
Abstract
This paper presents a navigation algorithm based on interval type-2 fuzzy neural network fitting Q-learning (IT2FNN-Q), and succeeds in providing a solution for mobile robot navigation in complex environments. The algorithm utilizes the fuzzy reasoning adaptive ability and extensive functional approximation features of IT2FNN to solve this problem, mapped from state space to action space, of the Q-learning algorithm in unknown environments. Compared with the BP fitting Q-learning algorithm (BP-Q), IT2FNN-Q endows the robot with better adaptive and real-time decision-making abilities and solves the slow convergence and nonconvergence problems, through its local approximation. By comparison with the fuzzy neural network fitting Q-learning algorithm (FNN-Q), this proposed algorithm has more advantages for dealing with the external uncertainty, enabling the robot to complete a better path with less fuzzy rules. The results of the simulation and comparison of the proposed method with FNN-Q and BP-Q revealed that the mobile robot can navigate itself in complex environments with fewer steps, obtaining more reward values by adopting the algorithm presented in this paper.
Introduction
Mobile robot navigation in unknown environments is of current interest. Besides a complicated and changeable real-time system, robots in unknown complex dynamic environments also face other issues, such as uncertainties in the obstacle position, size, and scale as well as incorrect or incompletely measured data from the sensors [1, 2]. Therefore, a robot can only complete navigation by itself through self-learning in complex environments. Reinforcement learning enables an intelligent agent to perceive the state of the external environment, making it possible for the agent to select an optimal action through trial and error [3]. Furthermore, it does not need a priori knowledge to establish accurate mathematical models, and, as a consequence, is widely used in navigation systems.
In practical applications, when the state and action spaces of the external environment are in succession or excessive in number, the reinforcement learning training time becomes too long and the convergence rate is too slow. The effective way to solve this problem is to use a function approximation algorithm to realize the mapping from the state space to the action space [4–7], e.g., a fuzzy inference system (FIS) or neural network (NN). Paper [8] proposed a Q-learning algorithm based on FIS. The inference of FIS, which is more suitable for expressing fuzzy or qualitative knowledge, is similar to that of human thinking. The traditional fuzzy control method depicts the fuzzy set by the precise membership function, but the uncertain external factors widely exist, such as the uncertainty of fuzzy system inputs, fuzzy rule inputs, and training data. To deal with these uncertainties, Zadeh proposed an expansion of the membership of the fuzzy sets; from the exact values to fuzzy sets for further enhanced fuzziness [9]. Hagras presented a hierarchical Type-2 fuzzy logic control architecture for autonomous mobile robots that considered the uncertainties facing mobile robots in unstructured environments [10]. The type-2 fuzzy system includes a stronger description and processing of uncertain relationship. In addition, the type-2 fuzzy system lacks self-learning and self-adaptation abilities. By contrast, the neural network has the advantages of parallel computation, strong fault-tolerance, and adaptive learning; however, it does not make good use of existing and prior knowledge [11]. Therefore, the type-2 fuzzy system and neural network are combined to form a type-2 fuzzy neural network (T2FNN) so that the control system has both the advantages of the fuzzy reasoning adaptive abilities and extensive function approximation characteristics [12–14].
In order to reduce the complexity, the KM algorithms and error reverse transmissions are used to perform the type-reduction of the system [15] and to adjust the model parameters and weights, respectively. The interval type-2 fuzzy neural network (IT2FNN) was applied to the navigation system [16], which not only solves the problem of reinforcement learning for a large number of state spaces and difficult convergences, but also uses less rules to achieve a higher navigation accuracy.
The remainder of this paper is organized as follows: Section 2 provides an introduction to Q-learning and T2FNN; Section 3 describes the proposed method of IT2FNN fitting Q-learning and its application to robot navigation; Section 4 provides simulation results to demonstrate the advantages of the proposed method; the results are discussed in Section 4; finally, the concluding remarks are demonstrated in Section 5.
Q-learning and type-2 fuzzy neural network
Q-learning
Reinforcement learning is a principle of “trial and error” based on animal learning psychology. It can optimize decision sequences based on evaluative feedback signals in the process of interacting with the environment. Q-learning is a major reinforcement learning algorithm. It is not related to the external environment model and can provide the agent with the ability to select the best action. The best action is obtained by using the sequence of actions that have been experienced in the Markov decision process [17]. The algorithm achieves certain convergence conditions by continuously reducing the difference between the Q-estimates and adjacent states. Q (s
t
, a
t
) is updated as follows:
The type-2 fuzzy set is an extension of the traditional type-1 fuzzy set. The language information of the original data and uncertainty of the data are translated into the uncertainty of the fuzzy rules to be described by the type-2 fuzzy set. Its membership itself contains fuzzy sets. First, the exact input variable is subjected to type-2 fuzzification to obtain the type-2 fuzzy set input. Then, the type-2 fuzzy set output is obtained by fuzzy reasoning. Finally, the system requires precise output variables. Therefore, the demodulator is used to process the fuzzy set output before the defuzzifier. The principle diagram of the type-2 fuzzy system is shown in Fig. 1.
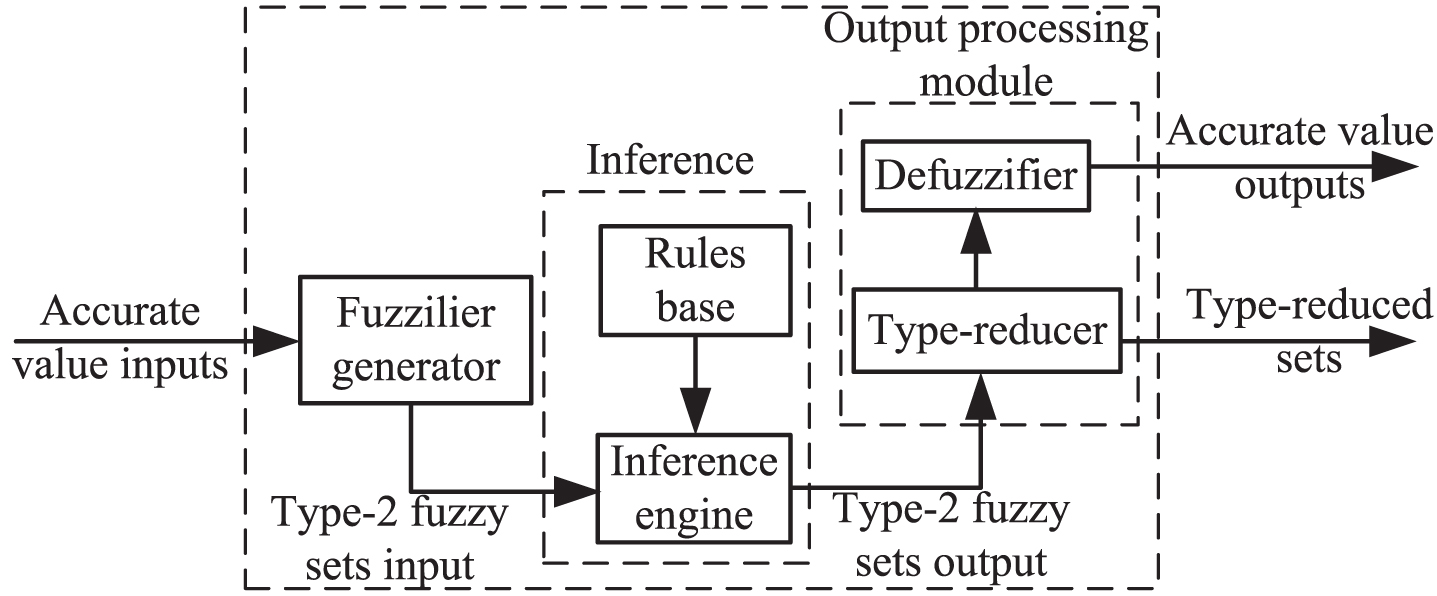
Principle diagram of the type-2 fuzzy system.
