
Abstract
Information extracted from L-fuzzy contexts is substantially improved by taking into account different points of view, which can roughly be represented by criteria. This work addresses the general study of L-fuzzy contexts were a set of criteria is introduced, analyzing situations in which their evolution over time is known. The relationship among criteria is also an important point in the study. In this sense, the treatment will vary depending on whether they are independent criteria or there exists dependency among them. Of special importance will be those elements that stand out for presenting a positive temporal evolution. Four algorithms are proposed in order to analyze the different situations. Finally, the applicability of the results is shown thought an example where the opinion of the clients of several hotels is analyzed taking into account both the type of traveler considered and the different aspects of the establishments on which a score is given.
Keywords
Introduction
Formal Concept Analysis [17, 22] studies the information given by a binary relation that represents a formal context (X, Y, R) with X and Y the objects and the attributes, and R ⊆ X × Y. This information is provided by means of the formal concepts which are pairs (A, B) with A ⊆ X and B ⊆ Y, verifying A* = B and B* = A, where (·) * is the derivation operator. Each formal concept represents a group of objects A that shares the attributes of B.
In [9, 10] an L-fuzzy context was determined as a tuple (L, X, Y, R), where L is a complete lattice, X and Y the sets of objects and attributes and R ∈ LX×Y a fuzzy relation defined among them. This is an extension of the formal context of Wille in which the relation among objects and attributes is not binary and belongs to a complete lattice L. The L-fuzzy concept analysis has been developed as a tool for knowledge extraction using L-fuzzy concepts ([4, 7]).
The relations among objects and attributes can be seen from different points of view called criteria. L-fuzzy C-contexts were defined in [13] to represent these situations.
So far there are no studies that have addressed the evolution over time of L-fuzzy contexts for which the relationship between objects and attributes depends on criteria. These criteria represent relevant points of view for the study. The possibility of introducing criteria allows to carry out a deeper analysis of the information stored in the L-context.
In this work L-fuzzy C-contexts that evolve in time are studied, using for this purpose different tools of L-fuzzy context sequences [1, 8].
To start, in Section 2 important results about aggregation operators and L-fuzzy concept analysis are recovered which will be useful in the further development of this work.
The rest of the paper is organized as follows: Section 3 presents new uses of L-fuzzy contexts associated with criteria. Two aggregation processes will be presented: Independent Criteria Aggregation Process (ICAP) for independent criteria and Dependent Criteria Aggregation Process (DCAP) for dependent ones.
In Section 4 the evolution of these contexts is analyzed using tools of L-fuzzy context sequences. General Study Process (GSP) and Evolution in Time Study Process (ETSP) are proposed.
Section 5 illustrates the results by means of a practical application. In the last section, conclusions and future work are detailed.
Preliminaries
This section recalls some useful aspects about the different aggregation operators that will be used along the paper depending on the nature of the aggregated data.
Agregation operators
The OWA operators were defined by Yager [23] as aggregation operators based on the ordered weighted averaging. Below is the definition of these operators.
In [6] OWA operators were used in the analysis of fuzzy contexts sequences in order to detect tendencies in the evolution in time of the contexts.
Later, WOWA operators were introduced in [20]. They merge characteristics of the OWA operators with others of the weighted means [14, 15]. They use two weighting vectors, w = (w1, w2, …, w n ) for the relevance of the values (operator OWA) and p = (p1, p2, …, p n ) for the relevance of the sources or experts.
In particular, if ∀i ∈ {1, …, n} w i = 1/n, then the corresponding WOWA is a weighted mean with the weights p. When p i = 1/n, ∀i ∈ {1, …, n}, an OWA with the weighting vector w is obtained.
WOWA operators have already been used in previous works [2, 3] to aggregate information in L-fuzzy contexts. In this work, the generalization of WOWA operators to Choquet integrals [16] will allow to aggregate values taking into account the existing relations among them.
In order to establish the definition of Choquet integral is necessary previously to recall the notion of fuzzy measure [19, 21] defined in
μ (∅) =0 μ (X) =1 B1 ⊆ B2 ⊆ X implies μ (B1) ≤ μ (B2)
The definition of Choquet integral was reformulated by Grabisch [18] as follows.
It is easy to see that weighted means, OWA and WOWA operators are special types of Choquet integrals [20].
