
Abstract
Cognitive computing is the mirroring of human brain and this is made possible by using natural language processing, pattern recognition and data mining. By mirroring the human brain (Cognitive computing system), helps to solve some of the complicated problems without much of human supervision. In the fast-changing world, the major challenge every organization facing is difficulty in retaining its employees. Employees may leave an organization due to low salary, overwork, lack of opportunities and recognition, work culture, work-life imbalance etc. Better ways to retain employees is to understand their requirements and fulfill them. The proposed employee feedback sentiment analysis system collects the employee feedback reviews from open forums and perform sentiment analysis using Recurrent Neural Network – Long Short-term Memory (RNN-LSTM) algorithm. On performing Sentiment analysis, employee review comments are classified as Positive or Negative. A report is generated and sent to the HR of the organization as webapp or mobile app. The report has total number of positive and negative comments and positive and negative counts with respect to salary, work pressure etc. With the report, the organization can arrive at identifying social sentiments of their brand and may take corrective actions to retain employees which benefits both organization and employees. This paper also captures the performance of various models in training and predicting the employee feedback dataset and the models evaluated are Logistic Regression, Support Vector Machine, Random Forest Classifier, AdaBoost Classifier, Gradient Boosting Classifier, Decision Tree Classifier and Gaussian Naïve Bayes. The classification report and accuracy of each model is captured. The dataset size was gradually increased from 200 to 1000 and accuracy was predicted for each model. It was identified that the accuracy of machine learning algorithms was ranging between 66% to 85%. On training RNN-LSTM algorithm with dataset of size 30 k, the accuracy was 88%. It was identified that Deep learning algorithm RNN-LSTM performs better with huge dataset. Increasing dataset size still increase the performance of RNN-LSTM algorithm in training and prediction. Thus, the objective function of the proposed model to perform sentiment analysis on employee feedback review comments is achieved successfully.
Introduction
Today, social media is extensively used by people around the world to share their experiences and their learning. Sentiment Analysis is the common classification tool that analyses an incoming message and determines whether the piece of information is positive, negative or neutral. It also helps to asses opinion, attitudes and emotions. Sentiment analysis can be performed at three levels. They are document level analysis, sentence level analysis and aspect level sentiment analysis. Document level analysis identifies the overall opinion of the document. Sentence level analysis is performed on sentences. Sentence level analysis first determines whether the given sentence has opinion or not. Normally objective sentence has factual information while subjective sentence express opinion. If the sentence expresses any opinion, then sentiment of the sentence is identified. In the proposed method sentence level sentiment analysis is used. Aspect level analysis [8] is finer analysis and it is performed on each aspect of entities (Aspect/features represent components of entity - e.g. the screen of cell phone, service in hotel, picture quality of camera etc.) Aspect level analysis uses the Natural Language Processing (NLP) which is a subset of artificial intelligence (AI) that helps systems to understand the human language. Identification of aspects or features can be done through Topic Modelling or Deep Learning methods.
Sentiment analysis is being used in various field like business, politics, public actions, finance etc. It helps in identifying customer opinion towards products or services and helps improving business. Constant rise in employee attrition may result in reduced productivity and profit, difficulty in running the operations, customer attrition, low workplace morale and deteriorating product or service quality. One way to retain employees is through identifying their requirements and fulfil them. Though various engagement surveys are available within the organization, there is no true reflection of employee’s expectations. There are social mediums like Glassdoor.com, Indeed.com websites which would allow the employee to share freely their views or feedback about the organization. On performing Sentiment analysis on employee’s feedback, an automated monthly report is sent to the HR of the organization in web app or mobile app. Report contains classified positive and negative sentiments. With the report, the organization can arrive at identifying social sentiments of their brand and may take corrective actions to retain employees which benefits both organization and employees.
This paper’s contributions are as follows: Comparative study of performance of various algorithms like Logistic Regression, SVM, Random Forest Classifier, Ada Boost Classifier, Gradient Boosting Classifier, Decision tree classifier and Naïve Bayes in training and predicting employee feedback dataset. Investigating the performance of deep learning RNN-LSTM algorithm in training employee feedback dataset Perform sentiment analysis on employee feedback for selected organization using deep learning RNN-LSTM algorithm.
This paper is organized as follows: Section 2 includes articles relevant to the implementation. Section 3 explains techniques used in this study. Section 4 details the experimental setup and proposed system. Section 5 provides results and discussions and conclusion is discussed in Section 6.
Articles related to our work
Tweets related to 2016 US election has been classified [3]. Dictionary is constructed with words of polarity depending on the hashtags for the selected topic. Steps involved in implementation are data gathering, data processing, classification and its accuracy evaluation. Two classifiers used are Google cloud prediction API, Naïve Bayes. Result is also compared with other sentiment analysis tools like Meaning cloud, RapidMiner, StreamCrab, IBM Watson text analytics. Opinion polarity is very effective in predicting human attitude when analysing big data. This helped to understand the opinion polarity that helps to identify deep emotions expressed in social media.
Sentimental analysis of Machine Learning techniques, like a. Probabilistic classifiers, b. Naïve Bayes, c. Bayesian Network, d. Maximum entropy classifier, Linear Classifiers like a. SVM, b. Decision Tree, Rule based classifier were discussed in detail [16]. It was identified that lexicon-based approach solves many sentiment analysis tasks despite its high complexity. Using domain specific corpus provides good results than using domain independent corpus. This helped to learn multiple recent sentiment analysis techniques.
The proposal [1] is based on classifying tweets as extremist and non-extremist classes. Deep learning techniques are used in the tweet’s classification. Methodologies involves Data collection, Pre-processing, Training, Validation and testing. The workflow of the network comprised of following steps: i) collection of tweets, (ii) pre-processing (iii) classification based on LSTM + CNN model and other Machine Learning and Deep Learning classifier. It was understood that proposed system performed better with LSTM + CNN.
Ajay Shrestha and Ausif Mahmood [2] explaineddeep neural networks and their optimizations to improve accuracy. Also, the mathematical formulas behind deep neural networks has been briefed [2, 6]. Architectures of various deep learning algorithms like Deep Convolution Network, Deep Residual network, RNN, Reinforcement learning, Variational auto encoders were explained in detail.
Improved word representation method is discussed in detail [17]. Weighted word vectors are generated using traditional TF-IDF algorithm and it is fed as input into BiLSTM (Bidirectional LSTM) to capture the context information effectively. The proposed method is compared with other techniques like NB, LSTM, CNN and RNN. Results showcases that the proposed method has higher accuracy.
Paper [11] provides survey of various deep learning networks like RvNN, RNN, CNN, DGNN and Deep learning techniques along with their operating framework. Various applications of deep learning is also elaborated.
Sepp Hochreiter and Jurgen Schmidhuber [5] proposed long short-term memory (LSTM). Paper explains how the constant error flow in the naïve approach is overcome by LSTM. LSTM is experimented in Embedded Reber Grammar, Noise-Free and Noisy Sequences, Adding Problem, Multiplication problem. Advantages of LSTM is discussed in detail.
Power consumption forecasting system is proposed using deep learning and ensemble deep learning techniques [9]. LSTM-RNN is identified to be more efficient technique for load forecasting when compared with RestrictedBoltzmannmachine, deepbelief networks, Adaptive neuro-fuzzy inference systems and Optimally pruned extreme learning machines.
Malware detection in android is achieved at low cost by implementing Long Short-term Memory (LSTM) [12]. Performance of LSTM network is better when compared with RNN and other machine learning classifiers.
It is understood that sentiment analysis is very efficient and effective tool when used with appropriate algorithms. In RNN [4, 19] output of previous step is given as the input to current step unlike traditional Feed forward Neural Network where connection between nodes do not form cycle. One of the key challenges in training the artificial neural network is vanishing gradient problem [13]. In some scenarios, the gradient would be relatively small and in worst case scenario this might stop the network from further training. Vanishing gradient problem in RNN is solved using LSTM [7, 10]. RNN-LSTM has memory [18] that captures information that has been calculated so far and allows the information to persist. RNN-LSTM are promising solutions to sequence and time series problems. Since our project involves huge dataset and requires deeper understanding of emotions, Deep learning RNN-LSTM algorithm is selected for training and prediction.
Techniques used in this research
Since RNN-LSTM algorithm has the ability to remember or store the previous input and identify the next sequential data it is being used in our research.
LSTM ALGORITHM
Long short-term memory (LSTM) is an artificial (RNN) architecture used extensively in the field of deep learning. LSTM process sequence of data and also has feedback connections.
A common LSTM unit is composed of different memory blocks called cells [13]. Refer Fig. 1. The cell state and the hidden state are the two states that are carried to next cell. The memory blocks stores or remembers the valid data. Manipulating data in memory is achieved using three mechanism called gates. A forget gate, an input gate, and output gate. Refer Fig. 2 [20].
