
Abstract
Due to the fact that individual knowledge is often inadequate and deficient in group decision-making problems, it is commonly seen that the preference information provided by the decision makers are incomplete. To encounter this problem lots of relevant researches have already been carried out. However, previous methods often only take into account either the information of the expert who provided incomplete preference, or information provided by the rest of the group. To be more thorough and comprehensive, this paper combined both parts of the information, by first setting the unknown preference values as output and known ones as inputs, training the Bayesian regression model with the complete observations of other experts to detect the associations between them, and then putting in the incomplete preference information to predict the unknown ones. Moreover, inspired by the empirical rule of the Gaussian distribution, this paper also propose to combine the concept of confidence interval with that of interval-valued preference relations, by expressing the prediction results with interval-valued fuzzy reciprocal relations to allow some degree of uncertainty. On the basis of that an iterative consensus reaching process incorporated with feedback mechanism is also proposed. Finally a case study of possible application of our proposed model in project performance evaluations is carried out, the results of which then further verify the practicality and validity of our model.
Keywords
Introduction
Group Decision Making (GDM) [11, 40] is typically described as the cognitive process where a group of Decision Makers (DM), sometimes also referred to as experts, are gathered to collectively select the best alternative or alternatives from a set of feasible ones, considering all the opinions and preferences expressed by the DMs.
One of the most prominent advantages of GDM is that the collective intellectual or wisdom of the group is always greater than that of any individual, thus it is safe to say that the solution obtained through GDM is usually more thoroughly considered and well justified. And since the GDM relies on the collective intellectual of the entire group, it does not and cannot require all individual to have a complete and unimpaired knowledge about all the alternatives under evaluation. As a consequence, sometimes it is inevitable that the opinions and preferences provided by certain DMs are incomplete [3, 42], due to different types of reasons such as “limited expertise, domain complexity or even pressure in making a decision [15]”.
Various researches have been done regarding this issue. In [18] E. Herrera-Viedma et al. proposed an iterative procedure of estimating the unknown preference value based on the additive consistency property of the DM’s incomplete fuzzy preference relations. Alonso Sergio et al. in [2] put forward both the individual and social strategies of dealing with the situation of total ignorance where a DM does not provide any information about a particular alternative. Jian Wu et al. [37] proposed to estimate the unknown preference values based on the trust relationship of the experts obtained through a trust propagation algorithm. Qian Liang et al. [24] constructed a linear programming model to employ social ties as the bases of completing the missing preference value. Roughly speaking, these methods can be classified into two general categories: estimation methods based on consistency using only the preference information provided by the DM oneself [1, 36], and ones based on Social Network Analysis (SNA) using the preference information of the other experts within the group [24, 37].
It is worth noting that the majority of the estimation methods that fall into the first category are mostly based on various type of consistency, including additive consistency [12, 18], order consistency [9], multiplicative consistency [25] etc. This approach has several obvious advantages, one being that the estimation results would be compatible with the preference information the DM did provide, and another being that it does not require additional information about the nature of the relationship between the DMs. But this approach essentially assumes that the unknown preference value would be consistent, or at least as consistent as possible, with the other preference information, which may not be the case in practical applications where the preference relations provided by DMs are often inconsistent and contradictory.
As for the estimation methods of the second category, the question then arises on how the preference information provided by other DMs is utilized. In [37] Jian Wu et al. proposed to first compute the relative trust scores according to the trust relationship provided by the DMs, and then estimate the unknown 2-tuple linguistic preference values by aggregating the rest of the DMs’ decision matrices with the weighted arithmetic average operator where the RTSs constitute as the normalized weight vector. Whereas in [24] Qian Liang et al. proposed to use social network analysis methodologies to calculate the social ties’ strength of the DMs, then a linear programming is put forward with two objectives: one is to minimize the deviation between the estimated preference values and the weighted preferences of those DMs who have the strongest social ties to the DM under discussion, and the other is to minimize the inconsistency degree of the preference relation. It should be pointed out that these two methods share some clear similarities: for one thing, they both adopts the assumption that a person is more easily persuaded by the people who is socially closest to oneself; for another, both methods in essence estimate the unknown preference value by aggregating other DMs’ preference information with the weighted average operator. But there is one obvious disadvantage to these two methods, and that is they both require additional information regarding the social relationships of the DMs.
