
Abstract
Since information science and communication technologies had improved significantly, data volumes had expanded. As a result of that situation, advanced pre-processing and analysis of collected data became a crucial topic for extracting meaningful patterns hidden in the data. Therefore, traditional machine learning algorithms generally fail to gather satisfactory results when analyzing complex data. The main reason of this situation is the difficulty of capturing multiple characteristics of the high dimensional data. Within this scope, ensemble learning enables the integration of diversified single models to produce weak predictive results. The final combination is generally achieved by various voting schemes. On the other hand, if a large amount of single models are utilized, voting mechanism cannot be able to combine these results. At this point, Deep Learning (DL) provides the combination of the ensemble results in a considerable time. Apart from previous studies, we determine various predictive models in order to forecast the outcome of two different case studies. Consequently, data cleaning and feature selection are conducted in advance and three predictive models are defined to be combined. DL based integration is applied substituted for voting mechanism. The weak predictive results are fused based on Recurrent Neural Network (RNN) and Long Short Term Memory (LSTM) using different parameters and datasets and best predictors are extracted. After that, different experimental combinations are evaluated for gathering better prediction results. For comparison, grouped individual results (clusters) with proper parameters are compared with DL based ensemble results.
Introduction
The advancements in processing and storage of massive data enable rapid computation and analysis of collected data. This situation provides the extraction of knowledge considering relations between variables and detection of patterns. Especially for the prediction and classification problems, learning method’s performance relies on the structure of the dataset. With this respect, understanding the relationships between variables and their possible impact on prediction and classification problems are crucial. For this reason, analysis of the complex data requires more computational effort and sophisticated algorithms.
Forecasting algorithms highly depend on the dimension of the data to be evaluated. Research on this topic has been attracted for decades and considerable amount of approaches are aroused. Although regression and econometric models are widely applied, machine learning algorithms including neural networks (NN) and Support Vector Machines (SVM) are began to use to search dependencies between explanatory variables considering non linearity, time varying complexity and volatility [1, 2]. On the other hand, these methods have strong assumptions that are needed to be satisfied before the analysis and successive results cannot be generalized because of these assumptions. Additionally, single models generally remain incapable when presenting patterns in multi-dimensional data, multi-step based data and time varying data. Therefore, machine learning methods are adapted to a hybrid learning method named as Ensemble Learning (EL) which considers more than one method with basic classifiers and overall results are gathered using voting approaches. The main goal of this type of learning is to acquire better results by examining the output of multiple methods using group decision making methods. The reason for conducting EL is the intention of minimizing estimation error (Bias and Variance) using multiple methods’ results to gather strong learning algorithms [3]. According to [4], EL methods utilize multiple algorithms to generate weak predictive results using diversified combination of original dataset (named as sampling) and base classifiers (NNs, decision trees, random forests etc). In addition to that, voting schemes are conducted in order to integrate the final result of each algorithm. In other words, ideal predictive approaches can be accessed from EL by evaluating diversified sampling methods and approaches. From this point of view, it is expected that the adaptation of collective learning will reach better predictions than other single methods found.
Considering proper data analysis, deep learning (DL) based methods, such as deep neural networks (DNNs), have emerged significant milestone for both data representation and modeling [5]. In recent years, DL has attracted many research interest in the fields of speech recognition, chemical level prediction, brain disease diagnosis, disease classification, recognition of emotions, energy load forecasting etc. According to [6], DL has three vital advantages in (i) computational power executing the operations, (ii) processing large amount of data without over fitting issue, (iii) parameter optimization using an approximation to the objective function. Specifically for DNNs, the main differentiation is the dimension of networks containing hundreds of layers and neurons which can capture nonlinear relationships between predictor and outcome variables with higher prediction accuracies [6]. Although DNN is an excellent tool for complex data analysis, comprehensive parameter tuning is required for interpretability. Additionally, different parameter settings are needed to be evaluated for better prediction results [7]. Therefore, combining ensemble learning and DNN can be beneficial in order to aggregate individual results and achieve better representation of prediction methods.
