
Abstract
Weapon target allocation (WTA) is a classic NP-complete problem in the field of military operations research. In this paper, we addressed the multi-constraint WTA problems in multilayer defense scenario. To solve large-scale WTA problems effectively, a distributed MAX-MIN Ant System (MMAS) algorithm based on distributed computing framework Spark was developed and improved. An experiment environment comprising virtual machines was built for implementing the distributed MMAS. First, a small-scale WTA example, whose theoretical optimal solution can be obtained by existing optimization software, was taken as a benchmark problem to assess the performance of distributed MMAS. The result shows that it can find high-quality and robust approximate solutions. Then a large-scale WTA problem was constructed and used to further evaluate the performance of distributed MMAS in the experiment environment. The result shows that the distributed MMAS can also achieve high-quality approximate solutions with high robustness and computational efficiency even for large scale WTA problems. Our study demonstrates it is a promising approach for solving large-scale iteration-dependent optimization problems like WTA by means of incorporating heuristic optimization algorithms such as Ant Colony Optimization into distributed computing framework.
Keywords
Introduction
The Weapon Target Assignment (WTA) problem is a basic problem growing out of defense-related applications of operations research. This problem is to find an appropriate assignment of defensive weapons to targets with the objective of maximizing the survival asset value. Research on WTA problems stretched back to the 1950s and 1960s, in which the modeling issues for WTA problems were investigated [1, 2]. At that time, because of limited computing power and the less advanced research level, researchers had to make a number of simplified assumptions when modeling WTA problems and they could solve only small-scale problems by using mathematical programming methods, such as the Branch and Bound method or Dynamic Programming. In the past 30 years, when mentioning the WTA problem, many researchers have made increasing extensions and improvements on its mathematical model and relevant algorithms, including extensions from single-layer to multi-layer defense scenarios; from only considering weapon availability constraints to simultaneously considering more constraints in which some factors as manpower, budget and space availability could be concerned; from a static to a dynamic assignment situation; and from exact algorithms for solving small-scale problems to heuristic algorithms for solving large-scale problems.
The WTA problem is a representative constrained combinatorial optimization problem. In 1986, Lloyd and Witsenhausen [3] proved that the WTA problem with multi-type weapons was NP-complete for the first time. Exact algorithms based on mathematical programming theory usually resulted in an exponential increase in the computational requirements, regardless of whether the problem scale was large or small. Thus, the exact algorithms focused on only static WTA problems, with some restrictive conditions, such as that all of the weapons were identical [4] or that the targets could receive at most one weapon [5]. Recent researches mainly focused on dynamic WTA problems [6–8] or WTA problems based on multiple agent [9]. Researchers were interested in dynamic resource allocation problem and engaged in developing more effective algorithms for a significant computational runtime improvement.
An efficient solution of the WTA problem is of great interest in military operations research. The reason is that in an engagement with the enemy, the problem must be solved in real time. The enormous combinatorial complexity of the problem implies that even with the supercomputers which are available today, exact optimal solutions cannot be obtained in real time. Many researchers have been working on modern heuristic algorithms, for example ant colony optimization. Recent an algorithm research presents a hybrid approach which combines an ant colony optimization with a greedy algorithm [10].
Distributed computation technology has brought about changes on the compute mode in the distributed computation epoch. Unlike traditional compute mode featured with small amount of data and stand-alone compute environment, distributed computation refers to datasets that are terabytes to petabytes (and even exabytes) in size, and are stored on computational clusters instead of one or several devices.
Various types of data which derive from all aspects of human life [11–16] have been stored in nodes of various clusters. The situation is bringing new challenges to computation and analysis. Large amounts of data mean that they need to be processed in parallel rather than in sequence, and be handled in cluster mode rather than in stand-alone mode. Now computational processes dealing with data processing and data analysis have been handled using parallelized way through clusters, where each node is well-organized and might be stand-alone. The large distributed compute architecture has formed in rapidly developing distributed computation realm. Therefore, in the new computation architecture, algorithms which originated from stand-alone environment need to re-model and redesign for tackling new problems more efficiently.
This paper deals with how to solve a large-scale multi-constraint WTA problem in multilayer defense scenario [2, 17–19]. Distributed computation is a promising approach to this kind of problem [20]. For example, large batches of Traveling Salesman Problems [21] was solved with distributed computation. Recent researches on solving heuristic problems adopted distributed computation [22–25]. In this paper, we developed a distributed MAX-MIN Ant System (MMAS) algorithm [26, 27] based on Spark framework [28] to solve WTA problems. Spark has been a common computing framework in data analysis [29, 30]. The implementation schemes and some improvements of the proposed algorithm were presented. The experiment environment for implementing distributed computing based on Spark framework was built. Under the experiment environment, a small-scale WTA example taken as a benchmark was used to assess the performance of the algorithm. Furthermore the proposed algorithm was used to solve a large scale WTA problem. The solution quality and computational efficiency were presented and evaluated. The result shows that the distributed MMAS algorithm based on Spark framework are effective for even larger scale WTA problems. In addition, many heuristic algorithms can be incorporated into Spark framework for solving large-scale iterative optimization problems like WTA.
