
Abstract
In this paper we present a new algorithm called Neural Network Pruning Based on Input Importance (NNPII) that prunes the neural network based on the input importance. The algorithm depends on the frequency of using a certain value of an attribute in all the given instances in the dataset. Pruning will include only links between input layer and hidden layer. The algorithm has three phases, the first phase is the preprocessing phase, where the data inputs are replaced with their importance. The second phase is a forward pass, which is similar to forward pass in the backpropgation algorithm, but instead of using the real inputs as inputs, we use the input importance obtained in the preprocessing stage. The third pass is the backward phase which is again as backpropgation algorithm, but in this stage we use the input importance instead of real inputs, and β factor that measures the value changing for every input attribute, β will be incorporated in the formula in updating the weights between the input layer and the hidden layer. The elimination process is performed based on criterion that depends on Ω factor that represents a threshold value for a certain input attribute for all instances. It is worth mentioning that the pruning is performed within the usual training phases. The proposed algorithm has been tested through three types of experiments, a comparison between backpropgation and NNPII, Applying NNPII with various parameter values and finally comparing NNPII with other various pruning algorithms. Results show that NNPII performs well and compete with other pruning algorithms. NNPII outperforms all other algorithms when the classes are fairly distributed in the datasets.
Introduction
Backpropgation (BP) algorithm is a very well known algorithm for supervised neural networks, one of the problems of backpropgation algorithm is that in most of the cases there are full connections between the nodes in input layer with all nodes in the hidden layer and between all the nodes in the hidden layer with all the nodes of the output layer. In many cases many of these links could be useless and if removed at a certain stage, results of the neural networks remain the same. This made many researchers develop many pruning algorithms [3–15, 23]. In this paper we present an algorithm to prune neural network while training. The proposed algorithm is called Neural Network Pruning based on Input Importance algorithm (NNPII). The proposed algorithm performs the pruning based on the input importance. Section 3 is devoted to the explanation of NNPII.
Literature review
Han et al. [10] presented a neural network pruning approach, the approach depends on three steps, the first step is used to train the neural network to discover which links are correct. In the second stage the less important links are removed. In the last stage, retrain the network to further tune the unnecessary weights. This approach has been tested on ImageNet dataset, Authors claim that their method reduced the number of parameters of AlexNet from 61 million to 6.7 million and with VCG-16 reduced the number of parameters from 138 million to 10.3 million, in both experiments without losing the accuracy. Actually this approach is designed to deal with mainly images and not tested with any other type of datasets. Le Cun et al. [13] proposed an algorithm called Optimal Brain Damage (OBD) approach, it depends on a measure called ‘saliency’ of a weight, OBD approximates this measure by roughly finding the second derivation of the error obtained from the neural network output considering this weight measure. The pruning process is performed on a well trained neural network, then discovers the silences, removes them and continue the same process until satisfaction. Following the same approach of OBD, Hassibi et al. [11] proposed an algorithm called Optimal Brain Surgeon(OBS). The main difference is that “OBS removes the diagonal assumption idea used in OBD, because if the diagonal assumption is inaccurate, it can lead to the removal of wrong weights. However it is impractical for large networks” [4]. OBD and OBS are becoming very well known algorithms as neural network pruning algorithms. Suzuki et al. [20] introduced a new algorithm for pruning neural networks. This algorithm reduces the structure for the inputs and the hidden layer. Each unit as a trial is removed from the structure and the error is measured. Then the units that do not affect the error will be removed. The obtained results outperformed the OBD method. This approach is applied only on images. Castellano et al. [7] proposed an algorithm called Castellano Fanelli Pelillo (CFP), This algorithm like OBS in a way that it reduces the connections after training and modifies the rest so that the error becomes lower. One major difference is that OBS updates the weights of all the remaining weights whereas in CFP only the weights that are coming to the unit involved in eliminating the weight are adjusted. Schiavo [18] performed a comparative study between OBS and CFP on a non-linear time series prediction, and has shown that CFP performs better in prediction and both of them are good in pruning.