Several voting mechanisms are widely adapted including averaging, majority voting etc. Some of these methods (for instance, averaging) can cause information loss that may lead misunderstanding of prediction results. In that cases, synthesis of DL and EL can be preferable as a voting mechanism. Additionally, DL may have a substantial contribution to voting mechanism when multi-dimensional data analysis is applied in EL algorithm.
This paper focuses on the determination of the differences between integrated DNN-ensemble learning methods and DNN based method that is conducted separately. This research direction is supported by considering grouped samples based on feature extraction. The major contributions of the paper can be listed as follows: (i) interpretation of the prediction results based on diversified machine learning algorithms and results are integrated with DNN as voting mechanism ii) selected methods are adapted with different features and parameters in order to gather better prediction results iii) individual results are grouped and clustered based on prediction results and ensemble DNN approach uses these clusters in aggregation phase to achieve “diversity” that has not been indicated before. To sum up, this study examines DNN-EL combined methodology by considering a certain number of machine learning algorithms’ results as features and these features are specified as the predictors of DNN based structure named as stacking. The outcome of this system is the final predictive result. Note that results grouped as heterogeneous classes, predictors are clustered and outcomes are calculated via DNN structure with diversified features. Under these circumstances, information loss caused from voting mechanism will be minimized.
Main advantages of the proposed methodology over other machine learning methods can be given in three perspectives i) using single EL ii) DNN based EL and iii) clustering DNN based EL structure. EL provides several advantages over other methods such that, i) EL enables training diversity with related sampling methods, ii) diversity can be achieved by hyper parameter settings iii) ensembles provide an extra degree of freedom in the classical bias/variance trade off, iv) Overcoming of over fitting problem will be achieved for better predictive results. In addition, contributions of DNN based EL strategy can be described as i) Long term dependencies are modelled with accurate predictions ii) experiments demonstrate that combined DNN based EL enables more accurate results rather than utilizing DNN and EL separately iii) prediction results can be generalized because of EL adaptation. Finally, clustering final results provides diversity by using the combination of diversified predictive results. In addition to that, grouping similar results facilitates the interpretation of the overall results in ensemble.
The paper is organized as follows: In Section 2, literature reviews for DNNs, Ensemble Learning and deep ensemble learning methods are presented and described. In Section 3, preliminaries are briefly given and in Section 4, application of the proposed methodology using public datasets (Rossmann sales forecasting dataset from Kaagle competition database [34] and energy use of appliances dataset [32]) are explained. Adaptation of the proposed methodology to these datasets and comparative results for both EL-DNN based model are also gathered in Section 4. Concluding remarks are given in Section 5.
Literature review
In this section, former studies are discussed by focusing on presenting the research direction and literature gap that lead this proposed methodology. Although EL and DNN have drawn attention, there are a very few works on DNN used EL.
Deep learning (DL) deep neural networks (DNN) and LSTM
Since the advances in machine learning algorithms and parallel computation, a particular type of prediction and classification has been introduced: Deep Learning (DL) and DNN. The main contribution of DNN is not only the introduction of a data analytic framework, it also presents increasing number of neurons, hidden layers and complex structure between predictor and output variables. This structure provides the formulation of nonlinear relationships between variables and optimal learning from available data [6]. As a result of recent improvements on computational time of machine learning algorithms and deep neural networks (DNNs), significant advances have been achieved in special topics such as image recognition, speech processing and recognition, sales forecasting, oil price forecasting and chemical concentration prediction. As realized from these studies, DNN based methods are generally used as classifiers [27]. On the other hand, recent applications of DNN based models are utilized in other research directions including sequential data analysis of recurrent neural networks (RNN). RNNs are feed forward neural networks that have internal memory to process sequences of inputs. The example of these studies can be given in the fields of visual tracking, target tracking and handwriting recognition [27]. According to [2], these models achieved good results but they ignored long term dependencies of time series because of the disuse of the activation functions such as tanh. In addition to that issue, vanishing gradient problem is another topic that limits RNN usage with long term dependencies where weights are assigned immoderately.
