
Abstract
Metaheuristics gained world-wide popularity and researchers have been studying them vigorously in the last two decades. A relatively less explored approach in the improvement of metaheuristics is to design new neighbor generation mechanisms. Neighbor generation mechanisms are very important in the success of any single solution-based heuristic since they directly guide the search. In this study, a neighbor generation mechanism called cantor-set based (CB) method for single solution-based heuristics which use permutation solution representation is described. The inspiration for CB method stems from the recursive algorithm that constructs a cantor set which is a fractal set. Three variations of CB method are discussed (CB-1, CB-2, CB-3) considering the presented design possibilities. The computational experiments are conducted by embedding the mechanisms into the classical local search and simulated annealing algorithms, separately, to test their efficiency and effectiveness by comparing them to classical swap and insertion mechanisms. The traveling salesman problem (TSP) and quadratic assignment problem (QAP) which are very different problems that have incompatible characteristics have been chosen to test the mechanisms and sets of benchmark instances with varying sizes are chosen for the comparisons. The computational tests show that CB-2 gives very favorable results for TSP and CB-1 gives favorable results for QAP which means that CB-2 is suitable for problems that have steep landscapes and CB-1 is suitable for the problems that have flat landscapes. It is observed that CB-3 is a more generalized mechanism because it gives consistently good results for both TSP and QAP instances. The best mechanism for a given instance of the both problem types outperforms the classical neighbor generation of swap and insertion in terms of effectiveness.
Keywords
Introduction
Real-life problems are usually too complex to solve using exact solution methods. Since there is not a polynomial time algorithm for NP-hard problems, exact optimization methods that need exponential computation time to solve them are not useful. Therefore, heuristic methods are regarded as an alternative way to deal with computationally hard problems. Even though these methods cannot guarantee optimality, they are effective in finding approximate solutions within relatively short computer time. Heuristic methods for optimization problems were introduced in 1950s and hold research value since then. Metaheuristics are multi-purpose heuristics that can be classified considering their different characteristics. One of the main classifications includes single solution-based or population-based metaheuristics. As the names suggest, single solution-based metaheuristics manipulate a single solution, while population-based metaheuristics transform a set of solutions throughout the search. Clearly, in both classes of the metaheuristics, any solution point in the search space must be represented by an encoding scheme. Encoding must be appropriate to represent all solutions and a solution must be connected to other solutions in the search space. Single solution-based metaheuristics transform a solution into neighboring solutions using a neighbor generation mechanism (also named move operator, variation operator, transformation, manipulation, perturbation). The complete set of resulting neighbors constitutes the neighborhood of the solution. Type of the neighbor generation mechanism depends on the encoding scheme (i.e. solution representation). In single solution-based metaheuristics, the neighbor generation mechanism plays a crucial role in the performance of the algorithm since it explores the neighbors iteratively until a pre-determined stopping condition is met. If the neighbor generation mechanism used in the search heuristic is not compatible with the problem at hand, it cannot provide enough exploration and exploitation features.
More formally, a neighbor generation mechanism is a pre-defined list of rules to make small perturbations on
This study describes and improves a novel neighbor generation mechanism called CB method presented by the same authors in [16]. In the previous study, CB method is embedded into local search (LS) to see the computational performance of the method on TSP instances. However, the method is observed to be very slow. In this study, modifications are made to make CB faster, more efficient and also, to test its performance on a different combinatorial problem which is QAP. As presented in [16], CB method is inspired by the recursive algorithm that generates stochastic cantor sets which are fractal sets. Some famous fractals are given as examples in Figure 1.
Fractal set examples.
The objective of CB mechanism is to generate self-similar neighbors that retain the good chunks of the current solution and which are different enough. It must be noted that CB mechanism is not developed for a specific problem type. It is designed as a general mechanism which can be used for any combinatorial problem where a solution point can be represented by permutation encoding. TSP and QAP are chosen to be test problems because they exhibit very different characteristics as optimization problems. When solution spaces of both problems are considered, solution space of TSP has a steep landscape and the search benefits from drastic changes in the neighborhood whilst solution space of QAP has a flat landscape and the search benefits from subtle changes in the neighborhood.
