
Abstract
Fuzzy time series modeling has recently become an interesting topic to study. Among fuzzy time series models, the Abbasov-Mamedova (AM) model has advantages over the others because it can forecast the value that is outside the min-max range of the original data. However, the performance of the AM model strongly depends on three parameters that are user-defined. In previous studies, the optimal parameters of the fuzzy time series models have been identified with a global optimization method. Surprisingly, optimizing the parameters of the Abbasov and Mamedova model has not been solved in spite of its advantages over the others. This paper presents a new approach to improve the performance of AM model based on the evolutionary algorithm. Particularly, the objective function is calculated as the Mean absolute percentage error which will be minimized using the differential evolution (DE) algorithm. The experiments on Azerbaijan’s population, Vietnam’s GDP and rice production demonstrate the feasibility and applicability of the proposed methods.
Introduction
Forecasting is a science of predicting the future by scientific analyzing the collected data. Due to the remarkable development of science, numerous forecasting models have been proposed and demonstrated their suitability and effectiveness, so far. Although these models have contributed significantly to the forecasting theory, they still have limitations in practical application. For instance, regression models (e.g. linear regression [18, 43]) require a number of assumptions that are not always valid, whereas the time series models (e.g. ARIMA [7]) perform poorly when there are abnormal changes or the time series is nonstationary. Similarly, various models [11, 64] provided good results in considered data sets;.owever, we could not obtain the optimum solution for all cases, and most of them still have many disadvantages in real forecasting applications.
Based on the fuzzy theory of Zadeh [60], the fuzzy time series (FTS) introduced by Song and Chissom [51] is able to forecast without requiring any assumptions like regression and ARIMA. Recently, FTS has been an interesting topic and shown to be more efficient than any classical forecasting model. Using the fuzzy logical relationship table Chen [8] proposed a conventional fuzzy time series model, which is computationally easier than the method of Song and Chissom. Next, Chen [9] adapted the method in [8] for high-order fuzzy time series. Huarng and Yu [33] advanced a type 2 FTS model from the type 2 fuzzy set. Furthermore, Yu [59] proposed a weighted FTS model to resolve recurrent fuzzy relationships and assign appropriate weights to several fuzzy relationships, correctly reflecting their respective import. Abbasov and Mamedova [1] proposed the fuzzy time series model to forecast the population of Azerbaijan, where the first order difference of data is utilized. A list of researches which proposed fuzzy time series techniques to address the problem of forecasting can be found in [4, 54]. Most of the above models define the universe of discourse based on the min and max values of the original data, then fuzzify the time series and select the defuzzified value of fuzzified prediction variables;.herefore, the forecasting values always fall into the limited domain of original data, that is, they are unsuitable when dealing with the nonstationary data. For example, after establishing fuzzy logical relationship groups, the Chen model [8] uses the following rule for forecasting the output y (t + 1) at the time point t + 1:
Optimization algorithms can be decomposed into two major techniques: population-based algorithms and gradient-based searching algorithms. Recently, although there have been various population-based algorithms proposed in literature, it can be noted that the Genetic Algorithm (GA), the Particles Swarm Optimization (PSO) and the Differential Evolution (DE) are the three most popular ones. The GA [31] inspired by the natural choice and the survival of chromosomes which represent the solutions. To create new solutions, the GA utilizes some genetic operators termed as selection, crossover, and mutation. The objective is to find the best chromosome or solution after some termination conditions. The GA was performed well in many practical problems including computer vision [12], clustering [2, 55] and structural engineering problems [21, 23], etc. The PSO [35] focuses on the social behaviors of birds to solve the optimization problem. In the PSO, each solution is represented by a particle which has two main properties: the position and the velocity. The algorithm works to create new solutions through the movement of particles based on the velocity. The applications of PSO in various fields can be listed in [19, 42]. The DE [52] also uses the chromosomes to represent the solutions and generates the new ones using genetic operators like the GA but the operators are not all exactly the same as those with the same names in the GA. In the DE, the mutation operator which combines three randomly selected vectors from the population to form mutation vector plays a key role in finding the global optimum and is very different with the same operator in the GA. The DE and its variations were successfully applied to many fields, such as civil engineering, pattern recognition, etc. [13, 45]. In addition to the three above algorithms and their relevance, a large number of studies were proposed in various aspects including methodology and application [20, 46]. The comparisons of the GA, the PSO, and the DE were presented in [34, 58] in which all authors concluded that the DE has the best global search ability. Based on the best of our knowledge as well as many empirical experiments, we also identify that the GA has good ability to find the global optimum but has a slow convergence speed;.he PSO has a fast convergence speed but is easily trapped into a local optimum;.he DE is the best one when it balances both searching global optimum and saving the computational cost.
