
Abstract
This article introduces a different method for text representation in order to perform clustering over different articles which, arguably, has no subjective information with similar topic-sentiment use of language. Using the joint sentiment/topic model, the text is vectorized in a low dimensional space. These vectors were then used as distance measurement for clustering texts. While comparing this unusual method with a traditional bag ofwords representation an improvement in the performance of the algorithms was observed. The authors think this method of representation might have implications for future studies of the computational interpretation of texts.
Introduction
The idea of performing text clustering is defined in [3] as a way to organize different documents of a collection into several clusters in an unsupervised fashion. Each of these k clusters contains documents that are similar in some way, traditionally on the meaning of the words and the concepts they convey. In the same vein, ideally different clusters should be as different of each other as possible. However, clusters that are different in one aspect, for example lexical words appearing in them, might be similar in other, like the point of view they express in different events.
In order to achieve clustering, there are several techniques, the most common being the K-means algorithm [7]. Some other methods include hierarchical clustering algorithm [19] and topic clustering algorithm [14, 30]. In general, the first step in the clustering process is to represent a document as words. Later, each document is mapped into a multidimensional vector that is obtained on the frequency of the words chosen as features. Because of the way the natural language behaves, these vectors are highly sparse and of very high dimension order.
These procedures create two main problems. The first one is that obtaining vector similarity among vectors of large size, or many dimensions, is difficult. The second one is that all these methods assume that appearance of words is independent and that all the meaning of a word, as well of the intention it carries, are the same every time it appears. Natural language statements are not like this, though.
In order to overcome all these difficulties, capturing more efficiently different meanings of words in different contexts, this paper introduces a novel use of a method which is based on topic modeling, namely Latent Dirichlet Allocation (LDA) [4] with some added layer of sentiments, as proposed by the Joint Sentiment/Topic Model (JST) [16].
Even though the method was developed for simultaneously extracting sentiments and topics, this piece of research shows that it can be used for representing non-opinionated documents, such as news articles.
In Section 2 a summary of works related with text representation is introduced, in Section 3 works dealing with text clustering are discussed. Then on Section 4 an explanation of how Joint Sentiment Topic Model works is given. Section 5 presents how this new representation can be used for performing document clustering, as well as the results of that experiment. In Section 6 the results of the experiment are discussed along with comparison on other works. Finally conclusions are presented in Section 7.
Text Representation
Clustering of texts has been proven as an important task of text processing, with text mining, information retrieval, and automatic summarization, among others. In order to perform clustering, one of the most common ways of representing documents is through bag of words (BoW). This method consists in considering each different word as a dimension, then each document is a vector in which each component is the weight of every word of the vocabulary within the document.
BoW has shown to be a convenient way to represent a text by the words it uses. However, it fails to capture some important features of natural languages, like syntax and the semantic orientation of each word.
To solve these problems, different types of representations have replaced the bag of words approach. There are special kind of methods which take into account which words co-occur in certain, so called, context, and are known as distributional methods.
Distributional methods have had a great acceptance and they are the state of the art for many tasks [5, 24]. These techniques are inspired by some of the writings of Harris [12], who said that there are distributional regularities between different items of natural language. Based on this idea, Sahlgren [25] states that words occurring in similar contexts will have similar meanings.
Taking into account the previous ideas, there have been several attempts to represent words by their distribution among documents. These Distributional Space Models (DSM), as they have been called, have shown better performance than the simple discrete bag of words method.
Some examples of these methods are Probabilistic Latent Semantic Analysis (pLSA) [13] and Latent Dirichlet Allocation (LDA) [4]. These two methods are based on the idea that co-occurring words are similar, however, both of these are use the probability of occurrence and co-occurrence, not just on their count. They also create “topics” of the document. While pLSA is a statistical technique using a latent class model, LDA is a generative extension of it. For these models, a topic is a specific distribution over words of a given vocabulary.
Also, among the DSMs, there are other proposed models like Hyperspace Analogue to Language (HAL), BEAGLE, random indexing, and others [5].
Finally, Bengio et al. [3] proposed a stochastic neural model based on Soft-Max regression. In this way, a vector space based on this model was presented in [18]. This embedding method performed better than the regular DSMs as was shown by Baroni et al. [2].