The type-2 fuzzy system and neural network are combined to form the T2FNN. This algorithm has advantages [18] and can approximate any nonlinear and uncertain systems. This paper presents the IT2FNN, which can rapidly generate fuzzy rules and adjust the internal structure and parameters. IT2FNN has the interval type-2 membership functions of an adjustable standard deviation and uncertainty center value. Figure 2 shows the type-2 Gaussian membership function. The type-2 fuzzy set is a domain that describes the uncertain combination of the membership degree function. The shaded part of Fig. 2 is the footprint uncertainty (FOU) of the interval type-2 fuzzy set.
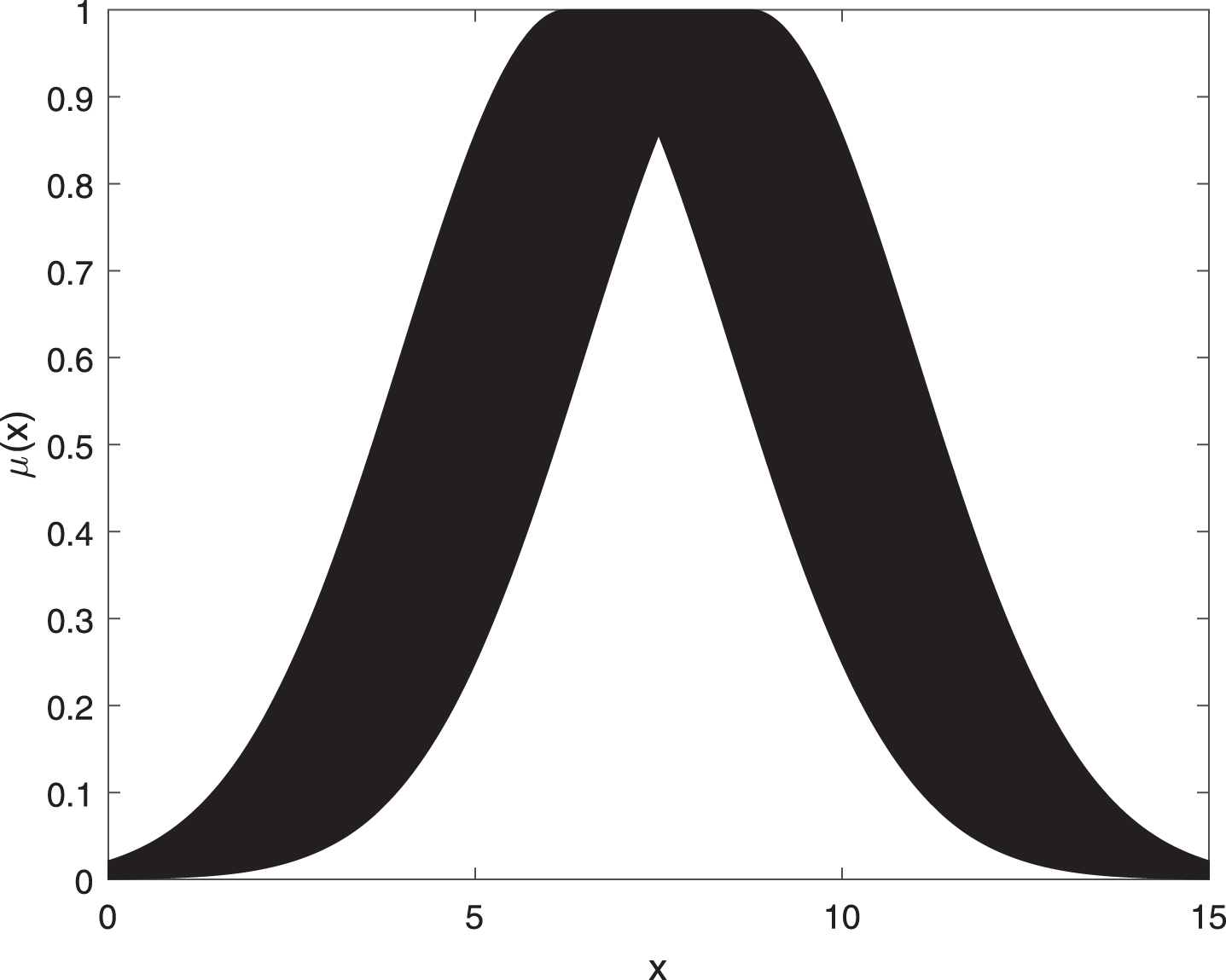
Gaussian membership function.
An IT2FNN has a strong ability of self-adaptability and a wide range of function approximation properties. Here, IT2FNN was combined with reinforcement learning. Such a network can-not only obtain the conclusion part of the fuzzy rule and parameters of the fuzzy membership function, but also simultaneously solve the reinforcement learning problem of continuous state and action spaces, realizing reinforcement learning using the relatively few fuzzy rule bases. Therefore, this network further improves the accuracy of the system. The input variables of IT2FNN are the state vectors of reinforcement learning. The outputs of the fuzzy rule are used as the action spaces of reinforcement learning. The state to action mapping is implemented by an extensive function approximation of IT2FNN. The reinforcement signals obtained by Q-learning in the environment constitute the error cost function of the network outputs. The network system determines the fuzzy rule by the back propagation of errors and adjusts the parameters of the fuzzy membership function. The corresponding block diagram is shown in Fig. 3.
