
Abstract
Nowadays, the exponentially increasing amount of digital images available imposes a great challenge to a content-based image retrieval (CBIR) system due to the requirement of extensive-computing. Considering this challenge, this paper presents an approach to achieve effectiveness and scalability of a CBIR system in a large-scale dataset. To do that, we propose a cache mechanism to spare the distance computation efforts of a retrieval task in the CBIR system. Additionally, a MapReduce technique is presented to exploit the cached data in a parallel facility, thereby not only improving the performance of a CBIR system but also ensuring scalability for the system. Additionally, a collaborative caching service has been introduced for enhancing the data availability, thus decreasing the network traffic load due to fetching data remotely in the distributed environment. Moreover, by clustering the dataset before a search, this system can be efficient at responding to a user query since only a portion of the dataset is actually operated at a time. Through experiments, our approach obtains significant efficiency gains compared to other methods in terms of response time and achieves an acceptable accuracy ratio, which is applicable in the practical environment.
Introduction
The widespread presence of digital cameras and the emerging trends of sharing multimedia data on social networks triggered an exponential increase of online image data. An exhaustive search is infeasible for these large-scale datasets due to its extensive time requirement. To address this obstacle, it is necessary to develop tools for efficiently indexing and retrieving these data. Generally, traditional approaches retrieved images based on image metadata and keywords might be unfeasible due to either the ambiguity in the image or semantics of words in the context surrounding an image. In this scenario, content-based image retrieval (CBIR) systems [1, 2] have been developed by researchers over the past decades as an alternative to overcome those limitations by considering the content of images for supporting retrieved images.
Basically, CBIR adopts an image as a query and retrieves images according to the match between two images. The critical points of similarity estimation depend on three important issues: 1) an effective feature description (the content of an image), 2) a proper indexing scheme, and 3) an appropriate distance metric. For image representation, researchers have spent many years attempting to identify and design effective feature descriptors for CBIR [3, 4], including global features [5] and local features (e.g., scale-invariant feature transform [6] and bag-of-visual-words representations [7]). In early CBIR, images were popularly represented by a single holistic feature, such as color correlogram [8], shape [9], etc. Later, with the introduction of the SIFT [10] and SURF feature [6], local visual features have been widely explored for CBIR. This feature demonstrates the excellent property of invariance to rotation and resizing transformations, and robustness to illumination changes. Generally, thousands of local features can be extracted from a single image. Meanwhile, the evaluation database has been increased to be on the scale of millions [11]. To address large-scale visual data, it becomes crucial to design an efficient indexing scheme.
Inspired by the success of information retrieval, the unsupervised index scheme is leveraged by grouping the similar image descriptor vectors into clusters. With local features quantized to a fixed-size vector, the training images are efficiently indexed by comparison with similar images using the Euclidean distance. Through the index structure, it is efficient to identify these target images sharing common representations with the query image and compute their similarity scores for ranking [12]. Note that unlike hashing techniques [13], the unsupervised index scheme still works well in high dimensional features, and therefore can still guarantee an acceptable ratio on the retrieval accuracy. With the above advantages, the unsupervised index structure has been exploited in many image retrieval systems [14, 18].
With the aid of the indexing scheme, CBIR can avoid an exhaustive search over the whole database. However, the CBIR performance still degrades because of the exponentially increasing multimedia content. Recent research studies another approach, which leverages the power of the distributed processing big data framework Hadoop to enhance CBIR performance [16–18]. The master-slave architecture controls the query requests from users in a parallel manner. A master node receives a query request, then based on data organization information, it divides a big task into sub-tasks and delivers them to slave nodes, where the required data to process the sub-tasks are located. The philosophy of pushing analysis code close to the data it is intended to analyze, rather than requiring code to read data across a network, has made Hadoop popular in the big data processing field. Hence, for a CBIR system integrated with Hadoop, each slave node will maintain its local index scheme for its local data [18]. The disadvantage of previous studies is that when a slave node is overloaded, the task is performed in another slave node, which requires remote access of the data from this node to the overloaded node. This degrades the performance of the CBIR system due to the I/O bottleneck access over the network. To overcome this issue, we propose a collaborative distance-based cache to alleviate the I/O access cost. Here, every slave node maintains a local distance-based cache when using an index scheme. Additionally, a global distance-based cache is maintained to collaborate the local caches, aiming at reducing the I/O cost during remote access.
For the above observations, we propose an efficient framework for retrieving similar images
in the distributed environment, summarized as follows: We employ a fast and robust feature extraction technique, namely SURF (speeded-up
robust features), which extracted features based on the appearance of the object at
particular points of interests and are invariant to image scale and rotation, then
represented image descriptors for every point of interest identified previously. The
goal is to provide a unique and robust description of an image feature, enabling image
search for different image features. We introduce an index structure based on the unsupervised clustering algorithm
VP-Tree to improve the performance in processing a similarity query. This technique
aims to accelerate data retrieval by grouping relevant objects based on distance
criteria. Moreover, this approach narrows the search space, avoiding the computation
of distances among all images of a given dataset. We propose an in-memory distance-based cache for a CBIR system. This proposed method
significantly increases the performance in terms of memory access rate while
calculating a distance between pairs of images. It also avoids duplicate calculations
during the search for similar images. In addition, a global collaborative cache
service is implemented to enhance the data availability, thus avoiding the remote
access data pattern, which causes performance degradation of a distributed
application. The three above techniques are intertwined inside a MapReduce framework for
accomplishing the similarity query process.
The remainder of this paper is organized as follows. Section 2 provides related studies relevant to the topic. In Section 3 Methodology, our methodology is discussed in detail. Section 4 presents an architectural overview of the proposed approach while the performance evaluation is discussed in Section 4. Conclusions and future work are summarized in Section 6.
