
Abstract
By using fuzzy set theory (FS), interval-valued fuzzy set theory (IVFS) and nonparallel support vector machine theory (NPSVM), the fuzzy nonparallel support vector machine (F-NPSVM) and interval-valued fuzzy nonparallel support vector machine (IVF-NPSVM) are constructed. Both F-NPSVM and IVF-NPSVM consider the membership degree of the training points in their models and the difference is the method to determine them. Then the solutions to them are derived. The experiments on both artificial data set and benchmark data sets show that most of the classification results by using the F-NPSVM and IVF-NPSVM are more accurate than NPSVM, support vector machine (SVM), interval-valued fuzzy support vector machine (IVF-SVM), generalized eigenvalue proximal support vector machine (GEPSVM) and twin support vector machine (TWSVM). Finally, Friedman test is used to verify that there is a significant difference between the two new models and the previous ones.
Introduction
Support vector machine (SVM) is a new classification technique which has drawn much attention on this topic in recent years [1–5]. The theory of SVM is based on the idea of structural risk minimization [3]. In many applications, SVM has been shown to provide higher performance than traditional learning machines [1] and has been introduced as powerful tools for solving classification problems. SVM first maps the input points into a high-dimensional feature space and finds a separating hyperplane that maximizes the margin between two classes in this space. Maximizing the margin is a quadratic programming problem and can be solved from its dual problem by introducing Lagrangian multipliers. Without any knowledge of the mapping, SVM finds the optimal hyperplane by using the kernel functions in feature space. The solution of the optimal hyperplane can be written as a combination of a few support vectors. After the theory of SVM, other parallel support vector machines are introduced. For the least squares support vector machine (LSSVM) [6], least square function with equality constraints is used as a loss function instead of the complex QP problem of SVM, so the solving speed is relatively fast. For the ν- support vector machine (ν– SVM) [7], a parameter ν lets one effectively control the number of support vectors.
The theory of fuzzy set is produced by Zadeh [8] in 1965 and has been widely used in many fields of modern society [9]. However, fuzzy membership degree is only a real number, which can only be supportive or against in practical application in decision making and so on. So, there is certain limit in using only membership degree of fuzzy set in some actual problems. Intuitionistic fuzzy set theory introduced by Atanassov [10–11] is an extension of the classic fuzzy set theory. The classical membership degree is transformed into a membership degree, a non-membership degree and a hesitation degree. Another well-known generalization is interval-valued fuzzy set which is introduced by B. Gorzafczany [12–14]. The classical membership degree is changed to an interval-valued membership degree and a hesitation degree. After that, some authors investigate the topic and obtain some meaningful conclusions [15–17].
There are more and more applications using the SVM techniques today. However, in many applications, some input points may not be exactly assigned to one of these two classes. Some are more important to be fully assigned to one class so that they should be separated more correctly. While some data points corrupted by noises should be better discarded otherwise once they become support vectors, they will produce a great effect on the classification result. SVM lacks these abilities. For this kind of situation, Lin [18–19] construct fuzzy support vector machine (FSVM). The inputs are assigned to different membership degree according to the different contribution to the class, thereby weakening the influence of noises on classification. How to determine the membership degree of the points is the key point to FSVM. At present, the more common method is based on the distance from the sample to the cluster center [20]. Points far from the center are given a smaller membership degree, while points in the opposite case are given a greater membership degree. But the limitation of this approach is that without considering the close degree among the points. Given two kinds of points which are sparse and dense separately, the former is more likely to be outliers than the latter. If the distance from the points to the class center is equal and both are endowed with the same membership degree, it will be easy to cause some classification error. Interval-valued fuzzy support vector machine (IVF-SVM) [21] considers both the distance and the close degree among the points when defining the membership degree so the classification accuracy has been improved in both artificial data and UCI data experiments.
In recent years, some nonparallel hyperplane classifiers, which are different from those searching for two parallel support hyperplanes, have been proposed. For the generalized eigenvalue proximal support vector machine (GEPSVM) [22], data points of each class are proximal to one of the two nonparallel planes. The nonparallel planes are eigenvectors corresponding to the smallest eigenvalues of two related generalized eigenvalue problems. For the twin support vector machine (TWSVM) [23–27], it seeks two nonparallel proximal hyperplanes such that each hyperplane is closer to one of the two classes and is at least one distance from the other. The strategy results that TWSVM solves two smaller QPPs, whereas SVM solves one larger QPP, which increases the TWSVM training speed by approximately four-fold compared to that of SVM. For the NPSVM [28–30], it seeks two nonparallel hyperplanes such that each class locates as much as possible in the ɛ-band of the hyperplane and each hyperplane is at least one distance from the other. NPSVM has several advantages compared to GEPSVM and TWSVM: the structural risk minimization principle, the kernel trick and the sparseness.