From the literature, one can conclude that forecasting problems utilizes machine learning approaches such as NNs, SVMs as well as regression based econometric models (ARMA, ARIMA, SARIMA etc.). These models are widely adapted to real case studies when coping with forecasting problems. In this term, studies indicated that high accuracies are achieved by the adaptation of DNN based models. For instance, [9] used one hidden layer based DNNs with data envelopment analysis for organ recipient functional status in healthcare. [10] investigated overall machine learning techniques applied in the field of supply chain demand forecasting. [7] studied remaining useful life via Bayesian structured DNN model. [11] adapted LSTM structured DNN for financial market predictions. Note that all these studies capture the advantages of DNN based models when complex data analytics is adapted with acceptable computational time.
As mentioned before, LSTM is a special type of RNN that can exhibit long term dependencies. Therefore, forecasting studies prefer to use LSTM structured DNN models in order to achieve better predictive results. The outstanding papers and their emphasized contributions are given in Table 1.
LSTM structured DNN studies
LSTM structured DNN studies
The main inference from LSTM based DNN studies are i) easy adaptation of training phase compared with other NNs ii) presentation of long term dependencies in diversified files iii) providing more complex NN structure with acceptable computational time. Therefore, LSTM is widely adapted in various fields and comparative studies indicate that preferable accuracy rates are achieved that cannot be succeeded with traditional econometric methods.
Ensemble learning is the set of procedures that aggregates multiple machine learning algorithms to generate weak predictive results by utilizing voting mechanisms. The main purpose of EL is reaching better predictive results based on aggregated results rather than using single approach. In this respect, EL based methods can be adapted to classification, prediction and forecasting problems in order to extract knowledge with using several machine learning algorithms named as basic classifiers [26].
According to [4], EL studies are generally presented as supervised ensemble classification, semi supervised ensemble classification and clustering ensembles which can be divided into four major categories: i) basic classifier level including classifier selection and weight adjustment, ii) feature level for feature selection, iii) sample level to select sample subsets, iv) ensemble model for performance measurement and model optimization. Briefly, supervised ensemble classification obtains gathering classification results from weak classifiers and merging multiple results. Note that, widely used ensemble classification methods are bagging, boosting, random forests, random subspace, gradient boosting. Bagging uses random subsets for training and AdaBoost algorithm evaluates misclassifications for weight determination of samples. Random forest combines multiple decision trees via diversified samples and features and random subspace that generates randomly sampling features for training basic classifiers. Finally, gradient boosting minimizes final residuals of errors. In addition to these methods, stacking provides the aggregation of multiple classification and regression models by training of complete training dataset and then, base level results are introduced as features that are needed to be trained. Note that some of the ensemble methods such as bagging and random forests minimize variance, however boosting and stacking enable decrease in bias and variance. This situation indicates that the ensemble learning performance highly depends on base classifiers’ individual errors. In addition to supervised ensemble classification, semi supervised classification is another topic for ensemble learning. Semi supervised classification focuses on widening training set. The classifier is initially trained using limited dataset and then unlabeled data is used in pseudo tags. This pseudo based labeled data provides the enlargement of original dataset. The substantial contribution of semi supervised classification is coping with data stream processing and high dimensional data analysis with better prediction results [4].
In the literature, ensemble learning methods are adapted to different base classifiers such as nearest neighbors (k-NN), 4.5 decision trees, ANN, Bayesian networks, SVM and stochastic gradient descent optimization (SGD) to provide proper classification. In addition to that algorithms, forecasting focused papers utilize ANFIS, SVR and heuristic approaches such as genetic algorithm and particle swarm optimization (PSO) in order to present diversified forecasting methods with minimized prediction error.