Based on the optimization algorithms, many approaches were proposed to perform fuzzy time series. Aladag et al. [3] introduced an invariant fuzzy time series model in which the membership values in the fuzzy relationship matrix are computed using particle swarm optimization technique (optimize the determination phase). However, in this research, each particle represents a fuzzy relation matrix whose number of elements is equal to the square of the number of fuzzy sets;.ence, the optimal model is obtained at a cost of increased computational complexity. Another limitation of this research is that the PSO may easily get trapped in a local optimum, according to [63]. Bas et al. [6] proposed a modified genetic algorithm to find optimal interval lengths or fuzzy sets (optimize the fuzzification phase). It is well-known that the Genetic algorithm has a slow convergence speed;.s a result, this research either takes a high computational cost or cannot reach the global optimum if a specific number of iterations is used as the stopping condition. Other methods integrating the optimization algorithm to the fuzzy time series model [36, 49] had the same drawbacks, such as taking high complexity or being trapped to local optimum. Furthermore, it can be noted that most of the above methods were formed by derivation from the Chen model, the Yu model or other models solving the problem in the original data. None of them proposed a method for optimizing the Abbasov and Mamedova model (AM) in spite of its advantages as mentioned earlier. Because the Abbasov and Mamedova model can handle the data that tend to whether increase or decrease, continuously, using the first order difference of time series, optimizing its parameters is important to provide a more accurate model for prediction.
The AM model requires three parameters consisting of the number of equal-length intervals n, the positive integer w and the constant C to be carefully selected for different data sets. However, in the studies of [1, 48], these parameters were chosen according to the author’s own experience. Hence, the built models can be unsuitable when dealing with various types of time series. For w, Song and Chissom [51] conducted a survey on the enrollment data and pointed out that the forecasting result will be better if we perform a less complex model, with a w value of two being optimal. However, this conclusion was only drawn from a small number of surveys and might lose generality. In addition, Ha et al. [28] proposed a two-stage algorithm for the AM model where the first stage identifies n, w and C before passing them to the AM model in the second stage. The major deficiency of this research is that the parameters n, w and C were separately examined and their interactions were not investigated. Therefore, a method that can evaluate the quality of the model when simultaneously changing the three parameters is highly desirable. Based on the above idea, this paper proposes a method for optimizing the quality of the AM model using the DE algorithm. We term the new model simply as the DEABB model in which the parameters n, w and C are selected so that the mean absolute percentage error, MAPE, is minimized. The contributions of this research are listed as follows:
In the DEABB, the optimization algorithm is applied to the AM model rather than the others;.herefore, the proposed method can forecast the values that fall outside the min-max range of the original data, whereas most of the previous models are not able to forecast those kinds of values. In the DEABB, three parameters including n, w and C are optimized, where n denotes the number of intervals used in fuzzification phase;.C has effects on the value of membership function;.nd w represents the number of years used to establish the fuzzy relationship in determination phase. Therefore, the proposed method can optimize the model in both fuzzification and determination phases when the previous methods often optimize one of them. The DE has a better convergence behavior in comparison with the GA and the PSO;.s a result, it can be expected that the proposed algorithm, DEABB, ensures both finding the global optimum and saving the computational cost thereby overcoming the drawbacks of existing methods. In addition to academic contributions, the DEABB can yield good forecasting results when dealing with the real-world data, such as Vietnam’s GDP and rice production, etc. The gross domestic product (GDP) is one of the major measures of nation’s economic health, whereas the rice production forecasting is one of the most necessities for a successful agricultural economics. Therefore, providing a more accurate forecasting has a significant meaning for the government. The proposed model is programmed in R, an open-source or free license that is easy for the user to refer, apply and modify.