Related work
A large percentage of the increase in data management requirements consists of media data such as images and videos. For instance, there are 250 billion images stored in a Facebook datacenter, while YouTube claims that more than 300 hours of video content are uploaded by users every minute. Therefore, the scalability of a CBIR system has been significantly studied in previous work [11, 19].
Some studies have focused on a centralized approach in CBIR systems. Jégou et al. [20] proposed an indexing scheme based on the concept of product quantization combined with an inverted file system for nearest neighbors search. They evaluated the performance by indexing two billion feature vectors. Lejsek et al. [21] introduced a version of the NV-tree for the nearest neighbors search that indexes 2.5 billion local feature vectors. While in [22], the authors describe results using the NV-tree to index a collection of 28.5 billion local features. In 2015, the authors in [23] employed the inverted multi-index to study the performance of the BIGANN dataset, containing one billion features. In contrast to these approaches, our indexing scheme is designed for parallel processing. Furthermore, N.Kumar et al. [24] evaluated VP-Tree performance in terms of the construction cost and search speed. Compared with other index methods, they claim that VP-Tree achieves better performance. It motivates us to employ VP-Tree as an index scheme in our work.
The earliest study of designing distributed indexing is presented in [25]. The authors report results on indexing approximately 1.5 billion feature vectors using 2,000 workstations. More recently, in [26], the authors utilize a multi-probe Kmedoids-LSH method, indexing two billion feature vectors to support a sketch-based retrieval system, but using only 10 servers. The first study of implementing the system of image retrieval on Hadoop is investigated by Zhang et al. [27]. Since then, variants of similar systems have been proposed, but most experiment on relatively small collections (e.g., see [17, 28–30]). One study used the largest collection of these, called ImageTerrier [31], indexing 10.9 million images using bag-of-words features from approximately 10 billion SIFT feature vectors. Some studies done on medical image retrieval domains were also inspired by such Hadoop frameworks, again with relatively small collections (i.e., [29, 32]). Moise et al. [18] built a CBIR system on top of an extended cluster-pruning (eCP) algorithm and introduced an index search scheme for large batches of queries. The experiments on a dataset contain approximately 100 million images extracted approximately 30 billion SIFT feature vectors using a cluster of more than 100 machines. Additionally, with recent explosive research on deep neuron networks, there are some studies that have demonstrated the outstanding performance in various vision fields. A recent work investigating collaborative index embedding combined with a convolutional neuron network (CNN) is presented in [33]. While the authors in [34] combined Support Vector Machine (SVM) and CNN to enhance for enhancing image retrieval process, a study in [35] employed deep belief network (DBN) method to extract the image features and improve similar measurements. However, it is beyond the scope of our work.
Many recent approaches have proposed to enhance the performance of CBIR systems based on Hadoop framework. Herein, [27, 28] are two first studies that employed Hadoop framework for improving a CBIR performance. However, the scalability of these approaches are limited due to the small datasets. Moise et al. in [18] proposed a Haddop-based CBIR framework using eCP indexing technique for a large dataset. They evaluated the performance on very large cluster infrastructure, including 192 computing nodes. Otherwise, the work in [29, 32] are applied for medical images system. The datasets are only used in a specific area, while our approach is performed on large datasets, including many subjects such as building, castle, computers, etc. Lastly, the study in [30] designed a CBIR system based on Hadoop for quickly retrieval image. However, the similarity measure between images is performed by colors, which limit the accuracy of CBIR system. Overall, a study of Yin et al. [17] is one of the most relevant studies to ours.
While all the above works focused on using MapReduce parallelization facilities for improving the response time of a CBIR system, none utilize the cache mechanism to enhance the overall performance. Our work proposes an elegant collaborative cache using the Redis (Remote Dictionary Server) framework employed in the Hadoop distributed system. It not only reduces the I/O cost but also increases the data availability for the Hadoop distributed system. Therefore, the proposed CBIR system can gain better performance. To the best of our knowledge, this is the first study to propose a collaborative cache mechanism for a CBIR system in the distributed environment. The differences between our study and other works are summarized in the Table 1.
Existing approaches and the approach presented here
Existing approaches and the approach presented here
Cache methodology
It is clear that access data from the cache is much faster as compared to disk access. With this motivation, a distance-based cache strategy, which was inspired by [36], is applied to our system in order to reduce the overhead of distance computations during a query. The main functionality of the distance-based cache is twofold. First, given a query object o q and a database object o i , the cache should quickly determine the desirable value in case it already existed in the cache. However, as the actual value could only be found in the condition, it has been computed in the previous sessions. Thus, this functionality is limited in some special cases, such as repeated queries or querying by a database object [36]. The second functionality is that given a query object o q and a database object o i , the cache must have the ability to quickly determine the tightest possible lower and upper bounds of σ (o q , o i ), which denote the distance from o q to o i . This faster approximation of lower/upper bound distances is useful to filter out some nonrelevant objects or even a whole part of the index.
It is assumed that the track of distances is stored in the cache as a tuple form:
After that, a filter can be applied by using lower/upper bound distances derived from the
cache, instead of calculating the exact σ again. As shown in Fig. 1, suppose we have a query ball
(q, r
q
) with respect to a
range query within the radius r
q
, and a data
ball (o
i
,
r
o
i
), which
partitions the metric space into two half-spaces: one has distances to
o
i
less than a radius
r
o
i
and other
has distances to o
i
greater than a radius
r
o
i
.
Noticeably, the data region can be eliminated from the search if there is no overlapping
between the two balls (Fig. 1a) by
using the tightest lower bound equation:

An example of pruning index regions during a search employing the distance-based cache approximation.
