
Abstract
The huge amount of digital image data in e-commerce transactions brings serious problems to the rapid retrieval and storage of images. Image hashing technology can convert image data of arbitrary resolution into a binary code sequence of tens or hundreds of bits through a hash function. In view of this, based on the image content characteristics, this study improved the traditional hash function and proposed a hash method based on bilateral random projection. At the same time, the projection vectors are acquired in the low-rank sparse decomposition process of the image data matrix, and the projection vectors are group orthogonalized. In addition, this study designed contrast test to carry out research and analysis on the effectiveness of the algorithm. The results show that the proposed algorithm works well and can be applied to practice and can provide theoretical reference for subsequent related research.
Introduction
The realization of the combination of CBIR technology and online shopping platform not only has important theoretical significance for the further development of CBIR technology, but also has important application value for the further improvement of online shopping platform. From a theoretical point of view, commodity image retrieval is an important research direction of CBIR theory, and it is a further expansion and improvement of CBIR theory. From the application point of view, CBIR technology applied to the online shopping platform will certainly facilitate the user’s shopping method and improve the user’s shopping experience, thus promoting the further development of the new e-commerce model of online shopping.
In this paper, a hashing method based on bilateral random projection is proposed. The projection vectors are obtained in the low-rank sparse decomposition process of image data matrix, and these projection vectors are group orthogonalized. The hash function maps the image data into the subspace formed by these orthogonalized projection vectors and performs binary quantization on the projection values to obtain the hash code of the image. The algorithm optimization process involves alternating iterative optimization. In the existing hash algorithm, the iterative quantization hash algorithm also uses a similar method to solve the image hash coding and shows better performance.
The basic idea of the algorithm is to minimize the quantization error of the projection value. Considering the validity of local information preservation, we introduce the local information retention constraint on the iterative quantization hash algorithm. In fact, if we have obtained the hash code of the image, we can make bit selection at some position on the code sequence to make the code more compact and effective. It can be verified that the similarity of the original data plays a major role in the process of screening the hash code. From this perspective, the rationality of the local information retention constraint in our algorithm is also illustrated.
Related work
At present, many researches have been done on the basic theory and application of CBIR. In terms of theoretical research, various new technical methods are emerging. Moreover, some well-known academic journals have opened special editions, and SPIE has an international conference on CBIR and related collections every year. In terms of applications, some research institutes have published their own CBIR prototype system on the Internet, including the famous QBIC system developed by IBM [1], the VisualSEEK system developed by Columbia University [2] and the Virage system developed by Virage [3].
The QBIC system structure is divided into three parts: image library creation, feature extraction and image query. QBIC not only provides basic indexing methods based on color, texture, shape, etc., but also provides image indexing methods based on hand-drawn sketches. The extraction of color features adopts two methods of average color and color histogram, and the extraction of texture features adopts the combination of texture roughness, contrast and directionality. The shape feature is extracted by the shape of the area, the circularity, the eccentricity, the principal axis direction, and a set of transformation-independent moments. Content-based image retrieval technology in OBIC has been applied to practical products such as IBM Digital Library, Hypermedia Manager, and image extensions for DB2 database.
The VisualSEEK system consists of a graphical user interface, a server application, an image retrieval server, and an image archive [4]. VisualSEEK provides image indexing methods based on color and texture. In VisualSEEK, the expression of the global color feature uses a global color histogram, and the expression of the local features of the color uses a binary color set method. For the expression of texture features, a wavelet transform based method is used. Moreover, the technology used by VisualSEEK has been applied in some fields such as electronic libraries, and the Virage system consists of four levels: image expression layer, image object layer, domain object layer, and domain event layer. In addition, the Virage system needs to perform image preprocessing when extracting features, and then extract the feature index of the image. Virage refers to features as “primitives,” which include primitives such as color, texture, and spatial distribution. These primitives can be further divided into general-purpose primitives and domain-specific primitives. VirageEngine and its operations on the image object layer are the heart of Vhge technology. VirageEngine has three main functions: image analysis, image comparison and image management. At the same time, it uses the query engine as a plug-in, which can be applied to general image queries, extended and applied to specific fields [5].
The research results of various aspects of CBIR are endless. However, the use of CBIR technology for commodity image retrieval is a relatively new application field, and has considerable commercial value, so the research literature published both domestically and abroad is limited. In foreign countries, Xia [6] et al. proposed a phased commodity image retrieval method that combines multiple features. The method combines various image bottom features such as color, texture and shape, and firstly uses texture features for preliminary retrieval, and then uses multiple features for comprehensive retrieval, thereby improving the retrieval speed. n addition, a weighted dynamic allocation method for multiple features is proposed in [7]. The method dynamically assigns weights to different types of underlying features according to the resolution of the retrieved images, thereby improving the retrieval effect. In addition, a US-based shopping site called Like, which was established in 2006, provides users with a visual way to search for goods. The website provides a visual search button for each product image. If the consumer is interested in the product or a similar product, the button can be clicked to retrieve all product images that are visually similar to the product image. This product image retrieval method uses CBIR technology, so the Like website has also become the first online shopping platform using CBIR technology [7]. In China, only a few researchers have explored the application of CBIR technology to commodity image retrieval. Wang Hailong et al. [8] proposed a clothing retrieval method based on CBIR. This method summarizes the features of the clothing image into colors, patterns, and styles. At the same time, the method uses the representative color to express the color of the garment, uses the gray level co-occurrence matrix to describe the pattern of the garment, extracts the outer contour feature to express the style of the garment, and proposes a corresponding matching algorithm to realize the comprehensive retrieval of the garment image. Lu Xingjing et al. [9] also proposed a CBIR method for clothing retrieval. The method uses the image background removal technology of the segmentation algorithm to reduce the interference of the background on the extracted features and uses the color histogram and LBP algorithm to extract the color and texture features of the image.