Table 1 briefly summarizes some properties of the DEABB and previous methods to clarify the proposed method’s contributions. The remainder of this article is organized as follows. In Section 2, the preliminary issues of the fuzzy time series and the AM model are reviewed. The DE algorithm as well as the proposed method is introduced in Section 3, illustrated and applied in Section 4. Section 5 is the conclusion.
The comparison of the DEABB and the existing algorithm properties
The fuzzy time series
Let Y (t) ∈.R, t = 0, 1, 2, ….e a time series, with a generic element, y t . If μ A (y t ) is the membership function which is a mapping from the universe containing Y (t) into [0, 1] and F (t) = {μ A (y0), μ A (y1), μ A (y2), …} is a collection of μ A (y t ) then F (t) is called a fuzzy time series.
The Abbasov-Mamedova model
Given the historical data X
t
which have m number of records, t = 1, 2, …, m, the AM model suggested by Abbasov and Mamedova [1] is formally presented by the following process.
Based on the defuzzified forecast variation V (t) and the previous value X (t - 1), the forecasted output X (t) is obtained using the formula:
Let X and
By applying the above criteria, the forecasted result of a model can be evaluated. The model with the lowest MAE, MSE, MAPE should be used for forecasting.
The differential evolution algorithm
The differential evolution algorithm, DE, is a well-known global search method based on population, designed to deal with the problems which can be continuous and discrete [52]. The DE dominance is proved through the effective and robust performance both in benchmark and real-world problems. There are four major phases in the procedure of DE including initialization, mutation, crossover and selection.Initialization
In the initialization phase of the DE, NP individuals are generated through a random sampling technique which can be formulated mathematically as:
rand/1:
rand/2:
best/1:
where integers r1, r2, r3, r4, r5 are randomly selected from {1, 2, …, NP }.nd must satisfy r1 ≠.r2 ≠.r3 ≠.r4 ≠.r5 ≠.i;.F is the scale factor and randomly chosen within [0, 2];.xbest is the best individual in the current population.
Crossover
After completing mutation, we calculate a trial vector u
i
for every target vector x
i
by substituting some components of the vector x
i
by some components of the mutant vector v
i
. The calculation can be carried out by the binomial crossover operation which can be formulated mathematically as:
Selection
Finally, each trial vector u i is compared to its target vector x i . The vector providing better objective function value is reserved for the next generation. The search will be executed as long as g <.maxiter, where g is the current iteration and maxiter is the maximum number of iterations.
As mentioned earlier, the AM model performance relies on the choice of parameters n, w, and C. The proposed method uses the concept of the optimization problem for the fuzzy time series problem. In particular, we propose a method to minimize the mean absolute percentage error for the AM model using the DE algorithm. Initially, because the DE defines a solution as a chromosome, it requires the solutions of n, w, and C to be encoded. The encoding phase is summarized in Fig. 1. It can be clearly seen from Fig. 1 that a possible solution is defined as a chromosome containing three genes which represent the values of n, w and C, i.e. the size of the chromosome will be the same as the number of variables. The MAPE can be viewed as the implicit objective function of n, w, and C, i.e., the values of MAPE can be different with different chromosomes.