In many parallel and distributed systems equipped with the MapReduce engine, data availability is considered a crucial factor in the performance of MapReduce. In particular, if a map task is placed on or close to machines that store the input data chunks, then a problem is called data availability. Obviously, when the data chunk associated with a task is stored locally, a system can reduce both the processing time of map tasks and network traffic load due to fetching data remotely. In our proposed in-memory distanced-based cache model in the distributed environment, unless the system includes a very large number of computing nodes, remote data is unavoidable. Consequently, the distance cache does not take full advantages. For example, in Fig. 2a, suppose that two distinct data types can be stored in a computing node; M1, M2, M3,..., M n refer to in-memory data blocks, which encapsulated the distance computations by the cache algorithm, and A1, A2, A3,..., A n refer to data blocks handled by HDFS. When map0 is assigned to a node 1, it accesses M1, A0 and A1 as inputs. While M1 and A0 are the memory block and data block stored in node 1, respectively, data block A1 has been fetched remotely from node 2. In this scenario, the performance of the MapReduce job is reduced by the additional time needed to transfer the data from node 2 tonode 1.

a) An example of fetching data remotely in a Hadoop map task. b) An example of pre-fetching data using the collaborative cache service.
Motivated by this observation, a collaborative caching mechanism is introduced, which coordinates all of the dedicated local caches to form a single global cache. It aims to synchronize data in every cache, thus the data availability increases in further map jobs for better efficiency. Overall, the main idea is that even when the requested data does not exist in the arbitrary local cache, it can still be accessed from a global cache without the need of explicit disk access. For instance, in Fig. 2b, it is assumed that block M1 in node 2 obtains the distance computations between a query and the data in block A1. In the collaborative caching model, block M1 will be collected by a global cache and then synchronized to the other node in the cluster. Consequently, node 1 will contain block M1 in its memory, even when the data inside is not actually computed by a map task in node 1. Later on, when a map task is generated in node 1 and data block A1 is required as its input, it can directly process data stored in memory block M1 without waiting for the fetching data time as compared to the scenario in Fig. 2a.
From the perspective on implementation, Redis is a suitable solution for our purpose. Intuitively, Redis is designed for adapting for various application purposes. Specifically, the Redis replication model supports master-slave architecture, in which data from one master can be replicated to any number of slaves. In the case of a master node failing, one of the remaining slaves is chosen to become a new master node, which enables fault-tolerance and data accessibility for this architecture. Moreover, the Redis replication is non-blocking in both the master and slave [45], which means that the master can continue serving queries when one or more slaves are synchronizing and slaves can answer queries using the old version of the data during the synchronization. Regarding this observation, Redis is a suitable solution for our collaborative cache service. From the deployment perspective, Redis clients can be set up in the same machines with Hadoop slaves, while the Redis master is launched in a separate machine. In particular, Redis slaves serve as a local in-memory cache to retain all distance computations from MapReduce tasks. Alternatively, the Redis master ensures a parallel job has a memory locality cache to improve the accomplished time by incorporating all local cache data from slaves to serve as a global cache, as explained in the above scenarios.
Briefly, the proposed architecture includes two main components: the offline component and the online component.
Offline component
As described in Fig. 3, the offline component consists of three main modules: build sequence file, create index tree, and group data.
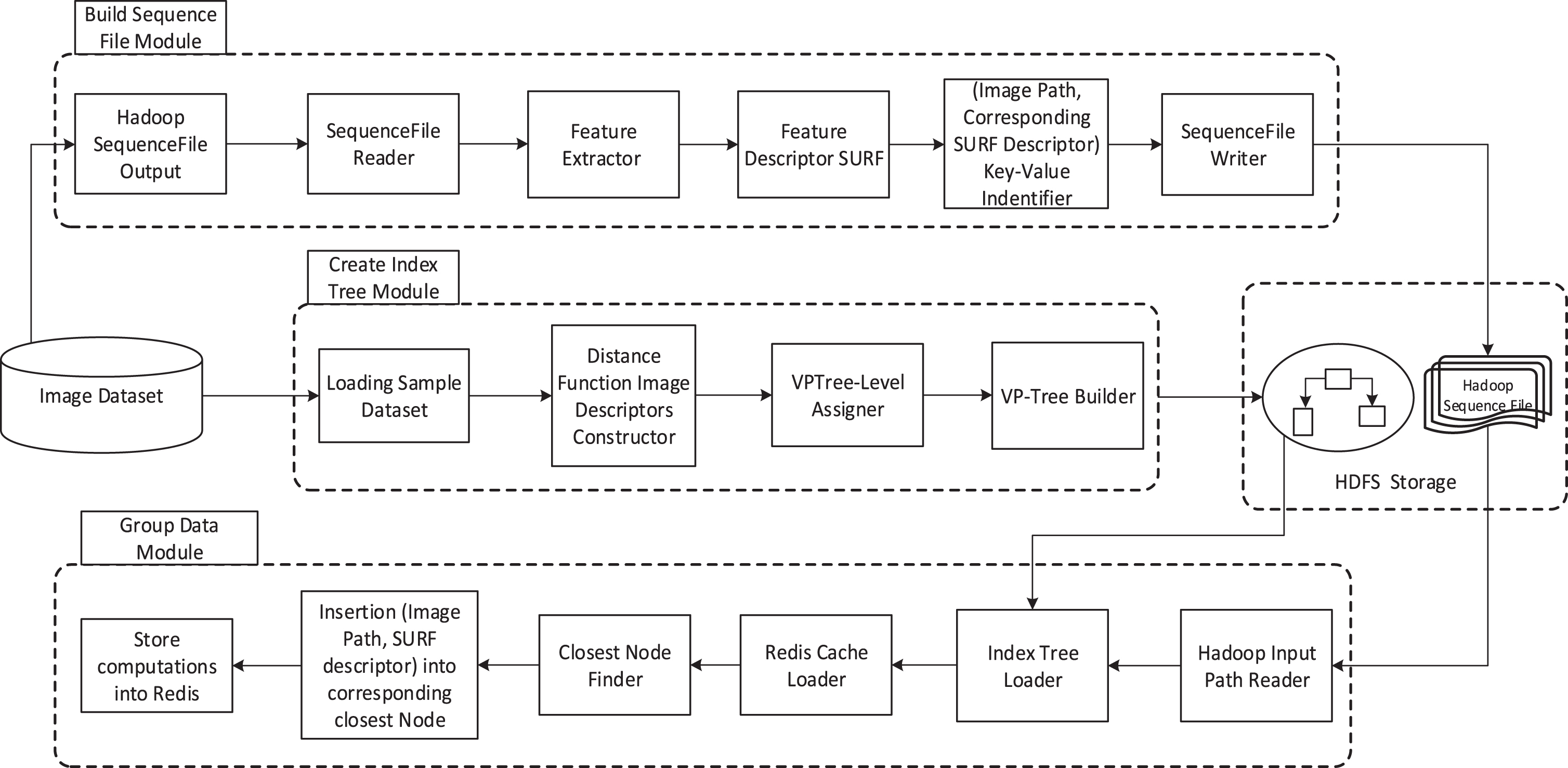
The offline architecture.
