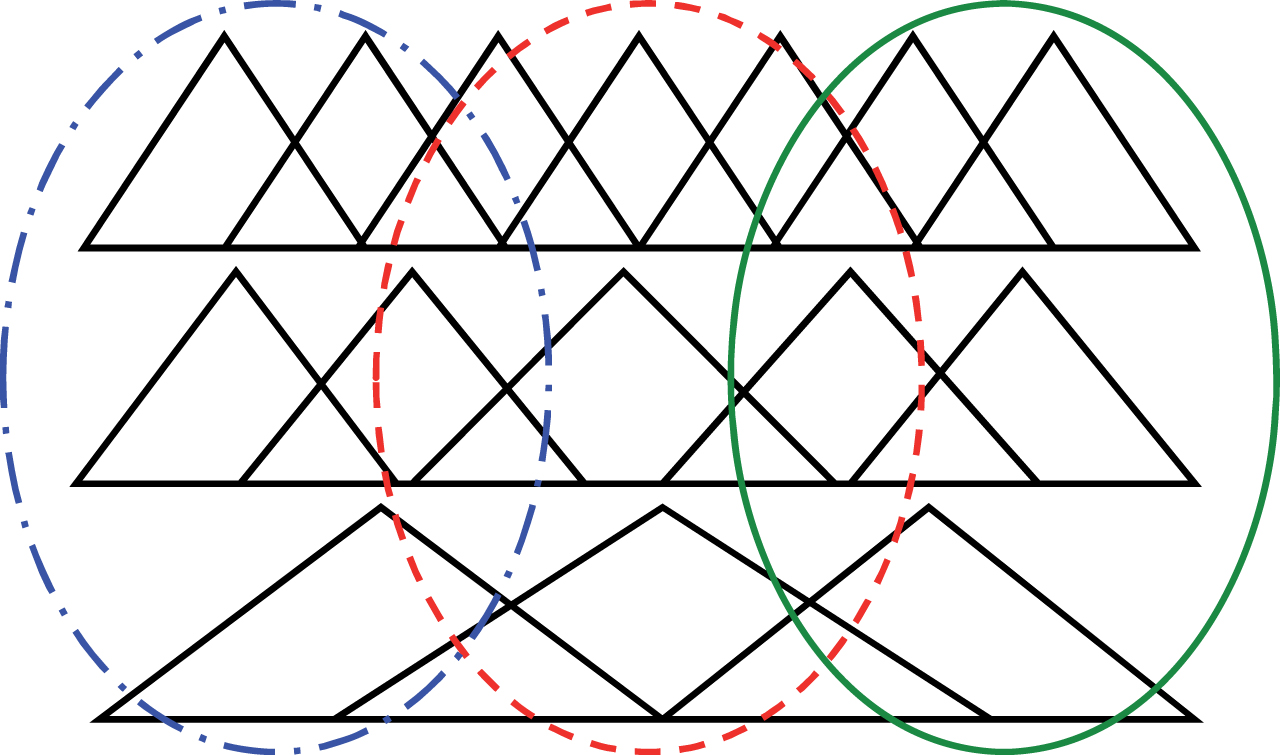
If a rule performs well and is related to the “very-low” value for the seven sets partitioning of an input variable, then it is likely to perform well if “low” for the three sets partitioning or “very-low” or “low” for the five sets partitioning are considered for the same input variable. Thus, in the synthesis of a classification FRBSs, the information of the most appropriate regions of interest is valuable for composing rules antecedents.
A region of interest, as shown in Fig. 3, is understood as the one that is composed, for example, of the “low” set in the three sets partitioning, of “very-low” and “low” in the five sets partitioning and of “very-low”, “low” and “medium-low” in the seven sets partitioning.
Considering that a given input attribute is partitioned into 3, 5 and 7 symmetric sets, each set/term can be considered conceptually understandable when used in the rules antecedents. The proposed method uses this affinity, which characterizes regions of interest or promising ones, in the optimization process.
Taking advantage of promising regions is the essence of QIEA, whose idea has been expanded in this work to formulate an QIEA for optimization with combinations of categorical attributes (fuzzy antecedent sets) that hold some affinity with each other.
In summary, the method makes use of more than one partitioning simultaneously in the DB (adequately predefined for good interpretability and with different granularities for good precision) and of an algorithm that produces combinations of antecedents, among those pre-established in the previous step. Rule generation favours those rules that cover promising hyper volumes of input variables, as well as those with few antecedents (use of Don’tCare), as detailed in the next section.