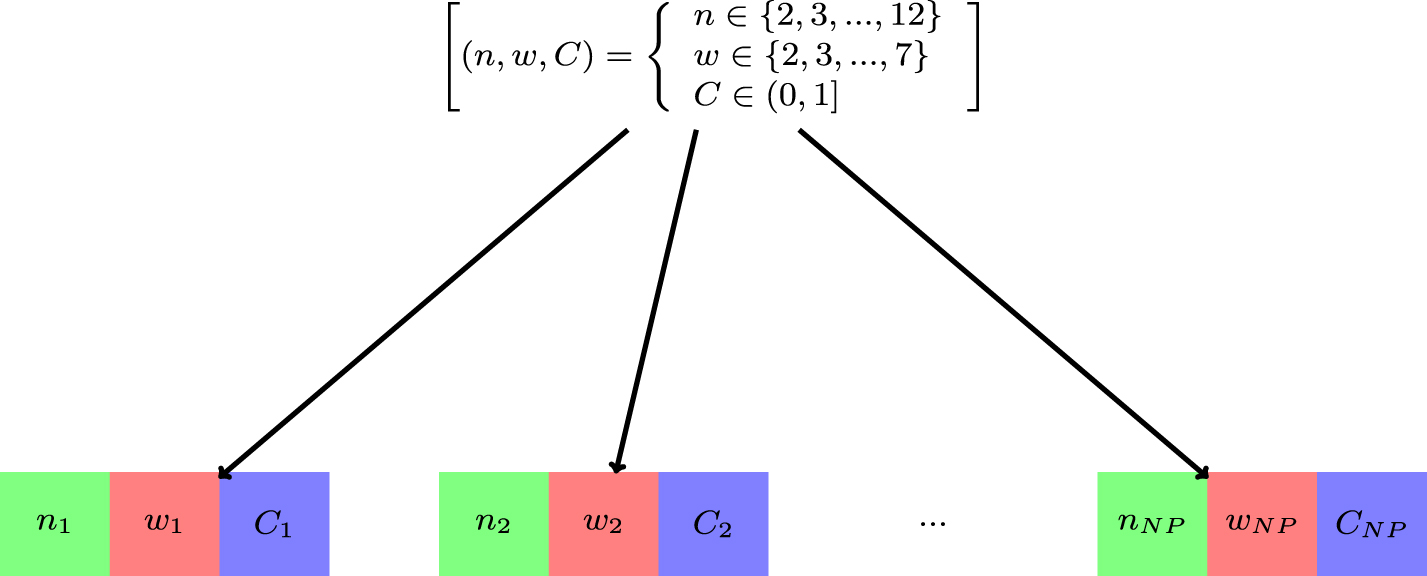
The illustration for the encoding.
After completion of encoding phase, the chromosomes or feasible solutions can be processed by the mutation, crossover and selection operators. Through any iteration i, only a fixed number of solutions n, w, and C can be selected for the next iteration. After maxiter iterations, a chromosome which provides the smallest MAPE will be considered as the best solution and then the optimal n, w, and C are given as input into the main phase of AM model. The overall process of the proposed algorithm, DEABB, is outlined by the Algorithm 1.

The DEABB model
In this section, the DEABB model is employed to solve forecasting problems. The outline of this section is briefly presented as follows. Firstly, the detail of each data set will be presented. Secondly, we present the investigation of the effects of the mutant factor F, crossover control parameter CR, and the maximum number of iterations maxiter on the optimal solution. Thirdly, the comparison between the DEABB and the others including the models in [1, 32], the GAABB model and the PSOABB model is designed to measure the effectiveness of the proposed method. Further, the paired samples t-test is performed to validate whether the difference is significant or not. Finally, the proposed model is applied to out-of-sample forecasting.
The data sets
To evaluate the performance of the proposed method, three experiments are presented. In Experiment 1, we adopted the well-known data of the historical population of Azerbaijan [1] to illustrate the proposed method and test its performance. The Experiment 2 and the Experiment 3 are used to test the robustness of the DEABB model when dealing with the real-world data, Vietnam’s GDP and rice production. For this purpose, Vietnam’s GDP per capita (USD) from 1990 to 2015 and rice production (thousand tons) from 1990 to 2014, are adopted. The original data of all experiments can be found in [1] and http://data.worldbank.org).