Image content feature retrieval
In computers, image data is usually stored in memory in a vector format, and the dimensions are often very high. Even if the image content features are extracted, the dimension of the feature vector will still be high [10]. In the image retrieval, if the scanning method is used one by one, it will take a lot of time, and with the explosive growth of the number of images in the database, the retrieval time complexity will be greatly increased, and the retrieval result is not satisfactory. In order to reduce the dimensionality disaster and improve the retrieval efficiency, the researchers propose to adopt the Approximate Nearest Neighbor (ANN) search method. In the case of guaranteeing a certain retrieval precision, the retrieval time is greatly reduced, and the practice proves that this method can also meet the needs of users. By constructing a high-dimensional indexing mechanism through hashing, an approximate nearest neighbor search can be implemented [11].
Locally sensitive hashing is the original algorithm used to do image hashing. The basic idea is to hash data into different buckets using a set of hash functions. That is, the more similar data is dropped into the same hash bucket, the more likely the more similar data falls into the same bucket. Images in the database are hashed into different buckets by the same hash function. In the image retrieval, the data is directly searched into the bucket in which the query image is located, and the Hamming distance is used as the similarity measurement criterion, which reduces the search time and improves the efficiency of the search matching. Locally sensitive hashing is an approximate nearest neighbor search method. Figure 1 shows the difference between the approximate nearest neighbor and the exact nearest neighbor of the query image [12].

Comparison of approximate nearest neighbors and exact nearest neighbors.
For a data set S and distance measure D, the specific definition of the local sensitive hash is: If there is any v, s? S satisfies the following two conditions, the hash function H ={ h : S → U } is called ɛ1, ɛ2, p1, p2 local sensitivity [13].
If v ∈ B (q, ɛ1), p rH [h (q) = h (v)] ⩾ p1H, and if v ∈ B (q, ɛ2), p rH [h (q) = h (v)] ⩽ p1H, Where B (q, ɛ) ={ v ∈ S|d (v, q) ⩽ ɛ } is a set f similar points whose distance from the query point q is less than ɛ in the set S, which is also called a hash bucket. p rH is a probability that satisfies p1 > p2, and ɛ1 < ɛ2 is usually a function set. The hash function h ∈ H of k numbers is selected from it to form a function hash function family G ={ g : S → U k }, and g (v) = (h1 (v) , . . . , h k (v)), Then, an integer T functions g1, . . . , g T are selected from the function family G, and each data is first stored in a bucket g i (v) by hashing. In the query phase, the hash bucket that conflicts with the query point q is first located, and then an object similar to q is searched for in the bucket according to the Hamming distance and returned. Figure 2 shows the algorithm flow chart [14].
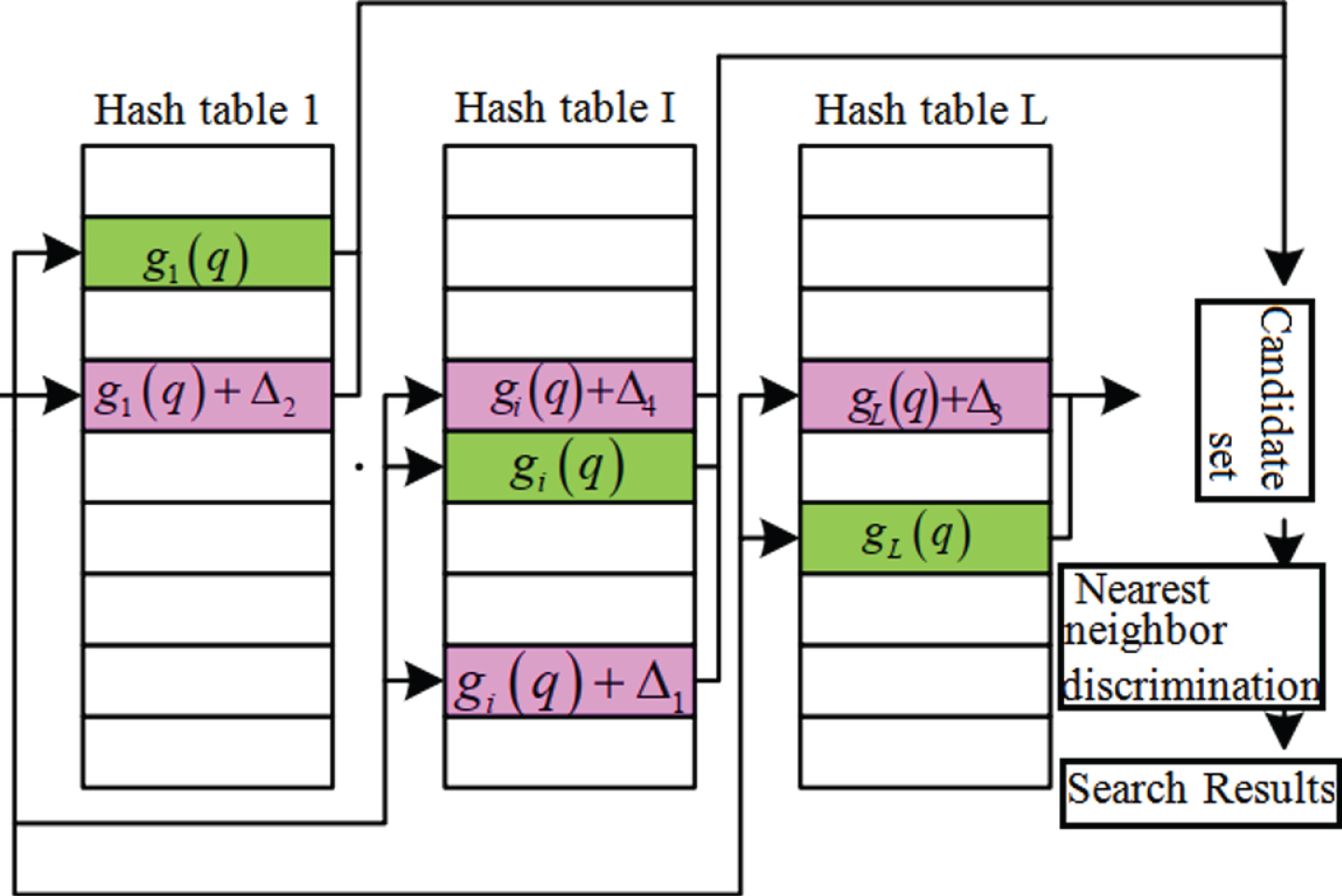
LSH flow chart.