Engelbrecht [8] proposed an algorithm called Variance Nullity Pruning (VNP) algorithm, which depends on a previous algorithm developed by Ponnapelli et al. [16]. In the paper of Pnnapelli et al. [16], only node removal is considered based on what so called sensitivity of weights, whereas in Bondarenko et al.’s paper [6], the algorithm considers both the node removal and weight.
Xin and Hu [22] proposed an approach for pruning inputs and hidden units. At the beginning identifying the more and less important inputs is performed based on the result ranking and their contribution. Then unnecessary inputs are removed. In the second phase the unnecessary hidden units are eliminated gradually from the network used for training based on the relevance measure. Hagiwara [9] proposed three ways to detect unnecessary hidden units and weights, these ways are goodness factor, consuming energy and weights power. These techniques are simple and their computational time is small. This approach comes under what is being called Magnitude Based Pruning (MBP). Augasta and Kathirvalavakumar [3] proposed a pruning algorithm called N2PS that is able to find the optimal architecture of the neural network by eliminating unnecessary inputs and hidden units. This is performed based on a measure that can be obtained using the sigmodial activation value of the unit and the weights of the outgoing links. Bondarenko et al. [6] presented an algorithm for neural network pruning depends on nodes/weights. In every iteration of pruning, an investigation is performed to identify the weight or the node needs to be eliminated. A classification error is computed without the weights and nodes in the input and hidden layers. The node/weight that is if removed does not affect the neural network (with the lowest effect on the classification error rate). It has been concluded that node pruning is better than the weight pruning in terms of more complex neural networks and computational time. Both will result in a pruned neural network.
Lazarevic and Obradovic [12] proposed two approaches to prune neural network ensembles. One approach is based on clustering which appliesk-means clustering to all classifiers to find out the similar classifiers, thereafter removing unnecessary classifiers within every cluster. Another approach has sequence of depth first trees construction for the classifiers followed by pruning process. The results show, by choosing an optimal subset of neural network, smaller ensemble of classifiers might be obtained maintaining the same accuracy or better using the complete ensemble. Stepniewski and Keane [19] investigated pruning in neural network based on the two stochastic methods, genetic algorithms and simulated annealing. It has been shown that given a small number of instances for data and verification, the neural network can fairly generalize. The main purpose of this research was to speed the training phase, to perform pruning and measure the network complexity. However, in this paper, it has been stated very clearly that “the number of tests performed here does not allow any conclusive” [19]. Sabo and Yu [17]proposed an algorithm for neural network pruning based on cross validation and sensitivity analysis, the proposed algorithm is called hybrid sensitivity analysis with re-pruning in which both node as well as weight pruning are considered. The proposed algorithm was compared with three approaches, local sensitivity method, the local variance sensitivity analysis and the cross validation pruning algorithm. This algorithm utilizes the advantages of all the three algorithms. The results show that neural network still maintains the level of accuracy with a minimized structure. Yilmaz [23] proposed a pruning approach for neural networks for velocity field. He started his neural network with 30 neurons in the hidden layer and trained the neural network based on that, and then a subsequent reduction by 2 in the hidden neurons is performed until only two neurons left in the hidden layer. In every reduction the neural network is retrained to get the best number of hidden neurons in the hidden layer. The one with the best prediction will be chosen as the pruned neural network.
Babaeizadeh et al. [5] proposed a new approach for pruning the neural network called NoiseOut, which works based on the correlation between the activation values in the hidden layer. Every two neurons have highly correlation are merged; this process is to keep the signal inside the neural network as close as possible to the original signal. In this case if a removal of a neuron occurs, the output result will not change much. Training will be continued after the removal to substitute any failure that might be caused by the merging. One of the problems is that there is no guarantee that the backprobgation algorithm yields to correlation between the nodes, which means in this case the approach can’t be applied. To solve this problem, the authors propose an adjustment for the cost function to increase the correlation between the neurons. The approach has been tested on various datasets and gave good results.