The effects of the parameters F, CR, and maxiter on the optimal solution
Before the DE algorithm can perform well, a set of parameters including the number of individuals NP, the scale factor F, the crossover control parameter CR, the maximum number of iterations maxiter, require to be provided by the user. To obtain satisfactory parameters of F, CR, and maxiter for all experiments, a survey of the effects of parameters on the optimal solutions is presented in this subsection. Based on the obtained results, a suitable set of parameters can be indicated. According to [5, 44], the number of chromosomes or the cardinality of the individual set in each iteration should be set as 10*d where d is the problem dimensions, i.e. NP=30 in this paper. With NP = 30 and a specific number of iterations, the effect of the mutation operator is described in Fig. 2. The data of Azerbaijan population in Experiment 1 have a simple linear trend;.ence, it can be clearly seen from Fig. 2a that the DE can find the solution that has the minimum MAPE in almost all cases of F. In case of more complex data, such as the Experiment 2 and the Experiment 3, the effect of F on the optimum solution is clarified. Using a small value of F, the DE cannot explore the search space effectively, as a result, cannot reach the optimal solution on the completion of the algorithm. In contrast, using a high value of F results in the occasional movement;.ence, the DE has a weak exploitation behavior for reaching the global optimum in the later steps. As evidenced by Fig. 2b and Fig. 2c, the solutions of the DE are not good when F >..7 and F >. in Experiment 2 and Experiment 3, respectively. In this case, F = 1 would be a stable choice, suitable for the data sets in this work.

The effects of F.
For the crossover control parameter CR, the trial vector tends to be the same with the mutant vector when CR →. and the same with the target vector when CR →.. Figure 3 shows how the MAPE changes when increasing CR value. According to Fig. 3, the same trends are obtained for Experiment 1 and Experiment 2 when the global optimal values can be reached in almost all cases. The best CR in Experiment 3 falls in the interval [0.3, 0.7]. According to the obtained results, a CR value which falls within the range [0.3, 0.7] would give the optimal MAPE. In this case, CR = 0.5 is used in this paper to balance the properties of the target and the mutant vectors.
The effects of CR.
Using the found F and CR, we continue to survey the effect of the maximum number of iterations maxiter. Figure 4 shows the MAPE of different maxiter values for the data sets used in the three experiments. It can be seen from Fig. 4 that with the maxiter ≥.0, the global optimum can be reached in all experiments. Based on the obtained results, we choose maxiter = 60 to reduce the computational cost as much as possible. For other applications, users can choose a larger maxiter to ensure convergence to the global minimum.
The effects of maxiter.
This subsection shows the comparison for the DEABB with other well-known fuzzy time series models for the three data sets. In particular, the performance of the proposed method is compared with those of the AM model [1], the Chen’s model [8], the Huarng’s model [32]. Also, we provide the extensive evaluations and comparisons with other well-known optimization methods such as the GA and the PSO, that is, we compare the performance of the DEABB model with those of the ones termed GAABB model and PSOABB model. To ensure the fairness, in our experiments for DEABB, GAABB and PSOABB, we consider the same stopping criterion, maxiter = 60. The validation is performed using the MAPE, MAE, MSE criteria as well as the paired Student’s t-test. Figure 5 shows the forecasting results of the DEABB and comparative models for the three data sets. Table 2 shows the comparison of some forecasting performance measures for the DEABB with other models. According to the forecasting results, we can group the models into two groups: Group 1 includes the models of Chen and Huarng;.roup 2 includes the AM-based models. The Chen model calculates the output using the simple average of the middle points;.ence, it results in a rough forecast and degrades the forecasting quality. The same deficiency is also found in the Huarng’s model. The AM-based models including the original AM, the GABBB, the PSOABB and the DEABB models utilize the sum of the original data and the first difference forecast as the output and it is because of this that the forecasting results are smooth and can adapt to the original data. Consequently, their performance are better than those of the Chen and the Huarng models. The DEABB model is more efficient than the AM model when it provides the lower MAE, MSE, and MAPE as shown in Table 2. This is due to the fact that the DEABB model not only can adapt to the original data as the AM model but also can optimize the AM model parameters.