The proposed algorithm can select any categorical elements of the DB pre-defined set “low” (3), “medium” (3), “high” (3); “very-low” (5), “low” (5), “medium” (5), “high” (5), “very-high” (5); “very-low” (7), “low” (7), “medium-low” (7), “medium” (7), “medium-high” (7),”high” (7),”very-high” (7), Don’tCare, where the number in parentheses corresponds to the partitioning to which the term belongs.
The selection of an antecedent among the possible ones available in the DB occurs by observing quantum genes. All the possible elements have initial probabilities of occurrence of (1-p)/15; Don’tCare is favoured with a significant probability (p), in the expectation that it occurs in a higher number of times to make the final system more compact. Thus, the structure behind a quantum gene in the categorical representation is formed by: (i) a set of observable elements; (ii) probabilities of occurrence of each of the observable elements; (iii) a counter of occurrences of the elements in classifiers of good quality.
In an individual encapsulating a complete classifier, the number of genes is that necessary to form all antecedents of all rules of the classifier. For an FRBS with N input variables and M rules, there will be M x N categorical quantum genes in an individual. A quantum gene qi,j represents a pointer to a data structure that stores a probability distribution associated with the set that will define the antecedent j of rule i. Initially, each quantum gene is configured to encompass with high probability all antecedent possibilities (its promising region is maximal and has no sub-region predominance) or Don’tCare.
A “good quality classifiers occurrence counter” for each of the observable element is used in the evolutionary process, leading to the narrowing of the region of interest for each gene. As quantum individuals are observed (which results in classical individuals who translate into classifiers, and that may be of good or poor quality), the antecedent information that compose the rules of the good classifiers is stored. After a few generations, it should be possible to identify the predominance of certain antecedents in the rules of classifiers of good quality, indicating the existence of promising regions.
Initially, the promising region considered in each quantum gene is the entire universe of discourse (UoD) for each antecedent. After some time, it is possible to restrict this region, according to the heuristic suggested in the tree of Fig. 4.
Convergence of promising regions.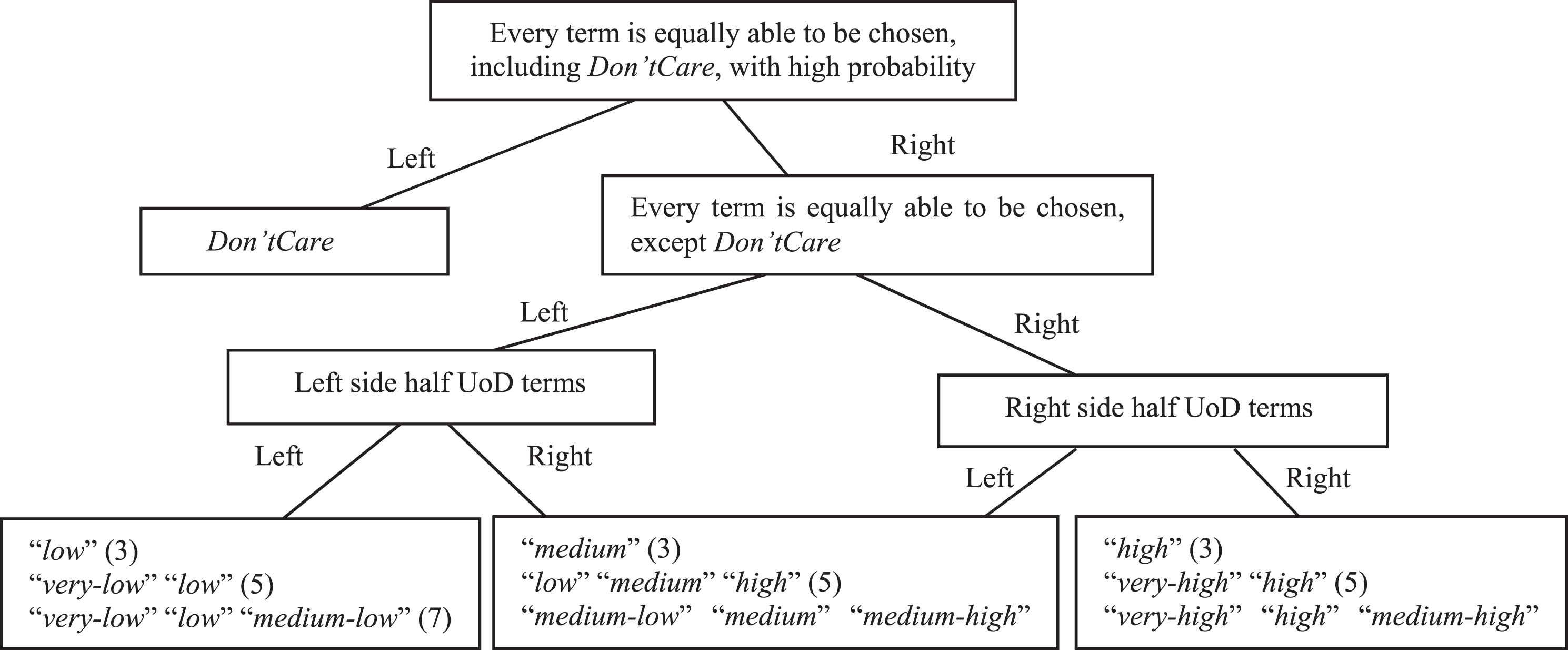
This is associated with each quantum gene (i.e. a rule antecedent). The “Left” and “Right” decisions correspond to “There is a significant number of good classifiers that have, in a specific antecedent of a specific rule, terms of the sub-region on the left/right”.
If after some generations the good quality classifiers present a large number of occurrences of Don’tCare in a specific antecedent of a specific rule, it is highly probable that the region of suitable interest for that antecedent corresponds to the Don’tCare side of the tree.
Similarly, if after some generations, for a specific rule, a specific antecedent presents a different element from Don’tCare in good quality classifiers, it is probable that the region of interest for that antecedent is the one composed of all possible elements except Don’tCare.
