
Abstract
The Meteosat Second Generation (MSG) satellite can be used to estimate rainfall through the multispectral images, which are provided every 15 min across 12 channels. However, most studies have not maximized the terabytes of data provided by the channels in this satellite, which are potentially rich in new resources that need to be exploited. Moreover, these studies classify pixels conventionally, where a pixel is considered either 100% precipitant or 0% (no-precipitant), whereas actually it cannot be classified in a clear and unambiguous way. To address this problem, we propose a method that exploits the images of the channels and constructs an estimation model in the form of fuzzy association rules to estimate the rainfall in Northeastern Algeria. Each rule is in if (condition)-then (conclusion) form, where the condition is a combination of the various fuzzy classes of MSG images, and the conclusion contains a single fuzzy class that represents the intensities of rain: no-rain, low, moderate, and high. The obtained results are compared with the data obtained by the European Organization for the Exploitation of Meteorological Satellites Multisensor Precipitation Estimate program.
Introduction
Rainfall is an important meteorological parameter. However, evaluating and measuring rainfall are difficult, especially in areas such as deserts, seas, oceans, and mountains. The vast spatial coverage of satellites allows us to provide data anywhere in the world. Several methods have been developed for estimating precipitation using these satellites’ data. Some methods [1–6] use infrared/visible information (IR/VIS) to find the relationship between the satellite information and the observed amount of rainfall measured on the ground. Microwave methods [7, 8] use satellite measurements that are obtained in microwaves. Other methods [9–11] that combine infrared data and microwave data exploit the advantages of the two previous methods. The MSG [12] is a satellite that estimates precipitation through its 12 channels. Many MSG satellite methods have been developed to estimate the rainfall. For instance, Lazri et al. in [13] presented a new method based on an artificial neural network (ANN) to identify precipitating clouds during day and night from MSG satellite data. The inputs of the ANN are the data of the MSG satellite, and the outputs of the used ANN method are the two classes (rain, no-rain) of the Sétif radar (Algeria). Ouallouche et al. in [14] also presented a method based on the ANN to delineate rain zones; they used four parameters from the infrared channels of the MSG satellite and three parameters from the Tropical Rainfall Measuring Mission (TRMM) satellite as inputs of the ANN method, and the outputs of the ANN method are the two classes (rain, no-rain) of the Precipitation Radar TRMM data. In [15], Bensafi et al. proposed a k-nearest weighted neighbor (WKNN)-based method to determine pixel rainfall intensity levels. A new rainfall estimation technique was introduced by Ouallouche et al. in [16], which is based on the random forest (RF) algorithm. The RF has two main parts: classification and regression, which are receptively performed on the MSG-retrieved data. The RF classifies the MSG images according to the rain rate type of precipitation (i.e., convective and stratiform) to three classes (no-rain, convective, and stratiform), whereas the RF regression is used to assign the rain rate of the pixels belonging to the convective and stratiform classes. Thies et al. [17] presented a method to identify cloud precipitation during daytime using data from the MSG satellite; their developed technique uses the reflectances in the channels VIS0.6 and NIR1.6 to obtain information about the cloud liquid water path and the differences in brightness temperature △TIR8.7 - IR10.8 and △TIR10.8 - IR12.0. The same authors developed another method [18] for identifying precipitating clouds in night stratiform systems from multispectral MSG satellite data; they used the brightness temperature differences, namely, △TIR3.9 - IR10.8, △TIR3.9 - WV7.3, △TIR8.7 - IR10.8 and △TIR10.8 - IR12.0. Roebeling and Holleman in [19] presented an algorithm based on clouds’ physical properties using multi-spectral data from the MSG satellite to detect precipitation and estimate rain rates. Feidas and Giannakos [20] developed two methods for delineating rain zones using brightness temperature differences of the IR10.8 with WV6.2, IR8.7, and IR12.0 channels. They also proposed two methods [21] that can detect precipitating clouds and identify convective and stratiform clouds using the same aforesaid brightness temperature differences.
