
Abstract
Optimization algorithms have been rapidly promoted and applied in many engineering fields, such as system control, artificial intelligence, pattern recognition, computer engineering, etc.; achieving optimization in the production process has an important role in improving production efficiency and efficiency and saving resources. At the same time, the theoretical research of optimization methods also plays an important role in improving the performance of the algorithm, widening the application field of the algorithm, and improving the algorithm system. Based on the above background, the purpose of this paper is to apply the intelligent optimization algorithm based on grid technology platform to research. This article first briefly introduced the grid computing platform and optimization algorithms; then, through the two application examples of the TSP problem and the Hammerstein model recognition problem, the common intelligent optimization algorithms are introduced in detail. Introduction: Algorithm description, algorithm implementation, case analysis, algorithm evaluation and algorithm improvement. This paper also applies the GDE algorithm to solve the reactive power optimization problems of the IEEE14 node, IEEE30 node and IEEE57 node. The experimental results show that the minimum network loss of the three systems obtained by the GDE algorithm is 12.348161, 16.348152, and 23.645213, indicating that the GDE algorithm is an effective algorithm for solving the reactive power optimization problem of power systems.
Keywords
Introduction
To transform the world is to use human knowledge to optimize the objective world, referred to as optimization. Optimization is an ancient and important topic that can be traced back to the Second World War. To make better use of war resources, Britain established a war research team to analyze the war process, and the results achieved good results. After World War II, the optimization ideas applied in the war were applied to production management, and as a result, operations research based on linear programming was formed. The problem it researches is to find the best solution among many schemes. Optimization technology is an application technology based on mathematical models and used to solve various engineering problems. The core of optimization is the model, and the optimization method is continuously developed with the change of the model. The optimization problem is to use the optimization method to achieve the optimization of a certain optimization target under the constraints of constraints. Optimization models such as linear programming, non-linear programming, and dynamic programming allow optimization methods to enter the era of rapid development.
Due to the importance of research algorithm Intelligent optimization, many research teams began to intelligent optimization algorithm research, and have achieved good results, WANG for the lack of traditional Z-N method in PID parameter optimization, a new intelligent PID parameter optimization algorithm. The simulation and experimental results show that the algorithm of PID parameters is efficient, accurate and fast. The algorithm is applied to the truck hydraulic control system. The simulation and experimental results show that when the peak oil pressure relief chamber changes, the optimization algorithm to find the maximum power will be required to change the relief pressure suitable relief surface displacement, thereby changing the displacement of the percussion piston, the percussion piston while changing The impact power and frequency impactor can automatically change the working parameters according to different conditions under the appropriate parameters and maximum power conditions. Experiments show that the method has some other reference value of the control target and control process [1–3]. Existing intelligent optimization algorithms tend to fall into a local optimal equilibrium state at the later stage of evolution and have low efficiency. To overcome these shortcomings, Cun-Bin proposed a group intelligent optimization algorithm based on orthogonal optimization, based on analysis of variance and analysis of variance proposed swarm intelligence optimization algorithm based on genetic algorithm. This algorithm determines the further search direction and search range of the orthogonal design method. This method was previously limited to the optimization search before group initialization and evolution. Using the characteristics of orthogonal design, it finds interval examples containing the optimal solution in an array. show that the algorithm can be optimized in the search process variance ratio analysis, simulation analysis of the hump humpback functions show that, compared with the existing intelligent optimization algorithm, the algorithm to calculate the amount of small, short search time, fast, and more High optimized search accuracy [4, 5]. Although the research results are abundant now, there are still shortcomings, mainly reflected in the low optimization efficiency.
In the research of grid computing platforms, the grid computing method is a very good method that can solve many inefficient problems. Therefore, it is widely used in the research of achieving high performance. SDN / NFV services provided on platforms and transport networks. On the one hand, they proposed a general architecture for deploying SDN / NFV services on multi-domain transmission networks and distributed data centers. On the other hand, they proposed two use cases for possible NFV services: the Virtual Path Computing Element (vPCE) and the deployment of a Virtual SDN Controller (vSDN) on a Virtual Transport Network [6, 7]. Diego proposed a new method for implementing a virtual network embedding strategy on the OpenStack cloud platform. They raised issues with the OpenStack cloud platform and issues related to virtual network embedding. Then, perform OpenStack dashboard customization to generate virtual network requests to process those requests. They modified the OpenStack computing module to provide bandwidth limits for virtual network requests, modified the data structure used between OpenStack Horizon and Nova modules, and implemented virtual network embedded algorithms on the OpenStack cloud platform [8, 9]. Due to the effectiveness of grid computing methods, can grid technology methods be applied to intelligent algorithm optimization to solve the problem of slow optimization efficiency.