Besides representing documents as vectors, it is possible, following transitions from words, to represent them as graphs. This representation has the advantage of not loosing word order, on the contrary, they exploit this to form their graphs [10].
Text data clustering
As discussed in Section 2, vectors representing the text of each documents are usually normalized taking into account different document lengths. This normalization makes possible to compare documents independently of the total amount of words they have. As a result of this, this vector space model [25] has many dimensions because there are, usually, a large amount of different type terms, often in the order of the thousands. Because of this, there is a huge dispersion of the tokens, what produces a largely sparse matrix representing the collection of texts.
As this matrix creates a discrete bag of words (BoW), the traditional way to measure similarity between documents is a lexical one. This is, to measure how much of vector representing d1 overlaps on vector representing d2. The geometric way of doing this, is by computing the dot product of both vectors and normalizing by the product of both norms. This procedure is the cosine angle between those two vectors.
As stated in Section 1, there are many different algorithms for performing clustering. These might be classified as: Partitioning algorithms. These are those as k-means or k-medoid in which data is split into k different groups ideally not related between them. This is, each cluster should be as compact as possible and as separated from other clusters as possible. hierarchical algorithms. Example of these are the Single-Link or the Average-Link [15]. In these algorithms, partitions are formed within clusters until all data points are organized in a specific cluster, thus forming a dendogram.
There are also algorithms that combine both approximations. One of these is the well known Scatter/Gather [8]. This was originally designed for a system of document browsing which is based on clusters. It first uses a hierarchical algorithm to find a first approximation of document clustering, the result of this first approximation is later processed by using a partitioning algorithm (k-means) in order to find better clusters.
The work of [29] compares hierarchical as well as partitioning methods on a different variety of test datasets. That study concludes that k-means is better, in terms of performance and clustering purity, than different hierarchical methods.
Joint Sentiment Topic Model as text representation
In this section the Joint Sentiment Topic (JST) a model presented in [16] is described. After that, an explanation of how and why this could be suitable for different tasks of natural language processing and text mining.
Joint Sentiment Topic Model
Latent Dirichlet Allocation [4] is based on the assumption that documents are a mixture of topics, where a topic is a probabilistic distribution over words that appear in it. In a broad way, the procedure in order to generate a word in the document can be summarized in to steps. First, a distribution is drawn from a mixture of T topics-per-document. Then, a topic is randomly drawn from the per-topic distribution and a word is taken from that topic according with it corresponding topic-word distribution.
Traditional LDA is composed by three hierarchical layers. In them, topics are associated with documents and words with topics. In order to model the semantic orientation [31] a joint sentiment/topic model is proposed in [16] by adding a layer between document and topic layer. In this way, this model is a four-layered one, where the sentiment labels are associated with documents in which topics are themselves associated with sentiment labels and words associate with both, topics and sentiment labels.
In this way, the Joint Sentiment/Topic Model (JST) is as follows:
Let’s assume there is a corpus with a collection of D documents, represented by C = {d1, d2, …, d D }; each document within the corpus is a sequence of N d words, expressed as d = (w1, w2, …, w N d ) and each word in the document is an element of a vocabulary set with V different terms: {1, 2, …, V}. The number of different sentiment labels is S and the number of different topics is T.
So, the procedure to generate a word w
i
in the document d follows three steps: Choose sentiment label l from the document-sentiment distribution π
d
. Choose the topic from the topic distribution θd,l where θd,l is conditioned by the sentiment label l previously chosen. draw a word from the corpus word distribution according to the topic and sentiment label.
It is important to note that topic distribution in this model is different to that proposed by LDA. While LDA there is just one topic distribution θ per document, in this model each document is related with S (amount of sentiment labels) topic distributions, where each of these l distributions has the same amount of topics. Because of this, it is possible to relate the semantic orientation with the extracted topic. The last step is different from LDA because in JST model word is not conditioned just by the topic.
Formally, the generative process, shown in fig.1, for JST is: For each label sentiment l in l ∈ {1, …, S}: For each topic j ∈ {1, …, T}, draw For each document d, choose a distribution π
d
∼ Dir (γ) For each sentiment label l in document d, choose a distribution θ
dl
∼ Dir (α) For each word w
i
in document d choose a sentiment label l
i
∼ Mult (π
d
), choose a topic z
i
∼ Mult (θd,l
i
), choose a word w
i
from φ
l
i
z
i
, a Multinomial word distribution conditioned by topic z
i
and sentiment label l
i
.