Mathematical model for WTA problem
We addressed the multi-constraint WTA problem in a multi-layer defense scenario. The solution for the problem aims to find a proper assignment of weapons to defend targets from attack with the objective of maximizing the survival asset value attained. The literature on WTA problem can be categorized mainly into two classes. First class relates to defense allocation models in which defensive weapons are assigned to targets without taking into account the behavior of the opposing side. The second class considers the opposing side’s actions as well as the defensive actions. However, we will only consider WTA from the defender’s point of view with known opponent’s attacking plan [31, 32].
Suppose that the defender sets up a multilayer defense system which contains D kinds of intercept weapons, for protecting its S strategic assets. These assets may be attacked by the attackers with A kinds of weapons. In general, each layer of the defense system is deployed only with the same type of weapon, for example, the low-altitude defense utilizing flak gun, high-altitude defense utilizing surface-to-air missile, space defense utilizing ballistic missile. Therefore we assume that the number of layers of the defense system is the same as the number of types of weapons owned by the defense system, that is, the number of layers of the defense system is D. Obviously, S assets are the targets intended to be protected by the defense system; on the other hand, the enemy’s offensive weapons are the targets intended to be intercepted by the defense system.
The WTA problem is to determine the number of different types d (d = 1, 2, ⋯ , D) of defending weapons deployed against the possible incoming enemy attacking weapons of type a (a = 1, 2, ⋯ , A), which will give maximum survivability to the assets s (s = 1, 2, ⋯ , S).
Decision variables of this problem are:
x dsa : Number of defending weapons type d to be deployed to intercept attacking weapon type a to defend asset s (defense plan).
The total number of decision variables is D × S × A. The definitions of other notation are given in Table 1.
Notation definitions
Notation definitions
The probability that weapons deployed in d
th
layer will not be able to intercept a single attacking weapon of type a on asset s is given by
The total expected surviving value of all the assets being the objective function is to be maximized is
Objective function:
Subject to constraints:
The objective function Equation (1) is to maximize the total expected surviving value of all the protected assets. Constraint Equation (2) indicates the total number of defending weapons type d to be deployed at all assets against all attacking weapons must be equal or less than the total available number of weapons type d. Constraint Equation (3) indicates the total ground area required at each asset s allocated for each type d of defending weapon to be deployed shall be equal or less than the area available at each asset. Constraint Equation (4) indicates the total required cost for procurement, deployment and operation of each defending weapon must be equal or less than the total available budget for all types of defending weapons which are deployed at all assets against all attacking weapons. Constraint Equation (5) indicates the total required manpower to operate all deployed weapons of type d at all assets should be equal or less than the total available manpower which operate weapons of type d.
Equations (1)∼(5) comprise a general mathematical model of the WTA problem in the multi-layer defense scenario. One can make some simplification or extension to this general model to form a variety of WTA problems. The above WTA model is a nonlinear integer programming problem that has been proven to be NP-complete. This result means that its optimal solution cannot be obtained within polynomial time when using an exact algorithm based on conventional mathematical programming theory.
The MMAS is an ACO (ant colony optimization) algorithm derived from Ant System and is one of the best ACO algorithms for the Traveling Salesman Problem (TSP). The MMAS algorithm can be formulated in Fig. 1, which is less formal than the original specification.

Sequential implementation of the MMAS.
We adopted an integer coding scheme when implementing MMAS algorithm. A complete solution to the WTA problem, which has D × S × A decision variables x dsa , is represented as a row vector on the following order:
The search space is divided into L stages, as shown in Fig. 2. The number of stage is equal to the number of decision variables, i.e. L = D × S × A. Each decision variable is associated with a stage in order of sequence of decision variables, i.e., stage 1 corresponds to x1,1,1, stage 2 corresponds to x1,1,2,..., the last stage corresponds to xD,S,A. At stage i, there are U i + 1 nodes numbered from 0 to U i . The number at a node indicates the value taken by the decision variable at the stage where the node is situated. U i is the maximum value possible for the decision variable at stage i to take.