Based on the grid computing platform, the principles and applications of intelligent optimization algorithms will be described in this article. Among the various intelligent optimization algorithms, the most widely used are representative genetic algorithms, simulation algorithms, hybrid optimization algorithms, tabu algorithms, and skip fields. This is a network optimization algorithm. In the course of research, various research methods are used, and the influence of various parameters of the algorithm such as genetic algorithm, genetic algebra, and population size on the optimization result is studied. Explore the impact on the scheduling process of the optimization results, discuss the taboo algorithms, the application of combinatorial optimization problems and function optimization problems, study more complex optimization strategies and hybrid optimization, and obtain outstanding research results.
Grid computing and intelligent optimization algorithm
Grid-based computing platform
Because more computing problems cannot be completed by a single computer, they must be solved by multiple computers to be completed in a predetermined time. The goal of building a computing platform is to solve the collaboration and cooperation of multiple computers to achieve a shared computing resource-based High-performance computing grid systems for large-scale applications [10].
In the use of the computing platform, the idea of unified control and the idea of full hosting is adopted. Unified control means that the user can use any resource and personal information of the user on all platforms as long as he or she logs in to the computing platform once. The system will also protect the personal information of the user and keep logged in until the user logs out of the computing platform. Full hosting means that the user can completely hand over the computer to the problem that needs to be calculated, and no user intervention is required in the middle, just log in again to obtain the calculation result after a certain time.
The overall architecture of the grid computing platform is shown in Fig. 1:

Structure of a computing platform.
The underlying support structure of a computing platform
Many personal computers and 100M LAN provide the underlying support structure required by the platform. Each computing node is connected through a LAN of up to 100M. Each computing node is equipped with a CPU with a frequency above IG Hertz and data storage above 20 G. Space, and equipped with a variety of efficient software, can provide strong support for the Globus system [11, 12].
System software
The personal computers used by the computing platform are installed with different operating systems, such as Windows2000pro, Red hat linuxs9.0, Windows98 and so on. Due to the heterogeneity of the system between computing nodes, the system software is needed to eliminate the differences between the nodes and achieve unified management of the entire grid computing resources. The Globus project is one of the most influential grid-related projects in the world [13]. Globus has conducted extensive research on key theories and technologies of grid computing such as information security, resource management, information services, data management, and application development environments, and developed a grid computing toolkit software (Globus) that can run on multiple platforms. Toolkit) can be used to help plan and set up a large grid experiment and application platforms, and develop large applications suitable for large grid systems [14, 15]. The main components of the Globus Toolkit implementation are as follows: Grid Security infrastructure-Grid Security infrastructure (GSI), pp. GSI is responsible for security authentication and encrypted communication in a wide area network, providing single sign-on function, remote identity authentication function, data transmission encryption function, etc. Provides the Generic Security Service API interface based on the GSI protocol. It is the core part to ensure the security of the grid computing environment. Information Architecture-Metacomputing Directory Service (MDS), pp. MDS mainly completes the discovery, registration, query, and modification of information in the grid computing environment, and provides a real, real-time dynamic reflection of the grid computing environment. It is mainly based on the LDAP protocol, and the information it processes is mainly the description of various resources (including data resources, computing resources, etc.), services, and other subjects in the grid computing environment [16, 17]. MDS is an information service center in a grid computing environment. Data Management-Global Access to Secondary Storage (GASS), pp. GASS simplifies the application’s operation on remote file l / O in the Globus environment, making applications using UNIX and standard C language I / O libraries unchanged. It can be executed in the Globus environment [18–19]. GASS is a middleware that supports remote I / O access to grid computing environments. Communication provides a multi-threaded communication library Nexus [20]. Provide globus_io library, on which the programmer can use TCP, UDP, IP multicast, file I / O and other services to achieve secure, asynchronous communication, and QoS. Error detection Heartbeat Monitor provides process monitoring and sends heartbeats to other monitors at regular intervals[21]. Portability-It provides portable libc library, thread library, data conversion library, Globus-utpAPI and basic data type library to be used by Globus Toolkit.
