
Abstract
Customer-based practices enable benefits to organizations in a contentious business. Offering individualized proposals increase customer loyalty to be able to afloat. Understanding customers is a vital difficulty to perform personalized recommendations. As a demographic feature, gender information essentially cannot be captured by human tracking technologies. Hence, several procedures are improved to predict undiscovered gender information. In the research, the followed indoor paths in a shopping mall are used to predict customer genders using fuzzy c-medoids, one of the soft clustering techniques. A Levenshtein-based fuzzy classification methodology is proposed the followed paths as string data. Although some studies focused on gender prediction, no research has centered on path-oriented. The novelty of the investigation is to analyze customer path data for the gender classes.
Keywords
Introduction
Smartphones possess an essential role in people’s regular days since their usage has grown after the millennium. Smartphones are frequently used in both academic and industrial data collection projects in an unobtrusive way [1]. Smart devices with various technologies communicate with smartphones through sensors. Whereas it provides spatiotemporal data collection, demographic information is not involved in the captured data. Because demographic information is meaningful in personalized systems, researchers have gradually focused on gender prediction in recent years. The demographic information such as age, location, gender, education level, and marital status are employed to prepare recommendation systems [2], prediction of future [3] and purchasing choices [4]. The gender information holds a vital role in decision-making, especially in the marketing domain [5–7].
Although developed technology with industry 4.0 provides to collect a vast amount of data, many sensor data do not contain gender information. Hence, gender prediction studies have gained importance [8]. Sensors integrated into smart devices capture spatiotemporal data from customers’smartphone as long as they permit the communication between devices. The event logs created from sensor data provide to find customers’paths, backgrounds, and interests [9]. For instance, female shoppers may visit more gym stores than male shoppers. Male consumers may spend higher time in entertainment stores than female consumers. Gender prediction is one of the most challenging issues thanks to highly dynamic human behaviors [10–12]. In previous studies, researchers used various approaches such as face [13], speech [14], handwriting [15].
Understanding customer needs from their indoor paths is a fascinating research field [16–18]. Nowadays, studies on path analysis for various purposes have a risen reputation [19, 20]. Dogan et al. [21] examined male and female shoppers’paths to explain changes in behaviors. The investigation shows male and female consumers have different actions concerning their paths in the shopping mall. Some researches adopted descriptive statistics to represent buyer behaviors [22], yet understanding user behaviors needs an overall insight into customer pathways [1, 24]. Henceforth, process mining methods are applied to create and evaluate user paths [1, 26]. The aim of process mining includes not only discovering customer paths for an overall insight but also producing understandable solutions.
In this study, data collected from one of the biggest shopping malls are collected. The data are collected through a Beacon network built for location tracking and other services by a Turkish start-up Blesh. The company has a Beacon network involving more than 100.000 beacons in over 50 cities in Turkey. Because of the company’s business model and related regulations, only a unique ID is collected from each user. The Beacons sends low energy Bluetooth based signals, any nearby mobile device can receive this signal, and if an appropriate application is installed on the device, it sends the Bluetooth signal to the servers. The server receiving the signal id and the id of the mobile device can process the data and send any messages to the mobile device. The decision process that runs on the server can provide better results as more information is known about the owner of the mobile device. Any demographics or interests of the users help the algorithms to give better campaigns or actions. However, the system can only have an ID representing each user. At this point, the research question of the paper is defined as the prediction of the gender from the location data of the users. The focal problem differs from classical classification problems in the fact that the input data is more complex, and it is not in a tabular form. To overcome this challenge, a novel approach Levenshtein distance-based Fuzzy c-Medoids Clustering (L-FCMd) method was proposed. One of the challenges about the problem is numerous stores exist in the shopping mall, and using them in the model with their names or identifiers causes the loss of some patters. The problem is simplified by converting the stores to store types such as Clothing, Catering, and entertainment. Because of this, visitor paths are represented by order of the store types. Levenshtein distance, a string metric for measuring the difference between two sequences, was used to obtain the distances between the paths. The distance values are then embedded into Fuzzy c-Medoids clustering, which can define clusters of paths by using fuzzy principles and distances between the paths.
This study is structured as follows. Section 2 presents related works related to both gender classification and user paths. Furthermore, studies about fuzzy-based k-nearest neighbor are given. The section reveals the literature gap. Section 3 introduces the developed algorithm, Levenshtein distance-based Fuzzy c-Medoids Clustering. Section 4 represents the case study. Finally, the consequences of the proposed algorithm and limitations are discussed in Section 5.