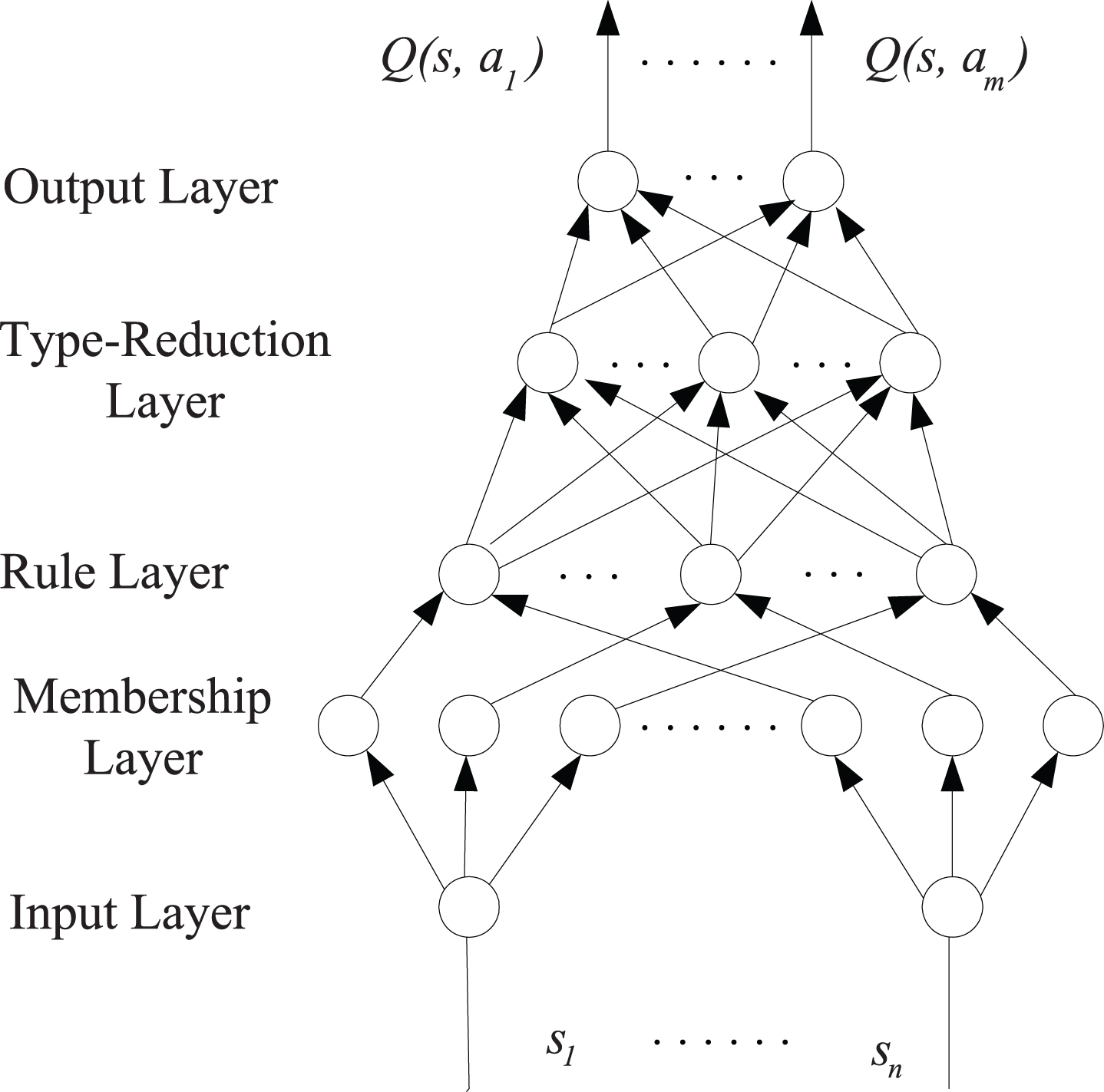
Structure of type-2 fuzzy neural network and reinforcement learning.
The external environment information obtained by the mobile robot body’s sensors and cameras is used for the network inputs. The number of inputs is n = 4. The output is the Q value corresponding to the set action. The number of outputs is m = 5. The fuzzy rule number is K = 3. The layers are mathematically described as follows.
Layer 1 (Input Layer): For each node i in this layer, s i denotes the inputs of IT2FNN. s = (s1, s2, s3, s4).
Layer 2 (Membership Layer): The interval type-2 Gaussian membership function is represented by
Where i = 1, 2, . . . , N and j = 1, 2, . . . , K.
Layer 3 (Rule Layer): Each node of the layer represents a fuzzy logic rule, and each node output corresponds to the strength of the fuzzy logic rule F j . F j is the interval type-1 fuzzy set;
Layer 4 (Type-Reduction Layer): This layer calculates the left and right points through the KM algorithm;
Here [
Layer 5 (Output Layer): This is based on the center value of the left and right points, and the exact fuzzy value of the system is calculated by;
From (7), the maximum Q value of the corresponding action is chosen as the output with a certain selection strategy. we define;
The mobile robot reaches the new state s t at this moment, and the corresponding reward value, R, will be simultaneously obtained from the environment. In accordance with the above method, the next action value, Q (st+1, at+1), is calculated. The output error is expressed as follows:
Here, the error function is
The main purpose of IT2FNN learning is to optimize the network step by step, maximize the system’s reward value through the online parameters of fuzzy membership function, and mapping the relationship of the fuzzy rules online. The structure of the IT2FNN fitting Q-learning is shown in Fig. 4.