The following literature on studies of designing and improving upon novel neighbor generation mechanisms shows that the research is very limited in the area. Generally, either the existing mechanisms or their combinations are used in heuristic algorithms.
[22] compared six separate neighbor generation mechanisms for TSP, QAP and flow shop scheduling problem to investigate simulated annealing (SA) application to combinatorial optimization problems that are suited to permutation encoding. The compared mechanisms are; (1) swapping two elements on consecutive positions (consecutive swap), (2) swapping two elements on any random positions (general swap), (3) inserting a random element into a random position (general insertion), (4) changing the positions of a subsequence of elements randomly (block insertion), (5) reversing the positions of a subsequence of elements randomly (block reversion), (6) reversing the positions of a subsequence of elements randomly and/or inserting a subsequence of elements into another random position (block reversion and/or block insertion). They concluded that different methods are suitable for different problem types such that the 6th, 4th and 2nd mechanisms are the best for TSP, flow-shop scheduling and QAP, respectively.
Similar neighbor generation mechanisms analyzed in [22] were also considered by [4] to show the effects of neighbor generation mechanisms on the performance of Tabu Search. The proposed Tabu Search algorithm alternates between insertion, block insertion, or swap mechanisms randomly. The purpose is to balance exploration and exploitation for solving the permutation flow shop scheduling problem. The proposed approach outperforms the compared algorithms in terms of speed and performance. Also, [15] tested the performance of the same neighboring mechanisms embedded into a hybridization of SA, LS and genetic algorithms to solve flow shop scheduling problem and the random swap mechanism was selected as the best mechanism as a result of the experimentation.
[7] presented iterated LS, SA and their hybridization to solve scheduling and transportation problems simultaneously in a job shop environment. Swap and insertion are used as neighbor generation mechanisms in the presented heuristics. However, a method called neighborhood reduction is added to the mechanisms in which the size of the neighborhood is decreased by some predefined rules. The experiments are done by using swap, reduced swap, insertion, reduced insertion, and reduced swap and insertion. They conclude that using both reduced swap and insertion gives the best performance.
[23] designed a neighborhood structure and embedded it into the SA algorithm to solve high school timetabling problem. In the study, neighbors are generated by using the swap mechanism between time slots, instead of assignments which is the usual option. After performing computational tests on two sets of benchmark instances, they concluded that their heuristic performs better than the existing methods.
[3] aimed to compare both single solution-based heuristics (LS, SA, Tabu Search, Variable Neighborhood Search) and population-based heuristics (Genetic Algorithm, Memetic Algorithm) in their experiments. They stated that the most commonly used neighbor generation mechanism in QAP studies is swap mechanism and for that reason they used swap for all the single solution-based algorithms. Their results showed that there is no single best algorithm for solving QAP and different instances respond well to different heuristics.
There are various neighbor generation mechanisms such as r-opt [11], ejection chains [8], stem-and-cycle [9] that are designed specifically for TSP and cannot be generalized to other combinatorial problems. However, most of the studies in the literature use swap for QAP (see for examples; [2, 20]) meaning there is not a neighbor generation mechanism specific to QAP. On the other hand rthe interest of the present study lies within generalized neighbor generation mechanisms not problem specific ones. In this study rwe designed and tested variants of CB method and used them to solve both TSP and QAP.
In the 2nd section, the test problems (TSP, QAP) and search heuristics (LS, SA) in which CB method is embedded are explained briefly. CB method is described in the 3rd section in detail. An experimental study conducted for several design issues of CB method and a comparative study of CB mechanisms with swap and insertion neighbor generation mechanisms is presented in Section 4. Finally, the conclusions are discussed in the last section.