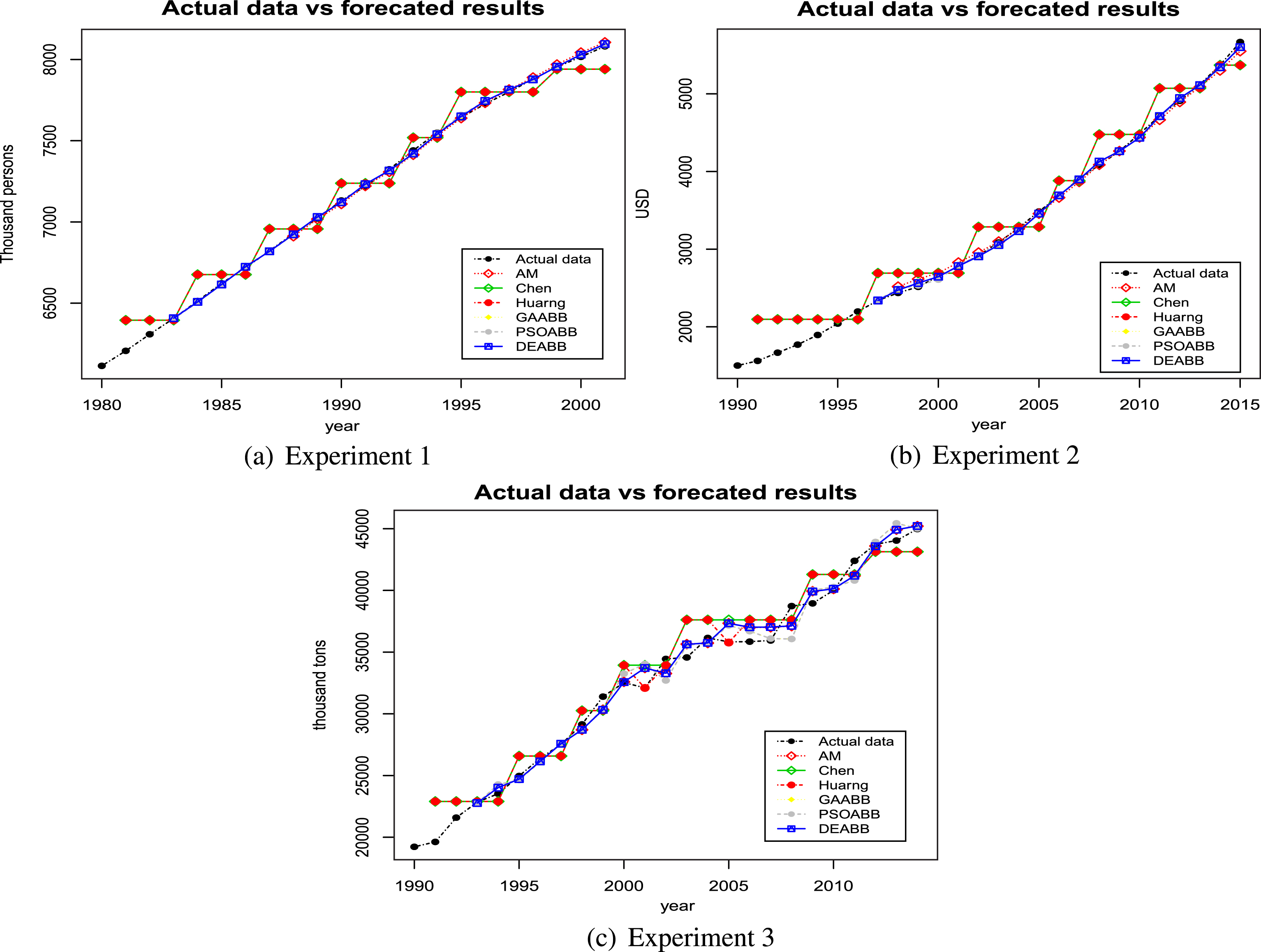
The actual data and forecasted results for all experiments.