The aim of overall classification methods is to utilize from a dataset to develop a model that assigns instances to the subgroups. On the other hand, forecasting problems are appeared with numerical results. Thus, classifier ensembles are sometimes generated with one type of classifier; for example, neural network (NN) ensembles [14], SVM ensembles, k-nearest neighbor (kNN) ensembles [15], or tree ensembles [17]. Classifier ensembles have improved this application to the extreme based learning by making proper changes on parameters for one single classification model as studied earlier times [16].
In recent years, practitioners have developed further methods to improve the performance of the classification models. [18] emphasized on a semi-supervised SVM to increase the performance of scoring models, and the performance of proposed model presents better results to other industrial applications. [19] studied clustered SVM to overcome the drawbacks of nonlinear SVM oriented approaches for classification. [1] adapted a Multi-Layer Perceptron (MLP) Back propagation Neural Network to develop better scoring performance.
Former studies indicated that combined classification models that include hybrid models and classifier ensembles are better than those of a single classifier in diversified areas. [20] proposed a novel genetic algorithm based hybrid model that uses neural networks to predict the accuracy. [21] studied a combined ensemble approach utilizing SVM and ensemble strategies (bagging and random subspace) and the final performance of the proposed model was better than the other classification models. [22] studied the performance of cluster analysis with classifier ensembles. Similarly, [23] modeled an ensemble approach relied on different base classifiers for improving the effectiveness.
The other important topic for classifier ensemble is classifier diversity rather than accuracy. For instance, [24] searched an ensemble classifier method using supervised clustering to consider the classification accuracy and classifier diversity. On the other hand, current ensemble classification methods have some drawbacks. The lack of robustness that caused from highly depending on current dataset can be given as one of these drawbacks. For the datasets including distinct patterns, the existing models should be conducted for different type of parameters such as identical types of classifiers. To overcome this limitation, the proposed ensemble method uses DNN structured methodology to combine individual base prediction models with different parameter settings and feature subsets.
Hybrid studies for DNN integrated EL methods
As mentioned in the previous sections, neural network models are generally adapted to many real life cases due to their flexibility in modeling with complex data structures. Many types of NN models are conducted for prediction problems such as feed forward NNs, wavelet NNs, RNN and CNN. On the other hand, long term dependencies cannot be effectively modelled with RNN while dealing with time series data. This limitation can be overcome with LSTM considering its gating mechanism and its recurrent structure. As [26] indicated, LSTM has some drawbacks such as overfitting caused by high complexity, explaining the relationships between model fitting, model complexity and decomposed components. In this respect, reducing variance error of the prediction results can be achieved by using hybrid prediction mechanism as mentioned by [25] and [13].Starting from this deficiency appeared in the literature, we try to combine DNN model for the aggregation of diversified base models. As observed in [26]’s study, DNN and EL based model reduces both bias and variance that enables trade-off between these two error types. In this framework, base models are first trained separately and results are collected. Then, these results are progressed to LSTM and DNN based models to aggregate individual results. Finally, aggregated forecasting result is obtained by weighting according to base model results. Here, results are gathered from feed forward and back propagation structure. Here, EL enables feature extraction and selection before DNN based phase.
When examining the studies adapted for both DNN and EL, a limited number of papers aroused from literature. These studies are given in Table 2. Main contribution of DNN based EL framework is better prediction results according to accuracy. In addition to that, DNN-EL combined methods ensure a certain generalization degree for the prediction results.
DNN-EL based models extracted from literature review
DNN-EL based models extracted from literature review
Since LSTM has recursive memory to cope with diversified features, evaluating long and short term dependencies for time series can be conducted successfully. In addition to that case, EL is utilized for improving LSTM performance with diversified strategies such as feature selection and parameter settings for experiments. In the following subsections, fundamentals for DNN and LSTM structure will be given in order to support technical information of proposed methodology.
Preliminaries for DNN, LSTM, and ensemble learning

Basic RNN structure.