TSP and QAP are frequently used in the literature to analyze performances of new methods since these problems are easy to code but hard to solve. TSP is a popular problem with the metaphor of a salesman starting from a city, has to visit n cities (from a known list of cities) exactly once and then he has to return to the first city. He wants to select an order to visit the cities with minimum total distance travelled. In QAP, there are a set of facilities and a set of locations. The distances between locations and the flows between the facilities are fixed. The objective is to assign each facility to each location while minimizing the sum of the products between flows and distances. Interested readers are referred to 18] and [6] for further information on TSP and QAP including their mathematical descriptions.
The objective of this study is to show the performance of CB method by embedding it into various search algorithms rather than to design a sophisticated heuristic algorithm for the selected test problems. For this purpose, basic LS and SA heuristics are selected to embed CB method into. These heuristics are explained briefly in the next subsections.
Local search
LS is the most basic single solution-based heuristic. LS starts from x, which is a single feasible initial solution. At each iteration, N (x) (whole or partial neighborhood of a solution) which is the set of neighbor solutions x′ is investigated. The search proceeds from one feasible solution to a better feasible solution by using a neighbor generation mechanism until a locally optimal solution is reached. The new current solution can be selected by one of the following strategies: best improvement, first improvement and random selection [21]. In this study, the best improvement is used as the selection strategy and the algorithm stops at the first time there is no better solution among the explored neighbors.
Simulated annealing
SA is a simple and effective stochastic heuristic proposed by [10]. SA algorithm accepts better solutions as they come along. However, in the course of the run, if the algorithm encounters a worse solution, it accepts that solution with a probability of
Cantor set based neighbor generation mechanism
Fractals are described by Mandelbrot [12]. Although there is no specific definition for what a fractal is, one of the definitive characteristics of fractals is that they have repetitive structures at different length scales (statistical self-similarity). One of the famous fractals is a cantor set which was discovered by Smith in 1870s and it was introduced to the world by Cantor in 1880s. Cantor sets can be built by recursive algorithms which is the inspiration of the proposed CB method. The steps in the recursive algorithm that generates a deterministic cantor is described in Figure 2 [1].

The recursive algorithm that generates a deterministic cantor set.
The deterministic generation of cantor sets is easier to explain as the intervals can be given specifically. Hence, it is easier to understand the stochastic cantor sets after observing deterministic cantor sets. In stochastic generation of cantor sets, in step 2, the line is not divided into three parts with equal lengths, but it is divided into three parts with random lengths.
In step 2 (and in the following steps), notice that the concerned part is divided into three parts and the middle sections are removed. However, if a section is removed from the solution representation, the integrity of the representation (which is the permutation of n elements) will be lost. Therefore, the dividing process is executed in CB mechanism, but the middle parts are committed to memory. CB mechanism produces similar neighbors that are different enough, by using the self-similarity aspect of fractal sets.