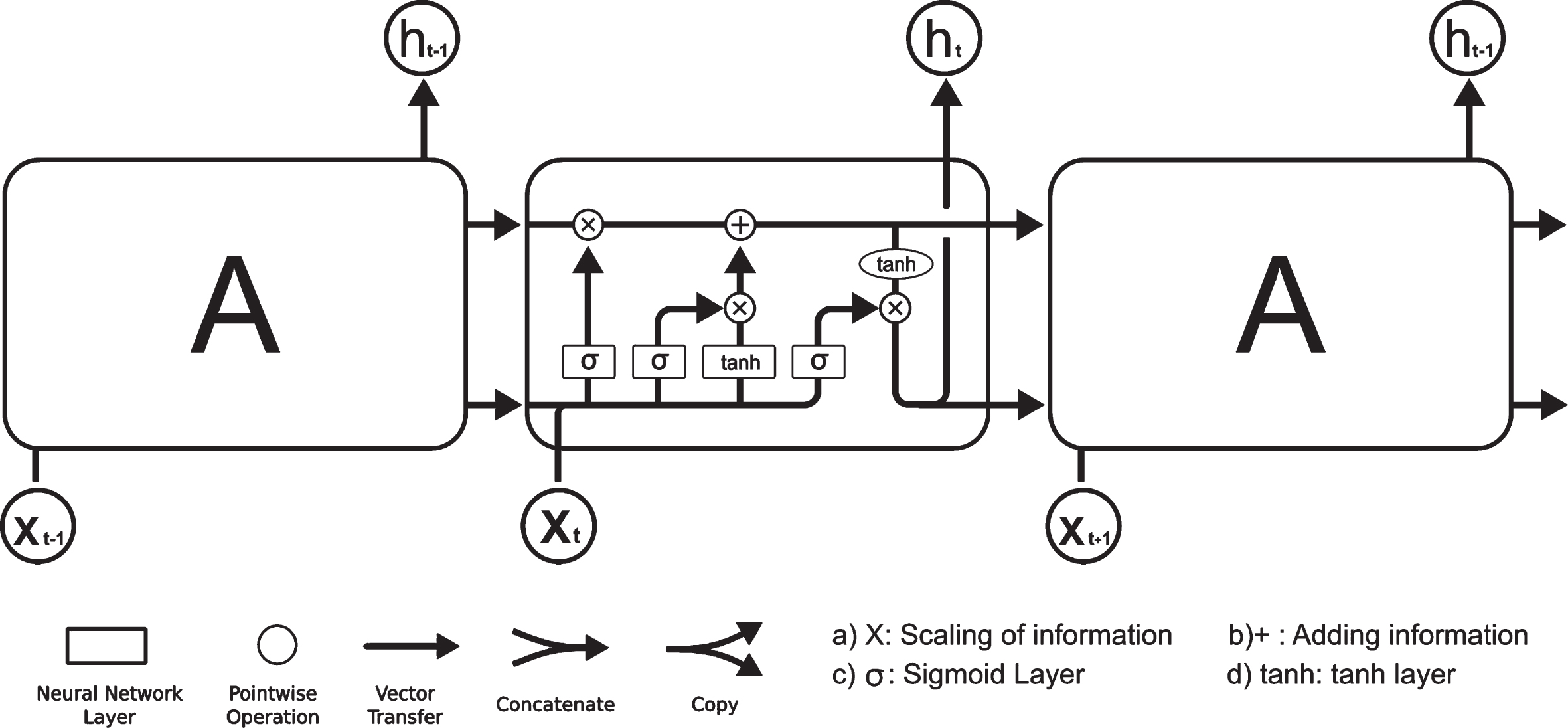
LSTM Architecture.
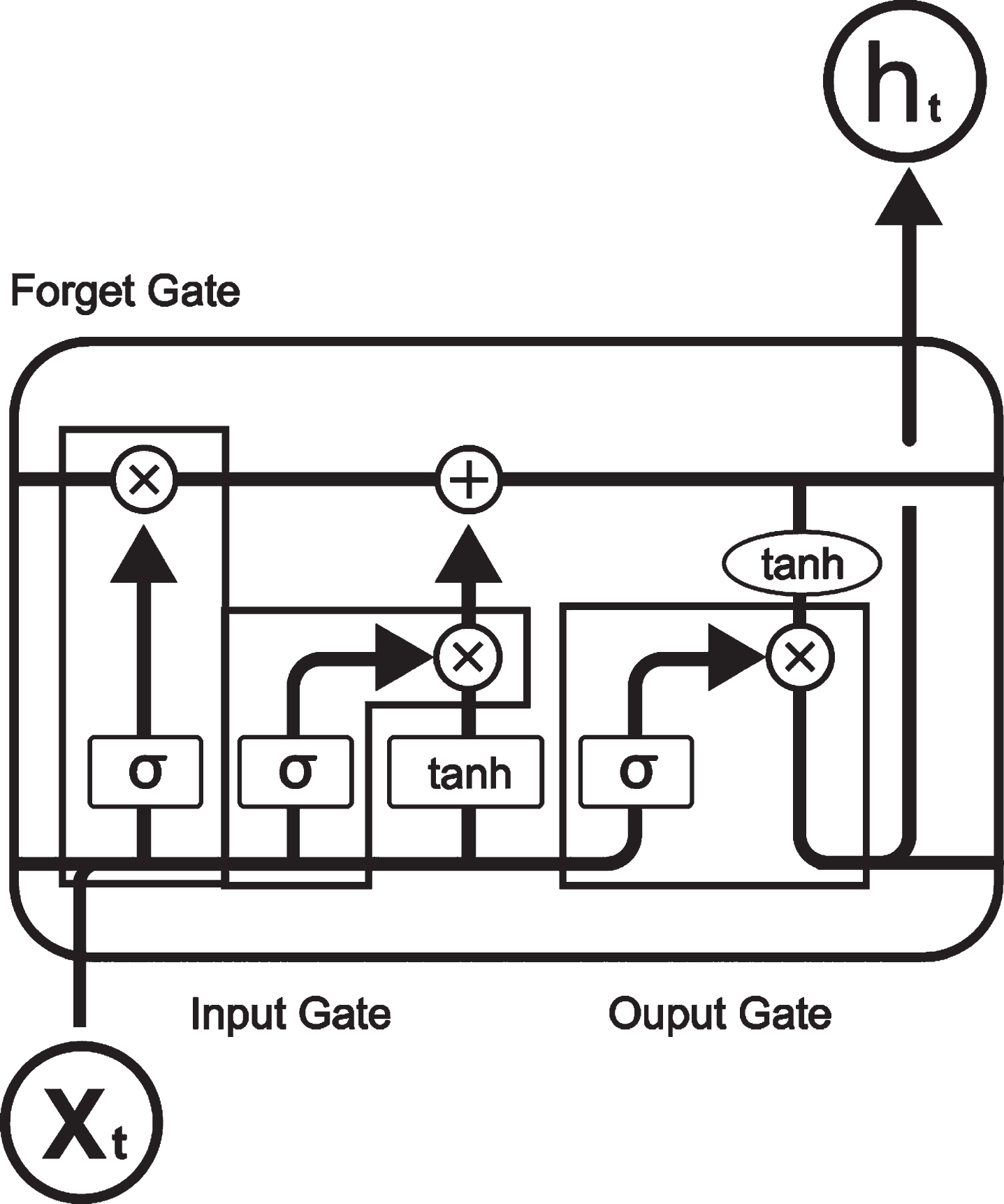
LSTM cell with forget gate, input gate and output gate.
The individual gate design is shown in Fig. 3.