Forecasting results of comparative models
To perform the comparisons with the GAABB and PSOABB models, we first run the three algorithms with 200 iterations. This would be very useful to obtain an overview of the convergence behavior as shown in Fig. 6. Figure 6 gives us some useful and intuitive views and we can draw some remarkable insights: (i) In the first two experiments, it can be seen that both the GA and the DE can reach the global optimum but the DE has the faster convergence speed. To reach the global optimum, it takes the DE about 5 iterations for Experiment 1 and 20 iterations for Experiment 2;.he corresponding number of iterations for the GA are about 50 and 70. Clearly, taking high computational cost is the major deficiency for the GA. In fact, fuzzy time series algorithms must be able to cope with real-time changes very quickly;.ence, to save the computational cost, we may take a smaller maximum number of iterations maxiter;.or instance, maxiter=60 as presented in the paper. In the event that maxiter=60, the GA would be stopped before converging to the global optimum. Therefore, the DE is the more feasible choice. (ii) The PSO is the worst method in the first two experiments when it gets stuck in a local optimum for a long time. In the last experiment, the PSO is better than the GA but still tends to be trapped in the local optimum. (iii) The DE can quickly reach the global optimum for all the three experiments. The comparison results in case maxiter=60 are shown in Table 2 where the lowest MAE, MSE, and MAPE are shown in bold. It can be observed that the DEABB is the best over the three experiments when providing the lowest MAE, MSE, and MAPE in most of the cases.
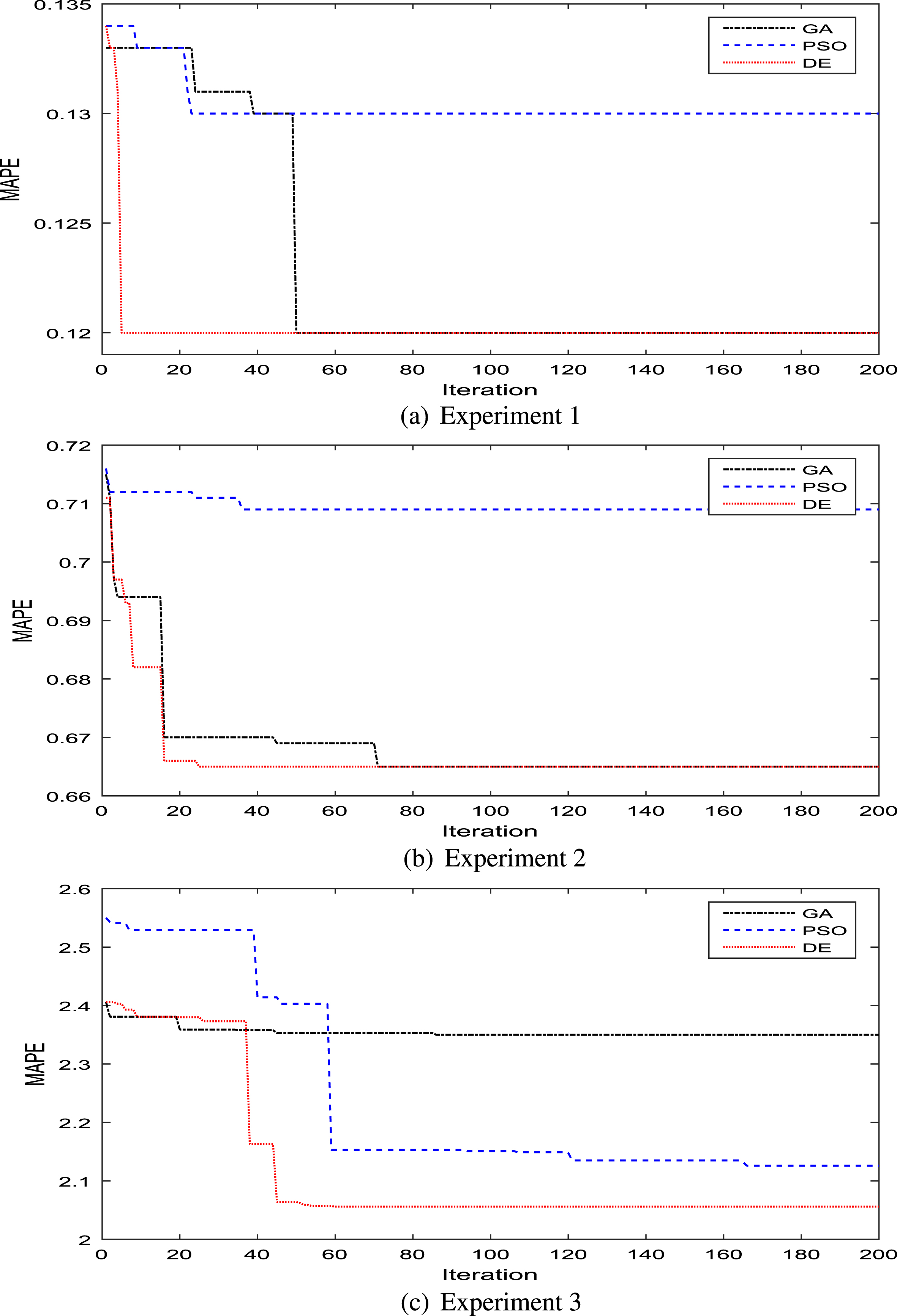
The convergence behavior.
Based on the above results and analyses, it can be initially concluded that the DEABB is more efficient than other conventional and optimization-based methods presented in this paper. However, the results are sometimes very close and are the averages of series of results;.herefore, it is necessary to validate whether the differences between DEABB and the others are significant or not. Therefore, we next perform the paired samples t-test on the forecasting results to get further analyses. Let us set the significance level at 0.1, that is, if the p-value of a test is less than 0.1 then we reject the null hypothesis or the difference is statistically significant. The testing results are presented in Table 3 where the number represents the p-value of the test. The results obtained in Table 