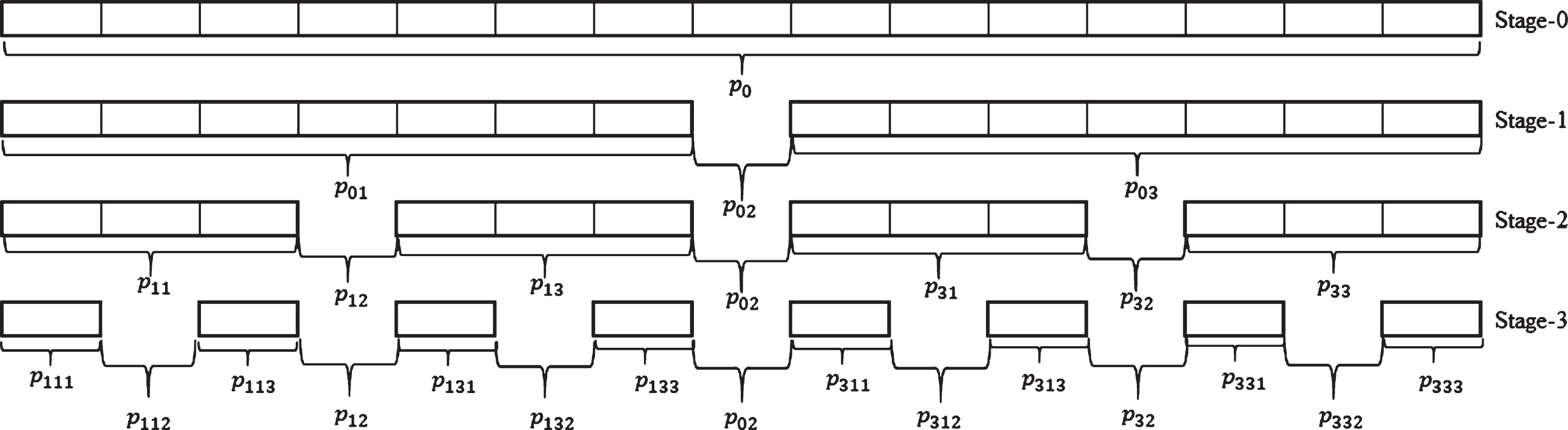
Figure 3 is presented to explain the structure of CB mechanism. In the initial stage (stage-0), the permutation solution representation, x = [x1, x2, . . . , x n ], is represented by a complete string (p0) of size n, where n is the problem size. In stage-1, p0 is divided into three substrings. For this purpose, a starting element, s, is systematically increased from 1 to (n - 2). For each s, an index number, m, is increased from 1 to (n - s - 1) such that the first substring (p01) contains the variables [x1, x2, . . . , x s ], the second (p02) contains [x(s+1), x(s+2), . . . , x(s+m)], and finally, the last substring (p03) contains [x(s+m+1), x(s+m+2), . . . , x n ]. For the sake of clarity, the dividing process in stage-1 is explained as follows:
A representative figure for how substrings would look like (mid-substrings are void to improve visibility).
(1) Substring p01 = [x1, x2, . . . , x s ] is changed for each s = 1, 2, . . . , n - 2. This means that p01 always starts from x1 and the number of elements in p0 is increased from 1 to n - 2 sequentially. Therefore, the number of times p01 is changed depends on problem size n.
(2) Substring p02 always starts with the element xs+1. The number of elements in p02 is changed from 1 element, up to n - 2 elements and for each different p02, p03 consists of the remaining elements such that, p03 = [xs+2, . . . , x n ] for p02 = [xs+1], p03 = [xs+3, . . . , x n ] for p02 = [xs+1, xs+2] and so on. The last possible choice for p02 is xn-1 which leads to p03 = [x n ].
Notice that the dividing process explained above is also valid for stage-2 and stage-3. For stage-2, steps 1 and 2 are applied to p01 and p03 (left and right parts in the recursive algorithm which generates a cantor set), separately. The mid-substring (p02) is never divided to maintain the self-similarity structure. From p01, the substrings p11, p12 and p13 are determined and the substrings p31, p32 and p33 are determined from p03 where p ij means that jth substring of string-i. In stage-3, steps 1 and 2 are applied to p11, p13, p31 and p33 separately. Hence, the substrings p111, p112 and p113 are generated from p11, the substrings p131, p132 and p133 are generated from p13, the substrings p311, p312 and p313 are generated from p31, and finally the substrings p331, p332 and p333 are generated from p33.
Once the substrings in the respective stages are obtained, the neighbors are generated using the permutations of the concerned substrings. In this study, two different permutation schemes are designed to obtain the neighborhood of a given solution. The first scheme provides big perturbations on the solution while the second scheme provides small perturbations as explained in the next two subsections.
In the first scheme, the neighbor sets of each stage are generated by permutating appropriate substrings. In stage-1, p ij is permutated for each j = 1, 2, 3. In stage-2, p kj for each k = 1, 3 (left and right substrings) separately while keeping the other substrings in the same position. Similarly, each substrings p ij , but the mid-substrings (pi2), are divided into three parts, t = 1, 2 and 3, to create substrings, p ijt , in stage-3. The neighbor set of stage-3 is created by the permutations of substrings p ijt for each pair of i, j separately while fixing the other substrings in the same position creating (3 ! -1) neighbors for each pair.