Together with the aggregation operators, it is necessary to recall the principal elements of the L-fuzzy contexts and their sequences.
In order to obtain information from these L-fuzzy contexts, were defined in previous papers [9–12] the derivation following operators 1 and 2.
The set
Moreover, for A ∈ L X , (or B ∈ L Y ) the associated L-fuzzy concept can be determined applying twice the derivation operators. In the case of using a residuated implication, the associated L-fuzzy concept is (A12, A1) (or (B2, B21)).
Although the derivation operators can be defined through any fuzzy implication operator, with the aim of simplifying the calculations, only residuated implications defined on L = [0, 1] will be used in this work.
A first study of the L-fuzzy context sequences defined on L = [0, 1] was tackled in [8]. The main definitions that appear in that work are showed below.
In order to summarize the information stored in the L-fuzzy context sequence, the following relation R F was defined using an OWA operator.
In [1] a complete study of the L-fuzzy context sequences defined on a complete lattice L was performed using OWA operators.
Moreover, the use of WOWA operators allowed to carry out a proper treatment of the sequence improving the previously proposed one. In [2] the authors proposed an L-fuzzy relation R F pw to aggregate the information of the different fuzzy contexts.
In this way, all the contexts of the sequence are combined defining a single R F pw that summarizes the information of the sequence. The use of two weighting vectors permits to give greater importance to some elements considered more representative than others. For example, a vector p can be chosen to highlight the most recent contexts, and a vector w to give relevance to the largest values.
Finally, as an important point in the study of L-fuzzy context sequences, in [6] were studied temporal trends defining Trend and Persistent Formal contexts.
L-fuzzy C-contexts were defined in [13] as a tool to represent those situations where the relationship between objects and attributes can vary depending on the chosen point of view or criterion. These new contexts were introduced by means of the following definition.
Derivation operators are defined by means of a fuzzy implication operator I as is shown in the following definition.
Also, consider V ∈ LC×Y, V2 ∈ LC×X is given by
In [13] was proved that the L-fuzzy C-concepts are pairs
On the other hand, it can be proved that, taking the L-fuzzy concept
In the next sections, the problem will be developed from the point of view of the objects, being also possible to do a similar analysis for the attributes.
Starting from the relationship between objects and criteria, in order to extract information from the context, one can proceed following the Independent Criteria Aggregation Process (ICAP) (see Algorithm 1).
In this case, WOWA operators can be used since criteria are independent. Vector w is going to be used for observations and vector p for criteria, giving a greater value to those observations or criteria that are considered to be more relevant.
1: (L, X, Y, R, C) : L-fuzzy C-context.
2: U ∈ LC×X: starting L-fuzzy relation.
3: F pw : WOWA operator of dimension l = |C| associated with p and w .
1:
2: Obtain the L-fuzzy C-concept
Aggregate the rows of the L-fuzzy C-concept
The advantage of using WOWA operators F pw with two vector of weights, p for the criteria and w for the observations, is the possibility of establishing different nuances in the study.
Dependent criteria
The L-fuzzy C-concepts represent the relationship between objects and attributes from different points of view.
To complete the study from these L-fuzzy C-concepts, in the previous section criteria have been assumed to be independent. In the case of working with dependent criteria, better results could be obtained if those criteria with strongest dependencies among them were combined instead of being treated in isolation.
Following this idea, the use of Choquet integrals was proposed in [3] to aggregate the values of the L-fuzzy C-concept
For every z
k
, k ∈ {1, …, l}, represented by an L-fuzzy set
Then, for every 0 < α ≤ 1, the set
Fixed α ∈ (0, 1], and using these sets of α-criteria, a measure can be defined on the set C.
Dependencies among criteria can be represented by a graph
Thus, if for every i, j ≤ l one denotes by
As it is well known, the ij’th entry of the matrix
With the purpose of aggregating the information provided by the different criteria, it will be used the maximum level for which all the criteria are dependent among them, that is, the maximum value
The actions to be done in order to aggregate the criteria are described in the Dependent Criteria Aggregation Process (DCAP) (see Algorithm 2).
1: (L, X, Y, R, C) : L-fuzzy C-context.
21: U ∈ LC×X: starting L-fuzzy relation.
1: Obtain the L-fuzzy C-concept
2:
3: Obtain
4:
5:
6:
7: Calculate
8:
9:
10:
11: Define the matrix A α .