3 confirm that the DEABB model outperforms the conventional methods in terms of error prediction. In comparison with other optimization-based methods, such as the GAABB and PSOABB models, the differences are not significant. However, according to their convergence behaviors as analyzed earlier, the DEABB would be the most likely model to reduce the error as well as the computational cost.
The results of the paired samples t-test
The previous subsection has shown the effectiveness of the DEABB model for in-sample forecasting. We now extend the discussion and conduct the out-of-sample forecasting for the next five years of Vietnam’s GDP and rice production using the DEABB model. It can be implied that the forecasting GDP and rice production of the next five years remain unchanged using the Chen and the Huarng models;.ence both of them are unable to cope with the out-of-sample forecasting. For the DEABB model, as shown in Table 4 new, the forecasting GDP and rice production in the next five years tend to increase substantially. It is possible due to the fact that Vietnam is on the path of development with economic promotion policies. It is evidenced that the DEABB model is a new method which can handle real-world applications in which historical data increase or decrease, continuously.
Out-of-sample forecasting results
Out-of-sample forecasting results
This paper proposes an improved fuzzy time series model, where the parameters of the AM model are optimized by the differential evolution algorithm. The proposed method can forecast the values that fall outside the min-max range of the original data, whereas most of the previous models are not able to forecast those kinds of values. The illustrative examples confirm the superiority of the DEABB over the conventional methods in terms of the mean of absolute error. In comparison with other optimization-based methods as GAABB and PSOABB, there are no statistically significant differences but the DEABB should be the most reasonable choice due to its ability to quickly reach the global optimum. The proposed model can be applied to numerous practical problems, such as population, GDP, rice production forecasting. The limitation of the proposed method is that it just optimizes the time-invariant fuzzy time series where the intervals have the same length. This has motivated researchers to extend the work towards time-variant AM model and its optimization in the future. Besides, a package can be programmed in R to apply the proposed model as well as other fuzzy time series models to practice.