This first module takes into account preparing a suitable image format which is input for all involved Map/Reduce processes in the system. It contains two main parts, as follows.
A comparison of some dominant feature extraction algorithms [46]
(+) = efficient level
Eventually, the Hadoop SequenceFile is constructed based on image descriptors obtained from the previous steps. Basically, SequenceFile is a binary key-value pairs format in which the key is a unique identifier of an image and the value is the image descriptor vector. SequenceFile is usually used to solve the large number of small files problem in Hadoop, which is the advantage of processing a few large files rather than a large number of small files.
In this module, we proposed an indexing technique for organizing data efficiently for retrieving rather than the traditional sequence matching method. Given a data point, it is desirable to find the items in a dataset that are closest to this point. Theoretically, this task can be done by comparing a given point to the rest of the points in a database. However, it does not perform well on a large dataset. Hence, for accomplishing this task, a hierarchical data structure has been used in this module.
Typically, an index structure based on [24] is utilized, namely VP-Tree, which relies on distance computations among points in metric spaces. First, the algorithm selects a vantage point v in a dataset. The distance from the remaining points to v (d (p i , v)) is computed. Second, the median distance among those is selected. The database points are sorted according to their distance d (p i , v) compared with the median distance. This means that all points having a distance d (p i , v) smaller than the median are assigned to the left subspace of v, while the remaining ones are assigned to the right subspace. This procedure is recursively applied to the left and right subspaces of v. Choosing an appropriate vantage point to separate a dataset plays an important role in the performance of the VP-Tree algorithm. However, for simplicity, we pick a random point to be the vantage point v for the index algorithm. Otherwise, VP-Tree is a binary search tree structure so the searching complexity is O (log2N).
Apart from that, the distance function constructor and VP-Tree level assigner (Fig. 3) are two precursors used to define the VP-Tree properties. For instance, an Euclidean distance is employed to measure the distance between a vantage point and candidate points inserted into a tree, while a height factor is used to identify a terminate condition when building an index tree. For calculating the level of this index tree, the formula log2N/S is used, where N refers to the number of images in the dataset and S is the number of machines in a cluster environment.
Grouping data
This module (refer to Algorithm 1) performs a process that distributes data points to
their corresponding groups using the MapReduce framework. In the beginning, Hadoop
SequenceFile is split into a set of InputSplits data. Then, each InputSplit will be
assigned to individual mappers, which are generated by the framework for processing.
Particularly, the mapper starts by loading the index tree from the HDFS as well as
retrieving a cache object in the memory of a working machine. Then, for each data point,
the mapper traverses through the index tree to find the closest group to this point.
Afterward, the mapper generates a set of key-value pairs in the form of
<GroupID, point> . Herein, pairs of values having a similar key
are sent to the same Reducer through the intermediate Hadoop shuffling process. The
Reducer aggregates all points with the same GroupID and writes them
into HDFS.
Moreover, while using the traversed tree to find the closest group for a specific point, the algorithm also tracks all distances between an inserted point with nodes in its path. In this way, the function not only provides a GroupID but also brings back a distance from an inserted node to its parent node. As a result, these distances are fed to a local cache for estimating the lower and upper bounds of an unknown distance between two objects during querying.
Online component
Following that described in Fig. 4, the online component consists of two main modules, the pre-processing query image and the MapReduce retrieving module.