Related works
The literature provides various studies on the behavior analysis of individuals. Yoshimura et al. [22] used museum visitors’data to detect the frequent paths being using in Louvre Museum using Bluetooth devices. In another branch of studies, De Looni et al. [27] used event log data to diagnose the process bottlenecks and optimize the hospital processes. Frisby et al. [28] focused on activities in the emergency room of a hospital;instead of the previous study, this study uses Bluetooth signals to define and optimize the operations. Arrayo et al. [29] concentrated on suspicious behaviors in a shopping mall. The researchers used the video-surveillance system and video processing techniques to detect suspicious events. Popa et al. [30] provided a study on shopping behaviors by using trajectories and shopping-related activities. Wu et al. [31] investigated on in-store events of the customers to provide a customer flow analysis within a store. In another study, Yim et al. [32] used the local area network system to detect customer location and estimate the next visiting location of customers. Oosterlinck et al. [33] also focused on human behavior in a shopping mall and showed the efficiency of using Bluetooth devices for human tracking.
As a member of data analysis methods, classification groups data samples into the predefined classes. A classification algorithm proposes to assign data points into the existing classes concerning the similarities.
Path studies with study purposes
Path studies with study purposes
Gender classification is one of the famous application domains in classification research. Several ways adopted to predict gender information in previous studies such as face [51, 52], speech [14], handwriting [15, 54] and video-based gait [55, 56]. On the other side, smartphones are a new tool to collect human data that can be used to predict gender. Choi et al. [57] investigate mobile text data for users’gender prediction. Current gender classification techniques using smartphones are mainly implemented in two forms: visual and audio. Danisman et al. [13] proposed a fuzzy-based inference scheme that utilizes some facial characteristics such as mustache and inner face. Agneessens et al. [58] gather audio signals from mobile phones and represent the gender of speakers.
Researches have various research goals in user path analysis such as path-based prediction, path-based recommendation, and mining frequent patterns. Table 1 presents a summary of the literature review. Naserian et al. [34] predicted individualized positions, which consider users’trip type. They introduced a new pattern discovery procedure from spatial-temporal routes to accomplish this aim. from spatial-temporal trajectories of users. User position data show individual interests and visit purposes. Salkin and Oztaysi [38] presents a new retailer segmentation strategy considering multi-criteria decision-making integrated with soft clustering. Shaw and Gopalan [46] developed a novel algorithm that cut the path duration into groups and later employs the k-means clustering method. Their study aims to reveal the frequent paths of moving objects using the clustering method and sequential pattern mining.
Dogan et al. [21] mention that no research predicts gender information using customer paths. Previous researches about gender prediction are not related to customer paths, and researches focus on customer paths have not predicted gender information. Dogan and Oztaysi [7] filled the gap in their recent study. They developed a Levenshtein-based fuzzy kNN method. In this study, a similar algorithm is adopted with different clustering method, fuzzy c-medoids algorithm.
This paper proposes a novel technique to predict the gender of customers in a shopping mall by combining Levenshtein distance and fuzzy c-Medoids. Figure 1 depicts the general view of the proposed technique.
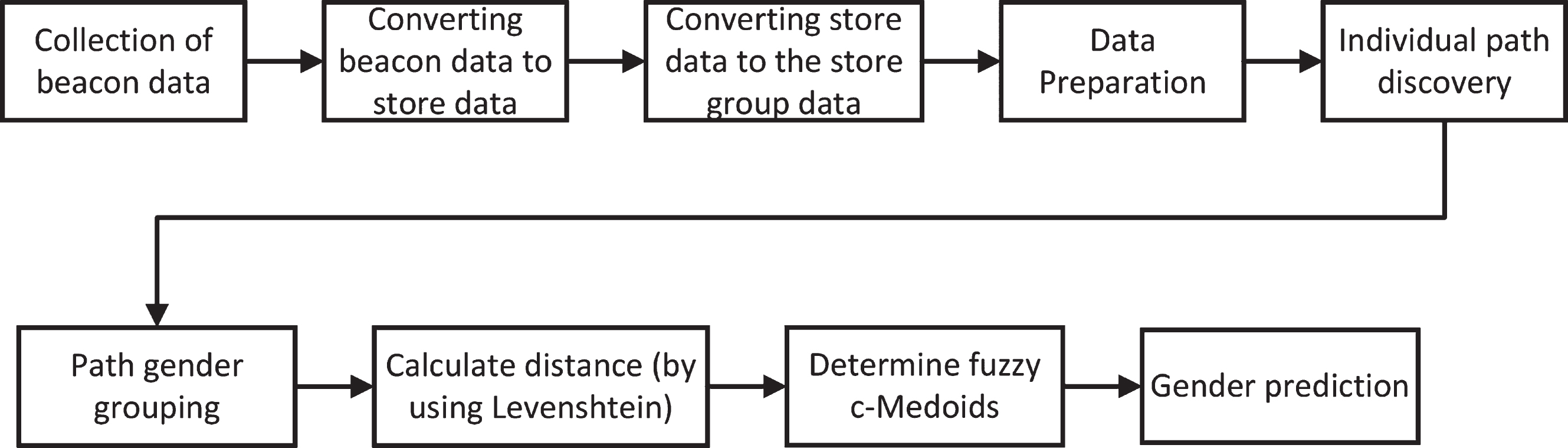
Flowchart of the proposed method for gender prediction from paths.
