
Abstract
Genetic algorithm is one of data mining classification techniques and it has been applied successfully in a wide range of applications. However, the performance of Genetic algorithm fluctuates significantly. This research work combines Genetic algorithm with fuzzy logic to adapt dynamically crossover and mutation parameters of Genetic algorithm. Two different datasets are taken during the experiment. Several experiments have been performed to prove the effectiveness of the proposed algorithm. Results show that the rules generated from a proposed algorithm are significantly better with high fitness and more efficient as compared to a normal Genetic algorithm.
Introduction
Today databases can range in size up to the terabytes of data which store hidden information of strategic importance. Data mining is used to extract knowledge from large databases [1]. To this aim, data mining technique finds correlations or patterns among dozens of fields in large relational databases [2]. Classification is one of data mining technique that assigns categories to a collection of data to support in more accurate predictions and analysis [3]. Genetic Algorithm (GA) is one of classification technique algorithms in data mining. The GA creates an initial population of solutions randomly. The new population is formed which consist of the fittest rules in the current population, as well as offspring of these rules [4–5]. The offspring is created by applying genetic operators such as follow [6]:
Selection: This deals with the probabilistic survival of the fittest, more fit chromosomes are chosen to survive. Where fitness is a comparable measure of how well a chromosome solves the problem at hand.
Crossover: In crossover, substrings from pairs of rules are swapped to form new pairs of rules.
Mutation: In mutation, randomly selected bits in a rule’s string are inverted.
In general, the main motivation of using GAs in the discovery of high-level prediction rules is that they perform a global search and cope better with attribute interaction than the greedy rule induction algorithms often used in data mining [7]. Represent the knowledge in the form of IF-THEN rules one of the most expressive and most human readable representation for hypotheses [8].
To extracting robust rules, GA behavior must be better tuned to offer the most appropriate exploration/exploitation [9, 10]. For these reasons, many adaptive techniques were suggested for adapting this behavior. One of these techniques lies in the application of Fuzzy Logic Controllers (FLC) for adjusting the control parameter of GAs [11].
The way of decision making in humans that involves all intermediate possibilities between digital values YES/NO. It has been applied to many fields from control theory to artificial intelligence [6]. It can control machines and consumer products. It may not give accurate reasoning, but acceptable reasoning. fuzzy logic helps to deal with the uncertainty in engineering. The main idea is to use an FLC whose inputs are any combination of GA performance measures and/or current control parameters and whose outputs are GA control parameters. Current performance measures of the GA are sent to the FLCs, which computers new control parameters values that will be used by the GA [12]. The generic structure of a FLC is shown in Fig. 1.

General structure of FLC.
Liu et al. [13] have introduced a hybrid Fuzzy-Genetic Algorithm (FGA) approach for solving the crew grouping problems. Fuzzy logic-based controllers were used to adaptively adjust the genetic algorithms crossover and muta-tion to ameliorate the genetic algorithm performance. The initial population was generated from a random selection of solutions while the crossover probability and the mutation probability are defined on some individuals of the population using several FLCs considering the fitness values of individuals and its distances. The crossover and mutation probabilities are updated considering the changes of the maximum fitness and average fitness in the GA population of two continuous generations where the best individual has the greatest probability to be chosen. The experiment results showed that the conventional genetic algorithm converges very fast with a larger probability to get besieged in local optima, while the Fuzzy Genetic Algorithm (FGA) spends more time to examine more feasible solutions with a larger probability to find global optimal solutions, which means that the proposed FGA method for the crew grouping problem is more efficient comparing to the standard GA approach.
Lee et al. [14] have implemented a fuzzy knowledge-based system to dynamically control genetic algorithm pa-rameters (GA). A fuzzy knowledge-based system is used to automatically control the population size, crossover rates, and mutation rates. A combination of GA performance measures and current control settings are used as system input where the output can be any of the GA control parameters. The system used triangular membership functions and the outputs defuzzification was done using the centroid method. In addition, online performance/offline performance have been used to measure ongoing performance and convergence, respectively. The Dynamic Parametric GA system showed the general applicability to a wide range of applications with an overall performance improvement.