The spectral hash first analyzes and summarizes the conditions that the image hash encoding should satisfy, namely: (1) The hash coded algorithm is easy to implement when obtaining a new image. (2) The images with the same semantics have the same or similar hash coding sequences, and the images with different semantics have different hash coding sequences. (3) The content features of the image can be represented by a shorter hash code sequence. In order to meet the requirements of these three conditions, the spectral hash regards the encoding process as a graph segmentation process. Then, the spectral analysis of the high-dimensional data set is carried out, and the problem is transformed into the dimensionality reduction problem of the Laplacian feature graph by relaxing the constraint condition, thereby obtaining the hash code of the image data. We assume that there are n d-dimensional images in the database, and the database is expressed as
Where, Y
i
represents the i-th row of Y, r represents the length of the hash code sequence, 1 = [1, . . . , 1] T ∈
n
, W, 1 = [1, . . . , 1] T ∈
n
, W, W is the adjacency matrix, and W
ij
> 0 represents the similarity between the two sample points x
i
and x
j
in the original space. In the constraint, 1
t
Y = 0 means that each hash value has a probability that 0 or 1 is equal, and Y
T
Y = nIr*r Y
T
Y = nIr*r indicates that there is no correlation between hash codes on different bits. The diagonal matrix D is introduced such that the diagonal element D
ij
= ∑
j
W
ij
and the objective function is [16]:
In the formula, L = D-W is called Laplacian matrix. As we all know, this is a NP-hard problem, but if the condition Y
ij
∈ { 1, - 1 }, then the problem becomes that the eigenvector corresponding to the smaller r eigenvalues of the Laplacian matrix is calculated (excluding the 0 feature). By selecting an appropriate threshold, these feature vectors are quantized to obtain an image hash code. In order to solve the hash coding problem of the query image, it is also necessary to consider expanding the above problem. Assuming that the data in the image library is sampled from the probability distribution p (x), equation (2) can be expressed in the expected form as [17]:
The constraint Y
ij
∈ { - 1, 1 } Y
ij
∈ { - 1, 1 } is relaxed to simplify the problem to a spectral problem, and the solution of the objective function is a characteristic function of the Laplacian-Beltramy operator. Assuming that the overall obeys a uniform distribution of U(a,b), the eigenfunctions and eigenvalues of a Verapela-Beltramy operator are [18]:
Figure 3 shows the steps of the SH algorithm: The first step is to obtain the principal component directions of the image data by using a principal component analysis algorithm. The second step is to calculate the eigenvalues according to equation (4) in each principal component direction and select the first r minimum values to obtain a total of r * d eigenvalues. Then, it is sorted in order from small to large, and the first r minimum eigenvalues are selected to calculate the corresponding feature function values. The third step is to binary code the feature function values to obtain hash coding [19].

Spectrum hash algorithm flow chart.
The Principal Component Analysis (PCA) method was used in the first step of the algorithm. This method is a classical linear dimension reduction method, and the method arranges the eigenvalues of the training data covariance matrix in descending order. The corresponding feature vectors are referred to as a first principal component direction and a second principal component direction, respectively, up to the d-th principal component direction. The disadvantage of spectral hashing is that it has two conditions that are difficult to satisfy at the same time in the actual situation, that is, the data is assumed to be sampled from a multidimensional uniform distribution and the hash codes in different dimensions are required to be independent of each other. Therefore, the widespread use of spectral hashes has been limited [20].
The most basic evaluation index in the field of image retrieval is the precision-recall rate index. The precision and recall rate respectively reflect the two most important aspects of the retrieval system. The precision is a measure of the signal-to-noise ratio of the image retrieval system, that is, the ratio of the number of images in the search result related to the content of the query sample to the total number of images retrieved. The recall rate is a measure of the success rate of the retrieval system, that is, the ratio of the number of images in the search result related to the content of the query sample to all related images in the image library. The specific representation of the two is as shown in Equation (5).
In the formula, T represents the number of images in the search result related to the content of the query sample, N represents the number of images in the search result that are not related to the content of the query sample, and F represents the remaining image in the image library except the retrieved related image. In this experiment, the precision-preview curve is based on the search result that the Hamming distance between the query image and the training image is less than a certain threshold. The precision of the results of the first K numbers (precision K) and the recall rate (@ recall K) are also commonly used evaluation indicators in the field of image retrieval. In this experiment, the search results are sorted according to the Hamming distance, and the search results of the first K numbers are used to calculate the precision and recall rate for the @ precision K curve and the @ recall K curve. In addition, the paper also verified the Mean Average Precision (MAP), and the average accuracy is the average of the accuracy after each related image is retrieved. The higher the correlation image retrieved by the system, the higher the average accuracy.
The color histogram algorithm is based on the idea of counting the number of times different pixels appear in an image. Its mathematical calculation formula is shown in (6).