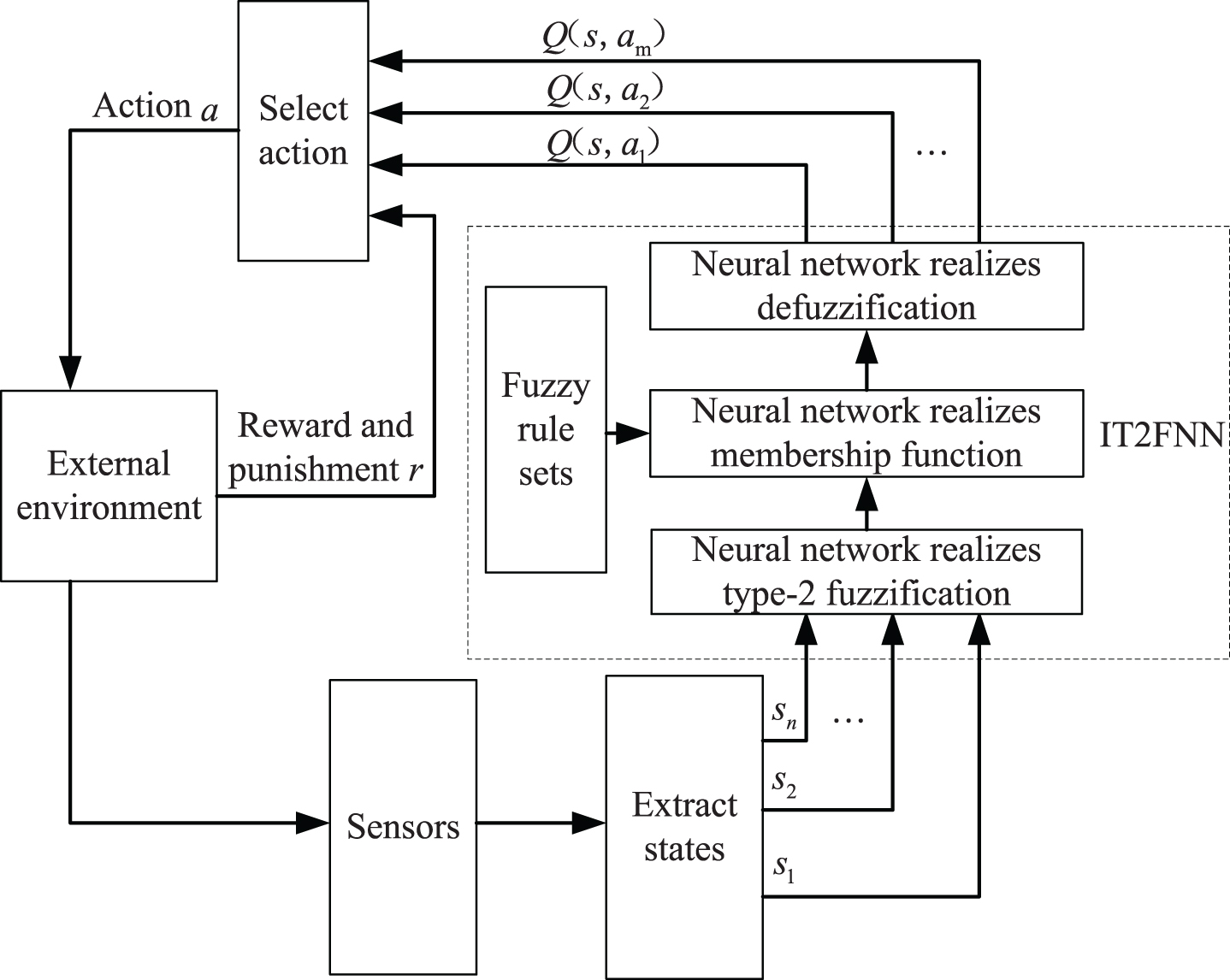
Structure of IT2FNN fitting Q-learning.
The proposed IT2FNN-Q algorithm is presented in Table 1.
IT2FNN-Q algorithm
System input and output settings
In this study, the IT2FNN system is used to approximate the Q (s, a) value. The network input is a four-dimensional vector, which corresponds to the state variables of the mobile robot state space. We define s = [s left , s front , s right , s goal ], where s left , s front , and s right are the minimum distances between the left, front, and right sides, respectively, of the mobile robot and obstacle. s goal is the angle between the body direction of the mobile robot and target point. In order to smoothen the robot movement path, this paper proposes the setting of five output actions, which include left turn 30°, left turn 15°, straight, right turn 15°, and right turn 30° respectively. The mobile robot running speed is determined by the distance between the robot body and its surrounding obstacles. If there are no obstacles in front, the mobile robot will move at full speed. The mobile robot slows down when encountering obstacles. The calculation formula of the mobile robot velocity is defined as follows:
Here, v is the velocity of the mobile robot; β is the velocity scale coefficient; D is the maximum distance measured by the sensor; and d min is the shortest distance between the robot and obstacle. If the value of d min is greater than D, then d min = D, in which case the mobile robot has a maximum travelling speed.
To make better use of the expertise, when setting the structure parameters the input variables are fuzzified based on expertise. The universe of discourse of the distances s left , s front , and s right between the body and obstacle are divided into {danger, moderation, and safety}, respectively. The universe of discourse of the angles between the body direction and target point are divided into {negative, zero, and positive}. In this study, the interval type-2 Gaussian membership function with uncertain central value is used. The result of the fuzzification is shown in Fig. 5.