(1) Genetic Algorithm
A genetic algorithm is one of the earliest proposed intelligent optimization algorithms. This algorithm simulates the survival of the fittest in the natural world to perform population evolutionary optimization [22, 23]. Good genes are kept in the population, and bad genes are eliminated from the population. In addition to the three operations of selection, crossover, and mutation, the most important part of the genetic algorithm is the coding method. The encoding method directly determines the optimization result of the algorithm. Binary coding and real coding are the most commonly used coding methods [24].
1) Binary encoding
The basic genetic algorithm uses binary coding. X = (X1, X2, K, Xn). Each individual is called a gene. The reason why it is called binary coding is Because the value of each gene of the individual is 0,1. Genetic algorithms using binary coding are more beneficial to crossover and mutation operations after coding. Binary coding is mainly used in backpack problems and assignment problems. The main advantages of the binary encoding method are that it is convenient for bit value calculation, and the range of real numbers that can be represented is large, and it is easy to implement cross-operation.
2) Real number encoding
Real number coding means that each gene consists of real numbers, and the length of an individual’s gene is equal to the number of variables to be solved. The real number encoding must ensure that the gene value is within the domain and the value generated by the crossover operator and the abrupt mutation operator must be within a predetermined interval. The genotype spatial topology of the real number coding method is consistent with the phenotypic space topology. The real number coding brings unparalleled optimization effects to the combination problem.
(2) Simulated annealing algorithm
The basic idea of the simulated annealing algorithm is to simulate the process of solid annealing [25]. When the temperature of the solid is raised high enough, the internal energy of the internal particles increases with the temperature and gradually becomes disordered. When the temperature of a solid decreases, the internal energy of its internal particles also decreases. As long as the temperature drops slowly enough, the particles inside the solid will be in equilibrium. When the solid temperature drops to normal temperature, its internal particles are in the ground state. According to the Metropolis sampling criterion, when the solid particle state is in equilibrium at temperature T, the probability distribution of its state is proportional to exp(- ΔE/kT) Z. Among them, E is the total internal energy of solid particles at temperature T, and Δ E is the amount of change. k is Boltzmann constant. The flowchart of the simulated annealing algorithm is shown in Fig. 2.

Flow chart of the simulated annealing algorithm.
The objective function value f is used to simulate the internal energy E of the solid, and the temperature T is converted into the control parameter t. The change of the parameter t simulates the cooling process, and the solution optimization problem can be simulated as a solid annealing process: Set the initial parameter t. Randomly select the initial solution x; Randomly select a new solution in the neighborhood of the existing solution; accept or reject new solutions by Metropolis guidelines; Check whether the equilibrium state is reached at this temperature, if yes, go to step 5, otherwise go to step 2; Cooldown according to the established strategy; Check whether the end condition is met, if yes, output the solution and stop the algorithm, otherwise go to step 2.
After the annealing process, the internal energy of the solid is minimized. Correspondingly, through the calculation process of simulated annealing, the objective function of the optimization problem finally reaches the minimum value, that is, the optimal solution of the problem is obtained.
Construction starting point of 2.3GASA hybrid optimization algorithm Fusion of optimization mechanisms, In theory, GA and SA are optimization algorithms that belong to the probability distribution mechanism. The difference is that SA will give time-varying and eventually zero probability jumps during the search process, which can effectively avoid falling into a local mini-mode and eventually fall into global optimization. The GA survival concept will optimize population genetic operations. The combination of the two algorithms that are so different in the optimization selection mechanism helps to enhance the search operation of the optimization process, improve search capabilities and efficiency, and have global and local significance. Complementary SA algorithm with an optimized structure uses serial optimized structure, and GA uses a group parallel search. According to the two combinations, SA becomes a parallel SA algorithm, which improves the optimization performance. Complement the evolutionary power of GA. Combining optimization operations The state generation and receiving operations of the SA algorithm only retain one solution at a time, lacking redundancy and historical search information; and the GA’s replication operation can retain the excellent individuals in the population in the next generation, cross-operation It can make the offspring inherit the excellent model of the parent to a certain extent, and the mutation operation can strengthen the diversity of individuals in the population. The combination of these different functions of optimization operations enriches the neighborhood search structure in the optimization process and enhances the full-space search capability. Weakening the harshness of parameter selection SA and GA have a strong dependence on algorithm parameters. Improper parameter selection will seriously affect the optimization performance. The convergence conditions of SA lead to the harsh and even impractical parameter selection of the algorithm; while the parameters of the GA have no clear selection guidance, they must be determined through a lot of experiments and experience when designing the algorithm. The mixture of SA and GA makes the searchability of all aspects of the algorithm improved, so the selection of algorithm parameters does not have to be too strict.