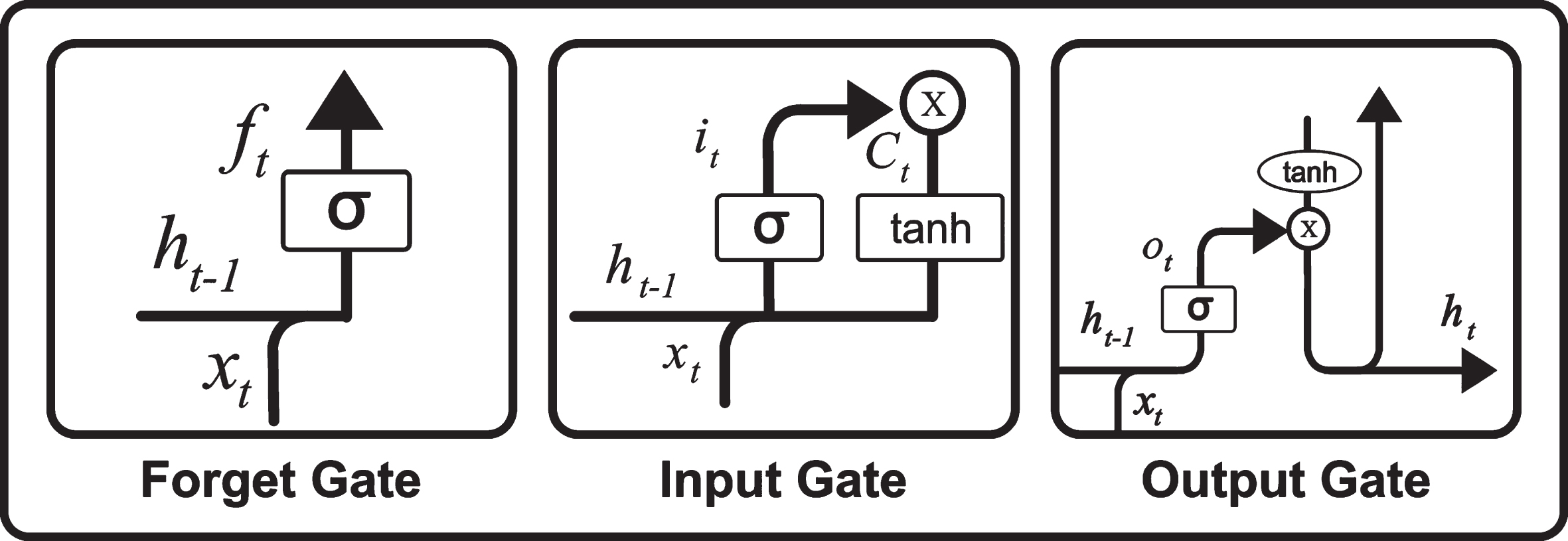
Gate with input flows.
A forget gate is responsible for removing information that are no longer required from the cell state. Sigmoid function takes X(t) and h(t-1) as input and decides which values to keep and which values to discard.
The input gate is responsible for the addition of useful information to the cell state through three steps. Regulating values using Sigmoid functions. Creating vectors for new inputs using tanh. Multiplying values of sigmoid gate to created vector and finally add useful information to cell state.
Output Gate Create vector using tanh and scale the values rom – 1 to 1. Sigmoid layer decides which parts of the cell state goes to output. Multiply the values of sigmoid gate with vectors.
Mathematical Implementation
In this section, the mathematical model of the LSTM algorithm is presented. For this purpose, variables are defined first. The goal of the algorithm is to predict the sentiment of the given employee feedback sentences.
Parameters
C: Cell h: Output values t-1: Previous LSTM block value t: Current block values σ: Sigmoid function tanh: hyperbolic tangent function ft: Forget gate vectors it : Input gate vectors ot : Output gate vectors W: Weights assigned for input w: Weights assigned for recurrent output b: bias value
Operations
+: summation ×: multiplication
The gate computations [14, 20] are described in equations below
Comparative study of various algorithm performances
This project begins with collecting the employee feedback dataset and classify them as positive and negative comments. Refer Table 1.
Sample Dataset
Sample Dataset
Dataset is loaded and cleaned dataset by removing the html tags and numbers. All the sentences are converted into lowercase and split into words. Stop words are removed. The Models are defined. Refer Table 2. sklearn is an Open-source library in Python that defines many supervised, unsupervised learning algorithms. The Machine learning algorithms used in our model are Logistic Regression, Support Vector Machine, Random Forest Classifier, AdaBoost Classifier, Gradient Boosting Classifier, Decision Tree Classifier and Gaussian Naïve Bayes. Refer Fig. 4.
Model Definitions
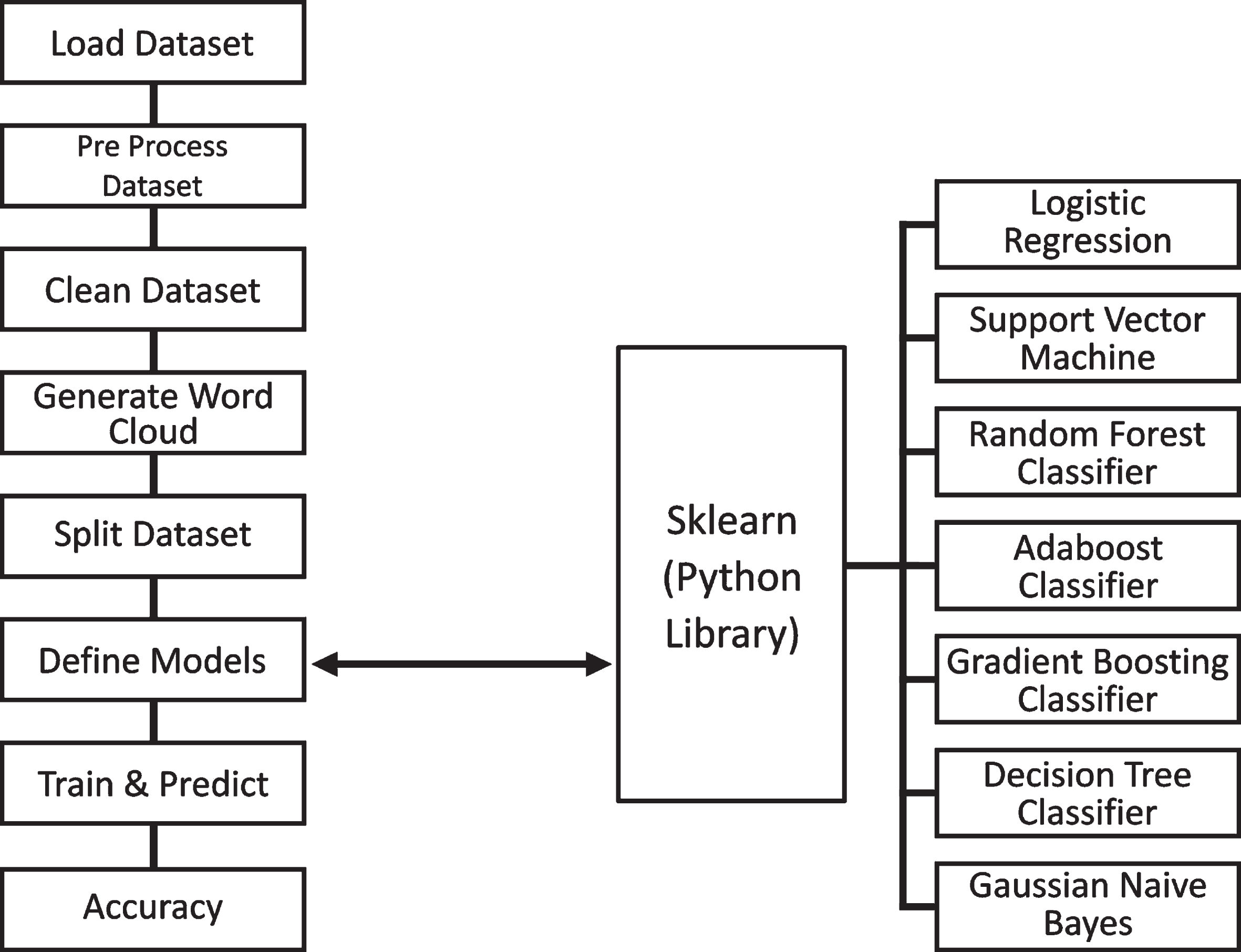
Performance computation block diagram.
Split the dataset size ‘test_size’ as 0.2, so that 80% of dataset is allocated for training and 20% of dataset for testing purpose. The dataset is trained with each model and accuracy and classification report for each model is displayed. The size of dataset is changed from 200,400,600,800,1000 and accuracy of each algorithm is noted. The achieved performance is compared manually.
The sentiment analysis Architecture Diagram Fig. 5 explains the input and output that flows through the system and the training and prediction performed by the RNN-LSTM algorithm.