The antecedents that occur most in classifiers of good quality are periodically evaluated (through the Counter available to each quantum gene) and a decision is taken on which is the most appropriate sub- region of interest, with a gradual narrowing of the regions of interest (by reducing the number of categorical elements composing it).
At the algorithm’s initialization, each quantum gene points to the root of the tree that maps the convergence of promising regions. When observed, it can produce a Don’tCare or any other term. From the observation of quantum individuals, classical individuals are produced, corresponding to the combinations of antecedents of the input variables that will become the classifier’s rules premises. For each premise, a statistical learning process is carried out to specify the rule’s consequent, exactly as proposed in [48] (see Section 3.4). The performance of a classical individual (that is, of the corresponding classifier) indicates which promising sub-regions have occurred in the good quality classifiers. For example, if a good classifier has a “very high” (5) term for a specific antecedent for a specific rule, the “very high” (5) corresponding to that quantum gene is incremented.
After a few generations, the promising sub-region that was most ranked is identified and each quantum gene will point to it. That is, a transition to the appropriate lower level of the tree containing the convergence progression of promising regions is made. This transition occurs systematically; the lower level always corresponds to a significantly smaller subset of the original set of terms.
As with the multiobjective QIEA-R, individuals belonging to the Pareto front are used to update the quantum individuals; those quantum individuals that did not produce classical individuals that belong to the Pareto front are directed to the root of the tree of Fig. 4 (to ensure exploratory ability).
The multiobjective evaluation of each classical individual considers the classification error rate and the level of interpretability – regarding each rule (by the minimization of antecedent conditions in each rule or the massive use of Don’tCare) and the number of active rules (those with at least one antecedent other than Don’tCare).
In addition to the categorical representation of quantum genes for RB learning purposes, each quantum individual contains some real number quantum genes, for DB tuning purposes. This fine tuning intends to not drastically modify the symmetric partitioning of each input variable and to preserve the structure of the promising regions heuristic.
A total of 3 × N real representation quantum genes (where N is the number of input variables that will be submitted to tuning, each one comprised of 3, 5 and 7 terms) was appended to the quantum individual. For each partitioning of each variable, a small offset is applied – the tuning of DB operation. These genes are used for producing a value in the range [–0.5, 0.5], which is multiplied by a small fraction of the variable’s universe of discourse size, producing the lateral offset. The final quantum individual representation is shown in Fig. 5.