Selection of experimental intelligent optimization algorithms
Algorithm selection is the first step of optimization algorithm design. It is the matching problem between the optimization algorithm and optimization problem. How to choose a suitable optimization algorithm for an optimization problem is mainly based on the characteristics of the optimization problem, especially the characteristics of the optimization solution. The basic principle of the optimization algorithm selection is that the algorithm should be able to fit the characteristics of the problem.
Analyzing the characteristics of the optimization problem is the premise of algorithm selection. This is most obvious in the choice of traditional optimization algorithms. Traditional optimization algorithms can only solve continuous optimization problems, that is, the objective function is continuous. For discrete optimization problems, traditional optimization algorithms usually use smoothing techniques to convert them to continuous optimization problems. Whether a continuous optimization problem is suitable to be solved by a traditional optimization algorithm depends on whether the form of its objective function and constraint conditions meet certain characteristics. This characteristic varies with the specific traditional optimization algorithms. For example, a linear programming problem requires the objective function and constraints to be linear, while a convex programming problem requires the objective function and constraints to be convex.
Experimental operator design
Optimization operators refer to operations on data in optimization algorithms, such as crossover operators and mutation operators in genetic algorithms. After the optimization algorithm is selected, the type of optimization operator is determined. However, it is necessary to design the specific operation behavior of the optimization operator according to the characteristics of the optimization problem to achieve the expected purpose.
The factors that need to be considered in the optimization operator design mainly come from the optimization problem.
First, the encoding of the solution affects the operation of the operator. For example, using genetic algorithms to solve the TSP problem. Using sequential coding or neighborhood coding, the crossover operator and mutation operator are very different.
Secondly, the distribution characteristics of optimization problems also affect the design of optimization operators.
Third, designing optimization operators also needs to consider: the complexity of the optimization operator, the flexibility of the optimization operator, and so on.
Experimental parameter design
Choosing the right parameters is a very important step in the optimization algorithm design. The effect of algorithm running will be very different depending on the parameter selection. Parameter selection has always been the most important part of the experimental link in the optimization algorithm design.
The parameter selection method currently used is still at the empirical stage. Through experiments, some parameters that can achieve better-operating results are found. The correlation and sensitivity tests of parameters can roughly determine the effect of parameter changes on the operation of the algorithm. With good results, the number of experiments can be greatly reduced.
Numerical experiments
Numerical experiments are an important method to verify the algorithm. Selecting appropriate test samples is the key to numerical experiments. The experimental content is the overall performance evaluation, operation test and parameter test of the algorithm. The results of the numerical experiments are fed back to the parameter selection phase, the operator design phase, and even the algorithm selection phase.
Through the steps of algorithm selection, operator design, parameter selection and numerical experiments, the algorithm design goes through a cycle. Through the cyclic process of these steps, the performance of the algorithm is continuously improved to achieve the purpose of optimizing the algorithm design.
Algorithm simulation analysis
To verify the effectiveness of the identification algorithm, the following system was used as the simulation object
Simulation conditions: The input signal is a pseudo-random binary signal with an amplitude of 1, and a length of 200. The first 100 points are used as model identification signals, and the last 100 points are used as model comparison signals. The sampling time interval is T-0.15.
Let the model input noise variance be O, and examine the relationship between the tabu list length and the recognition results. The results are shown in Table 1:
Taboo list length and recognition results
(Parameter description: a1, a2, a3 are the coefficients of the linear part denominator polynomial A, bl, b2 are the coefficients of the molecular polynomial B, and r1, r2, r3 are the coefficients of the non-linear part.)