The introduced technique commences with data collection from beacon devices through users’mobile phones. The data is transformed to store group information. Various data preprocessing steps are implemented to prepare for analysis. Then, the individual indoor paths are discovered for each customer. The paths are classified into gender patterns. Levenshtein distance computes the distances between a gender-unknown path and all gender-known paths. Finally, fuzzy c-Medoids manages to predict the gender of customers.
Levenshtein distance is a special kind of sequential alignment technique. It can compute the distance between two string variables such as customer paths. Traditional similarity methods based on calculating numerical results are not applicable in string-based data [59]. Levenshtein distance is one of the well-known algorithms that can cover variations among string data [60]. In this algorithm, the distances are computed with three kinds of transformations: substitution, deletion, and insertion [61].
The first and second customer paths are shown by f and s, respectively. The transformations are executed to the single part of f and s. The first element in the string array is adjusted zero to calculate the distance. Hence, the similarity comparison matrix comprises of l f + 1 rows and l s + 1 columns.
f = f (0) , f (1) , f (2) , …, f (l f )
s = s (0) , s (1) , s (2) , …, s (l s )
where l f and l s refer to the first and second customer path lengths. f (i) and s (j) give ith element of the first path and jth element of the second path, respectively. The Levenshtein distance, shown by Lev (f, s), presents the distance between the f (i) and s (j), and can be determined as Equation 1.
where Lev (i - 1, j) +1 is deletion, Lev (i, j - 1) +1 is insertion and Lev (i - 1, j - 1) +1 substitution operations.
Fuzzy clustering allows an individual data element to be partially classified into more than one cluster. In crisp clustering, each individual is declared as a member of only one cluster. When the number of clusters is set to K, the algorithm provides a set of variables mi1, mi2, . . . , m ik which represent the probability that data element i is classified into cluster k. In classical crisp clustering algorithms, only one of these values will be one and the rest will be zero since they assign a data element into only one cluster. In fuzzy clustering, each data element has membership values spread to all clusters. The m ik can be between zero and one, with the condition that the sum of m ik is one. The advantage of fuzzy clustering is the fact that it does not force data objects into a specific cluster and thus it can provide much more information to be interpreted.
The fuzzy c-medoids algorithm is proposed by Krishnapuram [62] as a modified version of the fuzzy c-means algorithm. The fuzzy c-means algorithm is a popular clustering technique, but it can be affected by outlier data. Thus, Krishnapuram modified the original algorithm and replaces the means with the medoids [62]. The steps of fuzzy c-medoids algorithm is given as follows:
Step 1: Set the number of clusters (c)
Step 2: Randomly pick initial set of medoids V = v1, v2, v3, . . . , v c from X c , where X = {x i , |i = 1, . . . , n} is the set of n objects. Set iter = 0.
Step 3: For each cluster and data object compute u ik values using Equation 2
Step 4: Store the medoid values (V old ).
Step 5: Calculate the new medoids (V) values by using Equation 3.
The Levenshtein distance-based classification method is adopted from D’Urso and Massari [59]. Let X = (x1, x2, …, x N ) be the dataset to be clustered in this research ordered sequences and V = (v1, v2, …, v N ) is a subset of X with cardinality C. Levenshtein distance-based fuzzy C-medoids clustering is formalized like in Equation 4.
where u k (x i ) is the membership value of data x in fuzzy cluster c k . The fuzzifier m must be greater than 1. The clusters are turned into the crisp format when m equals to 1. Levenshtein distance between data point x i and cluster center v k is represented by Lev (x i , v k ).