DNN can be described as one of the machine learning subfield that copes with large amount of data and features with a hierarchy of multiple layers. DNNs contain a plenty number of structures such as CNNs, RNNs for presenting diversified data samples including images, words, numerical values and characters. As a special type of DNN, RNN deals with sequential data and allows a ‘memory’ of previous inputs to process in the networks internal structure. By this way, it affects the output of the network [26]. The overall structure of RNNs also includes activation function based representation to assign weights. A basic RNN is illustrated as seen in Fig. 1.
As mentioned in previous sections, RNN neglects long term dependencies of time series due to the misusage of required activation functions. Therefore, LSTM is developed for modeling long term dependencies of time series without facing gradient vanishing problem and has a memory unit to process sequences of inputs [28].
As shown in Fig. 2, LSTM unit includes cell, input gate, output gate and forget gate. The cell recalls values considering permissive time intervals and gates decide which information can be stored or forgotten. The equations in time t are given as follows:
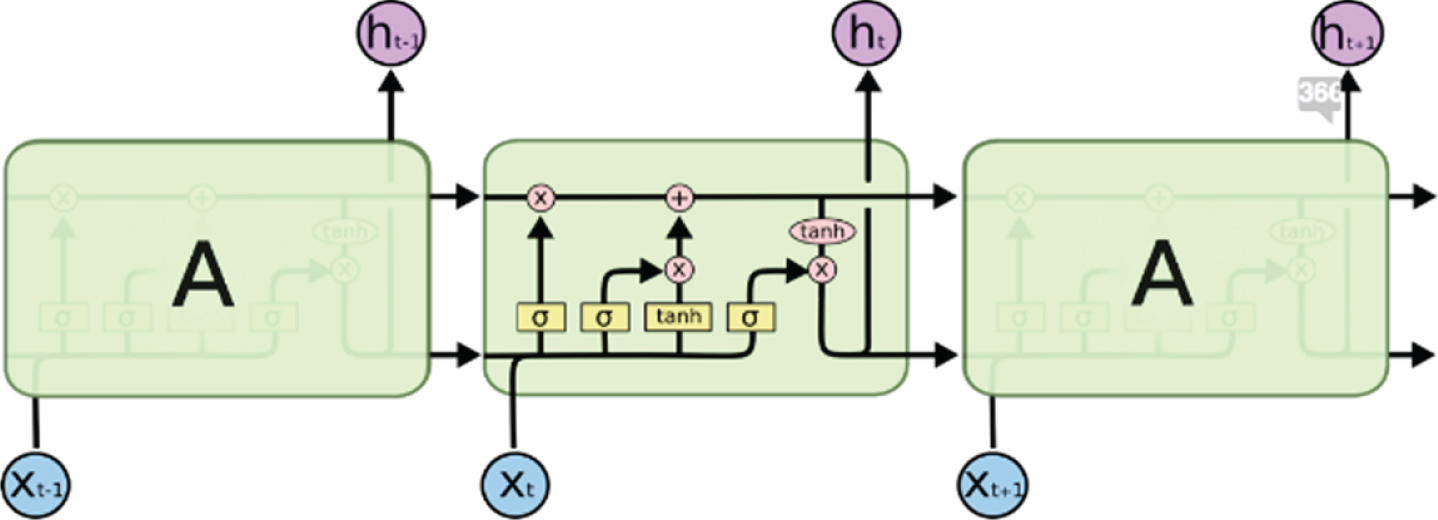
LSTM structure (From [33]).
Aer aspect of our study is EL phase that assists the combination of diversified predictive results to improve the accuracy. EL h three classic approaches: bagging, boosting and staing. The main objective of these techniques is improving prediction results by manipulating the dataset.n our case, random forests, SVM and ANN are utilized for gathering prediction results. The random forest relies on CART (classification and regression tree) structure as base learner, which is a special type of decision tree. Random forest regression can be implemented as follows: each decision tree is constructed from a manipulated sample of dataset, including 70% as sample. Observations that are not decided for the sample set are denoted as out-of-bag (OOB). At each node, regression tree is grown at each sample, one third of input variables is randomly assigned and the best separation is selected considering the lowest Gini index. For each data manipulation iteration, response value for OOB data is estimated and averaged over all trees. The separation process is iteratively fulfilled to each tree until a stop condition is satisfied [30]. In random forest, two parameters are optimized using manipulated dataset and performance measurements such as Mean Square Error (MSE): number of regression trees and different input variables per node.