Another drawback of both of the categories is that they only take into account part of the preference reference information at hand: the consistency-based methods only make use of the information provided by one DM, while the SNA-based methods only make use of the information provided by the rest of the group. Therefore to be more thorough and comprehensive, this paper propose a new approach to estimate the unknown preference value based on Bayesian linear regression [10], which can utilize both parts of the preference information. If we take the preference values the DM did provide as inputs, and the unknown preference values as outputs, then a regression model can be constructed to predict the DM’s preferences when he or she is not able to provide one. The fundamental idea of this approach is as follows: we suppose that the preferences of one alternative over another is essentially a reflection of the DM’s evaluations of the alternatives over certain criterions, therefore there exists some kind of correlation or association between the preference values of one DM, which we proposed to detect through Bayesian linear regression.
It is worth mentioning that previous research [6] has in fact also adopted a Bayesian perspective in consensus building in the Analytic Hierarchical Process Group Decision Making (AHP-GDM) problems [32]. Although our method differs from it in various aspects, some reasons that made Bayesian linear regression model suitable for AHP-GDM problems also apply here. First, since in the classical fuzzy GDM scenarios the number of DMs is fairly small and the under-sample problem may occur, one advantage of Bayesian linear regression then emerges that it does not require a large amount of data samples, making it easier to utilize in practical applications. Second, the estimation results obtained through Bayesian linear regression model takes the form of probability distribution, which allows the DM to maintain some degree of doubt and uncertainty, making it easier for the DM to accept the completed preference relation as a fair representation of his or her original opinions.
Moreover, after the estimation of the unknown preference values is completed, in GDM there usually is a Consensus Reaching Process (CRP), in which the DMs can negotiate and gradually bring their positions closer to each other to finally reach a consensus solution. The CRP is of such great importance that it has been well studied in various GDM researches [5, 41]. In this paper, we also propose a CRP model based on Bayesian linear regression. First the unknown preference values in the Incomplete Fuzzy Reciprocal Preference Relations (IFRPRs) provided by DMs are estimated with Bayesian linear regression; then we propose to represent the prediction results in the form of Interval-Valued Fuzzy Reciprocal Preference Relations (IVFRPRs); next the consensus level of each DM is calculated and the DMs with insufficient consensus levels are identified and revision advice is generated to help these DMs to reconsider their preferences; finally an exploitation phase is carried out to select the best alternative or alternatives from the feasible sets.
The rest of this paper is organized as follows: Section 2 briefly introduces some preliminary concepts of IFRPRs and Bayesian linear regression; in Section 3 the general Bayesian model for estimating the unknown preference values is constructed, the result of which is then proposed to be represented with IVFRPRs, and an illustrative example is carried out; in Section 4 said Bayesian model is utilized, and the complete process of consensus reaching with IVFRPRs is described; in Section 5 a numerical case study of our model’s application in project performance evaluations is carried out; finally Section 6 marks the end of this paper with some concluding remarks.
Preliminaries
Incomplete fuzzy reciprocal preference relations
Suppose there is a finite set of alternatives A = {a1, a2, . . . , a M } (M ≥ 2), and a group of experts denoted as E = {e1, e2, . . . , e N } (N ≥ 2) who are gathered to rank said alternatives from the best to the worst, according to their own individual knowledge of the task at hand. Each expert gives his or her preference information in the form of Fuzzy Reciprocal Preference Relation (FRPR), the formal definition of which is given below.
When the number of alternatives M is small enough, the FRPR is often expressed in the form of a M × M matrix:
The usual GDM problem often assumes that the preference relations provided by the experts are complete and satisfactory, which may not be true in certain circumstances. Individual knowledge of the question under evaluation is, more often than not, inadequate and deficient. And as a result, in practical applications, some expert may not be able to provide his or her preference information on certain pair of alternatives. It is worth noting that the lack of a preference value is not equivalent to complete indifference between the alternatives, therefore it is of great importance to employ an appropriate method to estimate the missing preference value. And in order to do that, here we first give the formal definition of Incomplete Fuzzy Reciprocal Preference Relation (IFRPR).
The main purpose of this subsection is to introduce the basic concepts of Bayesian linear regression [8, 10] for its later utilization in estimating the missing value in IFRPRs.
The general goal of regression can be briefly described as: given a data set compromising N′ observations {
Following these steps, first we formulate our knowledge about the regression problem at hand. Here we assume that the target value t is generated by a deterministic linear function with additive Gaussian noise, namely
Now for a data set compromising of input predictors
For the simplicity of computing the posterior distribution, here we also assume a conjugate prior of the parameters for the likelihood function, which means that the prior distribution of parameters
According to the Bayes’ Rule, the posterior distribution is proportional to the product of the prior distribution and the likelihood function
And from the standard result from Gaussian, if the marginal distribution P (
Remark. Note that the posterior distribution in Equation (7) has two hyper parameters, α and β, the former represent the precision of the prior Gaussian distribution of the parameters
In practical applications, usually we are not interested in the distribution of the parameters
It is also true that following the product rule of probability, we can obtain
With Equations (11) and (12), we can now write
In the right-half of the Equation (13), the conditional probability distribution of the target variable P (t*|
As aforementioned, in practical applications, it is a common occurrence that the expert provided IFRPR due to the fact that the individual knowledge of the alternatives is often inadequate or deficient. In this section we propose to estimate the unknown preference value through Bayesian linear regression.