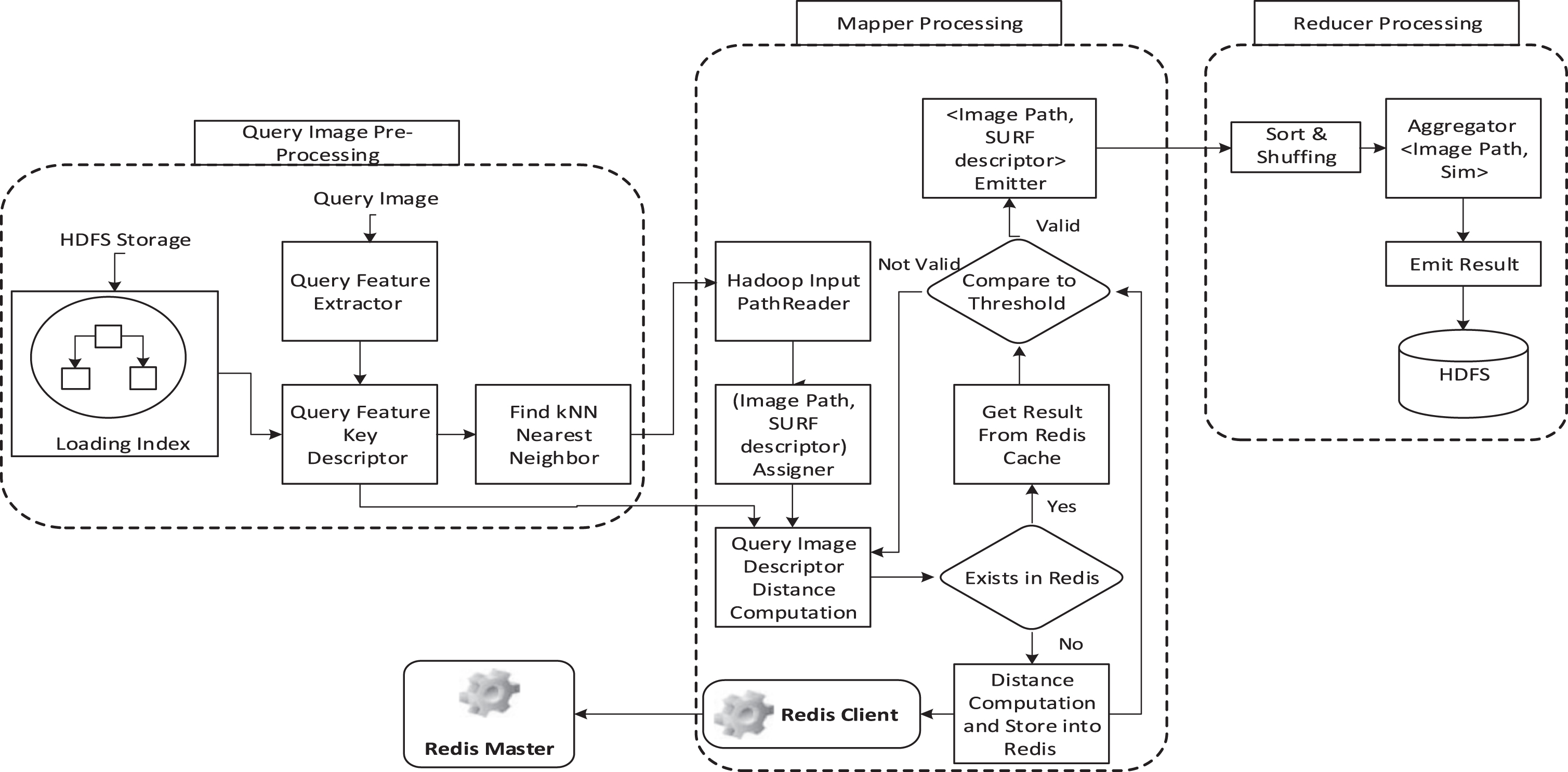
The online architecture.
This task receives a query image from a user and process it in the same way with an offline phase in order to generate an image descriptor vector. Then, the index tree is loaded from HDFS, which is used to find the kNN nearest neighbors for this query. Additionally, the paths to its neighbor’s group are fed as inputs to further the mapper processes.
Mapper-reducer retrieval
This module (refer to Algorithm 2) aims at exploiting a MapReduce framework for finding the similarity between a query image and images stored in the dataset. The basic task is to calculate the similarity between two images, then use a pre-defined threshold to filter values which satisfy this user-defined condition, whereby the system might return a list of suitable images to the user.

Experiments
Environment setup
The proposed framework has been implemented in Java with JDK version 1.8 and deployed on top of Hadoop 2.6.0. Furthermore, OpenCV library 2.4.9, which is wrapped under the Java component has been used as an auxiliary tool for developing and maintaining images involved in the pre-processing and searching phase. Additionally, a stable released package Redis 2.8 is set up under the master-slave replication model. It supported data synchronization from the global cache to each local cache for enhancing data availability. The Hadoop cluster includes one master node and seven data nodes, in which a master node is also configured as a data node. The details of the configuration used for the experiment can be found in Table 3.
System configuration
System configuration
Since our work focuses on how to find similar images that were captured at different angles of the same object for a given query, some well-known large datasets, such as CIFAR-10, SIFT-1M, and Eighty Million Tiny Images, are not suitable for this target. Instead, we employ multiple different datasets (Table 4) in the experiment in order to ensure that the proposed framework can operate efficiently under a variety of image characteristics.
Image dataset description
Image dataset description
Holidays dataset: The Holidays dataset was introduced in [37]. It mainly contains photos that were taken in various conditions: rotation, view point, and illumination changes, blurring, etc., with the purpose of testing the robustness of the similarity matching image algorithm. Concretely, the dataset contains 1,491 images of 500 scenes and objects provided together with a ground truth. The first image of each scene is used as a query.
UCID dataset: The UCID dataset [38] collects over 1300 uncompressed images of which 262 are query images along with defined matching ground truth images. Its goal is to evaluate image retrieval techniques in CBIR applications.
NUS-WIDE dataset [39]: This dataset contains 269,648 images downloaded from the social photography site Flickr that have been manually annotated, with several tags (2-5 on average) per image. The tag dictionary is a collection of 81 different tags. This dataset is used to conduct the experiments of the proposed framework on a large dataset.
MIRFLICK-2500 Image Collection [40]: As its name suggests, this collection consists of 25,000 downloaded images from Flickr through its API, which are provided as distractors. It offers users the ability to search and share their pictures based on image tags.
Our synthetic dataset: This dataset accumulates from nearly 1,000 images, which were taken from different places around stadiums, buildings, etc. and also guarantees similarity characteristics for comparison.
Various dataset sizes are needed to evaluate the effectiveness on scalability for our proposed framework. Thus, three datasets are constructed as shown in Table 5.