In fact, the application of fuzzy set theory in the field of nonparallel support vector machines has aroused great interest. The combination of fuzzy set theory and nonparallel support vector machines has produced some new classification models, such as fuzzy proximal support vector classification via generalized eigenvalues [31], fuzzy twin support vector machine [32] and fuzzy least squares twin support vector machine [33], etc. The performance of these models has been improved to some extent in both artificial data and UCI data experiments.
In this paper, the fuzzy set theory and interval-valued fuzzy set theory are applied to NPSVM. Two new NPSVMs are proposed which are referred to as fuzzy NPSVM (F-NPSVM) and interval-valued fuzzy NPSVM (IVF-NPSVM). Through the distribution of points, we determine the fuzzy membership degree and interval-valued fuzzy membership degree of them. At last SVM is used to classify the points after they are processed in fuzzy and interval-valued fuzzy way.
The rest of this paper is organized as follows. A brief review of FS, IVFS, SVM and NPSVM will be described in Section 2. Then F-NPSVM and IVF-NPSVM will be derived in Section 3. Experiments and a statistical test will be presented in Section 4. Some concluding remarks will be given in Section 5.
Preliminary
FS and IVFS
FS [8]
Let X be a non-empty set, F = {< x, μ F (x) > |x ∈ X} is called a fuzzy set in X.μ F is the membership degree function of F, μ F : X → [0, 1], μ F (x) represents the membership degree of x belonging to F, and 0 ≤ μ F (x) ≤1 .
IVFS [12]
Let X be a non-empty set, L = { [a, b] |0 ≤ a ≤ b ≤ 1}. A = {< x, [A- (x) , A+ (x)] > |x ∈ X} is called an interval-valued fuzzy set in X. A- and A+ are the interval-valued membership degree functions of A, A-, A+ : X → L, [A- (x) , A+ (x)] represents the interval of membership degree of x belonging to A, and 0 ≤ A- (x) ≤ A+ (x) ≤1.
The difference π A (x) = A+ (x) - A- (x) is called the interval-valued fuzzy index and should be treated as a hesitancy margin connected with the evaluation degree while qualify or not each element x to a set A. It is the most important and original idea distinguishing the interval-valued fuzzy set theory from the fuzzy set theory.
SVM and NPSVM
SVM [1]
Consider the binary classification problem with the training set T = {(x1, y1), ⋯, (x l , y l )}, where x i ∈ R n , y i ∈ {-1, +1}, i = 1, ⋯, l. The aim of SVM is to find an optimal separating hyperplane (w · x) + b = 0 that classifies the training points correctly or basically correctly, where w ∈ R n , and the scalar b ∈ R. The separating margin between the two parallel planes (w · x) + b = 1 and (w · x) + b = -1 should be as large as possible. Now to find the optimal separating hyperplane is to solve the following optimization problem
With Wolfe theory the primal problem (1) can be transformed to its dual problem
w* can be decided by the KKT (Karush-Kuhn-Tucher) condition of problem (2)
and choose an element of α*,
Then a new testing point x can be classified according to the decision function
Sometimes it is unnecessary to ask f (x) to be a linear function. In this case, one common strategy is to map the original input points into a high-dimensional feature space F = {φ (x) |x ∈ X} to find a separating hyperplane in it. The optimization problem corresponding to the problem (2) is as follows
Where K (x i , x j ) = φ (x i ) · φ (x j ) denotes a kernel.