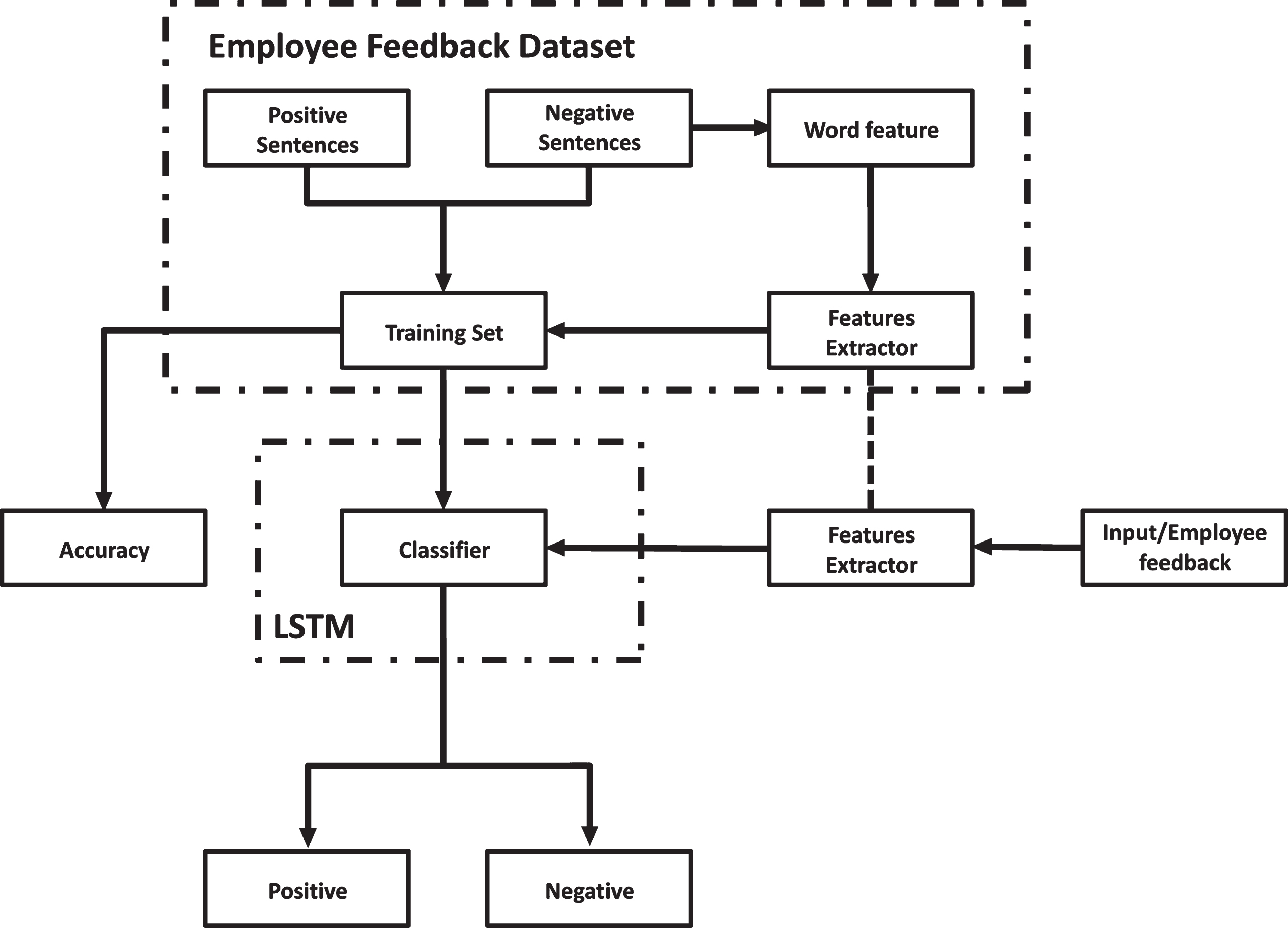
Architecture diagram of sentiment analysis on employee feedback reviews.
During training RNN-LSTM algorithm, dataset of size 32 k is passed. Dataset is loaded and cleaned by removing the html tags and numbers. All the sentences are converted into lowercase and split into words. The stop words were removed. Word to int and int to word dictionary is created. Matrix is created to tokenize the words [1].
LSTM model is designed with 500 nodes and set the dropout as 20% (where dropout is the prediction technique which randomly shuts down some neuron from overfitting). Density of LSTM model is set to 1. Activation function used is “Sigmoid”.
LSTM model is trained by calling fit function and it returns history attributes which contains training metrics for each epoch. Accuracy is captured while training the dataset.
Once the training is over, Web application is launched. User is allowed to select an organization from the list of 10 organizations. On clicking the ‘submit’ button sentiment prediction module is called and each feedback comment for the selected organization is analyzed and classified as Positive or Negative and predicted result count is displayed in the web page. Sentiment analysis Implementation has single LSTM layer, with 500 LSTM cells/unit. Dropout is set as 0.2. Each sentence is split into words. Words are converted into vectors and added to the word to int list. Use the weights created during LSTM training. Inputs of different lengths are padded, and it is reshaped into a matrix of single row and multiple columns. Finally, the sentence is predicted as positive or negative based on the value 0 or 1 available in the matrix position [0,0].
The mathematical procedure involved in identifying the sentiment (0/1) is listed from step 1 to step 11 and the calculations are performed using equations Equations (1) to (5).
Step 1: Execution starts with forget gate (equation 1) where weight Wf and wf gets multiplied with the input value xt . and previous output ht - 1 respectively. Bias b f is added to the input.
Step 2: Activation function (Sigmoid) is applied to values to convert them between 0 and 1. If the value is greater than 0.5, then it is assumed as 1 else it is assumed as 0.
Step 3: Weights and bias are added for input gate (equation 2), sigmoid function is applied.
Step 4: Similarly weights and bias are added for output gate (equation 3), sigmoid function is applied.
Step 5: For candidate gate (ct) tanh function is applied.
Step 6: Next sell state vector is calculated using candidate gate equation (equation 4).
Step 7: Output ht is calculated using the equation 5.
Step 8: Calculated candidate gate value (c t )and Output (ht) is passed to the next LSTM cell.
Step 9: Step 1–8 is repeated for all cells.
Step 10: Finally, LSTM produces output.
Step 11: If the obtained calculated value is 1 then sentiment is classified as “Positive” else sentiment is classified as “Negative”.
Similarly repeat step 1 to 11 for all the feedback comments for the selected organization. Predicted result is saved in the Result.xlsx file for the respective feedback comments. Total number of positive and Negative comments and number of feedback comments with respect to salary, workload, culture is created as report and sent to the HR of respective organization.
Experimental results and discussion
Performance of algorithms
The accuracy of each model is captured by varying the size of dataset from 200 to 1000. The performance of all models in training the dataset is shown in Table 3. The graphical representation of results is shown in Figs. 6–10.
Result: Performance of each training model
Result: Performance of each training model
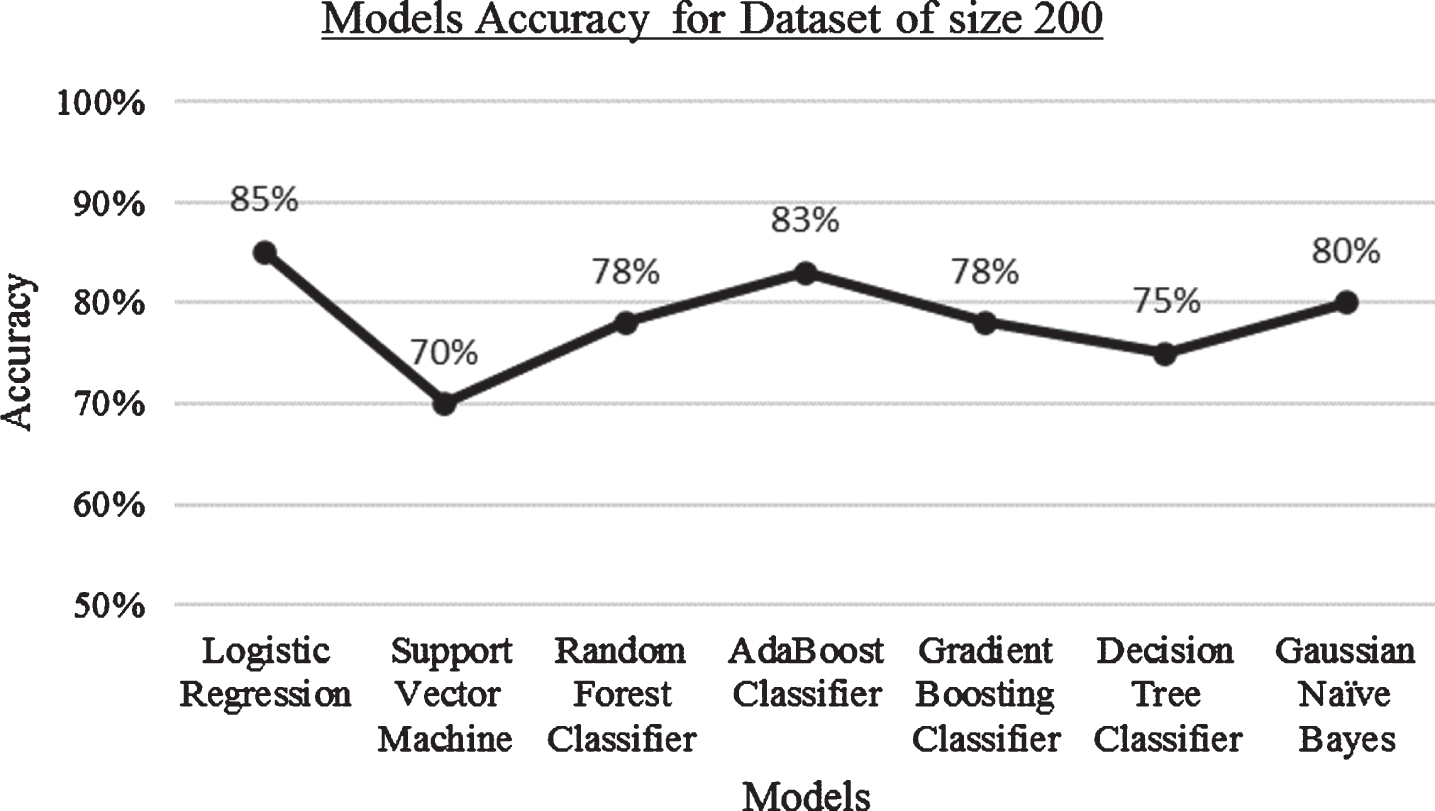
Result: Accuracy of algorithms when the dataset size is 200.