Where f (x, y) M×N is the value of the image color at point f (x, y), M × N is the size of the two-dimensional image, and C is the set of image color sets. Figure 4–C 6 is a color histogram of the flowers in the RGB color space.

R component histogram.
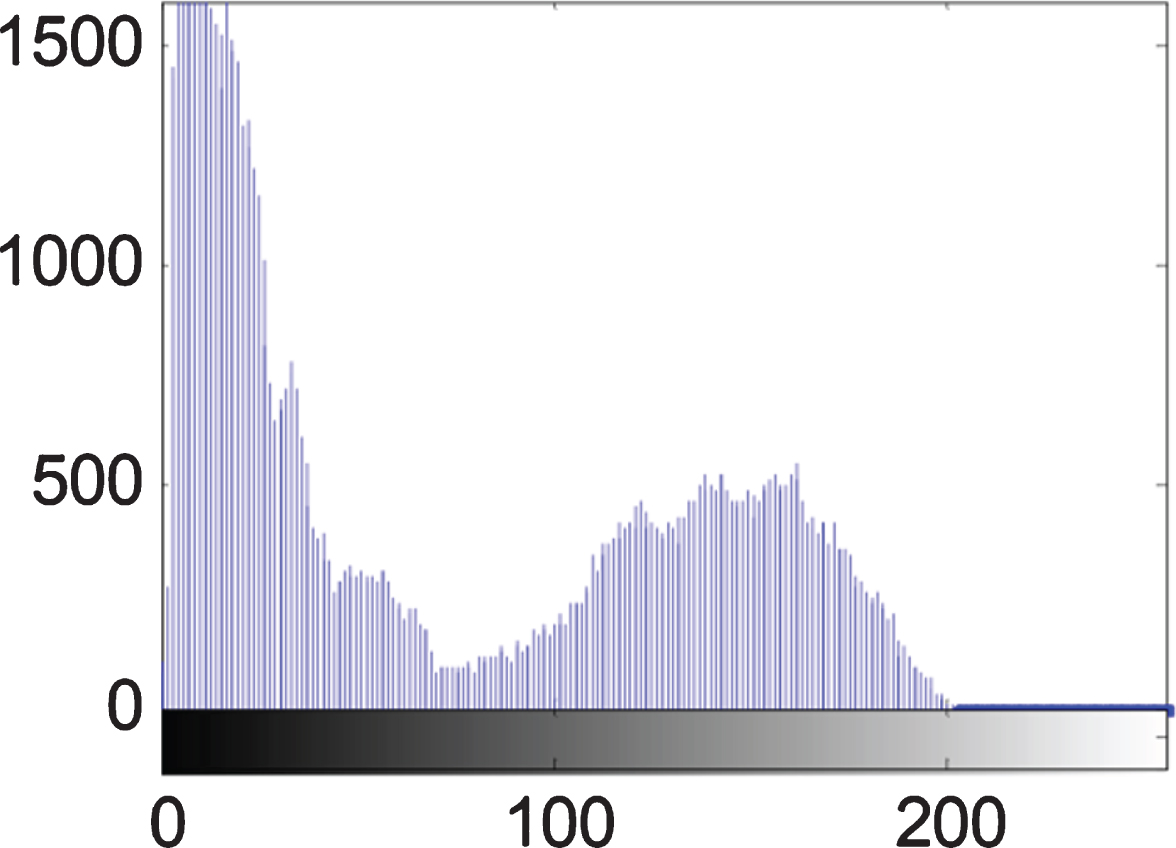
H-component histogram.
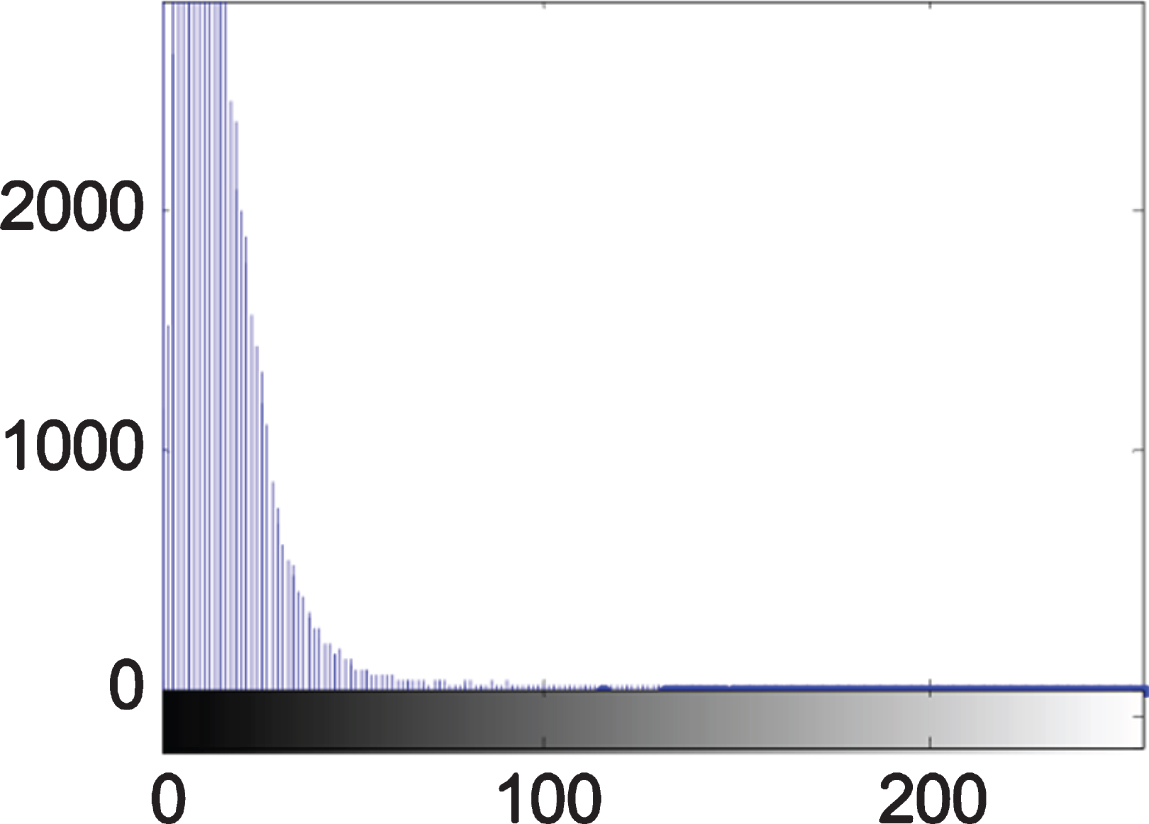
B component histogram.