The possible solution list is 40 in length and the neighborhood is divided into 28. The identification result is verified by the test signal when the length of the taboo list changes, and the prediction error between the measured system and the identification model is shown in Fig. 3:
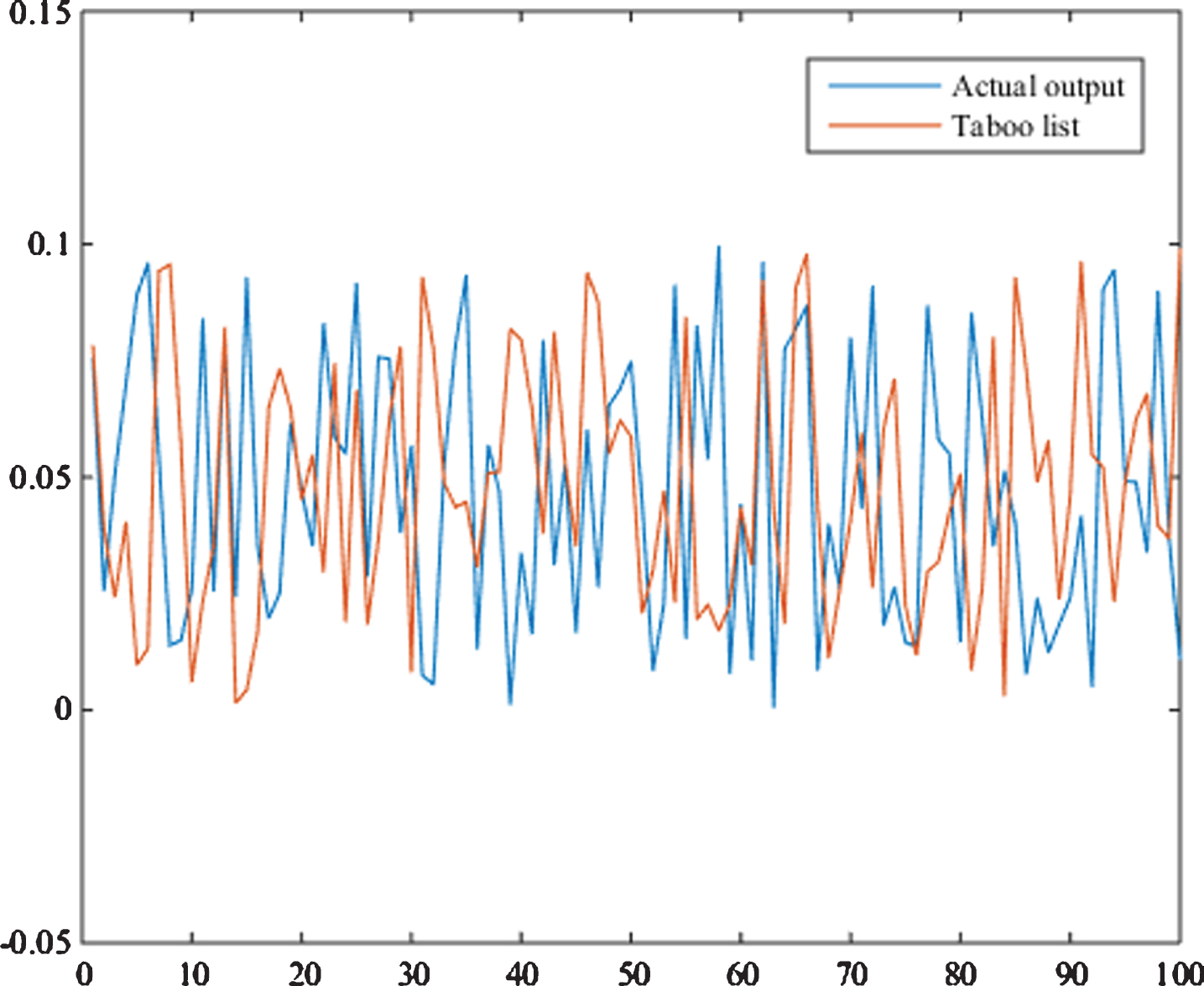
Prediction error of recognition results when taboo list length changes.