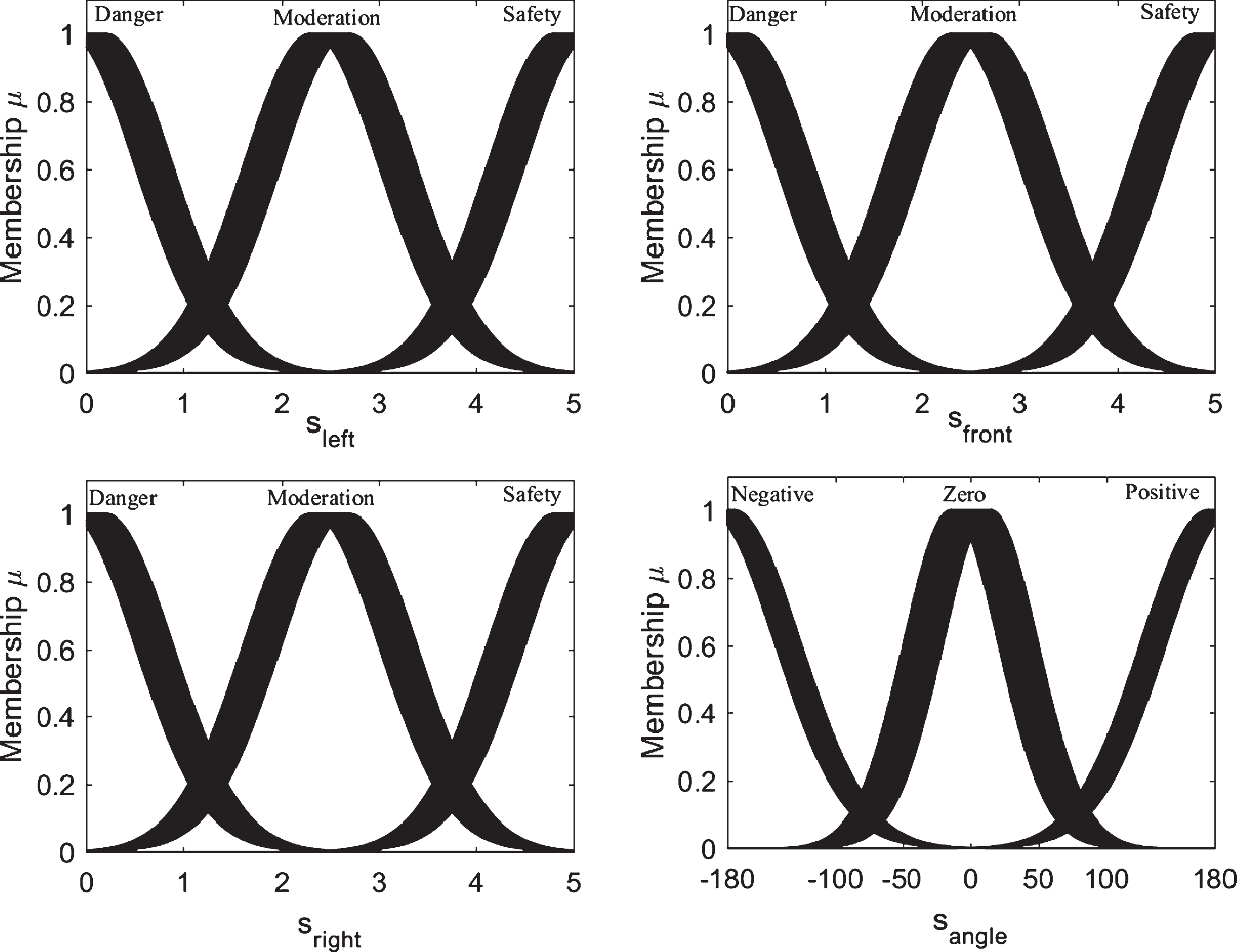
Fuzzy membership functions of input parameters.
Generally, a mobile robot needs to complete two tasks; avoid obstacles and approach the target. To approach the target, the closer the robot is to the target, the larger the reward value. In contrast, if stays away from the target point, it will be penalized. As for obstacle avoidance it is desirable that the distance between the mobile robot and obstacle is maximized, and the rule is that the closer the robot is to the obstacle, the more it will be penalized, i.e., the mobile robot is rewarded for staying away from obstacles. Setting a reasonable reward value is a key factor in Q-learning. Considering the above two behaviors, the reward values are set as follows:
First, various network parameters are initialized. The parameters are as follows: D = 5, γ = 0.9, η w = 0.5, η ξ = 0.2, η σ = 0.1, and ɛ = 0.85. The algorithm combining the above-mentioned IT2FNN and Q-learning is applied to the robot navigation system. Different simulation environments are established in the MATLAB GUI. When the mobile robot is set to collide with obstacles, it is set to return to the origin and retrain the operation. After 100 training periods, the consumption steps and consumption time to the target are shown in Figs. 6 and 7.
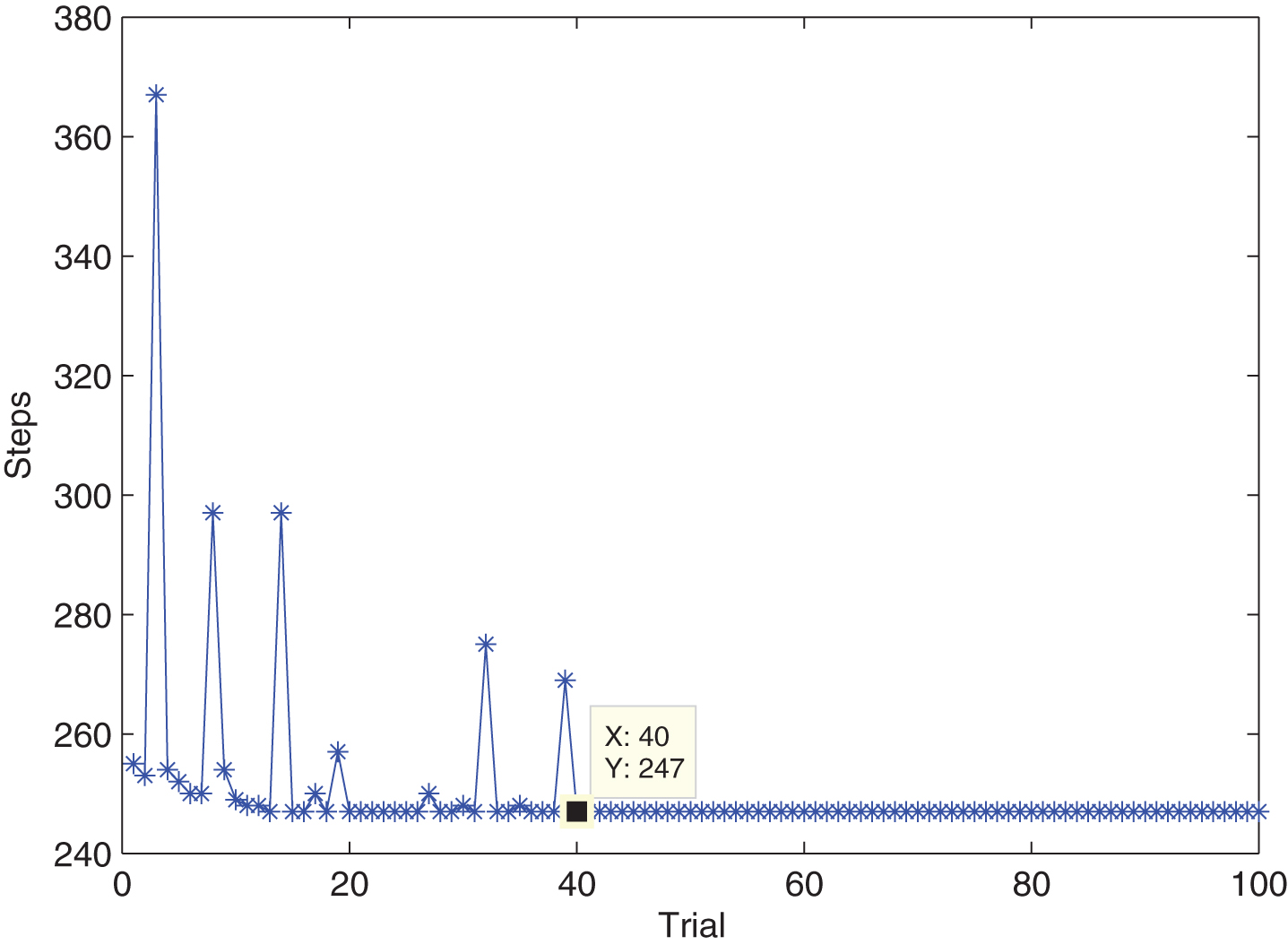
Consumption steps to the target.