The first problem we encounter is that the preference values of IFRPR all falls into the unit interval, which contradicts the assumption of Gaussian distribution, so we proposed to first apply a bijective conversion function before constructing the Bayesian model, the details of which is described in subsection 3.1; then in subsection 3.2, for estimating the unknown preference value of IFRPR, a general Bayesian model is constructed and the predictive probability distribution is obtained; next in subsection 3.3, to maintain some degree of uncertainty we proposed to represent the prediction results with interval-valued numbers, and constructed a complete IVFRPR from IFRPR; in subsection 3.4 we also discussed the preprocessing of preference values to take into account other circumstances where there is more than one pair of preference values unknown in IFRPR.
Conversion of the preference values
Recall that in the classical Bayesian linear regression model, it is assumed that the target variable is generated by a deterministic linear function with additive Gaussian noise, as described in Equation (2), therefore the range of possible values for the target variable would be (- ∞ , + ∞). This could be problematic because it contradicts the definition of the IFRPR, where each preference value must fall into the unit interval [0, 1]. This problem can be dealt with through bijective conversion function, which is to say, before constructing the Bayesian linear regression model, we need to first convert the range of preference values from [0, 1] to (- ∞ , + ∞) with a bijective function t = g (r), and after the prediction was given, we also need to convert the results obtained from (- ∞ , + ∞) to [0, 1] with the inverse function r = g-1 (t). It is worth pointing out that the requirement of bijective conversion function is essential so that the preference values can be invariant after two conversions. Here we consider the following conversion function (a > 0, q > 0):
Like demonstrated in Fig. 1, it is easy to see that
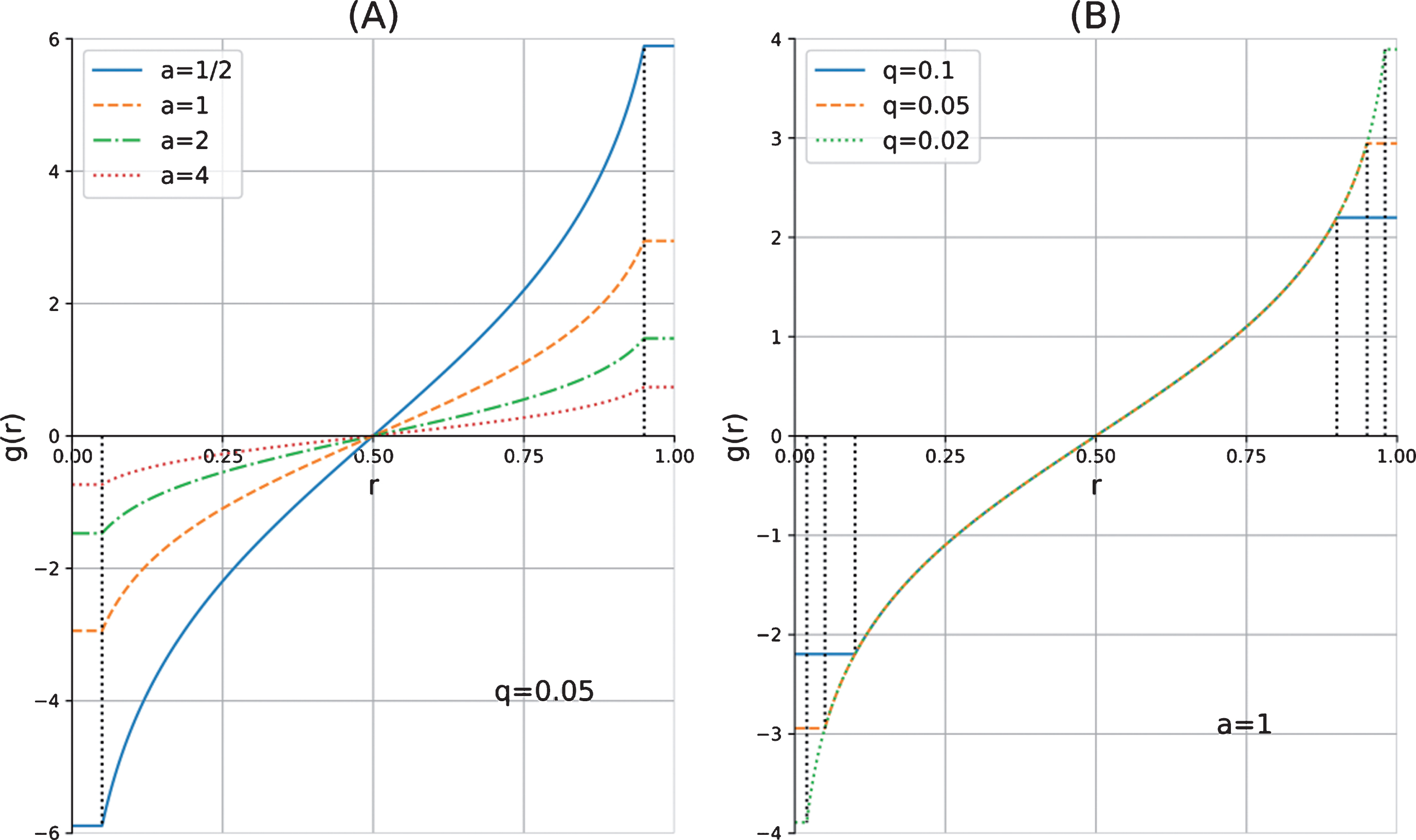
The conversion function g (r) with adjustable parameters a and q.