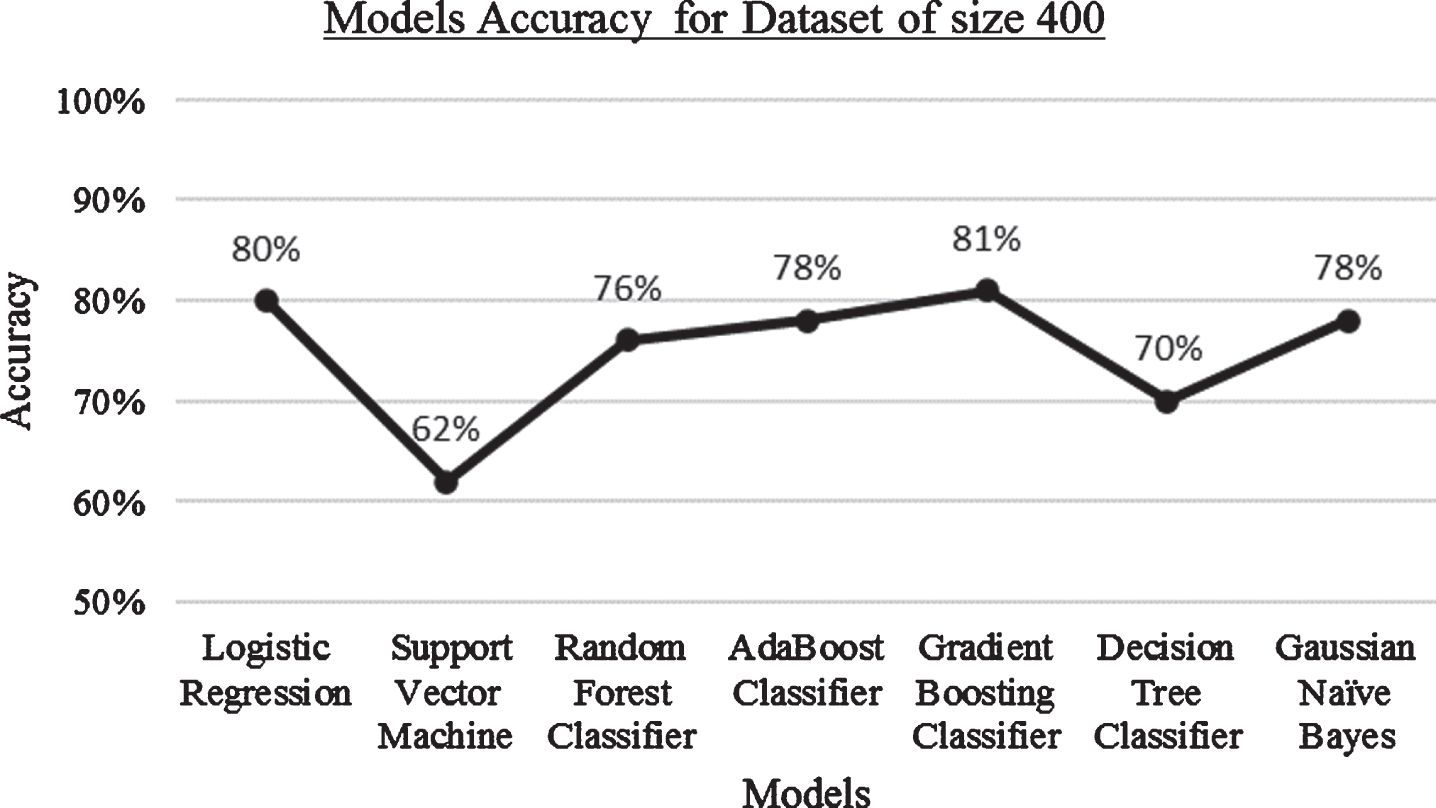
Result: Accuracy of algorithms when the dataset size is 400.
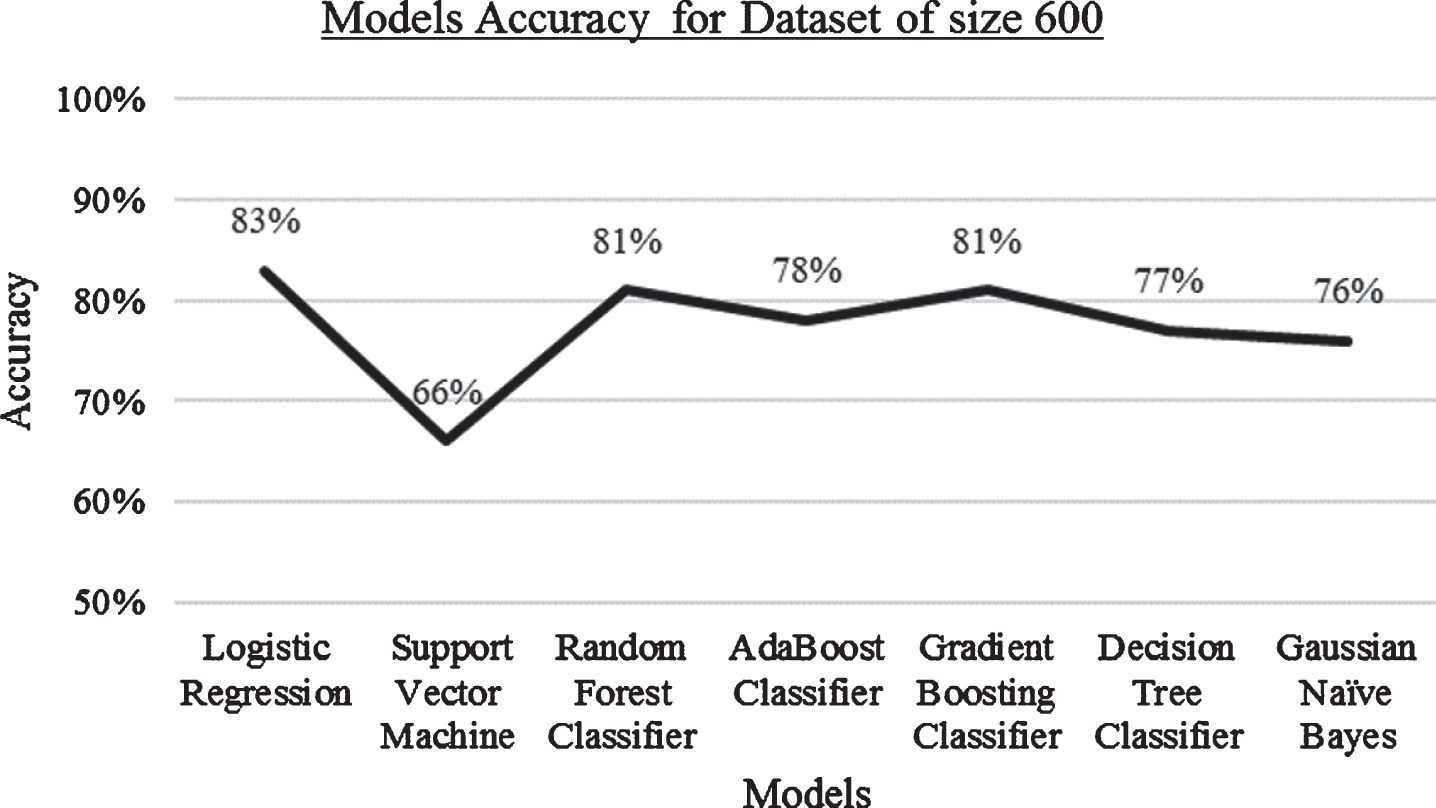
Result: Accuracy of algorithms when the dataset size is 600.