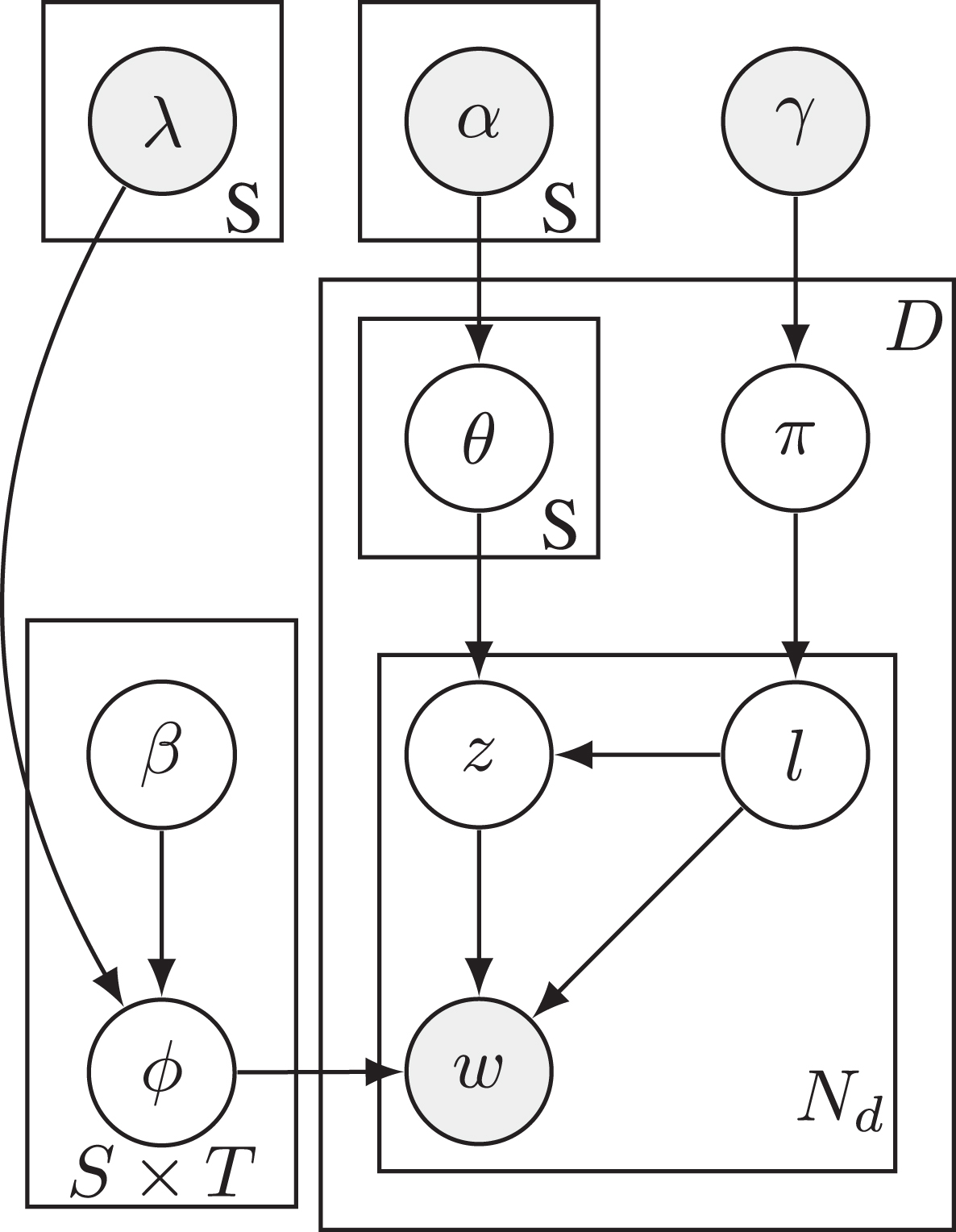
JST Model.
In fig.1, it is possible to observe a plate diagram of the Joint Sentiment Topic Model as originally proposed.