12: Calculate
13:
14: Obtain
15:
16: Calculate the set
17:
18: Define the
19: Use the Choquet integral associated with
The next step consists in dealing with relations between objects and attributes associated with criteria that may vary with the passage of time. In order to model these situations contexts sequences will be used, which are defined as follows.
These L-fuzzy context sequences are special because they are associated with a set of criteria C that represent points of interest in the study. However, all the developments defined in [8] can be used.
The study of the evolution of the relationship between objects X and attributes Y taking into account the criteria C can be addressed in two different ways. First, one can build an aggregated context for the L-fuzzy C-context sequence. Second, keeping the sequence to analyze different moments in time. In the last case, for every L-fuzzy C-context (L, X, Y, R i , C) , i ∈ {1, …, n} of the sequence, it is possible to obtain the L-fuzzy C-concepts that represent the relationship between objects and attributes in a fixed moment, taking into account the different criteria.
In general, the moment from which the values are aggregated will be chosen looking for a simplification of the process, at the cost of losing interesting nuances such as the evolution of the relationship over time or information provided by different criteria. The following sections show how to do it.
Aggregated L-fuzzy context associated with criteria
The information underlying in an L-fuzzy context sequence (L, X, Y, R i ) , i ∈ {1, …, n}, may depend on which is the valuation of the objects X taking into account the different criteria C. Representing this valuation by an L-fuzzy relation U ∈ LC×X, the relationship among objects and attributes can be analyzed from different points of view by means of the L-fuzzy C-concepts of the L-fuzzy C-context sequence (L, X, Y, R i , C) , i ∈ {1, …, n}.
As a first approximation, a general idea can be obtained aggregating the L-fuzzy C-contexts of the sequence, using techniques of L-fuzzy contexts sequences. After that, it will be calculated the L-fuzzy C-concept associated with U in the new context, from which one can extract information.
The entire process is collected in the General Study Process (GSP) (see Algorithm 3).
1: (L, X, Y, R i , C) , i = {1, …, n}: L-fuzzy C-context sequence.
2: U ∈ LC×X: starting L-fuzzy relation
3: F
pw
: WOWA operator of dimension n associated with p and w such that ∀i = 1, …, n
1: Aggregate the L-fuzzy context sequence using an WOWA aggregation operator F
pw
:
2: Obtain the L-fuzzy C-concept
3:
4: Choose a Choquet integral as aggregation operator aggr
5:
6: Choose a WOWA operator as aggregation operator aggr
7:
8: Aggregate the values of the L-fuzzy C-concept associated with each criteria with the aggregation operator (steps 3-7) obtaining the pair
Evolution in time of the L-fuzzy context associated with criteria
Aggregating the different L-fuzzy contexts of the sequence, relevant information relative to the different moments of the study can be lost. For this reason, a further complementary study is needed in order to maintain the information associated with each value of the sequence until the end of the process.
In this second step, the evolution of the relationship among objects and attributes will be analyzed from the point of view of each criterion. Specifically, the analysis will focus on those objects and attributes whose membership degrees grow in the L-fuzzy concepts associated with a certain criterion.
Starting from the L-fuzzy context sequence associated with criteria and the L-fuzzy relation U ∈ LC×X representing the relationship between objects X and different criteria C, the actions to be performed are described in the Evolution in Time Study Process (ETSP) (see Algorithm 4).
1: (L, X, Y, R i , C) , i = {1, …, n}: L-fuzzy C-context sequence.
2: U ∈ LC×X: starting L-fuzzy relation.
1:
2: Obtain the L-fuzzy C-concepts
3:
4: Define the L-fuzzy C-concepts
5:
6:
Note that the pairs
The following definition will be helpful in the study of the different criteria.
In order to obtain a general overview of the L-fuzzy concepts
As was explained at the beginning of the paper, the study has been carried out from the point of view of the objects but, taking as a starting point a set of attributes V ∈ LC×Y, capitals attributes can be also defined.
These capitals objects and attributes are the prominent elements of the study. On the other hand, the fact that an object or attribute is capital does not imply that it is so for all criteria.
Practical application
With the aim of illustrating the applicability of the developed results, this section analyzes the degree of satisfaction of the guests who have stayed in several hotels located in the center of the city of Munich, as well as the evolution of their opinions over time.