Similarly, Song et al. [15] have used a Fuzzy Logic Controlled Genetic Algorithm (FCGA) for the environmental and economic dispatch problems. To achieve the best possible performance two heuristics based fuzzy crossover and mutation controllers was implemented and the crossover probability and mutation rate were dynamically adjusted. The fundamental rule used to update the crossover probability is that if the variation in average fitness of the populations is above zero and keeps the same sign in successive generations then the crossover probability should be increased, otherwise it should be decreased. On the other hand, the flip function is used to determine the mutation operation, and the mutate bit is randomly selected. The achieved results have shown performance improvement comparing to standard GA and the Newton-Raphson method. Yun et al. [16] have proposed a comparison study between four Adaptive Genetic Algorithms (AGAs). For the adaptive abilities, a FLC is improved by them and three heuristics from the conventional studies are used. The adaptive abilities performance was compared considering the search quality and search speed as an important measure. Tow crossover and mutation FLC were designed to adaptively regulate the crossover and mutation rate in the search process by encouraging the well performing operators that produce more offspring and reduce the chance of poorly performing operators. The analysis results have demonstrated that the AGA with the scheme of the FLC can give better performance in search quality and search speed than the heuristics ones and applying the FLC for building an adaptive ability is more robust than applying the three heuristics.
Xu et al. [17] have applied a Fuzzy Evolutionary Algorithm (FEA) to automatically generate a trajectory of 7 degree of freedom robot. This algorithm represents an integration of fuzzy expert systems with evolutionary algorithms. Proposed FEA is used to solve the problems of slow search speed and low accuracy by selecting initially the population size, chromosome size and control parameters and adjusting them on-line. Experimental results have shown that the 7 degree of freedom robot trajectories can be automatically generated very fast with high accuracy. Herrera et al. [12] have succeeded to design technique to adapt the genetic operators based on FLCs known as coevolution with Fuzzy Behaviors (FBs). Vectors with linguistic values are used to represent the fuzzy rule bases of the FLC known as FBs. Also, one GA which used to create the fuzzy rule bases of the FLCs coevolves with the GA that uses the genetic operator to be controlled (coevolution). The main objective of coevolution with FBs is to get fuzzy rule bases can create correct control parameter values that allow the genetic operator to show an appropriate performance. The proposed technique is used to adapt the crossover operator for real coded GAs to examine the models’ performance and optimal results have been achieved.
In this paper, fuzzy logic was combined with GA in data mining to extract interesting and accurate rules. The growth rate function is proposed to update crossover and mutation probabilities according the change of genetic algorithm performance parameters between two continuous generations. This change was calculated using the maximum fitness and the average fitness of the populations of the two continuous generations. In experiment 2, different datasets were used to compare their outputs using the normal genetic algorithm and FGA to show the goodness of using FLC in genetic algorithm. In the literatures, the fuzzy controller was mainly used to adjust the gains of the general genetic algorithm.
The rest of this work is structured as follows. Section 2 covers the proposed algorithm. Section 3 provides the simulation and experimental results. Finally, conclusions are written in Section 4.
The performance of the GA is correlated directly with its careful selection of parameters. To ensure good performance of GA, the crossover and mutation should be adapted dynamically along the evaluation process.
In this paper, growth rate formula is used to express the change of the fitness size between generations.
Growth rate formula in Equation (1) normally use to know the average annual growth rate of the population. This gives more information than stating the exact population growth for the entire time, and allows for better prediction of future years of growth or decline for the population
The fitness function used consists of two parts. The first one measures the degree of interestingness of the rule, while the second measures its predictive accuracy. The degree of interestingness of a rule, in turn, consists of two terms. One of them refers to the antecedent as in Equation (3) of the rule and the other to the consequent as in Equation (4).
AntInt is the degree of interestingness of the rule antecedent.
ConsInt is the degree of interestingness of the rule consequent.
InfoGain(Ai) gives the information gain of attribute Ai
|dom (G) | is domain cardinality (i.e., the number of possible values) of the goal attribute G k occurring in the consequent.
Pr (G l ) is the prior probability (relative frequency) of the goal attribute value G l .
β is a user-specified parameter, empirically set to 2 in our experiments, can be regarded as a way of reducing the influence of the rule consequent interestingness in the value of the fitness function.