The optimal solution is obtained by minimizing Equation [63].
Figure 2 represents the proposed L-FCMd algorithm for string data. It can determine the optimum number of clusters without apriori knowledge by calculating Xie-Beni Index (XBI), which is a performance indicator of a fuzzy clustering method.

The integrated L-FCMd algorithm.
User’s gender prediction from smart devices is a difficulty which needs a vast amount of location, time, and text data [27]. iBeacon devices, a Bluetooth-based technology, is established to collect customer data. Four hundred eighty-two (482) gender-known indoor paths, which are 96 male and 385 female, and 1124 gender-unknown paths are collected. Store groups, instead of stores, are considered to enhance the understandability of the customer paths. Every store in the shopping mall is combined according to the most dominant product or service to decrease the number of considered locations. Figure 3 shows the flowchart of the proposed system.
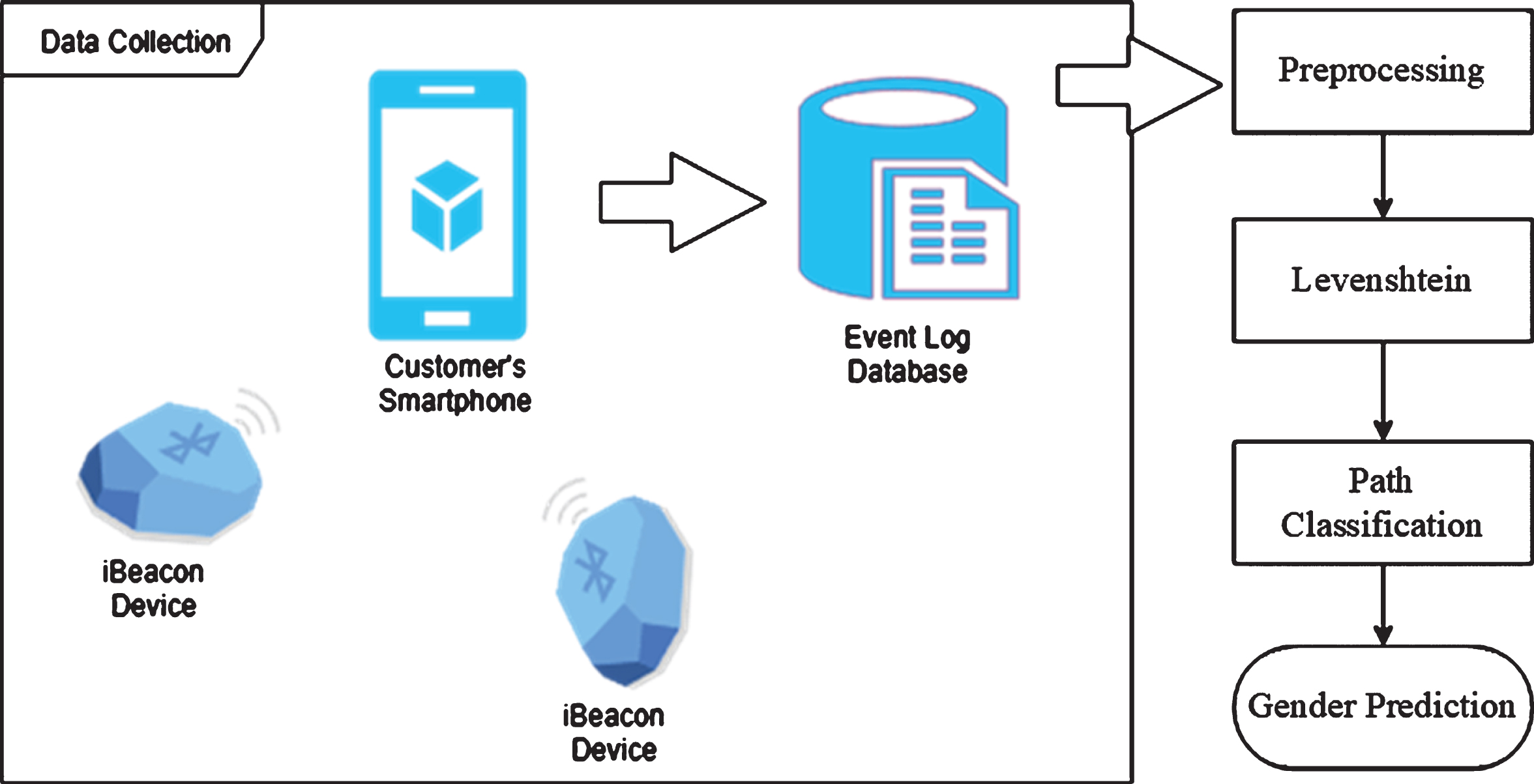
An overview to gender prediction methodology.