Figure 1 also shows the effect of different settings of parameters on the conversion function g (r). In Fig. 1 (A) we fix the parameter q = 0.05, while the parameter a is set to be 0.5, 1, 2 and 4 separately. It is clear that the smaller the parameter a, the sharper the increase of g (r) with respect to r. In Fig. 1 (A) we fix the parameter a = 1, while the parameter q is set to be 0.1, 0.05 and 0.02 separately. And the greater the parameter q, the more insensitive the DM is to the preference values, as in the DM can overlook greater deviation between the preference values 0 and q, as well as 1 - qand 1, deeming them as indifferent.
Since the fundamental purpose of constructing the Bayesian linear regression model is to estimate the unknown preference values in IFRPR, it is necessary to convert the results obtained from (- ∞ , + ∞) to [0, 1]. Like illustrated in Fig. 2 we now consider the inverse function r = g-1 (t):
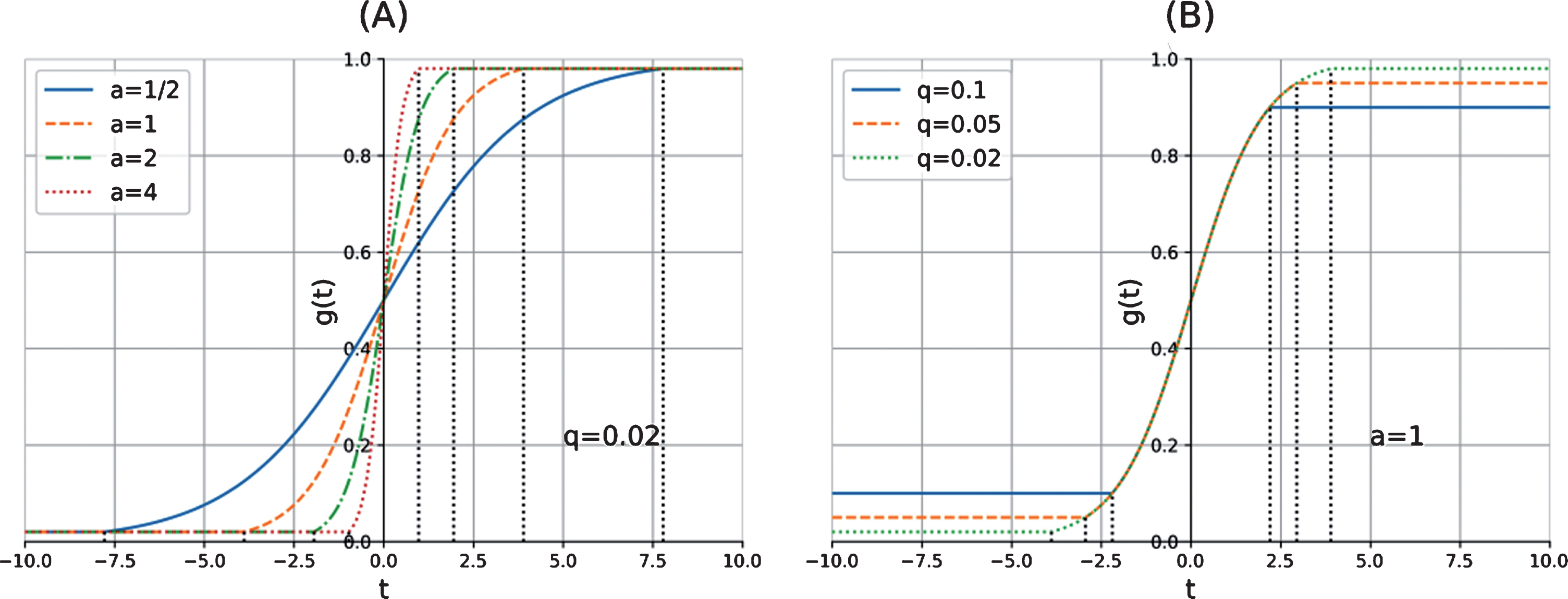
The inverse conversion function g-1 (t) with adjustable parameters a and q.