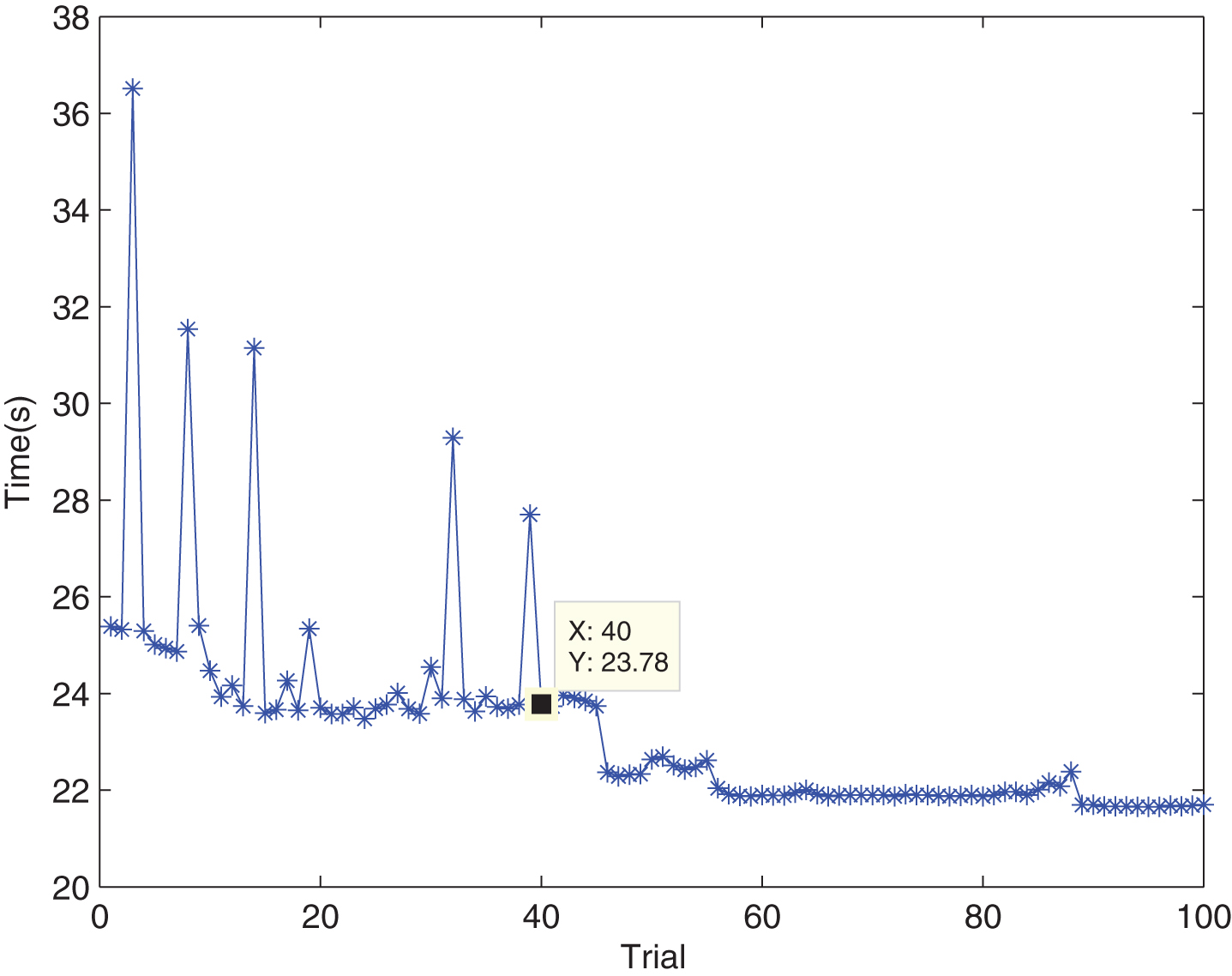
Consumption time to the target.
Figures 6 and 7 show that the robot reached the target point after 247 steps, and it ran for 23.78 s in 40 training periods.
A simulation verification was performed in different environments, and the results are shown in the Fig. 8.