PredAcc is the predictive accuracy of the rule.
|A&C| is the number of examples that satisfy both the rule antecedent and the rule consequent.
|A| is the number of examples that satisfy only the rule antecedent.
W1 and W2 are user-defined weights. In our experiment they are set to 1 and 2, respectively.
The computation of these two degrees of interestingness is described in [18].
The computation of these two degrees of interestingness is described in [19]. The second part of the fitness function measures the predictive accuracy (PredAcc – formula in Equation (5) of the rule.
Equation (6) gives the final fitness function. Where W1 and W2 are user-defined weights. They are set to between 1 and 2 in the experiment.
This formula was used in the FLC to adapt crossover and mutation probabilities (P c , P m ) as shown in the Fig. 2.
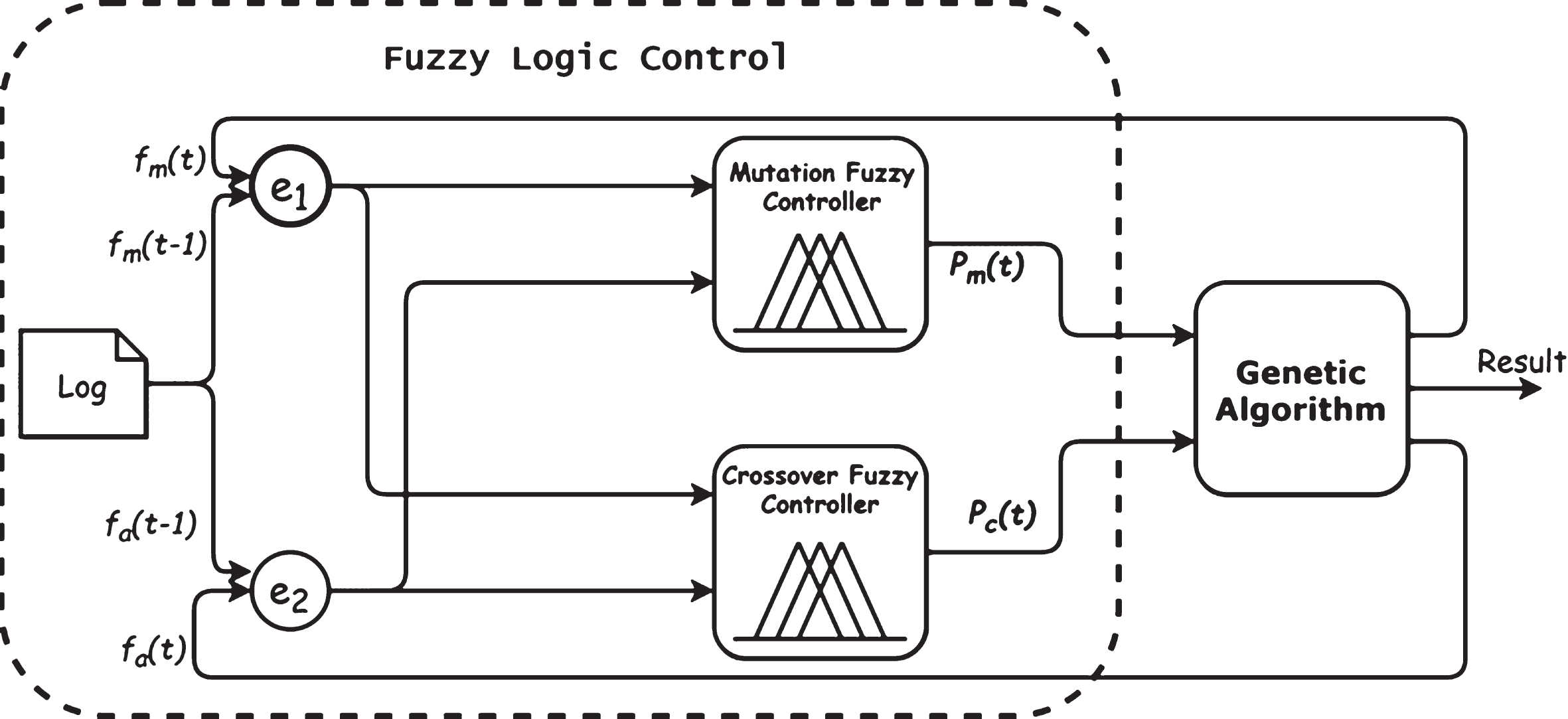
Fuzzy logic Controller.