Image dataset of different scales
To evaluate the accuracy of the CBIR system, two commonly used metrics are precision and
recall, which are calculated as follows:
In addition, some other factors, such as total response time and cache hit ratio, are also considered. The total response time is determined by the average time that the system actually spends to process one query image, with the condition that the content caching has been filled by some previous queries. The cache hit ratio is the number of times the objects found in a cache divided by the number of times the systems found objects outside the cache. The higher the ratio, the more effective the cache is at improving the overall performance.
Experiment I: Evaluate the accuracy ofthe proposed framework
In this experiment, the accuracy factors of the proposed framework in terms of recall and F-measure are validated against two methods SR-Tree and LSH [41] on the same Holidays dataset. We estimated the MAP@K metric against others methods, such as SR-Tree, PCAH [42], SH [43], and the approached used by Hong et al. [44]. This experiment investigates the influence of dataset features on the accuracy factor of the CBIR systems when a large number of distractor images are involved in the dataset. First, the featured category used for similarity matching is extracted from the 1,491 images in the Holidays dataset and 269,648 images in NUS-WIDE dataset. To improve the computation speed of the SURF method, the number of features detected in each image, known as the HessianThreshold, is limited to a value 500. Then, a set of descriptors is built based on the features extracted in the previous step. On average, the size of descriptors for each image is 64x250, which means that each image has approximately 250 descriptors for representing its visual content, modeled by a 64-dimension vector. Thus, the total number of data points that are stored in the HDFS file system in the pre-processing step is approximately 372,750 for the Holidays dataset and 67.5 million for the NUS-WIDE dataset. Afterwards, the descriptors are partitioned into blocks using the VP-Tree clustering algorithm. To ensure the balance of the index tree, the depth level is calculated by using the formula O (log 2N/S) (Section 4.1.2). It is important to note that a balanced treestructure not only ensures the fairness of used resources among computing nodes but also avoids the bottleneck problem when a small portion of resources retain a large demand data placed on it. Lastly, threshold and sample query data are generated from each dataset. Concretely, the threshold is obtained by calculating the average distance for all possible candidate pairs of images.
Figure 6 represents the results according to the F-measure metric. The proposed framework achieves a higher accuracy and recall against the SR-Tree approach. Specifically, an F-measure attains 3.76% enhancement for our framework over SR-Tree and likely 2.8% enhancement for the recall factor. Against LSH, the proposed framework is approximately 2.53% and 2.29% higher for F-measure and the recall metric, respectively. Overall, the above results indicate that although our proposed method does not achieve remarkable performance compared to others, the outcome is still able to attain the requirement for a specific dataset in a CBIR system.

Several example images belong to the same group of the NUS-WIDE dataset with respect to “Building”, “Castle”, and “Computers”, but it is hard to determine the relevant images using a visual-content approach.
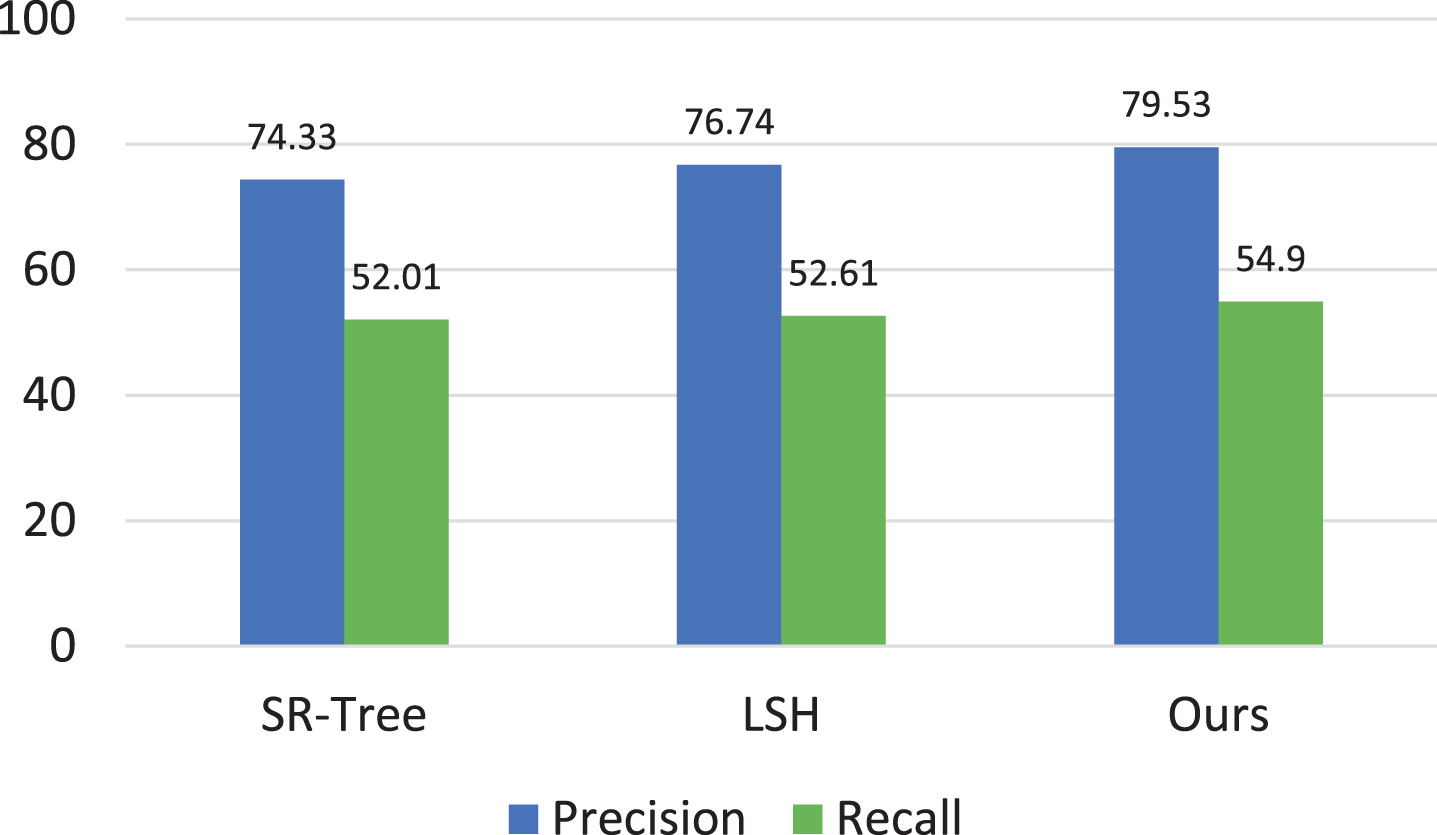
F-measure and recall for our proposed framework versus SR-Tree and LSH for the Holidays dataset.