Hyperparameter α might be understood as the prior counting of the topic amount j related with sentiment label l that has been sampled from a document. In a similar fashion, β is the prior of the number of words that has been sampled from topic j related with sentiment label l before any word observation. The hyperparameter γ might be interpreted as the prior count of times that sentiment label l has been sampled from a document before any word of the corpus was observed. The latent variable sets that must be inferred, are: per-document sentiments distribution π, specific sentiment label of the per-document topic distribution θ, and sentiment/topic word joint distribution φ.
This means, π is the distribution of sentiments in a specific document for all the documents, θ is the specific topic distribution dependent on a given sentiment label on a particular document for every document in the collection, and φ the joint distribution on the corpus of the words given a topic in a specific sentiment for all the topics in all the sentiment labels.
The prior semantic orientation of the words, is encoded in the matrix λ. The shape of this one is S × V. This matrix might be seen as a transformation of the prior β.
So in this model, the Greek letters represent different prior distribution and the Latin represent the computed distribution. A thorough explanation of the model and its implementation can be found on [16, 17].
The use of topics for clustering documents has been shown a good approach on different tasks [1, 26]. By using JST it is possible to create a dense, low dimension matrix embedding sentiments and meanings in such a fashion that clustering would be possible.
By taking advantage of a representation that encodes in a dense vector space meaning of the words, as well as the semantic orientation (sentiment) which they are carrying, the document would have another form of being processed. This is, the assumption is that meaning of a word is not complete unless the semantic orientation of the word is known.
Following this idea, it is possible to model a document, even allegedly objective ones, such as newspaper informative news reports, as a vector containing the meaning of their words, as traditional LDA would do, as well as the semantic orientation being expressed by the appearance of these words, as JST propose.
To achieve this representation, an initial sentiment lexicon is needed. This lexicon should be distributed by the amount of sentiment labels required:
Where l is the number of labels and S i is a real number representing how much of the word w belongs to the i th sentiment label. For example, if there are six sentiment labels, each word should be represented as six real numbers such that the sum of the six is one.
Usually distribution is not equal, but there is a label which overweights the other, thus it is possible to assume that the word belongs with more centrality to that label.
Once that the lexicon is defined, the JST inference over the words representing the corpus could be done as explained in 4.1. After inferring all the variables that, under the model, generated the text, it is possible to observe the different φ, θ and π representations.
Once these representations are obtained, the model might be used for different text mining tasks, such as clustering.
As it has been explained in 4, there are different sets that are inferred when getting the JST Model. We will treat the result of inferring these sets as a vector representation of the document.
So, there are different representations that can be done. The text might be represented as a sequence of w:l:t. This sequence would encode the token w, the sentiment label l assigned to that specific token in that specific document and the topic t assigned to that specific token in that specific document. By doing this representation, the size of the vectors is inconveniently large. It is V × S × T, where V is the size of the vocabulary, S is the amount of sentiment labels and T is the number of topics. Because of this, this representation would be unpractical.
Instead of words or terms, or the embedding of each word in a context window being a dimension, the document is represented by the proportion of topics associated with sentiment that lies within it. This is the matrix θ computed when estimating the joint sentiment topic model. As stated, this is the set sentiment/topic word joint distribution.
In this set, each document is represented as a matrix. Each row represents a sentiment label, and each column represents a topic. The number in each cell is the proportion of sentiment l associated to topic t in the specific document d. Thus each document turns into a matrix of size T × S. Each of the cell contains the proportion in which topic t is associated with sentiment label l. Thus, the sum of each row is 1.
A third possible document representation that allows the JST model, is a more dense and with lower representation. This is that extracted from the π set. In that set each document is represented by the distribution of th l sentiments within it.
Text Clustering by using JST
In this section the experimental setup and case of study of JST for clustering non-opinionated documents is explained and raw results are showed.
Spanish Emotion Lexicon Modified
The JST model, as a weakly supervised methodology, requires a sentiment weighted lexicon in order to know the prior sentiment distribution.
For this experiment we used a lexicon prepared by Sidorov, [9, 27]. called the Spanish Emotion Lexicon1. This lexicon has few words and is split in six basic emotions: (joy, sadness, anger, fear, disgust, surprise). Each word has a probability factor of affective use (PFA). This is a measure of the probability of association of the word with the emotion. It is based on how many annotators labeled the word as belonging to an emotion with null, low, medium or high value.