The previously cited methods have given satisfactory results. However, most of these methods do not fully exploit the data from some channels. In addition, the classification of the data is done by means of the precipitating and non-precipitating pixels in a conventional way, which is not always consistent with reality. Classifying a pixel as precipitating or not is difficult and to address this, we introduce the fuzzy set theory proposed by Lotfi Zadeh [22] because it allows for the management of measurements of imprecise data and inexact notions. In addition, the National Office of Meteorology (ONM) in Algeria has accumulated a very large volume of MSG images. Therefore, data can be extracted through the application of the association rules to search for possible hidden correlations among the data from these images. The use of Knowledge Discovery in Databases (KDD) techniques, such as association rules, can help us discover and extract interesting relationships among MSG image data. The most appropriate method to clearly and explicitly predict these correlations is the association rules, which provides a convenient and effective way to discover and represent certain dependencies and relationships among attributes in a database [23]. Moreover, association rules are widely used in production systems because of their very rigorous formalism (condition → conclusion), in addition to their very high explanatory or semantic level compared with other techniques, such as neural networks, which are often called black boxes (low explanatory level). The estimation and explanation of meteorological phenomena, such as precipitation, are the main objectives of our research. This estimate is not accurate; thus, fuzzy association rules based on fuzzy set theory are useful. Then, we propose in this work a method that exploits multispectral data from 11 channels of the MSG satellite (excluding the HRV channel). Moreover, instead of using crisp models to estimate the prevision of the rainfall in Northeastern region of Algeria, a new model based on the fuzzy association rules is developed to find and extract correlation information among the images of these channels. Furthermore, the proposed fuzzy method is compared to the Multisensor Precipitation Estimate (MPE) product, where the obtained comparison results demonstrate the effectiveness and the performance of this fuzzy method.
Our paper is organized as follows. Section 2 contains basic notions on association rules and fuzzy association rules. Our proposed method is described in detail in Section 3. In Section 4, we present the experimental results to evaluate the performance of the proposed method. Finally, we conclude and give research prospects in Section 5.
Basic notions
Association rules
The association rules is a method introduced in 1993 by Agrawal et al. [24], wherein; the apriori algorithm [25] gives a number of rules based on support and confidence, selecting frequent rules and ignoring rules that have less than minimum support and minimum confidence. Their definitions are as follows.
The discovery of association rules by the a priori algorithm [25] and its variants were designed only for Boolean databases. We placed the value “0” in the transactional database if an element does not belong to the set; otherwise, we place the value “1”. By contrast, with Zadeh’s theory of fuzzy sets [22], an element can belong to more than one fuzzy set to different degrees. Fuzzy association rules are an extension of association rules based on fuzzy subsets theory, allowing reasoning on quantitative attributes. The fuzzy-based definitions of the aforesaid original crisp association rule, support, and confidence are as follows.
To calculate the fuzzy support of a fuzzy itemset and the fuzzy confidence of a fuzzy association rule, two fuzzy operators are used: (1) the t-norm operator (denoted as ⊤): this operator is considered the minimum in [26–28] and (2) a fuzzy cardinality based on the α-cuts [29], which represents a threshold membership function. For this reason the new definitions for the support of a fuzzy itemset and the confidence of a fuzzy association rule are the following.
where |T| is the number of transactions in the database T and α represents the threshold membership function of the following equation:
where μ X (t i [A]) is a vector of l fuzzy values; l indicates the number of items in the itemset A, and each fuzzy value of this vector represents the membership degree of each item a i,(i=1…l) ∈ A to its associated fuzzy set x i,(i=1…p) ∈ X. α-cut is a minimum threshold membership degree defined by the user.
A flowchart of our proposal is illustrated in Fig. 1. As seen from this figure, our proposed method contains three main components, which are (1) transactional database creation, in which two types of images,i.e., MSG and MPE, are used for creating the initial transactional database; (2) fuzzy transactional database creation, which is responsible for transforming the initial created crisp transactional database into a fuzzy one through the use of trapezoidal membership functions and fuzzy c-means algorithm (FCM) [30], and (3) fuzzy association rules extraction, where the fuzzy association rules are extracted using an extended version of the original apriori algorithm [25] by using the aforesaid definitions of the fuzzy support of a fuzzy itemset and the fuzzy confidence of the fuzzy association rule. In the following, we describe each component in detail.

Flowchart of our proposed method
In our study, 12 attributes (items) are considered for creating the transactional database, where the first attribute represents the MPE images (denoted as rainfall attribute) and the others represent the MSG images, except for the HRV image, which has different dimensions compared with the others. The channels’ names are regarded as names for the considered attributes. Each MSG image is composed of a set of pixels, and every pixel value represents the intensity of the rays reflected by the clouds or the Earth’s surface measured by the Spinning Enhanced Visible and InfraRed Imager (SEVERI) sensor [12] in different spectral bands. The pixel intensity is digitally encoded on 8 bits; hence, its value (i.e., gray level) is a numerical number that lies in the interval [0, 255], where 0 represents the black color and 255 indicates the white color.