The histogram features generally used in retrieval need to be obtained by quantization methods. The advantages of the color histogram are: the feature extraction algorithm is simple, and the color distribution in the color image has an overall description; but it has certain defects, it does not consider the spatial correlation of each color, and cannot perform the characteristics of the target object Means.
Color Moments is another image color feature description algorithm. The form of the color descriptor is simple and effective. It can be known from mathematical related theories that moments can describe the color characteristics of an image, and higher-order moments contain less image color information and have a larger amount of calculation. Therefore, low-order moments are generally used to represent color information. The mathematical calculation of the first three moments is as follows
First moment:
Second-order center moment:
Third-order center moment:
The advantages of color moments are: there is no quantization process, the extraction process is simple, and the color information of the image can be described with lower-dimensional features. However, its disadvantage is that it cannot describe the layout of the color space, and the characteristics of describing the image have certain limitations.
Color correlation map is a color feature extraction algorithm based on spatial position. This algorithm makes good use of spatial relationships, combines the appearance probability of color types and spatial position to represent the image, and forms a color descriptor.
For image I, Ic (i) refers to the collection of colors c (i), and its mathematical calculation formula is as follows:
Where i. j∈ [1,2,...,n, 1,2,...,n], n is the number of different colors the image contains, k ∈[1,2,...,d, 1,2,...,d], d represents the maximum pixel distance set independently, | p1-p2 | is the distance between pixels p1 and p2. Therefore, the color correlation diagram is similar to an index indication table, which is the information describing the color pairs of the image <i, j >, which is the probability information of the color pair, referring to the color c in the image (i) and c (j), and the ratio of color to distance k in the whole image is also called the probability of occurrence. For an image, if the relationship between each color is considered, this will increase the amount of calculation, and the spatial complexity is very high, reaching O (n2d). Later studies by scholars proposed a simplified method for calculating color correlation maps, which ignored the spatial relationship of different colors, which greatly reduced the number of calculations and reduced the space complexity from O (n2d) to O (nd)
The advantages of a color correlation map are: it reflects the spatial information between colors, and the image has a strong description ability; its disadvantages are a large amount of calculation, high spatial complexity, and a high feature dimension.
The core idea of the traditional LBP algorithm is: grayscale the color image to obtain a two-dimensional grayscale image, and then based on the neighborhood window of3×3,the center position is the key point, and the key point is compared in this neighborhood window If the neighborhood is smaller than the key point, the neighborhood location is encoded as 0; otherwise, the neighborhood is encoded as 1. The calculation formula of LBP is as follows:
Where gc is the central pixel value and g p is the neighborhood pixel value.
After the LBP texture feature extraction algorithm was proposed, many variants of texture feature algorithms have been proposed one after another. The following introduces a classic variant algorithm, LTP (Local Temnary Patterns). The calculation formula of this algorithm is shown in (13), but the threshold is set for the binarization, and s (x) is changed:
The Fourier Descriptor is a method based on closed boundaries to represent shape characteristics. It is a periodic function. The coefficients after the Fourier transform are closely related to the shape of the image, so the Fourier transform is usually used. Coefficient to describe the shape of the object. Let L be the edge curve of a certain area P, S be the perimeter of L, the initial point b0 of edge L, b be the point of movement at edge L, and s be the arc length in the counterclockwise direction between b0 and b, The coordinates of the moving point b (x (s), y (s)) represent the arc length, and its mathematical expression is:
Since the Fourier transform is a periodic function:
Let t = 2π s/ S, then the above formula can be expressed as:
L (t) is a periodic function of length 2π. The expansion of curve L is:
Usually the first few components of the Fourier series, that is, the shape characteristics of the Fourier descriptor are described as follows:
Among the algorithms for describing shapes based on regions, one of the more commonly used algorithms is invariant moments, which use the moment parameters of the area occupied by the image target as the shape feature descriptor of the image.
Invariant moments are the most widely used description method. Hu 7th moments are one of the commonly used moment features. Let f (x, y) represent the image, then the mathematical expression of the moment of order p + q is as follows:
Normalize the center moment as shown below.
Euclidean distance is easy to calculate and is one of the classic distance algorithms. This method is also used in many image retrieval. The similarity of images can be evaluated based on Euclidean distance, where the formula for calculating Euclidean distance is shown below.
Dist (a, b) is a numerical index for determining the similarity between two image features, and the similarity becomes higher as the value of Dist (a, b) decreases.
χ2 distance is a statistical distance-based calculation method, and it is also a more classic distance calculation method in image retrieval. The specific distance calculation formula is as follows:
Quadratic distance is a measure that is more in line with human perception of color. The retrieval result is generally more accurate than the Euclidean distance, but its calculation is large.
Where M=[mij], mij refers to the value of the correlation between color i and color j. The calculation of the quadratic distance takes into account the correlation between colors and has a high retrieval effect.