As we were trying to use three sentiment labels, we had to reduce the six categories into three. By asking to different humans, they agreed that “joy” was a positive sentiment while “sadness”, “anger”, “fear” and “disgust” were negative feelings (in general). They also agreed that surprise was not neutral but depending on the cause of the surprise could be positive or negative, therefore we discarded the words that were labeled only as surprise, words belonging to “joy” were considered as positive and the rest of the words were treated as negative.
In order to get a probabilistic model, it is required that all sentiment words has a chance to occur. Some of the words of the lexicon had, already different polarities, however, there were many that had just one polarity. In order to give all the words a chance to belong to any of the three labels, the SEL was normalized in such a way. For attaining this normalization, the probabilities were rearranged following Zipf distribution. This was done based on different observations of the behavior of sentiments in the words.
Newspaper Corpus
The newspaper articles that are going to be used for this experiments are all informative journalism [6, 11]. This is because we are interested in observe how well the JST model performs in a piece of text that is supposedly objective (factual information).
All the articles are about economy and finances. Being all notes from a single subject, we aim to cluster more coarse grained domains, but using a model designed to capture sentiments, we think we could cluster the news for domain/sentiment.
One of the relevant factors taken into account in order to select the subject, was the fact that the information expressed in the articles could be more fact based, as finance and economy are objective data based. Also we choose this subject as it is of great importance in different ranges of social life.
Once we have had specified the subject, we extracted the articles from all the printed newspaper of nation wide publication that belonged to it. For this, we used a private database that store the papers. By that time we got access granted from January to October of 2014. So all the newspapers are from those dates. This will allow to have wide variability of the subtopics dealt within the main topic of economy and finances.
The bulletins that were replicated by more than one newspaper were deleted so they would not affect the volume of words as duplicated articles. If different articles deal with the same event, but are from different authors, they were allowed to stay as that would let observe different features, different points of view and, therefore, different use of language.
Author Clustering
PAN is a series of scientific events and shared tasks on digital text forensics co-located with the Conference and Labs of the Evaluation Forum (CLEF). During 2016, they held an author clustering task.
According to their task: Author clustering is a task where given a document collection the aim is to group documents written by the same author so that each cluster corresponds to a different author.
For that year, they established the task as given a collection of (up to 100) documents, identify authorship links and groups of documents by the same author. All documents are single-authored, in the same language, and belong to the same genre. However, the topic or text-length of documents may vary. The number of distinct authors whose documents are included in the collection is not given [28].
Text Clustering
To perform the text clustering, in the case of the Author Clustering task, the pre-processing steps that were followed are going to be described. First the texts were tokenized by words. All the punctuation marks and a list of common grammar words that add not much semantic information to the document were deleted. This words are better known as stopwords. After that a process of stemming was performed over each document and the new versions were saved.
A base-line representation was constructed by traditional vector space model. Each document was represented by the words it contained. Hence, this generated a large sparse matrix for each problem. Es there were six different problems, there were six different matrices.
The first one had 50 documents and 2186 different words, so this created a 50 × 2126 matrix. In problem 002 the matrix generated was very similar and it had the shape of 50 × 2187. For problem 003 it was 50 × 2118. In problem 004 the number of documents now was 80, and the shape of the matrix was 80 × 3961, for problem 005 it was 80 × 4245 and finally in problem 006 the matrix took the shape of 80 × 4086.
Finally, these matrices were used to perform clustering. As the ground truth was known, the real number of clusters were directly used as the idea for this particular problem was not to find the best way to establish an optimal number of clusters but to know if a new representation performed better in some ways.
Since the idea is to reduce the number of dimensions necessary to represent the text, and therefore create dense matrices, this experiment was performed using the implementation of the JST algorithm is the one made by Chenghua Lin and Yulan He 2. The number of topics were established to 1, 10, 20 and 30. More topics would create not dense matrices as the maximum number of documents were 80.
The θ and the π representation were used. As stated before in Section 4.3, the θ set represents each document as a matrix where each row is a sentiment and each column is a topic. For the sake of this experiment, the matrix was flattened by concatenating each row at the end of the previous one. In this fashion each vector has a size of 1 × (T × S).