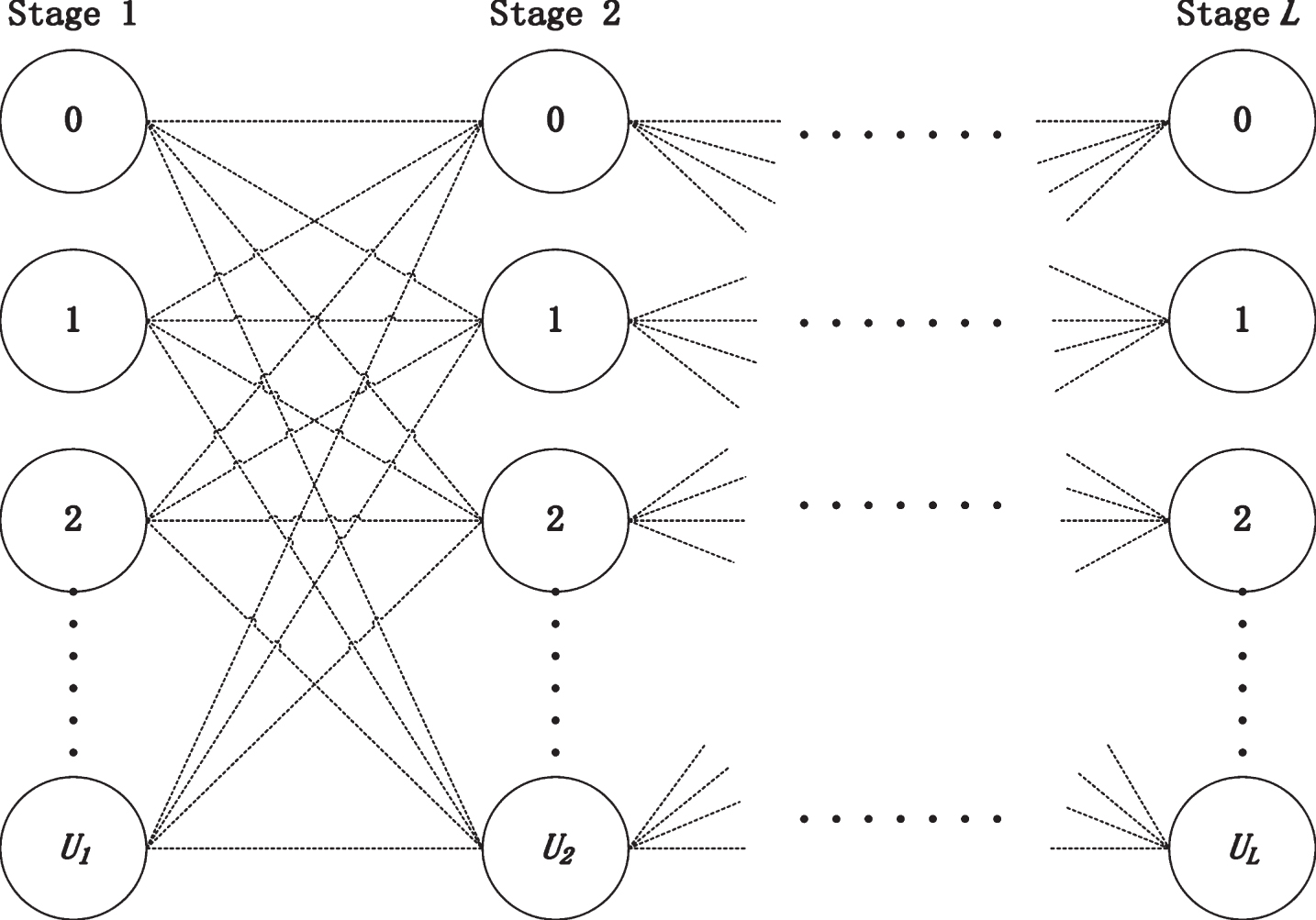
Search space.
Suppose the decision variable associated with stage i is xd,s,a. Then the possible maximum value at stage i, U
i
can be simply set to B
d
(the available number of defense weapon of type d). Or, in order to reduce the search space for large-scale WTA problems, taking constraints Equations (2)∼ (5) into account, U
i
is determined as following.