SVM is a supervised machine learning technique that depends on the statistical learning theory. Bu utilizing from a training dataset, SVM directs input data into a high-dimensional feature space by determining a maximum margin of split between classes and forms a separation hyper-plane in maximum margin. The main goal of SVM is the minimization of loss function and by solving the convex optimization problem given below, it will be able to find the function f(x) with minimum value of loss function [29]:
s.t.
Where
Finally, ANN is adapted for individual predictive results. ANN consists of parallel-dispersed operators for evaluating experimental knowledge. The network is usually comprised of a number of layers and nodes. The layers named as input, hidden and output layers and obtain N, L and K number of nodes, consequently. Each node in the input layer is connected with all the nodes in the hidden layer considering weighted links. When N and L number of input and hidden nodes are appeared, network also hosts as a bias node (number of output+1) in its input and hidden layers. In training phase, ANN changes its weights to determine output considering an acceptable error. If it proceeds, training set achieved learning phase and also, it is ready to evaluate unprocessed data. If it fails, the network tries to approach the correct output with re-learnings. The weights are reassigned when each iteration is proceeded to the training set. The process will stop until the appropriate weights have been assigned.
According to the implications from literature review, predictive results become more reliable and generalizable when several models are used to gather a combined result. As LSTM and RNN methods have the capability of strong predictions and diversification with independent error distributions, a prediction method that combines these two methods with EL structure, which are named as LSTM-EL and RNN-E. Note that they are developed to further improvements of the prediction accuracy as seen from Fig. 3.

The architecture of the proposed DNN based EL methodology.
The sequential data in a time window form is the first input for both LSTM and RNN to make independent predictions. In parallel, dataset is modified with respect to feature selection a random forests, SVM and LSTM are separately adapted to real dataset and modified dataset. Then, their predictions on each scope are combined using LSTM and R structure to produce the aggregated prediction. Note that, individual results are grouped for clustering. The final prediction result is then used as the output of the input sequence. By repeating this process, n-time stamp predictions can be gathered.
In order to demonstrate the effectiveness of the proposed methodology, two case studies are evaluated with their datasets: i) Rossmann sales forecasting dataset from Kaagle competition as a public dataset [34] ii) energy use of appliances prediction dataset [32]. For the first case study, one-day-ahead sales volume for each store is predicted based on the history of previous sales. The dataset comprises 842,806 days of past sales from 1113 different pharmacies. In terms of preprocessing, following categorical variables are utilized: store ID, state holiday, school holiday, store type, assortment. In addition, we used the following numerical variables: promotion continuing or not, sales (turnover), competitor distance, and promotion interval. For the second case study, ten minute records from logged energy data are evaluated and the features considered in this study are: lights, energy use of light fixtures in the house, temperature and humidity in kitchen, living room, laundry room, office room, bathroom, outside the building (north side), ironing room, teenager room, parents room, temperature outside, humidity outside, pressure, wind speed, visibility. The timespan for the second case study dataset includes 4.5 months and consumption dataset has high variability.
Before implementing the proposed methodology, datasets are normalized and missing values are eliminated with averaging. In addition to that, features are selected according to the correlations between them as seen in Fig. 5.
After that, dataset is divided as training and testing data. Random Forests, LSTM and SVM are adapted as prediction methods for the first case study. Experimental analysis is also conducted for providing proper parameter settings including altering epoch number, batch size etc. Finally, individual results are grouped according to the predictive results and results are then merged considering both with clusters and without these clusters as seen in Fig. 4. Considering the base models and clustered results, lowest MSE value is appeared after individual results are clustered according to the predictive results with using LSTM based EL methodology. By providing lowest MSE and MAE, we demonstrate the proposed algorithm enables acceptable accuracy with diversified clusters. The final results are presented in Table 3.