Note when t ≤ - Q, 1/ - 1 + e aQ = q > 0; and when t ≥ Q, 1/ - 1 + e-aQ = 1 - q < 1, therefore after converting with g-1 (t), the results should all satisfy the requirements of fuzzy preference relations. It is worth noting that g-1 (t) is monotonically increasing, and the closer t to 0, the sharper increase of g-1 (t) with respect to t; meanwhile the closer t to ±Q, the slower increase of g-1 (t) with respect to t.
This feature is actually the reason that we chose to utilize the conversion function in Equation (16), and it is desirable because we believe that with the adjustable parameters, it can model some characteristics of human perception in the decision-making process. Recall that we assume the probability distribution of the target variable t, which essentially is the converted preference value given by the experts, takes the form of Gaussian distribution. In other words, let us suppose that
Now with conversion function, we can construct the general Bayesian linear regression model for the unknown preference values in IFRPR. Recall that given any IFRPR R
l
(l = 1 : N), it is always true that ∀i, j = 1 : M,
For brevity, for now we assume that only one expert e
h
provided IFRPR R
h
, with only one pair of preference values
Notice that the number of observations in the data set is roughly the number of experts consulted with the GDM problem, while the number of inputs is roughly half the square of the number of alternatives. That is to say, in practical applications the under-sample problem may occur, where the number of inputs is greater than the number of samples. And to overcome this problem, the Bayesian linear regression is chosen to estimate the missing preference value because it has no need for cross validation and therefore utilizes all the samples provided. Another advantage of Bayesian linear regression is that it models the associations between the predictors and the target variable with probability distribution, which allows some degree of uncertainty for the expert with IFRPRs.
We now give an illustrative example to show the conversion process and the rearrangement of preference values.
Notice that the IFRPR R6 provided by expert e6 is incomplete with preference values
To start with, the range of the preference values need to be converted from [0, 1]to (- ∞ , + ∞). Here we set the parameters as a = 1 and q = 0.02, then the conversion function can be written as
If we take expert e1 for instance, the preference value
Then after conversion with g (r), the complete FRPRs provided by the other 7 experts need to be rearranged into the form of observations and target variables. For instance, the FRPRP1 provided by expert e1 is rearrange into a predictor
The training data set compromising of 7 observations and their corresponding target variables
So far, the estimation of unknown preference value has been transformed into the problem of predicting t(6), given the new input predictor
Next the detailed process of Bayesian linear regression for estimating the missing preference value is described. Like in Section 2.2, let
If we assume that the converted preference values are drawn independently from the distribution (19), then we would have the likelihood function:
Next we also assume a zero-mean isotropic Gaussian distribution with a single precision hyper parameter α for the prior of parameters like in Equation (5), then following the standard results in Bayesian linear regression, the posterior distribution of the parameters is as described in Equations (7), (8) and (9) where
Now with the posterior distribution, we can make predictions for the target value t(h). Following similar procedures like described in subsection 2.2, we can have the predictive distribution
Now given the new input
In other words, for the new observation
In the subsection 3.2 above, we obtained the predictive distribution of the target variable. And to complete the IFRPRs, additional procedures must be carried out to extract information about the unknown preference values from the predictive distribution in Equation (25). The naïve approach would be taking the expectation of Equation (25) and converting it back into the range of unit interval. But since the fundamental reason that we proposed to take a probabilistic perspective in the first place is to model the uncertainty and ambiguousness of the DM, and valuable information may be lost by simply replacing the unknown value with the converted expectation, here we proposed to express the prediction result in the form of Interval-Valued Fuzzy Reciprocal Preference Relation (IVFRPR), the definition of which is given below.
In subsection 3.2, Equations (25) and (26) show the predictive result of the target variable P (t(h)), which takes the form of Gaussian distribution. It is well known that for Gaussian distribution
Admittedly other confidence level ξ can also be utilized as long as it satisfies the equation P (c1 ≤ t ≤ c2) = ξ, where [c1, c2] is the corresponding interval. But it is reasonable to believe that the interval of two or three deviations away from the mean value would suffice to meet most of the practical demands.