FLC has two controller Mutation Fuzzy Controllers (MFC) and Crossover Fuzzy Controller (CFC) to adapt both mutation and crossover rates, respectively.
The use of MFC allowed to solve problems that occurs in GA that the optimal solution replicate the entire population. This problem occurs because the mutation initially selects a small number and remains constant throughout the development process, which means it is trapped in one solution area.
MFC helps to move the solution areas to a new area that might have better fitness rather than being trapped in one solution area. This is done by increasing the mutation whenever the difference between the previous and the current generation is decreased and vice versa.
To control the crossover rate, CFC is used to increase the crossover when the fitness average of current generation is the better than the previous, which will accelerate the exploration of solutions and guarantee faster convergence. Conversely, when the fitness average of the current generation is worse than the previous one, the crossover rate will decrease because it might destroy the high fitness individuals.
The best fitness in every generation is maintained by transferring a K number of the best individuals to the next generation, which means that the difference between best max fitness in the current and previous generations will be always positive or zero number.
Furthermore, both crossover and mutation rates are in the allowed defined ranges; (0.5=< crossover<1) and (0 > mutation < =0.2).
The reason of setting these ranges is that it is possible to destroy a high fitness individual when a large crossover probability is set; the performance of the algorithm would fluctuate significantly. For a low crossover probability, sometimes it is hard to obtain better individuals and does not guarantee faster convergence. High mutation introduces too much diversity and takes longer time to get the optimal solution. Low mutation tends to miss some near-optimal points [16, 17].
The rule base matrix of these controllers’ criteria is shown in Table 1. The control surface for these rules is shown in Fig. 3.
Fuzzy rule table for crossover and mutation rate change
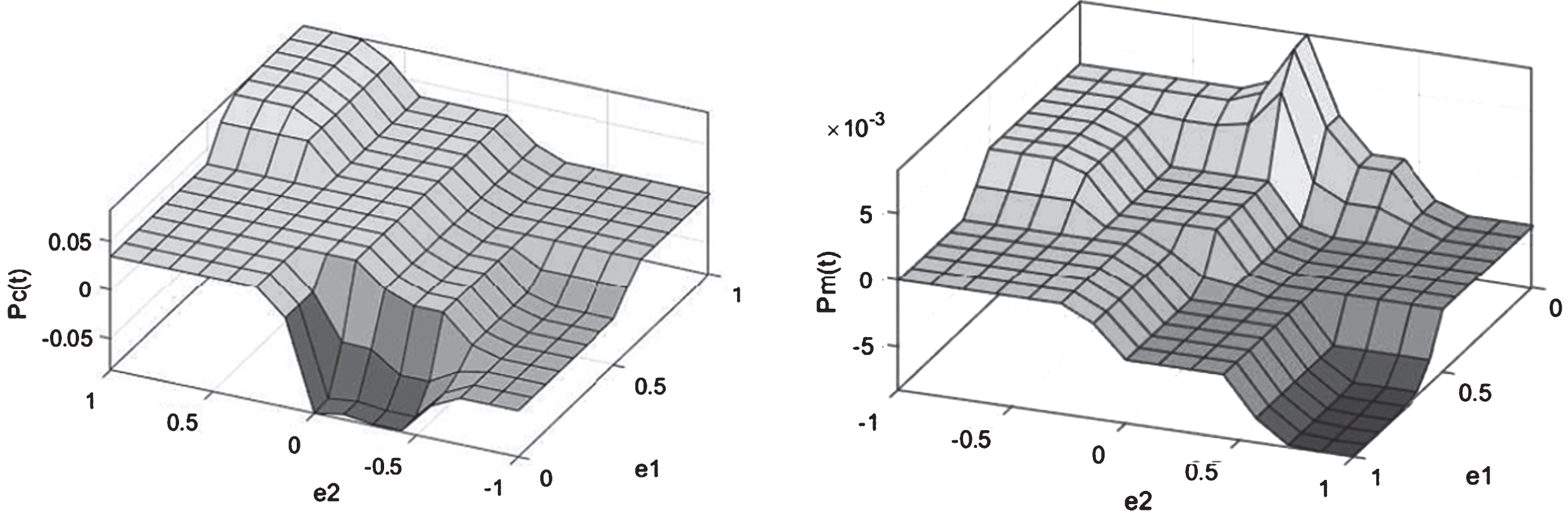
Control surface of P c and P m .