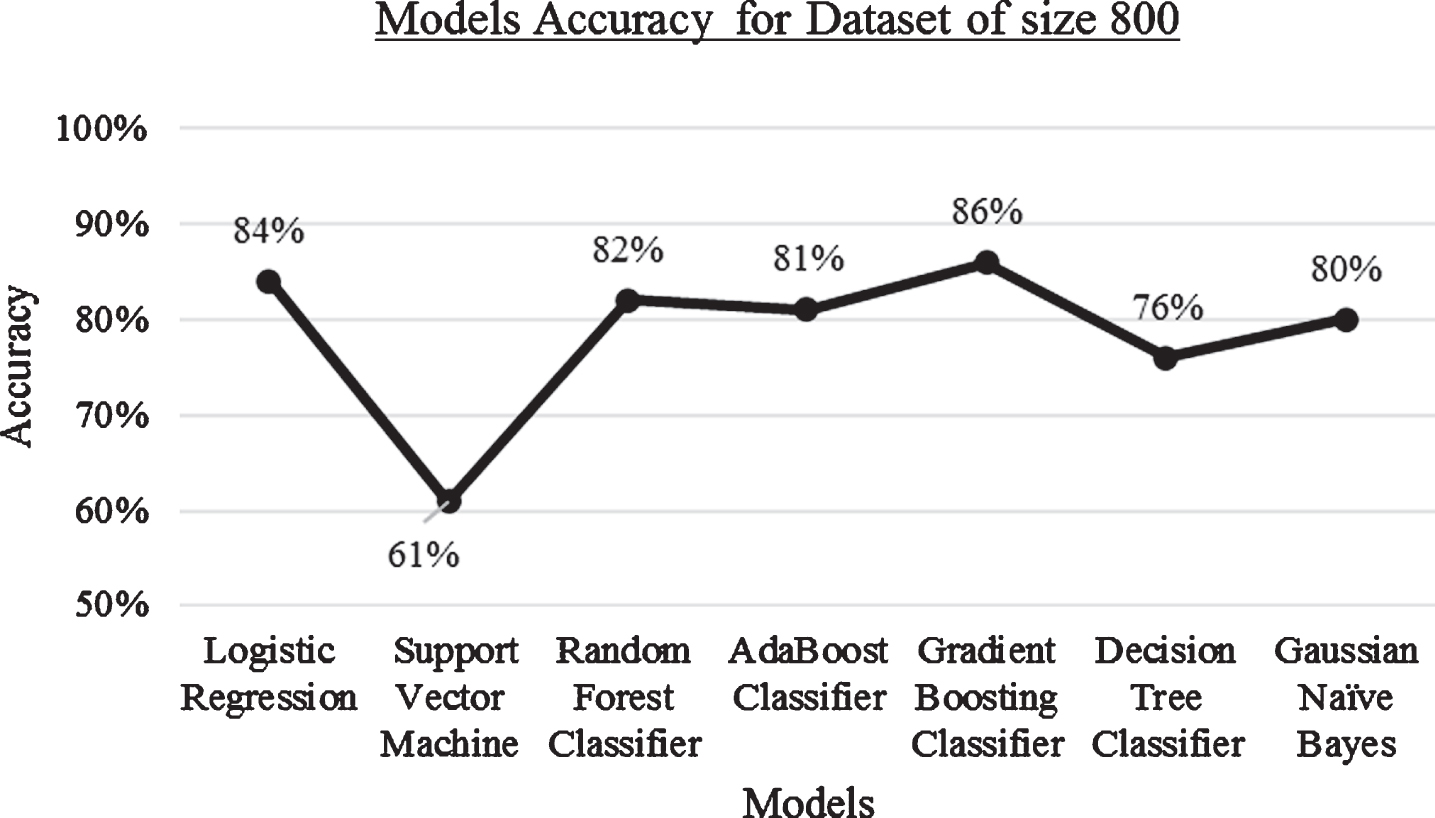
Result: Accuracy of algorithms when the dataset size is 800.
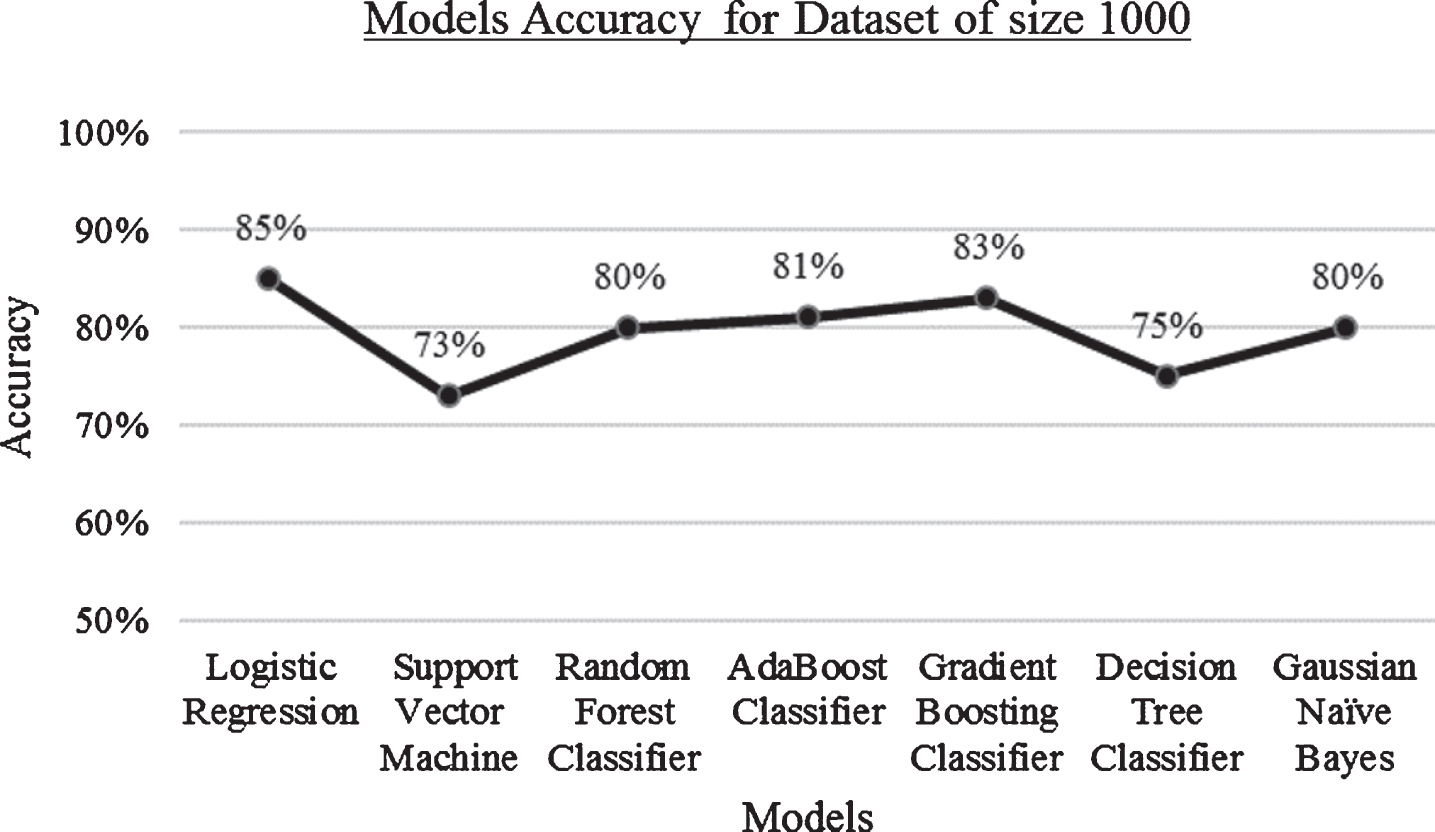
Result: Accuracy of algorithms when the dataset size is 1000.
When the dataset size was increased from 200 to 400 there was dip in performance of all the models except Gradient Boosting whose performance rose from 78% to 81%. When the dataset size was increased gradually from 400 to 1000 the performance started to increase.
When the dataset size is 200, the performance of Logistic regression is better with 85% accuracy and support vector machine shows lowest performance with 70% accuracy when compared with other models. Refer Fig. 6.
When the dataset size is 400, the performance of all the models dropped when compared to the previous performance except Gradient Boosting classifier whose performance increased from 78% to 81%. Refer Fig. 7.
When the dataset size is 600, the performance of Logistic regression is better with 83% accuracy, followed by Random forest classifier and gradient boosting classifier with 81% accuracy. Refer Fig. 8.
When the dataset size is 800, the performance of Gradient boosting classifier is better with 86% accuracy and Logistic regression with 84% accuracy. Support Vector Machine performs with lowest accuracy of 61% when compared with other models. Refer Fig. 9.
When the dataset size is 1000, the performance of Logistic regression is better with 85% accuracy and support vector machine with lowest accuracy of 73% when compared with other models. Refer Fig. 10.
The dataset of size 32 k is trained using LSTM model and accuracy is captured. The Epoch (Number of times the entire dataset is passed through by the learning algorithm) is changed as 2,3 and performance is captured.