Final quantum individual composition.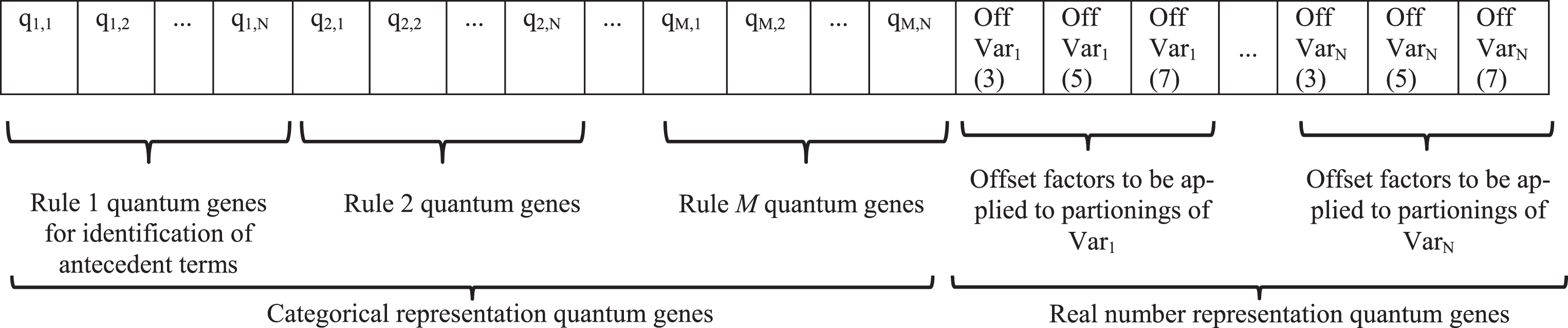
Each rule in a classifier is formed by the combination of antecedents, to which a class and a degree of certainty of the rule are associated. This is performed as in [48, 63], for comparison purpose. This step is described below.
The construction of a classifier considers that there are m training patterns x p = (xp1, xp2, . . . x pn ), where x pi is one of n attributes of an instance (training pattern), which belongs to one of M classes.
A rule has the format:
RULE R q : IF x1 IS A q 1 AND... x n IS A qn THEN Class = C q |CF q ,
where x = (x1, . . . x n ) is an instance of the set of available examples, with n attributes, and A qi is one of the linguistic terms defined for the universe of discourse of attribute i. A rule has a degree of certainty associated with it, called CF. The degree of compatibility of each training pattern x p with the antecedents of the rule R q (which are A q = (A q 1 , . . . A qn )) is defined as μAq (x p ) = μ Aq 1 (x p 1 ) . μ Aq 2 (x p 2 ) . . . μ Aqn (x pn ), where μ Aqi is the membership function of A qi .
In order to determine the class C
q
(consequent) and the degree of confidence CF
q
of rule R
q
, the degree of confidence c of the rule “A
q
→ Class h” is calculated, for each of the M classes, as:
The class used as the consequent of the rule is the one that results in a higher degree of confidence for that rule:
The degree of confidence of the rule is then:
Finally, when a classifier is assembled, it is evaluated on the basis of its classification efficiency, which is obtained by submitting instances to the classifier. When an input pattern is submitted to the classifier, a single rule is chosen by considering the following criteria:
Thus, the classification process is given by assigning the class of the winning rule (w) among all the rules of the classifier.
Experimental results
The data from [48] and [63] were used to evaluate the performance of the proposed QIEFC-MO model. In fact, both works employ the same form of evaluation of MOEFS for classification, which was proposed in [48] and used in [63] to compare results.
Data sets used in the experiments ([65])
Data sets used in the experiments ([65])
*Patterns without values for some attribute have not been considered.
It should be noted that [64] produced classifiers with the use of C4.5 (they were not linguistic FRBSs for classification), [65] produced FRBSs for classification based on rules initially formed by statistical learning of the combination of antecedents, and [63] produced linguistic FRBSs for classification but starting from a classifier built with the use of C4.5. That is, all methods employed some form of initialization that strongly directed the construction of the classifier to a very high performance and only then submitted it to the evolutionary process.
The model proposed in this paper, on the other hand, does not consider any previous conformation leading to high performance. This premise was adopted precisely to subject the QIEFC-MO model to the highest effort of learning the DB and RB simultaneously, which is an extremely complex task.