The membership function for ɛ1 and ɛ2 were distributed as shown in Figs. 4 and 5. While the membership function of the output p c is distributed with the same distribution of ɛ2, P m differed only from ɛ2 in the range of distribution. It was distributed among –0.01 to 0.01. In the defuzzification method center of gravity was used.
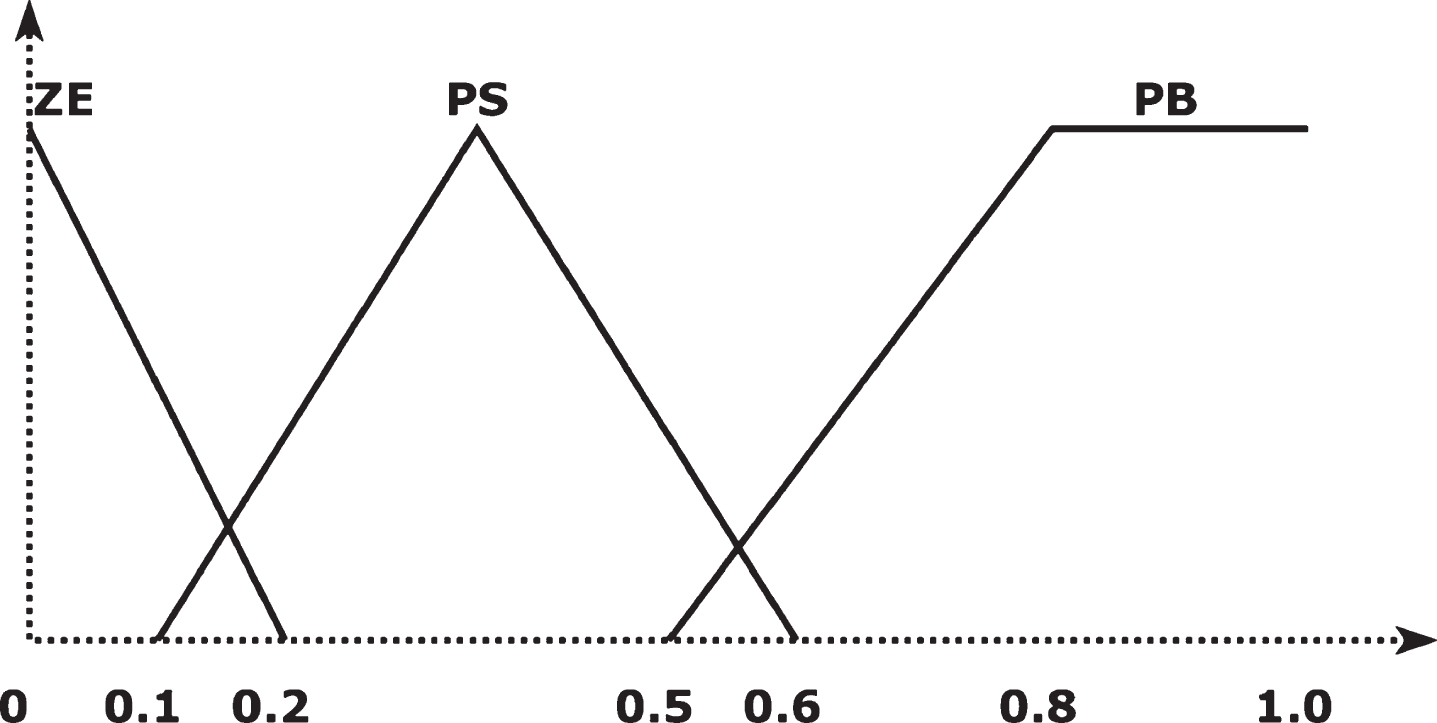
ɛ1 Member function.