Molchanov et al. [14] presented a pruning algorithm for convolutional kernel in neural networks. The proposed method consists of three steps, tune the neural network until reaching to convergence to the target, keep pruning and tuning iteratively and finally stop pruning when the target convergence and pruning level are achieved with some balance. Experiments have been conducted on transfer learning problems and the obtained results are encouraging. Pan et al. [15] introduced an algorithm for removing neurons during training. According to the authors, the work is in its early stages and some experiments have been conducted on autoencoder, conventional and sparse linear regression neural networks, the authors feel that their approach is promising. Abbasi-Asl and Yu [1] proposed an approach for convolutional neural networks to compress them based on compressing and pruning the neural network weights and the filters. The filters are pruned during the training of convolutional neural networks. To perform their approach, they have introduced an index called filter importance index that should be equal to the accuracy of classification reduction after pruning a filter. Experiments have been conducted on Alex-Net and ResNet-50. The author claim that they have achieved very encouraging results. The same authors in [2] performed more experimentation to show the capability of their approach. Convolutional networks are basically used for computer vision and proved high performance. The proposed approach by the authors still need to show its effectiveness on several other domains specially those which are not related to images.
It is to be noted that in most of the existing pruning neural networks algorithms, the pruning starts after performing training or within the training but then iteratively pruning and training are applied. This will extend the training as well as the pruning time. Also many of those algorithms are related to certain domains. In this paper we propose an algorithm that performs pruning while the initial stage of training is taking place. This reduces the time used to initially train the neural networks. In most of other pruning algorithms, pruning start after the initial training and during advanced stages of training which means various levels of training are needed, whereas in our proposed approach only one stage of training is required. The other main difference between the proposed approach and other approaches is that it depends on the nature of the data, which means before starting any training, a sample of the dataset is selected to guide the pruning. In addition, the proposed algorithm is domain independent.
The proposed algorithm
The main purpose of NNPII algorithm is to prune the neural network during training. The pruning will occur only in the links between the input layer and the hidden layer. NNPII is performed in three stages. The first stage is called preprocessing stage, the importance of every input/attribute is obtained based on the possible changes of the values of the attribute over the dataset. The concept is that, the less is the change in the value of the attribute, the less is the importance of the attribute in affecting the produced output. Similarly, the more is the change in the values of the attribute in the dataset, the more is the importance of the attribute in the effect of obtaining a certain output. In this phase, every input instance which contains inputs for every attribute is going to be converted into input importance for every attribute. Also, in this stage a factor called beta (β) that measures the changing factor of every input attribute based on the attribute’s variation of inputs is computed. β is going to be used in the backward bus during the weight update.
The second stage, which is forward pass, is similar to BP algorithm, but the input importance computed in the preprocessing stage for every attributed is going to be considered instead of the real input in the formulas. At the end of this stage, the error is computed. The last stage is the backward pass which back propagates the error as in the backpropgation algorithm. The only difference is that β which is computed in the preprocessing stage is incorporated in the weighing update formulas. Also, in the backward pass, the pruning is performed based on a factor called Ω as explained in the next sections.
Preprocessing phase
In this phase we exploit and utilize the inputs and the nature of the dataset to identify the importance of every attribute input in producing certain output. The importance of every attribute input for every instance is going to be computed based on the changing factor β for every input attribute. The input in each instance is going to be replaced by its importance in the forward phase. The main steps for the preprocessing phase are below: A random sample scan of the given dataset is selected. Let us assume m is the of the number of randomly selected instances. For categorical and integer data, every attribute input di, there is ni (we will use it as n only in the set Pi) possible values. Compute the proportion of every attribute input di for every possible value as given in Equation (1)
riv is number of values equal to v in the random sample for di
Equation (1) yields to a set given below:
Pi is a set of all the proportion values of the data item di. pivj in Pi is the proportion of attribute di with possible jth value. Pi is required to compute the changing factor as stated in step 4. At this stage, a heuristic function is used to compute the changing factor βi for every di as shown in Equation (2)
Equation (2) leads to: Whenever the value of βi approaches 0, it means the value of di keeps changing, which means it might have more effect on changing the output. βi approaches 0 when there is an equal opportunity between the possible values of di. Whenever the value of βi approaches 0.5, it means the value of di does not change much, which means it might have less effect on changing the output value. βi reaches to 0.5 when all the values of the attribute/data item di are fixed. In our algorithm, we assume each di has at least two possible values. The steps of random selection of instances can be repeated many times say z times to find the average of βi′s to reduce the possibility of unfairness of random selection. For every input value in the instances, compute its importance using simple multiplication as given in Equation (3)
It is to be noticed that if we have real data, steps 2 and 3 will be replaced with the following: 2. For every attribute di, find the maximum value (Maxi) and minimum value (Mini) and compute the size of interval range for the values of di attribute. This is computed based on Equation (4).