Symbol (int) means taking the integer part of a real number. Equation (7) implies that when all decision varia1bles, except for the given variable xd,s,a, are set to zero, and all constraints are satisfied, the maximum value that xd,s,a can attain. At each stage in the search space, an ant chooses one node to pass through. Then all nodes stopped over by an ant from the first to last stage are lined up sequentially to construct a searching path which indicates a solution to the problem. Different to the regular ACO algorithm, in this paper pheromone trails are resided on nodes rather than on routes between two nodes. More pheromone trail one node possesses, more ants will be attracted to stop over that node. At iteration t and stage i, the probability of ant k choosing node j of stage i is also termed as transfer probability, which is denoted by
where τ
ij
(t - 1) is the pheromone trail on node j of stage i at iteration
When each searching iteration is completed, the node’s pheromone trails need to update. Usually an elitist strategy can be used to update pheromone trail, namely, only the pheromone trails on nodes of the global optimal path (the path with maximum objective function) so far are strengthened, while the pheromone trails on other nodes are evaporated. When iteration t is completed, the pheromone trail on node j of stage i is updated to τ
ij
(t), which is calculated by the following formula:
where ρ is the evaporation factor of pheromone trail, τ0 is the initial pheromone trail, f
best
s
o
f
ar
is the best objective function so far, and f
average
(t) is the average value of objective functions over all ants at iteration t. In the meantime, to prevent premature of the search process, we refer to the practice of MMAS, to limit node’s pheromone trail to an interval [τmin, τmax]. According to defacto experiment results, we made several improvements on MMAS abovementioned. First, it was possible that after limited iterations, all ants finally assembled to same path because the pheromone trail on the path associated with the best ant did not change again, which means the algorithm could not explore better solutions. And then, we changed pheromone trail updating strategy, instead of only considering the global optimal ant, the locally best optimal ant in each iteration was also taken into account for pheromone trail updating. A complementary pheromone trail updating rule was proposed:
Equations (9) and (10) constitute a combinatorial strategy for pheromone trail updating. After the locally best ant updating rule (Equation (10)) was applied m times consecutively, the globally optimal ant updating rule (Equation (9)) was executed once.
Second, for some randomly selected or the smallest decision variable xd,s,a in stage i, we utilized greedy strategy to increase its value by an incremental Δx. If xd,s,a + Δx meets constraints Equations (2)– (5), we reset xd,s,a to xd,s,a + Δx.
Third, at each iteration n ants’ moves were actually irrelevant, so we could deal with their moves concurrently. We utilized a kind of data structure called RDD (Resilient Distributed Datasets) in Spark framework to compute the objective function and constraints of WTA problem, so as to best utilize the parallel ability of Spark.
In Ref. [33], Marco Dorigo and Thomas Stützle have proved the convergence property of ACO algorithm. In general the computational complexity of an algorithm is measured by time complexity and space complexity. The time complexity is defined by O(g(N)), where N is the size of the problem; while the space complexity reflects the way the data are stored and retrieved. With the rapid development of computer technology and the dramatic improvement of storage capacity, nowadays the issue of space complexity is becoming less and less severe especially in a distributed computing environment. As a heuristic algorithm, the MMAS is a kind of polynomial time algorithm. This means it is able to find a solution to the WTA problem within a reasonable amount of computation time. In practice, as a surrogate, we can use the CPU time spent for solving an NP-hard problem which reflects the computational efficiency to measure the computational complexity of a heuristic algorithm.
We adopted Spark framework as the kernel of the distributed compute architecture. Now Spark technology is becoming an important and effective way to process big data through distributing executable code to every compute node for realizing program concurrency. Spark provides a series modules including real-time analysis, batch analysis, DataFrame framework (a kind of function similar to SQL queries), machine learning, graph analysis framework and so on. It can process structured, semi-structured and unstructured data, and quickly respond to business system.
We utilized Spark 2.1 on Hadoop 2.7 [34] version for our experiment. In our experiment architecture, the Hadoop tool mainly focused on data storage and the input data files were stored to HDFS file structure which could be accessed by Spark conveniently. Spark mainly focused on distributed computation. We set one master (driver) node and n work (compute) nodes in virtual machine to realize distributed computation. Of course the experiment configuration should be modified according to experiment requirements such as the number of work nodes. In this paper, we set two work nodes. Every compute node in virtual machine had one CPU core and 3GB RAM and linux ubuntu operation system to run some executors, while one executor set up N tasks to handle RDD datasets concurrently. The distributed compute architecture was shown in Fig. 3. The principle of Spark framework is to deploy source code to every work (compute) node without moving data files, and then run the source code concurrently by transmitting messages between nodes.