Meanwhile, the mean average precision (MAP) of the proposed framework is shown in Fig. 7a, 7b, and 7c when it is performed on a large dataset like NUS-WIDE. As mentioned above, the NUS-WIDE dataset consists of a thousand images in which categories are manually tagged by the user. Many of the unique tags arise from spelling errors [39], thus decreasing the semantic correlation and increasing noise in the dataset. For example, some irrelevant images were tagged in the same categories by the user as shown in Fig. 5. The objects in each category are not totally related at all, but they are arranged in the same group. Therefore, the average precision archives generally below the expected. In particular, we performed experiments on varying parameters K, which indicate the number of neighbor results returned for a given query.

Evaluation of the MAP for the proposed framework.
According to results, our proposed framework outperforms PCAH, with 0.34% versus 0.2% at K = 1, and by 0.11% versus 0.015% at K = 100, respectively. While against SH, our approach is also better for most K values, for instances, by 0.34% versus 0.3% at K = 1, and by 0.11% versus 0.1% at K = 100. In contrast, comparing with the approach used by Hong et al., our proposed framework is not as good as for differences in K. The main reason is that the approach used by Hong et al. extracts different concept relationship features from three levels, including textual expression, visual images, and the occurrence frequency of concepts labeled on the image, whereas our feature-matching method only takes into account the visual content of images.
In this second experiment, our proposed method is validated regarding the time factor. To conduct the experiment, all the datasets shown in Table 4 are accumulated into a large dataset with a total size approximately 8 GB. The cache size of each slave nodes is set to 50 MB. The descriptors built from this dataset can be up to nearly 75 million data points. For the classifier, we also utilize the VP-Tree clustering algorithm for grouping similar data into clusters.
Meanwhile, the Redis replication model and the distance-based cache method are used to store distance calculations when clustering data. In particular, the Redis master merges distance caches from local nodes. Then, it performs the synchronization. As a consequence, the slave computing nodes not only contain the cached data, which was performed on its own machine, but also retains cached data on other nodes in the cluster. Hence, the performance in computational cost is crucially improved. In other words, the more distance calculations between images filled the cache, the more significant the computation cost of the further matching are deduced. Otherwise, dataset of various sizes are also constructed to validate the impact of dataset size on the proposed framework performance. As shown in Table 5, along with the large dataset, we also split it into two different sizes. The small dataset contains approximately 8 * 104 images in 2.9 GB and the medium dataset includes nearly 16 * 104 images in 4.29 GB.
For the results, we show the response time of our proposed framework in a single node and Hadoop cluster environments. In a single node environment, Fig. 8a indicates that the performance increased in a logarithmic manner with an increased number of images. Therefore, it proves that our proposed framework is capable of stable operation in the variant scale of dataset sizes. In the Hadoop cluster environment, we construct a cluster of eight computing nodes to study the effectiveness of using the distributed environment to enhance the performance in term of a time factor. Concretely, our experiment result compares with Yin et al. [17] works in the same cluster environment. The performance results are presented in Fig. 8b for the response time, which assumes that sufficient training queries have been accomplished before the current query is processed. The purpose of this work is to guarantee the cache data is carried out enough to utilize the advantages of the distance cache model. According to the experimental outcomes, the proposed framework outperforms that of Yin et al. in most testing activities. In particular, our work has achieved a significant improvement by saving approximately 94% time consumption for running a Hadoop job. The benefit of the distance cache model is also considered by comparing the performance of the system with and without the cache. The result is shown in Fig. 8c, which emphasizes the usefulness of the caching model by reducing the time consumption of a job ranging from 5% in the small dataset up to 10% in the large dataset. Eventually, Fig. 8d shows the ratio time saving of our proposed framework when deployed in different environments (1 node vs. 8 nodes). Specifically, the system performance has gained approximately 76% speedup for the corresponding large dataset, approximately 75% for the medium size, and up to 74% for the small dataset.