where pai is the number of data partitions inputted by the user. pai is an integer number, the less is its value, the more is the size of the interval, and the more is its value, the less is the size of the interval. Based on the calculated inti, find the starting number and the last number of every interval and classify every number in the input related to attribute di to which interval does it belong. 3. The proportion of every di can now be computed as in Equation(1), but it will be rewritten as below
Pi = {piv1, piv2, piv3,..... pivn}, Pi is a set of all the proportions values of the data item i (di).
This phase is similar to the forward pass in backprogation algorithm, the only difference is that in this algorithm the importance of the input is going to be used instead of the input value itself. To make the next equation simple, we assume for every input Xi there is importance Ii (instead of also including the instance in the index) as shown in the preprocessing phase. The output of every neuron will be computed based on Equation (6).
where act is the activation function. Compute the output error as in backpropgation algorithm for every jth output neuron.
where Yj is the target output and Oj is the actual output.
In this phase as backpropgation algorithm, the error will be back propgated and the weights will be updated. In this stage a significance change will happen in the formulas used for weight updates and a prunning process will be performed. The steps to perform the backward phase are as below: Adjust the weights between the intermediate neuron i and the output neuron j according to the calculated error. This formula is typical similar the one used with backpropgation algorithm.
where lrate is a momentum constant 0≤lrate≤1, and α is a small value 0≤ α ≤1. Calculate the error Erri for neurons i as in the intermediate layers in backpropgation algorithm
where z is the number of outputs. Propgate the error back to the neuron K of lower level
Keep applying similar mechanism between the hidden layers until reaching the last hidden layer, then the weight change between the input layer (x) and hidden layer (k) will be
We notice in Equation (10), βx has been added. This addition is to change the weight of the input in accordance to the changing factor of the attribute computed in the preprocessing phase. Update each network weight Wa,b using Equation (12)
Any weight Wa,b < Ωa, then the corresponding link will be eliminated, where Ωa is a threshold value for the ath input in the neural network and computed using the following equation
where 0≤δ≤1 and Aa is the weight average of all weights related to the same input (here a) with all the neurons in the hidden layer.
To evaluate our proposed algorithm, we conducted various experiments based on UCI benchmarks datasets [21]. We used ionosphere, iris, vote, breast cancer and diabetes datasets. Three types of experiments have been conducted, the first one is to compare the results of the proposed approach with backpropgation algorithm without any type of pruning, the second experiment is to show the results of the proposed approach with various types of parameters. The third experiment is to compare the obtained results using the proposed approach with other pruning algorithms.
Experimentation parameter setting
In this section we present in Table 1 the parameters values that we used to obtain the best results in all the experiments. The parameters values that gave the best results have been selected after many running attempts.
Experimentation parameter setting
Experimentation parameter setting
It is to be noticed that m in the Table 1 has been listed in percentage instead of giving the number of randomly selected instances. For example, 40% related to breast cancer dataset means 280 instances out of the total number of instances which is 699 instances have been selected.
In this experiment we apply BB and NNPII algorithms on the same datasets and compare the results. The used datasets are of various sizes, data types and domains. The used datasets are breast cancer, ionosphere and vote as shown in Table 2. The datasets selected to have high accuracy value using BP to record its accuracy using NNPII.
Datasets used in experiment one
Datasets used in experiment one
The best obtained results are shown in Table 3 and Fig. 1.

Classification accuracy using BP and NNPII.
Classification accuracy using BP and NNPII
From the results, we clearly notice that NNPII outperforms BB in all the datasets. This means in addition to pruning, the NNPII is still performing well and the classification does not degrade. As an example, the best result for breast cancer was obtained using the following parameters, lrate = 0.2, momentum = 0.2, δ= 0.2, number of hidden layers is 1, number of neurons in the hidden layer is 2 neurons, number of epochs is 3500, number of randomly selected instances m (40% of the number of instances), number of partitions for real dataset is 6. The obtained weights between the input layer and the hidden layer using NNPII are shown in Table 4. The zero weight means the corresponding link iseliminated.