The decision function is determined by
Consider the binary classification problem with the training set T = {(x1, +1), ⋯, (x
p
, + 1), (xp+1, -1), ⋯, (xp+q,-1)}, where x
i
∈ R
n
, i = 1, ⋯, p are positive inputs, and x
i
∈ R
n
, i = p + 1, ⋯, p + q are negative inputs. In nonparallel support vector machines, NPSVM classifier has been proved more superior theoretically and more efficient compared with the existing TWSVM and GEPSVM. For the linear case, NPSVM seeks two nonparallel hyperplanes by solving two convex QPPs (Quadratic Programming Problems) as follows:
In the objective function of primal problem (8), the term
With Lagrangian coefficients
In a similar way, we could obtain the dual formulation of (9) as follows:
After solving the problem (10), w+ can be expressed as
and choose a component of
Similarly, w- can be expressed as
and choose a component of
A new testing point x is classified as +1 or −1 depending on which of the two hyperplanes it lies closer to, i.e.,
where | · | is the absolute value.
In nonlinear situation, the optimization problem corresponding to the problem (8) and (9) are as follows
where K (x i , x j ) = φ (x i ) · φ (x j ) denotes a kernel. The decision functions and the judgment method are determined in a similar way.
F-NPSVM
In many real applications, the effects of the training points are different. Some training points are more important than others in the classification problem. We would require that the meaningful training points must be classified correctly and better weaken the effect of some points like noises.
That is, each training point no more exactly belongs to one of the two classes. It may 70% belong to one class and 30% be meaningless, and it may 10% belong to one class and 90% be meaningless. In other words, there is a fuzzy membership degree associated with each training point. This fuzzy membership degree can be regarded as the attitude of the corresponding training point toward one class in the classification problem. So, the concept of NPSVM is extended with fuzzy membership degree and becomes F-NPSVM.
Consider the binary classification problem with the training set T = {(x1, + 1), ⋯, (x p , +1), (xp+1, -1) , ⋯, (xp+q, -1)}, where x i ∈ R n , i = 1, ⋯, p are positive inputs, and x i ∈ R n , i = p + 1, ⋯, p + q are negative inputs.
In order to find two nonparallel hyperplanes that classify the training points more correctly, we have the following Algorithm1: F-NPSVM.
For positive point x i (i = 1, 2, ⋯ , p),
The distance between negative point and the class center is processed in a similar way.
For positive point x i (i = 1, 2, ⋯ , p), assume its fuzzy membership degree is m i ,0 ≤ m i ≤ 1, then let
x k belongs to the positive class.
The fuzzy membership degree of negative point is determined in a similar way.
Since m i is the membership degree of point x i toward one class and the parameter ξ i is the measure of error, the term m i ξ i is the measure of error with different weight. The optimal hyperplane problem is then regarded as the two QPPs.
With Lagrangian coefficients
After solving the dual problem (25), w+ can be expressed as
Choose a component of
Similarly, w- can be expressed as
Choose a component of
then the decision functions can be expressed as
A new testing point x is classified as +1 or −1 depending on which of the two hyperplanes it lies closer to, i.e.,
where | · | is the absolute value.
In nonlinear situation, the optimization problems corresponding to the problems (23) and (24) are as follows
where K (x i , x j ) = φ (x i ) · φ (x j ) denotes a kernel. The decision functions and the judgment method are determined in a similar way.
Combining NPSVM and fuzzy set theory, the classifier F-NPSVM is proposed. But this method determining the membership degree has a limitation: not considering the ambient conditions around the points. In this part, we will put forward a new classifier IVF-NPSVM which combines NPSVM and interval-valued fuzzy set theory to solve the problem.
Consider the binary classification problem with the training set T = {(x1, + 1) , ⋯ , (x p , + 1) , (xp+1, - 1) , ⋯, (xp+q, - 1)} where x i ∈ R n , i = 1, ⋯ , p are positive inputs, and x i ∈ R n , i = p + 1, ⋯ , p + q are negative inputs.
In order to find two nonparallel hyperplanes that classify the training points more correctly, we have the following Algorithm2: IVF-NPSVM.
For positive point x i (i = 1, 2, ⋯ , p)
The distance between negative point and the class center is processed in a similar way.
For positive point x i (i = 1, 2, ⋯ , p),
Num represents the number of elements in the following set and R is the neighborhood radius for point x i which can be adjusted.
Obviously,
The negative points are processed in a similar way.
For positive point x
i
(i = 1, 2, ⋯ , p), assume its interval-valued fuzzy membership degree is
x k belongs to the positive class.
The interval-valued fuzzy membership degree of negative points is determined in a similar way.