For the construction of rules of the initial population through statistical learning, it was possible to introduce a probabilistic prioritization scheme for the use of Don’tCare, in which p(Don’tCare) is set to 0.95 for the Sonar database and to 0.8 for the other data sets. Similarly to the approach taken in [48] and [63], a population of 200 individuals and 5,000 generations (making a total of 1000000 evaluations per execution) was adopted – 100 executions for training and 100 for testing, for each set of examples, as a result of using 10 × 10-fold cross validation.
The main results related to those tests are presented in Table 2. It is important to consider that [48] used six different approaches for the treatment of multiple objectives. In the first three, an algorithm based on the NSGA-II (MOP-1, 2 and 3) dealt with more than one objective; in the last three algorithms, it dealt with only one objective and the evaluation of the different objectives was performed by using previously established weights.
Best average error rates for test set
In the other works, the application of evolutionary algorithms may be considered an adjustment of existing classifiers. This was not the case of the QIEFC-MO model, which was applied in the simultaneous learning of the FRBS’s DB and RB. Therefore QIEFC-MO proved to be an interesting option, providing the best result for two datasets, even without any a priori information.
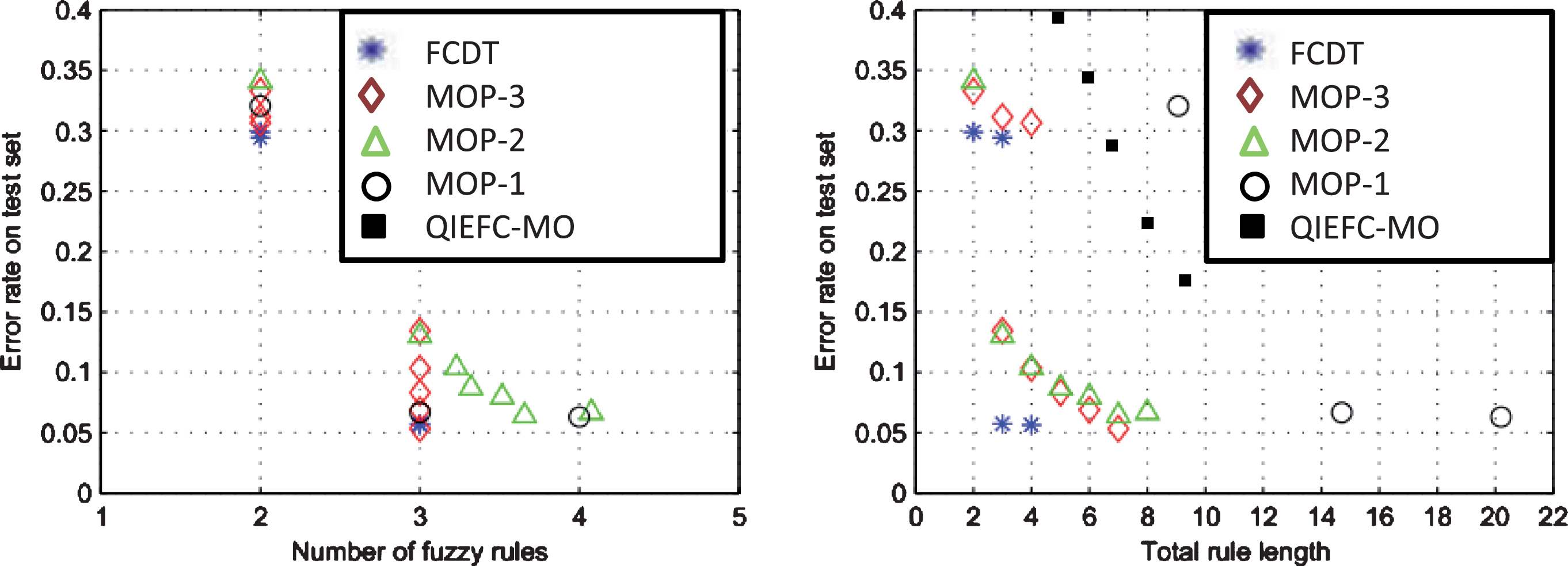
From the experiments with the six datastes, the results for Pima and Wine have been selected (Figs. 6 and 7) to show that QIEFC-MO performs very closely to the other classifiers even without any initial configuration. Figures on the left hand side show the error rate averages for classifiers with the same number of rules, provided that this number of rules has figured in more than 50% of the 10 × 10-fold cross validation runs. On the right hand side, the mean error rates are shown for classifiers with the same total of antecedents, provided that this number has figured in more than 50% of the 10 × 10-fold cross validation runs. This form of presentation was originally proposed in [48].