The obtained weights after applying NNPII
From Table 4 it is to be noticed that out of 18 links (9 inputs×2 hidden neurons), 7 links are eliminated in the breast cancer dataset. On the other hand, for the vote dataset, 12 links out of 32 (16×2) links are eliminated and for ionosphere dataset 87 links out of 238 (34×7) links are eliminated. The remaining input links after applying NNPII is shown in Table 5. The percentage of input link elimination from all input connections in the neural network is shown in Fig. 2.
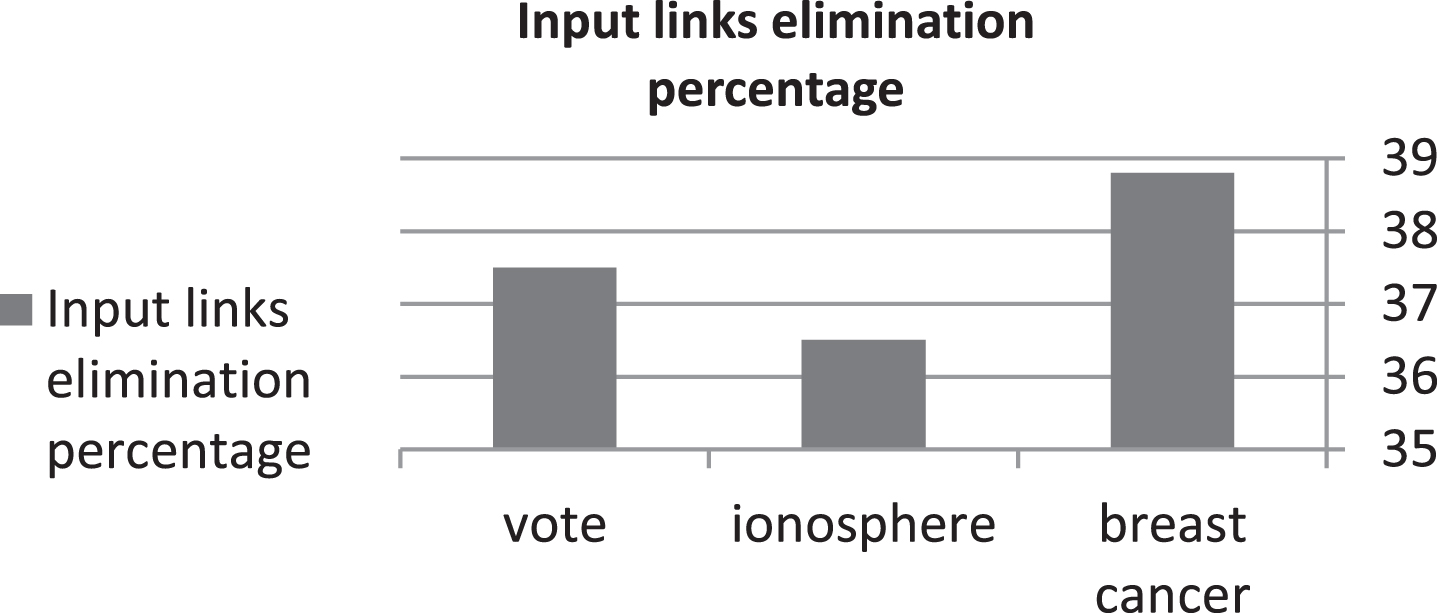
The elimination percentage in the input links from all the input connections in the ANN.
The remaining input links after applying NNPII
It is noticed from the obtained figures and tables that the elimination percentage is depending on the number of instances, the more is the number of instances, the more is the percentage of input links elimination, but this might not be always true.