Because the properties of the dictionary used, as explained on 5.1, three sentiments were considered. This means that the size of vectors were 1 × 30, 1 × 60 and 1 × 30 dimensions instead of matrices of 3 × 10, 3 × 20 and 3 × 30 for the 10, 20 and 30 topics respectively. This reduction allowed that for all problems the shape of the matrices representing the corpus were n × m, where n is the number of documents in that particular problem and m is the triple of the number of topics.
In the case of 1 topic vector, each document in the corpus was represented as a 1 × 3 matrix. However, as each cell in the matrix was the distribution of the only topic for each sentiment label l, the number in every cell of every document was 1, hence that particular representation became totally useless.
When using the π representation, all documents were represented as three dimensional vectors. Each cell represented the proportion of each sentiment in the document. Thus this representation showed how much of each of the sentiment label was in the text. In other words, it could be seen as how much of the text belong to each of the sentiment sets.
After having the different representations, each one was used to feed a k-means clustering implementation. Each clustering was repeated 10 times and the best results were reported.
All representations were evaluated in order to observe if different representations could behave in different ways. In order to obtain an evaluation, we performed clustering over a set of news as described in 5.2, and over a corpus obtained from the PAN 20163 competition.
Results
By evaluating the clusters obtained by using the explained representations (Section 5.4), the results obtained allowed to observe if the hypothesis that sentiments help to better represent the text was true.
Because the ground truth was known for one of the corpora but not for the other one, the evaluation performed on them was different. The ground truth was known for the Author Clustering Task, while the expected clusters were unknown for the News Articles Corpus.
For the News Articles Corpus, the evaluation performed was intrinsic. This is, the silhouette of the clusters was analyzed in order to determine how far apart were each cluster from the closest one while knowing how close were the data points belonging to each one. This silhouette score (S-score) is such that -1≤S-score≤1. If the number is negative it means that clusters are not well formed and are scrambled. Positive numbers mean they are well formed. If S-score is close to 0, it means that clusters overlap with each other.
On the other hand, the evaluation performed on the Author Clustering Task corpus was a more traditional one, based on knowing what the expected clusters were. This allowed to perform a measurement of precision, recall and f-score.
In the Table 1, it is possible to observe the f-scores for the six different problems that were needed to solve in the Author Clustering Task. The scores are those of the f-score got in the number of clusters belonging to the ground truth. This is, in problem 001, the ground truth established 25 clusters, so the f-scores reported are for 25 clusters got using different vector representations and using the k-means algorithm.
F-scores for the Author Clustering Task
F-scores for the Author Clustering Task
As can be observed, the JST model θ representation outperformed the f-score in three of the six problems observed. However, the results were similar. It is also possible to observe that the π representation never outperformed the baseline, but reached the same level in different problems.
A different method of evaluation which is more proper for evaluating clusters, given the ground truth is known, is the measure of homogeneity and completeness and the v-measure [22]. Homogeneity is the measure of how many different classes are in a cluster. Ideally all the elements of a cluster should belong to the same class. Completeness is the measure of how many of a given class got into the same cluster. Ideally all the elements of the same class should belong to the same cluster.
The computation for conditional entropy and entropy in Equation 5.5 are symmetric to Equations 3 and 4 respectively.
The score is a real number between 0 and 1 for both of them. A homogeneity of 1 means that all members of a cluster are of the same class. Similarly, a Completeness score of 1 means that all the elements belonging to a single class got grouped into a single cluster.
The harmonic mean of this two measures is called V-measure. This is computed as:
If homogeneity and completeness were both 1, the v-measure would be 1. As it is possible to observe from this formula, the value get closest to the lower value. This forces a system to focus on both measures to uprise the v-measure.
This is arguably a better method than Precision and Recall and F-measure for evaluating clustering because it takes into account not just the values of true or false but also if it performed as expected, bringing together the elements more alike and splitting out those that are different.
In Table 2 the v-measures for the same clusters are reported.
V-measures for the Author Clustering Task
As it is possible to observe, by measuring the v-measures of the different clusters, the baseline is always outperformed.
In two of the six problems, the π representation performed the best. In all the other cases the θ representation was the one that performed the best.
Some details of the clustering and the evaluation are discussed in Section 6.
As explained before, the ground truth of the expected clusters and classes was unknown for the News Articles Corpus. For this reason, the evaluation must be done using the model itself, that is an intrinsic measure.