Hamming distance is the distance between binary feature vectors. When Hamming distance is used in image retrieval, the feature vector is first encoded into a binary code according to a certain encoding method, and then the formula is calculated based on the Hamming distance. Calculate the distance. The specific calculation formula is shown below.
nbits represents the number of encoded bits. Many of the many hash-based retrieval algorithms calculate similarity based on Hamming distance. There are many algorithms in image retrieval systems, and it is very important to make a general evaluation of various algorithms. The following introduces several commonly used evaluation criteria for image retrieval performance. The matching percentage is a discriminant evaluation method and an index for judging the quality of the search results. Its calculation expression is as follows
Where N is the total number of images returned by the search results, and S is the position of the target image in the order of the search results. Under normal circumstances, the average of multiple experimental data is used to measure the retrieval effect. The advantage of the retrieval evaluation criterion of the matching percentage is that the calculation is simple. However, its shortcoming is that it only applies to only one similar image, and its application scope is very limited.
Assume that the total number of images returned by the search is N, the total number of related images is NR, the position of the related images in the search results is ρ, and the theoretical total number of targets related to the query image is NA. for:
The loss rate of the related images is calculated as follows:
The implementation process of the system includes the feature establishment process of the offline product image library and the online product retrieval process.In order to improve the retrieval efficiency of the system, the product feature library adopts the offline mode, and the color texture histogram features CEDD and SiftBowDirfk features of the commodity library image are extracted and saved, and the commodity library features are established. The process of searching for online goods: First, the query product was input, and the color texture histogram CEDD feature was extracted for the query product, and the method based on the sparse multi-category classification is adopted to classify the query product. Moreover, the items of the N categories of products having similar merchandise were queried to constitute a set of candidate items, which is used as a product library in which the features in the exact search layer match. Then, the SiftBowDirfk feature of the query image was extracted, and the SiftBowDirfk feature and the CEDD feature were weighted and merged. At this point, the product library features in the selection were also weighted and merged. The precise search layer used the fusion feature to perform the similarity comparison feature, and the measurement method was the Euclidean distance. Finally, according to the result of the similarity comparison, the first eighteen images similar to the query image were output, and the results were displayed for the user to visually view the query result.
The product image library used in this system is the collected product, part of which is from the product image in PI100, and part of it comes from the goods collected on Taobao. The product image library has 10 categories, as shown in Fig. 7, each product has 100 images, that is, the product library has 1000 images.

Sample of the merchandise library image.
In the image screening layer, 90 pieces of each type of commodity were randomly selected as the training library, that is, there are 900 images of the training products. The extracted CEDD feature composition dictionary was used for image filtering based on sparse multi-category image classification. In this paper, 10 images of each type of product were selected as tests, that is, there are 100 images of test products. The average precision and recall of the 100 test items were calculated to evaluate the performance of the retrieval system.
The screening layer of the product image is a method based on image content feature retrieval. First, the image was trained from the commodity library, and the CEDD feature was extracted from the training image library to construct a sparse dictionary. The method was based on the no-dictionary training process, and the query commodity was sparsely decomposed under the constructed dictionary. Then, the image content feature retrieval method proposed in this paper was used to classify, and N categories of tags of the query products were obtained to form a candidate product set of the accurate search layer, so as to achieve the purpose of screening the product images.
It can be seen from Table 1 that in the commodity image library, the classification accuracy of CEDD features is higher than that of EHD features and HSV color histograms. Under the same characteristics, the proposed method is more accurate than the traditional classification, and the effectiveness of the proposed image screening method is also verified.
Classification accuracy of different features and methods
In the precise retrieval layer, this paper used Euclidean distance to measure the similarity between product image feature descriptors. First, under the online, the characteristics of the library of the commodity were extracted, and then the corresponding features of the query commodity were extracted, and the similarity between the query product and the feature vector of the image in the commodity library was compared. According to the similarity, the top M items of the same or similar as the query image were output. Table 2 is a comparison of the single feature and the Dort fusion method of this article in returning 20 pieces of product retrieval performance. Figure 8 is a P-R curve comparison of a single feature and the multi-feature weighted fusion method herein.