To construct the transactional database, we assign to the attribute IR10.8 the image pixel values of the thermal infrared channel IR10.8 whose temperatures values are less than -35°C [4], which is the minimum cloud top temperature, and represents a high possibility rainfall. The temperature of each IR10.8 image pixel value (CN
IR10.8) is calculated according to Equation (6) [31]. Then, for each uploaded CN
IR10.8 at a date-time (dt) with the pixel coordinates (x, y) corresponding to the created database’s transaction (t), we load the pixel values of the other considered MSG images and the rainfall amounts (RA) of the MPE images into their related attributes for the same database’s transaction t by considering their images, which are taken at the same date-time dt. Their related pixels have the same CN
IR10.8’s coordinates. In Equation (7), the RA of each MPE image is calculated as defined by the European Organization for the Exploitation of Meteorological Satellites (EUMETSAT).
To create a fuzzy transactional database (FTD) from the initial crisp one, we divide the universe of each quantitative attribute into several fuzzy subsets. Moreover, each attribute of the crisp transactional database (CTD) is associated with its related fuzzy subset to form fuzzy items for the FTD. To calculate the new values of the FTD’s fuzzy items, the crisp values of each CTD’s attribute are transformed into their fuzzy values (membership degrees) according to their related trapezoidal membership functions for the rainfall and visible attributes (VIS0.6, VIS0.8, NIR1.6), as well as the FCM algorithm for the infrared attributes (IR3.9, WV6.2, WV7.3, IR8.7, IR9.7, IR10.8, IR12.0, and IR13.4). In the following, the number of FTD’s fuzzy items (i.e., the number of fuzzy subsets for each CTD’s attribute) is determined, and the fuzzy value definition for each fuzzy item is presented.
Fuzzy item number definition
For each CTD’s attribute, the number of its fuzzy subsets is defined as follows.
Visible channel attributes: The pixel values for the images of the visible channel attributes, which represent the images’ brightness, vary between [0, 255]. To create the fuzzy subsets of the visible channel attributes in our study, we propose to divide this brightness interval into five fuzzy subsets as follows: [darkly, dark, medium-bright, bright, brightly]. For this reason, we use five trapezoidal membership functions to represent these fuzzy subsets, as shown in Fig. 2. Consequently, for each visible channel attribute in CTD, five associated fuzzy items are created in the FTD.
Fuzzy partition of the brightness of the visible attributes with 5 functions of trapezoidal membership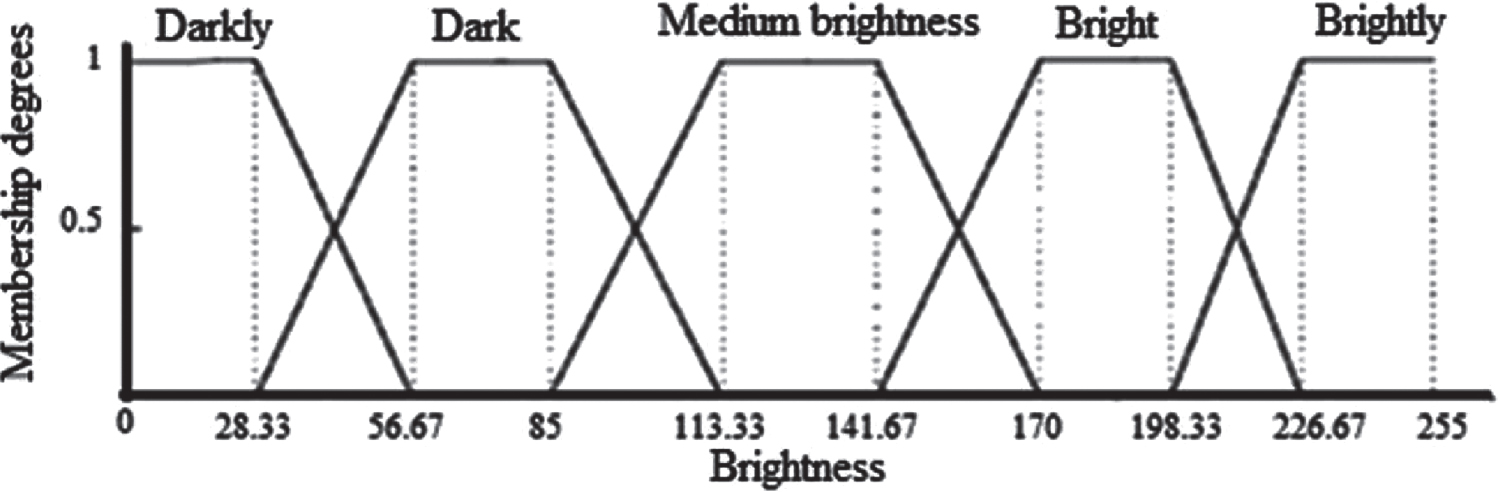
Rainfall attribute:
Rainfall amount in Algeria

Fuzzy subsets of the rainfall attribute with four Trapezoidal membership functions
Infrared channels attributes: For the rainfall attribute, the number of fuzzy subsets is defined by the experts (i.e., ONM), whereas its value for the visible channels attributes is determined according to the brightness knowledge of the MSG images (In our study, we propose five subsets). However, in the case of the infrared channel attributes, the number of fuzzy subsets is ambiguous because we do not have any expert information about its linguistic term sets. Hence, we need to use fuzzy algorithms to define the number of fuzzy subsets for each infrared channel attribute. In our study, the well-known FCM [30] algorithm and the validity index [32] are used to define the number of fuzzy subsets (clusters) for each CTD’s infrared attribute. The number of clusters is between a minimum number (C