The silhouette coefficient [23] s is defined as:
The silhouette coefficient measures the arithmetic mean distance a between a sample and all the other points in the same cluster and the arithmetic mean distance b between the sample and all the points in the next cluster.
Table 3 presents the S coefficients obtained after clustering the News Articles Corpus. It presents the scores obtained for the pi, theta, and the BoW baseline. Because of the size of the corpus detailed in 5.2, the number of topics were set to 1, 10 and 20. The metric distance that was used for computing the scores was an euclidean distance.
S-scores for the News Articles Corpus
The table shows that the s-scores for the BoW (bag of words representation) stay constant. This happens because it was scored once without topics, as that representation does not uses any kind of topic. For the 1 topic case, the θ has no value as the clustering could not be performed in that case.
As it is possible to observe, the pi representation gets the best results, while theta shows many overlapping clusters, as the coefficients are closer to zero than the former. It shows that in every case, the dimensional reduction using a JST model create more compact and separated clusters from each other than the baseline BoW. Between the two representations after reducing dimensions, the best representation seems to be the pi representation. It gets the coefficients closer to 1 than the theta representation, which means that clusters are more separated from each other. These results will be further discussed in Section 6.
The results of Table 1 and 2 show that different metrics will retrieve different results.
While measuring traditional precision and recall, the proposed representations perform in a similar way to a traditional representation. However, if the measure is based on the information of the clusters, i.e. entropy, the v-measures in Table 2 clearly show that using sentiments for representing texts performs better in all the cases than a traditional bag of words representation.
It is important to observe that representations that mix topics and sentiments allowed a better clustering than those containing just sentiments or just the stem of the words. The corpus was itself a difficult one to cluster, because the clusters were too small. Many of them consisted on just one document. In all cases setting the number of clusters to the same of documents obtained the best f-score and v-measure, although it was not the right answer.
In the case of the News Articles Corpus (Table 3), it has been explained that it was just possible to measure the silhouette of each cluster. In that measure, it is observable that the pi representation, the one that contained just sentiment vectors, was the one that created more separable clusters. It is possible to think that this was due to the number of dimensions in this representation. However, an objective evaluation of these clusters, similar to that made for Author Clustering Task, is necessary in order to conclude that this new representation works better than a traditional BoW.
A qualitative evaluation performed with a small sample of documents belonging to each cluster with k = 500 was performed. This evaluation was done by extracting 5 random documents of each cluster and given to different evaluators in order to observe if they could find a structure in clusters. They observed that there were some co-occurrences of market feeling in the news, although the main topics were not completely related. This is, they observed that the articles reported a fall or rise in stocks, or there were a feeling of success or failure on some actions, etc. However, this qualitative evaluation is not reproducible, therefore it was not reported in the results section.
This gives the idea that even in financial news, where factual information is being reported, the sentiment layer of classification could help to better organize information in order to allow a better clustering of documents that are related by a more complete meaning of the message transmitted in them.
Conclusions and future work
This paper introduced the idea that a document representation, that was originally thought for reviews and other opinionated text, can be used for representing non-opinionated text. This is following the idea that the meaning of a word is determined not only by its conceptual meaning but also by the semantic orientation it bears.
In order to test this hypothesis, first a brief introduction of traditional text representation was made. Then, the paper explained the task of text clustering. Later, the Joint Sentiment Topic Model was detailed as well as how it is possible to represent text by using it.
An experiment to prove the idea was set up. This experiment was performed on two corpora. One of them was a corpus made for clustering the authors of text and the other one was a corpus of informative news reports. After that, the results were exposed and discussed.
After the clustering was objectively evaluated, it is possible to conclude different things: That using different evaluation metrics will bring different results. V-measure score is an entropy based metric that is better suited for clustering than F-measure score that is based on statistic performance. That the JST model representation is useful for document clustering. That sentiment distribution helps to complete conceptual meaning. Clustering just by sentiments might help to better separate clusters not by the main topic, but by sub-laying layer that explains what is being said about the topic.
As future work it is necessary to better evaluate the performance of clustering using JST on informative news report in order to understand that sub-laying layer that was found. It is also necessary to observe if this text representation can help to NLP and text mining tasks different of document clustering.