Performance comparison of 20 products returned by different methods (%)
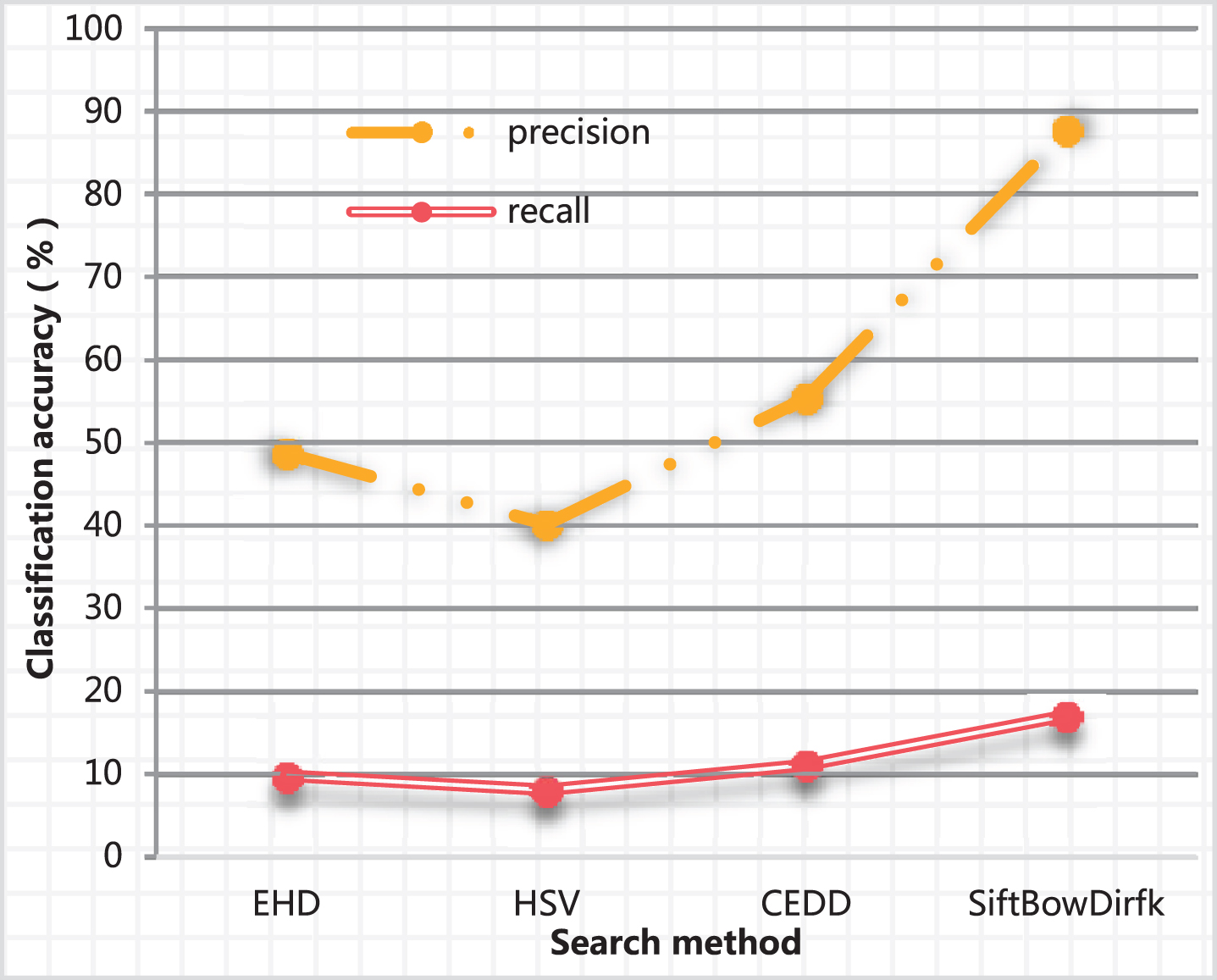
P-R curve of a single feature and the Dort fusion method of this paper.
It can be seen from Table 2 and Fig. 8 that for product images, SiftBowDirfk has the best retrieval performance for single feature retrieval, followed by CEDD features, and the retrieval performance of EHD features and HSV histogram features is poor. Therefore, in this feature fusion method, the CEDD feature and SiftBowDirfk are used for weighted fusion, and the weight of SiftBowDirfk is larger. Form the PR curve of the single feature SiftBowDirfk and the multi-feature fusion method of this paper shows that for the retrieval of commodity images, the multi-feature weighted fusion method of this paper is slightly higher than the single SiftBowDirfk feature retrieval, and its retrieval performance is significantly improved compared with the single CEDD feature.
Comparison of retrieval performance of 20 items returned by single layer and hierarchical retrieval (%)
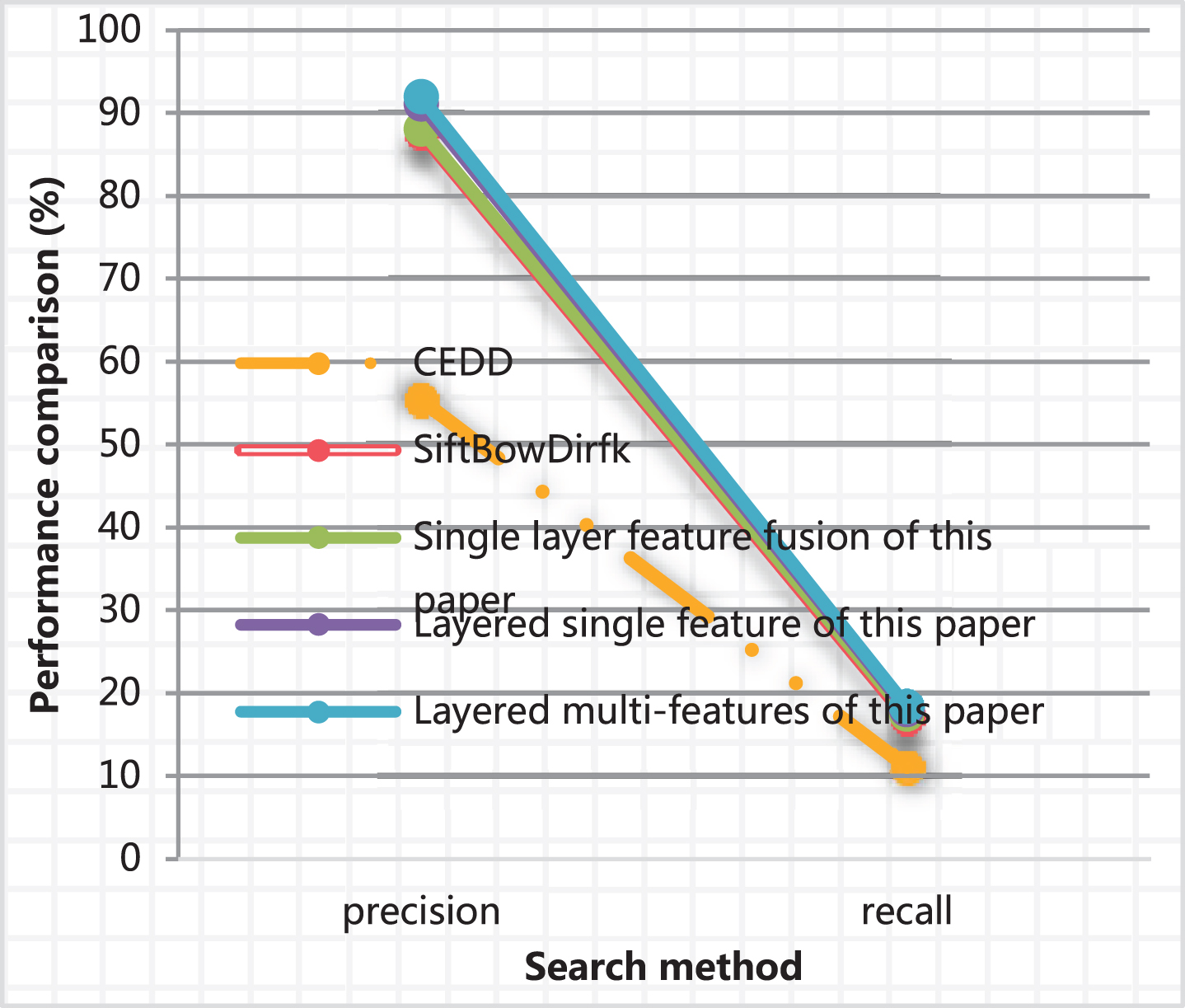
Is a single layer and the P-R curve of the layered goods retrieval in this paper.