min
≥ 2) and a maximum number (C
max
), which are defined by the user. According to Bezdek [33], C
min
= 2 and
Step 1. For C
i
=
Step 1.1 Apply the FCM algorithm using the inputs C i and E i .
Step 1.2 Calculate the validity index (V C i ) [32].
Step 2. The optimal number of clusters C i is related to the V C i with the maximum value.
The following two notations are considered:
[VR, FS] is a fuzzy item for the visible/rainfall attribute VR with its associated fuzzy subset FS. For example, [VIS0.6, Brightly] is a fuzzy item for the visible attribute VIS0.6 with its associated fuzzy subset ‘Brightly’.
[IR, C (cr)] is a fuzzy item for the infrared attribute IR with its associated fuzzy subset C, where cr is a real value that represents the center value of the cluster C. For example, [IR12.0, C2 (47.28)] is the fuzzy item for the attribute IR12.0 related to the cluster C2, which has the center value of 47.28.
To calculate the membership degrees of each [VR, FS], we use 5 trapezoidal membership functions (see Fig. 2) for each VR ∈ VIS0.6, VIS0.8, NIR1.6 and 4 trapezoidal membership functions (see Fig. 3) for the rainfall attribute. While, for evaluating the membership degrees of each [IR, C (cr)], the FCM algorithm is used.
Fuzzy association rule extraction
Our aim is to extract fuzzy association rules in condition ⇒ conclusion form, where the right part (conclusion) of each generated rule has only one fuzzy item, which is described as [rainfall, FS], where FS ∈ {no-rain, low, moderate, high } are the fuzzy subsets associated with the rainfall item. To extract these fuzzy association rules, two steps should be followed. First, an extended version of the apriori algorithm [25] is used to find the list of the frequent fuzzy itemsets from the created fuzzy transactional database FTD. Second, the fuzzy association rules are generated using the found frequent fuzzy itemsets. The descriptions of these two steps are presented in the following subsections.
Identification of frequent fuzzy itemsets
To find the list of frequent fuzzy itemsets (LFFI), we adopt the apriori algorithm in our fuzzy rainfall estimation. Originally the canonical apriori algorithm is introduced to deal with crisp itemsets. However, in our method, the items are described as fuzzy items. Hence, the canonical apriori algorithm needs to be extended, where its crisp support formula is replaced by the defined fuzzy-based formula, which is given in Equation (3). The extended version of the original apriori algorithm, which is called fuzzy apriori algorithm, is given in pseudocode format in Algorithm 1.
- FTD: The fuzzy transactional database.
- Mfs: The minimum fuzzy support.
- α-cut: The minimum threshold of membership in a fuzzy subset.
- LFFI: list of frequent fuzzy itemsets.
1: L 1 ={Frequent fuzzy 1-itemsets}
2:
3: C k ← apriori - gen (L k-1) ⊳Candidates of fuzzy K-itemsets.