Figure 4 shows a visual representation of scheme-1. It should be noted that mid-substrings (pi2, i = 0, 1, 3) are not divided into subparts and also, the permutations in each stage are obtained using only the three adjacent substrings for the sake of self-similarity structure of cantor sets.

A visual representation of neighbor generation using scheme-1 (left hand side) and scheme-2 (right hand side).
In the second scheme, dividing of the substrings is the same as the previous application but the permutation procedure differs in that permutations are only done between substrings pi2 and pij2 without changing the position and order of other substrings as explained in Figure 4 visually.
A pseudo code that shows the general structure of CB mechanism is presented in Figure 5 where f (x) is the minimization objective function.

Pseudo code of CB method.
The interested reader can access three numerical examples for the neighbor generation in stage-1, stage-2 and stage-3 in http ://bit . ly/2LMdSwW.
Several choices in the design of CB mechanism are analyzed to increase the effectiveness and the efficiency. These design issues are especially important to decrease the memory space and run-time required by the mechanism. Pre-experiments showed that the following design choices may affect the performance and run-time of the mechanism: choosing the best solution when advancing to the next stage, the number of stages (1, 2 or 3) that CB mechanism proceeds, reverse ordering of substrings, neighbor generation schemes (scheme-1 and scheme-2).
A pre-experimental study was made by implementing CB mechanism on several TSP and QAP instances in varying sizes considering all possible choices of the mentioned design issues and some other choices were abandoned as they gave unsatisfactory performance. The remaining design choices are chosen to be presented in this study, since they have already outperformed the other alternatives in terms of effectiveness and/or efficiency.
Design issue to deal with exponential increasing in the number of neighbors: It is obvious that the number of neighbors increases exponentially as the number of stages increases since each neighbor created in each stage is an input string to the next stage in the general structure of CB mechanism as illustrated in Figure 4. To avoid this exponential increment, the neighbor that gives the minimum objective function value in the previous stage is picked and the process of the next stage is applied to the selected neighbor instead of complete set of neighbors of just previous stage. For example, for an n = 100 problem, the algorithm gives very similar results 13 - 15 times faster when this design choice is implemented.
Design issue of all stages: CB mechanism can proceed until stage-1, stage-2 or stage-3 and therefore, the maximum number of the stages is another design issue. To improve the exploitation capability of CB, additional neighbors are generated using the reverse orders of the elements in the mid-substrings.
Straight ordering and reverse ordering: Once the solution is divided into substrings as explained in Section 3 and illustrated in Figure 3, each mid-substring pi2 and pij2 is used in the neighbor generation scheme-1 or scheme-2 in two different ways. The first way, called straight ordering, means that the mid-substrings are used directly. On the other hand, reverse ordering changes the sequence of the elements in the mid-substrings and use them in reverse order.
Variations of CB mechanism used in this study
Originally, it is possible to generate neighbors by using the general idea behind the method. However, there are many options that can make the algorithm too slow. Therefore, in consideration of the design choices, 3 alternative CB variations are presented: CB-1, CB-2 and CB-3. CB-1: Proceed until stage-2, straight ordering, scheme-2. CB-2: Proceed until stage-2, reverse ordering, scheme-1 CB-3: Proceed until stage-3, reverse ordering, scheme-1
Experimental study
In the computational tests, MATLAB 2017 was used for coding where the hardware was an Intel i5-7200U CPU @ 2,50GHz 2,70 GHz. The benchmark instances are taken from TSPLIB [17] and QAPLIB [5]. For the experiments, every mechanism was embedded into LS and SA algorithms separately and they were run 30 times starting from the same initial solution using these test instances.
In Table 1 CB-1, CB-2, and CB-3 are compared in terms of solution quality and the total number of neighbors generated until the termination condition of LS procedure is met while solving TSP instances. The same comparisons are given in Table 2 for solving QAP instances. SA results for number of generated neighbors are not reported here because the number of generated neighbors depends on the cooling schedule not the neighbor generation mechanism itself.