Experimental Results for Case Study 1
Experimental Results for Case Study 1

The main architecture for the proposed DNN based EL combination structure.

Feature importance for Rossmann sales forecasting dataset.
In the second case study, similar steps are followed to prepare the overall dataset before implementing the experimental study. Particularly, dataset is divided into training and test dataset that 75% of dataset belongs to training for the base models and the rest is used for testing. Thereafter, feature selection is conducted considering the high correlation between variables and additionally, main effect on output variable (energy use). As similar with Case study 1, MAE and MSE are considered for the performance measurement considering the same experimental settings given in Fig. 6. Again, LSTM based EL method performed best MAE and MSE values according to the clustered individual results that are merged in aggregation phase.
In the second case study, similar steps are followed to prepare the overall dataset before implementing the experimental study. Particularly, dataset is divided into training and test dataset that 75% of dataset belongs to training for the base models and the rest is used for testing. Thereafter, feature selection is conducted considering the high correlation between variables and additionally, main effect on output variable (energy use). As similar with Case study 1, MAE and MSE are considered for the performance measurement considering the same experimental settings given in Fig. 6. Again, LSTM based EL method performed best MAE and MSE values according to the clustered individual results that are merged in aggregation phase.

An Example for experiments made for the proposed approach.
In detail, Fig. 7. presents the predicted sales for Rossmann dataset from January 2015 to August 2016. As seen from the figure, gap between predicted and actual sales is aroused especially for the extreme points given in January and April. The underlying reason for this situation is the followed sequential path in

Predicted sales for Case study 1 with LSTM based EL method.
LSTM gives the extreme points away and actual effect of these extreme points can be grabbed after several steps are calculated. Specifically, correlations between variables should be examined before implementing LSTM structure of EL. For instance, each correlation demonstrates the relationships between variables with each other. These correlations indicate strong and weak connections between variables and highly correlated variables should be eliminated. The first cause of this circumstance is the independence assumption which must be satisfied before applying LSTM. For the case study 2, living room and bathroom has strong correlation that if anybody stands in the living room, bathroom temperature and humidity will be lower than standing any other room.
Figure 8 indicates the difference between MSE values appeared for diversified base models. One can conclude that LSTM base model performed better when compared with ANN and SVM. ANN and SVM prediction performances are similar when a great number of epochs are adapted. With limited number of epochs, ANN performed better prediction results. The main reason can be SVM needs long training time and epochs rather than ANN if same iterations are conducted to these models.

MSE values after individual results are gathered. Note that number of epochs is determined as 100. (*Grey dotted: SVM, Blue dotted: ANN and Yellow dotted: LSTM base model predictions).
Figure 9 introduces actual and predictive results for Rossmann dataset. By considering small number of timespan, predictions are carried out more precisely. Same issues can be realized as seen in Fig. 7 that extreme points can cause problems in terms of following sequential data. In addition to that case, if a considerable number of iterations are performed, extreme points can be predicted better than conducting small number of iterations.

Actual and predictive results for Case study 1(x axis: number of iterations, y axis: difference between actual and predicted results).
In this paper, DNN based ensemble learning approach with experiments using different features and parameter settings is proposed. In addition, individual predictive result clusters are considered. DNN-EL combined methodology includes machine learning algorithms’ (SVM, random forests and LSTM) results as features and these features are the predictors of DNN based structure which can be named as stacking. The outcome of this system is the final predictive result. As the results constitute heterogeneous groups, predictors are grouped and output variable is determined with diversified features. In these premises, higher accuracy for prediction is achieved and diversity is provided with adding clustering structure rather than using voting mechanism. Therefore, ensemble learning framework based LSTM can be adapted to many cases in order to evaluate the final results. As further studies, other predictive approaches such as Least Absolute Shrinkage and Selection Operator (LASSO) should be conducted for the diversification of the overall results. In addition to that, critical parameter changes can be processed for enriching individual base results.