4:
5: C t = subset (C k , t, α - cut)
6:
7: c . supp = + ⊤ (α X (t [A])) ⊳ ⊤ (α X (t i [A])): is the minimum fuzzy value for the membership degrees of the fuzzy items (A,X) relating to the fuzzy itemset c in the transaction t.
8:
9:
10:
11:
12: LFFI = ⋃ k L k
As shown from this algorithm, the frequent fuzzy 1-itemset is generated in line 1 by calculating the fuzzy support for each fuzzy item of FTD, and only keep those fuzzy items that satisfy the minimum fuzzy support (Mfs). After that, steps 2 to 10 are repeated until the stopping criterion is stratified (i.e. L k =∅). In each iteration cycle k of this algorithm, the function apriori - gen (L k-1) generates a set of candidate fuzzy k-itemsets denoted as C k through the joining of the previous frequent fuzzy (k-1)-itemsets L k-1 with itself. In the C k set, we delete each fuzzy itemset c, which has not a frequent fuzzy subset with k - 1 length in the L k-1 set, and we prune also the not valid fuzzy itemsets. In order to find the L k set from the C k set, at first, for each transaction t from the FTD database, a set of fuzzy itemset C t is created from C k by considering only the C k ’s fuzzy itemsets, which satisfy the minimum threshold of membership in a fuzzy subset (α-cut) threshold. At second, for each c ∈ C t we calculate its fuzzy support c . supp and finally the L k is created by saving just the c fuzzy itemsets that have c . supps greater or equal than Mfs.
To clarify the aforesaid fuzzy apriori algorithm, the example of Figure 4 describes how to find the frequent fuzzy itemsets LFFI = ∪ k L k . Given the FTD as shown in Figure 4 where the first column indicates the number of the FTD’s transaction and the other columns of this table represent three items (Item 1, Item 2 and Item 3) which are associated with their fuzzy subsets (FS1.1 to FS3.2). The two parameters Mfs and α-cut are set with the values of 0.25 and 0.5 respectively. The first step is to find the 1-fuzzy itemset (L 1), which contains all the fuzzy items of the candidate list C 1 where their fuzzy support are greater than Mfs (i.e. The non frequent fuzzy itemsets of C 1 with gray colors are not considered to generate L 1). Next, each C k , k = 2, 3, . . is generated using its list of frequent fuzzy itemsets l k-1. For example the candidate list C 2 is produced by performing the join operation between the fuzzy set L 1 and itself (i.e. C 2 = L 1 ⋈ L 1 = {(1) , (4) , (6) , (7)} ⋈ {(1) , (4) , (6) , (7))} = {(1 4) , (1 6) , (1 7) , (4 6) , (4 7) , (6 7)}), however the last fuzzy itemset (6 7) is not a valid fuzzy itemsets (i.e. See the cell drawn using a thin dashed border) because the two fuzzy itemsets 6 and 7 have the same attribute Item3. Therefore we prune it from C 2. To find L 2, we calculate the fuzzy supports of C 2 (e.g), after that L 2 is created by adding to it those fuzzy itemsets from C 2, where their FSs ≥Mfs. The same aforesaid process (Join and Prun) is applied to generate C 3 by using L 2, where the fuzzy itemset (1 6 7) is omitted from C 3 because it is not a valid fuzzy itemset. Furthermore, the fuzzy itemset (1 4 7) (See the cell drawn using a bold dashed border) is also removed because it contains a fuzzy itemset (4 7), which is not a member of L 2. As result LFFI = L 1 ∪ L 2 ∪ L 3 = {(1) , (4) , (6) , (7)} ∪ {(1 4) , (1 6) , (1 7) , (4 6)} ∪ {(1 4 6)}.

An example of generating the list of fuzzy frequent itemsets using the fuzzy apriori algorithm
To extract the list of fuzzy association rules (LFAR), Algorithm 2 is used to generate this list from LFFI, which is created by fuzzy apriori algorithm 1.
- LFFI: list of frequent fuzzy itemsets.
- Mfc: The minimum fuzzy confidence.
- α-cut: The minimum threshold of membership in a fuzzy subset.
- LFAR: list of fuzzy association rules.