Percentage deviations from the best known solution (DBKS*) and number of neighbors generated (NNG*) by CB variations for TSP
Percentage deviations from the best known solution (DBKS*) and number of neighbors generated (NNG*) by CB variations for TSP
Percentage deviations from the best known solution (DBKS*) and number of neighbors generated (NNG*) by CB variations for QAP
For TSP, CB-2 and CB-3 generates significantly more neighbors than CB-1. However, CB-2 gives the best results among the mechanisms in terms of solution quality. Hence, it is thought that the number of neighbors generated by the mechanisms is a result of their design and performance does not get affected by it. This observation is supported by the QAP results that can be observed in Table 2. Even though CB-3 generates significantly more neighbors than CB-1 and CB-2, CB-1 gives the best performance.
CB-1, CB-2 and CB-3 are compared to classical swap and insertion mechanisms in terms of effectiveness and efficiency. In addition, since SA heuristic had to be tuned before actual runs, test runs were executed for the sake of parameter tuning.
Parameter tuning for SA
In this study, a static parameter set, which is determined by a factorial design is used for SA. Parameters of the geometric cooling schedule, which is one of the widely used schedules, and the levels of each parameter determined by pre-experiments are given as follows for both TSP and QAP: Cooling rate (α): 0.90, 0.95, 0.99 Initial temperature (T0): n, 5n, 50n, 100n
Ending temperature (T
f
): 0.1n, 0.01n, 0.001n
Equilibrium state (δ): n, 5n, 10n, 15n
Three benchmark instances (small, medium and large sized) of TSP and QAP are chosen for the experiments. Each possible parameter combination is tested 30 times. For TSP, the following set of parameters is determined:
Statistical tests
To provide statistical inferences from the comparison of the mechanisms, SPSS-24 was used as a statistical analyzer. Tables 3 and 4 show the descriptive statistics of percentage deviation from the best-known solutions for TSP and QAP, respectively.
Descriptive statistics of the mechanisms in terms of percentage deviation from the best-known solution for TSP
Descriptive statistics of the mechanisms in terms of percentage deviation from the best-known solution for TSP
Descriptive statistics of the mechanisms in terms of percentage deviation from the best-known solution for QAP
For TSP, the results given in Table 3 show that when LS is used, CB-2 and CB-3 mechanisms perform similarly well compared to the other mechanisms in terms of percentage deviation from the best-known solution. Although, CB-2 is slightly more robust than CB-3, it greatly outperforms the other mechanisms. When SA is used, CB-2 and CB-3 are again the best mechanisms by far, albeit CB-2 is slightly better than CB-3. CB-1 is not suitable for TSP at all, giving similar results with insertion and swap. For QAP, the results given in Table 4 show that when LS is used, CB-1 mechanism is the best compared to the others in terms of percentage deviation from the best-known solution. CB-1 is also more robust than other mechanisms since it has a lower standard deviation. Swap is the best mechanism when embedded into SA and CB-1 exhibits a similar performance with swap in terms of percentage deviation from the best-known solution. CB-2 is not suitable for QAP at all, giving similar results with insertion mechanism.
In addition, Friedman Test is applied to compare the mechanisms for TSP and QAP, separately, by using percentage deviations from the best-known solution data and the results are presented in Table 5. Friedman test is a ranking method based non-parametric statistical test that is used to compare matched groups. While interpreting the results, the mechanism that has the lowest ranking is considered the best while the mechanism that has the highest ranking is considered the worst as the resulting deviation is desired to be zero in the ideal case. For TSP, CB-2 embedded into LS and SA is the best. For QAP, CB-1 embedded into LS and swap embedded into SA are the best. These results support the interpretations observed from Tables 3 and 4.