The data have been obtained from the well-known websites Booking and Trivago, and normalized to the interval [0, 1].
The information is stored in an L-fuzzy context sequence (L, X, Y, R i , C), i ∈ {1, …, 4}, that represents the average score given to the hotels (X) by each type of guest (Y) throughout one year (from June 2017 to May 2018). This sequence is represented in Table 1.
L-fuzzy context sequence
L-fuzzy context sequence
The considered sets of objects and attributes are the following ones:
The objective is to find those hotels that have obtained a better score and also to analyze which of them have maintained or increased their rating over time. To do this, a set C of criteria will taken into account. In this case, the considered criteria are the different features that have been subject to assessment in the satisfaction survey:
Criteria will initially be supposed to be independent, to further consider their dependence on a later stage.
First, a relation R F pw is obtained which summarizes the information in gathered in the sequence using WOWA operators.
The values are aggregated using the weighting vector p = (0.1, 0.2, 0.3, 0.4), in order to make the most recent opinions more relevant, and the vector w = (0.4, 0.3, 0.2, 0.1) to give greater weight to the highest ratings. The resulting relation is given in Table 2.
Relation that summarizes the sequence
Then, considering the relation U ∈ LC×X, which represents the average score obtained by each hotel in the different criteria or features that have been assessed in the query (see Table 3), it is possible to obtain the associated L-fuzzy C-concept
Average score of the hotels in each feature
L-fuzzy C-concept
From this L-fuzzy C-concept Hotels Uhland (x1), Brack (x3) and Bavaria Boutique (x6) have obtained good ratings in all the features from families (y1) and solo travelers (y3). Groups of friends (y5) have also given high scores to these three hotels in rooms (z2) and, to a lesser extent, in cleanliness (z4).
In addition, if the criteria are supposed to be independent among them, resumed information can be obtained aggregating the rows of the L-fuzzy C-concept corresponding to the different criteria through a WOWA operator. In this case, the used weighting vectors are p = (0.2, 0.2, 0.2, 0.2, 0.2), in order to consider all the criteria as equally relevant, and
In this case, the result of aggregating the observations in the L-fuzzy C-concept
This result can be interpreted to mean that the hotels Uhland (x1), Brack (x3) and Bavaria Boutique (x6) have received the best scores, particularly from solo travelers (y3). Families (y1) and, to a lesser extent, business travelers (y4) and groups of friends (y5) have also given good ratings to these hotels.
More accurate information could be obtained considering dependencies among criteria. In this case, one can apply the Dependent Criteria Aggregation Process (DCAP) described in Algorithm 2 starting from the relation U ∈ LX×Y that collects the average ratings obtained for each hotel in the different analyzed features.
First of all, the derived L-fuzzy concept
The maximum value of α that provides a connected graph is
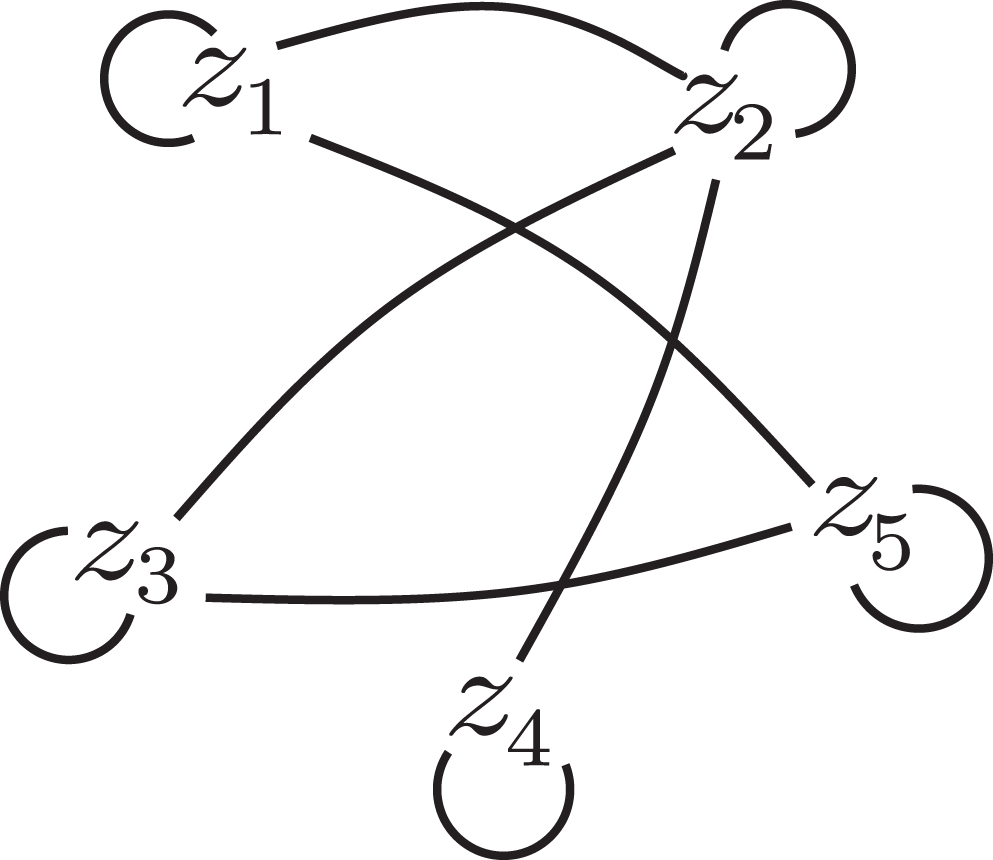
Graph obtained from the set of criteria when α = 1.
For this value
Values of the measure
L-fuzzy C-concepts
Pairs associated with the trimesters
Then, taking the measure
From the pair