1:
2:
3:
4: Generate the fuzzy association rule FAR from (A, X) as follows: (A, X) - [rainfall, FS] ⇒ [rainfall, FS]
5: Calculate the confidence Conf FAR of FAR using equation (5)
6:
7: LFAR = LFAR ⋃ FAR
8:
9:
10:
11:
As shown from the pseudo-code format of the fuzzy association rules extraction given in Algorithm 2, we take only the fuzzy itemsets (A, X) of the lists L k with k ≥ 2 and contains the fuzzy item [rainfall, FS], where A represents the list of the used attributes, X indicates their associated fuzzy subsets and FS = {low, moderate, high, no-rain} are the fuzzy subsets associated with the rainfall item. For each taken itemset (A, X), generates its fuzzy association rule FAR as follows: (A, X) - [rainfall, FS] ⇒ [rainfall, FS] and calculates its fuzzy confidence Conf FAR . If Conf FAR ≥ Mfc, we add FAR to the final list LFAR, where Mfc is the minimum fuzzy confidence, which is defined by the user.
Given the list LFFI = L 1 ∪ L 2 ∪ L 3 = {(1) , (4) , (6) , (7)}∪ {(1 4) , (1 6) , (1 7) , (4 6)} ∪ {(1 4 6)}, which is generated by the fuzzy apriori algorithm for the example shown in figure 4, and considering Item2 as the rainfall attribute, where their associated fuzzy subsets are FS2.1, FS2.2 and FS2.3; hence the fuzzy items including the attribute rainfall are [Item2, FS2.1], [Item2, FS2.2] and [Item2, FS2.3] which are represented by the numbers 3, 4 and 5 respectively. From LFFI, only the frequent fuzzy itemsets (A, X)s= {(1 4) , (4 6) , (1 4 6)} are considered to generate the fuzzy association rules, because L 1 is a fuzzy 1-itemsets list and (1 6) , (1 7) are fuzzy 2-itemsets that do not contain at least one of the fuzzy items described by the numbers 3, 4 and 5. Herein, the generated fuzzy association rules are FARs={1 ⇒4, 6 ⇒ 4, (1 ∧6) ⇒4}, where ∧ indicates the fuzzy conjunction operator. As seen from this list, each FAR is generated from its related (A, X) by assigning to the right part (conclusion) of the FAR only one fuzzy item, which is [rainfall, FS] and the left part (condition) of FAR are all the fuzzy items of the associated (A, X) except for the fuzzy item, which is given to the conclusion part of this FAR. For instance, (1 ∧6) ⇒4 is a FAR generated from the fuzzy itemset (1 4 6), where its conclusion is the fuzzy item [Item2, FS2.2], which is represented by the number 4. By using equation (5), where Mfc = 0.65 and α-cut=0.5, the confidences of each generated FAR are calculated and only the FARs that have confidences greater or equal than the defined Mfc are considered to construct the final list LFAR. The confidence values of the generated FARs for the aforesaid example are: Conf 1⇒4 = 0.68, Conf 6⇒4 = 0.59 and Conf (1∧6)⇒4 = 0.84; therefore LFAR = {1 ⇒ 4, (1 ∧6) ⇒4}.
Experimental results
In this section, to verify and validate the effectiveness of our proposal, two real databases are used. the first one is adopted to train (learn) the proposed model (fuzzy association rules), and the second one is used to validate the trained model. The description of the used databases is given in the Data sets subsection. Then, the trained model is presented in the subsection model construction. In the final subsection (Model validation), we validate the generated model by performing an effective comparison against MPE, which is a very useful product for estimating rainfall.
Data sets
In our study, we select the northeastern region of Algeria for rainfall estimation because it is the most precipitous region according to the ONM. It is located between 34.5° Northern and 37° Northern, and between 3.5° Western and 9° Eastern. Two databases are considered to create and validate the proposed model for estimating the rainfall of the selected region. For this reason, the databases are created by collecting the SEVIRI’s images from 11 of the multispectral channels of the MSG satellite (except for the HRV channel) and the images of the MPE product. In our study, we choose the rainy period to collect the aforesaid images, which are collected from October 1,2016 to March 31, 2017, where the images are acquired every 15 min from 8:00 to 16:00. For each hour, the first database (denoted as TrainDB), which is used to train the developed model, is created by assigning to TrainDB the images acquired in the minutes (00, 15, 30). Meanwhile, the second database (denoted as ValidDB), which is used for validating our proposal, is constructed by recording to ValidDB the images acquired at 45 min.