In the layered image retrieval layer, firstly, the query commodity was input, and the query product was classified by using the sparse-based multi-category classification method proposed in the paper, and the commodity library image was filtered to form a candidate product set. Then, according to the multi-feature weighted fusion method proposed in this paper, the searched goods were accurately retrieved. Finally, the first M items that are the same or similar to the item being queried were returned to the user. The search performance evaluation value calculated in this experiment is the average value of multiple product searches. Table 3 is the data of the precision and recall rate of the single-layer commodity search and the hierarchical commodity search method of this paper, which returns the precision and recall of the first 20 commodities. Figure 9 is a P-R curve of a single layer commodity search and a layered goods retrieval method of this paper.
It can be seen from Table 3 and Fig. 9 that the precision and recall rate of the layered goods image retrieval in this paper is higher than that of the single-layer feature retrieval, which verifies that the hierarchical image retrieval method of this paper is effective.
Content-based image retrieval is an important re-search direction of multimedia information retrieval, and it is a retrieval technology based on “search by graph”, which is widely used in many fields, such as commodity image retrieval in e-commerce. With the popularity of the Internet, digital images have grown significantly and become the source of the main in-formation in the multimedia society. A wide variety of images are available throughout our daily life learning, and how to quickly and accurately analyze and retrieve image information has important re-search implications.
With the rapid development of digital multimedia technology, Internet technology and e-commerce, big data has attracted more and more attention. As a carrier of information, images contain extremely rich content and are intuitive. Therefore, picture applications are one of the fastest growing applications in both the e-commerce and mobile Internet sectors. However, in the face of massive image data in the database, the rapid retrieval of images has become a challenging problem, which has attracted extensive attention from academia and industry. The traditional image indexing technology cannot meet the retrieval time requirements. To solve the problem of large-scale database high-dimensional indexing, content-based image hashing technology has gradually developed as an emerging technical means. This paper mainly studies the content-based image hash retrieval algorithm, and the main research results are as follows:
(1) The classic image hash algorithm is introduced, and its basic ideas, implementation steps and their advantages and disadvantages are analyzed, summarized and summarized. The content-based image feature extraction method is studied, and the Gist feature extraction method and the similarity metrics used in the hash-based image retrieval algorithm are introduced in detail.
(2) A bilateral random projection hashing method is proposed to solve the problem of randomness of local sensitive hash, low accuracy and improved retrieval time complexity caused by multi-hash table. The local sensitive hash method does not depend on the data set in the learning process of the hash function. In order to improve the retrieval precision, the hash function learning process depends on the data set. The method combines the matrix low-rank de-composition based on bilateral random projection and the vector packet orthogonalization technique to learn the hash function, which improves the hash coding quality. Compared with the traditional hash method, this method shows better performance in various indicators of image retrieval.
(3) The local hold iterative quantization hash pro-posed in this paper, and the algorithm optimization process uses the alternating iterative quantization method, which is consistent with the bilateral random projection hash algorithm optimization method pro-posed in Chapter 3. Since the variance distribution of each principal component direction is not uniform, the iterative quantization hash adopts a method of rotating the principal component direction to obtain a direction in which the variance is uniformly distributed, and the learned hash function has better performance. The local hold iterative quantization hash method takes into account the importance of embedding high-dimensional data into low-dimensional Hamming space and maintaining similarity information. On the basis of iterative quantization hash, the local information retention constraint is explicitly introduced, which improves the original method and improves the coding quality. Compared with the traditional methods, the algorithm has certain advantages in various evaluation indexes of image retrieval.
Conclusion
In the mobile network environment, performing massive product image retrieval is a challenging and hot topic, which involves many factors. In terms of image transmission, there are many factors to consider, such as the network environment, mobile communication devices, and the like. How to improve system throughput and improve transmission efficiency through concurrent transmission strategies will be a good direction. Aiming at the problem of large number of images, large number of feature matching and high computational cost in content image retrieval, this paper proposed a method for searching and screening basic image content features, filtering the image library and filtering out images that are not similar to the query image. Aiming at the deficiency of single feature description image, this paper adopt-ed multi-feature weighted fusion method to represent image and designed and implemented a commodity image retrieval experiment system to test the effectiveness of the above algorithm. The system is a single file-based retrieval system, which has the characteristics of simple design and convenient use and is suitable for small-scale image retrieval experiments of image libraries.