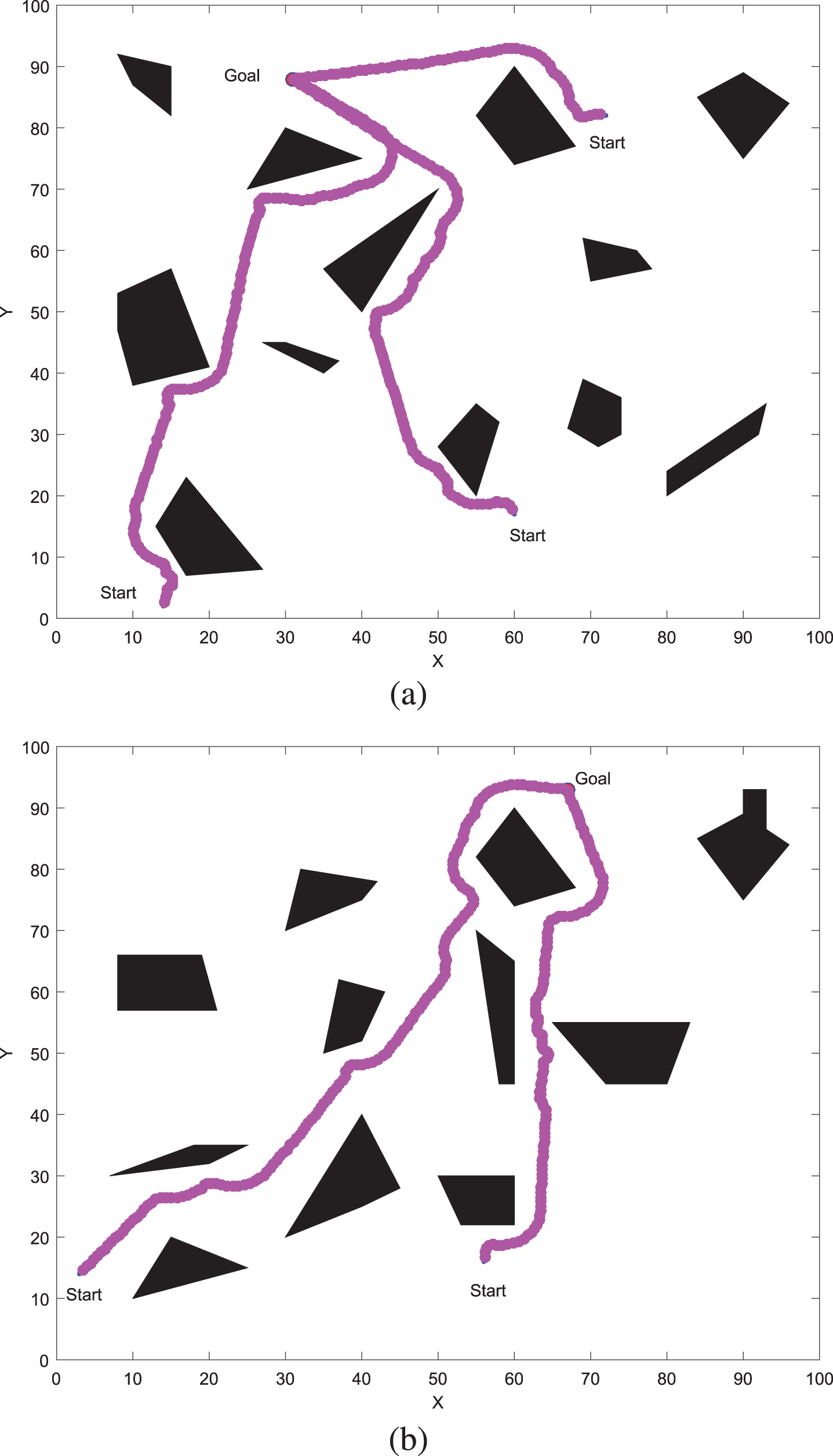
Navigation simulation results in different environments (No interference).
Figure 8 shows that the mobile robot can quickly and effectively avoid obstacles from the starting point to the target point after using the combined algorithm. The navigation algorithm has a good generalization ability in different environments. When the starting position of the robot is changed, that is, when the external state changes, the navigation system can still output a reasonable response quickly.
In the previous analysis, the sensor measurement was assumed to be ideal and unbiased; however, there would be unavoidable measurement errors in actual operation. Therefore, assuming that the measurement error of the sensor is less than 5%, random noise was added to the ideal input measurement. Through multiple simulation training experiments, the simulation results using MATLAB are shown in Fig. 9.
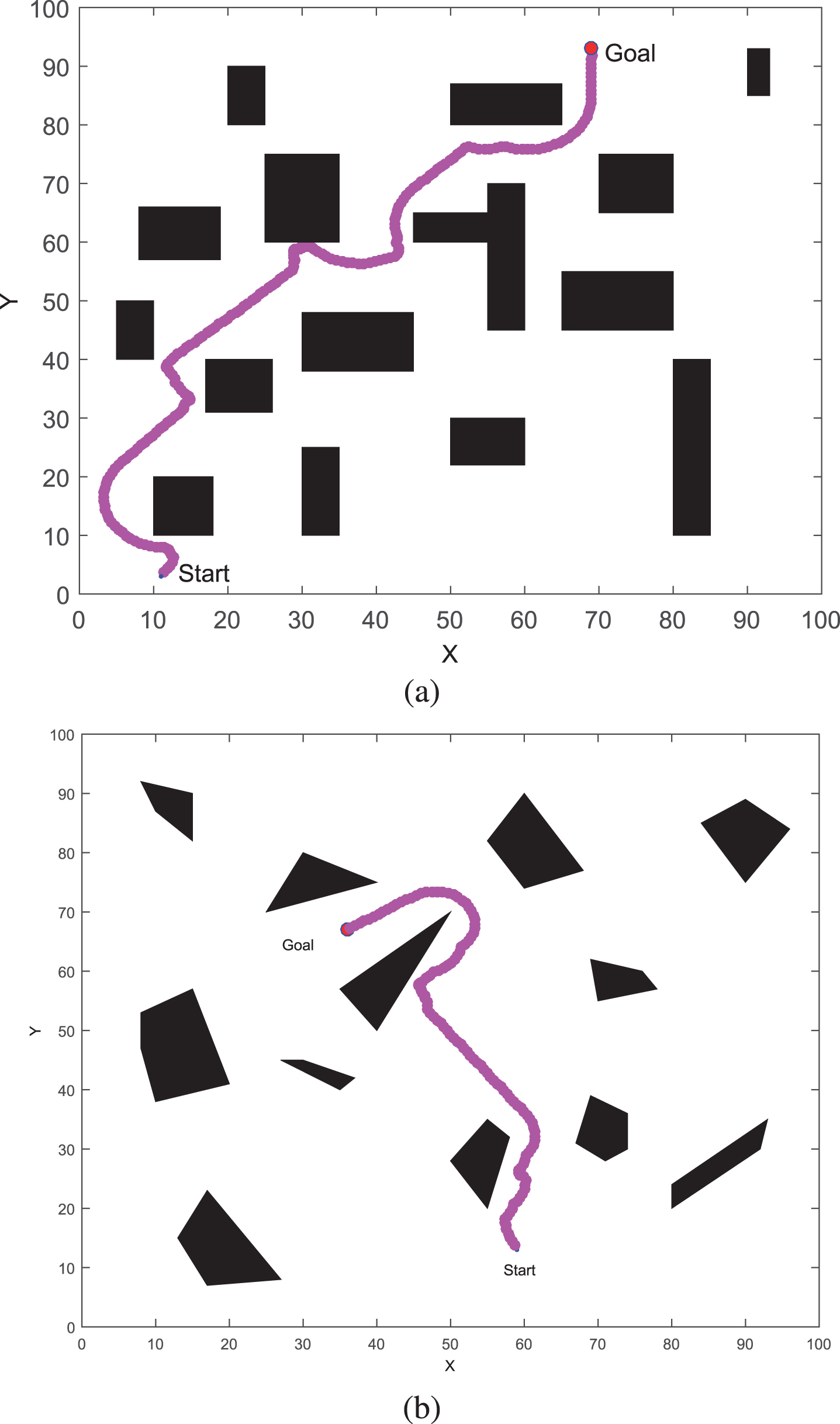
Navigation simulation results after adding interference.