Loss value refers to the errors made during training or validation. When the loss value is lower better model is achieved. The Validation Accuracy achieved for epoch 2 is 89% and it is shown in Fig. 11.
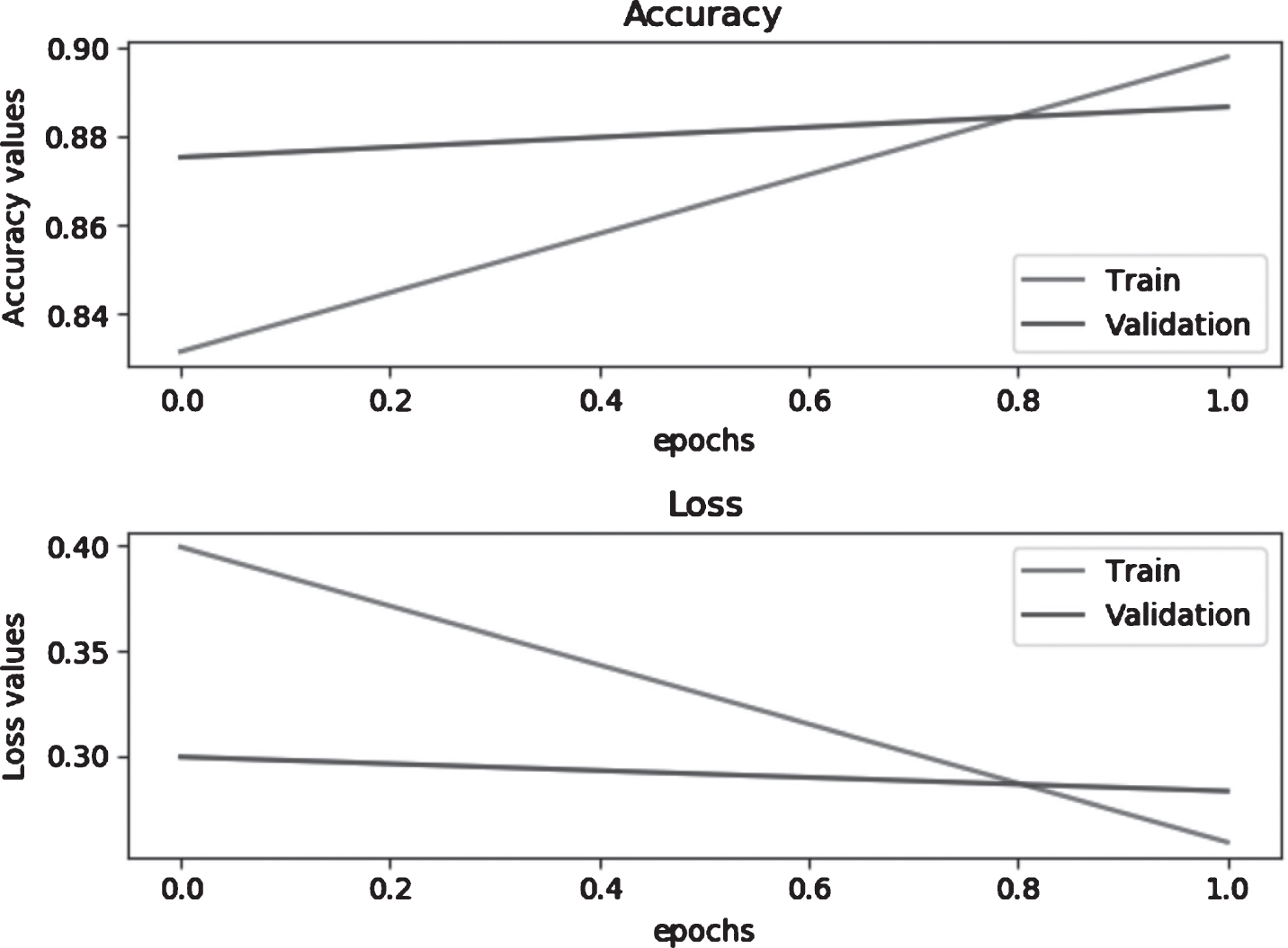
Result: Performance of LSTM with dataset size 32 k with epoch 2 and accuracy 89%.
The Validation Accuracy achieved for epoch 3 is 88% and it is shown in Fig. 12.
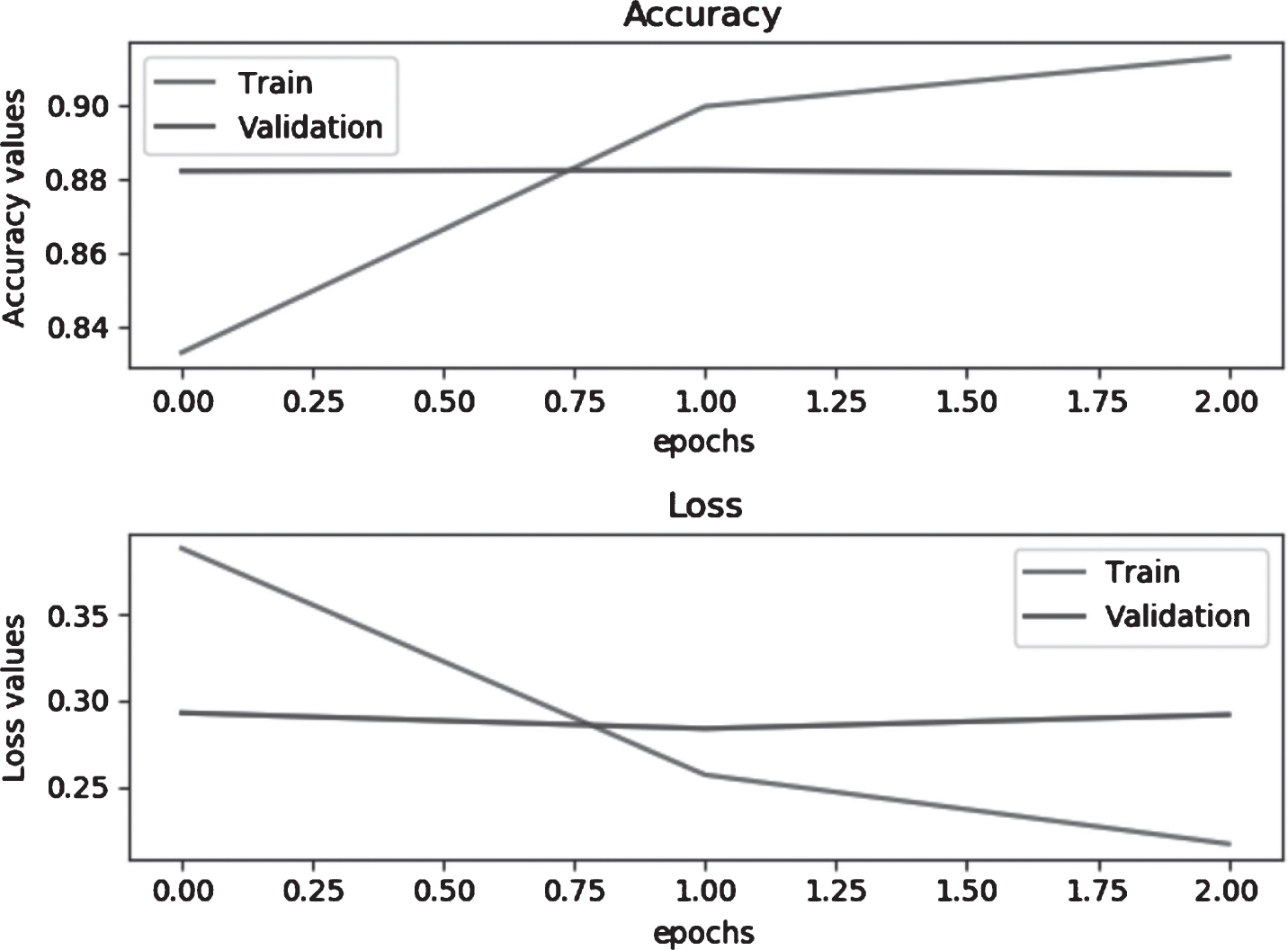
Result: Performance of LSTM with dataset size around 32 k with epoch 3 and accuracy 88%.
On launching the web application, organizations list would appear on the screen. On selecting the organization, feedback review comments are analyzed, and result is updated in the “Result” excel file created in the same location. Sample output is shown in Table 4 and report is generated as shown in Figs. 13 and 14.
Result: Sentiment Predictions using LSTM Algorithm
Result: Sentiment Predictions using LSTM Algorithm
The total count of positive and negative comments is displayed in the pie chart as shown in the Fig. 13.