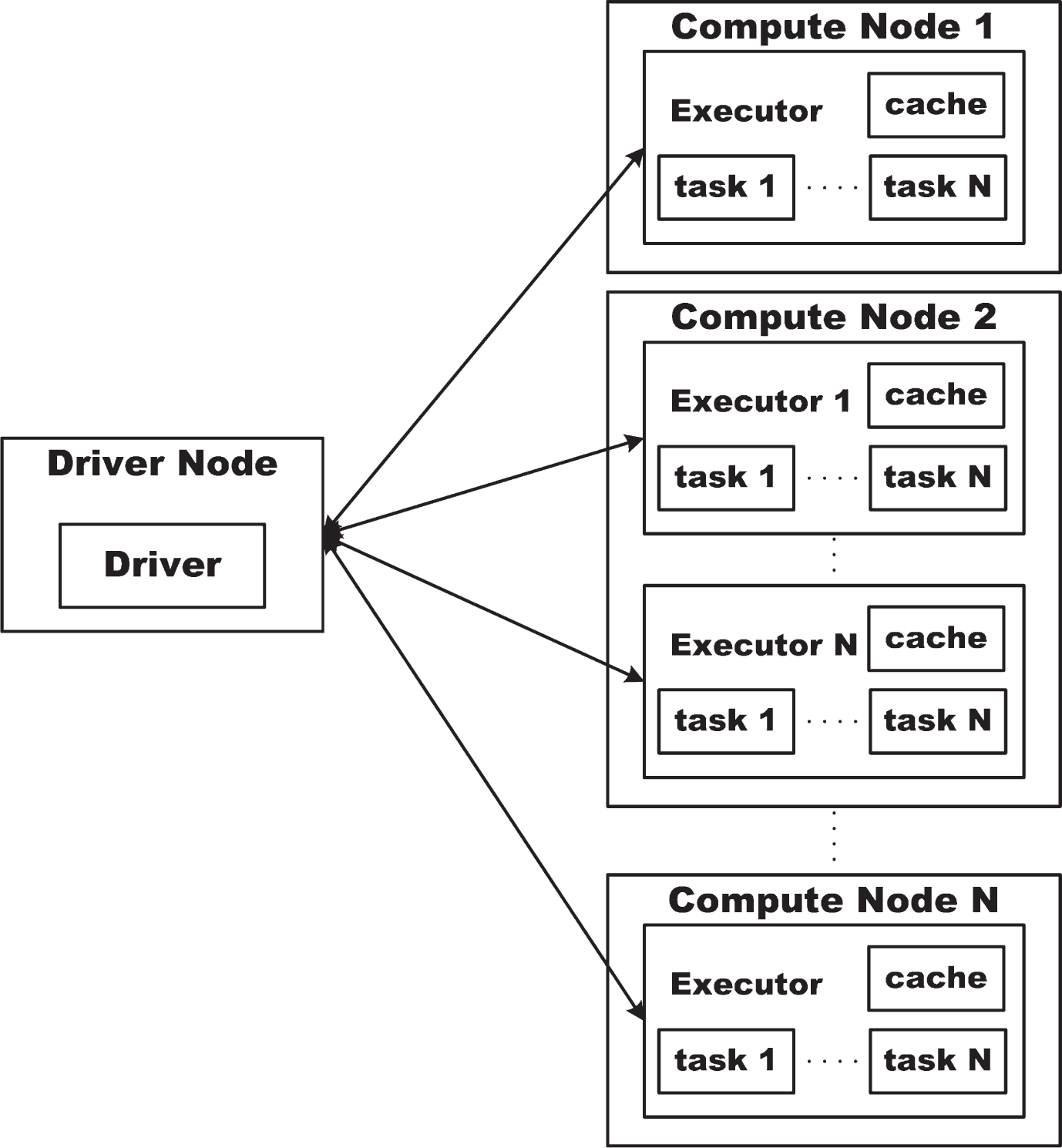
Architecture of ‘yarn-client’ mode in Spark framework.
We conducted our experiments in ‘yarn-client’ mode of Spark framework. One node was set as driver and another two nodes served as compute nodes. The jobs waiting for execution were controlled in driver node and actually executed in compute nodes. In every compute node, one or many executors (according to the parameters given in spark-submit command) were set up to store states and run jobs; while in every executor some tasks (according to the partition given in the program) were set up to complete jobs in parallel. Our programs were distributed to executors to run. Executors communicated with the driver node. Due to our hardware limitation, the Spark framework in the virtual machine allocated only two executors for our experiments.
In order to test the effectiveness and performance of the distributed implementation of the MMAS, a small-scale WTA problem was constructed. In Ref. [18], a numerical example of a small-scale WTA problem in a multi-layer defense scenario with the dimension of 2 × 3 ×2 was given, in which the defender deployed two types of defensive weapons at three assets against attacks from two types of offensive weapons, i.e., D = 2, S = 3 and A = 2.
We made a modification to some of the data in this example to construct a slightly different example. The theoretical optimal solution to the modified example will be taken as a benchmark to assess the performance of MMAS for solving the WTA problem. We call this modified example the “benchmark problem”. The parameters in the benchmark problem are set as follows.