Friedman Test using percentage of deviation from the best-known solution for TSP and QAP
In Tables 6 and 7, run-time (average time required until a local optimum is met) is compared on each instance for TSP and QAP, respectively. For each instance, swap is the fastest mechanism embedded into both LS and SA for solving TSP. Because swap is a simple mechanism, its computer time requirement is less than that of the other mechanisms. However, its simplicity fails to find high quality solutions as reported in Table 3. On the other hand, CB-3 is the slowest mechanism when LS is used while CB-2 is the slowest when SA is used to solve TSP instances. For QAP instances, swap and insertion perform in similar run-times when embedded into both LS and SA. These mechanisms are faster than CB mechanisms on QAP instances. CB-3 requires more computational time compared to the other mechanisms.
Run-time (in seconds) for TSP
Run-time (in seconds) for TSP
Finally, Figures 6 and 7 are presented to visualize the performance comparisons between CB mechanisms. Figure 6 illustrates the solution quality performances of CB-1, CB-2, and CB-3 using LS and SA heuristics for TSP instances while similar illustrations are given in Figure 7 for QAP instances. A curious observation regarding Figure 6 is that CB-2, which is the best mechanism for solving TSP, performs better embedded into SA for n < 150 and CB-2 performs better when embedded into LS for n > 150. A similar situation can be observed for CB-3 results as well.
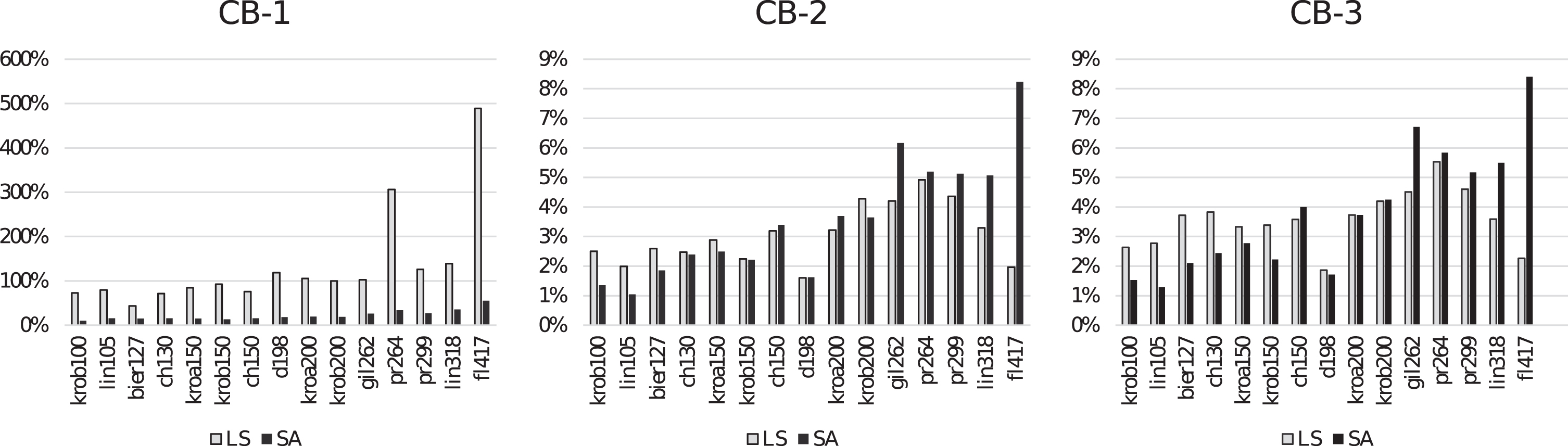
Comparison of CB-1, CB-2, CB-3 on TSP instances in terms of deviation from the best known solution.