With Lagrangian coefficients
After solving the dual problem (47), w+ can be expressed as
Choose a component of
Similarly, w- can be expressed as
Choose a component of
A new testing point x is classified as +1 or % −1 depending on which of the two hyperplanes it lies closer to, i.e.,
In nonlinear situation, the optimization problems corresponding to the problems (45) and (46) are as follows
In this section, in order to validate the performance of our F-NPSVM and IVF-NPSVM, we compare them with SVM, IVF-SVM, GEPSVM, TWSVM and NPSVM on different types of datasets. All methods are implemented in MATLAB 2012a on a PC with Intel(R) Core (TM) i7-3520M CPU 2.90GHz processor and 8GB RAM.
Experiments conducted on artificial dataset
As shown in Fig. 1, (a) shows a true data distribution of 80 artificial points. The ratio of the two types of points is 3:7, where 24 positive points are showed in red and 56 negative points are showed in blue. These two types of points are centered on (4, 1), (6, 2), and generated by Gaussian distribution respectively. (b)-(h) show the linear classifiers obtained by SVM, IVF-SVM, GEPSVM, TWSVM, NPSVM, F-NPSVM and IVF-NPSVM separately. Both F-NPSVM and IVF-NPSVM consider the membership degree of the input points. In (b)-(c), the two black lines are the support lines, and the blue one is the decision line. In (d)-(h), the two black lines are the positive proximal line and the negative proximal line, and the blue one is the decision line. From (b)-(h), it is easy to see that NPSVM, F-NPSVM and IVF-NPSVM can obtain the best accuracy. Among them, although the classification lines are very similar, the proximal lines of the positive points in F-NPSVM and IVF-NPSVM are better.
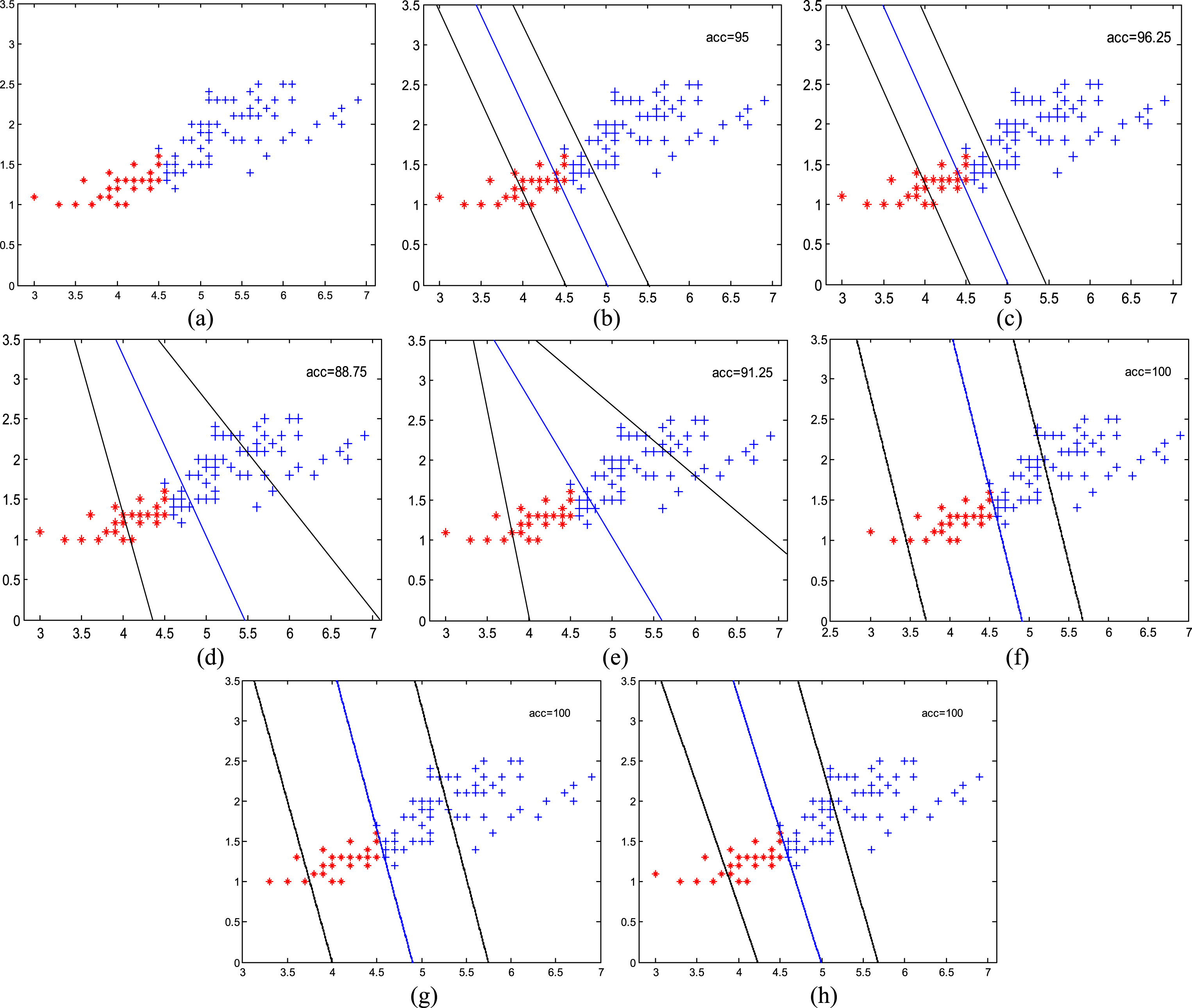
(a) The true data distribution. (b) SVM. (c) IVF-SVM. (d) GEPSVM. (e) TWSVM. (f) NPSVM. (g) F-NPSVM. (h) IVF-NPSVM.