In this experiment we apply NNPII on iris dataset with various parameter values concerned directly with the proposed algorithm. iris dataset has 150 instances with 5 attributes including the class. All the attribute values are real values except the class attribute which has three possible valuesIris-setosa,Iris-versicolor,Iris-virginica. We fix δ as 0.2 and keep changing the values of number of partitions pi for real datasets and number of randomly selected instances m. Table 6 shows the obtained results when m is fixed as 40% of the total number of instances and varied number of partitions. Table 7 shows the results accuracy of iris datasets with various m and pi values.
Iris classification accuracy using fixed m and various p
i
Iris classification accuracy using fixed m and various p i
Various results accuracy of iris datasets
From Table 6 and Table 7, we notice that the best obtained result is with 40% as percentage of randomly instance selection and 6 partitions. The results obtained using 50% as percentage of randomly selected instances and above with 6 partitions gave the same results (98.6%). This result could mean that the nature of the attribute values does not tolerate more partitions than 6 regardless of various values of p i . Also 40% indicates that this much of randomly instance selection is enough to give better classification. However, even values above 40% are still giving good results. In our experiments we consider a fixed partition for all the attributes. It is to be noted that the number of partitions might differ from one attribute to another based on the nature of the data and that will definitely increase the results accuracy.
In this section we perform a comparative study between NNPII results and the other results obtained by other pruning algorithms. Table 8 shows the datasets used for comparison.
The datasets used for comparison between NNPII and other pruning algorithms
The datasets used for comparison between NNPII and other pruning algorithms
Table 9 and Fig. 3 show the results of the comparative study between NNPII algorithm and other pruning algorithms. The results presented here are related to BP,N2PS, VNP, Xing-Hu, OBD,OBS and MBP algorithms and have been taken from [4].
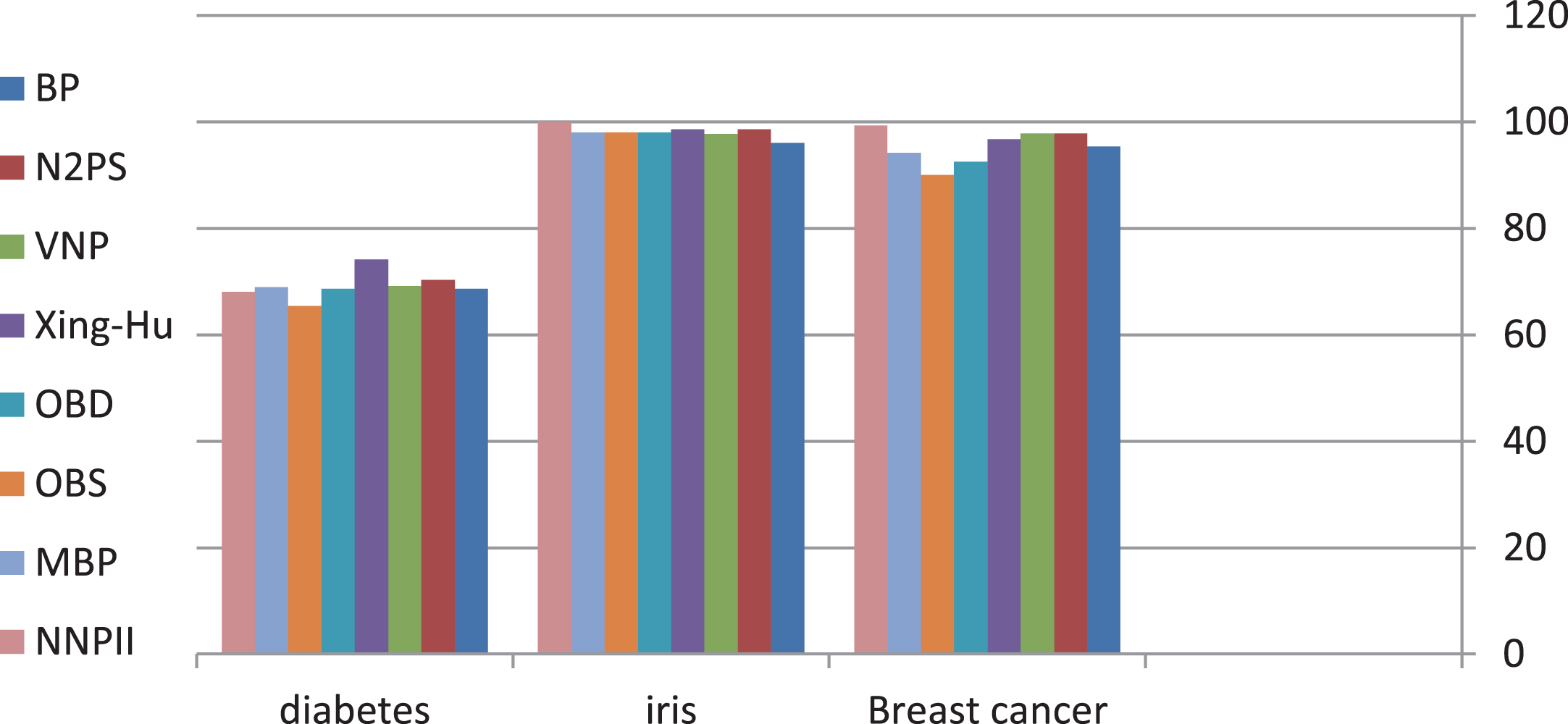
Comparative results between various pruning algorithms.