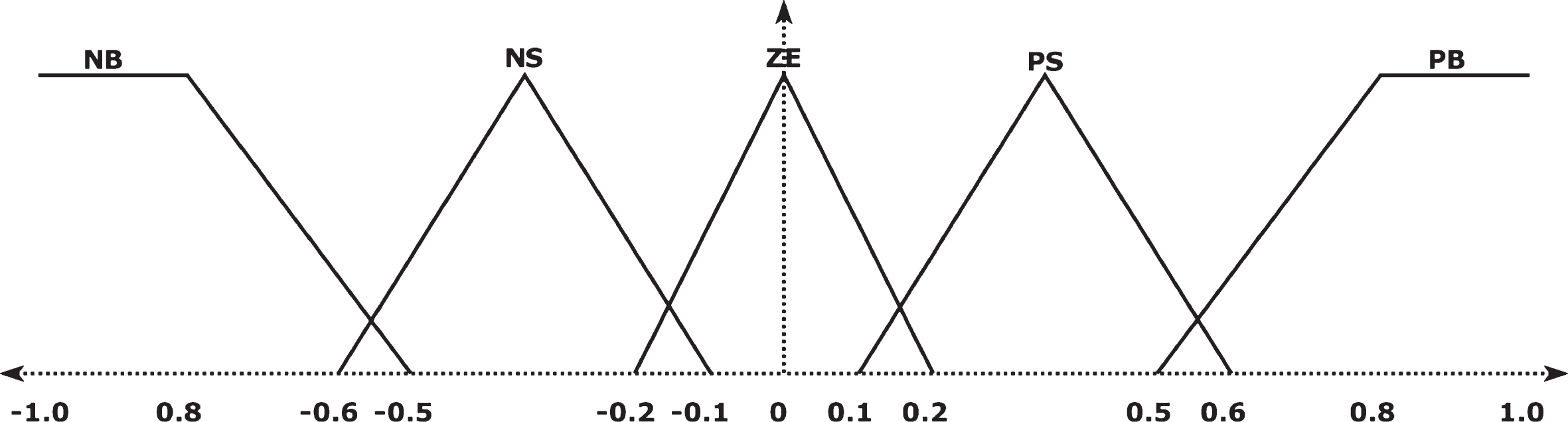
ɛ2 Member function.
In this study, a series of experiments were conducted to examine the performance of the proposed FGA in com-parison to the normal GA. Two different benchmark datasets from the UCI machine learning repository was used in these experiments. These datasets were Car evaluation dataset and Nursery dataset.
The car dataset consists of 1,728 instances with 6 attributes and the Nursery dataset consists of 12,960 instances with 8 attributes. Nursery dataset was developed to rank applications for admission procedures in public school systems in Ljubljana, Slovenia [18]. Table 2 shows the description of each dataset.
Car evaluation and Nursery datasets description
Car evaluation and Nursery datasets description
The system was built and simulated in C# and as well in MATLAB and then a comparison has been made, which shows same results.
From several experiments, the results of Table 3 show that maximum fitness in FGA gives the same results in all the experiments and it has the higher fitness for every class. The average fitness also shows a variation in the results and the difference between them and maximum fitness is big (between 0.027 and 0.202). Thus, indicating there is a diversity of solutions.
The result of 3 experiment of GA and FGA methods
Exp: Experiment, MF=Maximum Fitness and AF: Average Fitness.
While the results of the GA are different in each experiment, and maximum fitness results are always less than the results obtained in FGA. The results also show the average fitness is always equal or less than maximum fit-ness by very small difference which does not exceed 0.003. This indicates that the optimal solution replicates the entire population in GA results.
In Fig. 6, the graph shows examples of the results obtained for some classes and their comparison between GA and FGA. The summary of the results is follows:
In GA, The mutation and the crossover are constant and do not change across all generations. The average fitness is close to maximum fitness across all generations, it means that there is control over the optimal solution. The algorithm falls in local solutions and do not give the best solution globally. It takes many generations to reach the best maximum fitness. It took more than 700 generations in the class v-good in the car dataset and more than a thousand generations in the Nursery dataset class recom to get the maximum fitness (0.33). Plot of development process of the classes V-good and recom in GA and FGA.