The maximum number of available defending weapons of type 1 is B1 = 100 and that of type 2 is B2 = 50. The number of attacking weapons of type 1 and 2 is 50 and 29, respectively. The values of the first, second and third assets are v1 = 400, v2 = 300 and v3 = 200. The attack plan is known to be n11 = 5, n12 = 9, n21 = 25, n22 = 7, n31 = 20 and n32 = 13. The area available at assets 1, 2 and 3 is G1 = 2250, G2 = 1500 and G3 = 1950, respectively. The area required by defending weapons of type 1 and 2 (to be deployed) is t1 = 34 and t2 = 51, respectively. The cost of defending weapons of type 1 and 2 is C1 = 20 and C2 = 30, where the total allocated budget is Cmax = 3800. The maximum manpower that is available for defending weapons of type 1 and 2 is M1 = 350 and M2 = 320, while the manpower required for operating each defending weapon of type 1 and 2 is m1 = 5 and m2 = 4. The effectiveness of defending weapons and the damage probability of the attacking weapons are given in Table 2.
Interception and damage probabilities
The parameters for MMAS are set as follows: Size of ant colony m = 40; Initial pheromone trail τ0 = 1; Pheromone evaporation factor ρ = 0.01; Maximum pheromone trail τmax = 10 τ 0 ; Minimum pheromone trail τmin = 0 . 01 τ 0 ; Stopping criteria is that the maximum iteration times of 1000 are reached. For the benchmark problem, there are 12 decision variables (2 × 3 ×2, two types of weapons available to defend three assets against two types of attacking weapons), so the search space consists of 12 stages.
The benchmark problem has only 12 decision variables, for which the theoretical optimal solution can be obtained by existing optimization software. By using LINGO 11.0, we obtained the optimal objective function value of f* = 537.516 or expressed it as a normalized value,
This optimal solution indicated that the total number of defending weapons of type I to be deployed was 70 and that of type II was 50. At the theoretical optimal solution, all of the constraints were met; two constraints, the available weapons of type II and the available manpower for weapons of type I, were tight to upper bound, while the other constraints were loose. This result provided a guideline for how to improve the optimal solution. For example, the decision-maker could improve the survival value of assets by reducing part of the weapons of type I and using the saved resources to augment weapons of type II.
We also constructed another 3 × 20 × 3 numerical example of the WTA problem. This example can be considered to be a large-scale WTA problem relative to the small-scale benchmark problem. The scenario of the problem was set as follows.
Defender: The defender plans to build a three-layer defense system with D = 3, in which ordinary missiles, tactical missiles and ballistic missiles are deployed at the first to the third layer, respectively. The number of strategic assets needed to be protected by the defender is 20, namely, S = 20. The available numbers of defensive weapons of types 1, 2 and 3 are B1 = 560, B2 = 300 and B3 = 140, respectively. The manpower needed to operate per defensive weapon of type 1, 2 and 3 is m1 = 6, m2 = 5 and m3 = 4, respectively. The available number of professionals to operate defensive weapons of types 1, 2 and 3 are M1 = 3500, M2 = 1600 and M3 = 500, respectively. The operation and maintenance cost per defensive weapon of type 1, 2 and 3 is c1 = 20, c2 = 30 and c3 = 40, respectively. The overall operation and maintenance budget for defensive weapons is Cmax = 25000. The ground area that is required for deploying individual defensive weapons of type 1, 2 and 3 is t1 = 32, t2 = 48 and t3 = 72, respectively. The value of each asset and the space available for deploying defensive weapons at each asset are listed in Appendix A of our prior work [20]. The successful intercept probabilities of various defensive weapons are given in Appendix B of our prior work [20].
Attacker: The enemy has three types of offensive weapons, A = 3. The number of attacking weapons of type 1, 2 and 3 is A1 = 275, A2 = 170, A3 = 95, respectively. The enemy’s attacking plan and the destroy probabilities of various offensive weapons are given in Appendix C of our prior work [20].
We used MMAS algorithm to solve the benchmark problem under the experiment environment based on Spark cluster with Intel 2.6GHz and 3GB RAM on every node. The best objective function value over 10 random runs was 0.596377, the corresponding optimal solution was:
Note that this solution was close to the theoretical optimal solution. At this solution, the numeric constraint on the weapons of type II and the manpower constraint on the weapons of type I were tight to upper bound, while other constraints were loose. This scenario was consistent with the features of the theoretical optimal solution. The results obtained for 10 consecutive random runs were listed in Table 3.
Results of 10 MMAS Random Runs (2 × 3 ×2 problem)
Results of 10 MMAS Random Runs (2 × 3 ×2 problem)
Table 3 also gave the relative deviations of the objective functions attained from the theoretical optimum. The coefficient of variation, denoted by CV, was used to measure the stability or robustness of an algorithm.
where μ and σ was the average value and standard deviation of the objective function over 10 runs, respectively. The smaller the coefficient of variation was, the more robust or stable the algorithm was. The CV for the benchmark problem was only 0.1073%. Very small relative deviations as well as coefficients of variation, means that MMAS algorithm can obtain satisfactory solution to the benchmark problem with high robustness.