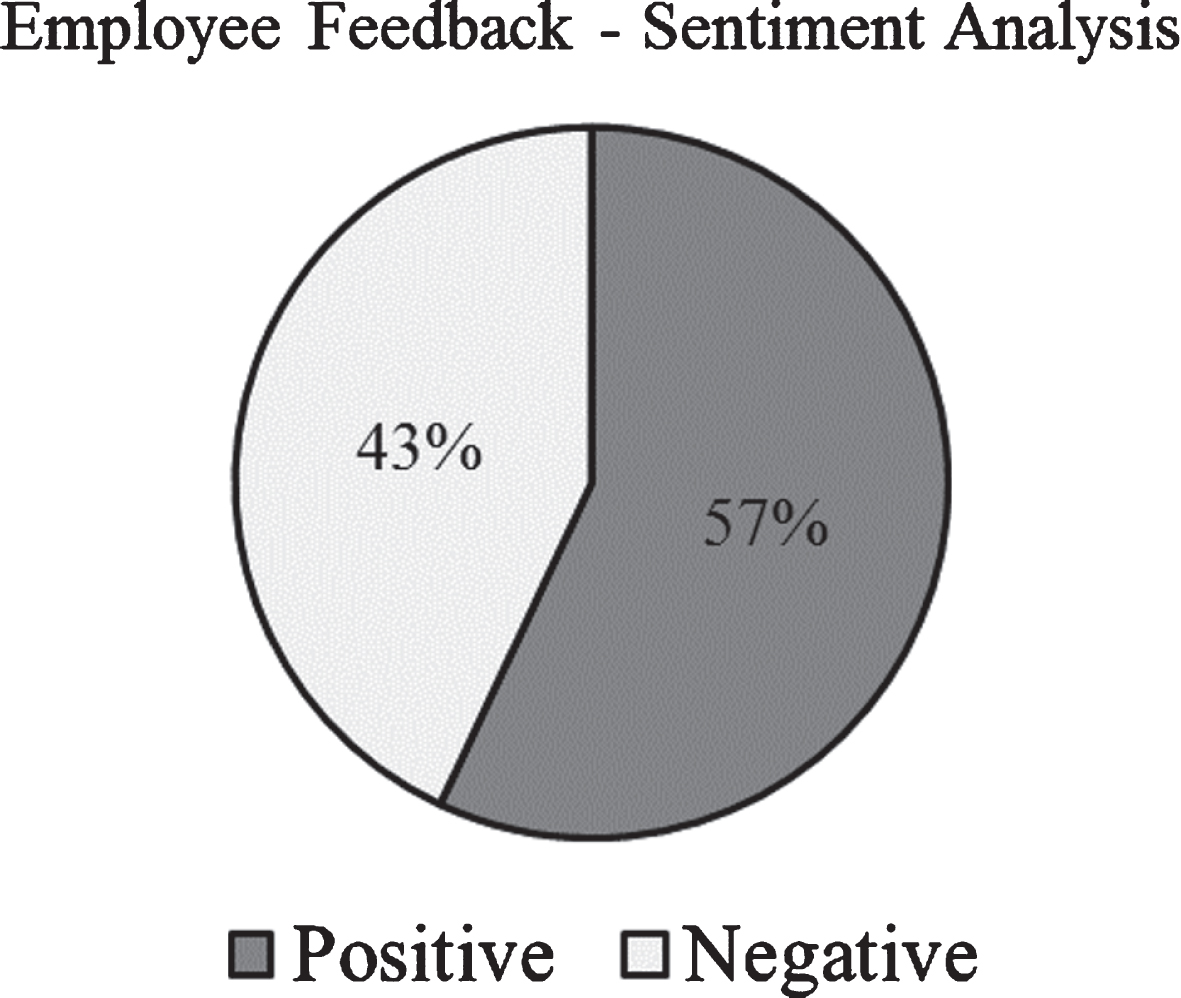
Result: Sentiment Predictions using LSTM Algorithm.
The Bar chart representing the number of positive and negative comments with respect to salary, work culture and pressure is displayed after performing sentiment analysis. Refer Fig. 14.
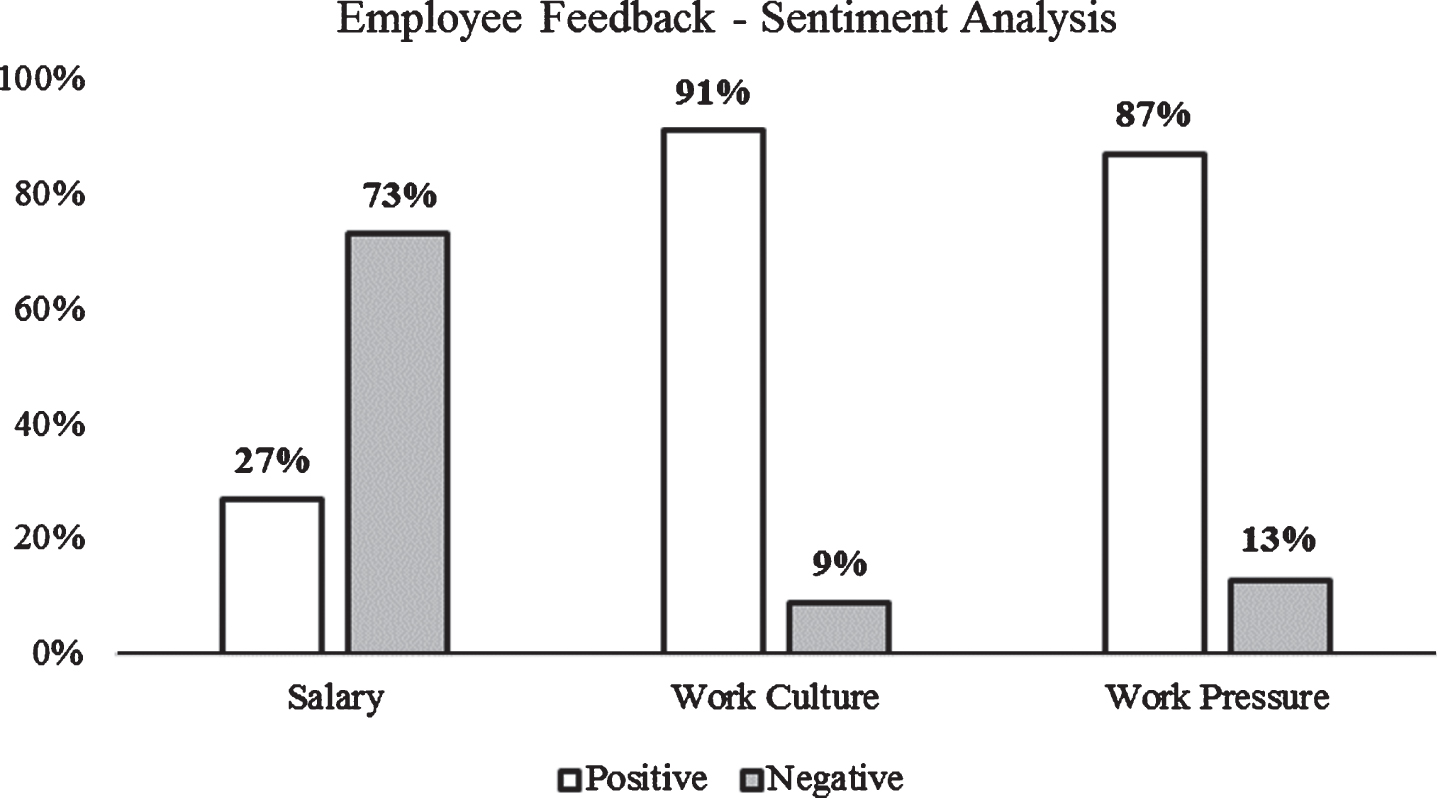
Result: Bar chart representing positive and negative comments with respect to salary, work culture and work pressure.
On comparing our LSTM performance result with the proposed technique mentioned in [1], it is identified that both the results remain in the same range. Refer Table 5.
Result of deep learning based sentiment analysis model
The cognitive performance of various models in training and prediction of employee feedback dataset is found. This paper also analyzes the performance of RNN-LSTM algorithm in training dataset which showed up performance of 89%. Also, sentiment analysis is carried out using RNN-LSTM algorithm.
To run more epochs for large dataset high performance system is required.
With 500 dataset RNN-LSTM displayed an accuracy of 72% [15] whereas with higher datasets like 32 k, accuracy increased to 89%. RNN-LSTM algorithm performed better with bigger dataset. Overall, RNN-LSTM algorithm performed well in training and classifying sentiments.
Though, reasonably good performance is achieved using RNN-LSTM network, still there is scope for future enhancement. To improve the performance and accuracy more hidden layers and 50 K dataset will be used. Number of epochs will be increased to improve the performance and accuracy.
The same procedure could be applied in other applications like college review sentiment analysis [15], product review sentiment analysis. The discussed method could act as an experimental baseline for further research in sentiment analysis using RNN-LSTM algorithm.