Comparison of NNPII algorithm and other pruning algorithms
Based on the obtained results, it is noticed that NNPII outperforms other pruning algorithms when breast cancer or iris datasets are used. In case of diabetes, NNPII does not perform well, but it still gives better performance than OBS. Xing-Hu approach outperforms all other approaches with diabetes dataset. The performance of NNPII using diabetes dataset is not bad comparing it with the other algorithms, the regression in the performance could be because the data instances are not distributed fairy among the class attribute values. The same reason could have the same effect on all the other algorithms. Because the NNPII algorithm depends on the nature of inputs, this leads to low accuracy. It is noticed that whenever there is a fair distribution in the dataset related to class attributes, NNPII performs better than other pruning algorithms. For example, in case of iris dataset, the class attributes are equally distributed where each class attribute has 50 instances, and in the case of diabetes 500 (65.1%) instances have value 0 and 268 (34.89%) have value 1, which indicates clearly that the class value distribution is unfair. In case of breast cancer, 458 (65.5%) have values benign and 241 (34.5%) malignant, which also indicates unfair distribution of class value attributes, but NNPII still gives the best results. One important issue to be considered is that the number of attributes in diabetes is 20, whereas the number of attributes in breast cancer is 10 with almost the same number of instances, this is one among other reasons that makes algorithms perform better with breast cancer comparing with diabetes as shown in Fig. 3. This is also valid for NNPII specially because the number of instances of diabetes dataset is small comparing to number of attributes with various possible values for each attribute (integers), this made it an obstacle for NNPII to decide correctly the importance of the data item. In the case of breast cancer, NNPII as other algorithms could perform well (even the best). This occurred despite that the data is not balanced, but NNPII could well recognize the importance of attributes because the data values for each attribute that can affect the results are clear within certain ranges in the dataset. To summarize, the reason why all the algorithms including the NNPII perform well using breast cancer is that there is a clear distinction in the value of attributes to classify benign or malignant whereas all the algorithms perform bad using the diabetes because the values of the given attributes are very close in a way classification becomes difficult and the number of instances is not enough to make the algorithms easily generalize. In brief, fair distribution of instances based on class attribute gives more opportunity to NNPII to perform better than other algorithms.
A pruning algorithm based on input importance called NNPII has been presented in this paper. NNPII is designed to remove only connections between the input layer and the hidden layer. NNPII has three stages, preprocessing stage, forward stage and backward stage. In NNPII, input importance is used to replace the real input. Pruning is performed throughout the training phase. Most of the previous works related to pruning, training and pruning are performed iteratively, which makes the training take a lot of time. Various experiments have been conducted. Results show the capability of NNPII to remove around 35% of the input connections. Comparing NNPII with various pruning algorithms, results show that whenever the class values are distributed fairly in the dataset, NNPII performs better than other algorithm, whereas when the distribution of the class values is not fair, NNPII still compete with other algorithms. The obtained results match with the logic of the NNPII algorithm, which depends on the nature of the inputs. Some future directions are considering pruning of nodes as well as the connections between the hidden layer and the output layer.