For the 3 × 20 × 3 WTA problem, there are a total of 180 integer decision variables for which optimization software like Lingo is inapplicable. Now we applied MMAS to solve this problem. In order to get better solution, we set the size of ant colony m = 1000 and the maximum iteration 2000. Ten random runs were performed under the same experiment environment as that of benchmark problem. The results obtained for 10 random runs were listed in Table 4. The CV was 0.2714%. The average CPU time over 10 runs was 19.2 minutes. Very small coefficient of variation implied that even for a large-scale WTA problem, MMAS could obtain a robust result.
Results of 10 MMAS Random Runs(3 × 20 × 3 problem)
We also compute some results under the same scheme and parameter settings, except that the size of ant colony m = 2000 and the maximum iteration was increased to 5000. We obtained the best objective function value of 0.66803, whose optimal solution was shown in Table 5.
Optimal Solution to the 3 × 20 × 3 WTA Problem
At this optimal solution, the total cost required was 25000 which was tight to upper bound. The numbers of various defensive weapons actually deployed and manpower required for each weapon type were listed in Table 6. The spaces actually occupied at each asset were listed in Table 7.
Numbers of various weapons deployed and manpower required
*constraint was exactly satisfied.
Spaces required at each asset
Next we evaluated the distributed computation performance of the algorithm. We built an extreme case in which the algorithm performed only one iteration but generated 1000 ants by using one executor and two executors respectively. Each executor set up only one task. The snapshots of the results were shown in Figs. 4 and 5.

Result for generating 1000 ants using one executor.

Result for generating 1000 ants using two executors.
We found that the number and input data size of total tasks (accumulatively created rather than generated simultaneously) distributed to two executors was equal to that distributed to one executor. The distributed compute worked actually and assigned jobs to two executors almost equally. The run time recorded in Spark was optimized slightly, because the pheromone trail updating in the algorithm necessitated shuffling all objective function values computed by ants. The shuffling procedure consumed some time. Of course the computation efficiency can be improved by amplifying the number of executors.
Abovementioned experiment set only one task to run the program in each executor. However each executor could set up N tasks running concurrently like threads in computer system. Then we deliberated whether the computation efficiency could be optimized by using more tasks. We set different partitions to arouse needed tasks. Figure 6 depicts the relationship between the running time for one iteration generating 1000 ants with the number of tasks. Here the running time refers to the average time over 10 random runs.
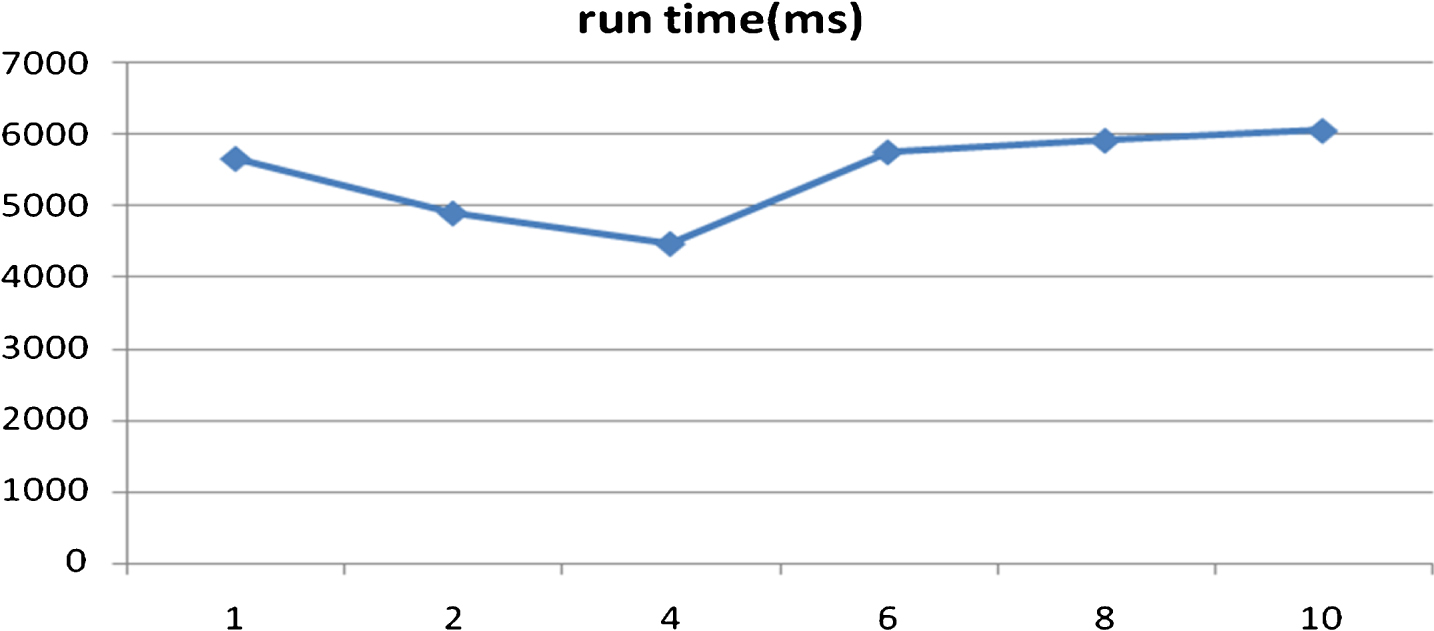
Run time(ms) for tasks num from 1-10.