Model construction
To extract the list of fuzzy association rules (model), the database TrainDB is used to learn the constructed model. The FCM [30] algorithm and the validity index [32] are used together to define the number of the fuzzy subsets for the infrared attributes, and their fuzzy values. The FCM’s parameters are set as follows. The used distance is the Euclidean distance, the fuzziness exponent m = 2, and the stopping criterion epsilon ξ = 0.001. The C min and the C max parameters are initialized with values of 4 and 10, respectively. The generated model is constructed using the fuzzy apriori algoithm given in Algorithm 1 and the fuzzy association rule extraction given in Algorithm 2; their parameter settings are as follows: the minimum fuzzy support Mfs = 0.1, the minimum fuzzy confidence Mfc = 0.7, and the minimum threshold of membership in a fuzzy subset α-cut = 0.67.
Fuzzy supports for each fuzzy item of the rainfall attribute
Fuzzy supports for each fuzzy item of the rainfall attribute
In the fuzzy apriori algorithm, we start by generating the 1-itemsets list (L 1), which contains the first list of the fuzzy frequent items. This list is determined by taking only the fuzzy items with fuzzy supports higher than the defined Mfs. In our study, to have fuzzy association rules in the form of condition⇒ [rainfall,FS], where FS ∈ {no-rain, low, moderate, high}, the list L 1 should have all the fuzzy items of the rainfall attribute. However, and especially for our region study, the frequency value of the rain precipitation with a high or moderate levels is very small compared with the frequency value of the low or no-rain precipitation levels. Therefore, the fuzzy supports of the two fuzzy items [rainfall, moderate] and [rainfall, high] have very low values compared with the fuzzy supports of the [rainfall, low] and [rainfall, no-rain] fuzzy items. For instance, as shown in Table 2, which represents the fuzzy supports for the fuzzy items of the rainfall attribute given by performing our proposed method on TrainDB, the fuzzy support values of the two fuzzy items [rainfall, moderate] = 0.04 and [rainfall, high] = 0.02, which are less than the Mfs = 0.1 (not frequent fuzzy items); thus, fuzzy association rules in the form of condition ⇒ [rainfall,moderate] or condition ⇒ [rainfall,high] cannot be obtained.
To solve this problem and to construct a model with a list of fuzzy association rules that can decide from each pixel (database’s transaction) its related rainfall fuzzy subset (i.e., no-rain, low, moderate and high), we need to generate four sublists of fuzzy association rules for each rainfall fuzzy item. The final list of the fuzzy association rules (LFAR) for the constructed model is the regrouping of these generated fuzzy sublists. The initial fuzzy database is denoted as FtrainDB, which is provided from the TrainDB by running our proposed method. The following steps are performed to generate (LFAR).
Step 1. For i =1 to 4 do //where i represents the index value of each generated fuzzy sublist.
Step 2. Calculate the fuzzy supports for the fuzzy items of the rainfall attribute. Step 3. Sort in ascending order the fuzzy items of the rainfall attribute according to their fuzzy support values. Step 4. Generate the fuzzy sublist of the fuzzy association rules SL
i
of the fuzzy item rainfall, which has the greatest fuzzy support by performing Algorithms 1 and 2 on the FtrainDB, where the Mfs and Mfc parameters are set with new values. Step 5. Update the FtrainDB by eliminating the transactions of this fuzzy item that have degrees of membership greater than α-cut. Step 6. LFAR = LFAR ⋃ SL
i
Tables 3–6 represent the four fuzzy sublists of the constructed model (i.e., LFAR). In our study, to select the rainfall fuzzy subset for any transaction of the validated database, the rules are checked from the first fuzzy sublist (SL
1) to the last one (SL
4), and the first verified fuzzy association rule is applied to define the fuzzy subset of this transaction.
List of the fuzzy association rules for the fuzzy item [rainfall, no-rain] with Mfs = 0.14 and Mfc = 0.74.
Fuzzy items labeling: 21:[NIR1.6,dark], 36:[WV7.3,C4(63.830)], 40:[IR8.7,C4(73.203)] 48:[IR10.8,C4(71.075)],52:[IR12.0,C4(68.569)], 56:[IR13.4,C4(60.506)] 60:[Rainfall, no-rain]
List of the fuzzy association rules for the fuzzy item [rainfall, low] with Mfs = 0.12 and Mfc = 0.95.
Fuzzy items labeling: 12:[VIS0.6, medium bright],18:[VIS0.8, bright], 21:[IR1.6, dark] 31:[WV6.2, C3(48.667)],35:[WV7.3, C3(55.399)],39:[IR8.7, C3(63.396)] 47:[IR10.8, C3(61.174)],51:[IR12.0, C3(58.792)], 55:[IR13.4, C3(52.706)] 57:[Rainfall, low]
List of the fuzzy association rules for the fuzzy item [rainfall, moderate] with Mfs = 0.12 and Mfc = 0.8.