Without loss of generality, here we assume that for the probability distribution in Equation (25) of the target variable t(h),the chosen confidence level is ξ with corresponding confidence interval [c1, c2], namely P (c1 ≤ t(h) ≤ c2) = ξ. Then because the conversion function g-1 (t) in Equation (17) is monotonically increasing, so after conversion we would have
As aforementioned, we proposed to represent the predictive result in the form of IVFRPRs. For the unknown preference value
In subsection 3.2, we assumed that only one expert in the group provided IFRPR, and with only one pair of preference values unknown. Unfortunately in practical applications, there may be much more complex circumstances. In this subsection, the preprocessing of the preference values is utilized to address these kinds of problems, which we believe should fall into three categories, or their combinations: Only one expert provided IFRPR, but with more than one pair of preference values unknown.For simplicity, suppose expert e
h
provided IFRPR R
h
with two pairs of preference values More than one expert provided IFRPR, but with only one same pair of preference values missing. Suppose experts e
h
1
and e
h
2
provided IFRPRs R
h
1
and R
h
2
, but with the same pair of preference values More than one expert provided IFRPRs, but with different pairs of preference values missing. Without loss of generality, we assume that expert e
h
1
and e
h
2
both provided IFRPRs, but R
h
1
is incomplete with
Consensus reaching process
Simply put, the objective of GDM can be described as choosing the best alternative or alternatives from the set of feasible ones, on the basis of the experts’ preferences and opinions. And in order to do that, a selection process must be carried out, which usually involves two stages: the aggregation of the individual opinions provided by the experts, and the exploitation of the collective opinion of the group [19]. But some expert may be reluctant to accept the final decision result if he or she felt that his or her opinion has been neglected or not well-reflected. So it would be preferable to reach the state of consensus before entering the phase of exploitation.
But in reality, a group of experts seldom agree with each other completely, and it is nearly impossible to reach a unanimous decision due to the experts’ divergent backgrounds and possible conflict of interests. So instead of asking the experts to reach a full agreement, a softer type of consensus is proposed, where some consensus indices are defined to measure the degree of agreement among the experts. With these consensus measurements, the experts are asked to revise and modify their preferences step by step until they reach a sufficient consensus degree. A detailed demonstration of the entire CRP with IFRPRs is shown inFig. 3.
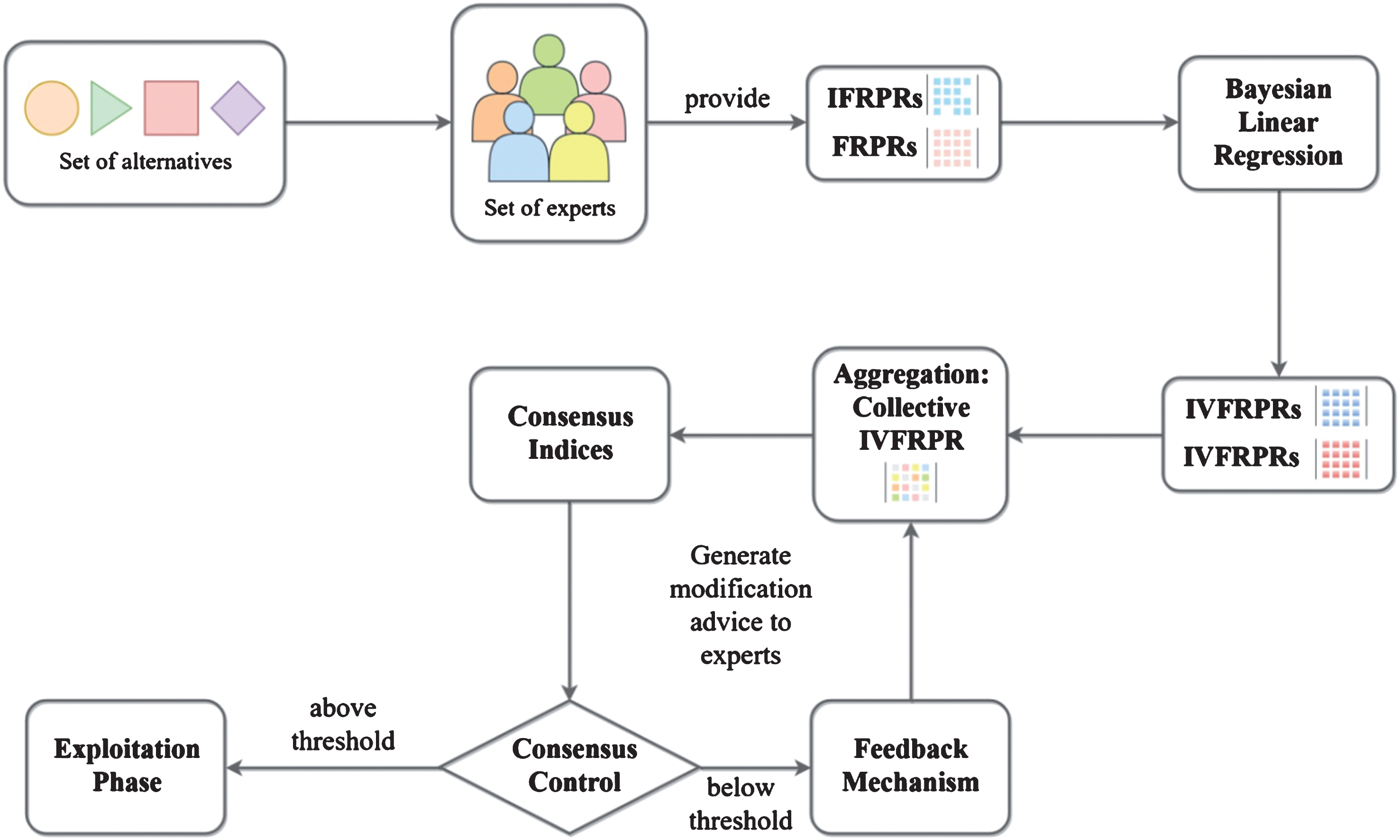
CRP in GDM with IFRPRs using Bayesian linear regression.
As illustrated in Fig. 3, the CRP with IFRPRs consists of 7 steps:
The first three steps have already been covered in Section 3,the more detailed description of Step 4 to 7 would be the focus of this section.
For Step 4, we first need to aggregate each expert’s opinion
.
Now with these operators we can have the weighted average operator for IVFRPRs.
Then the collective IVFRPR of the group can be obtained:
Now we have the collective IVFRPR of the group, next in Step 5 the consensus indices of each expert e h can be defined on three levels: pairs of alternatives, alternatives and preference relations[38].