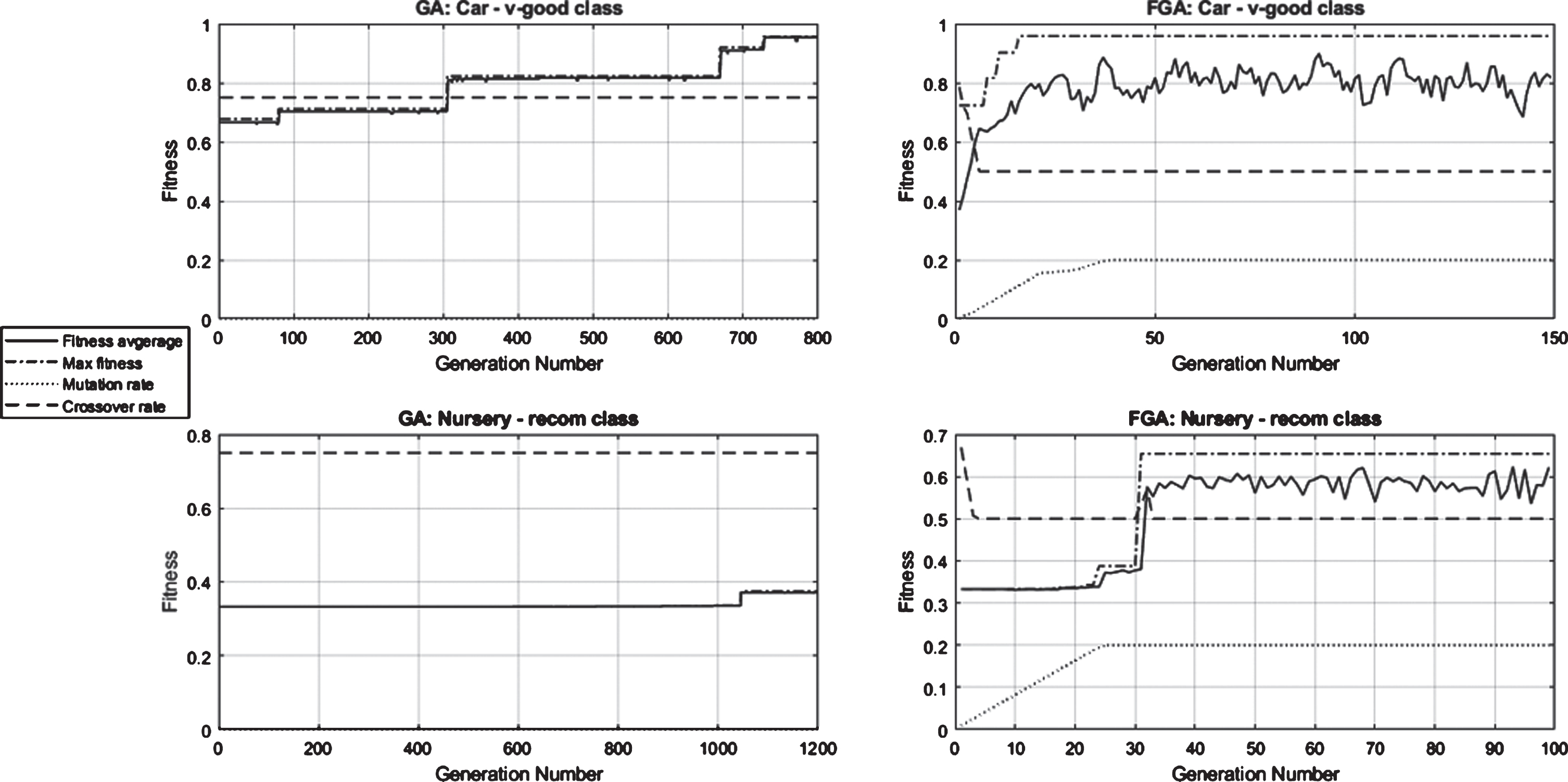
In FGA, Both crossover and mutation values are automatically updated along the development process until they reach an appropriate value and do not exceed the permissible limits of 0.5 and 0.2 for the crossover and the mutation, respectively. The average fitness value appears to be increasing and decreasing throughout the generations, thus confirm-ing the diversity of the population during the stages of the development of generations. Reaches the maximum fitness after a few stages of development of generations. In Fig. 6, the FGA in Nursery dataset class recom reach the maximum fitness value of 0.655 after just over than 30 generations and in the car dataset class v-good it reaches the maximum fitness after less than 20 generations only. There are diversity and change in population which has helped to find these solutions in a very short time compared to the GA, which means it give global solutions.