In the data preparation step, because the shopping mall opens between 10 am and 10 pm, paths out of this period are ignored. When the time gap between two visits for the same shopper is greater than ninety minutes, it is assumed as a different visit. Minimum visit duration is adjusted to 1 minute to ignore walking people data. Since beacons send signals every three seconds, customers can be seen in every location during their visit. One-location visits are ignored to decrease classification accuracy. Two-hundred ninety-three (293) stores in the shopping mall are grouped into store groups with respect to their dominant product or services. Eleven store groups are obtained, which are alphabetically Accessory (A), Catering (C), Clothing (D), Common area (E), Electronics (F), Entertainment (G), Entrance (H), Home (I), Mother&Baby (J), Personal Care (K), Supermarket (L). The path lengths have a range from 2 to 18 locations. Visits between 2 and 10 locations constitute 99.07%of all customer paths. The most visited store groups are C and D. Table 2 gives an example of customer paths. Each letter indicates a consecutive visit for a specific location. For example, customer C3 visits three different places;first Clothing (D), then Personal Care (K) and finally, Catering (C).
A sample of customer paths
10-fold cross-validation results
Comparison of two methods
A sample of L-FCMd results
In predictive models, some methods, such as cross-validation, are developed to progress the correctness. 10-fold cross-validation is applied to the training dataset to eliminate some obstacles such as underfitting and overfitting [64]. Eight hundred ninety-three (893) customer paths, including 189 male, 704 female paths, are investigated. The introduced method is returned ten times. The training dataset is interchanged in each run, and other known elements are predicted. Table 3 presents the 10-fold cross-validation results for Levenshtein distance-based fuzzy c-medoids clustering method. Then, the average accuracy of the introduced method is calculated. The accuracy between 59%and 70%is acceptable to validate the robustness of a classification problem [53]. In the study, it calculated 87.62%. It indicates every roughly nine out of ten shopper paths are ideally classified.
k-medoids is a clustering method based on the centroid model. The centroid must be a real data point, which described the medoids. Therefore calculation of the means is not needed at each step. Additionally, k-medoids is more beneficial for the achievement time, not sensitive to noise points and outliers. k-medoids algorithm starts with randomly selecting a sample from the dataset to determine as medoid k. Then, it computes all the distances between each data point and medoid k. The nearest medoid is chosen to assign the selected data point. The medoids for each cluster are re-defined by only considering assigned cluster elements. The distance calculation step is repeated with new medoids. The loop continues until a predetermined number of iteration or encountered with no changes in medoids between subsequent iterations.
The fuzzy c-medoids upgrades accuracy obtained by the crisp k-medoids method in most classification problems [65]. In the study, the accuracy results are compared to verify the improved method and crisp method. Table 4 gives the empirical outcomes of the training dataset for both methods. fuzzy c-medoids outperforms k-medoids, as expected, by producing more reliable performance.
Results
Because the improved L-FCMd approach predicts better gender information, it is applied to the paths for the gender-unknown customer. Table 5 presents a small part of the obtained results for one iteration given in Table 2. d m and d f indicate the minimum Levenshtein distance to male and female clusters, respectively. u m (x) and u f (x) present the membership values of the path belonging to the male and female clusters, respectively. Path Classification shows the predicted class. For instance, the path HD requires five Levenshtein operations to be the same with the male cluster medoid, DNCLH, and two Levenshtein operations for the female class medoid, DFD. The number of Levenshtein operation defines the similarity. The membership values of the classes are determined by Equation 5.