Notice that the closer the expert’s preference is to the group, the bigger the consensus indices. In the rare case that
Usually in the CRP, to help the experts to reach sufficient consensus level within an acceptable time frame, a moderator is often present [19]. A moderator’s first responsibility is to compute the consensus levels of each expert according to the IVFRPRs they provided, and to deem if sufficient consensus level has been reached. Suppose γ is the designated consensus threshold, it is deemed as acceptable consensus within the group if for every expert in E = {e
h
|h = 1 : N}, we have CR
h
≥ γ. If so, the CRP is terminated and the exploitation of the collective IVFRPRs of the group is carried out; if not, the moderator then needs to identify those experts with insufficient consensus levels, which can also be described on three levels: on preference relation, on alternatives and on pairs of alternatives [38]. The experts with insufficient consensus index CR on the preference relation are identified:
For those experts in EXPCH, the alternatives on which their consensus index is below the threshold are identified:
For those alternatives in ALT, the pairs of alternatives whose preference value needs revision are identified:
The moderator will then supply this information as feedback to the experts with insufficient consensus indices. To accelerate the CRP, suppose (h, i, j) ∈ APS, the moderator will also generate revision advices for expert e
h
: “The consensus index of your preference of alternative a
i
over a
i
is
Exploitation phase
Up till now, the first 6 steps of the CRP are completed, we now have the collective IVFRPR
With the arithmetic operators of interval numbers described in subsection 4.1, we can calculate the average preference degree ρ
i
[7] of alternative a
i
over the rest of the alternatives as:
To compare two interval numbers, in [43] Xu defined the possibility degree of ρ
i
≥ ρ
j
as:∀i, j = 1 : M
Then the complementary matrix D = (d ij ) M×M is constructed, and it is easy to see that d ij > 0, d ij + d ji = 1, d ii = 0, ∀ i, j = 1 : M.
Finally in [7], the author defined the ranking value RV (a
i
) of alternative a
i
as:
Then the alternative or alternatives with the highest ranking value would be selected as the solution to the GDM problem, and Step 7 of the CRP is completed at last.
To demonstrate the entire procedure of CRP with IFRPRs based on Bayesian linear regression, here we provide a case study about possible application of our proposed model in project performanceevaluations.
Project performance evaluations is a method by which the design, implementation and performance of a project is documented and evaluated. Since a project usually takes up a relatively long period of time, varying from months to years depending on the objectives and nature of the project itself, it is a common practice to divide the project into several stages or tranches. Then at the end of each stage, a performance evaluation process is often carried out, to determine if the project has been satisfactorily accomplished on schedule. What’s more, the results from the performance evaluations can then be used to make comparisons with other projects of similar natures, and serve as the bases of assigning rewards to those who have achieved great accomplishments, or providing improvement advices to those who has fallen behindschedule.