As has been explained before, another option is to work with each of the context in the sequence and, starting from U ∈ LC×X, obtain similar information for each of trimester that were are analyzing. The calculated L-fuzzy C-concepts are showed in Table 6.
Aggregating the values corresponding to the different criteria in each of the L-fuzzy C-concepts, taking into account the dependencies among them, the pairs showed in Table 7 are obtained associated with the considered four trimesters.
From these pairs can be concluded that: In the period from June to August 2017 Brack Hotel (x3) was the best rated and the highest scores came from solo travelers (y3). From September to November again Brack Hotel, but also Uhland (x1) and Bavaria Boutique (x6) received the highest scores, particularly by groups of friends (y5). In the next trimester, were Uhland (x1) and Bavaria Boutique (x6) the best rated hotels and the costumers who gave the highest scores were solo travelers (y3). From March to May 2018 again Uhland (x1), Bavaria Boutique (x6) and Brack (x3) were the most valued hotels but, in that occasion, best ratings were given by families (y1).
It is also possible to analyze which hotels have seen improved their assessments concerning with the different considered features. The capital objects for each criterion are in this situation the following ones: Considering the location (z1) and services (z3), the capital hotels have been Uhland (x1), Schweiz (x4) and Bavaria Boutique (x6). Those hotels that have improved their ratings corresponding to rooms (z2) and cleanliness (z4) are Trip (x2), Schweiz (x4) and Bavaria Boutique (x6). Schweiz Hotel (x4) is the only one that have kept its rating related to value per price (z5).
Finally, calculating the capital objects, can be concluded that Uhland (x1) and Bavaria Boutique (x6) hotels have improved their average rating and, in the case of Schweiz Hotel (x4), this score has remained constant throughout the year.
This work has focused on different and complementary ways of studying L-fuzzy contexts associated with criteria where the evolution in time is known. In general, the selection of the most appropriate one will depend on the nature of the criteria and the interest of the study. It will be studied in each practical application.
Specifically, two different studies have been proposed. The first one consists on build an aggregated context looking for a simplification of the process. The second one keeps the sequence obtaining interesting nuances such as the evolution of the relationship over time or the differences between the criteria.
This extension of the L-fuzzy Concept Analysis increases its applicability to real situations as has been illustrated by the practical case proposed in section 5.
In a future work, sets of criteria will be analyzed for which some of their elements are dependent on each other and others are not. Another interesting issue to be addressed deals with working with different measures, especially with those measures that are additive, as well as analyzing the possible influence that the change of the measure may have on the obtained results.
Footnotes
Acknowledgments
This paper is partially supported by the Research Group “Intelligent Systems and Energy (SI+E)” of the Basque Government, under Grant IT1256-19 and by the Research Group “Artificial Intelligence and Approximate Reasoning” of the Public University of Navarre under Grant TIN2016-77356-P (MINECO, AEI/FEDER, UE).