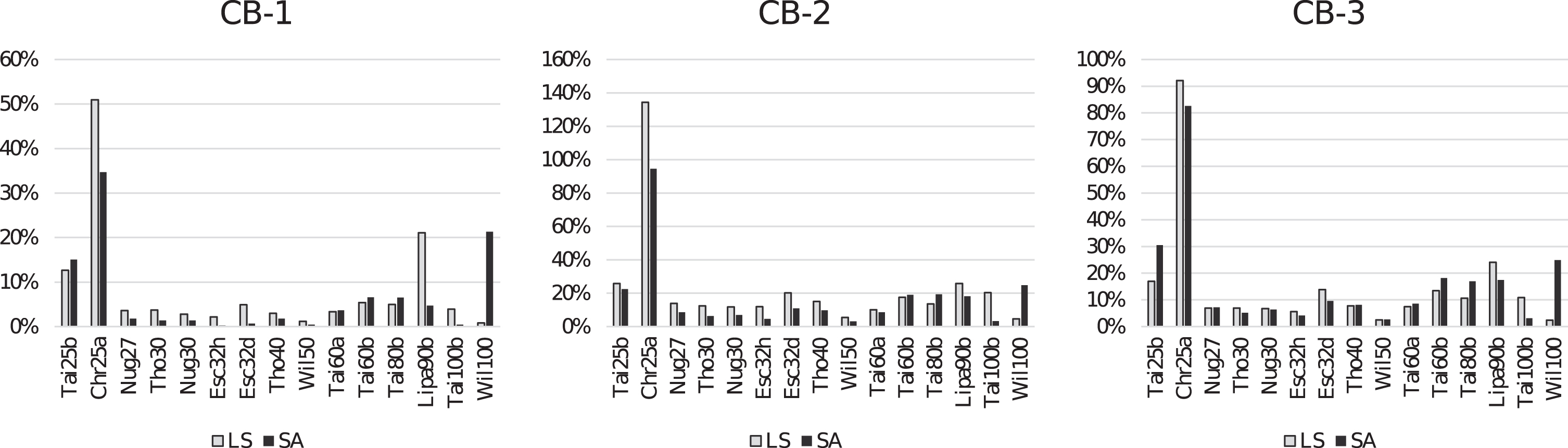
Comparison of CB-1, CB-2, CB-3 on QAP instances in terms of deviation from the best known solution.
In this study, a novel neighbor generation mechanism, called CB, to enhance the performance of single solution-based heuristics is described and improved. CB mechanism is inspired by the recursive algorithm that creates stochastic cantor sets which is one of the well-known fractal sets. Several issues in the design of CB mechanism are investigated for the purpose of finding a mechanism that performs well on TSP and QAP which have differentiating characteristics. Considering the design issues, three variations of CB mechanism are created: CB-1, CB-2 and CB-3. The variations of CB are compared with classical move operators, swap and insertion, on benchmark instances of TSP and QAP. The results present that among CB variations, CB-2 embedded into LS and SA to solve TSP outperforms swap and insertion mechanisms in terms of solution quality while CB-3 exhibits the next best performance after CB-2. For QAP, on the other hand, CB-1 embedded into LS is superior to both swap and insertion, however, the solution qualities generated by CB-1 and swap mechanisms are very close to each other. This proves that, for TSP, big jumps in the search space provided by CB-2 and CB-3 give better results while a more delicate approach with small jumps created by CB-1 is necessary for QAP. In other words, it is showed that different variations of CB mechanism are able to deal with different characteristics of TSP and QAP where the landscapes in TSP instances contain deep valleys and the landscapes in QAP instances have flat valleys. On the other hand, CB mechanism is always slower than swap and insertion mechanisms in terms of run-time, even though it requires a reasonable amount of run-time to solve moderate or larger sized instances.
The major contribution of the presented study is the introduction of a novel neighbor generation mechanism because the literature mainly consists of traditional swap and insertion mechanisms or their variations. Another important insight obtained from the experimental study is that CB-3 gives consistently good results when solving both TSP and QAP despite of their contrary characteristics in their landscapes. This is an encouraging result since there is not a common neighbor generation mechanism which performs well for both TSP and QAP.
As a future study, CB mechanism will be improved further in terms of run-time and as a more efficient generalized neighbor generation mechanism. It also will be applied to different benchmark or real-life combinatorial optimization problems to show its applicability and to enhance its usage in the operational research community.