We perform the seven algorithms on 22 UCI datasets. The UCI Machine Learning Repository is a collection of databases, domain theories, and data generators that are used by the machine learning community for the empirical analysis of machine learning algorithms. All samples were processed such that the features locate in [0, 1] before training. For each method, the parameters are tuned for the best classification accuracy. The procedures are repeated five times and Table 1 shows the comparison results in terms of accuracy, training time and p-value for SVM, IVF-SVM, GEPSVM, TWSVM, NPSVM, F-NPSVM and IVF-NPSVM with RBF kernel.
Comparisons on UCI datasets with RBF kernel
Comparisons on UCI datasets with RBF kernel
The p-values are obtained from a t-test by comparing each algorithm to INF-NPSVM. The best correctness results are in bold red, and the second in bold black.
In order to further analyze the performance of the seven algorithms, Friedman test [34] is used to test if there is a significant difference between the experimental results.
Friedman test is proved to be a simple non-parametric statistic method. To compute the Friedman statistic, the average ranks of the five algorithms on accuracy for the twenty-two UCI datasets are calculated and listed in Table 2. Under the null-hypothesis that all the algorithms are equivalent, the Friedman statistic can be computed as follows:
which is distributed according to the F-distribution with m - 1 and (m - 1) (N - 1) degrees of freedom.
Average rank on classification accuracy of nonlinear classifiers
According to (58) and (59), for the nonlinear case, we can obtain
The obtained results suggest that there is a significant difference between the seven algorithms since the real value of F F is much larger than the critical values. GEPSVM ranks the most backward, but its training time is the shortest. IVF-SVM ranks better than SVM, while F-NPSVM and IVF-NPSVM also rank better than NPSVM. Overall, IVF-NPSVM ranks first and F-NPSVM ranks second. These indicate that the classification models with fuzzy information have better average performance than the original models and the two new algorithms proposed in this paper are indeed superior to the other five algorithms in classification accuracy. Of course, we also noticed that because of the increase of parameters, the training models with fuzzy information are slower than other algorithms in training speed.
In order to further improve the performance of NPSVM, F-NPSVM and IVF-NPSVM which are meaningful extensions of NPSVM are introduced in this paper. They come from the theories of FS, IVFS and NPSVM. Besides the distance from point to the class center, the close degree of the points is proposed, and then the fuzzy membership degree and the interval-valued fuzzy membership degree of the points are determined. Since the contribution degree of different points is considered, the effect of outliers is reduced and the accuracy of the NPSVM classification is improved.
Although simulation results verify the two proposed algorithms perform better than NPSVM, the problem of time complexity is still in front of us. We will further study fast algorithms to improve the training efficiency, especially in the classification problems of large-scale datasets. The application of the algorithms in multi-class pattern recognition is also a research direction in the future.
Footnotes
Acknowledgement
This work was supported by the National Nature Science Foundation of China (NO.61571052) and (NO.71771028), Beijing Municipal University’s High-level Innovation Team Construction Project (IDHT20180510) and Beijing Intelligent Logistics System Collaborative Innovation Center.