From the above results, it can be seen that when the length of the taboo list is relatively short, the algorithm falls into a local optimum prematurely, so that it cannot obtain an optimal solution, and when the taboo list is relatively long, the algorithm does not unban the list from the list, and therefore Miss some of the best things. So the length of the taboo list should take a moderate value. As can be seen from the Fig., when the length of the taboo list is 10, the recognition effect is better. The intelligent optimization algorithm obtains the characteristic information of the optimization problem through sampling, and then uses this characteristic information to guide the algorithm search. Therefore, the process of intelligent optimization algorithm optimization can be regarded as a cognitive process of the characteristic information of the optimization problem. Analogous to target recognition, the optimization process is equivalent to identifying the optimal solution in the feasible solution domain.
This article uses four algorithms to solve the reactive power optimization problem. These algorithms include: genetic algorithm (GA), adaptive differential evolution algorithm (SADE), reverse differential evolution algorithm (ODE), and global differential evolution algorithm (GDE). The parameter settings of the algorithm are as follows: GA algorithm: crossover rate pc = 0.95, mutation rate Pm = 0.05, population number M = 100, maximum number of iterations MAX_iteration = 300. SADE algorithm: the lower limit of the amplification factor Fl = 0.1, and the upper limit of the amplification factor Fu = 1. The number of population M = 100, the maximum number of iterations MAX_iteration = 300. ODE algorithm: the number of population M = 100, the maximum number of iterations MAX_iteration = 300. GDE algorithm: the number of population M = 100, the maximum number of iterations MAX_iteration = 300.
In the reactive power optimization model, the penalty factor λ1 for the voltage violation of the PQ node and the penalty factor λ2 for the output reactive power of the PV node are both set to 1010. Setting a larger penalty factor helps the algorithm to obtain a feasible solution and maintain power Under the premise of system stability, the net loss is reduced and the stability of the power system is improved. In reactive power optimization, the upper and lower limits of state variables and control variables are shown in Table 2.
Upper and lower limits of state variables
Upper and lower limits of state variables
The initial state of the system in the experiment is: all the balanced node voltages are set to 1, the PV node voltage is set to 1, the transformer’s initial transformation ratio is set to 1, and all reactive power compensation equipment capacity is set to 0.