To ensure the impartiality and rationality of the performance evaluation process, usually a group of experts are consulted. So in other words the performance evaluation process can be described as a group of experts gathered to obtain a fair ranking of a set of projects, hence a GDM problem. And since the human judgement is inherently imprecise and ambiguous, it is more reasonable to formalize the project evaluation process as a fuzzy GDM problem. Suppose there are 12 experts, denoted as E = {e n |n = 1 : 12} who are gathered to evaluate and rank the performance of four projects with similar natures, denoted as A = {a i |i = 1 : 4}. Next our proposed method is carried out in detailedprocedures.
We first estimate the unknown preference value of R2 through Bayesian linear regression. For the time being we need to temporarily replace the unknown preference values
The training data set compromising of 11 observations and their corresponding target variables
The training data set compromising of 11 observations and their corresponding target variables
Next we set the parameters α = β = 10-6 by default, and train the Bayesian linear regression model to fit the data set, the result is as follows:
Now given the new input
In other words, for the new observation
Similarly, a Bayesian linear regression model can also be constructed for expert e7 with target variable set to be
And for the unknown preference
For the rest of the experts, let
For the sake of simplicity, here we only listed the consensus indices on pairs of alternatives where i < j, because it is easy to see that
Finally, the consensus index of expert e2 on preference relation is acquired:
Similarly, the consensus indices of other experts are calculated, the result of which is listed below:
Then for each (h, i, j) ∈ APS, the revision advice on the preference of alternative a
i
over a
j
is feedback to expert e
h
. Again we take expert e12 as an example, for (12, 1, 2) ∈ APS, the moderator would generate a revision advice to expert e12 that “The consensus index of your preference of alternative a1 over a2 is 0.525, which is below the designated threshold γ = 0.8. It is advisable to revise it to a value more close to [0.575, 0.575].”For the rest of experts in EXPCH, similar revision advices are generated and feedback, these experts are then encouraged to revise his or her preferences accordingly. Here we assume that all experts are cooperative and willing to make necessary adjustments to reach group consensus, and that each expert revises his or her preference using the weighted average operator with equal weights assigned to the original preference value of the expert and the collective preference value, which is to say, for (h, i, j) ∈ APS, expert e
h
revises his or her preference value of alternative a
i
over a
j
from
After all expert in EXPCH finished revising his or her preferences according to the feedback advice, the moderator then re-calculate the collective IVFRPR of the group, the result
It is clear that all experts have reached the pre-designated consensus threshold, and now the exploitation phase can be carried out.
To compare interval numbers, next we calculate the possibility degree of ρ
i
≥ ρ
j
through Equation (35) described in subsection 4.4, and the resulting complementary matrix is shown below:
Finally according to Equation (36) we obtain the ranking value RV (a
i
) of alternative a
i
as:
Thus the final ranking of alternatives is: a4 ≻ a1 ≻ a2 ≻ a3.
In this paper, we proposed to utilize the Bayesian linear regression model to estimate the unknown preference values in the IFRPRs. And since the probability distribution form of the prediction results naturally allows some degree of uncertainty, furthermore we proposed to express the completed preference information in the form of IVFRPRs. Then a CRP model based on Bayesian linear regression is constructed, where three levels of consensus indices are defined and a consensus control mechanism is applied to identify the experts with insufficient consensus level, meanwhile generating revision advice to help these experts to move their positions closer to the group. The CRP is iteratively repeated until sufficient consensus level is reached and the exploitation phase is implemented. The case study of possible application of our proposed model in project performance evaluations is also carried out to demonstrate and verify the practicality of our proposed method.
It is reasonable to believe that our proposed method has several advantages compared with previous researches, for one thing it does not require the experts to provide further information regarding their social relationships; for another it takes a novel probabilistic perspective to estimate the unknown preference values which is more flexible and allows uncertainty. But there is also room for improvement which will be the future focus of our research. For starter we only chose the simplest form of basic functions when constructing the Bayesian linear regression model, but more sophisticated forms of functions can also be adopted. What’s more, in our model the DMs are instructed to express their opinions in the form of fuzzy reciprocal preference relations, which may be difficult for certain DMs in practical applications, so how to modify our model to accommodate heterogeneous preference structures [16, 44] like linguistic preference or intuitionistic fuzzy preference, is an important subject worth exploring in the future.
Footnotes
Acknowledgments
The work was supported in part by the National Natural Science Foundation of China under Grant 71501186, Grant 61702543 and Grant 61806221.