225 male, 623 female paths are classified by the developed L-FCMd algorithm, and 45 customer paths are not classified because they have equal membership values, shown with u m (x) and u f (x). Some extra data processing steps are required to get the gender information. Because one consumer can visit the shopping mall more than once, the path classification is turned into gender prediction (Figure 4). For example, customer 34612045 acts as a male in her visit 4 and visit 12, and as a woman in the other five visits. Hence, it is decided customer 34612045 is female. At the end of the study, 494 gender-unknown customers are classified as 121 male and 373 female shoppers using path prediction.
Gender prediction from classified path.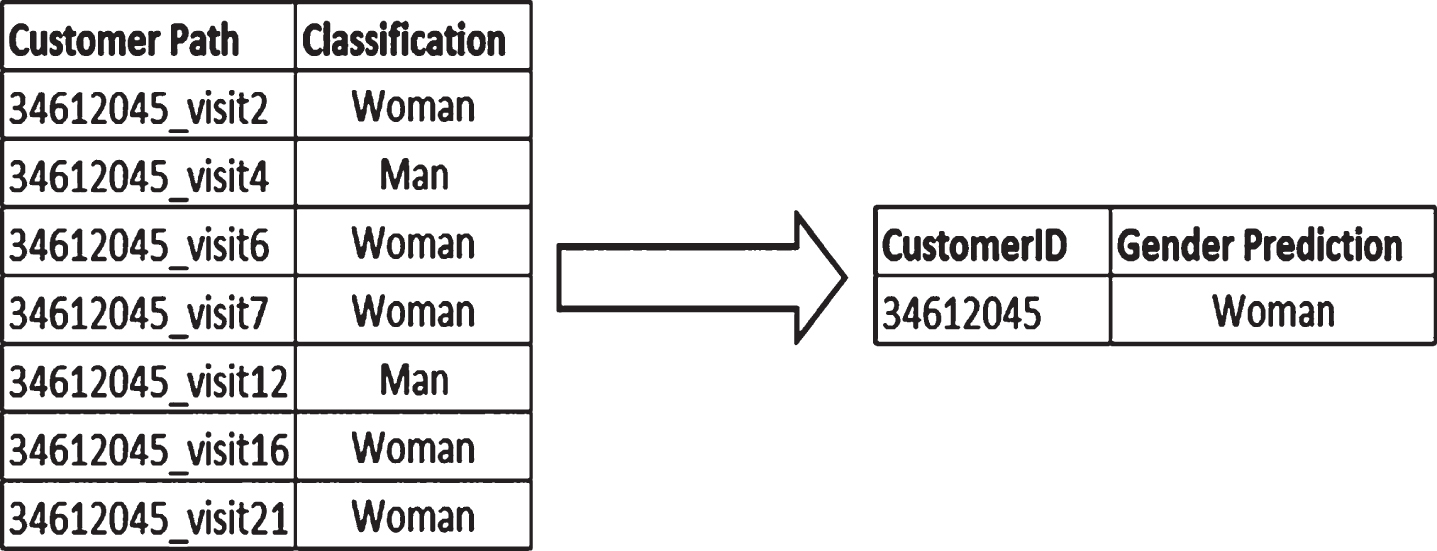
Gender information has great significance for companies, especially in the marketing domain, to improve user-oriented systems such as recommendations, discounts and campaings. Nevertheless, data collected by sensors do not involve gender data. There are some ways to predict customers’gender, such as handwriting, voice, and facial. However, none of them is suitable for sensor data. Shoppers’gender prediction using the followed indoor paths is an exciting field. In this research, users’gender is predicted from the paths, which classified using fuzzy clustering. The developed Levenshtein distance based Fuzzy c-Medoids (L-FCMd) Clustering algorithm is trained with the gender-known path. Then, it is tested and compared with the crisp k-medoids clustering method. It is confirmed that L-FCMd produces a more powerful classification performance which is measured by accuracy as 84.16%. Later, L-FCMd is applied to the gender-unknown paths to predict genders. The proposed method L-FCMd predicts 225 male and 623 female paths. Since shoppers can visit the shopping mall more than one time, the classified paths are used to obtain genders. Consequently, 121 male and 373 female paths are uncovered among gender-unknown paths. Because 45 user paths have an equal membership value to male and female clusters, they cannot be classified. Some other clustering techniques can be modified to decrease information missing by attempting to minimize the equal membership values during path classification. The study has a limitation. only 1-location paths are ignored since they may cause low accuracy. Besides, disregarding 2-location customer paths may improve the found classification efficiency.
Acknowledgment
This work was supported by Research Fund of the Istanbul Technical University. Project Number: MGA-2019-41949