The minimum network losses of GA, SADE, ODE and the GDE algorithm proposed in this paper in independent experiments are: 12.504985, 12.451623, 12.450214, and 12.448268. The reduction rates of the four algorithms for the initial network loss are: 21.03%, 21.37%, 21.38%, and 21.40%. Among the four algorithms, the GDE algorithm proposed in this paper has the smallest network loss and the largest network loss reduction Rate, meanwhile, GA, SADE, ODE and GDE four network loss standard deviations are: 1.1824146-001, 5.641027e-002, 7.964896e-002 and 5.397102e-004.
The standard deviation of the network loss obtained by the GDE algorithm is also the smallest of these four algorithms. The comparison of network loss standard deviation data shows that in independent experiments, the GDE algorithm not only obtains the smallest network loss value, but also has the best optimization stability, and the fluctuation of network loss is small. The network loss optimization curve of the IEEE14 node system is shown in Fig. 4.
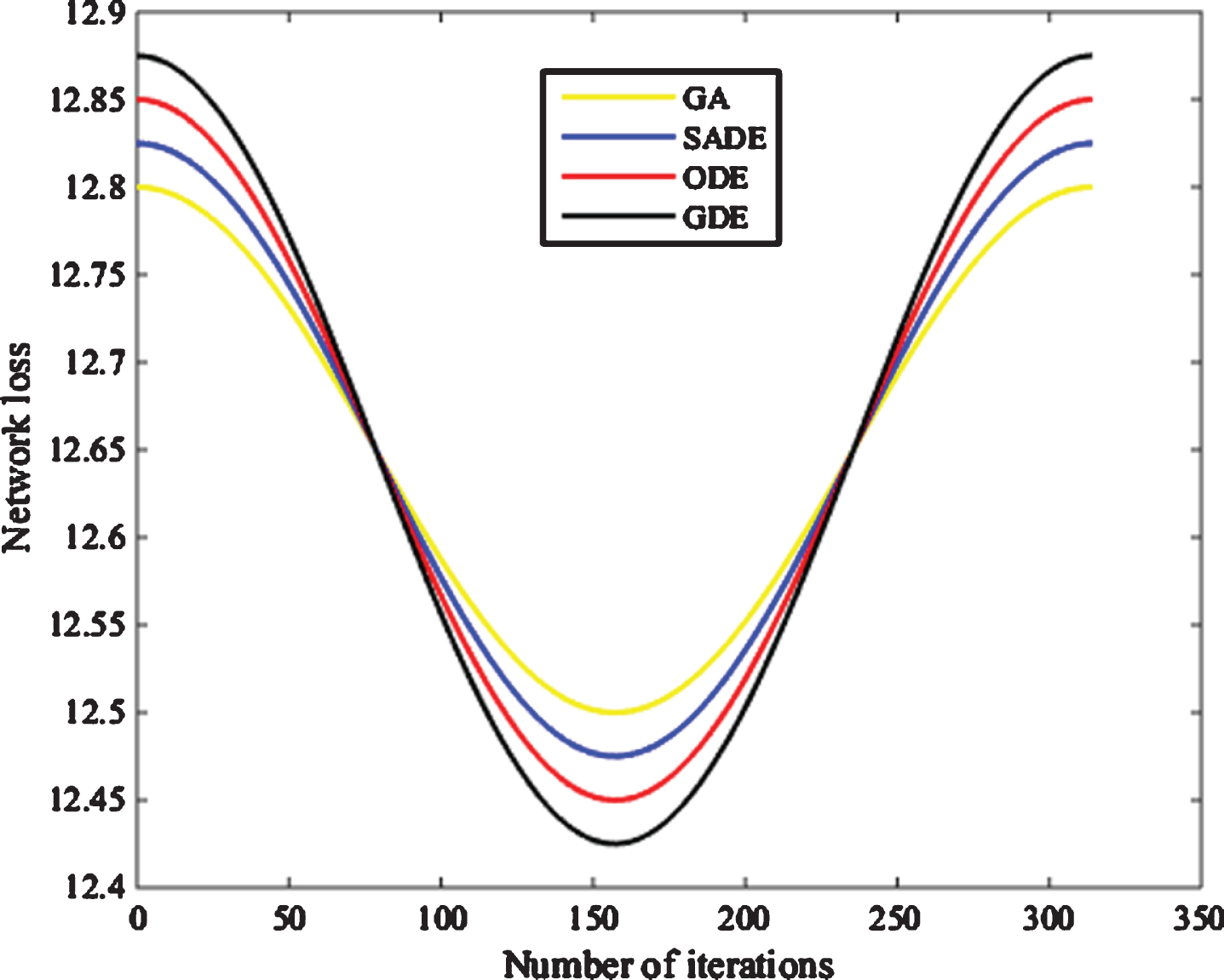
Optimization curves of IEEE 14-node system with four algorithms.
Improving the safety of the power system is also an important goal of reactive power optimization. The voltage stability of the PQ node is a major manifestation of the safety of the power system. The voltage of the PQ node is maintained within a feasible range, and the electrical load can be used for normal operation. Node voltage exceeding the upper limit will cause damage to the load insulation devices. PQ node voltage below the lower limit will cause the load to fail to operate normally and the power grid to collapse. The voltage distribution curve of the PQ node before the optimization (in the initial state) and after the GDE algorithm optimization is shown in Fig. 5. The black solid lines in Fig. are the upper and lower limits of the PQ node voltage amplitude of 1.05 and 0.95, respectively. It can be seen from the Fig. that in the initial state before optimization, the voltage of the 9th PQ node (the node is the M node of the entire system) is below the lower limit of 0.95, which causes the safety and stability of the power system to be reduced. However, after the reactive power optimization of the GDE algorithm, not only the net loss of the system is reduced by 21.40%, but also all PQ nodes are operating within the security range of 0.95– 1.05. At the same time, it can be seen that in the initial state before optimization, the voltage of the PQ node has a large fluctuation, but after the reactive power optimization using the GDE algorithm, the voltage of the PQ node is maintained in a small range and the voltage fluctuation is small.

Node voltage distribution of IEEE 14-node system.