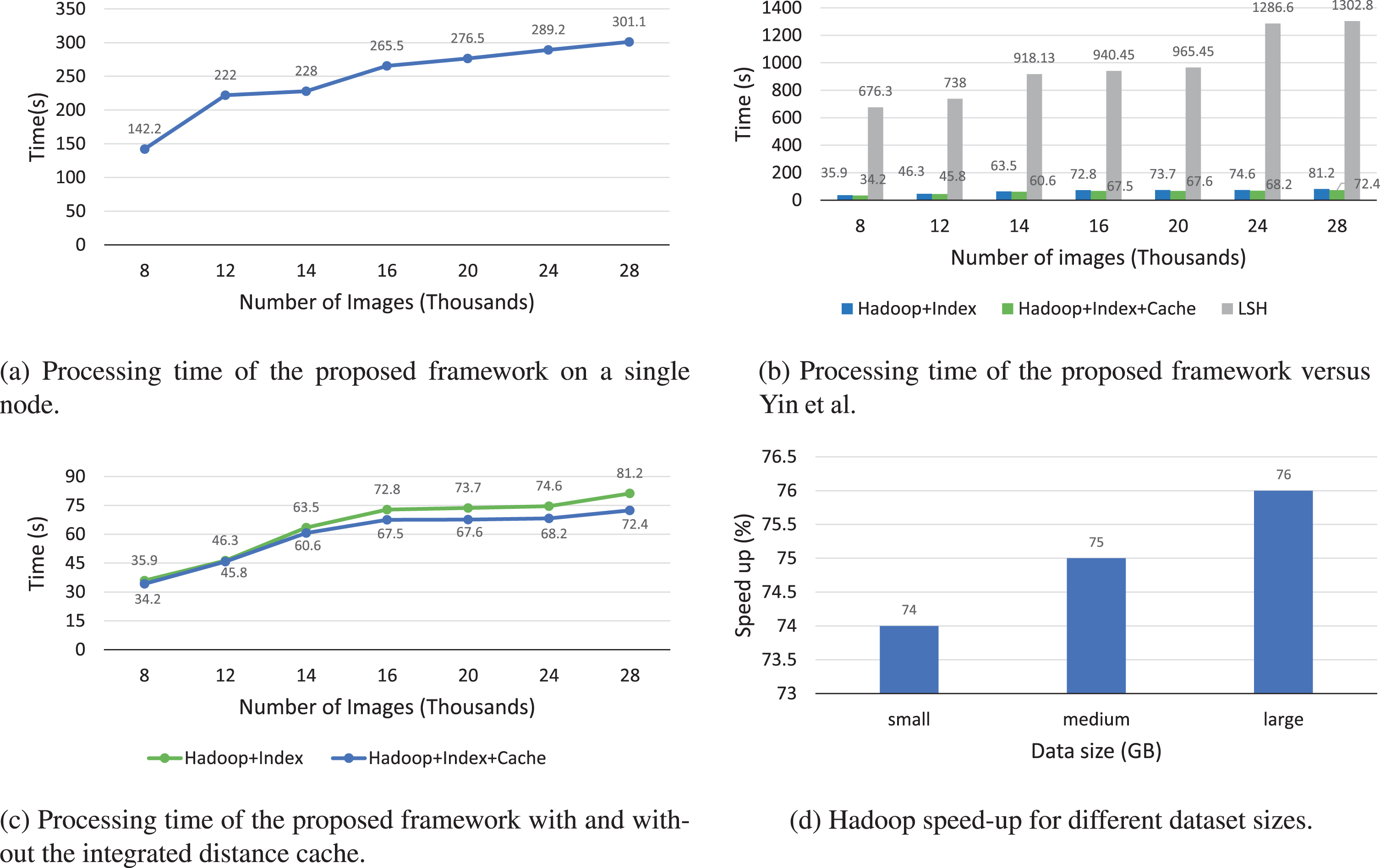
Evaluation the response time of the proposed framework for varying dataset sizes.
Figure 9 shows the exact, approximate, and total hit ratios as a function of the cache size. The approximate hit ratio is defined by the number of cache hits by using lower/upper bound distances. The first observation is that the distance cache has a remarkably large hit ratio, larger than 85% for the largest cache size tested. However, even with the lowest cache size of 10 MB, the distance cache model still obtains a higher hit ratio with 18 %. It is worth noticing that the approximate hit ratio is dramatically higher than the exact hit ratio, as shown in Fig. 9. The main reason is that when the cache is filled, the replacement policy retains only data which will give the best performance for the further approximate lower/upper bound calculation. Hence, instead of keeping the least recently used data (LRU) in the cache, it often replaces the old data with new data that ensures the policy above. Lastly, a trade-off between the time and accuracy factors arises when using the distance-based cache. In case of a miss, the distance cache will give an approximately distance instead of calculating directly. Obviously, this improves the overall speed of the system by reducing a part of the time-consuming computations. However, the accuracy metric may decrease due to the approximate calculation.

Hit ratio on varying cache size.
Combining the results between Figs. 9 and 8c, we can infer that the retrieval speed has inversely proportional to the hit ratio of distance-based cache service. When the total hits are increased, the performance of our proposed approach improves since the less distance computations are processed by the computing nodes. In contrast, if a cache miss occurs, the more distance computations are executed by the computing nodes. This leads to an increase in the response time of a job.
In this paper, we presented a scalable solution that was equipped with the most renowned parallel framework for improving the effectiveness of the CBIR system. Our contributions are considered as the following points. An indexing scheme based on an unsupervised learning method, namely VP-Tree, has been employed to classify the dataset, which gains the benefits of CBIR searching tasks, instead of using distance computation from the entire dataset. In addition, we proposed an in-memory distance-based cache to quickly determine the tightness lower/upper bounds between a query image and images in the database, thus improving the performance by avoiding the direct distance computations during the search process. Furthermore, a collaborative cache service is built together with the distance-based cache to increase the data availability for each computing node, which significantly accelerates the similar matching process due to the avoidance of remotely fetching data in a distributed application.
Through rigorous analysis on some well-known and public datasets, experimental results have demonstrated that the proposed method can achieve significant effectiveness compared to other studies with respect to response time and gain an acceptable accuracy ratio on varying datasets. Due to some limitations of the Hadoop MapReduce framework and the recent emerging growth of other technologies, we would like to investigate the effects of using other parallel computing frameworks for accelerating the proposed system.
Footnotes
Acknowledgment
This research was supported by the MSIT(Ministry of Science and ICT), Korea, under the ICT Consilience Creative program(IITP-2019-2015-0-00742) supervised by the IITP(Institute for Information & communications Technology Planning & Evaluation) and Institute for Information & communications Technology Promotion(IITP) grant funded by the Korea government(MSIT) (No. 2017-0-00294, Service mobility support distributed cloud technology