Average error rates in test sets, Pima dataset. Average error rates in test sets, Wine dataset.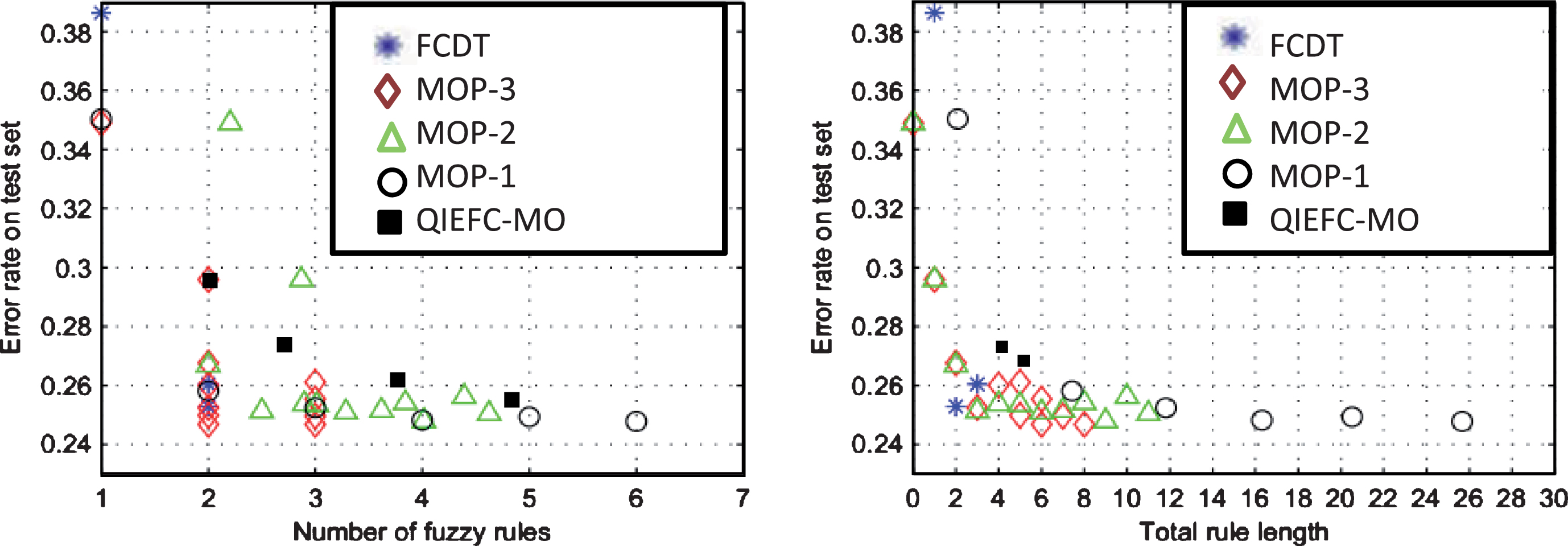
This work presented a new model to deal with multiobjective optimization problems, comprising a hybrid representation (real number and categorical elements), applicable in complex search saces, such as the synthesis of linguistic FRBSs for classification.
Results were very satisfactory, in that FRBS classifiers were synthesized without any initial conformation of individuals and produced similar classifiers to the ones synthesized by other techniques that start with a configuration of individuals directed to good performance for training sets. In test sets, the FRBS classifiers have produced models with good generalization.
An important contribution was the demonstration of the feasibility of mixing evolutionary algorithms based on probabilistic models with functionalities aimed at the treatment of multiple objectives (that operate by promoting the diversity of solutions) – seemingly contradictory concepts. In fact, the adoption of multiple probabilistic models (such as QIEA, not EDA) allows the convergence of more than one promising region in the search process.
The greatest challenge of this work was the accommodation of numerical and categorical representations in QIEA (typically employed in problems that require binary or numerical representations). This shows that categorical variables can be well manipulated with QIEA provided that a heuristic appropriate to the problem is incorporated into the optimization process.
Further investigations may include the use of more complex probabilistic models and incorporate dependency learning in the QIEFC-MO model.
Footnotes
Acknowledgments
The authors thank the Brazilian Agencies CNPq and FAPERJ for their financial support to develop this work.