For the IEEE 30-node system, there are 12 control variables for reactive power optimization, and the initial network loss of the system is 20.821546. The minimum network loss obtained by the four algorithms of GA, SADE, ODE and GDE are 16.430271, 16.351247, 16.324412, 16.314782. The reduction rates of the four algorithms for the initial network loss are: 20.97%, 21.45%, 21.48%, and 21.51%. Among the four algorithms, the GDE algorithm obtained the smallest network loss and the largest initial loss reduction rate. At the same time, in the independent experiments, the maximum network loss and average network loss of the GDE algorithm are also the smallest of the four algorithms. The network loss standard deviations obtained by the four algorithms are 1.812548-001, 5.046581e-002, 9.026498e-002, and 0, respectively. The GDE algorithm has the smallest network loss standard deviation and has the strongest optimization stability. The voltage distribution curve of the PQ node is shown in Fig. 6.

Node voltage distribution of IEEE 57-node system.
After using GA, SADE, ODE, and GDE to solve the power system reactive power optimization problem, this paper compares the optimization results of the GDE algorithm with the reported results, and uses the DE algorithm and EP algorithm to solve the power system reactive power optimization problem. The DE algorithm used is currently recognized as one of the basic DE algorithms with the best performance, and the experimental conditions are the same. For the three systems of IEEE14, IEEE30, and IEEE57, the minimum network loss obtained by the DE algorithm is 12.3375, 16.3784, and 23.8324, respectively. The minimum network loss of the three systems obtained by the EP algorithm is 12.4135, 16.5649, and 25.1527. The minimum network loss of the three systems obtained by the GDE algorithm is 12.348161, 16.348152, and 23.645213. By comparing the minimum network loss, it can be seen that for the three systems of IEEE14, IEEE30, and IEEE57, GDE has the smallest network loss among the three algorithms, and the worst and average network loss of the GDE algorithm in independent experiments are also three. The smallest of these algorithms.
With the rapid development of science and technology and artificial intelligence, intelligent optimization technology has been applied in various production areas such as production scheduling, securities investment, production planning and so on. Due to the strong operability of the intelligent optimization algorithm, there are no strict feasibility requirements for the initial solution and no analytical requirements for the objective function and constraints. Therefore, the intelligent optimization algorithm has a good development prospect. This paper studies the principle and application of intelligent optimization algorithms based on network computing platforms. This article describes the development status of intelligent optimization algorithms, analyzes the optimization structure and algorithm principles of genetic algorithms and simulated annealing algorithms, analyzes the characteristics of these three algorithms from the perspective of algorithm performance, and is used in commonly used improved algorithms. Learned the main ideas and strategies for improvement.
This paper proposes four intelligent optimization algorithms with superior performance. These four algorithms are: improved particle swarm optimization (IPSO) algorithm, distributed estimation particle swarm optimization (EDAPSO) algorithm, global differential evolution (GDE) algorithm, and effective global Harmony Search (EGHS) algorithm. The IPSO algorithm designs two-position update strategies to increase the diversity of the population and a random mutation strategy to prevent local optimization. EDAPSO algorithm uses the probability model of good particles to generate part of the population, and then the entire population is updated in speed and position. The GDE algorithm improves the mutation strategy of the basic DE algorithm, introduces the optimal solution as the mutation basis vector, and sets the mutation rate of the algorithm to a decreasing characteristic. The EGHS algorithm eliminates the fine-tuning operation in the process of generating the harmony vector, and fully considers the optimal harmony information in the process of generating the harmony vector.
This paper uses the IPSO algorithm to solve the reliability problem, the EDAPSO algorithm to solve the power system economic dispatch problem, the GDE algorithm to solve the power system reactive power optimization problem, and the EGHS algorithm to solve the integer programming problem. A large number of simulation experiments show that the four algorithms proposed in this paper have good optimization results and optimization stability in solving the above four practical application problems, and show good optimization ability. Intelligent optimization algorithms such as PSO, DE, and HS are relatively basic algorithms. When using intelligent optimization algorithms to solve actual engineering problems, the algorithms need to be improved to make the algorithm better adapt to the characteristics of the problem to be solved.
Footnotes
Acknowledgments
This work was supported by key project of Teaching Reform of Jiangxi Province in 2018 “Research and Practice on the Talent Training Program for Cyberspace Security Majors Based on School-Enterprise Cooperation” (No. JXJG-18-53-2).
This work was supported by Public Projects of Wenzhou Science & Technology Bureau (Grant No. G20150020&No. G20160007) and also supported by Hubei University of Arts and Science Scientific Research Starting Foundation (No. 2059073&2059074).