Similarly, the rules that were extracted from FGA are more logical and practical than GA rules in terms of rules results. Table 4 shows the best maximum fitness rules for each class in the dataset.
The highest maximum fitness rules of each class in GA and FGA
From car datasets the rule of the class v-good in FGA is more efficient than that of GA. Despite the almost equal maximum fitness between the two rules, the buying price is low is a common feature between the two rules, but the GA rule specifies the car with high maintenance. This is not logical because the car with high maintenance is always undesirable. While the feature luggage bot size is big and high safety is the other characteristic of the FGA rule.
Also, in the class un-Acc the fitness of the two rules converges, but rule in GA show us that safety is one of the most important features of accepting and rejecting a car. When safety is low even when luggage bot size is big this make the car unacceptable. However, the FGA rule gave unexpected knowledge that the car which just carried two persons do not accept even if it has only two doors. It is known that a car that carried two persons and has 3, 4 or more doors are not acceptable. The car with two doors and carried two persons are acceptable, but the FGA has given us a knowledge that contravenes the expectations of the car that carries a person even if the door is not acceptable.
In Acc class, the fitness was significantly different between GA and FGA, but in the features buying is high and safety is high are shared between the two rules. However, the FGA was distinguished from the GA by maintenance cost. Low cost maintenance is acceptable in FGA while the high cost maintenance in GA rule. In addition, the car must be big size luggage bot and carried more persons in GA.
In Nursery dataset we find that in the class not_rec the fitness of the two rules in GA and FGA is almost equal and share the features social and health. This indicates that these two features are the most important features in determining this class. The two rules differed in the value of the feature finance, and a new feature emerged of each case such as the house condition in FGA and the number of children in GA. It is generally observed that these two features were characterized by each situation.
The number of children in the GA was defined in three classes (not_rec, Very Recom, and priorty) and it was only specific in one class in FGA (recom). While the housing conditions for the applicant is specific attribute in 4 classes in FGA (not_rec, recom, Very Recom, and spec_peri), whereas in GA it was not a specific attribute only in the class Very Recom. This indicates that the determination of the classes in the FGA is considered important for housing conditions, while the number of children is an important feature in determining the GA classes.
The recom class in the total Nursery dataset, it is only existing in two instances, while in GA this class maximum fitness gets after more than thousand generations with poor fitness (0.336) and in the rule only one at-tribute is defined (if form is complete) and this feature is common with other classes and cannot be precisely de-fined only by this class. While in the FGA the rule was defined by more than one feature, and identify the class precisely, and with fitness (0.665). This rule has been devised in less than 35 generations as shown in Fig. 6.
This piece of work gives an integrated fuzzy logic and GA method and the use of growth rate function to calculate the change of the maximum fitness and the average fitness between two continuous generations to adapt dynamically crossover and mutation parameters of GA. A sequence of experiments was performed to show better performance of the proposed method over existing GA. The experiment evaluates two different datasets to extract interesting and accurate rules. The comparison results showed the proposed technique gives high performance and more accurate in terms of maximum fitness and average fitness. The proposed method generates same results in all the experiments, and it has the higher fitness for every class. Similarly, the average fitness also shows a variation in the performance and the difference between them and maximum fitness was big (between 0.027 and 0.202). Therefore, indicating that there is a diversity of solutions. The results generated by GA were different and always less than proposed method in each experiment. The same variation was also seen in case of average fitness.
Moreover, the normal GA spends more time and fail usually in the local optimal solutions while the FGA converges quickly to find the global optimal solutions and spends very less time and improving the performance. Also, the rules that extracted using FGA have high fitness than GA rules and more logical. Further, applying the integrated fuzzy logic and GA method needs much less computational efforts and it requires very time consuming to solve the problems. In addition, this method does not have the common problems existing in the GA/traditional fuzzy logic.