From Fig. 6 we found that the best computation efficiency derived from 4 tasks set by each executor. For more than 4 tasks, with the number of tasks increased the computation efficiency declined. This is because there were no enough threads in computer node to set up more tasks so that many tasks had to share one thread in fact. The experiment illustrated that the tasks set in every executor worked and the computation efficiency could be optimized by setting proper number of tasks.
Abovementioned experiment and analysis only addressed the benchmark problem. Furthermore we considered the large-scale WTA problem with 180 decision variables. The aim is to demonstrate whether the computation efficiency was still satisfactory when using Spark framework to large scale WTA problems. We still performed one time of iteration generating 1000 ants under 2 × 3 ×2 problem and 3 × 20 × 3 problem respectively, where 2 executors were set up with 4 tasks in each executor. The results were shown in Figs. 7 and 8.

Task Time in 2 × 3 ×2 problem.
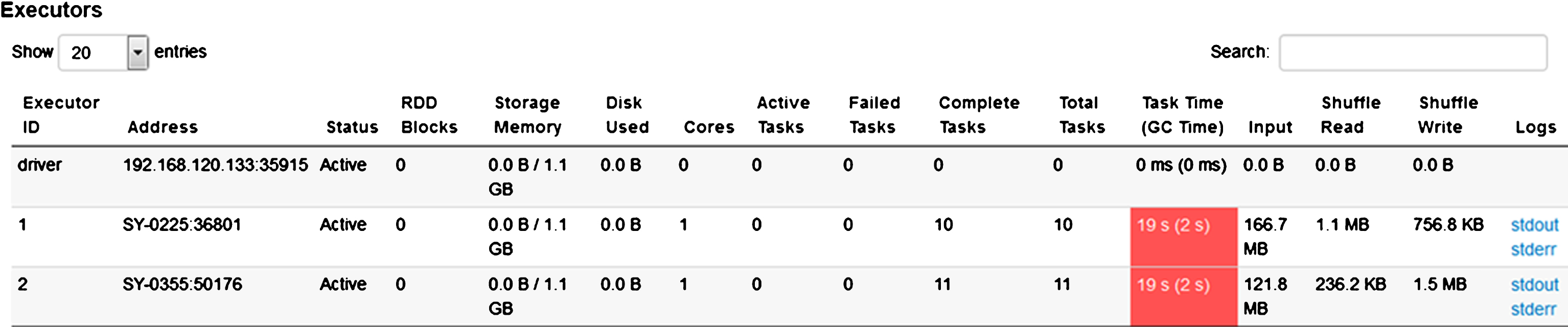
Task Time in 3 × 20 × 3 problem.
Both experiments produced a total of 21 tasks (accumulatively created). Because the number of variables in 3 × 20 × 3 problem was 15 times larger than that in benchmark problem, the large-scale problem had more input data size (288.5M compared to 10.9M). However the task running time for 3 × 20 × 3 problem was just about 2 times longer than that for the benchmark problem (19s compared to 10s or 8s). This demonstrates that the Spark framework is suitable for large-scale iterative heuristic computation. It may achieve satisfactory performance in both solution quality and computational efficiency when used to even larger scale WTA problems as well as similar combinatorial optimization problems.
The WTA problem is a classic NP-complete problem from military operations research. In big data environment new algorithm using more effective computation framework needs to put forward for disposing of this kind of problem. In this paper, addressing the WTA problem in a multi-layer defense scenario, a distributed MMAS algorithm based on Spark framework were developed. The algorithm implementation schemes were presented. Through a small-scale benchmark problem and a large-scale problem, the performance of the algorithm was assessed. The results show that the distributed MMAS algorithm based on Spark framework are effective for WTA problems and can achieve a high-quality approximate solution with high robustness. From performance improvement point of view, many heuristic algorithms can be incorporated into Spark framework for solving such large-scale iterative optimization problems as WTA problem.