Figure 9 shows the robot behavior after the input of the network is added with strong noise interference. As shown in Fig. 9, the running path of the mobile robot is not optimal, but it can successfully realize the navigation of the mobile robot without collision and avoiding obstacles. Simulation experiments show that the greater number of experimental training times, the smoother the walking path of the mobile robot. Thus, the superiority of the algorithm in dealing with interference input is achieved.
The simulation results show that the navigation algorithm combined with IT2FNN and Q-learning enables mobile robots to complete collision-free navigation. The performance of reinforcement learning is mainly measured by the convergence. However, the convergence can be reflected by the reward value of the reinforcement learning. To verify the superiority of the proposed algorithm in the same environment, the comparative experiments for three algorithms were conducted, namely the IT2FNN-Q, FNN-Q [11], and BP-Q [19] algorithms. One hundred training cycles are considered. Figure 10 shows the normalized reward value variation curves obtained by the three algorithms through the control strategy.
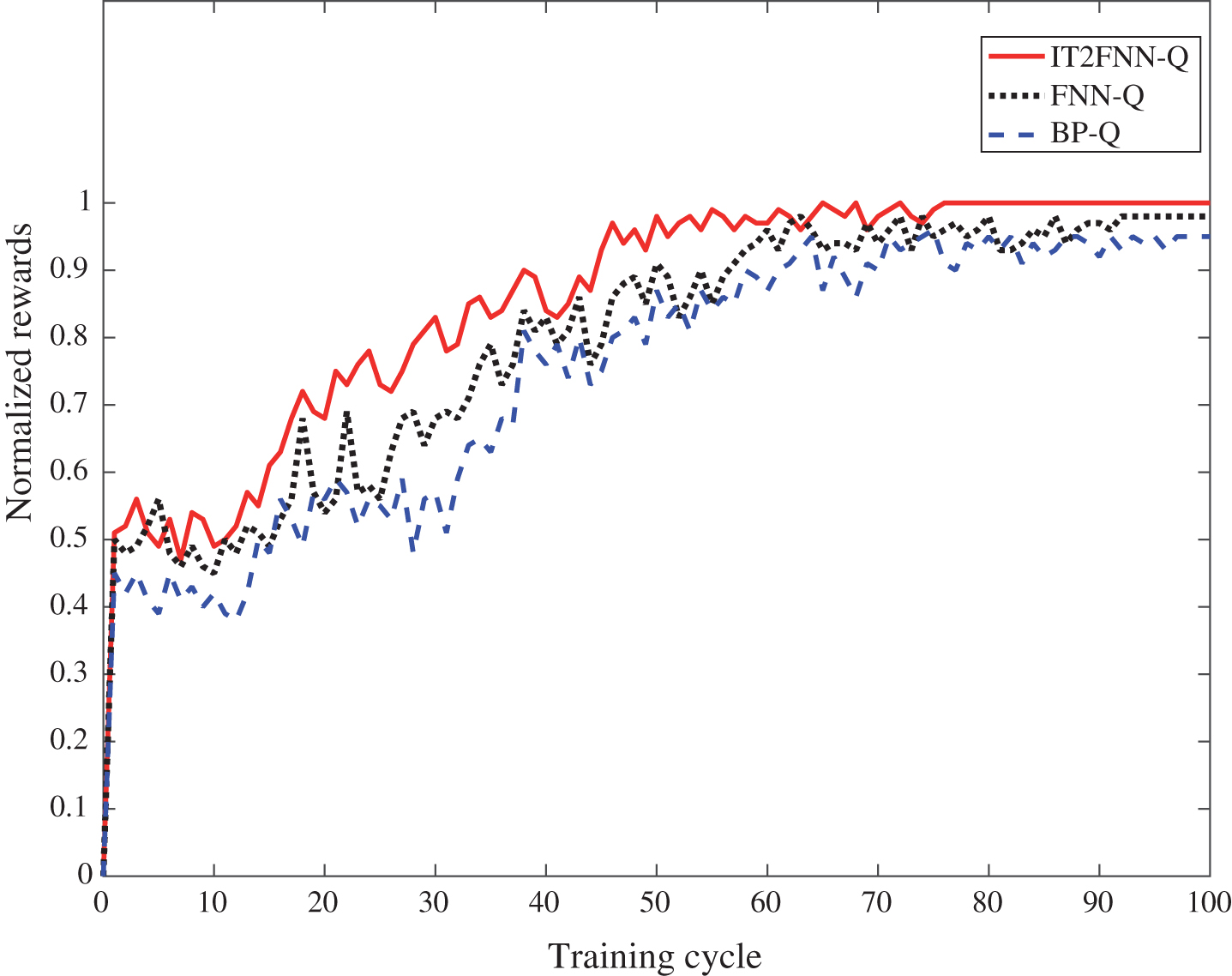
Normalized reward values for the three algorithms.
For an increasing learning number, the cumulative reward value obtained by each algorithm is gradually increased and finally reaches the convergence, as shown in Fig. 10. Each input variable is divided into three fuzzy rules in IT2FNN. However, it is divided into six fuzzy rules in FNN. The IT2FNN-Q navigation algorithm can acquire more accumulated reward values with fewer fuzzy rules, and it achieves a faster convergence rate. FNN-Q is better than BP-Q in terms of generalization ability. Thus, the results show that the BP network has the worst convergence rate. For the case of setting the same starting and target points, the number of iteration steps required for IT2FNN-Q to complete the navigation task is minimal, as shown in Table 2. It shows that the proposed algorithm (IT2FNN-Q) has better practicability and accuracy.
Iterative steps comparison
A mobile robot navigation algorithm for complex environments was proposed using IT2FNN fitting Q-learning. The function approximation feature of IT2FNN is used to solve the mapping relationship between the state and action spaces in Q-learning. The KM algorithm was used to reduce the order of the two fuzzy inputs, and the gradient descent method was used to adjust the parameters of the network. The result shows that the proposed algorithm (IT2FNN-Q) can still enable mobile robots to complete navigation tasks, even when there is interference from the external surroundings. Compared with FNN-Q and BP-Q, the proposed algorithm enables Q-learning to achieve a faster convergence rate by using fewer fuzzy rules. By changing the travelling speed, the mobile robot completes the navigation task in a complex environment with fewer iteration steps. The proposed algorithm has strong obstacle avoidance and a self-adaptive ability and robustness, which enables mobile robots to complete autonomous navigation tasks in complex environments in a short time.
Footnotes
Acknowledgements
This work was supported in part by the National Natural Science Foundation of China (grant no. 31760342) and Guangxi University Experimental Teaching Reform Project in 2017.