Fuzzy items labeling: 30:[WV6.2, C2(41.189)], 34:[WV7.3,C2(45.983)], 46:[IR10.8, C2(49.931)] 50:[IR12.0, C2(47.281)],54:[IR13.4, C2(43.738)], 58: [Rainfall, moderate]
List of the fuzzy association rules for the fuzzy item [rainfall, high] with Mfs = 0.19 and Mfc = 0.65.
Fuzzy items labeling: 22:[NIR1.6, medium bright], 33:[WV7.3, C1(31.673)] 37:[IR8.7,C1(36.413)], 41:[IR9.7,C1(44.919)],45:[IR10.8,C1(33.617)] 49:[IR12.0,C1(30.129)], 59:[Rainfall,high]
Number of pixels of each fuzzy item of the rainfall attribute for each α-cut
To evaluate the performance of the proposed fuzzy rainfall estimation method, we compare the rainfall estimation results obtained applying the constructed model on ValidDB against the rainfall estimation results obtained by the MPE product on the same ValidDB database. Herein, the MPE product is chosen for validating our proposal, because it is ranked as the best rainfall estimator.
For each fuzzy subset of the rainfall attribute and by varying the α-cut value from 0.80 to 0.50 by a decreasing value of 0.05, we calculate the estimated number of pixels found by our method (NP_M), the estimated number of pixels found by the MPE product (NP_MPE), and the number of valid pixels obtained by our method (NP_V), where only the pixels that have degrees of membership greater than α-cut are considered. For each ValidDB’s transaction, a valid pixel is a pixel that has the same fuzzy subset as the pixel of the MPE image (i.e., good classification). The values of the calculated NP_M, NP_MPE, and NP_V for each α-cut are presented in Table 7.
The following accuracy metrics are used to validate our proposed method.
Average validation rate (AVR), which is calculated as follows.
Root mean square error (RMSE), which is given in the following equation:
For each α-cut, we search for the one that maximizes the validation rate and, at the same time, the one that minimizes the estimation error. We calculate for each α-cut the average validation rate and the root mean square error. The obtained results are shown in Table 8, and the two histograms, as shown in Fig. 5 and Fig. 6, present the root mean square error and the average validation rate for each α-cut, respectively.
The average validation rate and the root mean square error for each α-cut

Root mean square error for each α-cut

The average validation rate for each α-cut
Fig. 6 shows that by varying the value of α-cut from 0.80 to 0.50 at 0.05 decrements, the value of the average validation is found to be higher than 0.69, which is an interesting value. Furthermore, as shown in Fig. 5, for the α-cut values lying in the range [0.50, 0.55], the mean squared error is with a low value compared with other values of α-cuts. Moreover, the best α-cut value that allows our method to obtain the best model is α-cut=0.55.
In this study, we present a new method for estimating rainfall using images from 11 MSG satellite spectral channels. The proposed method is based on the use of fuzzy association rules. Our method offers a reliable estimate of precipitation over Northeastern Algeria through the use of a large amount of diverse data from 11 channels and the introduction of fuzziness, which enables us to process these uncertain data in a flexible manner and estimate the intensity of rain in four fuzzy classes (no-rain, low, moderate, and high). Furthermore, our method can be applied to estimate rainfall during day and night. For night precipitation estimation, we use only the infrared channels’ data. The comparison of our proposed method’s and the MPE product’s results demonstrate and verify the validity of the generated model (fuzzy association rules) by our proposed method.
In the current study, the HRV channel data are not considered for estimating rainfall. Hence, in the future, we will consider relevant meteorological data other than those used in the current work, such as pressure, and wind speed, in the rainfall estimation process for improved precipitation estimation.
Footnotes
Acknowledgements
We express our deepest appreciation to all those who provided us the possibility to complete this report. We are sincerely grateful to the Editor-in-Chief for their valuable suggestions and encouragement, and to the reviewers for their comments, which further enhanced our manuscript. Furthermore we would like to thank the staff of the Remote Sensing Section from Space of Royal Meteorological Institute of Belgium for their crucial role in this work. Finally, we want to offer a very special thanks to Dr. Nicolas CLERBAUX.